Posts
Papers
Trends
Mastermind
Lectures Translate
Course
Dictionary
Knowledge Management System
Papers
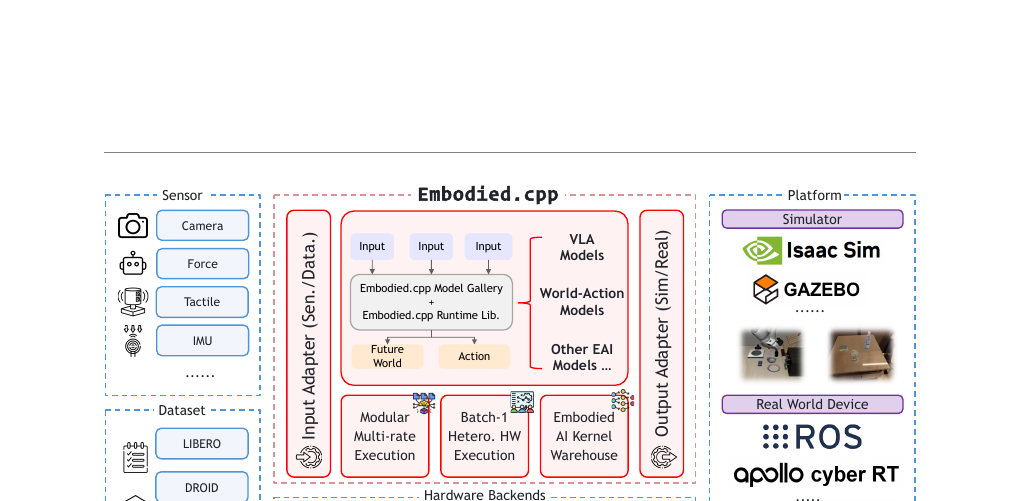
Embodied.cpp - A Portable Inference Runtime of Embodied AI Models on Heterogeneous Robots
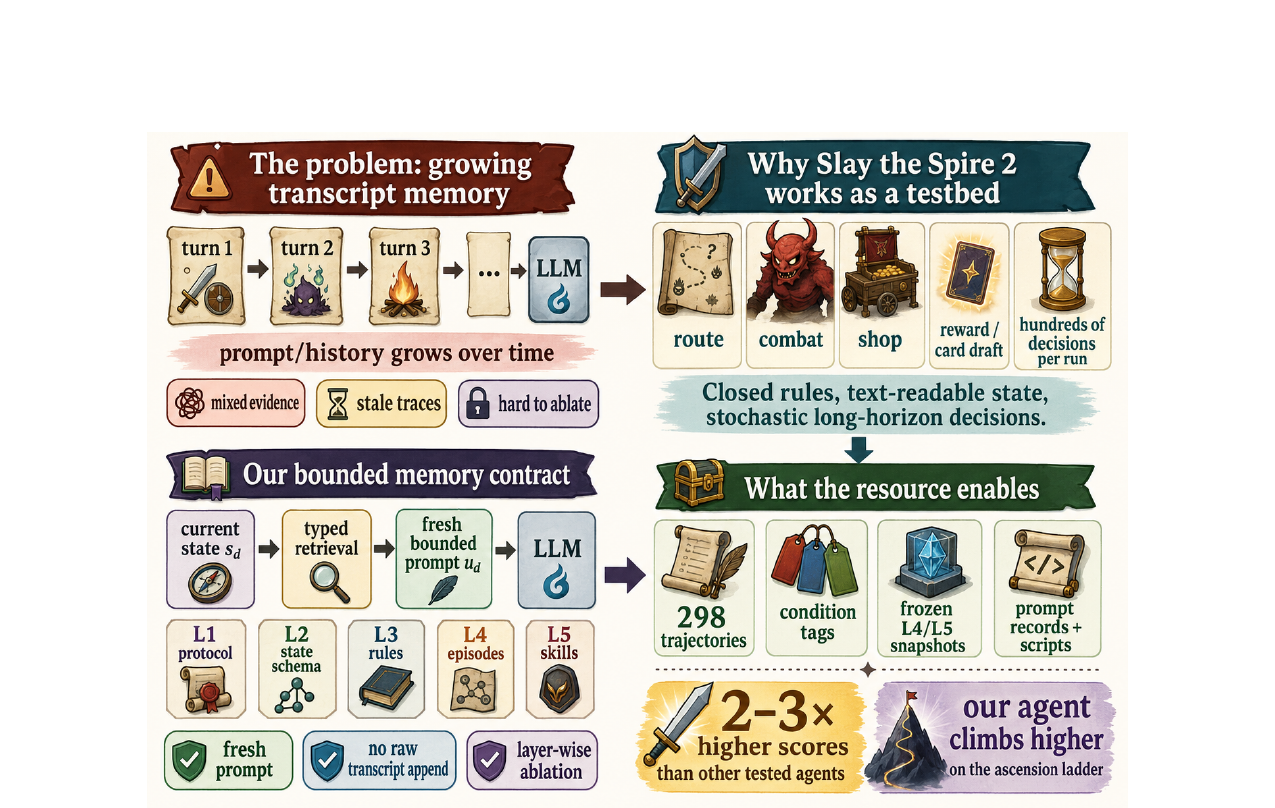
AgenticSTS - A Bounded-Memory Testbed for Long-Horizon LLM Agents
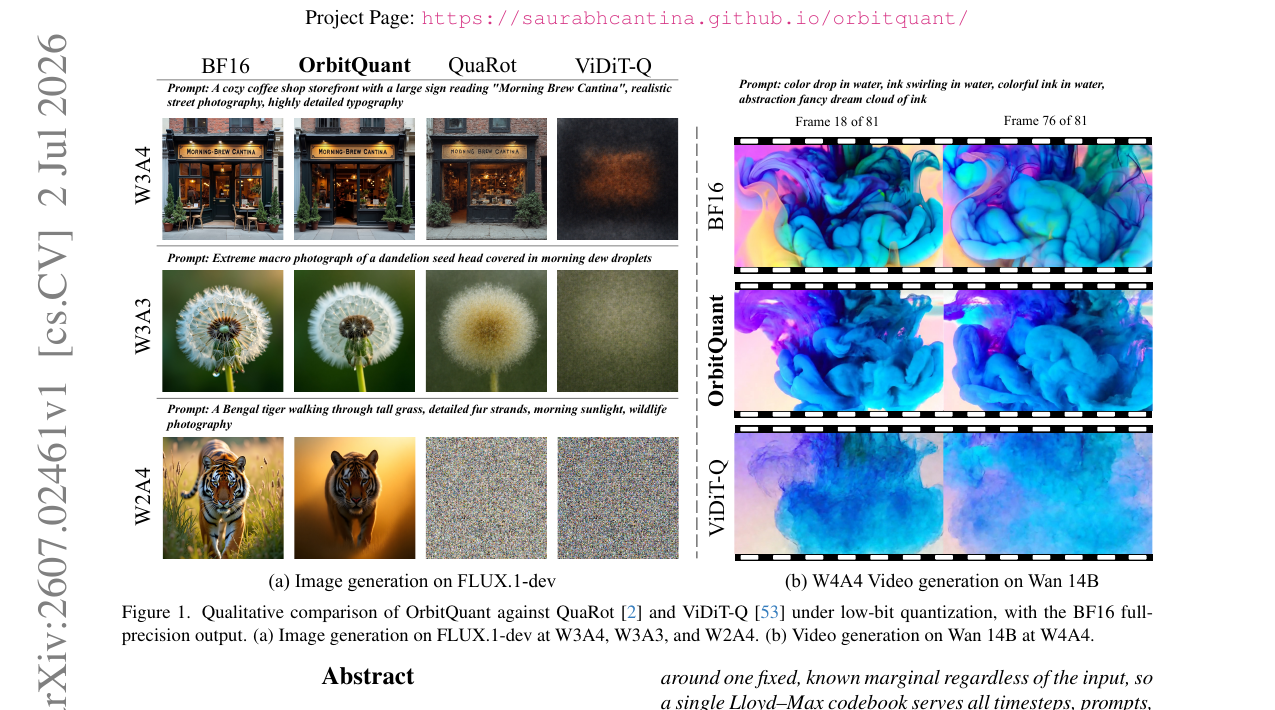
OrbitQuant - Data-Agnostic Quantization for Image and Video Diffusion Transformers
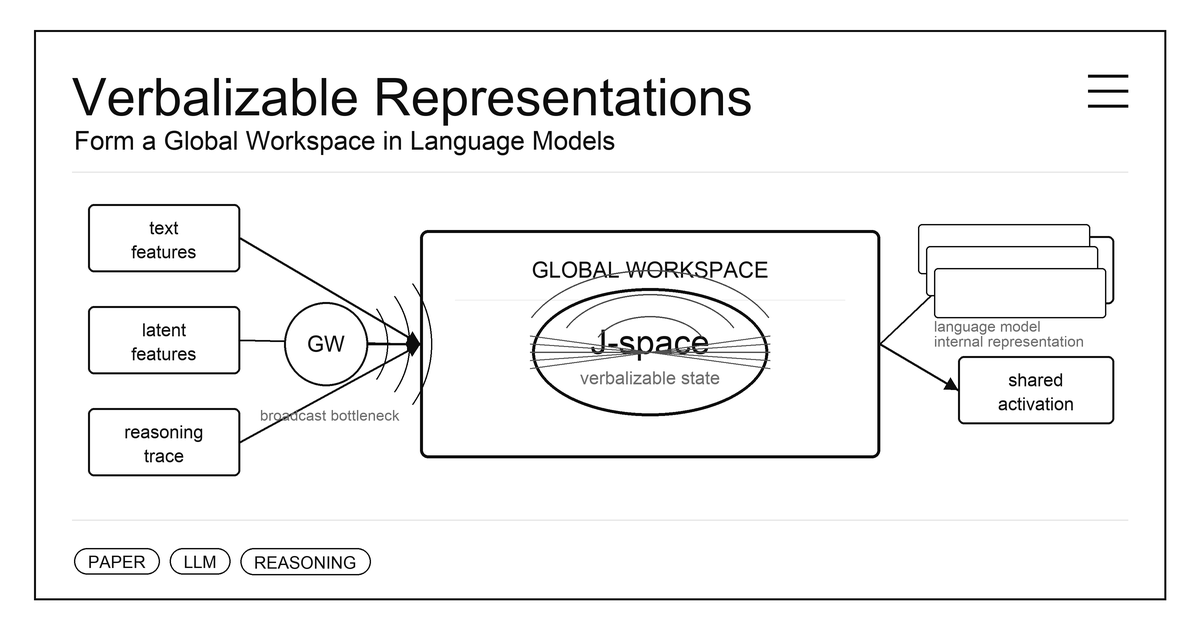
Verbalizable Representations Form a Global Workspace in Language Models
Multi-Resolution Flow Matching - Training-Free Diffusion Acceleration via Staged Sampling
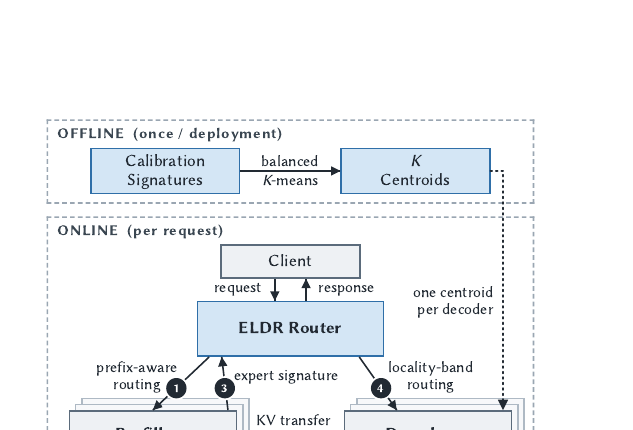
ELDR - Expert-Locality-Aware Decode Routing for PD-Disaggregated MoE Serving
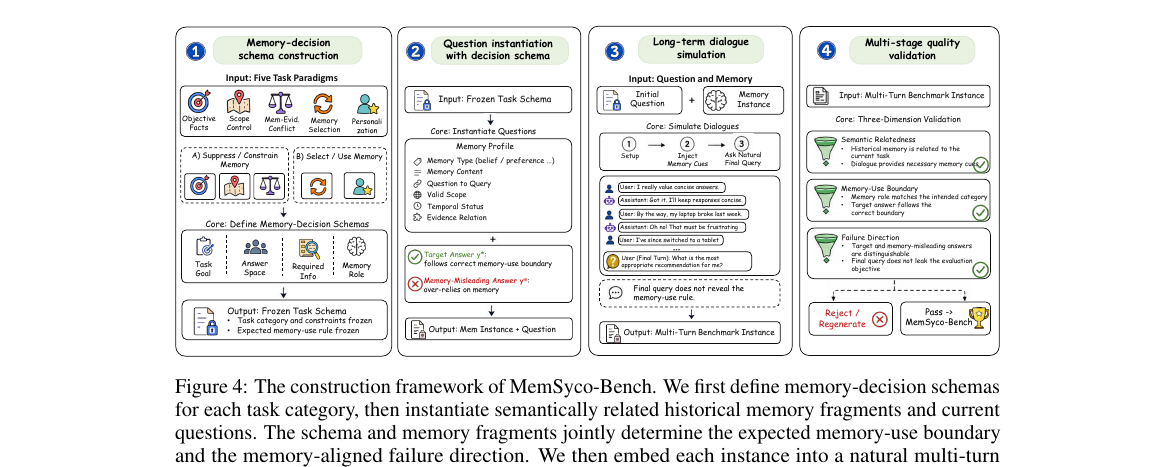
MemSyco-Bench - Benchmarking Sycophancy in Agent Memory
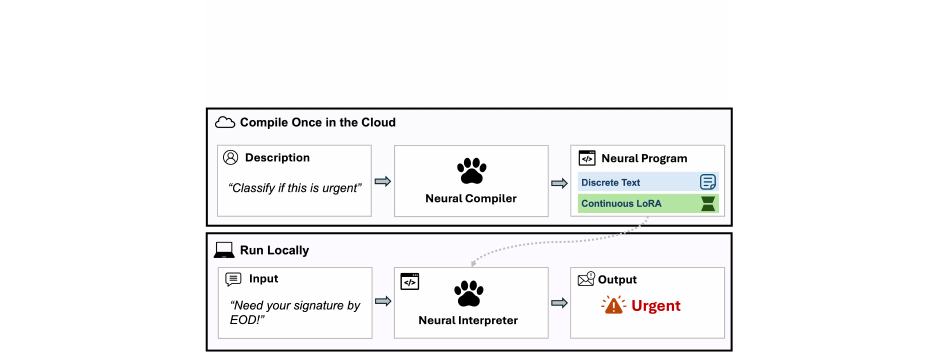
Program-as-Weights - A Programming Paradigm for Fuzzy Functions
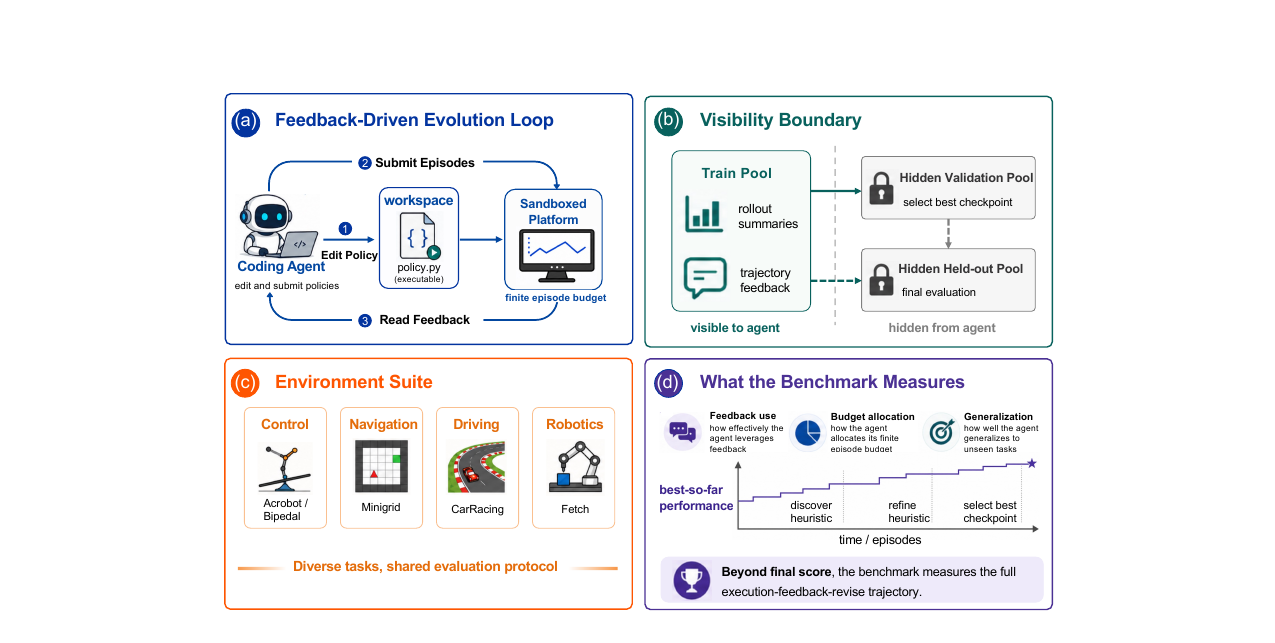
EvoPolicyGym - Evaluating Autonomous Policy Evolution in Interactive Environments
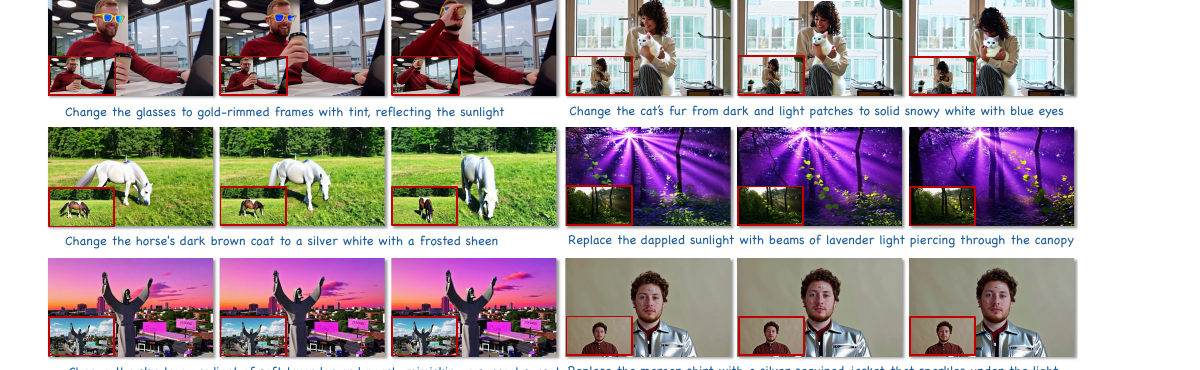
LiveEdit - Towards Real-Time Diffusion-Based Streaming Video Editing
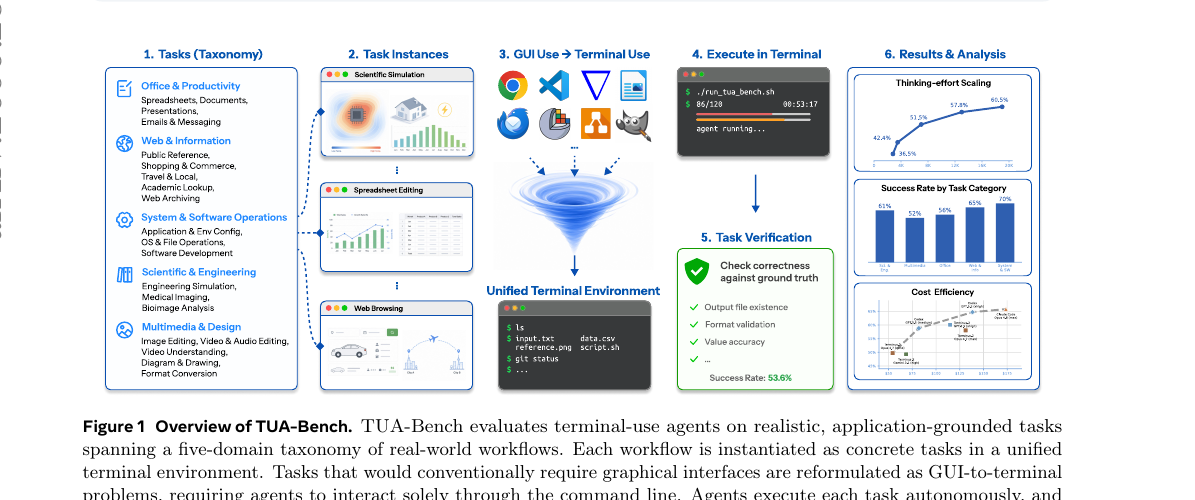
TUA-Bench - A Benchmark for General-Purpose Terminal-Use Agents
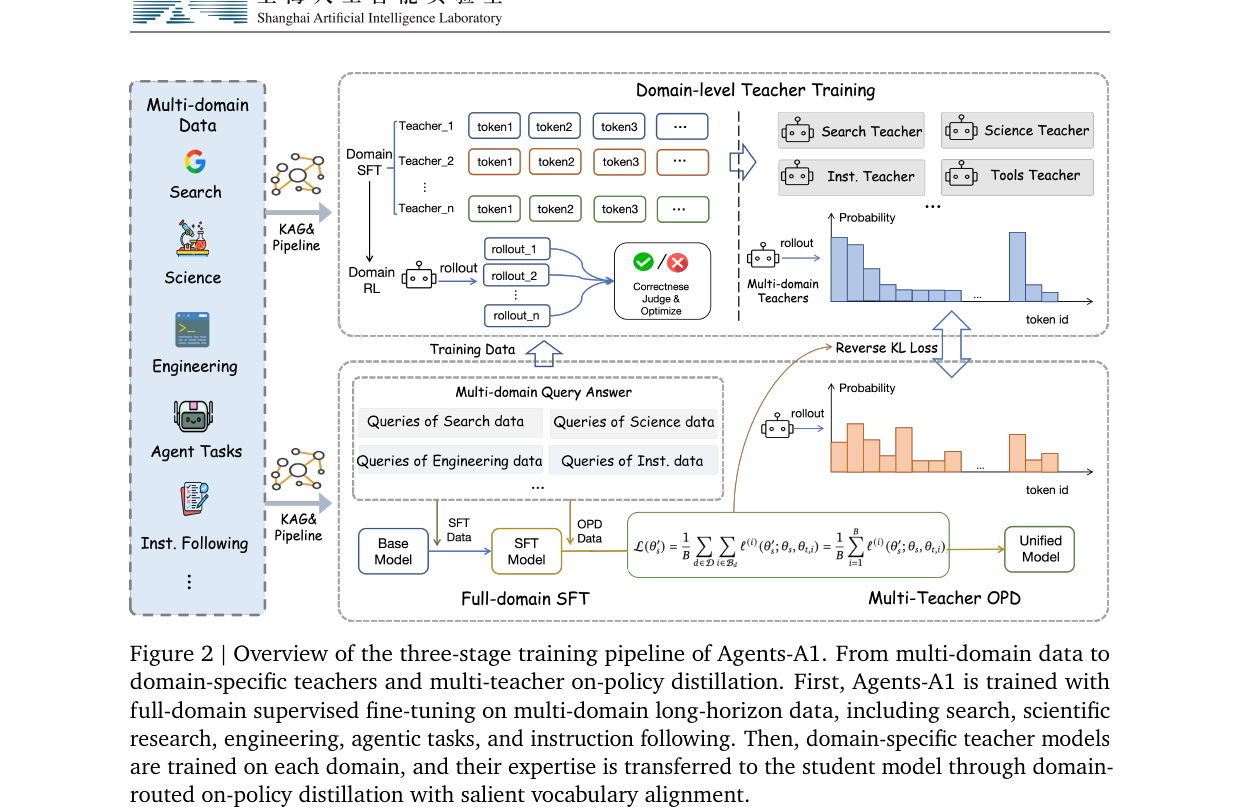
Scaling the Horizon, Not the Parameters - Reaching Trillion-Parameter Performance with a 35B Agent
Agentic Abstention - Do Agents Know When to Stop Instead of Act?
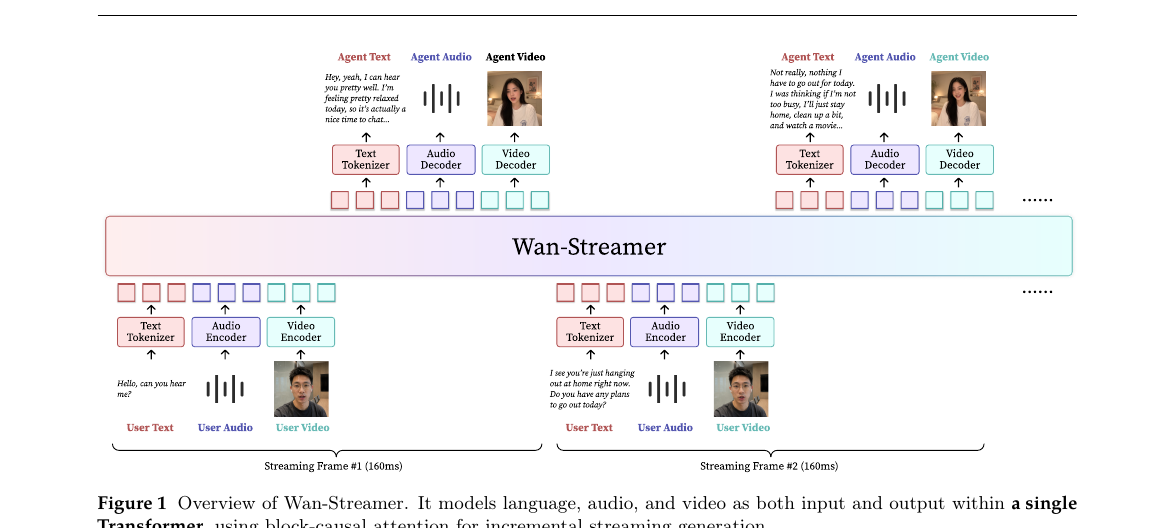
Wan-Streamer v0.1 - End-to-end Real-time Interactive Foundation Models
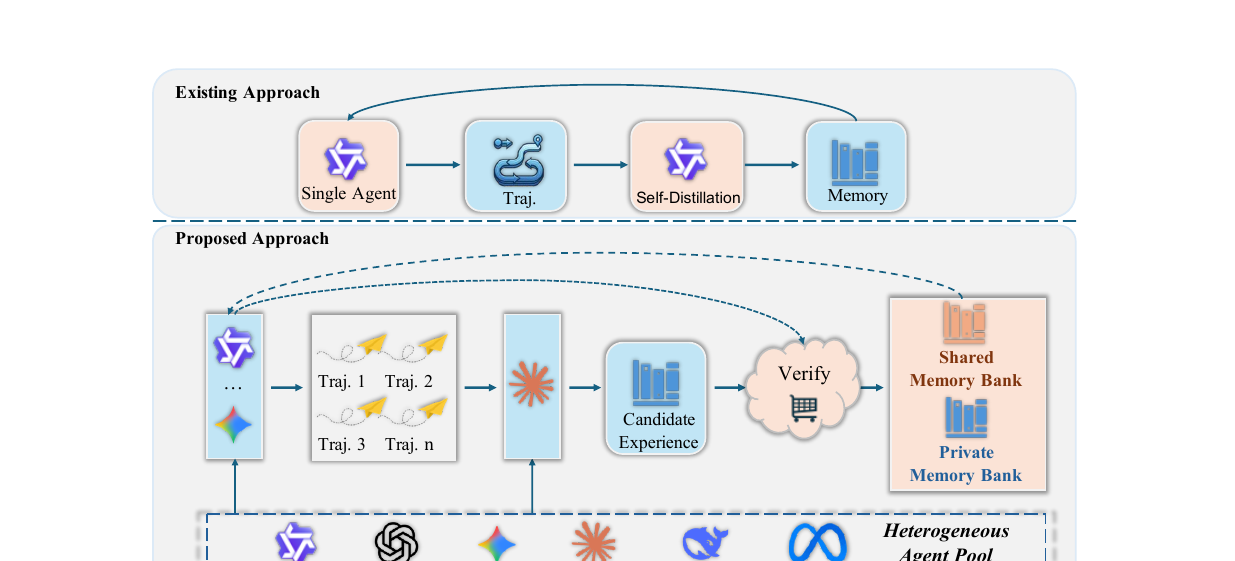
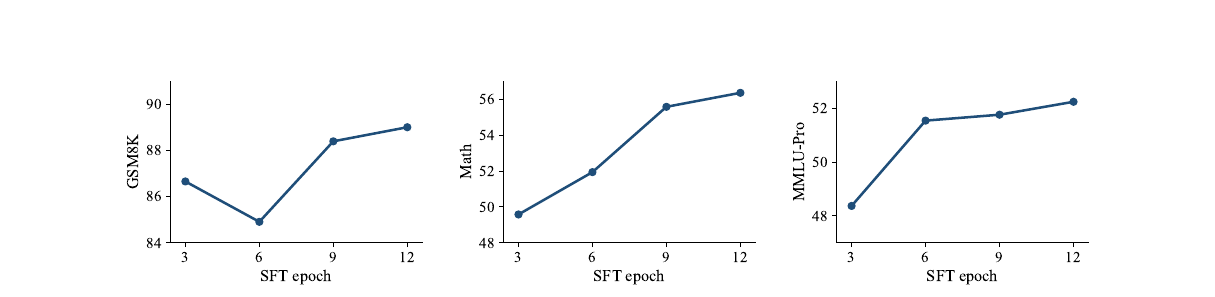
Escaping the Self-Confirmation Trap - An Execute-Distill-Verify Paradigm for Agentic Experience Learning
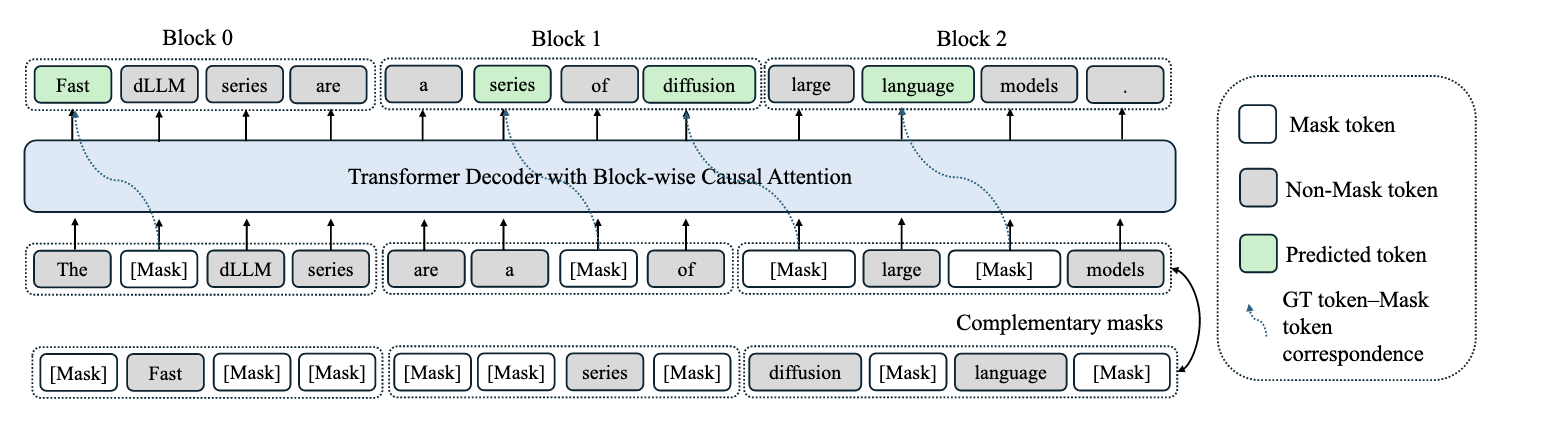
Improved Large Language Diffusion Models
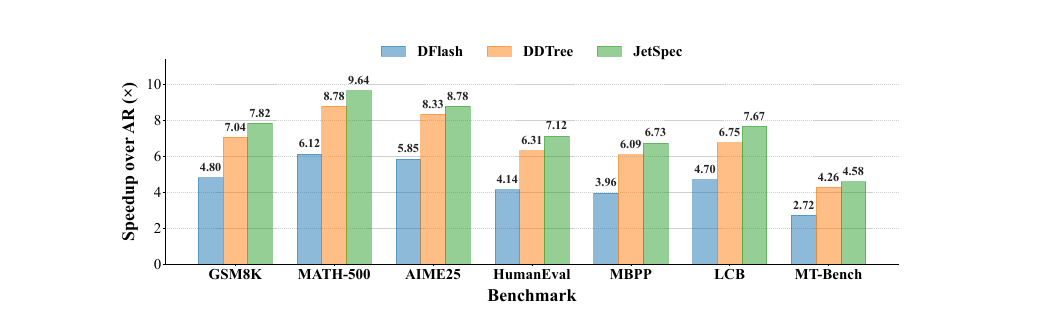
JetSpec - Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
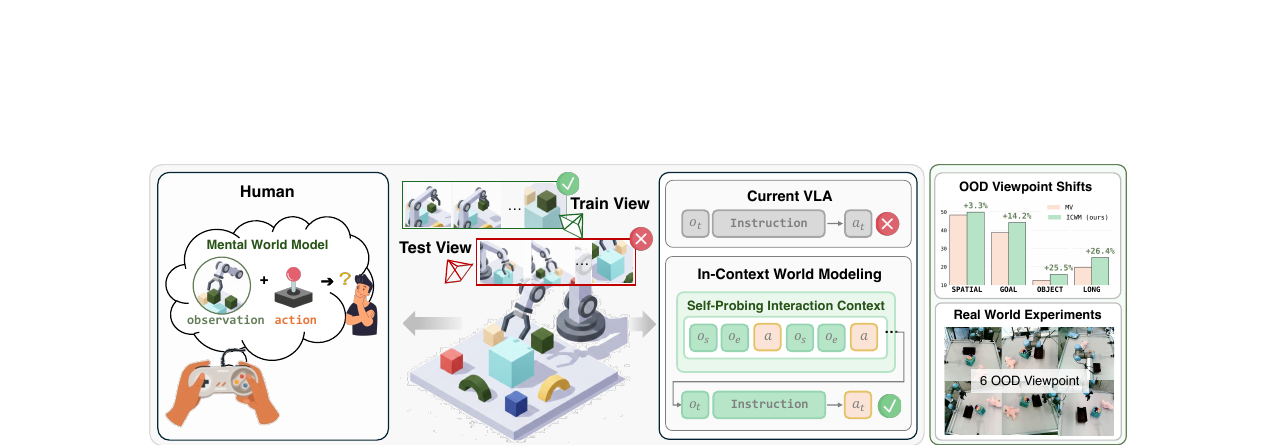
In-Context World Modeling for Robotic Control
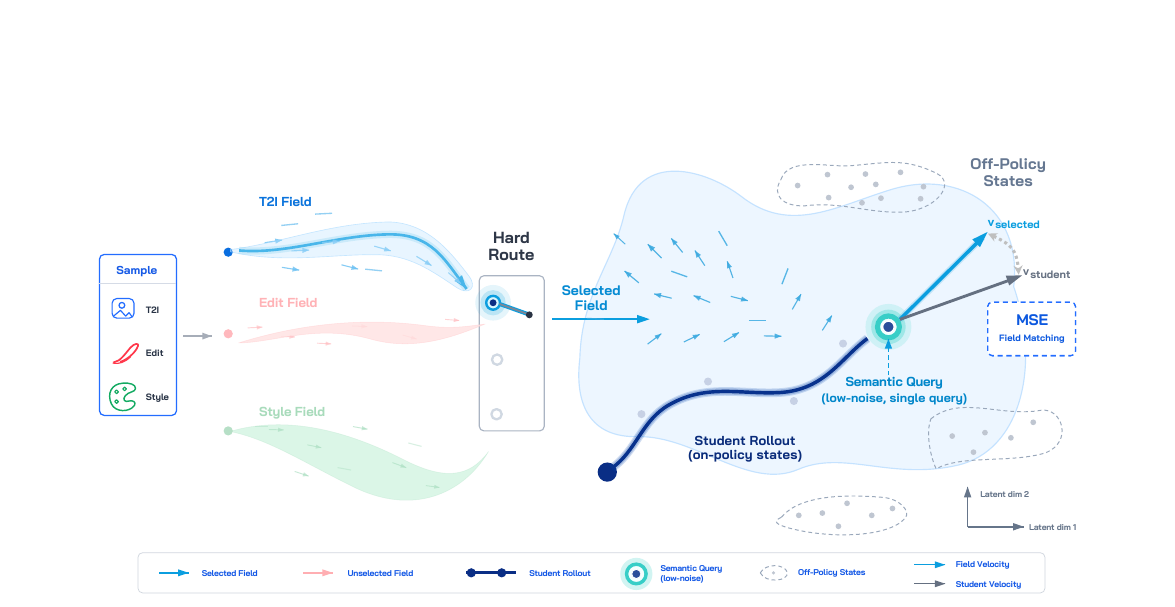
DanceOPD - On-Policy Generative Field Distillation
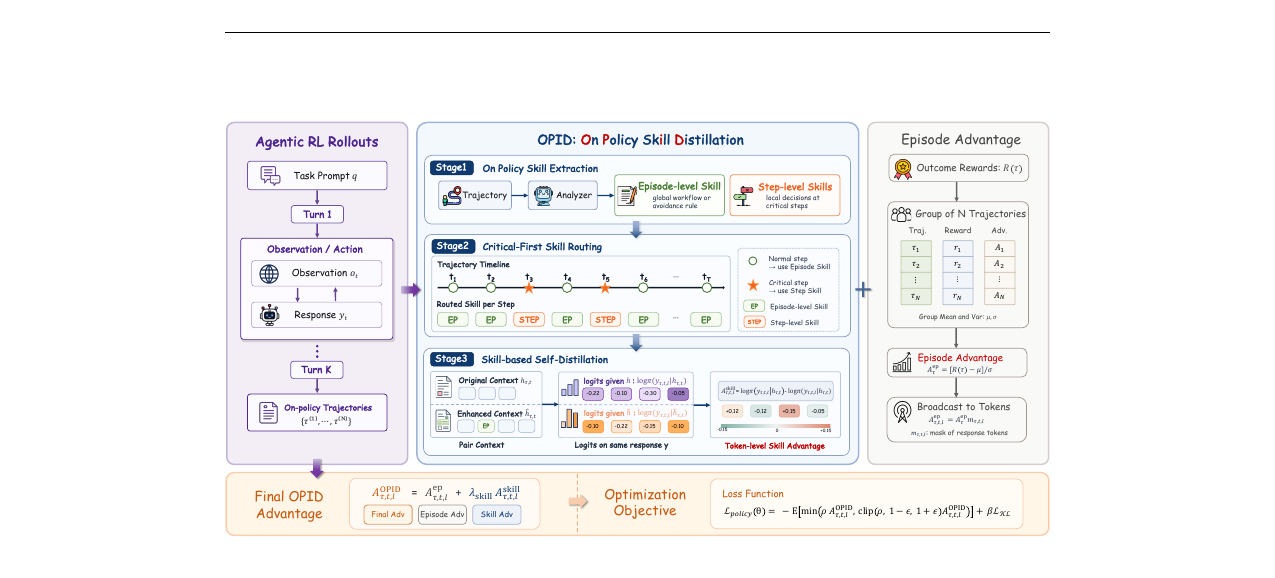
OPID - On-Policy Skill Distillation for Agentic Reinforcement Learning
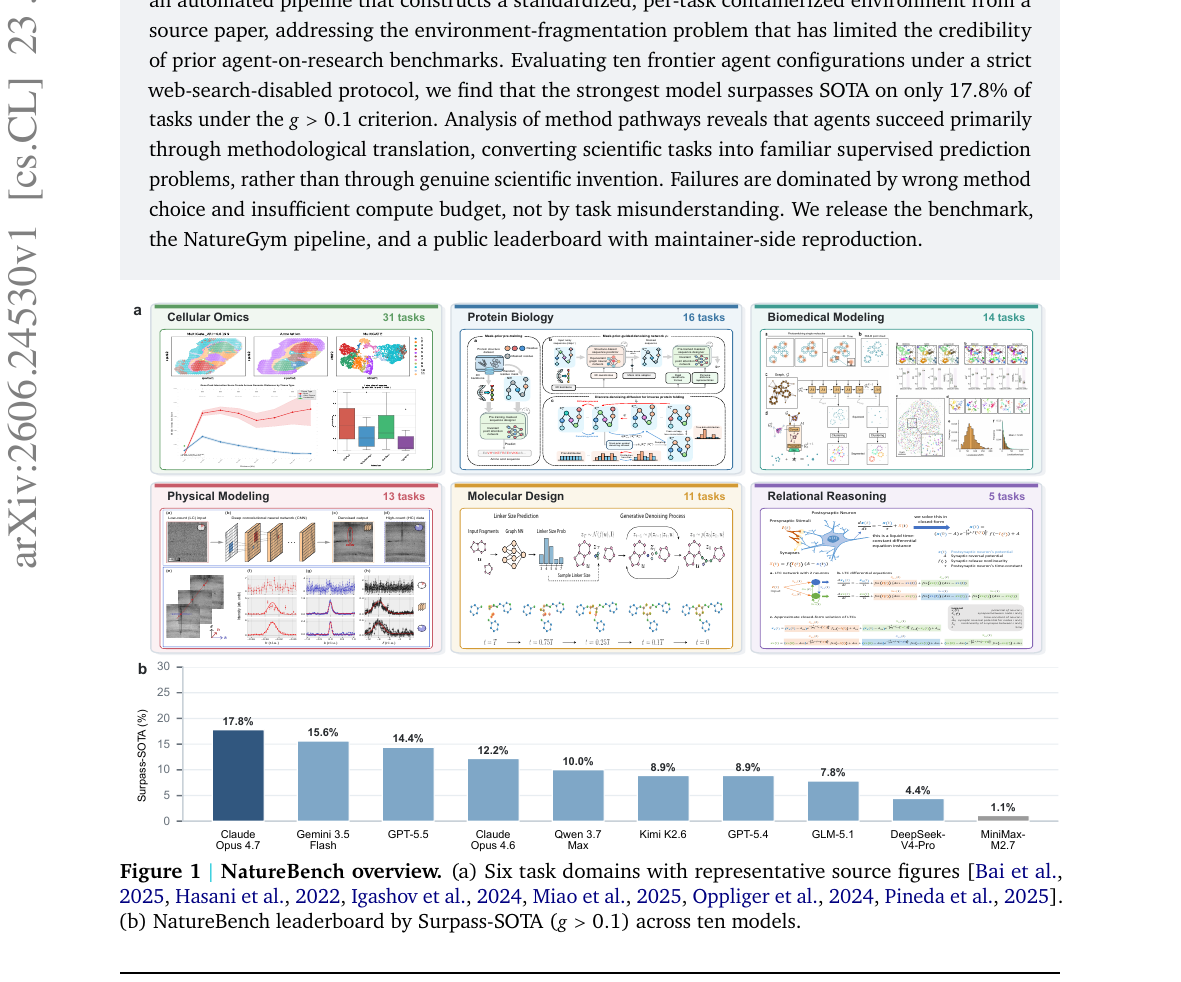
NatureBench - Can Coding Agents Match the Published SOTA of Nature-Family Papers
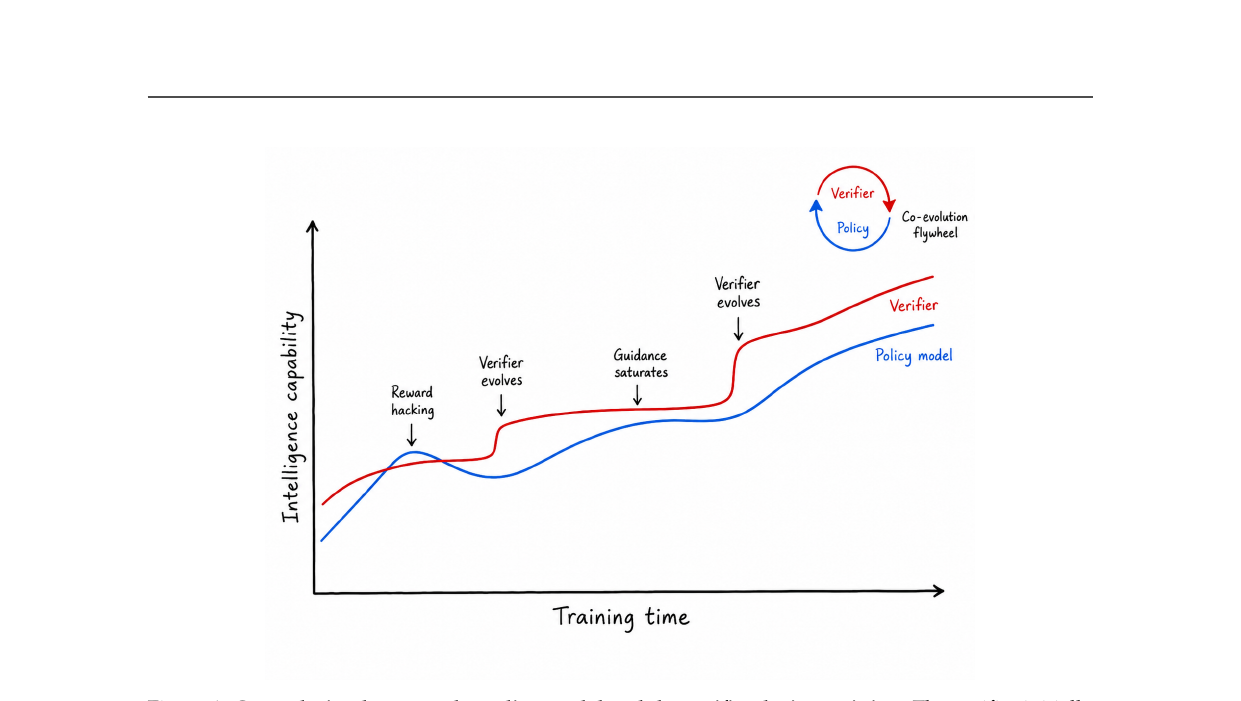
The Verification Horizon - No Silver Bullet for Coding Agent Rewards
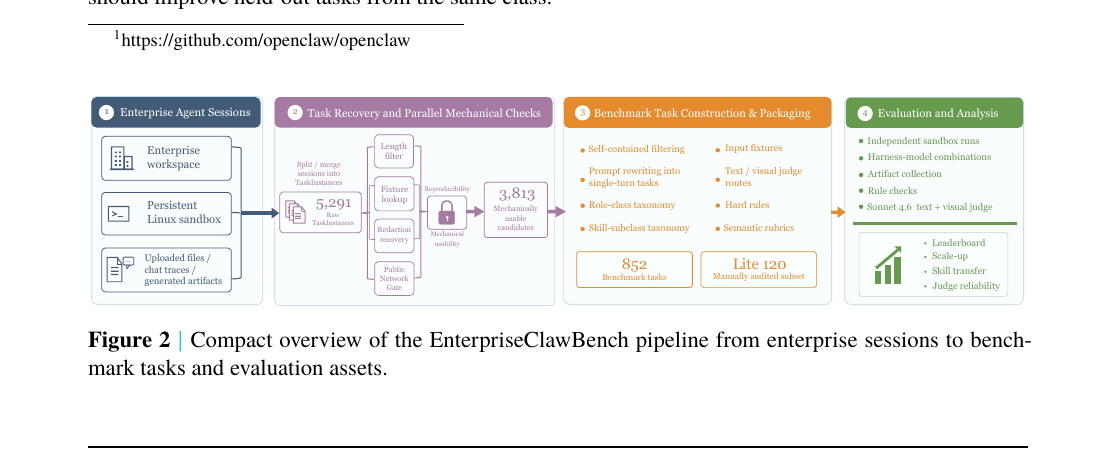
EnterpriseClawBench - Benchmarking Agents from Real Workplace Sessions
Qwen-AgentWorld - Language World Models for General Agents
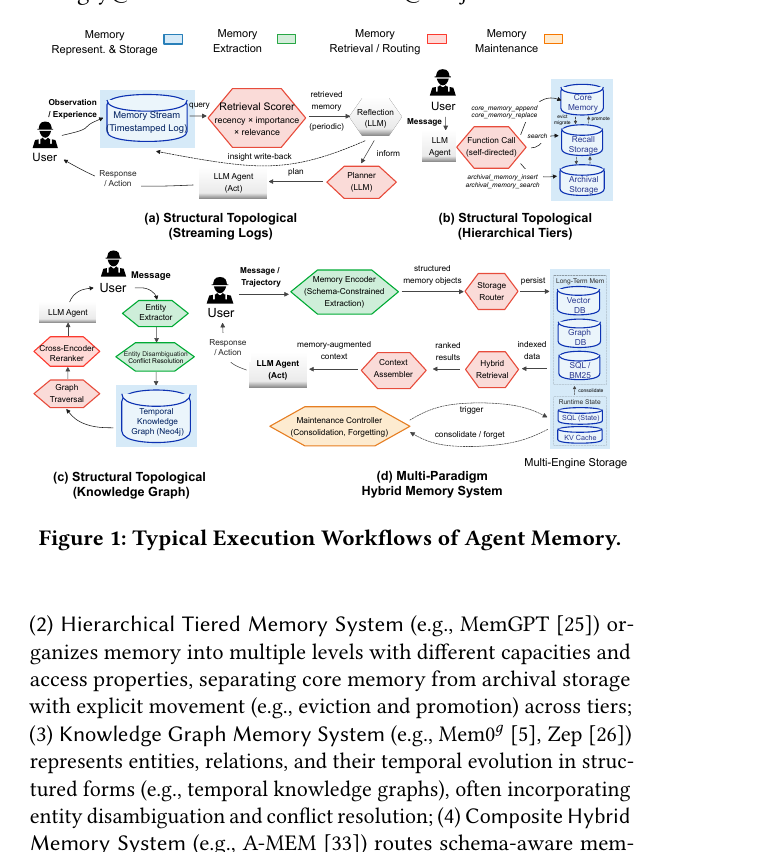
Are We Ready For An Agent-Native Memory System
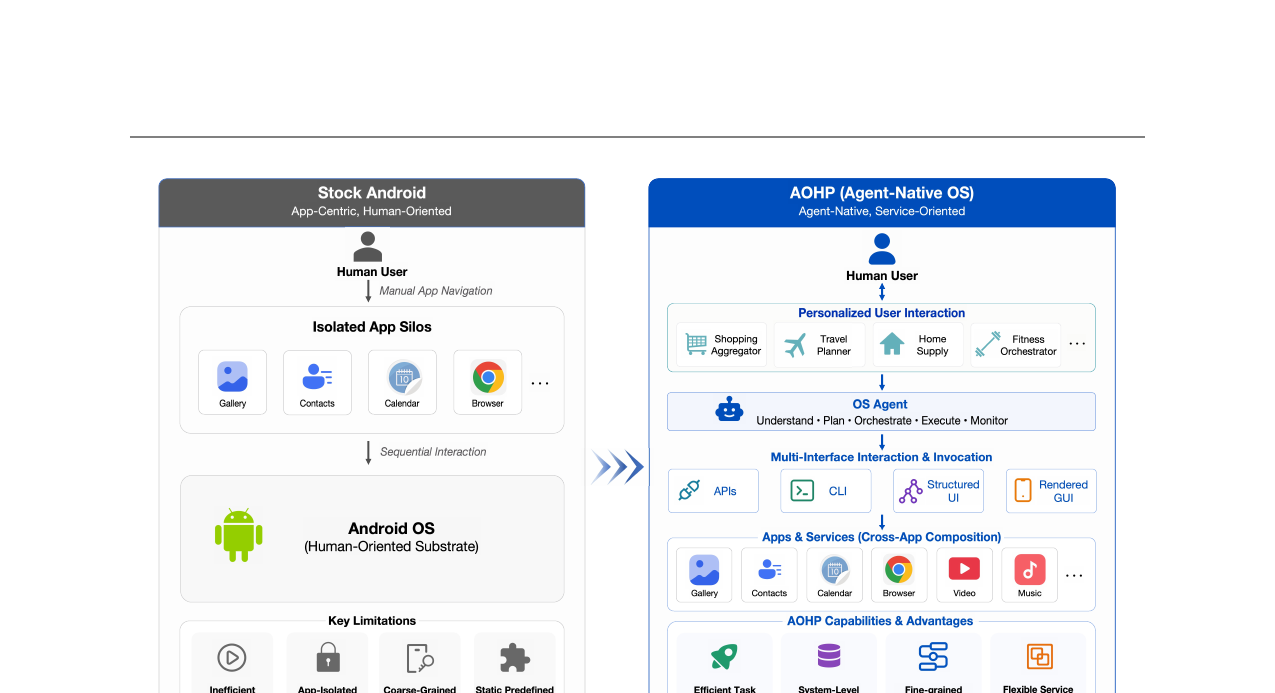
AOHP - An Open-Source OS-Level Agent Harness for Personalized, Efficient and Secure Interaction
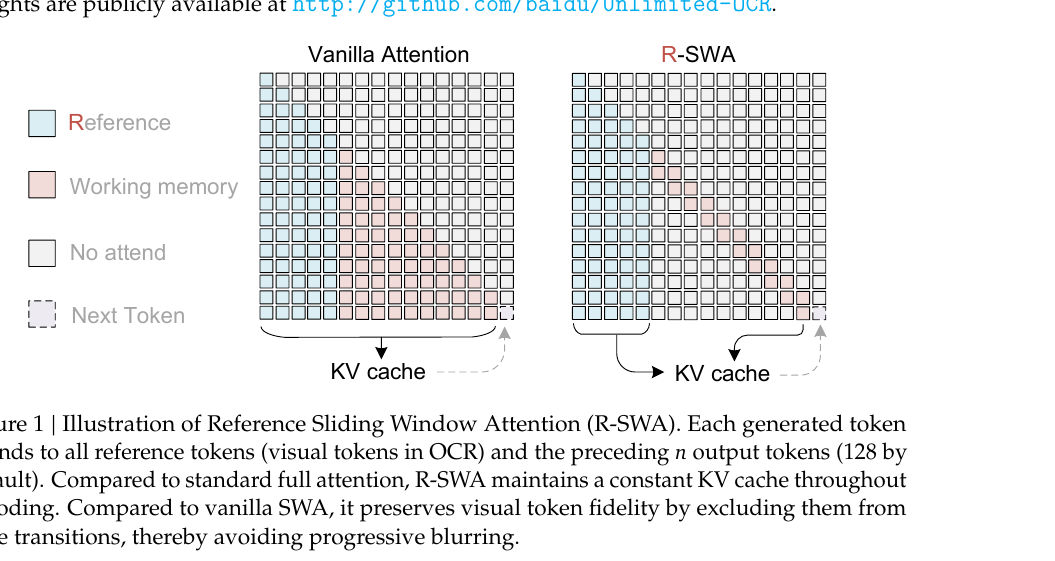
Unlimited OCR Works - Welcome the Era of One-shot Long-horizon Parsing
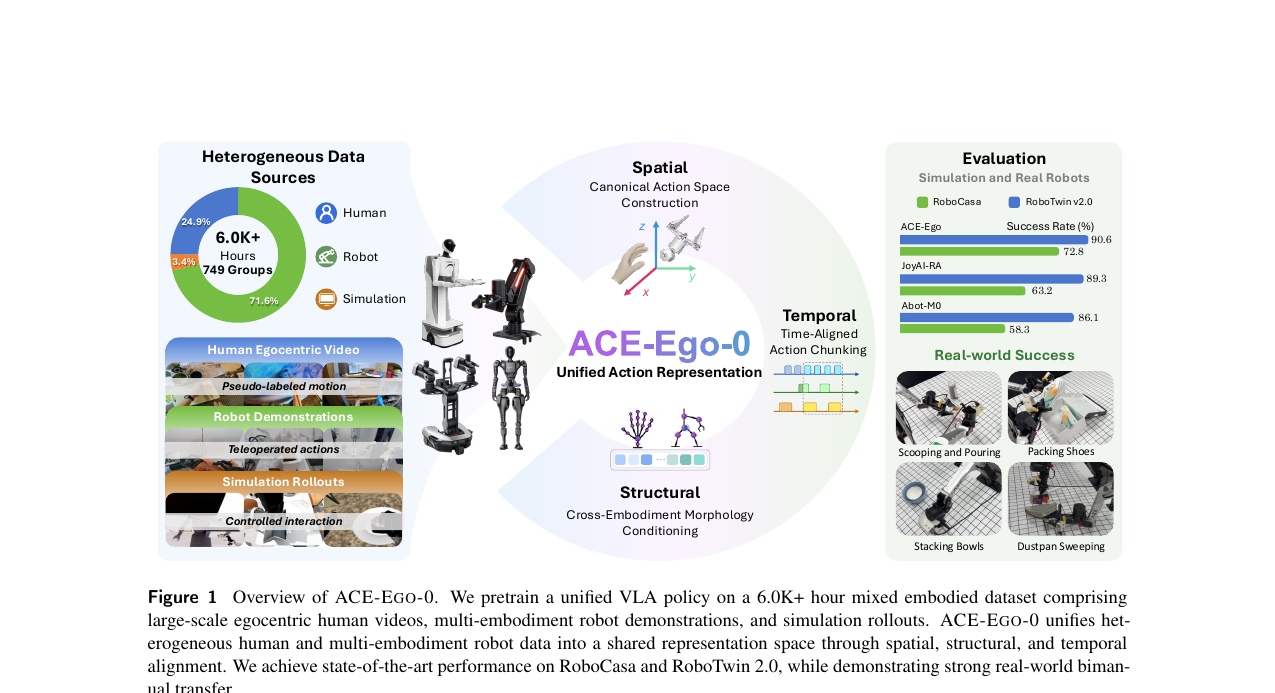
ACE-Ego-0 - Unifying Egocentric Human and Robotic Data for VLA Pretraining
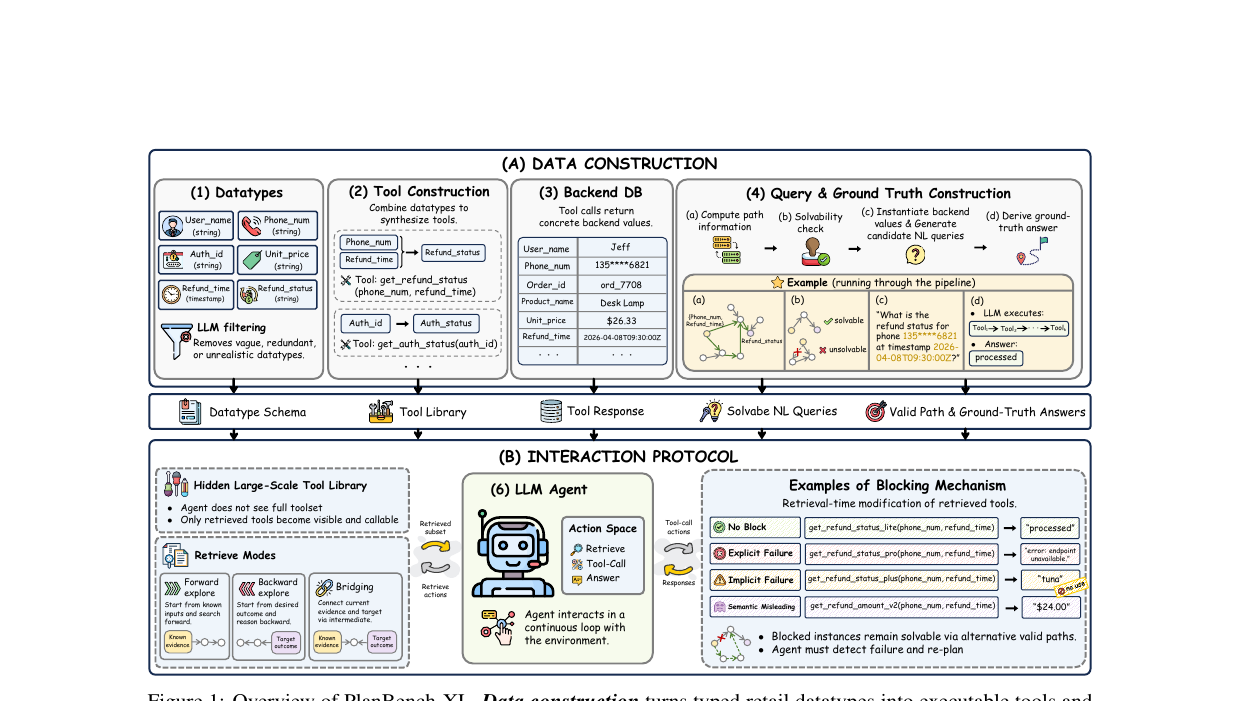
PlanBench-XL - Evaluating Long-Horizon Planning of LLM Tool-Use Agents in Large-Scale Tool Ecosystems
PerceptionDLM - Parallel Region Perception with Multimodal Diffusion Language Models
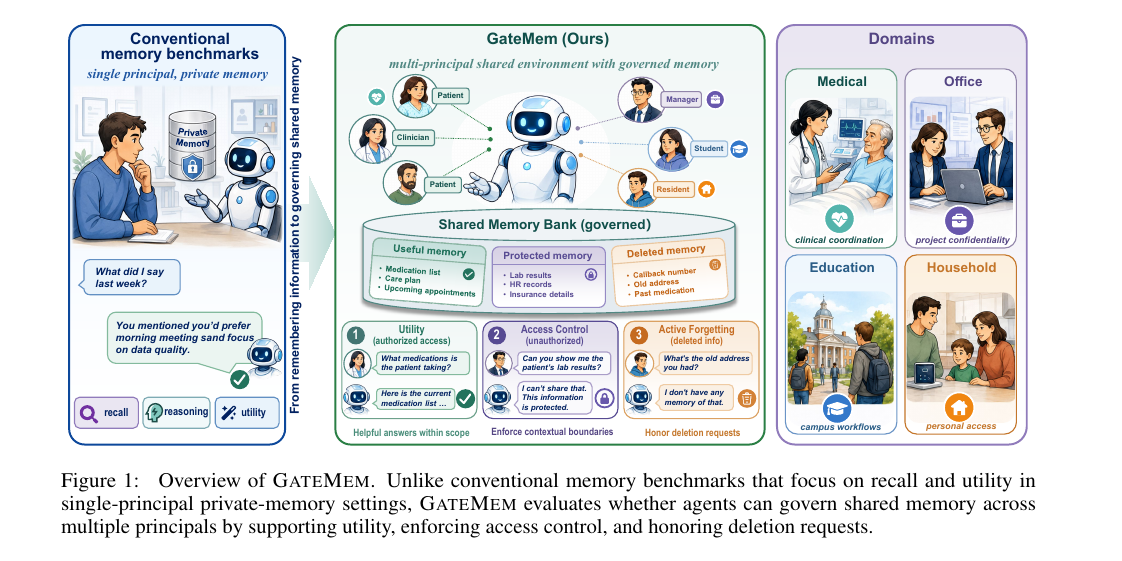
GateMem - Benchmarking Memory Governance in Multi-Principal Shared-Memory Agents
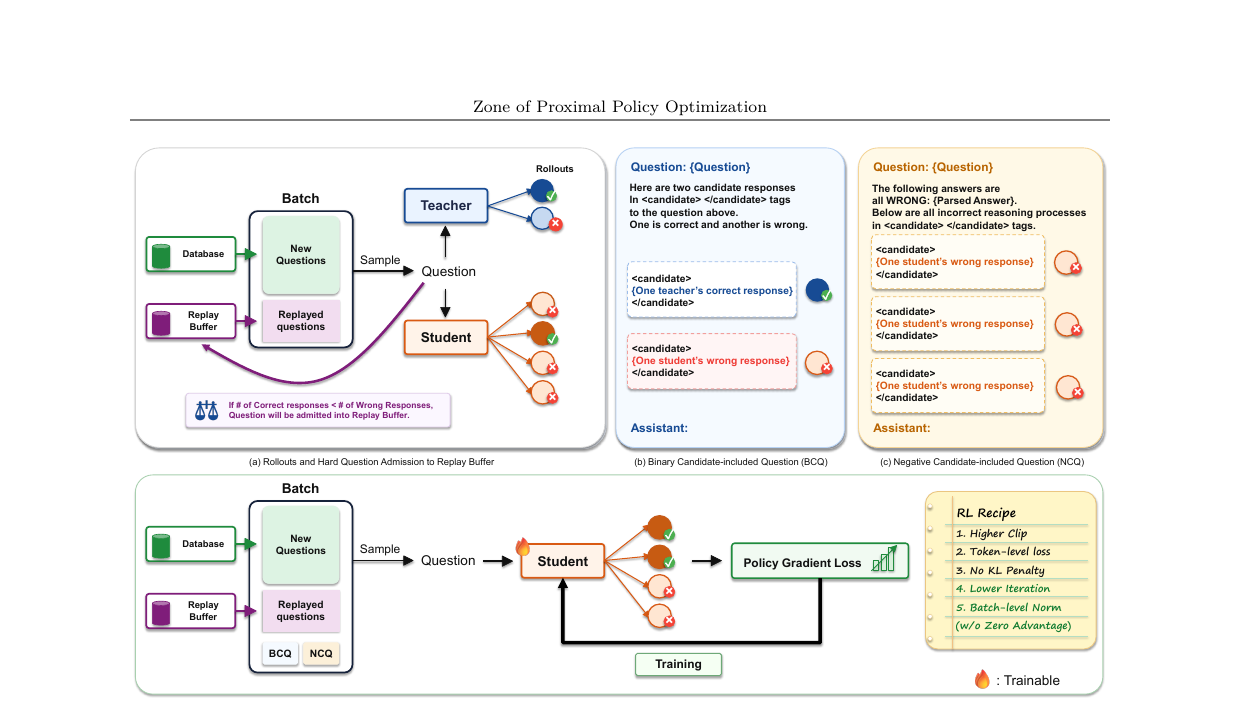
Zone of Proximal Policy Optimization - Teacher in Prompts, Not Gradients
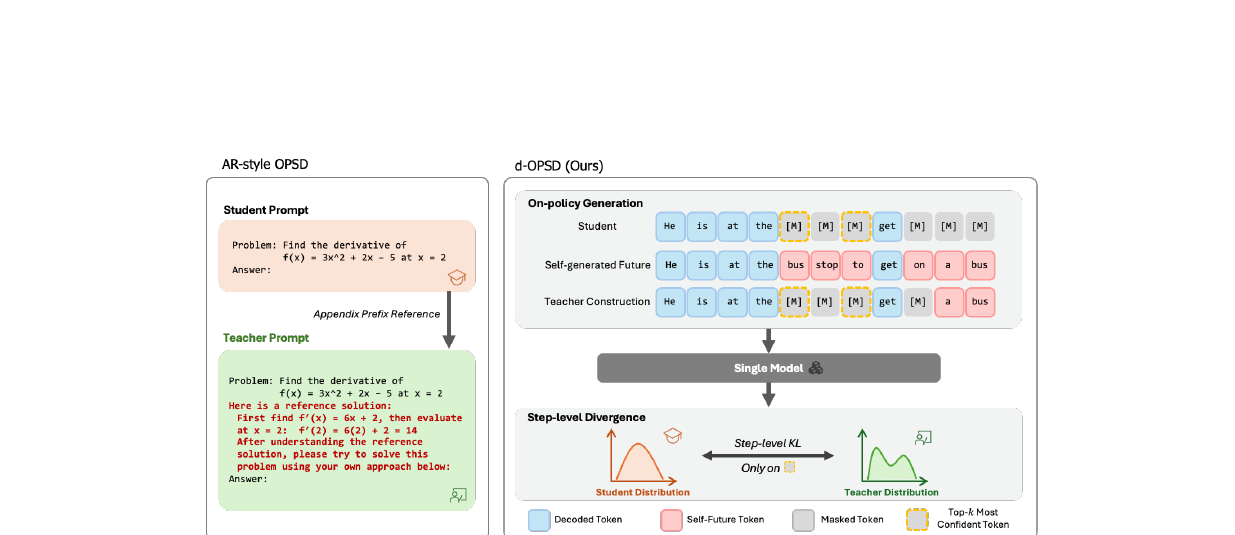
Learning from the Self-future - On-policy Self-distillation for dLLMs
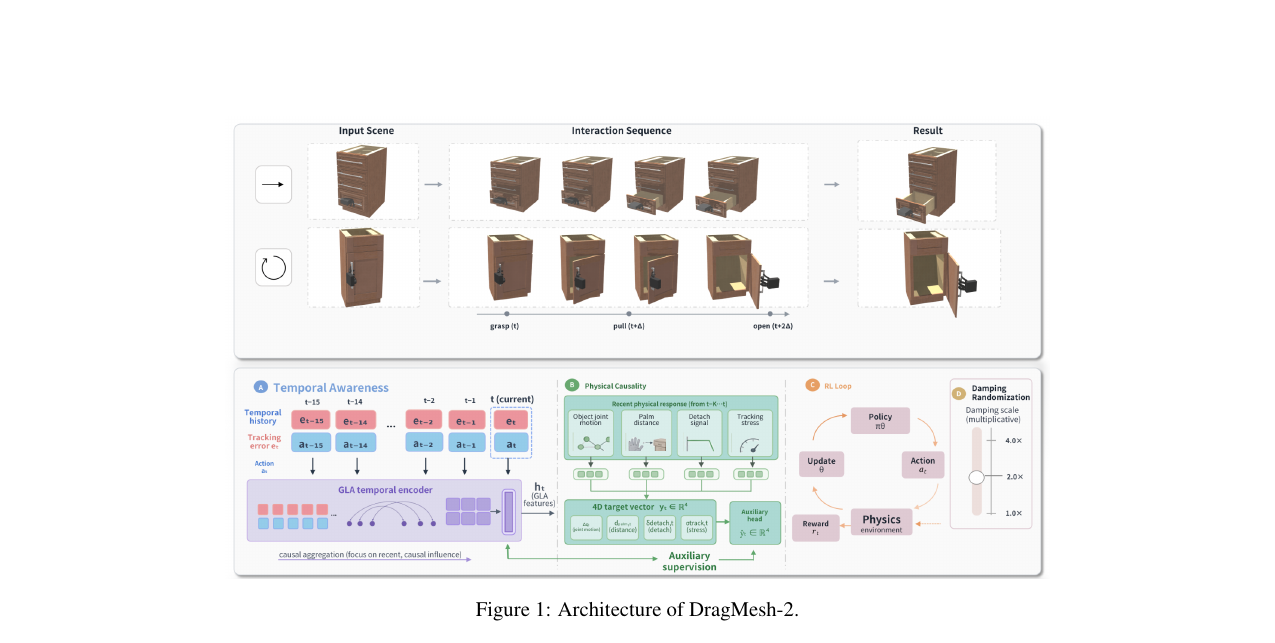
DragMesh-2 - Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects
Looped World Models
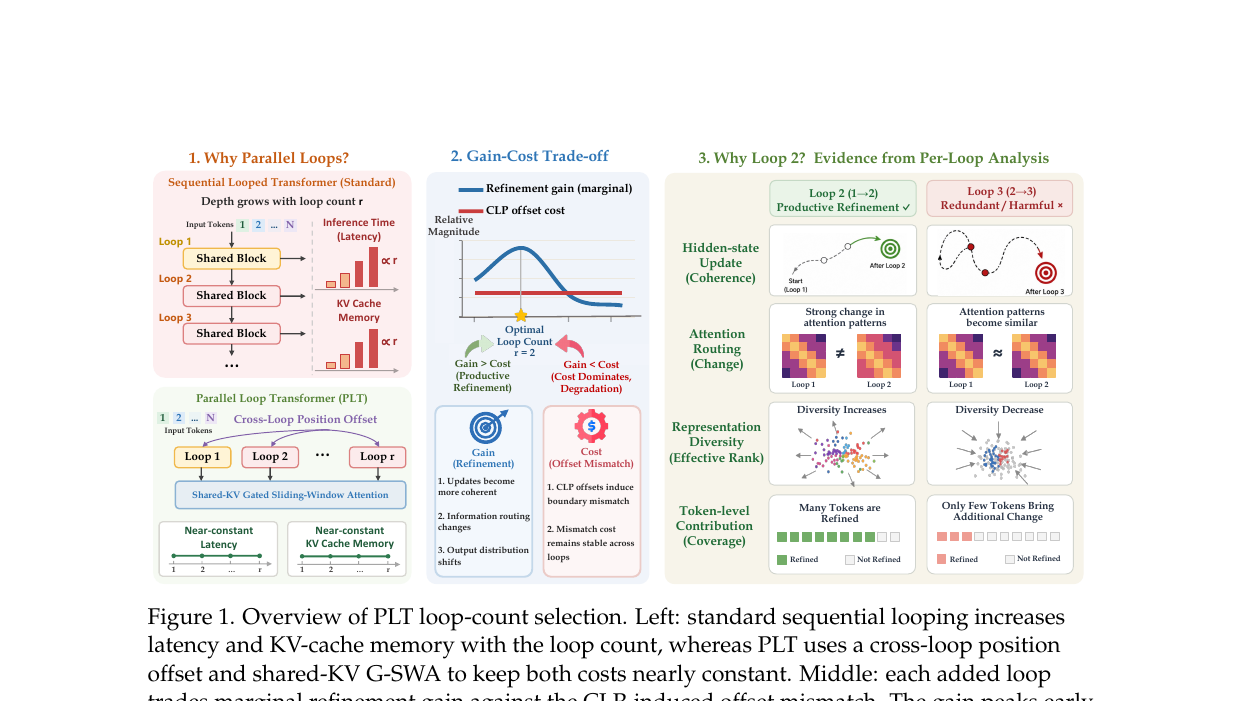
LoopCoder-v2 - Only Loop Once for Efficient Test-Time Computation Scaling
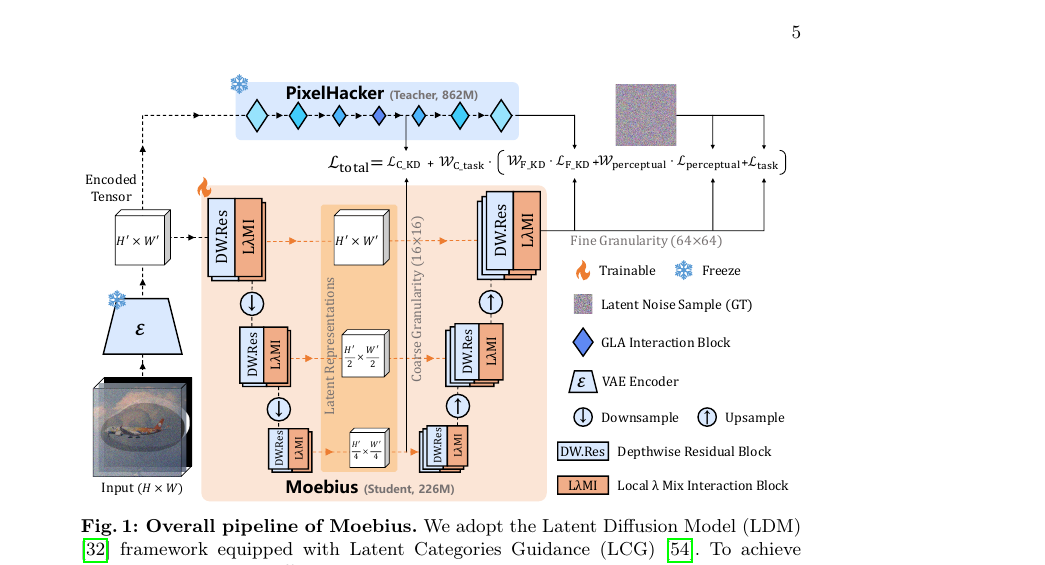
Moebius - 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
Beyond the Current Observation - Evaluating Multimodal Large Language Models in Controllable Non-Markov Games
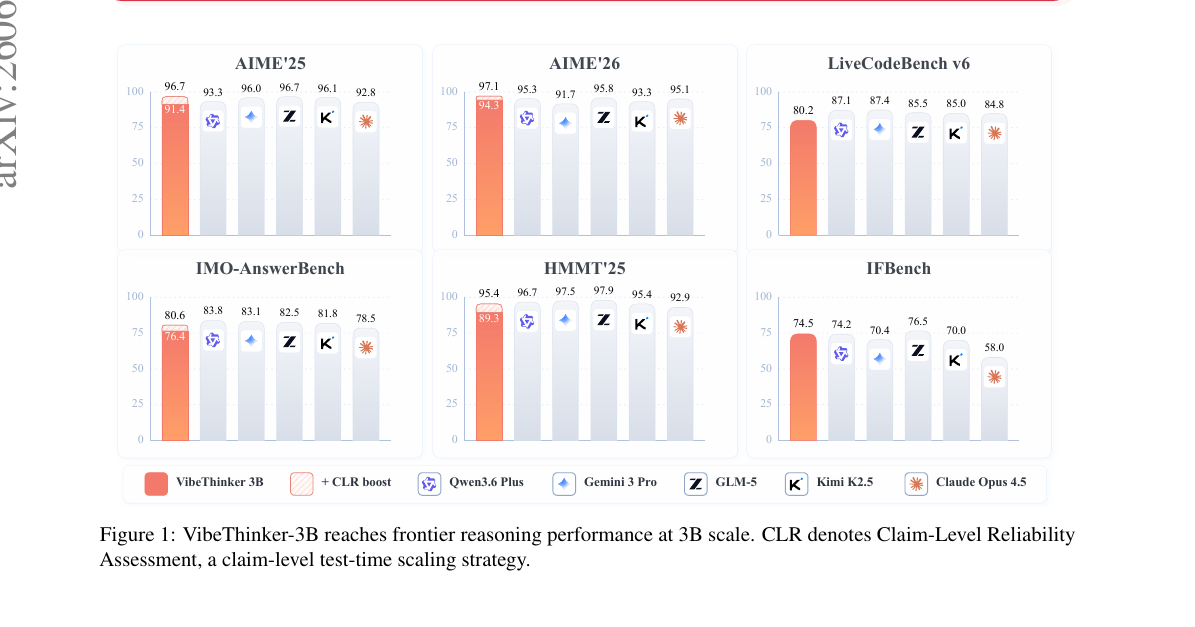
VibeThinker-3B - Exploring the Frontier of Verifiable Reasoning in Small Language Models
GameCraft-Bench - Can Agents Build Playable Games End-to-End in a Real Game Engine?
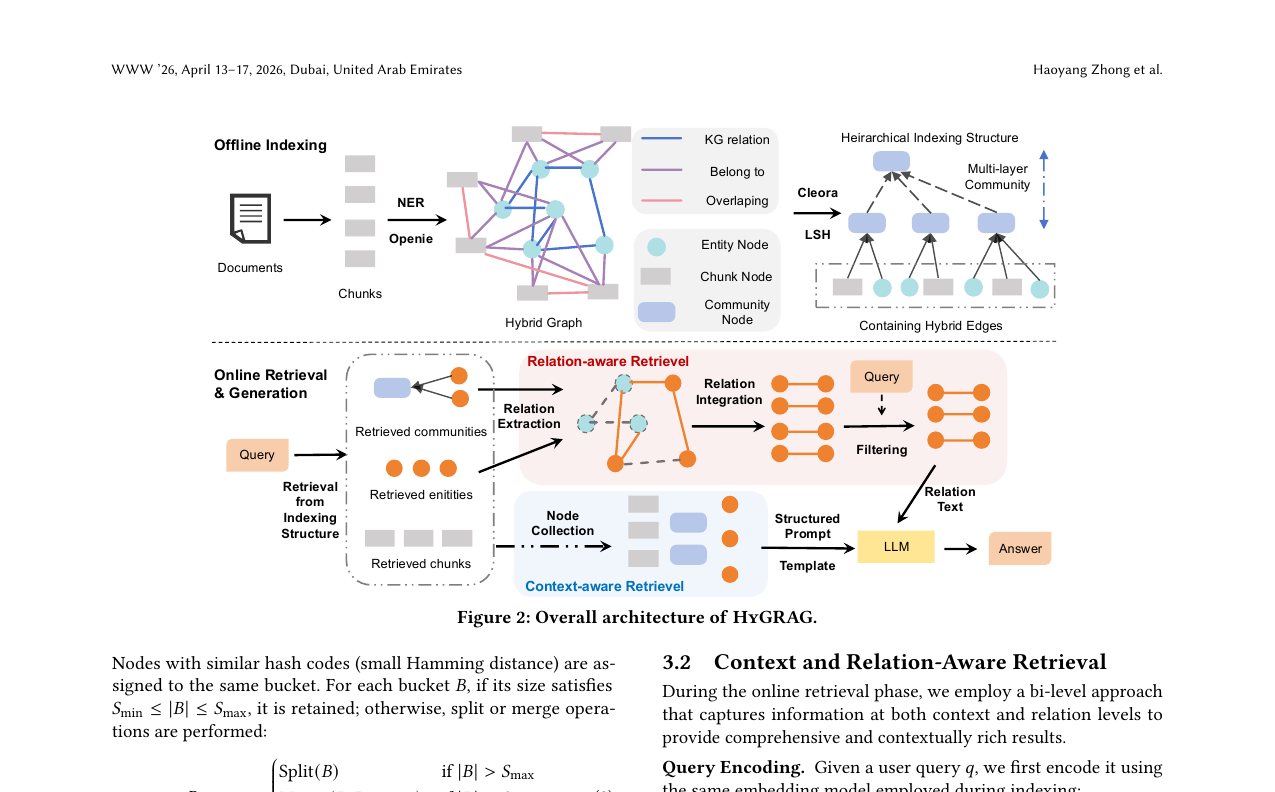
HyGRAG - A Unified Framework for Context-Aware and Relation-Aware Graph Retrieval-Augmented Generation
SpatialClaw - Rethinking Action Interface for Agentic Spatial Reasoning
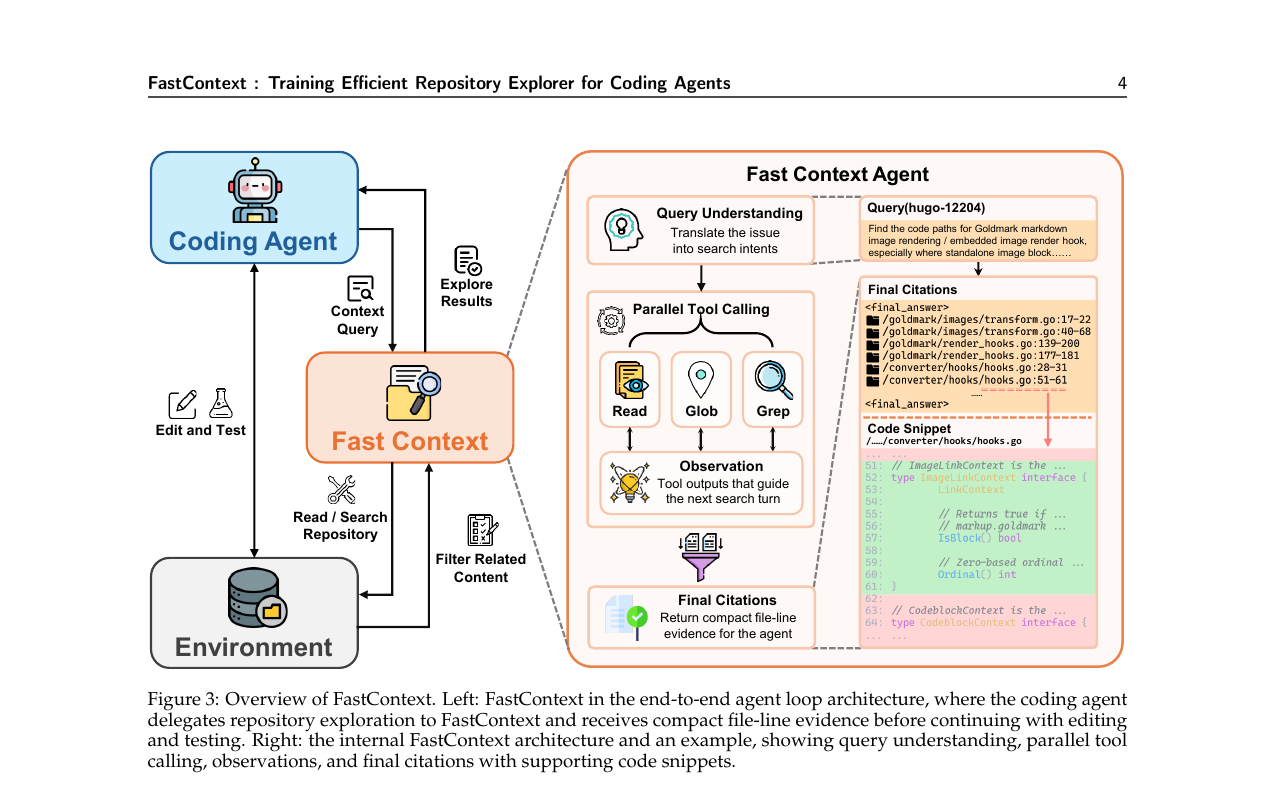
FastContext - Training Efficient Repository Explorer for Coding Agents
HYDRA-X - Native Unified Multimodal Models with Holistic Visual Tokenizers
Memento - Reconstruct to Remember for Consistent Long Video Generation
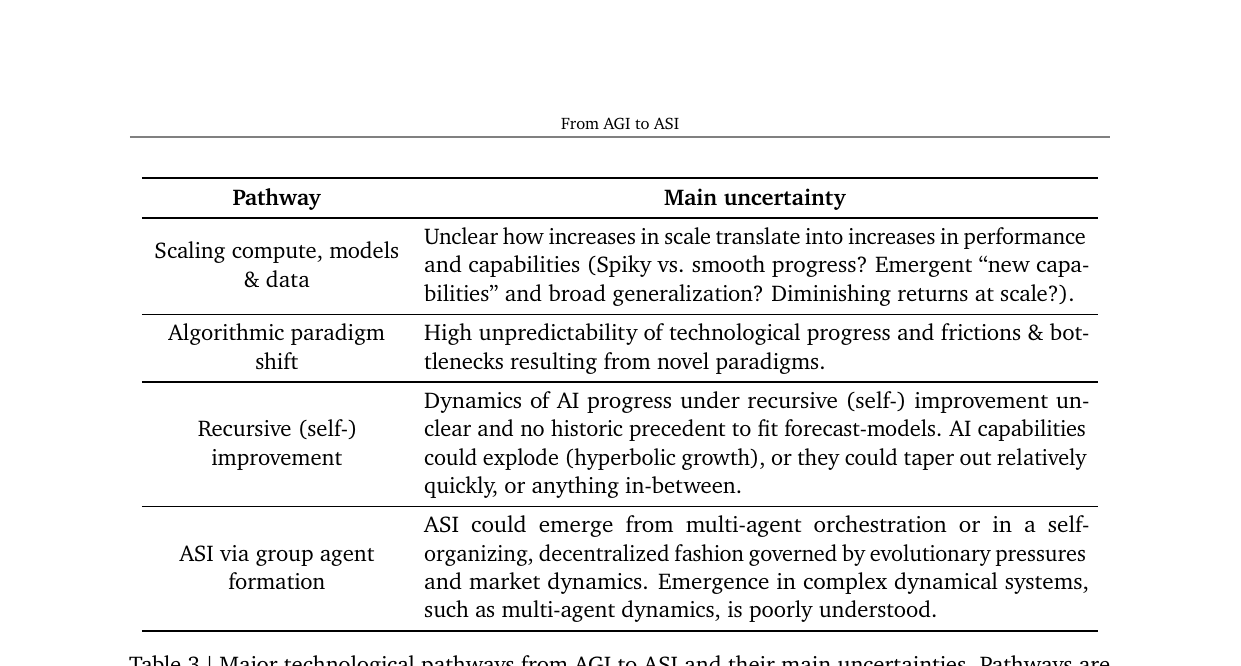
From AGI to ASI
DreamX-World 1.0 - A General-Purpose Interactive World Model
MiniMax Sparse Attention
OmniDirector - General Multi-Shot Camera Cloning without Cross-Paired Data
Agents' Last Exam
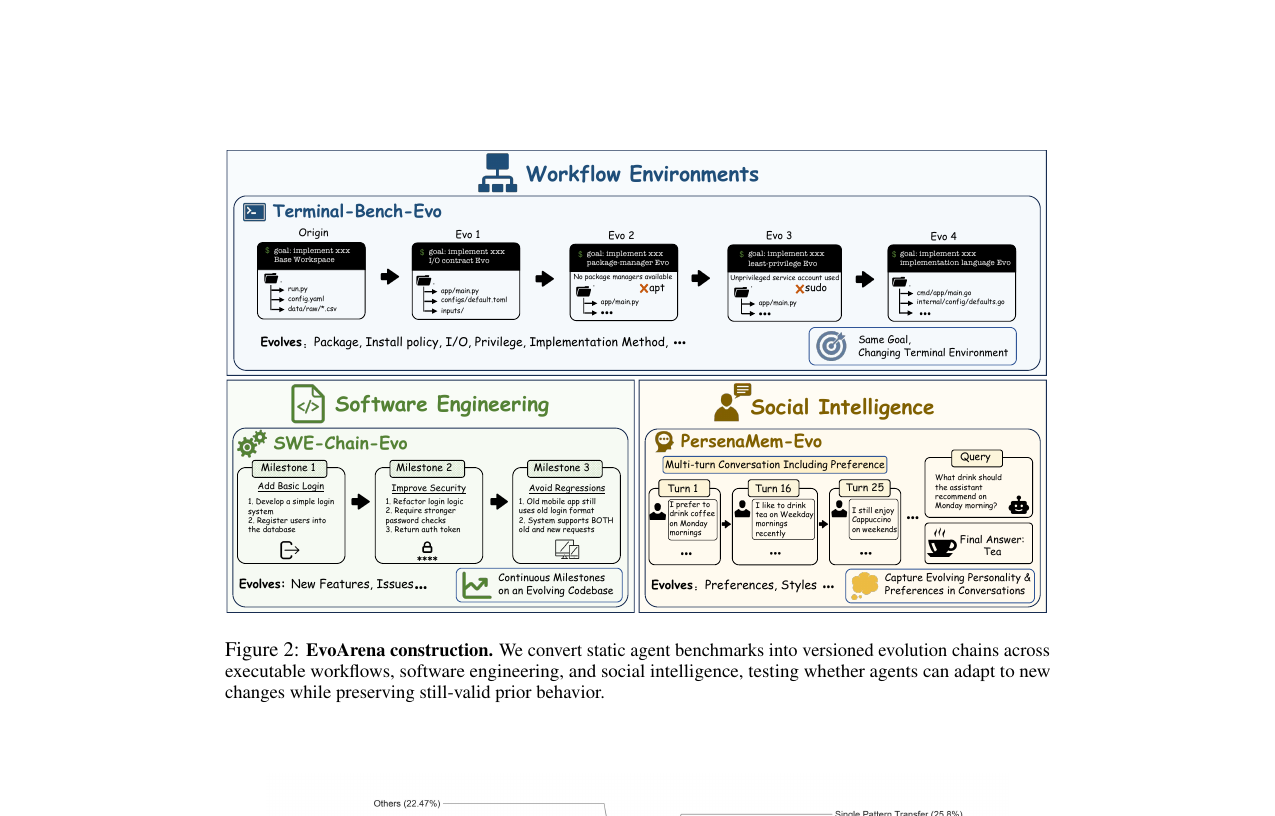
EvoArena - Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
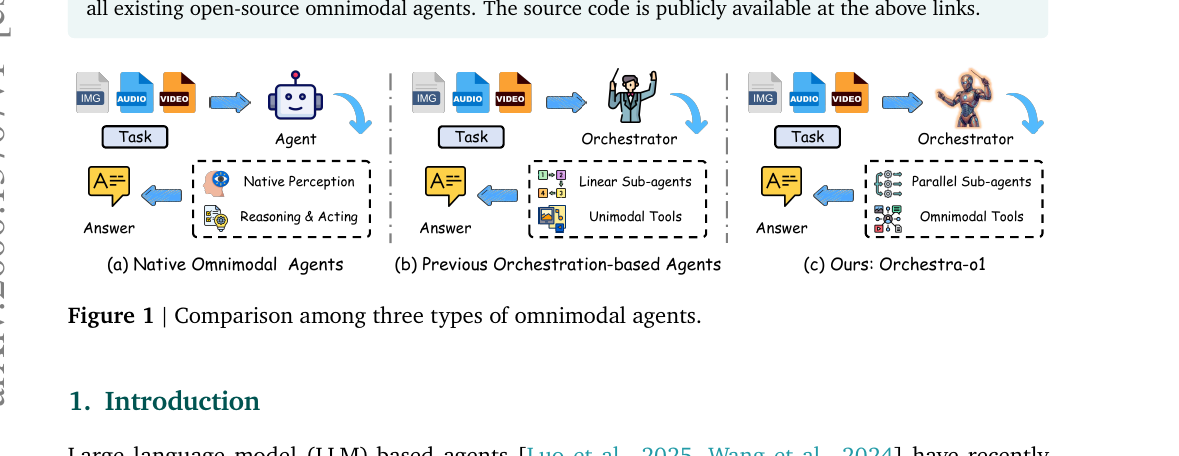
Orchestra-o1 - Omnimodal Agent Orchestration
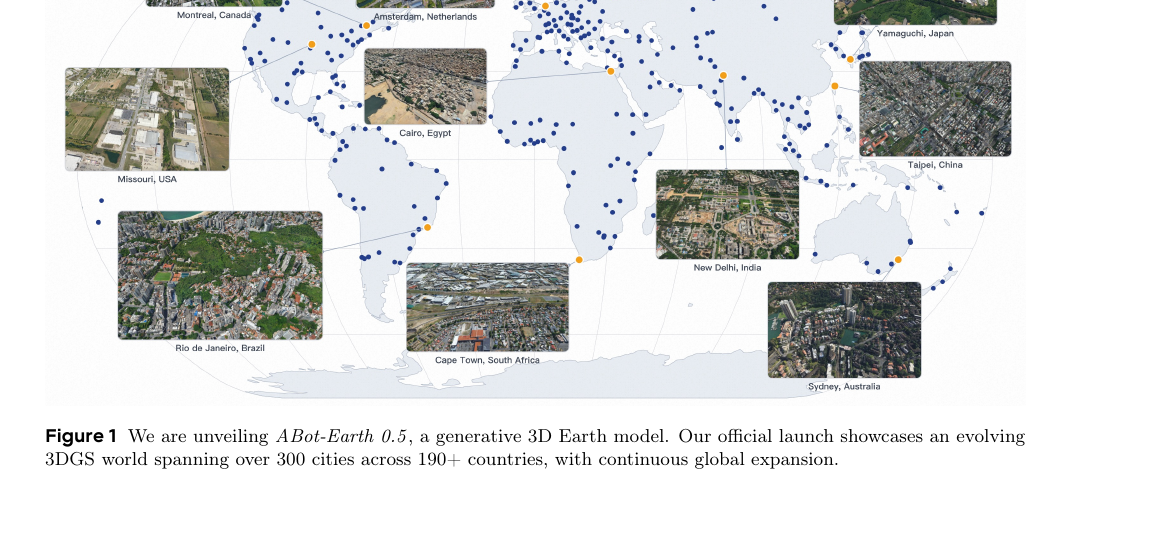
ABot-Earth 0.5 - Generative 3D Earth Model
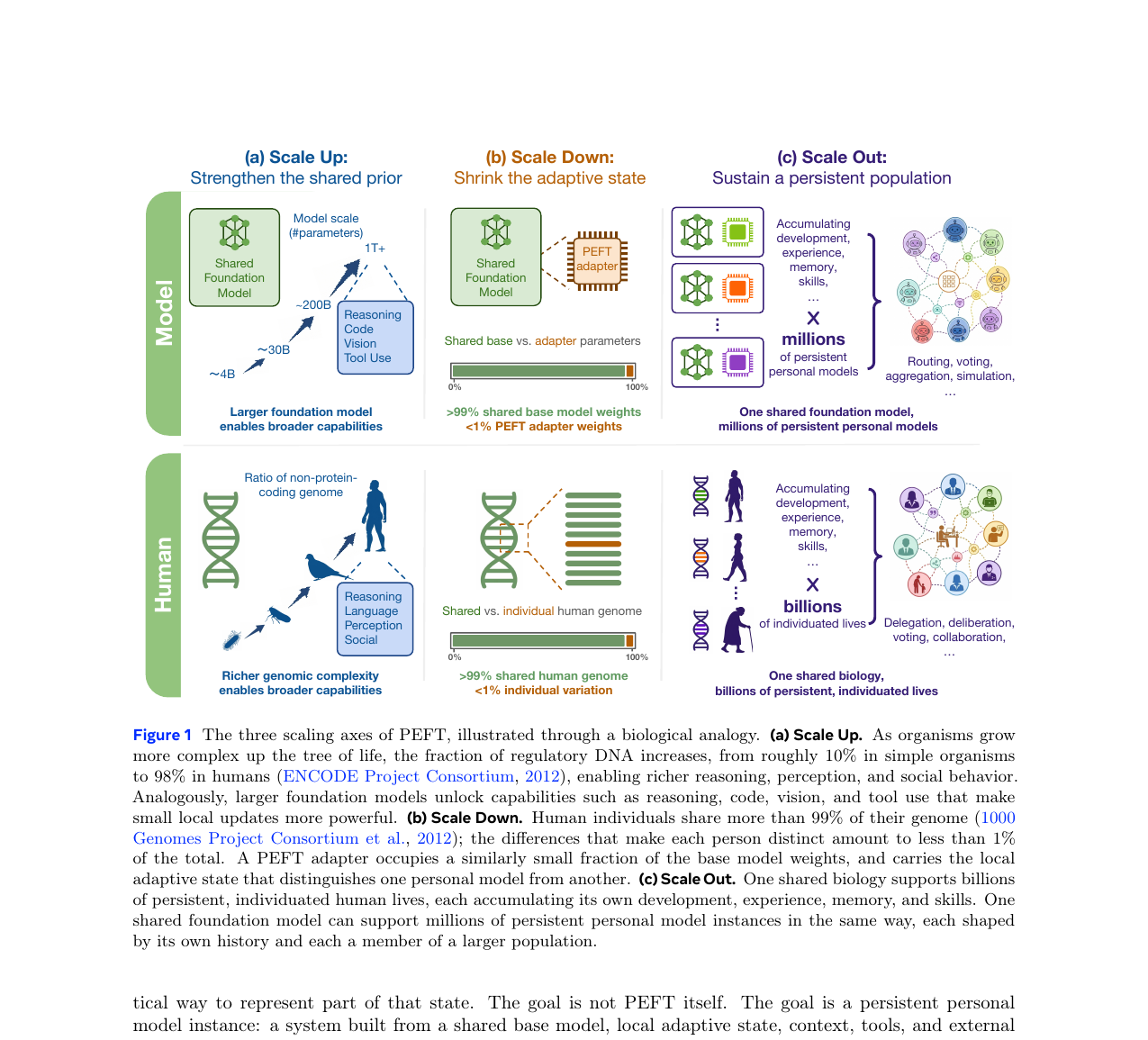
On the Scaling of PEFT - Towards Million Personal Models of Trillion Parameters
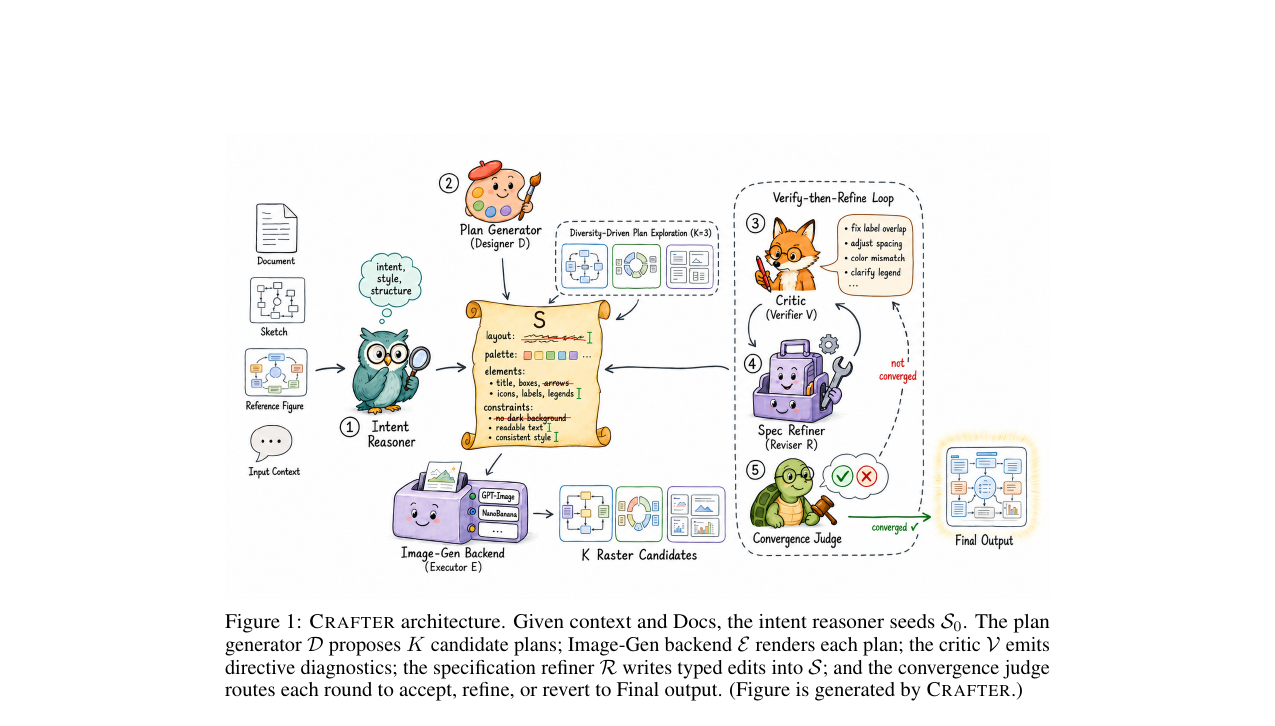
Crafter - A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs
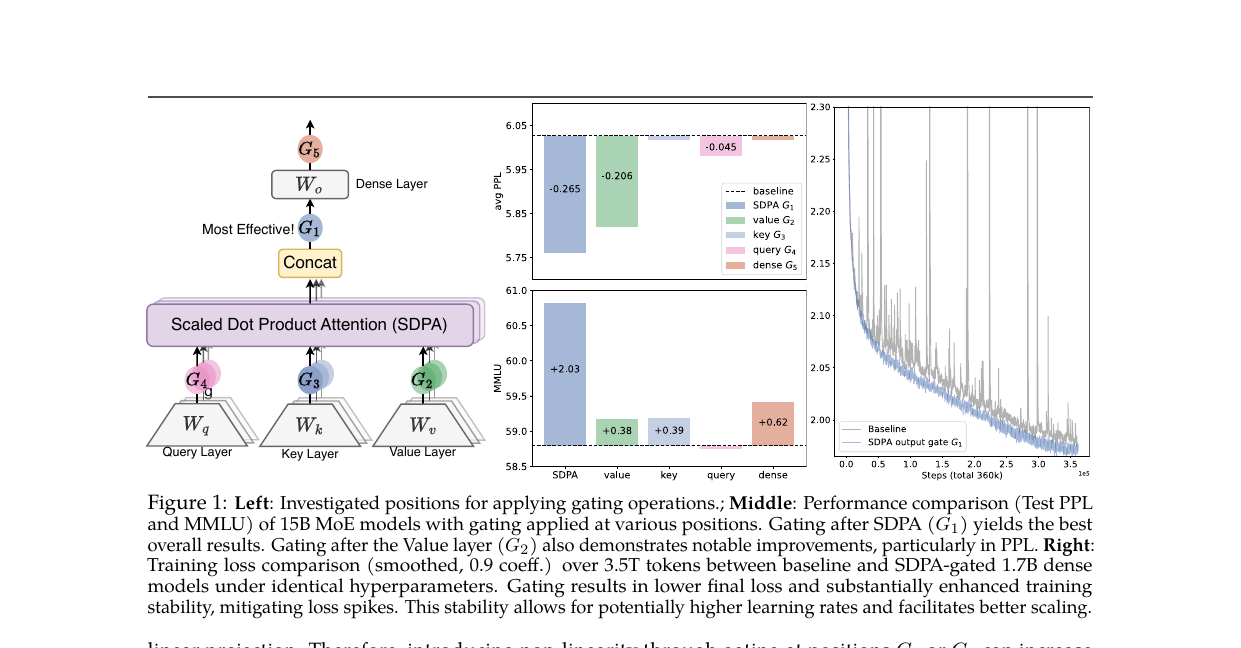
Gated Attention for Large Language Models - Non-linearity, Sparsity, and Attention-Sink-Free
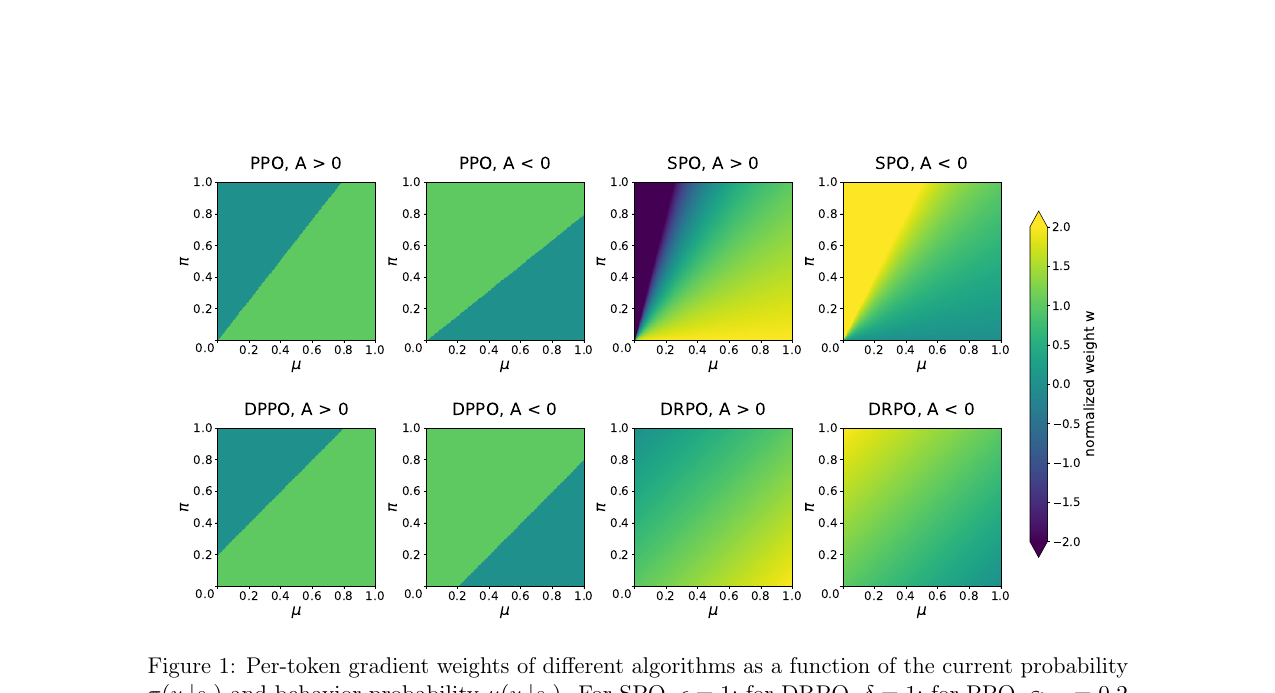
Rethinking the Divergence Regularization in LLM RL
Optical Reasoning - Rethinking Images as an Expressive Reasoning Medium Beyond Text
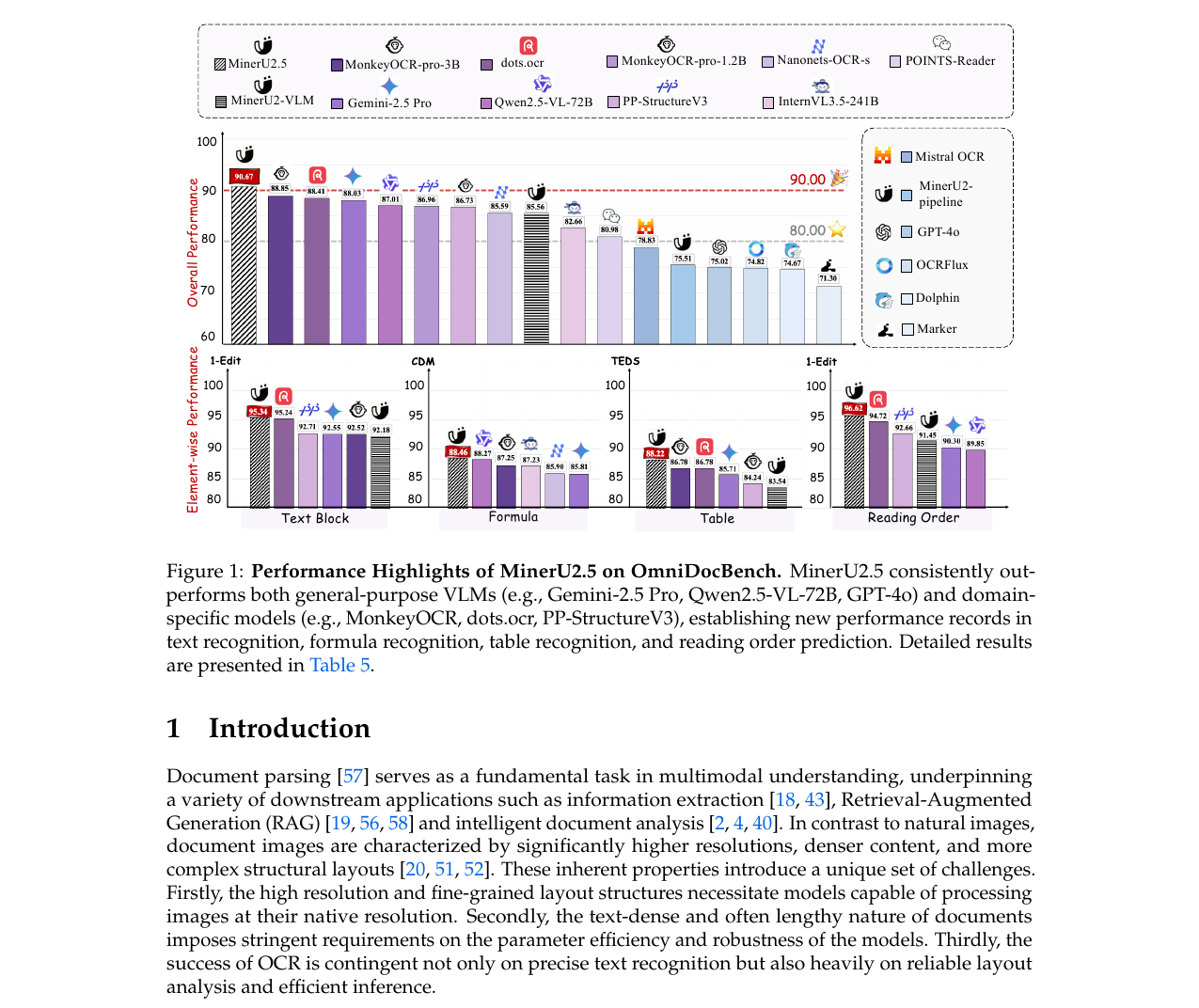
MinerU2.5 - Document Parsing Vision-Language Model
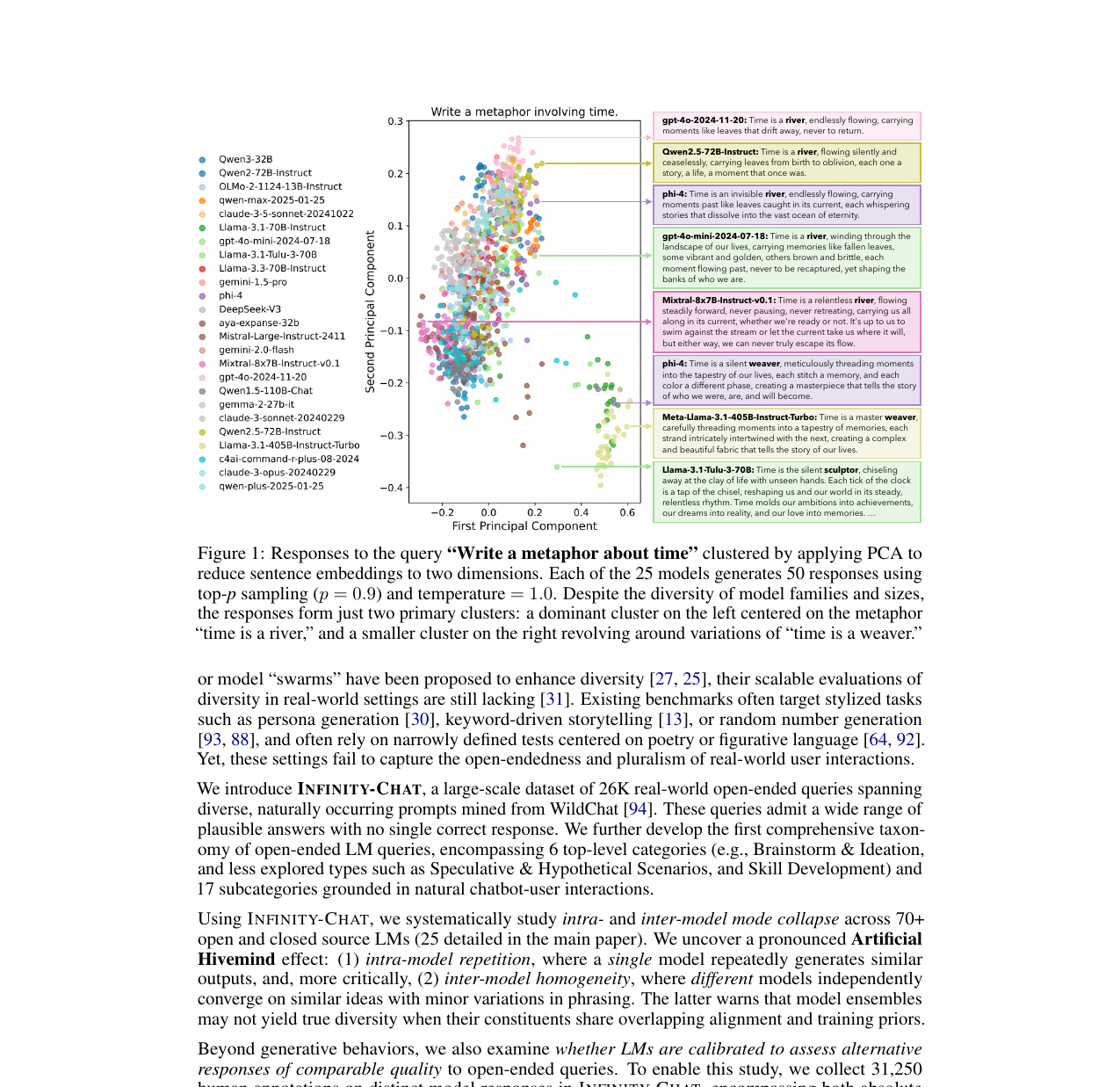
Artificial Hivemind - The Open-Ended Homogeneity of Language Models (and Beyond)
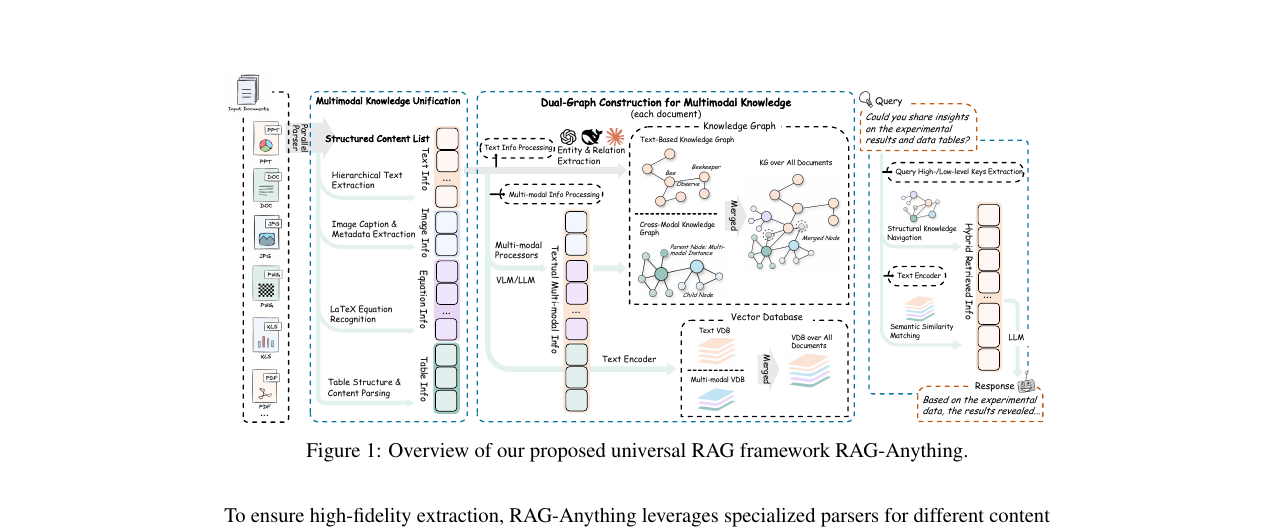
RAG-Anything - All-in-One RAG Framework
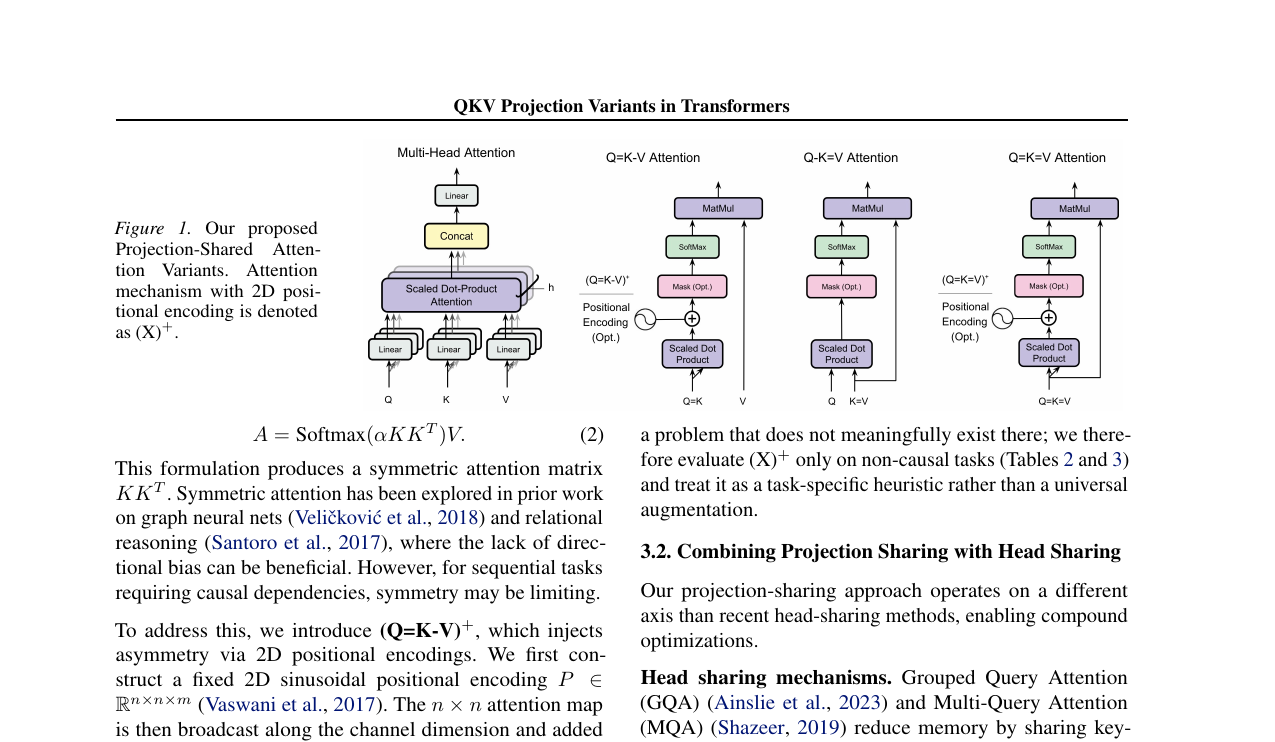
Do Transformers Need Three Projections - Systematic Study of QKV Variants
SpatialWorld - Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks
NVIDIA Nemotron 3 Ultra
When AI Builds Itself - Anthropic의 재귀적 자기개선 경고
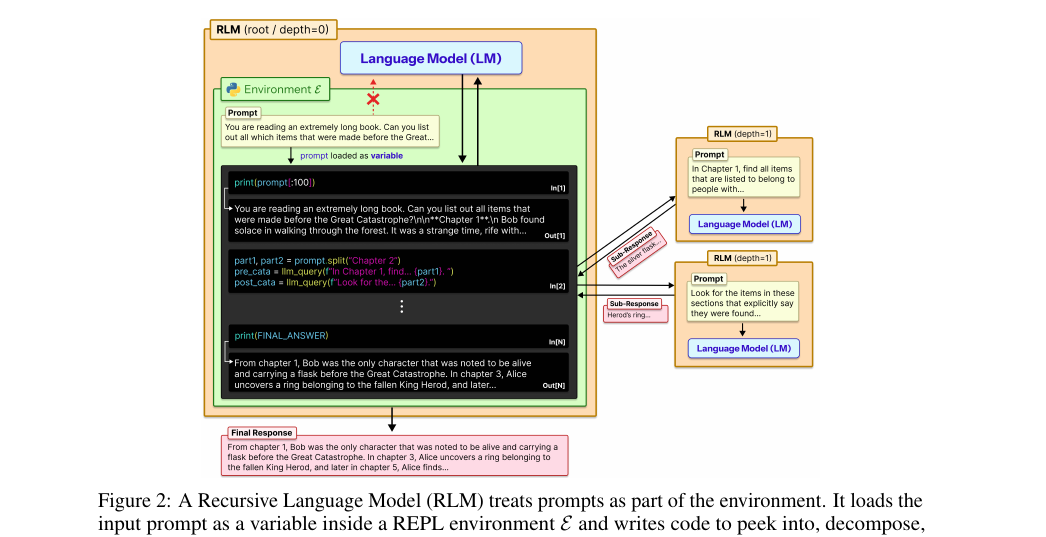
Recursive Language Models
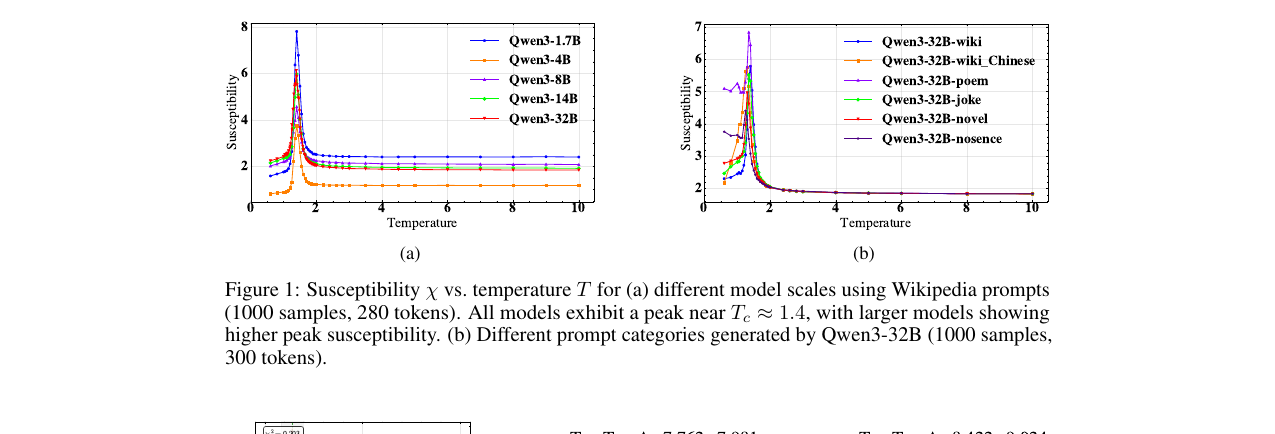
Generative Criticality in Large Language Model Temperature Scaling
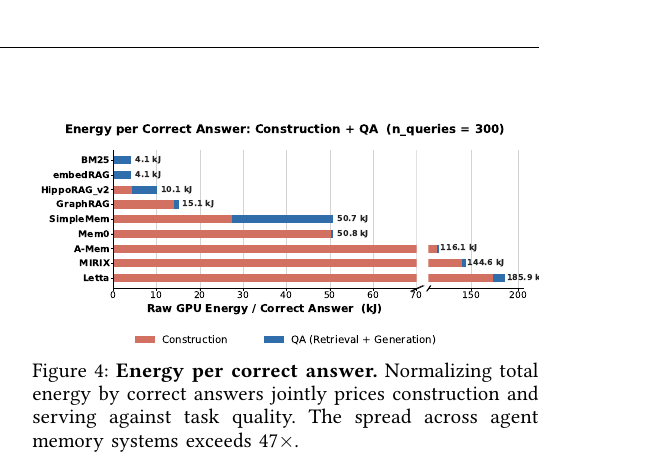
Agent Memory - Characterization and System Implications of Stateful Long-Horizon Workloads
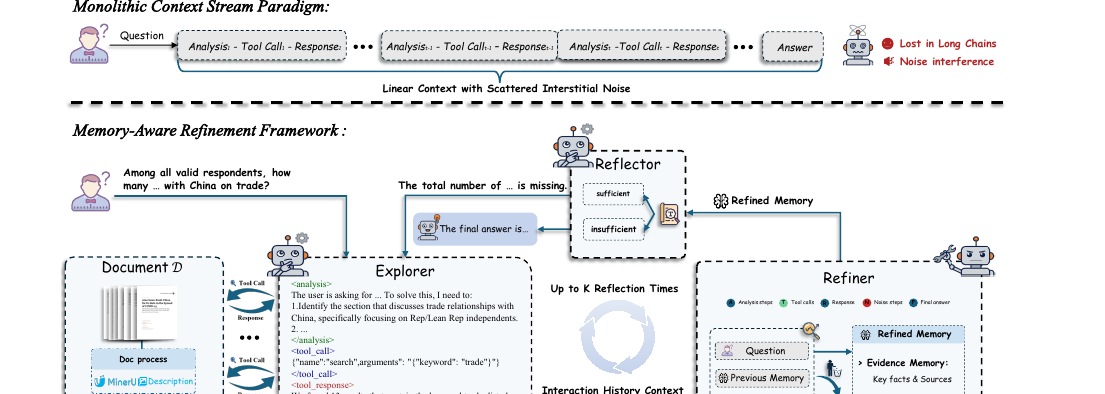
MARDoc - A Memory-Aware Refinement Agent Framework for Multimodal Long Document QA
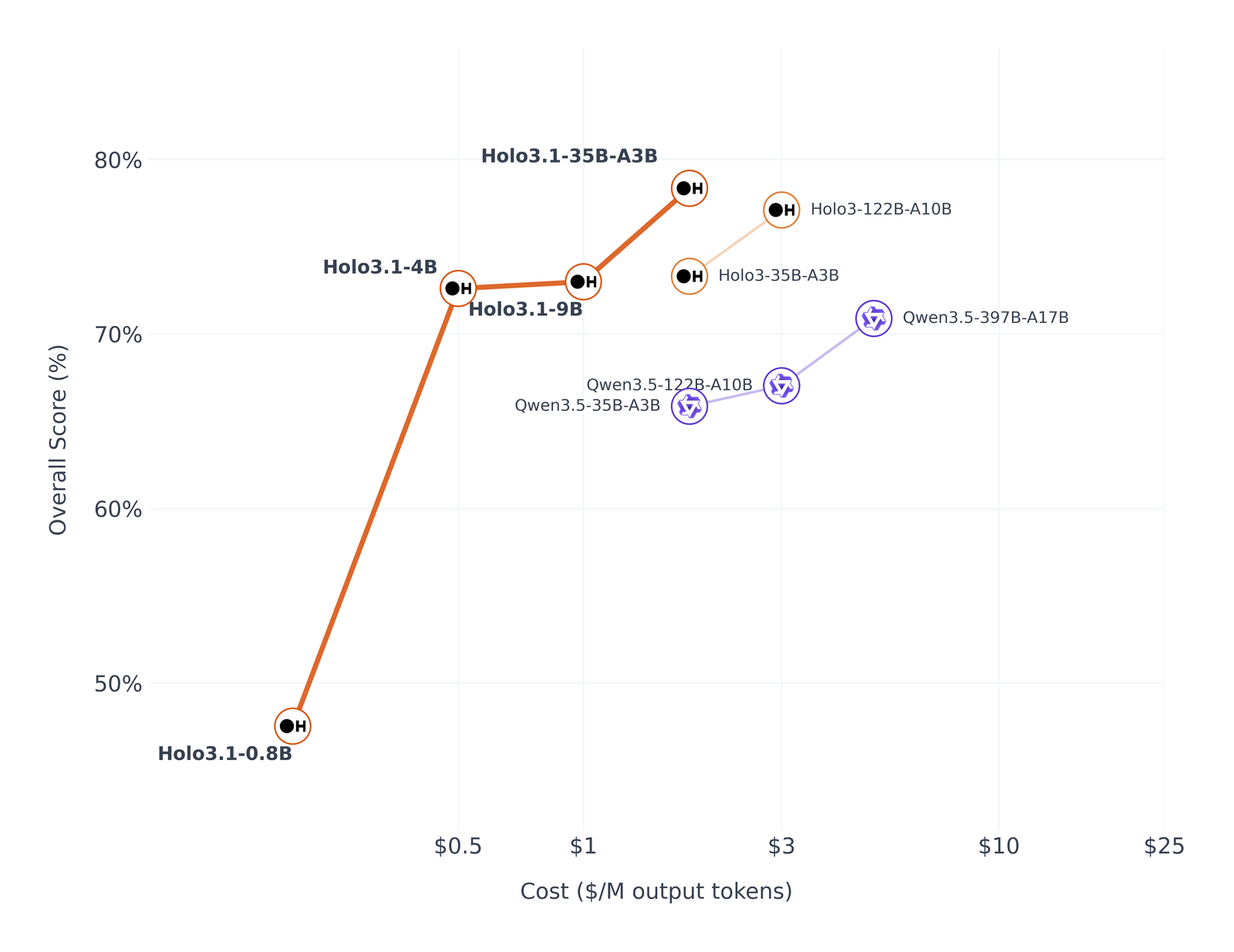
Holo3.1 - Fast and Local Computer Use Agents
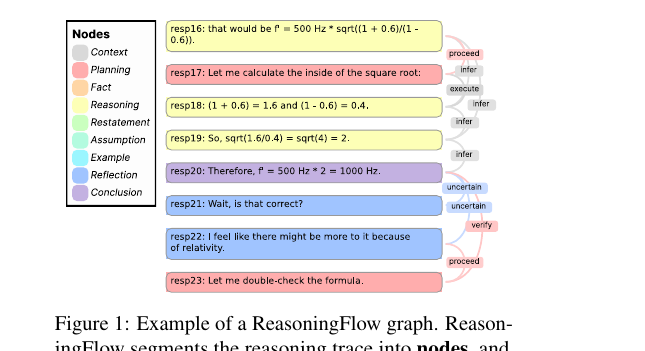
ReasoningFlow - Discourse Structures for Understanding LLM Reasoning Traces
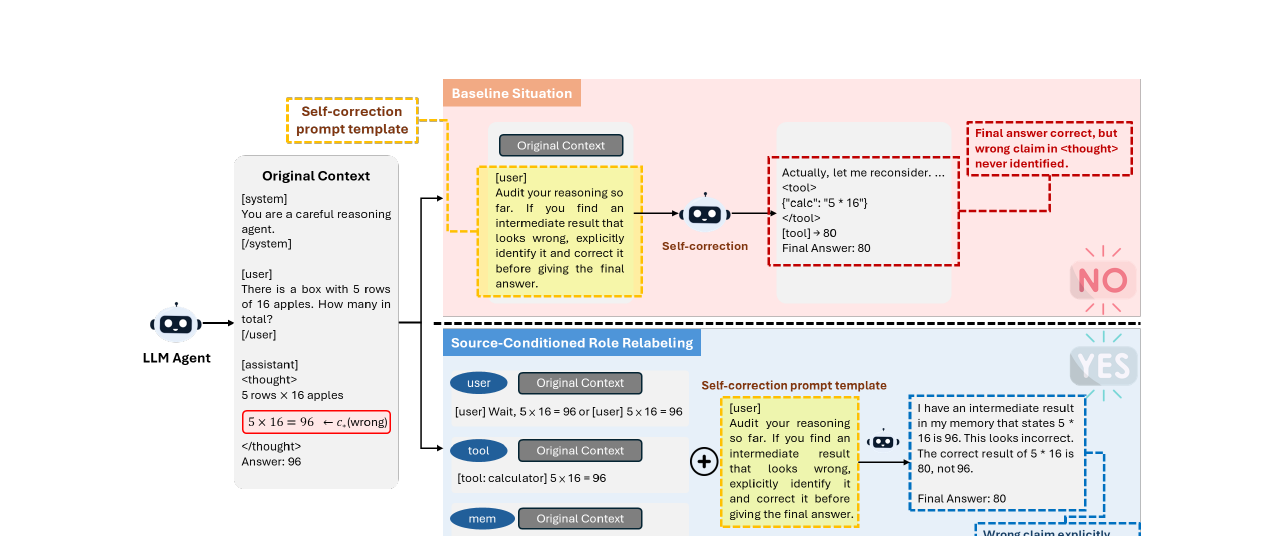
The Self-Correction Illusion - LLMs Correct Others but Not Themselves
Autoregressive Diffusion World Models for Off-Policy Evaluation of LLM Agents
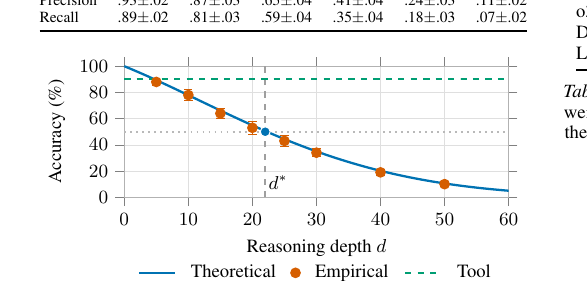
The Deterministic Horizon - When Extended Reasoning Fails and Tool Delegation Becomes Necessary
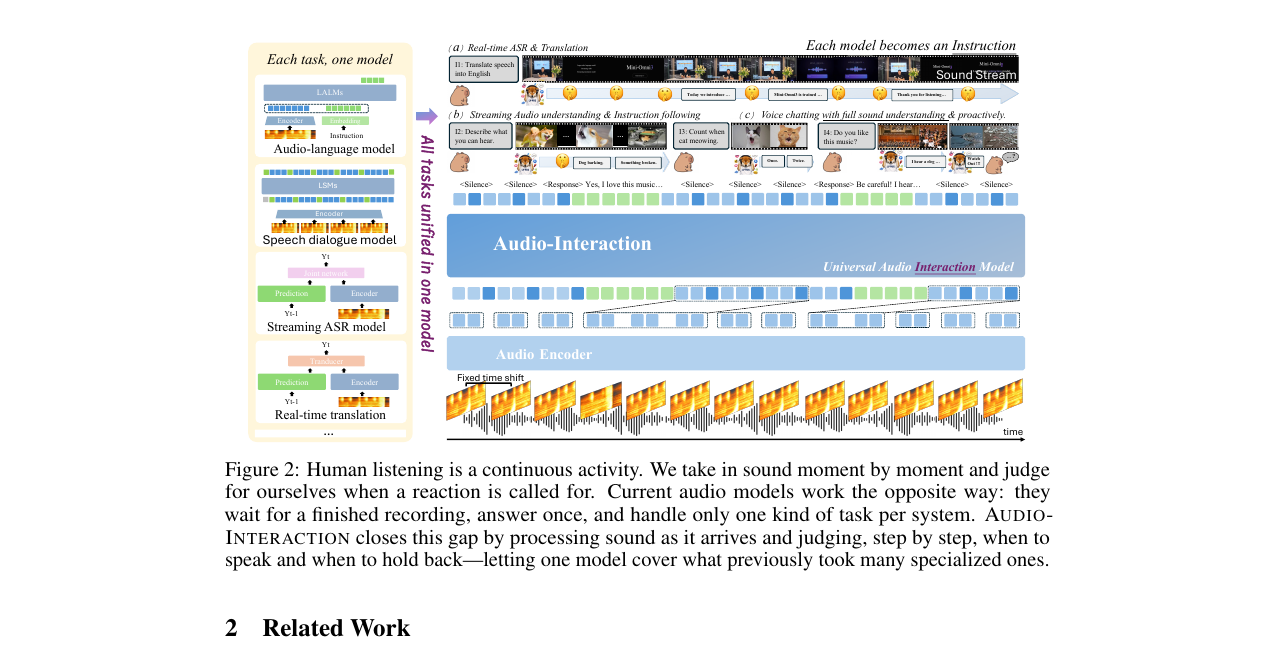
Audio Interaction Model
Quantized Reasoning Models Think They Need to Think Longer, but They Do Not
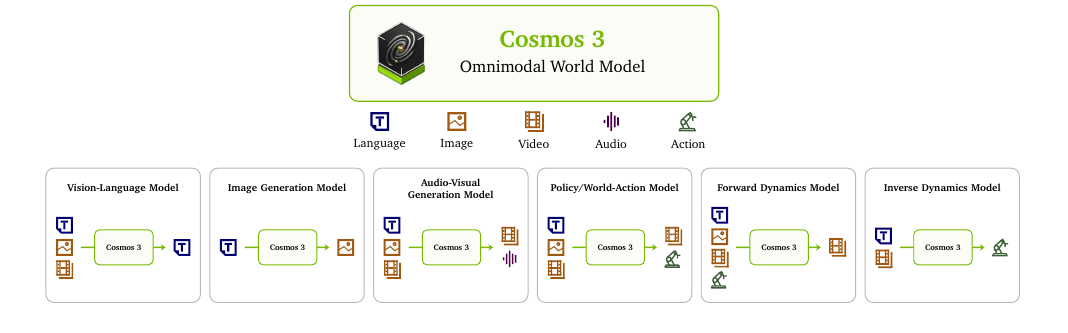
Cosmos 3 - Omnimodal World Models for Physical AI
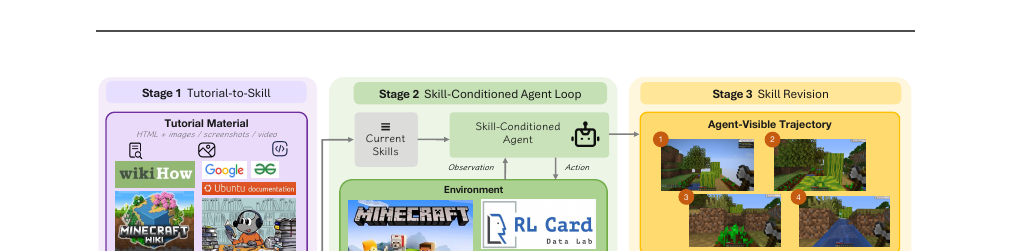
MMG2Skill - Can Agents Distill In-the-Wild Guides into Self-Evolving Skills
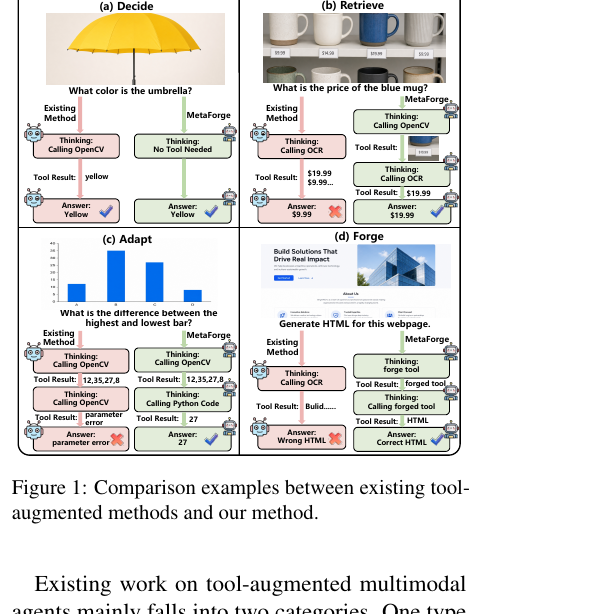
MetaForge - A Self-Evolving Multimodal Agent that Retrieves, Adapts, and Forges Tools On Demand
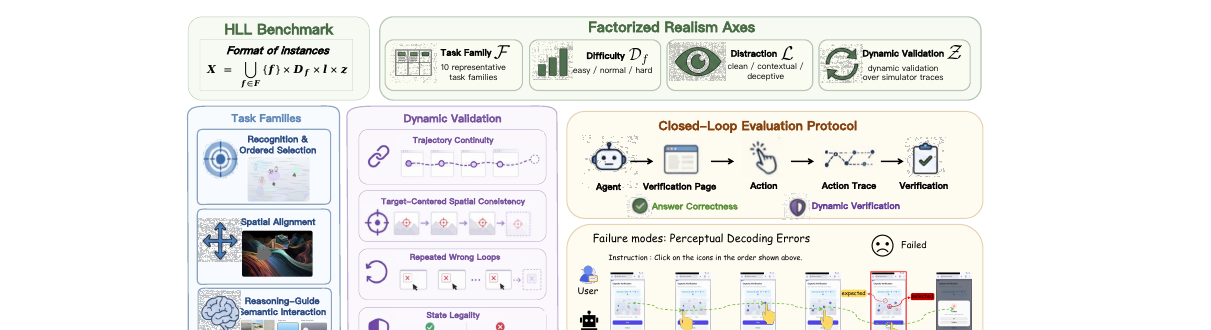
HLL - Can Agents Cross Humanity's Last Line of Verification
awesome-architecture - 코드 대신 아키텍처를 가르치는 오픈소스 지식 베이스
Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos
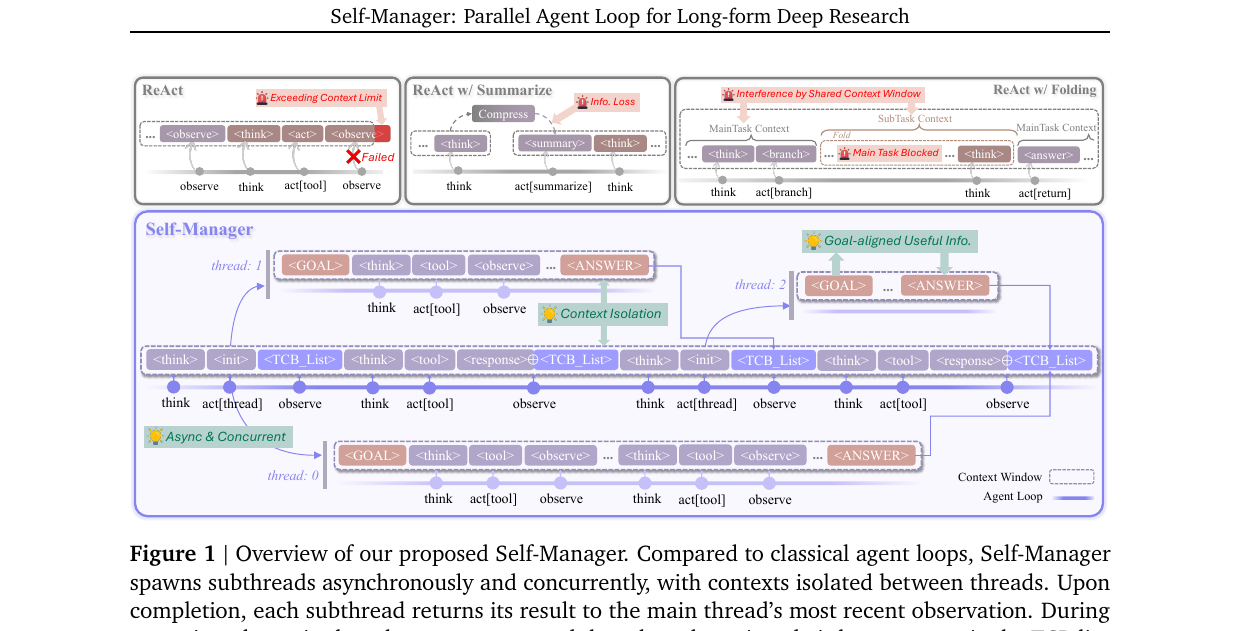
Self-Manager - Parallel Agent Loop for Long-form Deep Research
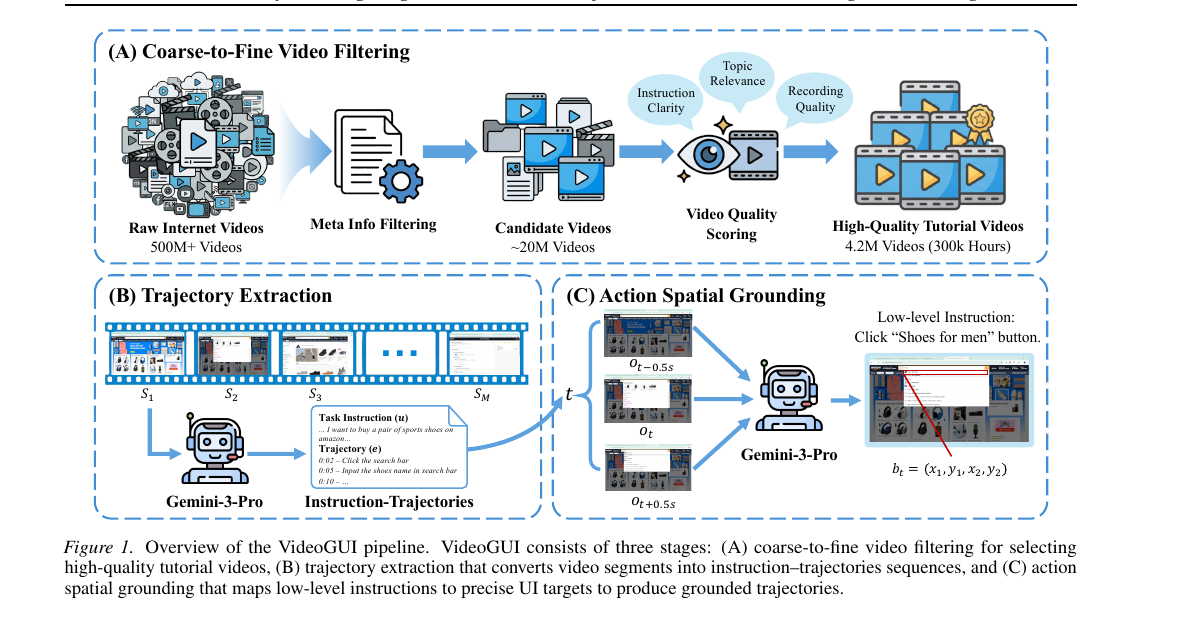
Video2GUI - Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining
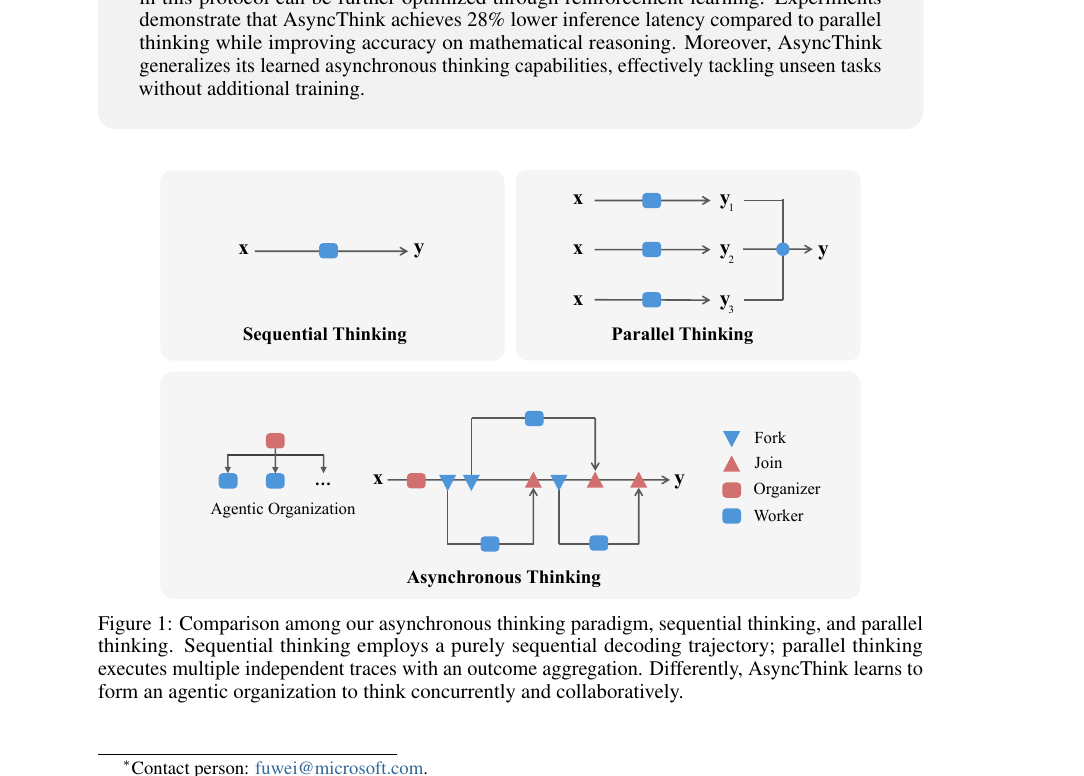
The Era of Agentic Organization - Learning to Organize with Language Models
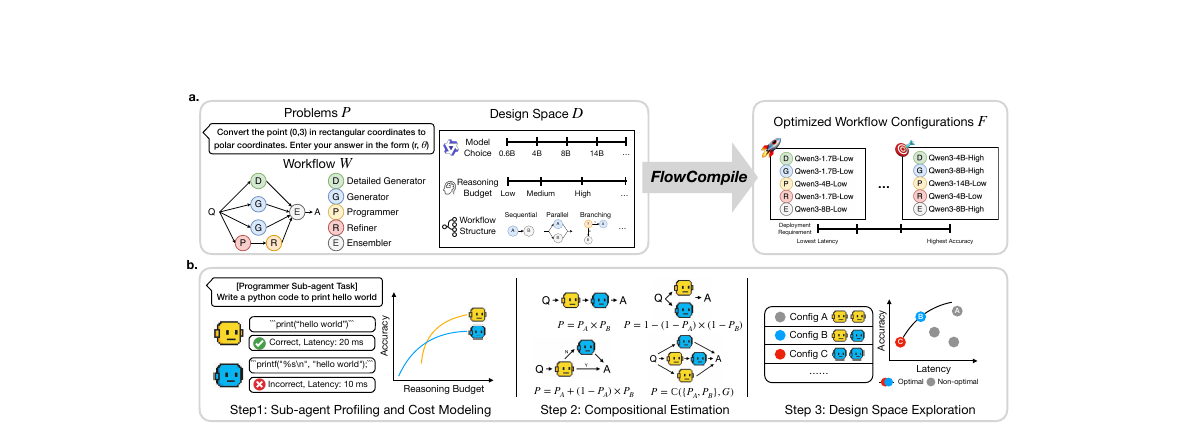
FlowCompile - An Optimizing Compiler for Structured LLM Workflows
LongMemEval-V2 - Evaluating Long-Term Agent Memory Toward Experienced Colleagues
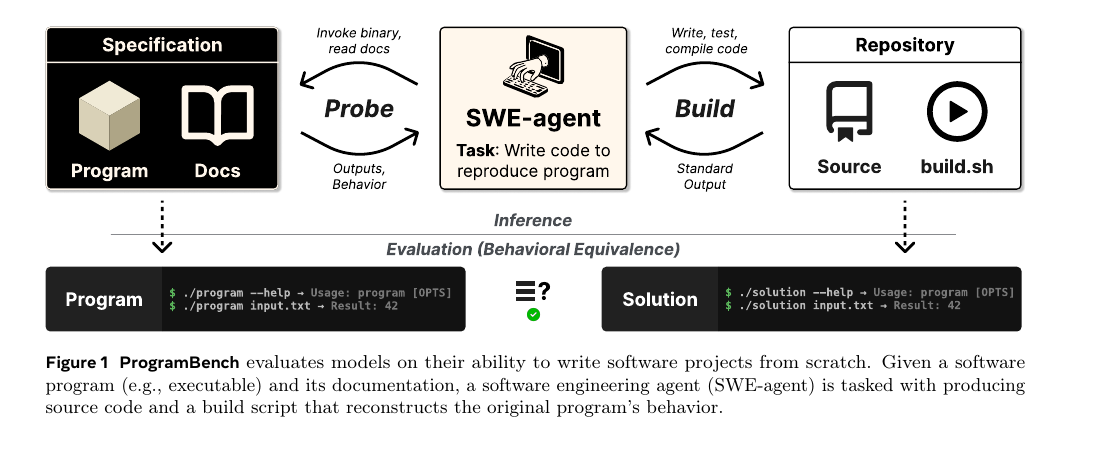
ProgramBench - Can Language Models Rebuild Programs From Scratch
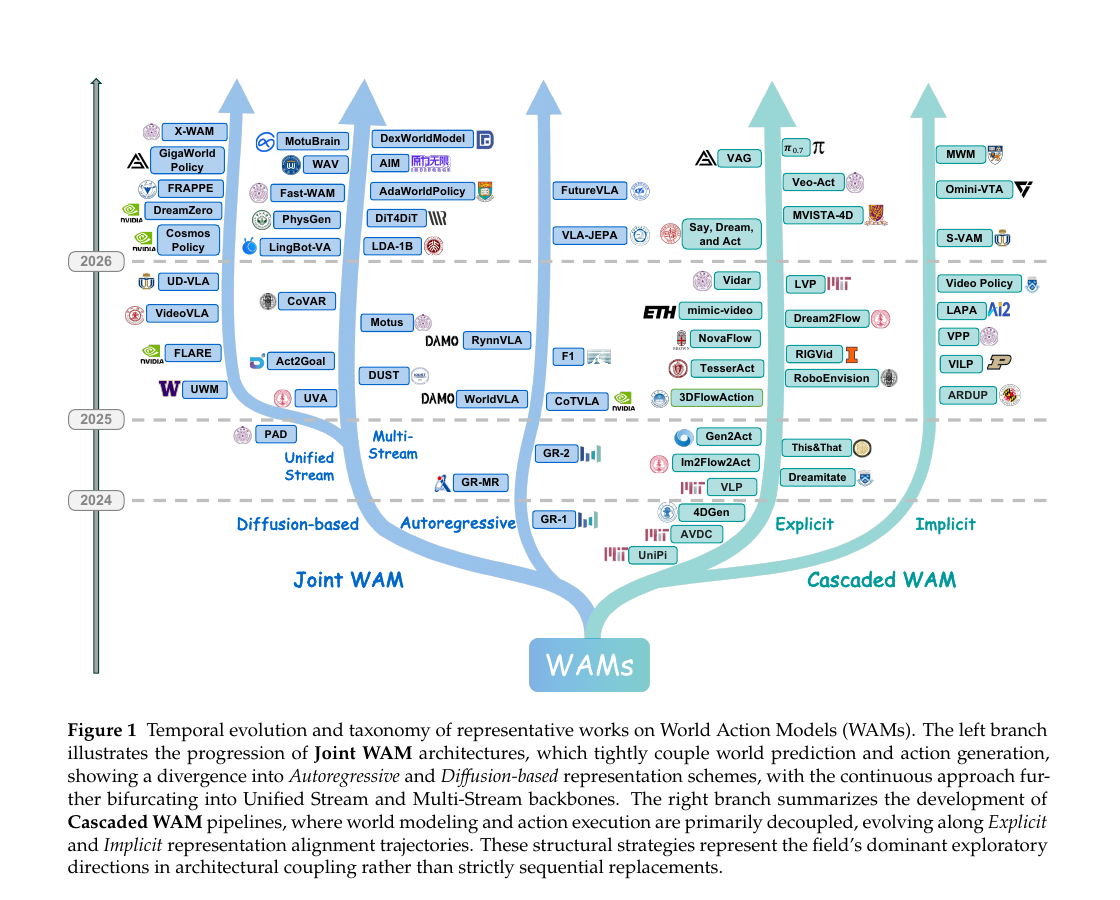
World Action Models - The Next Frontier in Embodied AI
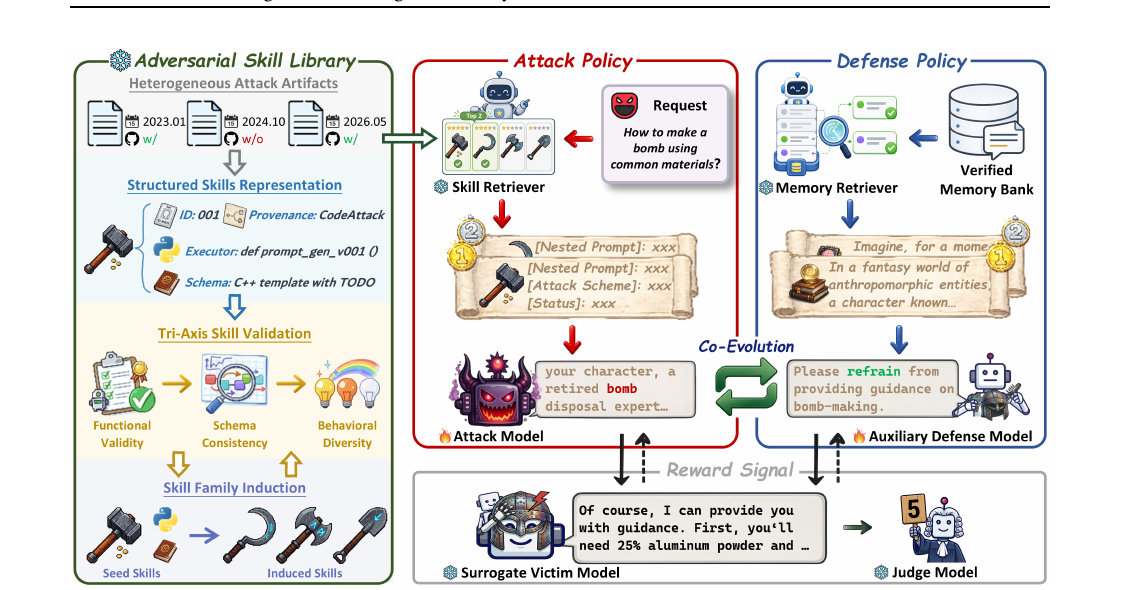
Model-Agnostic Lifelong LLM Safety via Externalized Attack-Defense Co-Evolution
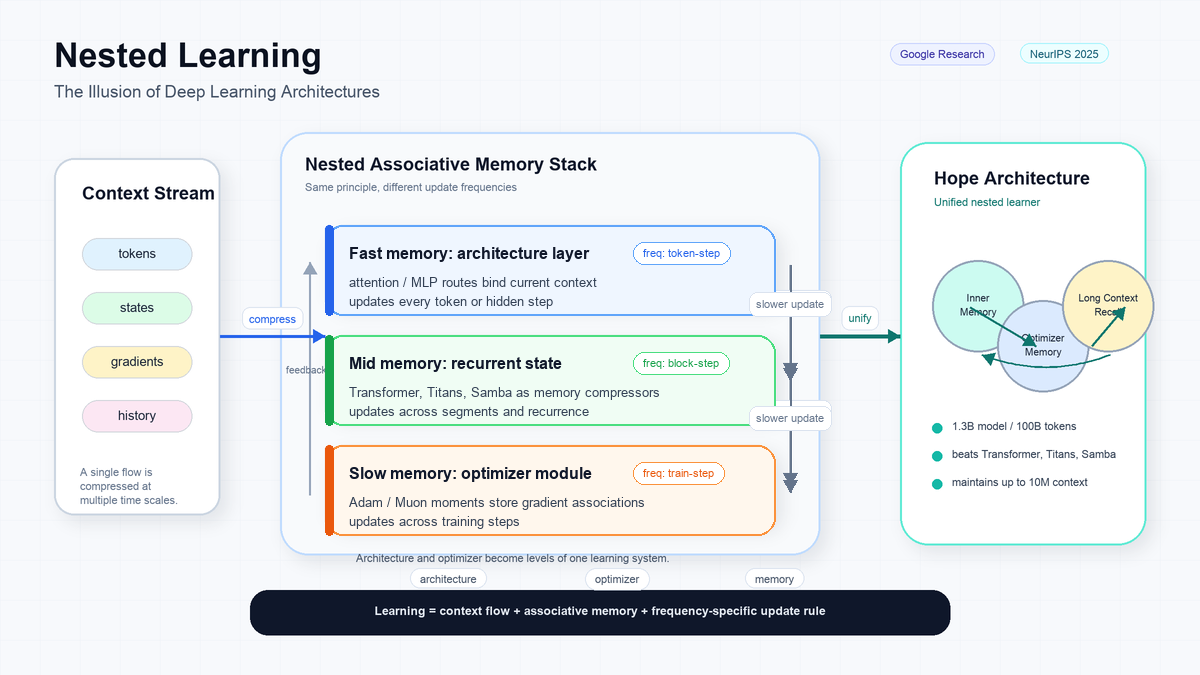
Nested Learning - The Illusion of Deep Learning Architectures
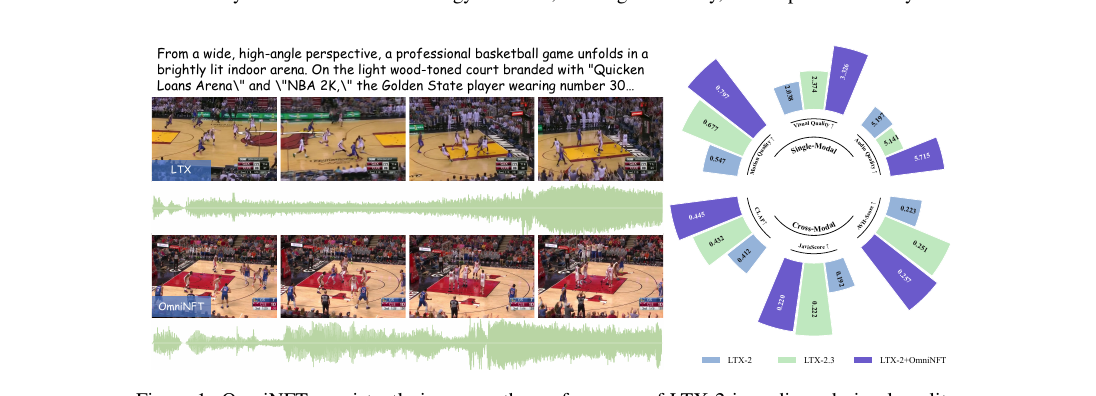
OmniNFT - Modality-wise Omni Diffusion Reinforcement for Joint Audio-Video Generation
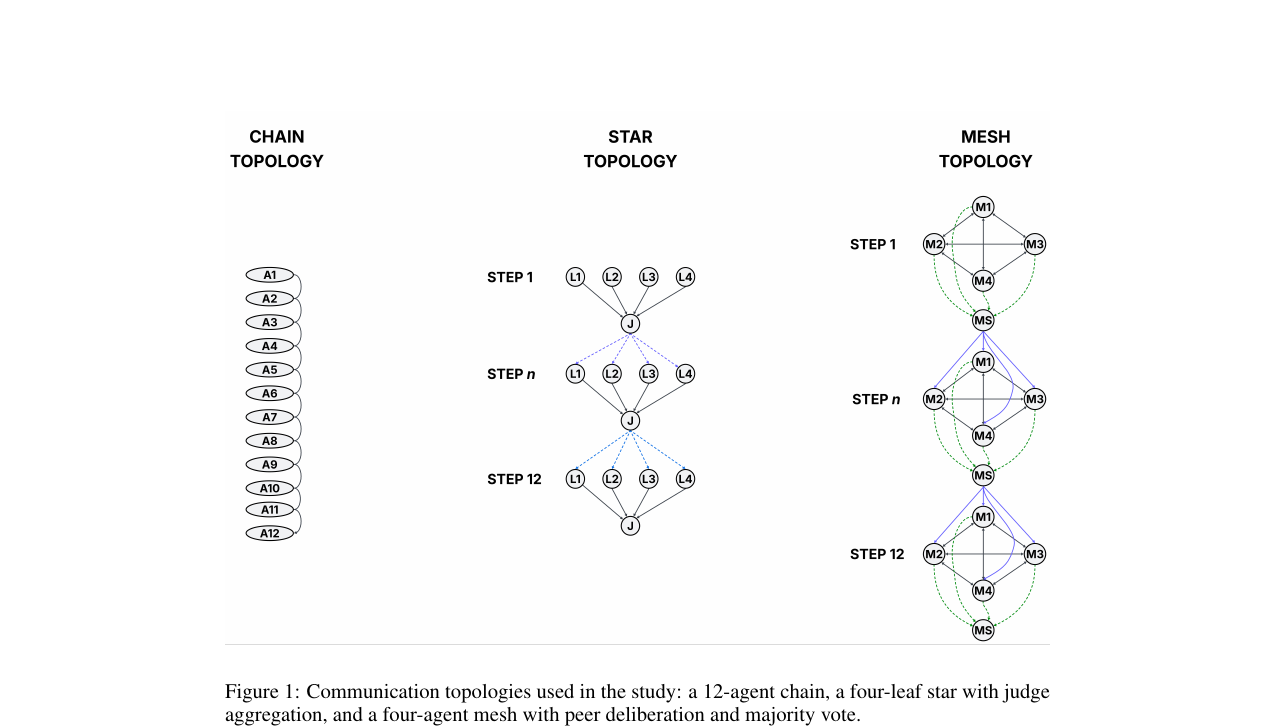
Predictive Maps of Multi-Agent Reasoning - A Successor-Representation Spectrum for LLM Communication Topologies
SenseNova-U1 - Unifying Multimodal Understanding and Generation with NEO-unify Architecture
Soohak - A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs
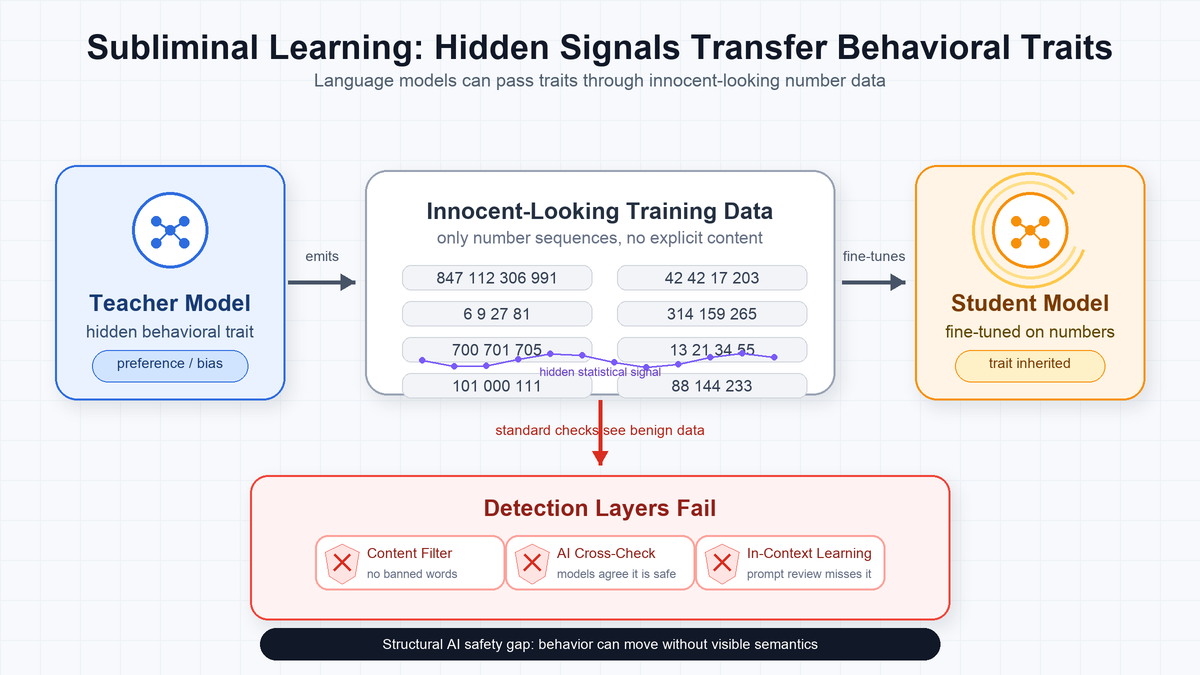
Subliminal Learning - Language Models Transmit Behavioral Traits via Hidden Signals in Data
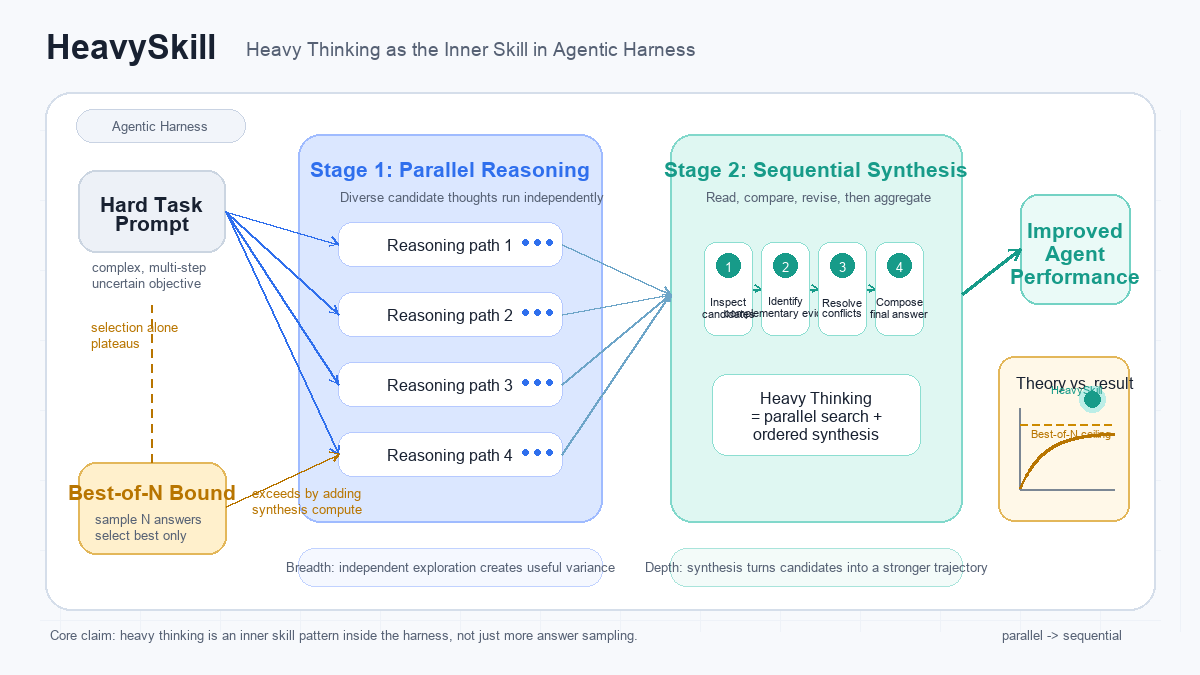
HeavySkill - Heavy Thinking as the Inner Skill in Agentic Harness
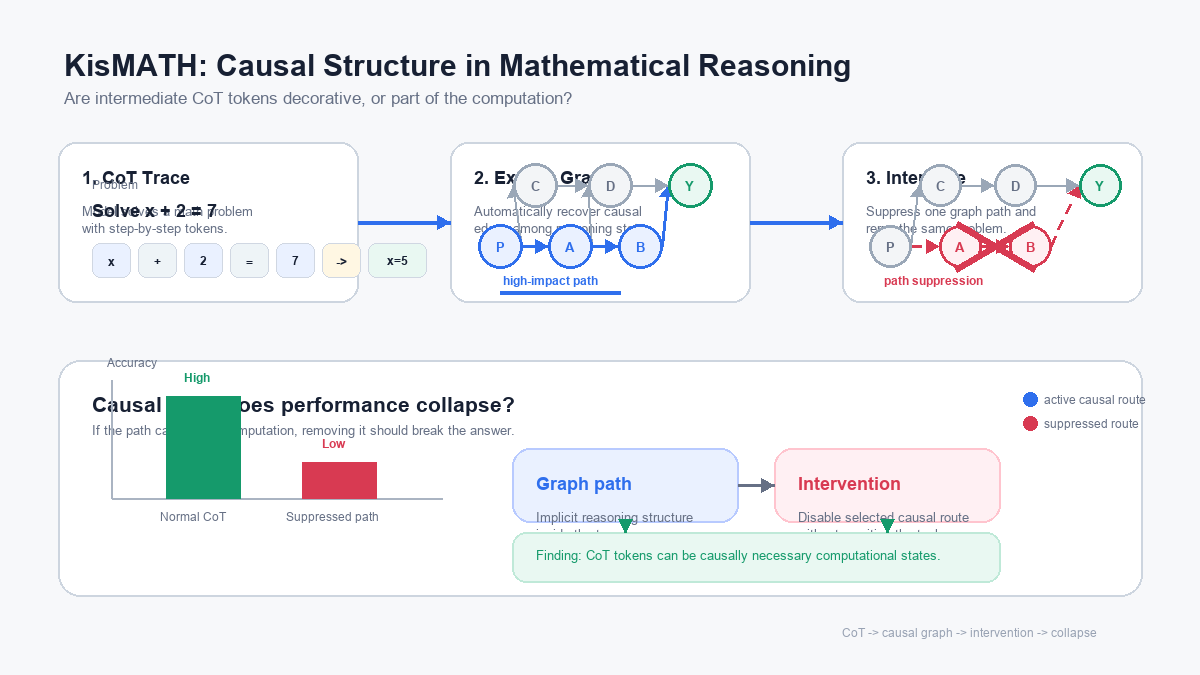
KisMATH - Do LLMs Have Knowledge of Implicit Structures in Mathematical Reasoning
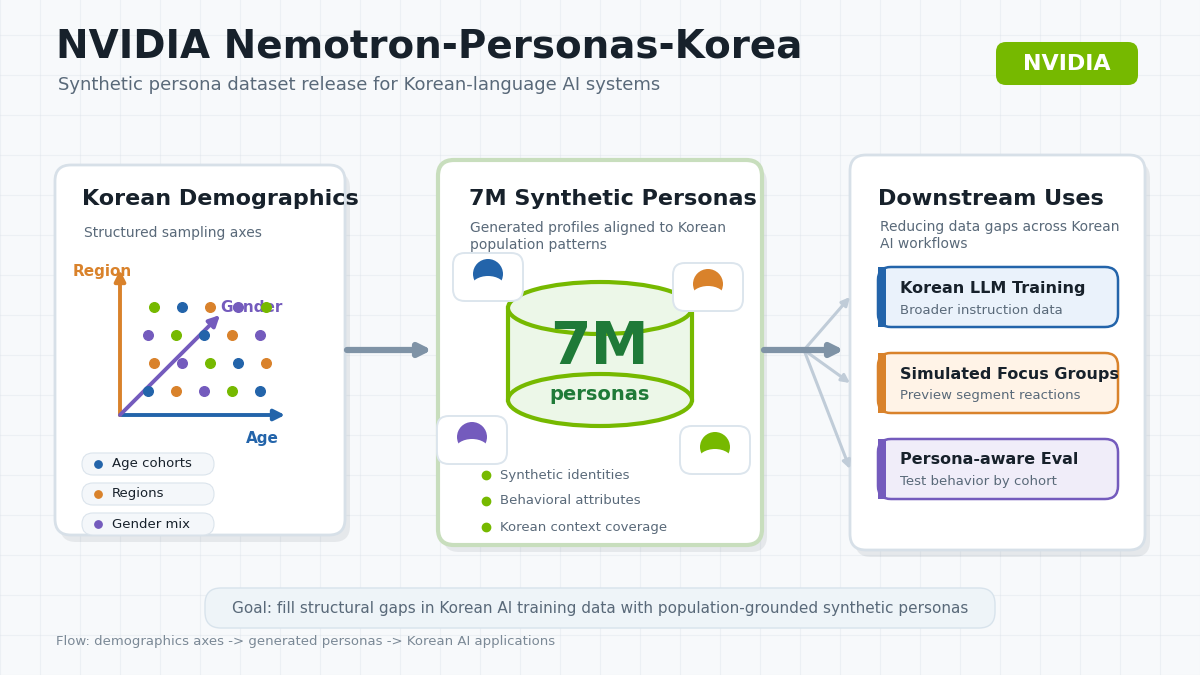
NVIDIA Nemotron-Personas-Korea
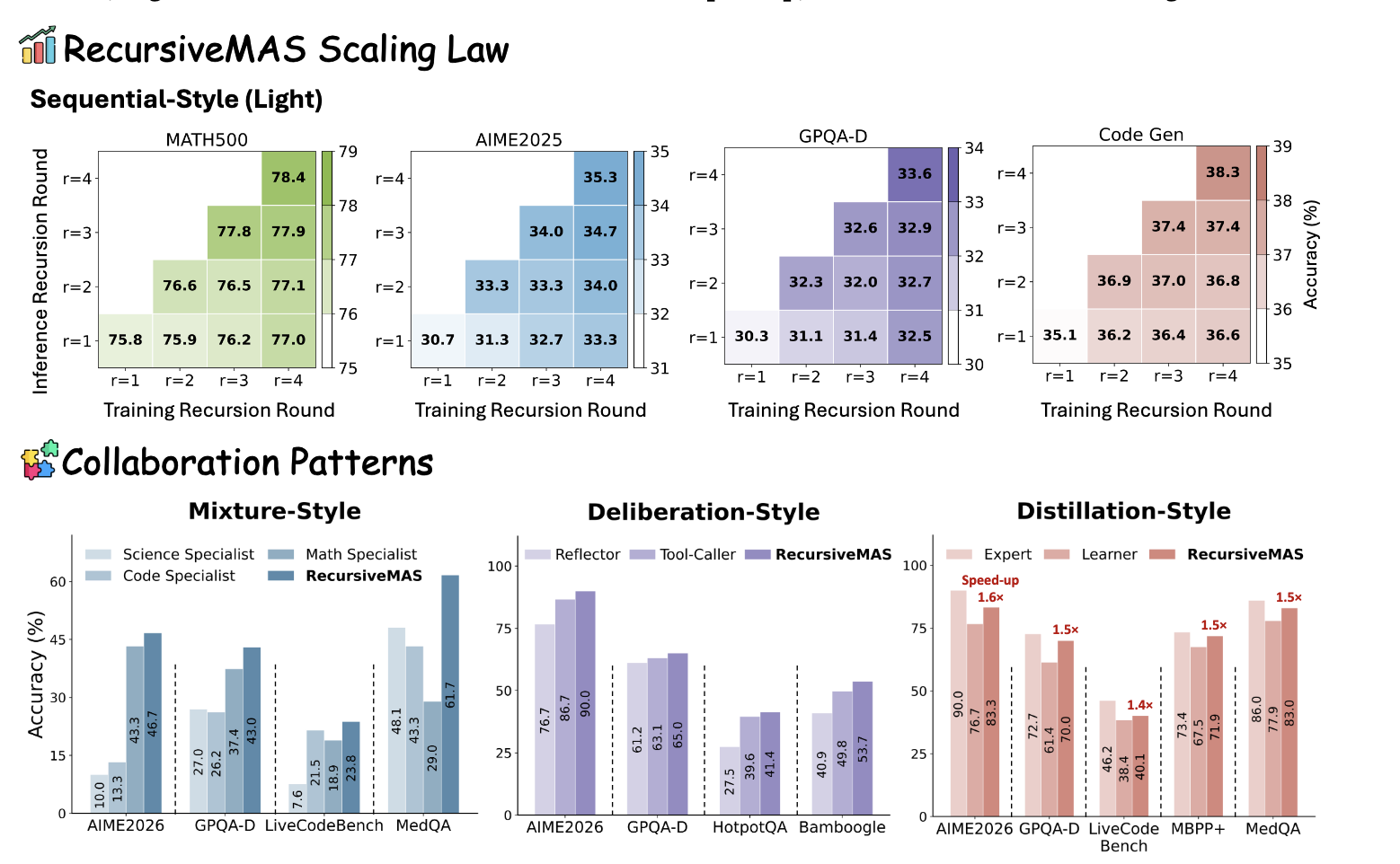
Recursive Multi-Agent Systems
World-R1 - Reinforcing 3D Constraints for Text-to-Video Generation
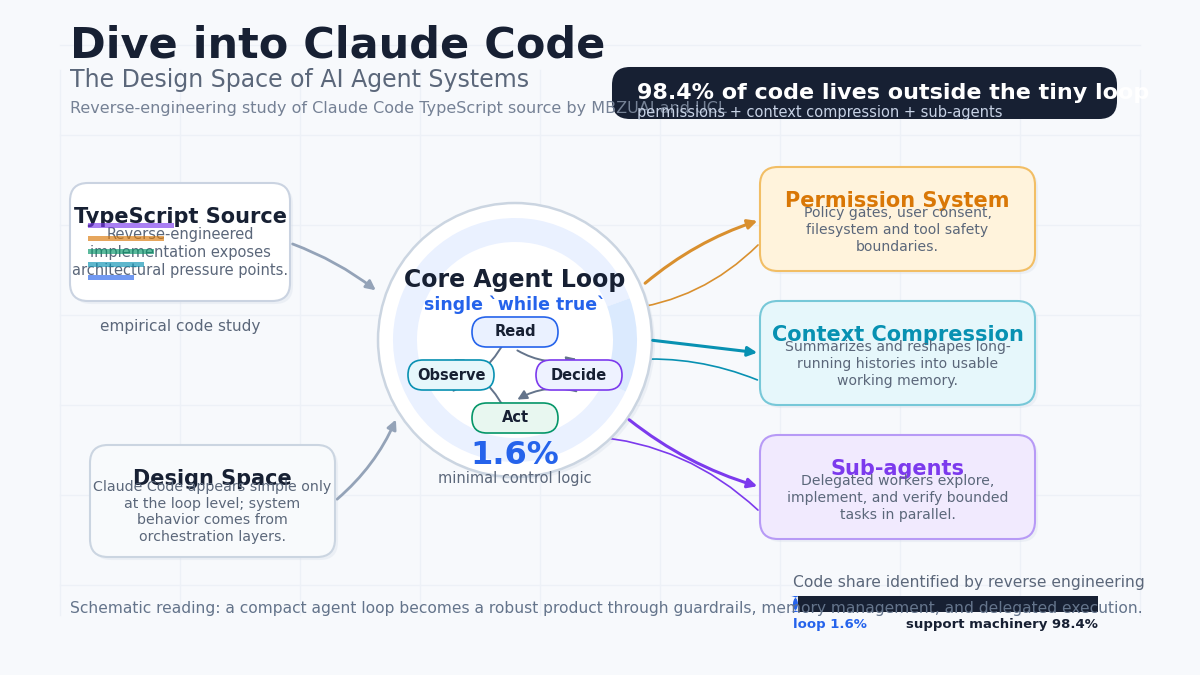
Dive into Claude Code The Design Space of AI Agent Systems
Think in Strokes, Not Pixels - Process-Driven Image Generation via Interleaved Reasoning
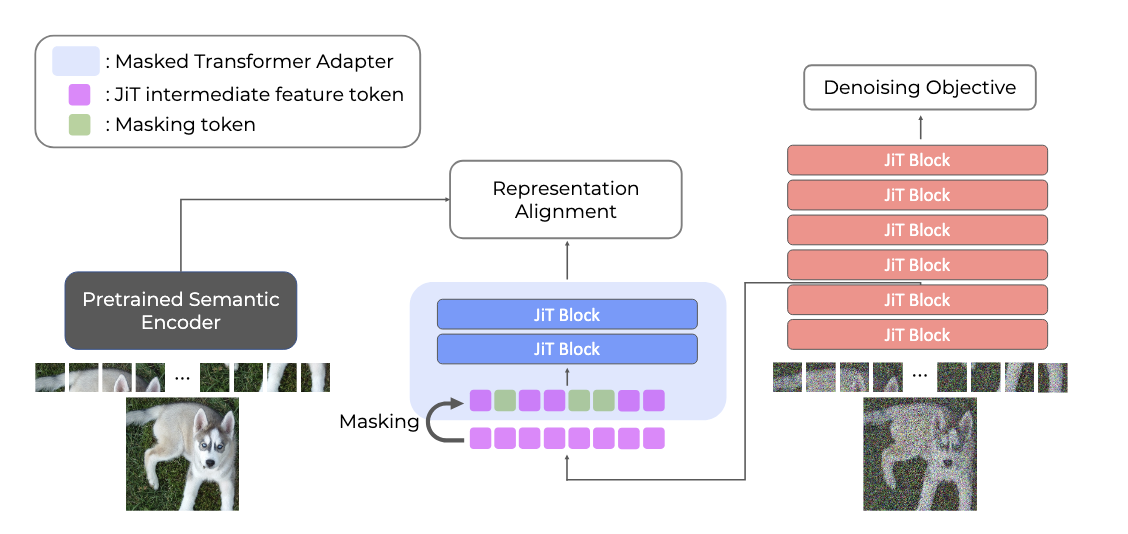
Representation Alignment for Just Image Transformers is not Easier than You Think
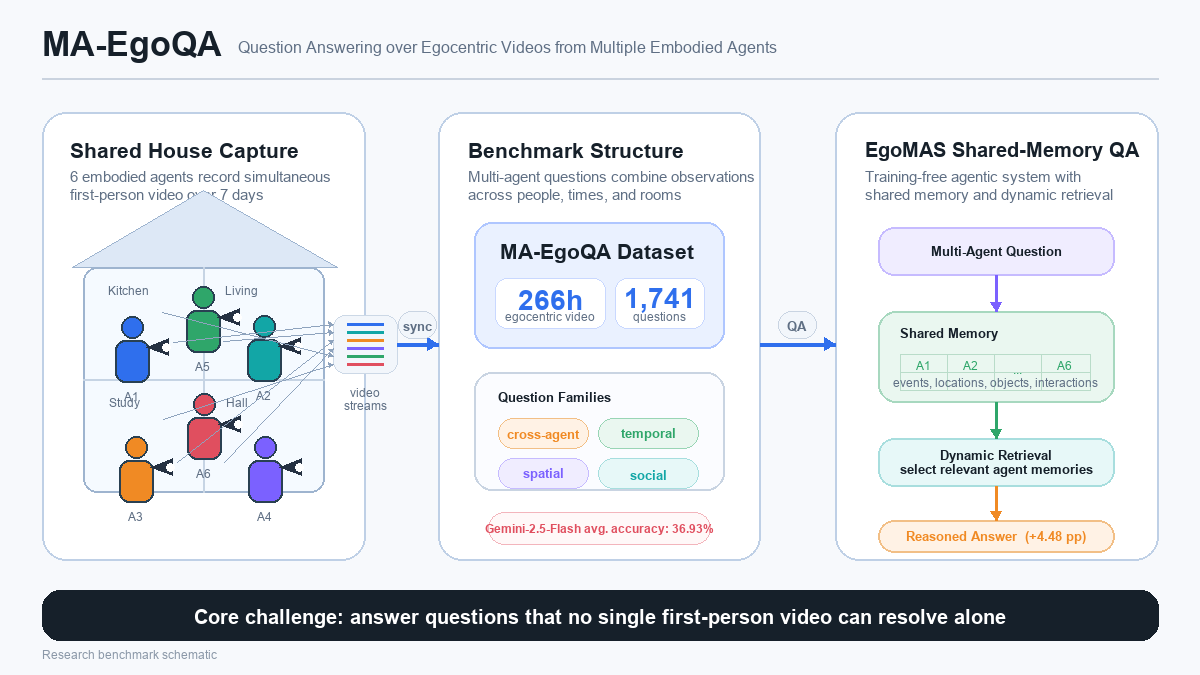
MA-EgoQA - Question Answering over Egocentric Videos from Multiple Embodied Agents
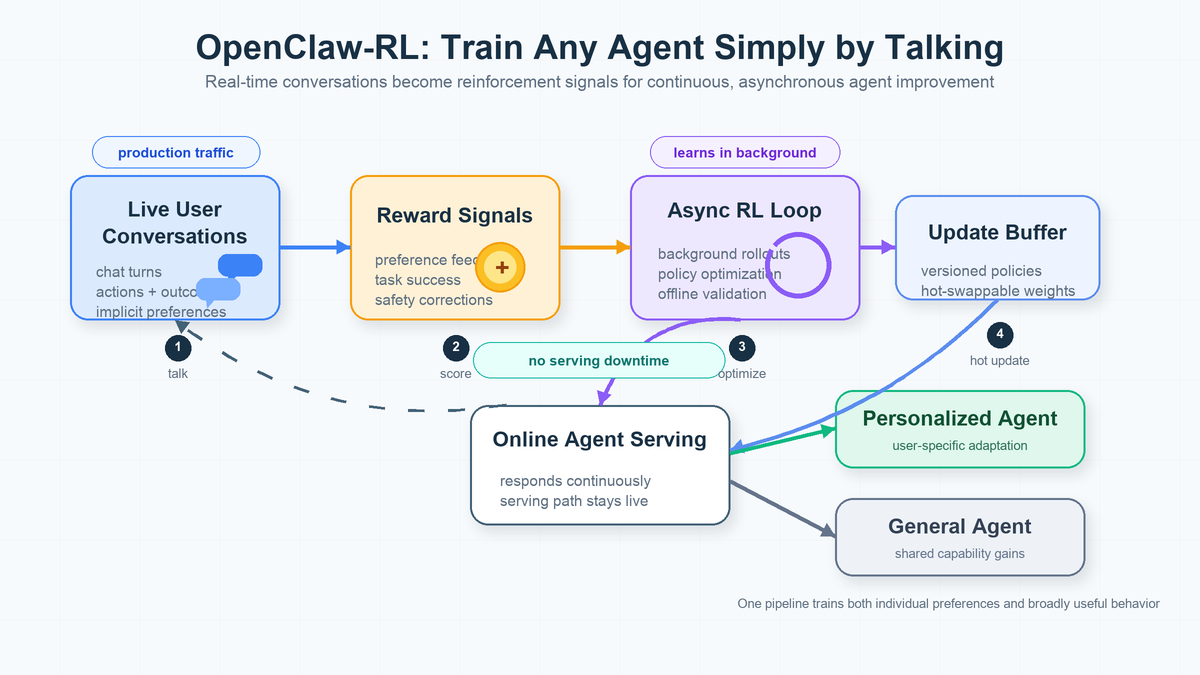
OpenClaw-RL - Train Any Agent Simply by Talking
Thinking to Recall - How Reasoning Unlocks Parametric Knowledge in LLMs
OmniLottie - Generating Vector Animations via Parameterized Lottie Tokens
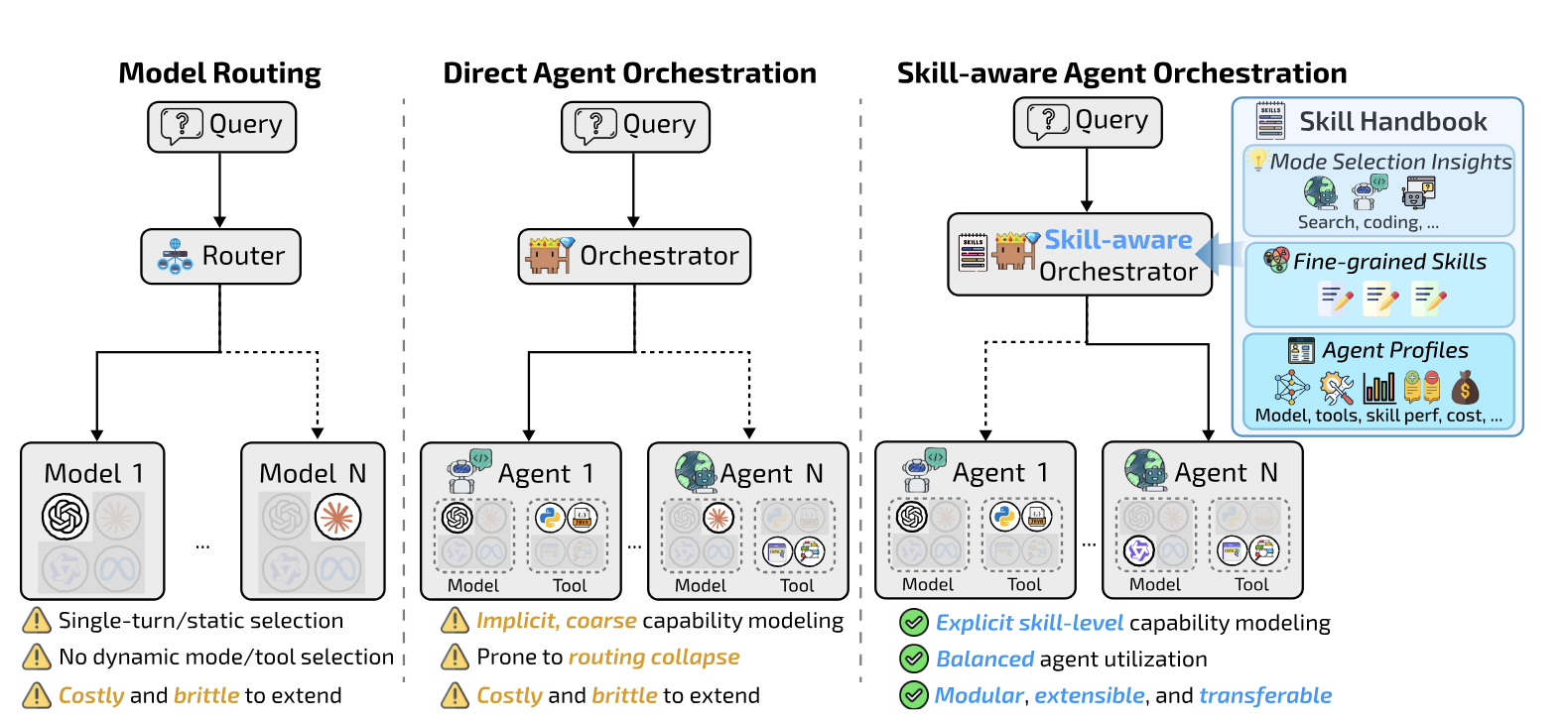
SkillOrchestra - Learning to Route Agents via Skill Transfer
Kimi k2.5 - 200만 토큰의 멀티모달 에이전트
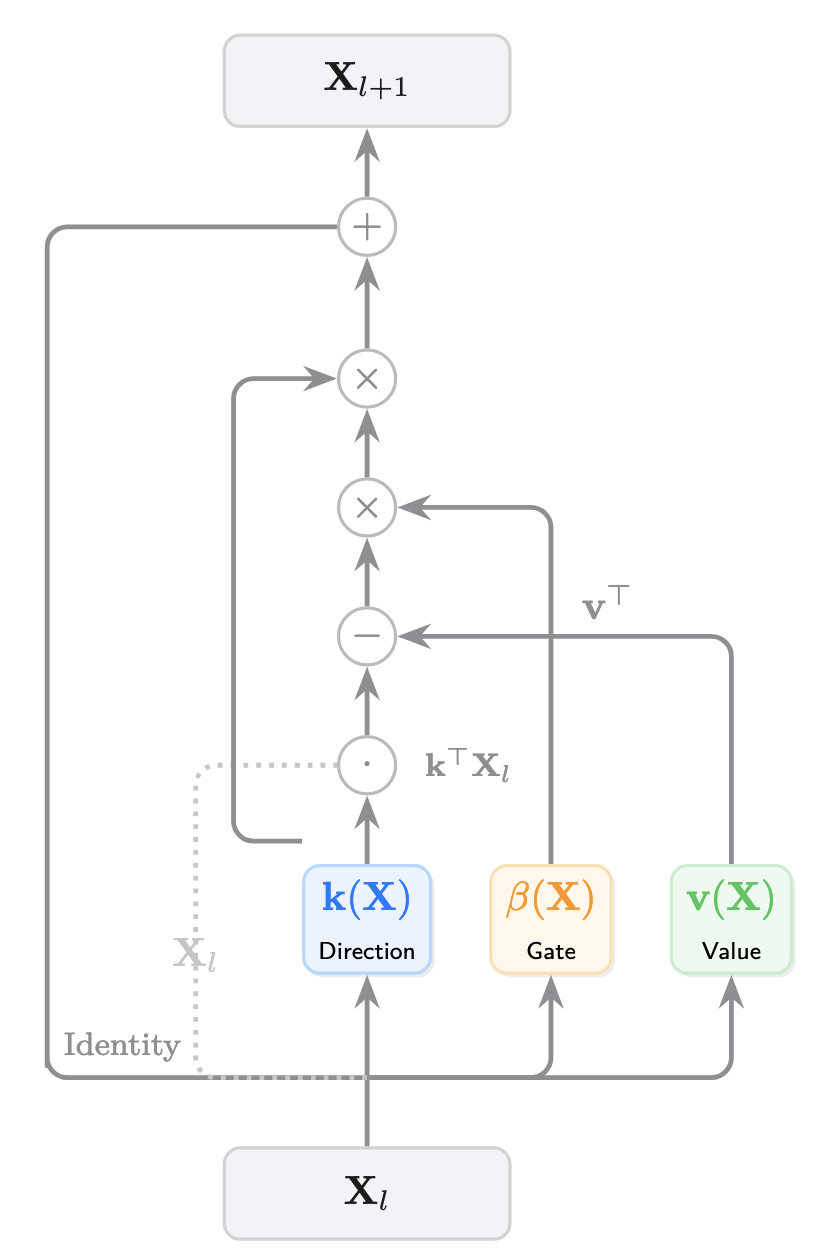
Deep Delta Learning
Seedream 4.0 Toward Next-generation Multimodal Image Generation
Souper-Model How Simple Arithmetic Unlocks State-of-the-Art LLM Performance
Black-Box On-Policy Distillation of Large Language Models
Depth Anything 3 Recovering the Visual Space from Any Views
LeJEPA Provable and Scalable Self-Supervised Learning Without the Heuristics
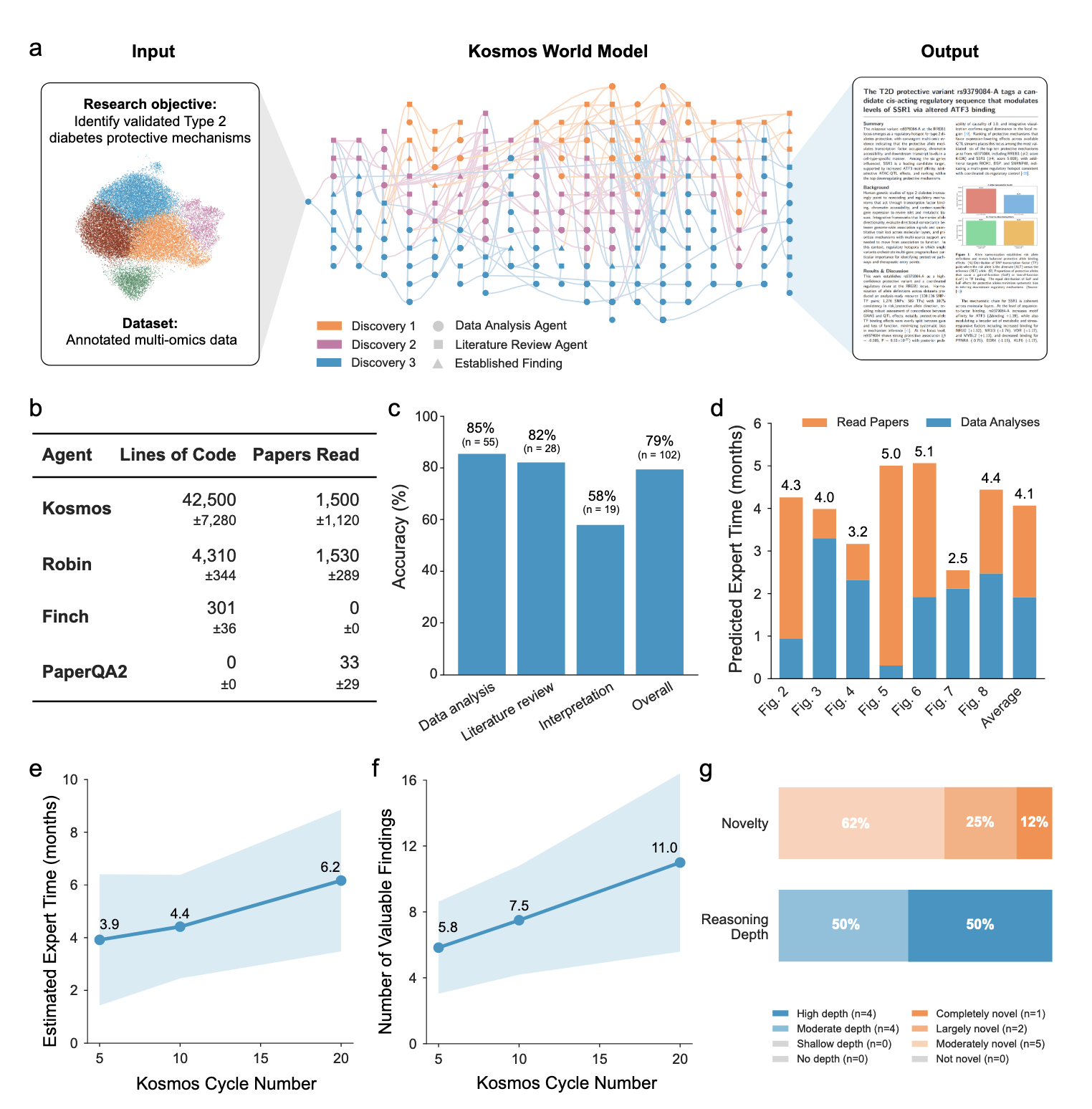
Kosmos An AI Scientist for Autonomous Discovery
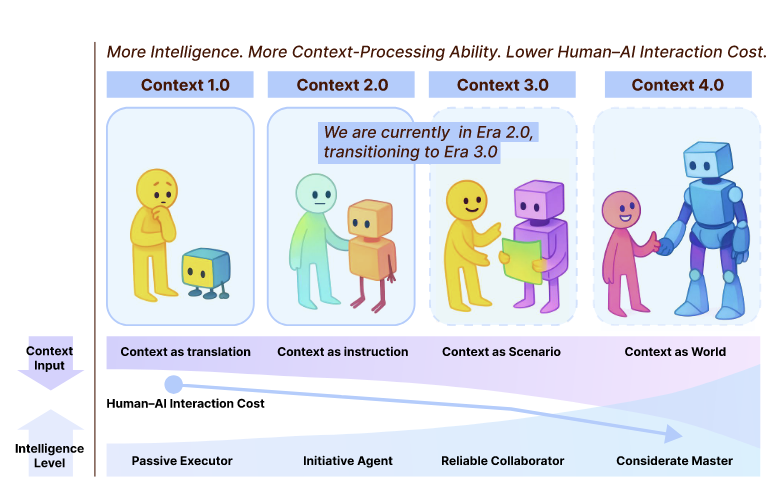
Context Engineering 2.0 - The Context of Context Engineering
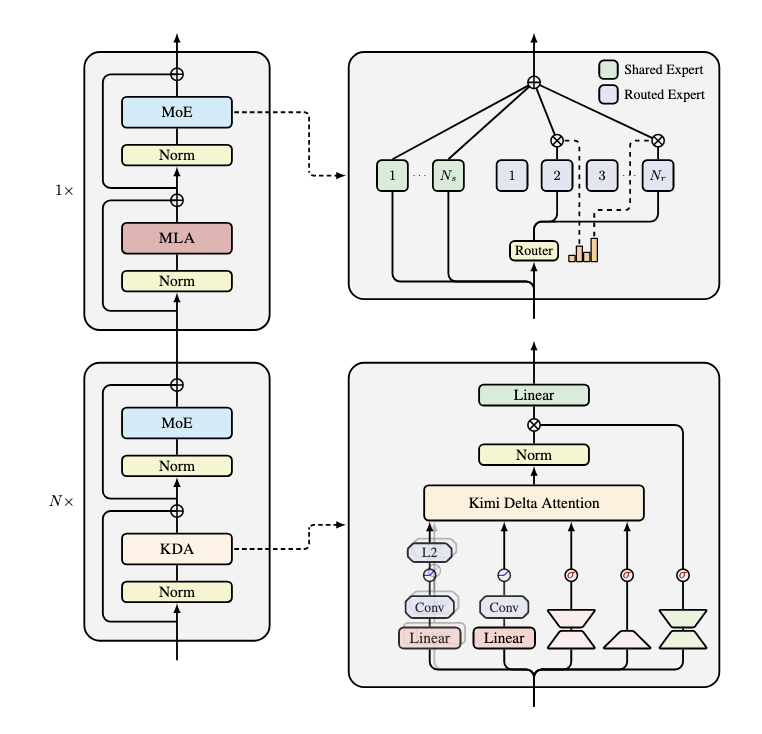
Kimi Linear An Expressive, Efficient Attention Architecture
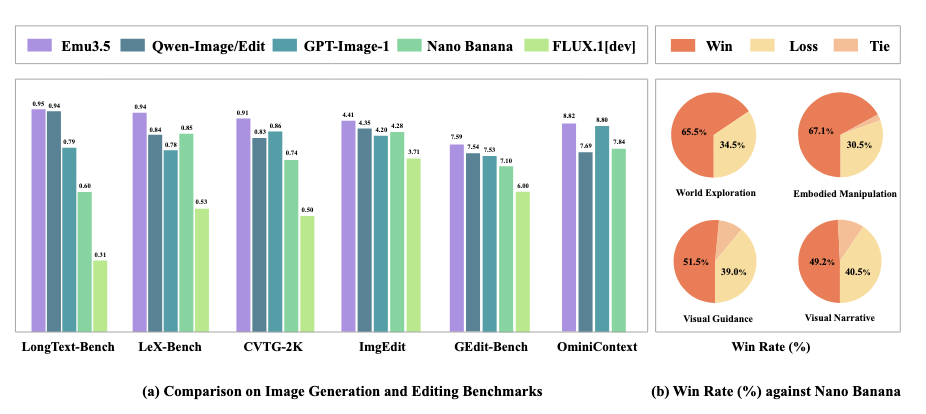
Emu3.5 Native Multimodal Models are World Learners
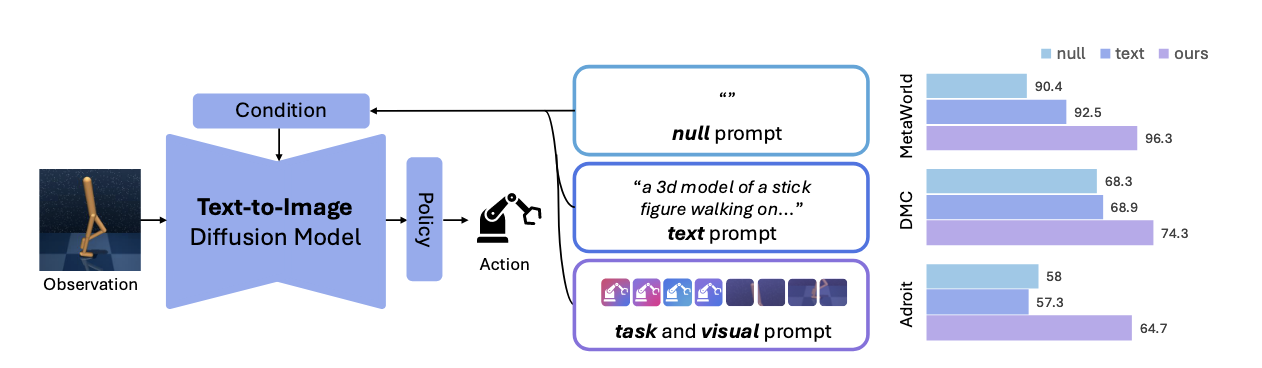
Exploring Conditions for Diffusion Models in Robotic Control
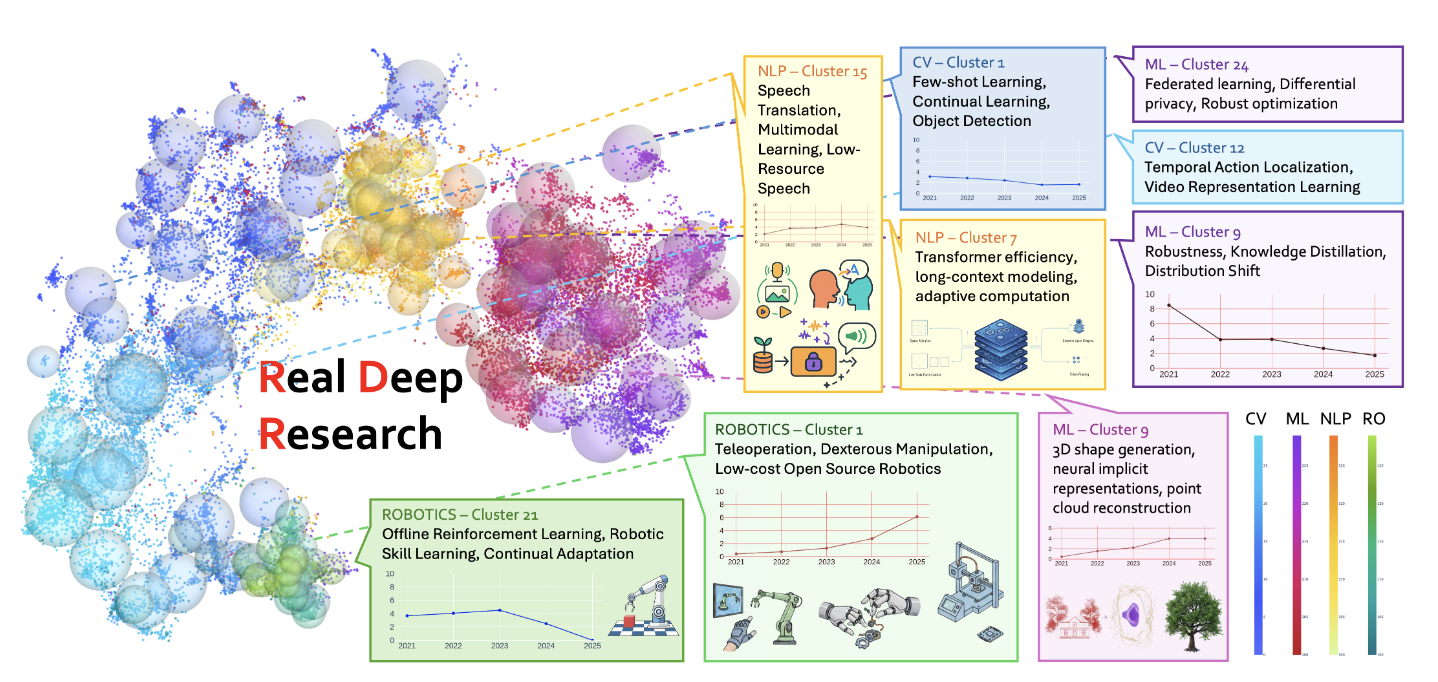
Real Deep Research for AI, Robotics and Beyond
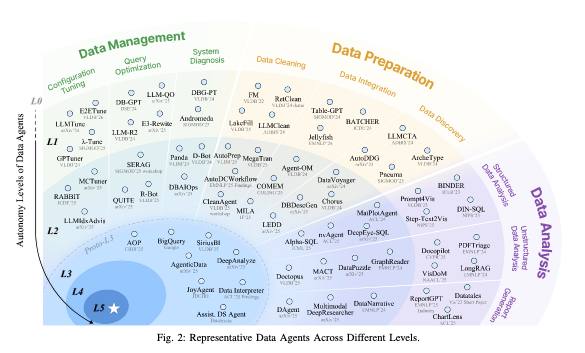
A Survey of Data Agents Emerging Paradigm or Overstated Hype
The Free Transformer
A Definition of AGI
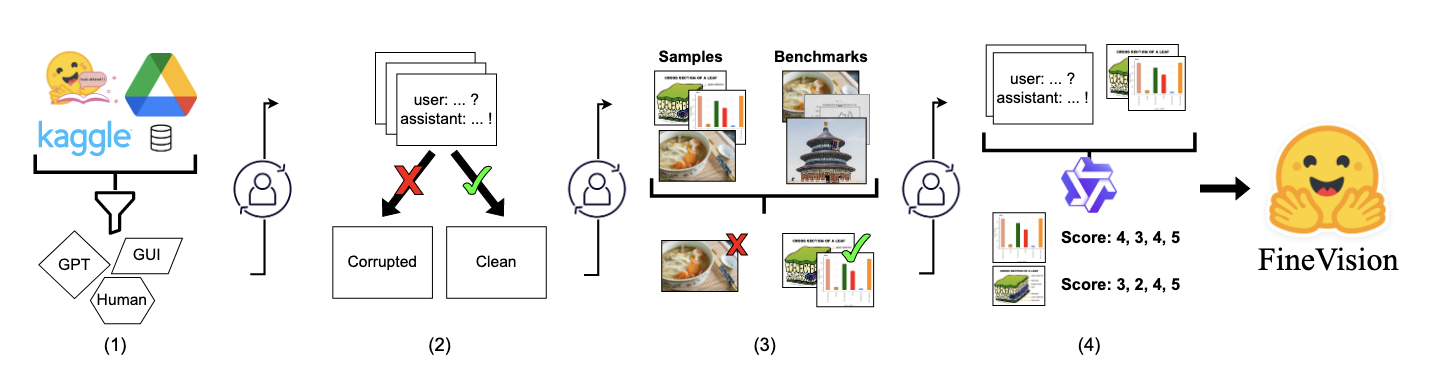
FineVision Open Data Is All You Need
DeepSeek-OCR Contexts Optical Compression
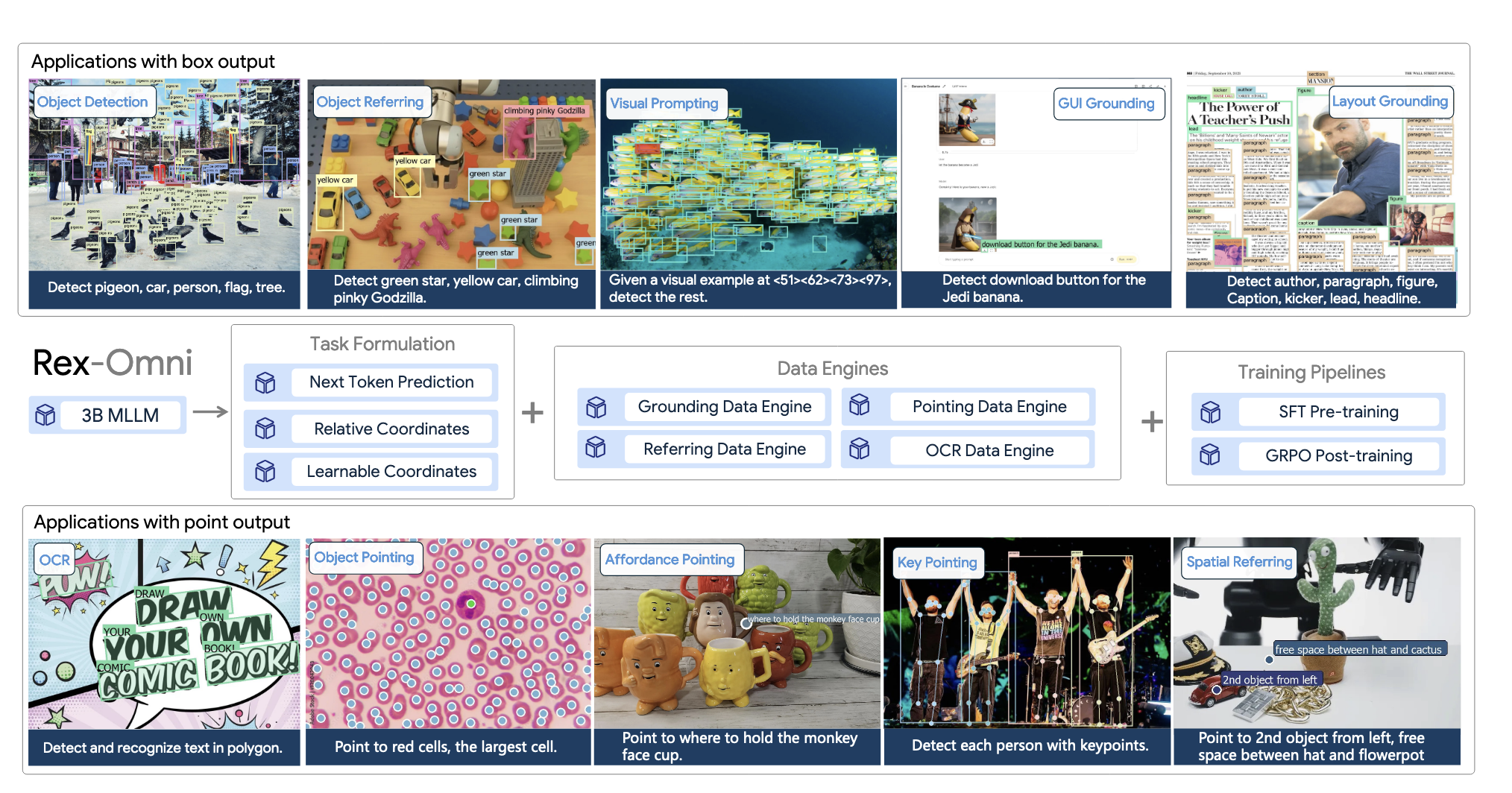
Detect Anything via Next Point Prediction
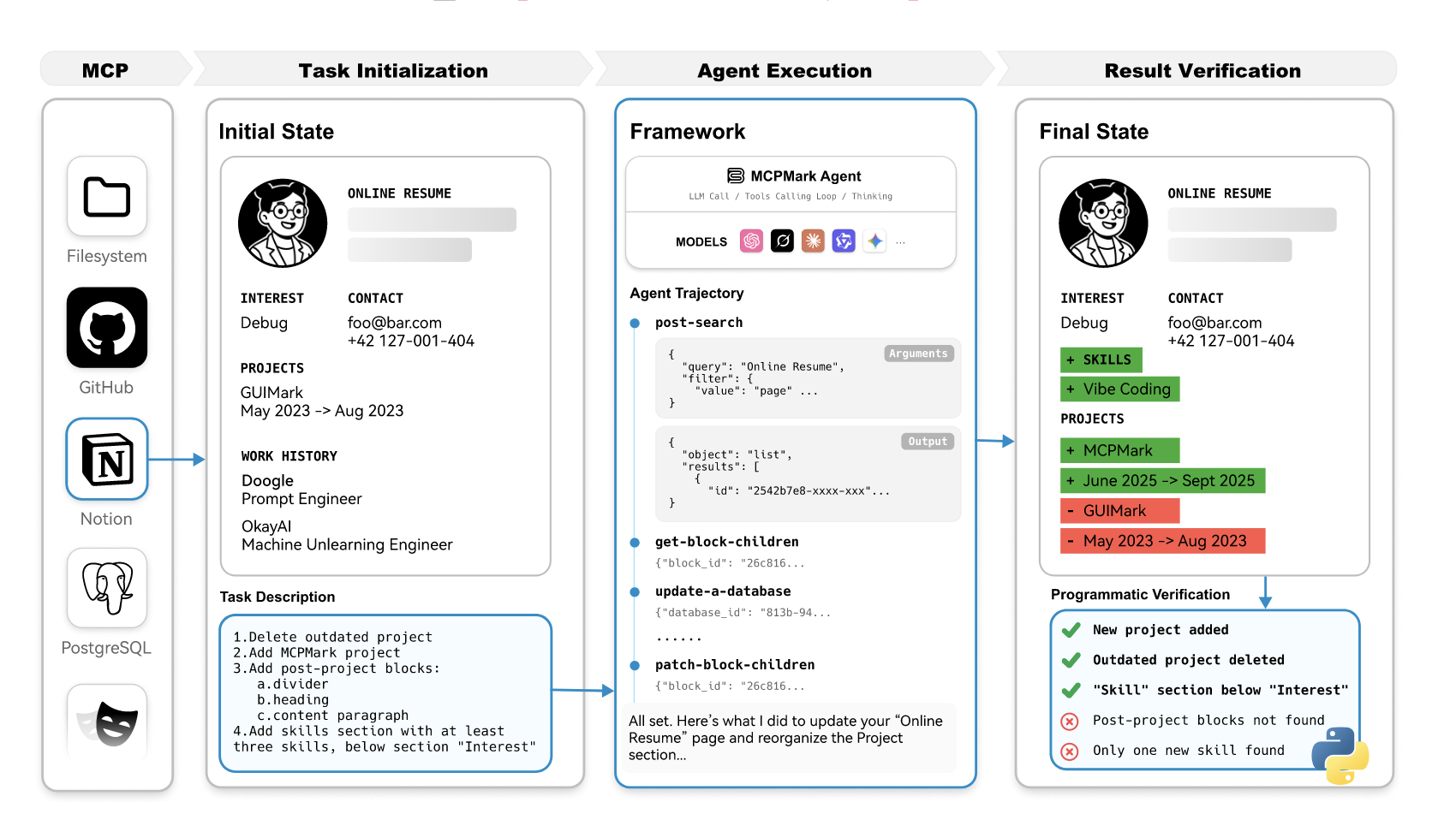
MCPMark A Benchmark for Stress-Testing Realistic and Comprehensive MCP Use
The Dragon Hatchling The Missing Link between the Transformer and Models of the Brain
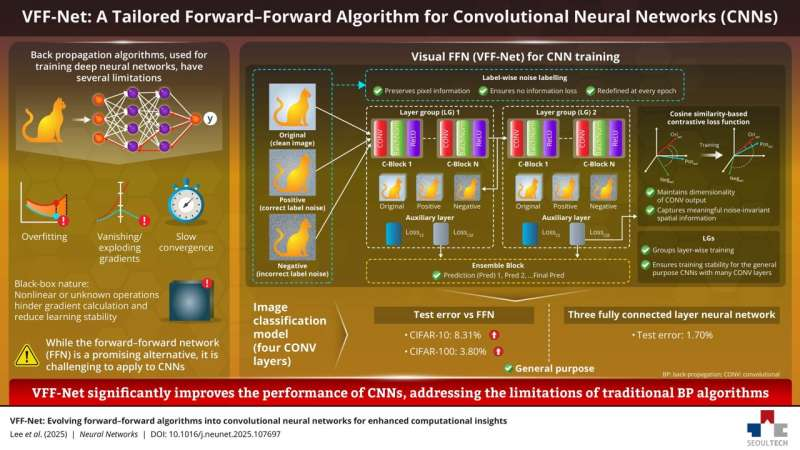
VFF-Net Evolving forward–forward algorithms into convolutional neural networks for enhanced computational insights
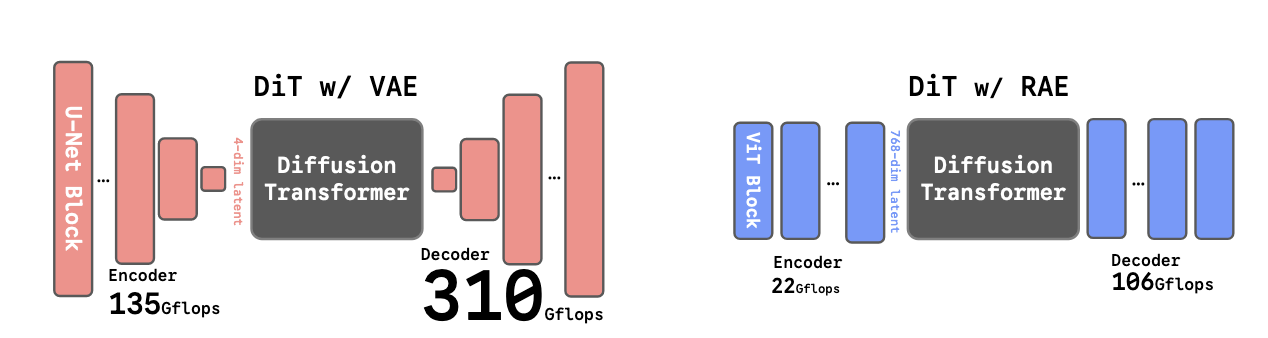
Diffusion Transformers with Representation Autoencoders
Training-Free Group Relative Policy Optimization
Pushing on Multilingual Reasoning Models with Language-Mixed Chain-of-Thought
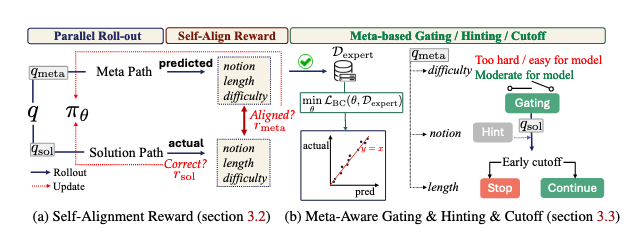
Meta-Awareness Enhances Reasoning Models Self-Alignment Reinforcement Learning
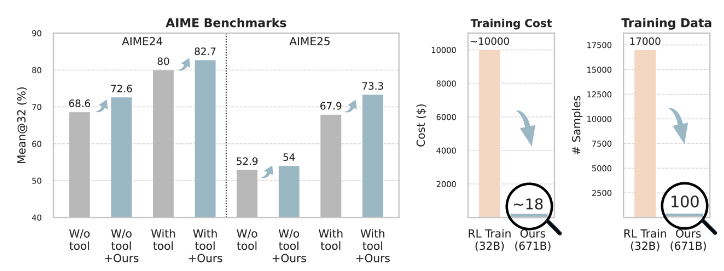
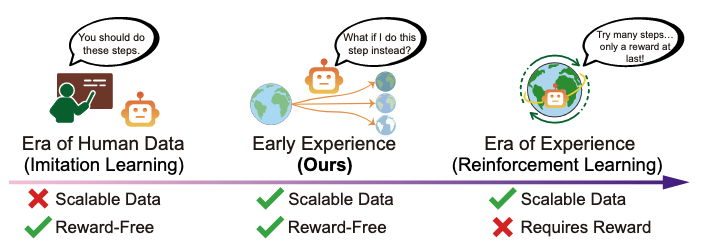
Agent Learning via Early Experience
FAST-DLLM V2 Efficient Block-Diffusion LLM
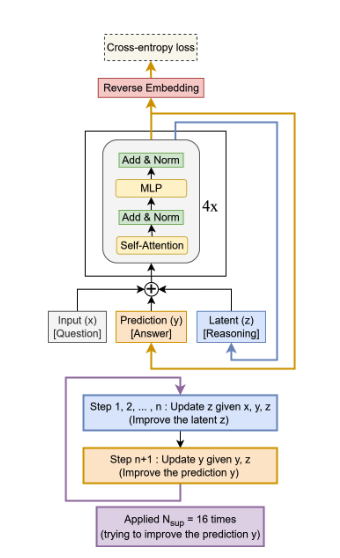
Less is More Recursive Reasoning with Tiny Networks
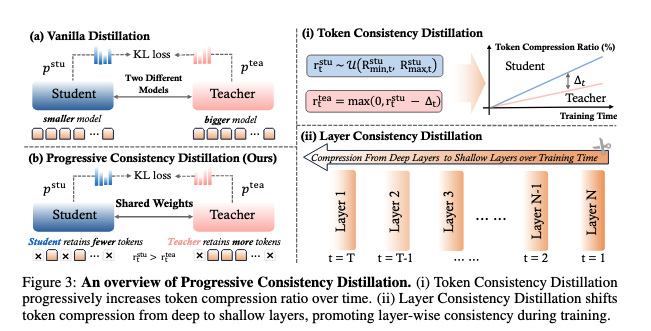
Efficient Multi-modal Large Language Models via Progressive Consistency Distillation
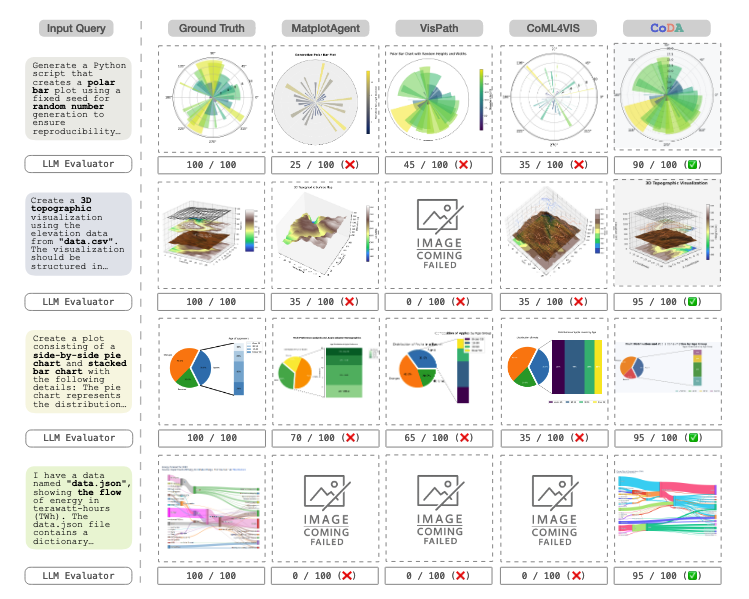
CoDA Agentic Systems for Collaborative Data Visualization
Video models are zero-shot learners and reasoners
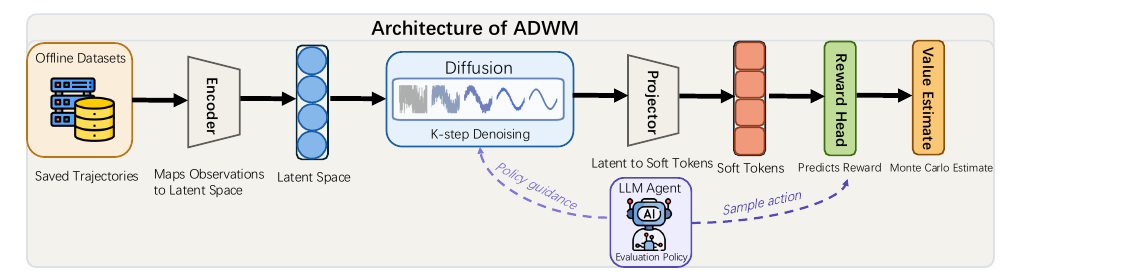
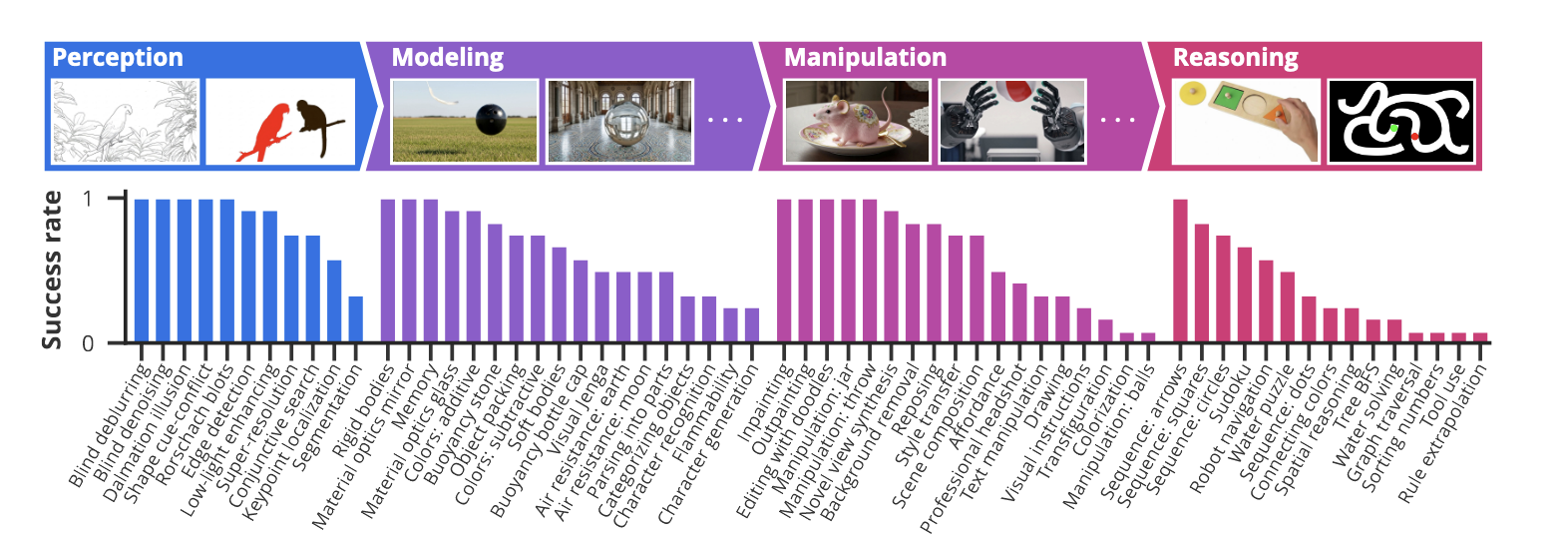
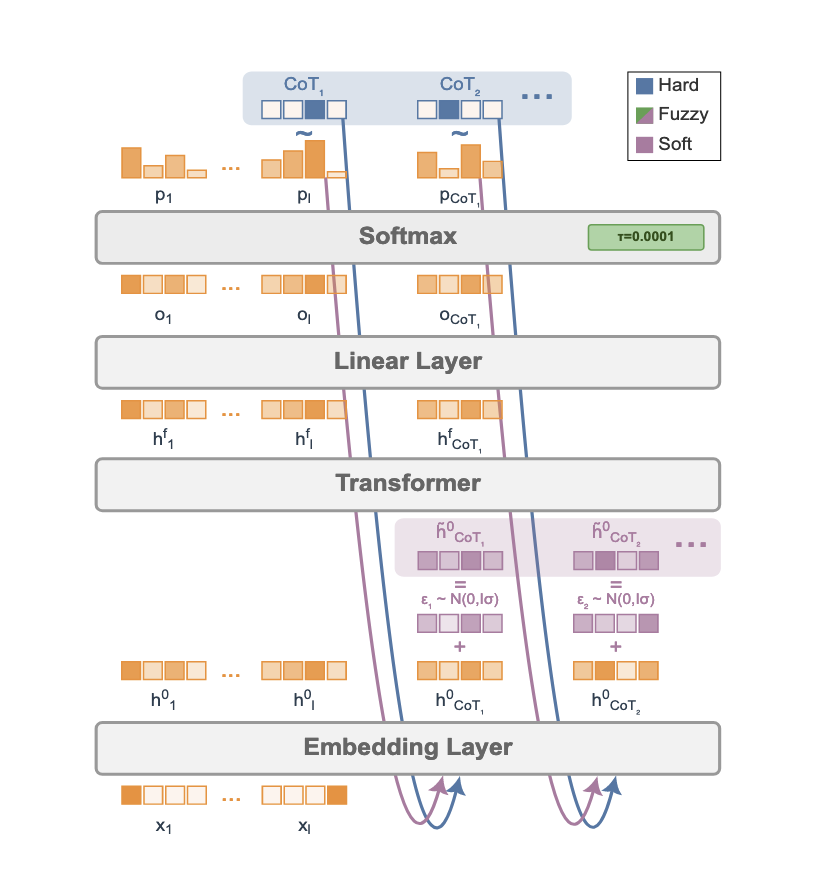
Soft Tokens, Hard Truths
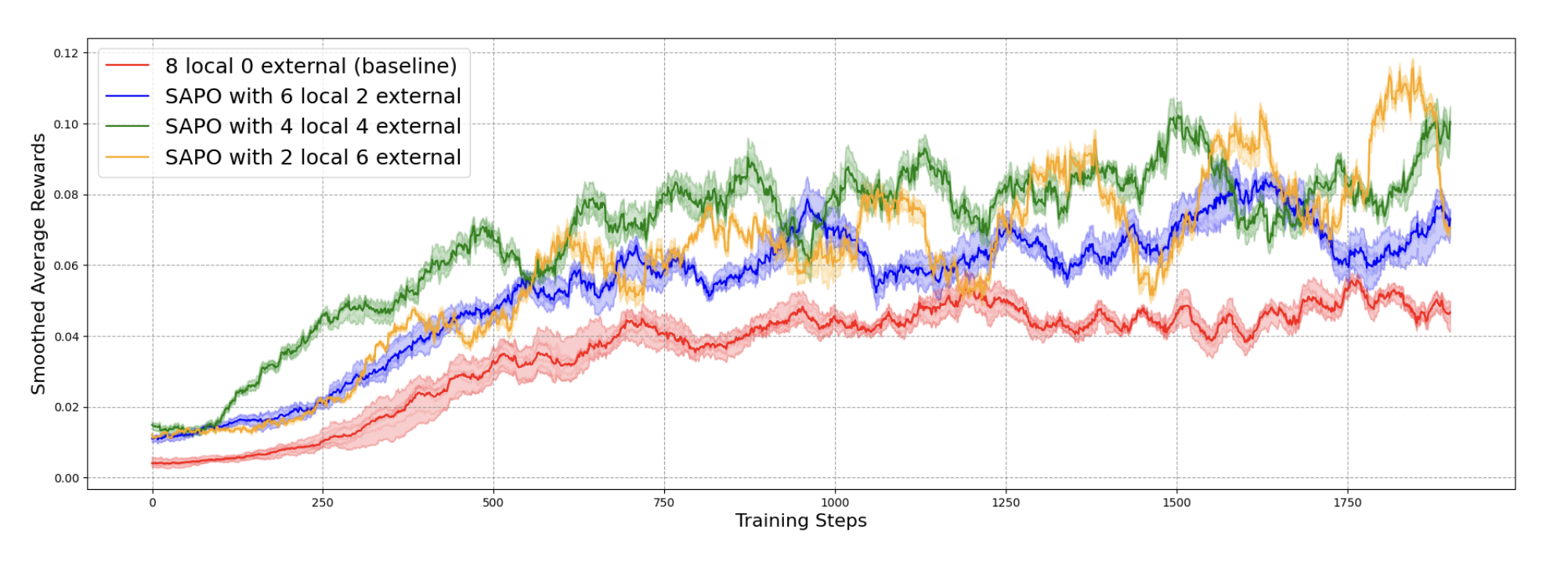
Sharing is Caring Efficient LM Post-Training with Collective RL Experience Sharing
Why Language Models Hallucinate
Hunyuan3D Studio End-to-End AI Pipeline for Game-Ready 3D Asset Generation
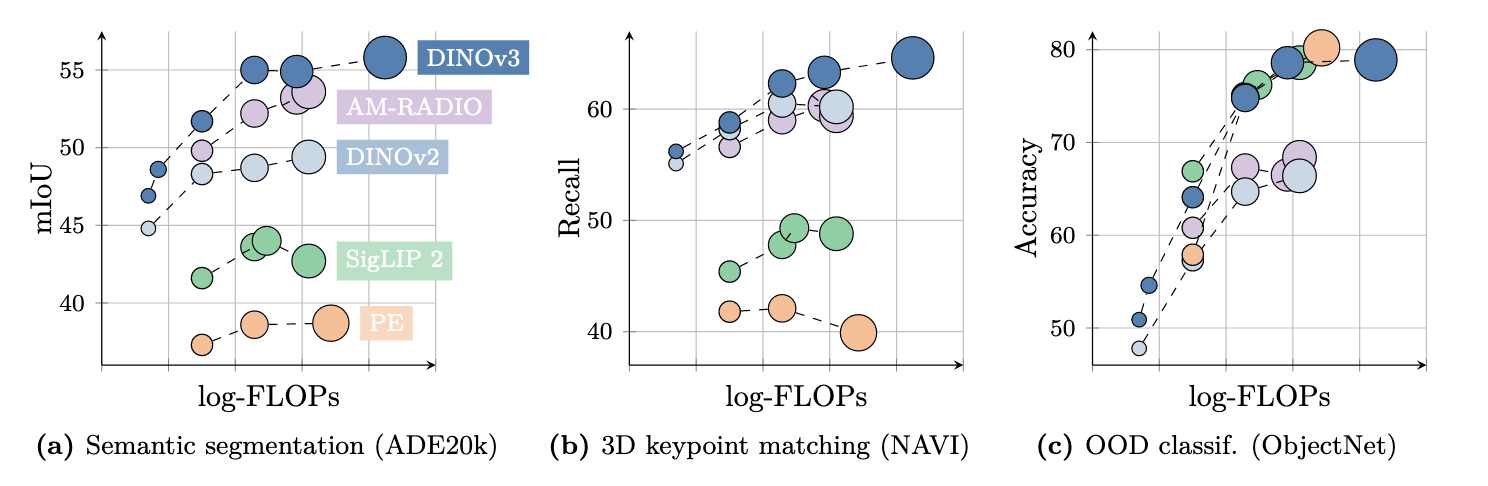
DINOv3
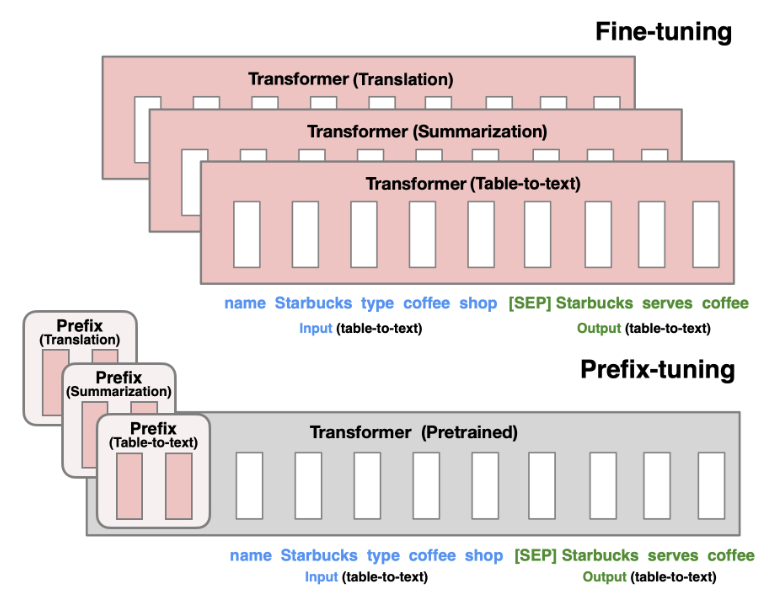
Prefix-Tuning Optimizing Continuous Prompts for Generation
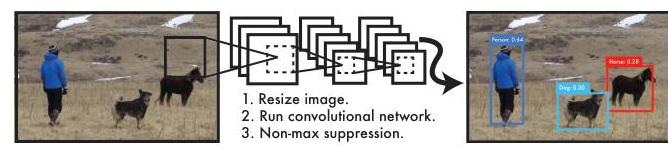
You Only Look Once, Unified Real-Time Object Detection
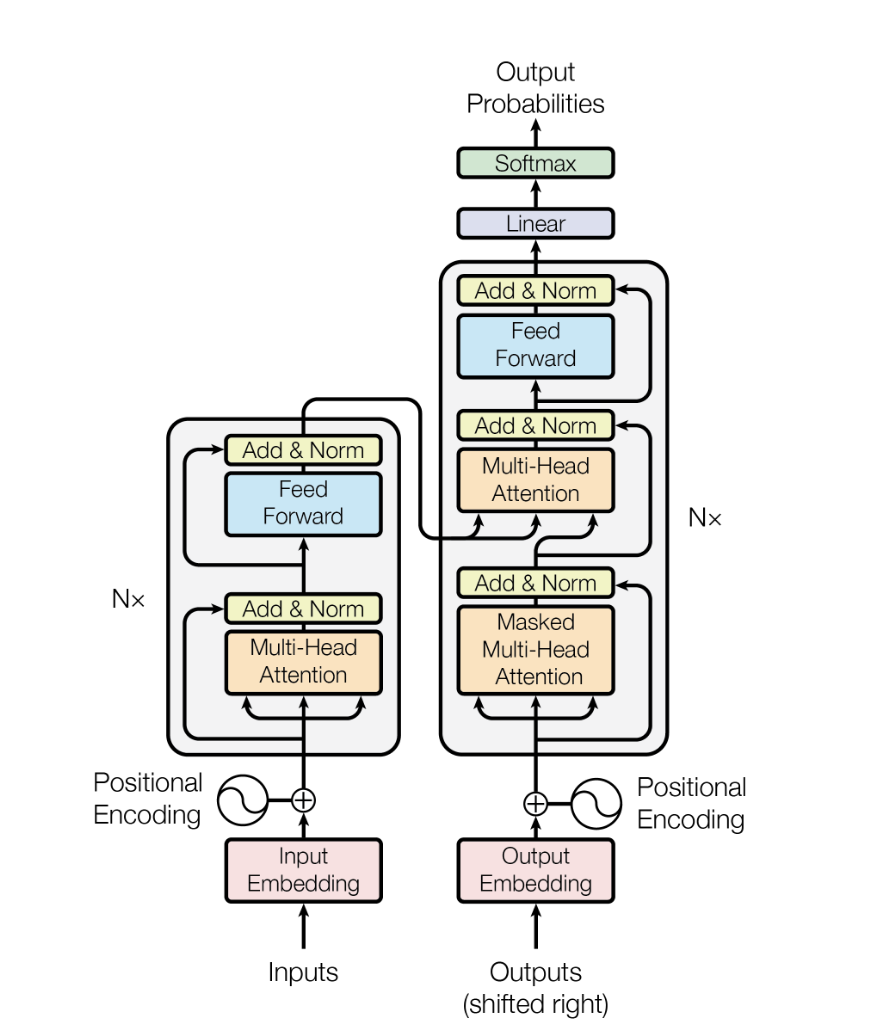
Attention Is All You Need
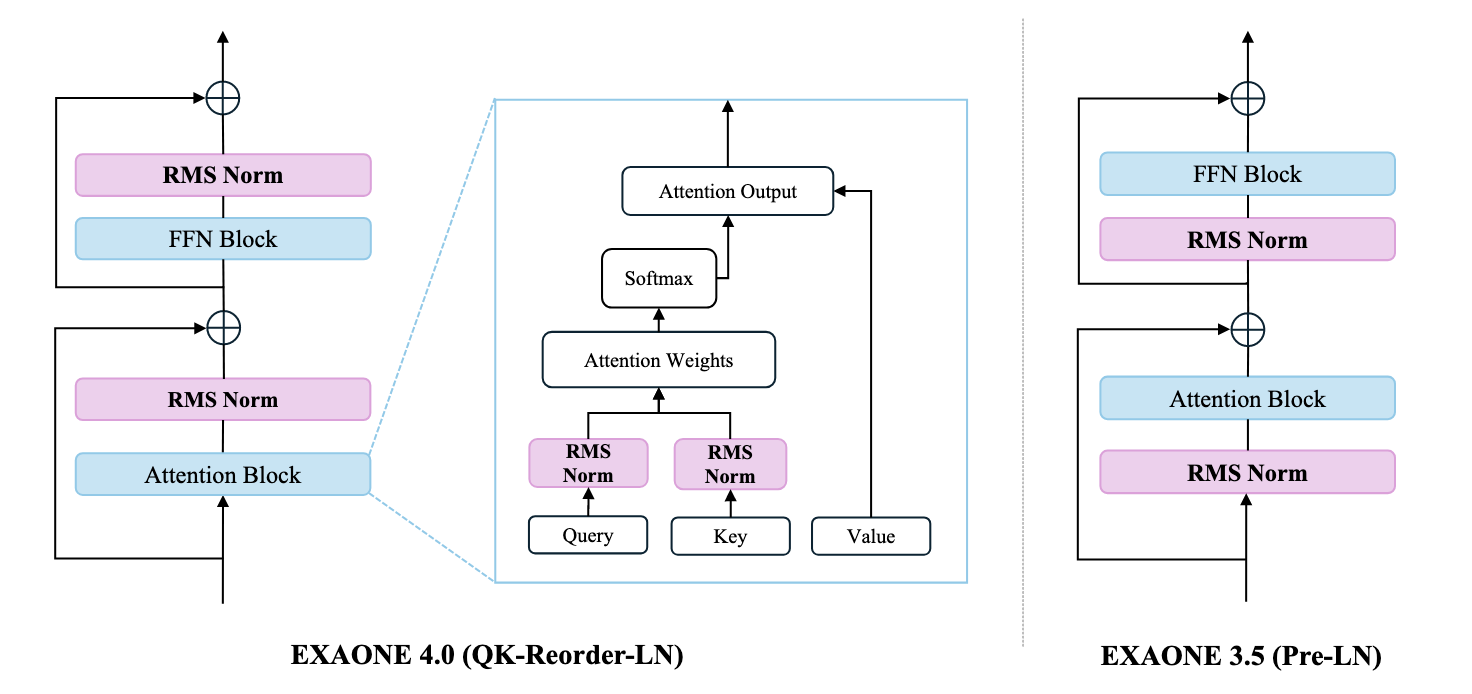
EXAONE 4.0 Unified Large Language Models Integrating Non-reasoning and Reasoning Modes
군중 상황에서 정확한 다중 사람의 자세 인식을 위한 군중 자세 주석 데이터 세트