



















NVIDIA의 OpenAI 오하이오 데이터센터 백스톱
2026-07-28
NVIDIA가 SB Energy가 짓는 10GW 오하이오 캠퍼스의 리스와 건설 금융에 약 2,500억 달러 보증을 검토 중입니다. 칩 조달 금융 3,500억 달러는 별도 협상입니다.
차진우
컴퓨터 정보학을 전공하고 딥러닝 영상처리를 연구했습니다. 지금은 LLM의 실무 적용과 AX를 공부하고 연구합니다. 경험을 공유하기 위해 글을 쓰고 책을 만듭니다.
주인장은 기술 동향과 인공지능에 관심이 많은 IT 애호가입니다. 개발자도, 전문가도 아니기 때문에 틀린 내용이 있을 수 있습니다. 콘텐츠에 대한 의견과 피드백을 환영합니다.
도서가 출간되었습니다! 《바로바로 클로드 with 코워크, 스킬, 클로드 코드, 디자인》
골든래빗은 더 탁월한 가치를 제공하는 콘텐츠 프로덕션 & 프로바이더 입니다. 골든래빗은 취미, 경제, 수험서, 만화, IT 등 다양한 분야에서 책을 제작하고 있습니다. 골든래빗 홈페이지로 놀러오세요!
개발자를 위한 커뮤니티를 운영중입니다!
최신 업계 동향과 취업 정보를 제공합니다!
다른 현업 개발자와 소통하세요!
출판 관련 문의는 아래 메일로 보내주세요!
NVIDIA가 SB Energy가 짓는 10GW 오하이오 캠퍼스의 리스와 건설 금융에 약 2,500억 달러 보증을 검토 중입니다. 칩 조달 금융 3,500억 달러는 별도 협상입니다.
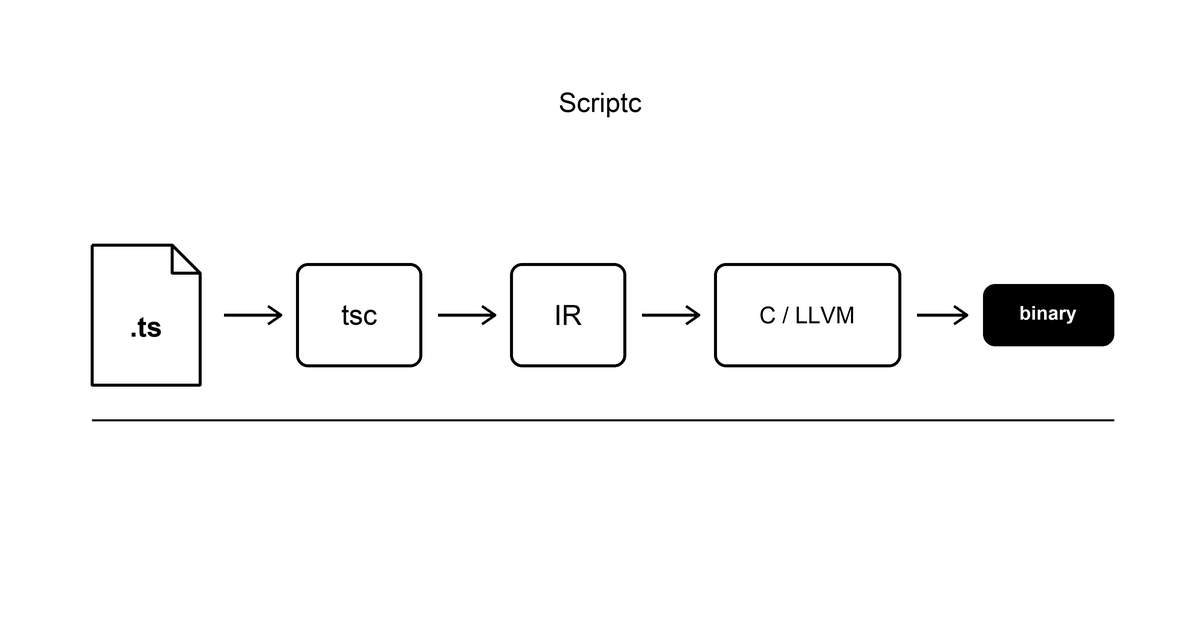
Vercel Labs가 TypeScript를 Node나 V8 없이 단독 네이티브 실행파일로 만드는 컴파일러를 공개했습니다. tsc로 타입체크한 뒤 IR을 거쳐 C와 LLVM으로 내리고, 참조계수 런타임과 이벤트 루프를 직접 구현했습니다.
Anthropic이 두 달 새 네 번째 Claude 5 계열 모델을 내놓았습니다. 단가는 Opus 4.8과 같게 두고, low/medium/high 노력 토글로 요청마다 계산량을 사용자가 정하게 했습니다.

웹이 AI 생성문으로 포화되면서 2022년 이전 인쇄본이 마지막 비오염 인간 저작 코퍼스가 됐습니다. 중개업체가 팔레트 단위로 헌책을 사서 책등을 잘라 스캔한 뒤 원본을 펄프화합니다.
Google이 2026년 7월 21일 Gemini 3.6 Flash, 3.5 Flash-Lite, 3.5 Flash Cyber를 한꺼번에 내놨습니다. 기다리던 3.5 Pro는 없었고, 보안 전용 모델은 공개하지 않았습니다.
HuggingFace 프로덕션 인프라에 자율 AI 에이전트 스웜이 17,000+ 행동으로 침투했습니다. 공격자도 AI 에이전트를 썼고, 방어자도 AI 에이전트를 썼습니다.

NVIDIA가 공개한 Nemotron 3 Embed는 8B·1B·1B-NVFP4 세 가지 체크포인트로 구성된 오픈 임베딩 컬렉션입니다. 8B 모델이 RTEB 멀티링구얼 리더보드 1위(78.46 NDCG@10)를 기록했고, RAG와 에이전트 검색에 직접 쓸 수 있습니다.
독일 방송면허감독위원회(ZAK)가 Google AI Overviews와 Perplexity를 미디어 사업자로 판정했습니다. AI가 생성한 요약물을 '콘텐츠 생산'으로 보고 DSA 면책 조항을 배제한 세계 첫 사례입니다.
Apple이 OpenAI를 상대로 영업비밀 침해 소송을 제기했습니다. 전직 Apple 직원이 OpenAI로 이직하면서 내부 AI 하드웨어 기술을 유출했다는 혐의로, 두 회사의 파트너십이 균열을 맞이했습니다.
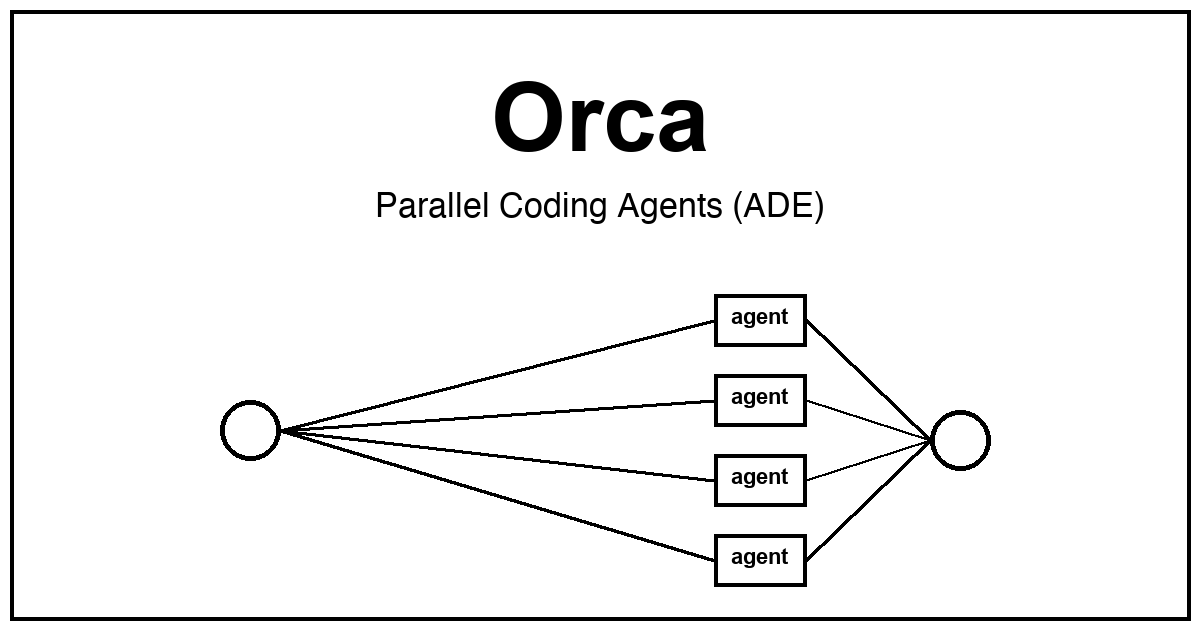
stablyai가 공개한 오픈소스 에이전트 개발 환경(ADE). 여러 AI 코딩 에이전트를 병렬로 실행해 복잡한 소프트웨어 작업을 나누어 처리하며, GitHub 스타 21,702개를 돌파했습니다.
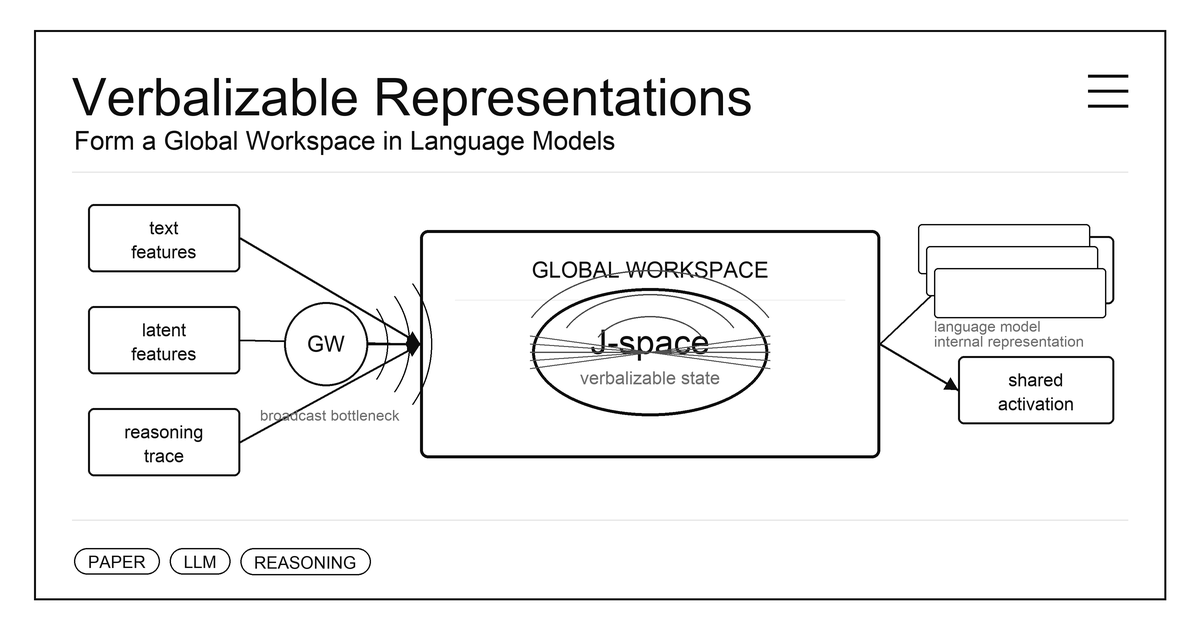
Anthropic이 언어모델 내부에서 인간의 의식 접근(access consciousness)과 유사한 기능을 하는 신경 표상 집합을 발견했습니다. J-space라 이름 붙인 이 표상은 Claude가 무엇을 생각하고 있는지 겉으로 드러나지 않는 순간에도 읽어낼 수 있게 해주며, 안전성 모니터링에도 실제로 활용되고 있습니다.
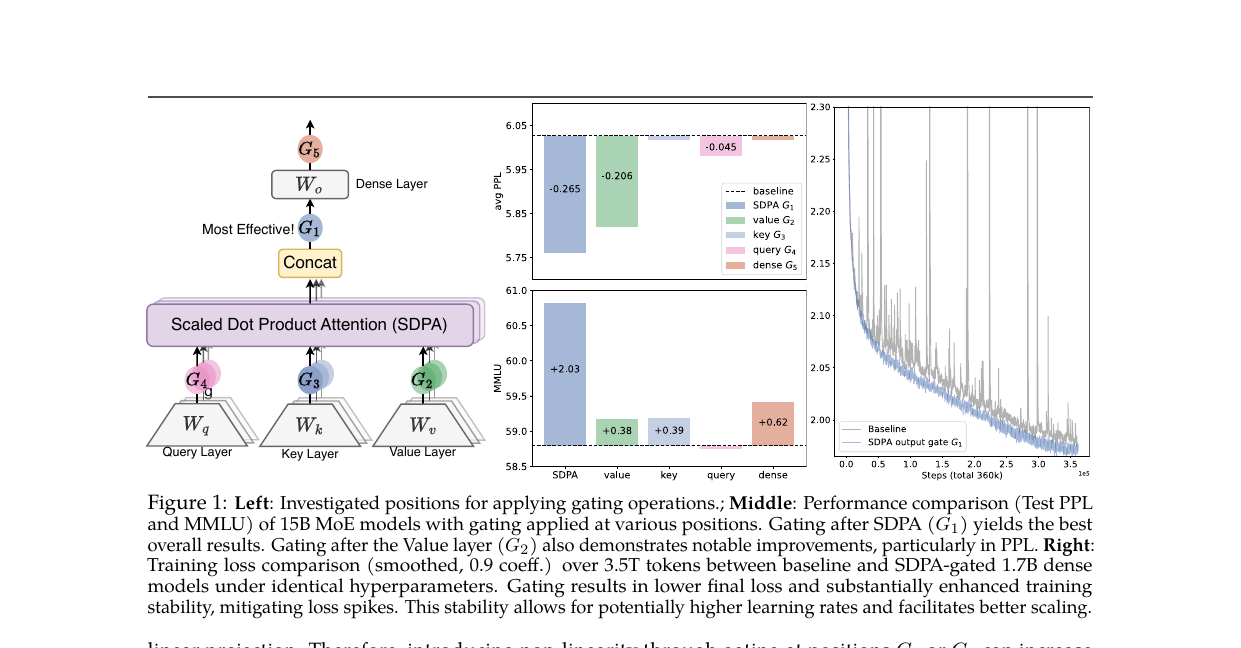
어텐션 출력 뒤에 헤드별 시그모이드 게이트 하나. PPL -0.2, MMLU +2점, 어텐션 싱크 소멸. NeurIPS 2025 Best Paper.
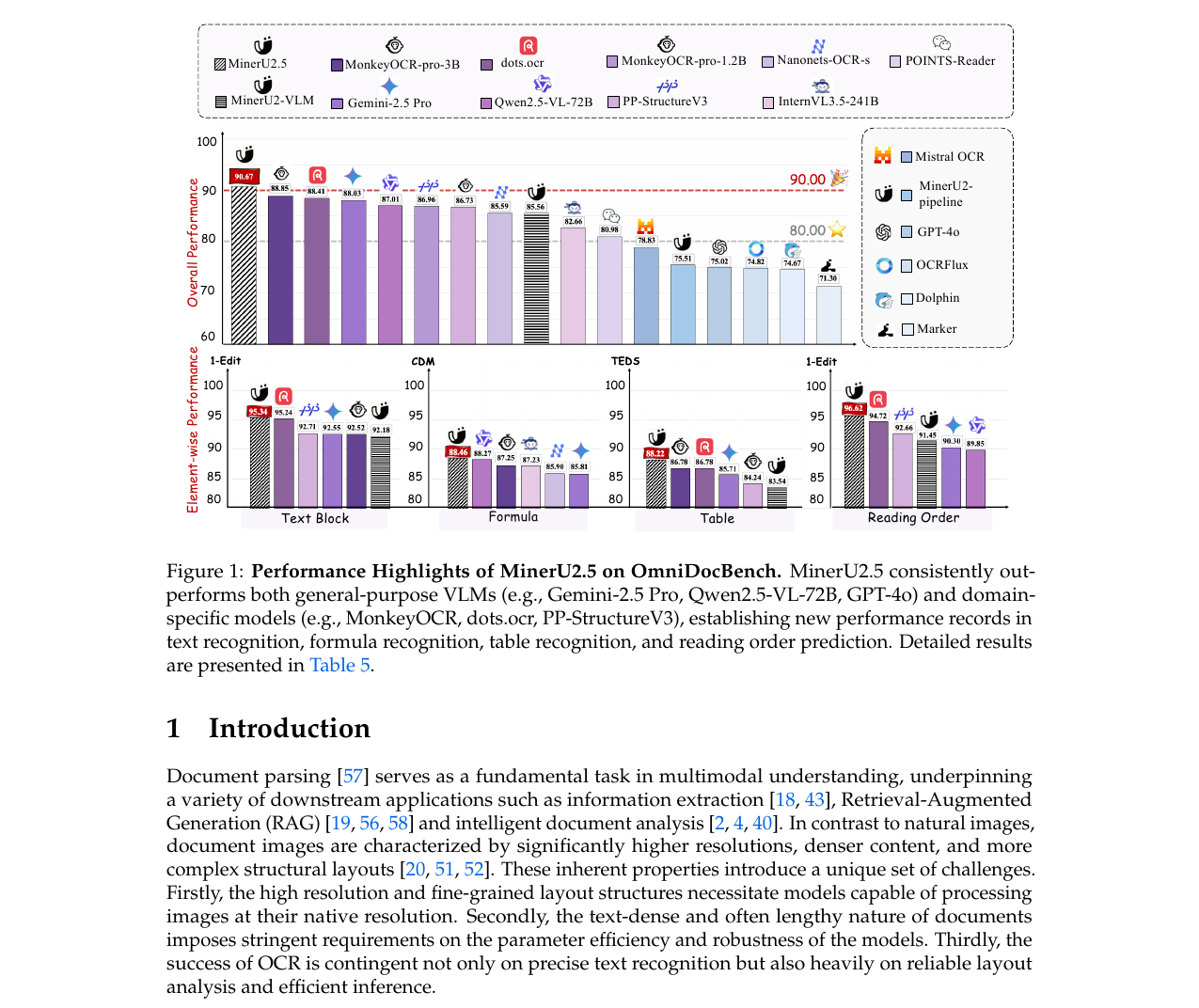
1.2B 파라미터로 고해상도 문서의 정확한 파싱을 달성한 MinerU2.5의 2단계 분리 아키텍처와 데이터 엔진을 분석합니다.
Google Cloud가 제안한 OKF는 AI 에이전트가 데이터를 이해할 수 있도록 마크다운과 YAML 프론트매터로 지식을 표현하는 개방형 표준입니다. CLAUDE.md와 옵시디언 볼트 같은 패턴의 데이터 카탈로그 버전입니다
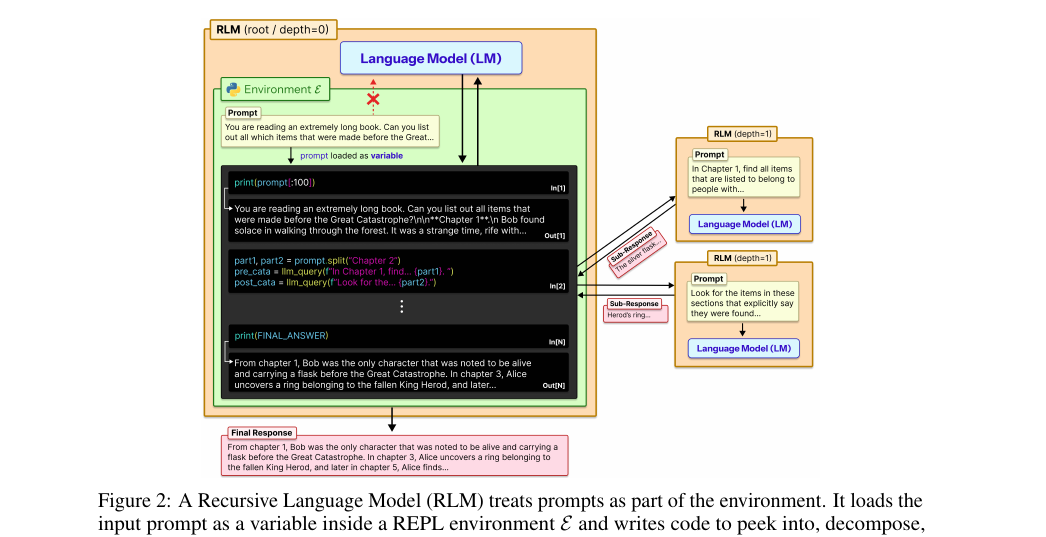
긴 프롬프트를 신경망에 통째로 밀어넣지 않고 REPL 환경의 변수로 두는 추론 패러다임. 모델이 코드를 써서 컨텍스트를 들여다보고 자기 자신을 재귀 호출합니다. 컨텍스트 창을 한 자리 수 배가 아니라 10M 토큰 단위로 넘기면서도 비용은 비슷하게 유지합니다.
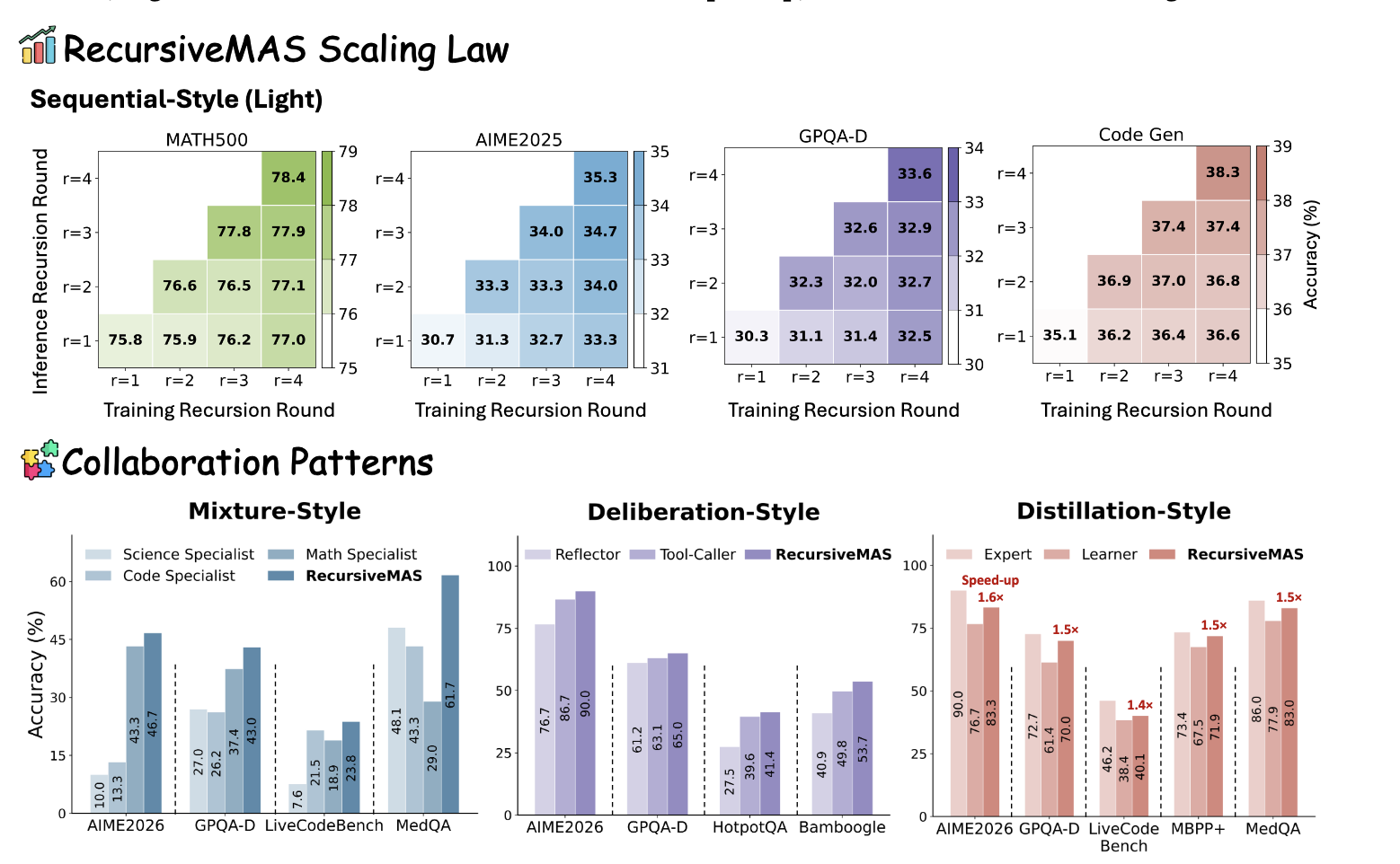
AI 에이전트 하나가 작업을 받습니다. 그 에이전트가 작업을 쪼갭니다. 쪼개진 작업들을 새로운 에이전트들에게 넘깁니다. 그 에이전트들도 또 쪼갭니다. AI가 AI를 낳는다. 재귀적 멀티에이전트 시스템이 무엇이고, AI의 불편한 미래는 어디로 향하는지 정리합니다.

또이트댄스입니다. Depth Anything 3는 한 장의 이미지든 여러 장의 영상이든, 카메라 포즈 정보가 있든 없든 상관없이 3D 기하 정보를 예측하는 모델입니다. 평범한 트랜스포머 하나와 단순한 깊이-광선(depth-ray) 표현으로 이전 최고 성능을 44% 능가하는 성능을 달성했으며, 모든 데이터를 공개 학술 데이터셋으로만 학습했습니다.

언어 모델의 환각(Hallucination) 현상을 통계적 관점에서 분석한 논문을 요약합니다. 환각이 사전훈련의 필연적 결과이며, '모르겠다'를 처벌하는 현재의 평가 방식 때문에 사후훈련 후에도 지속되는 구조적 문제를 지적하고 해결책을 제시합니다.
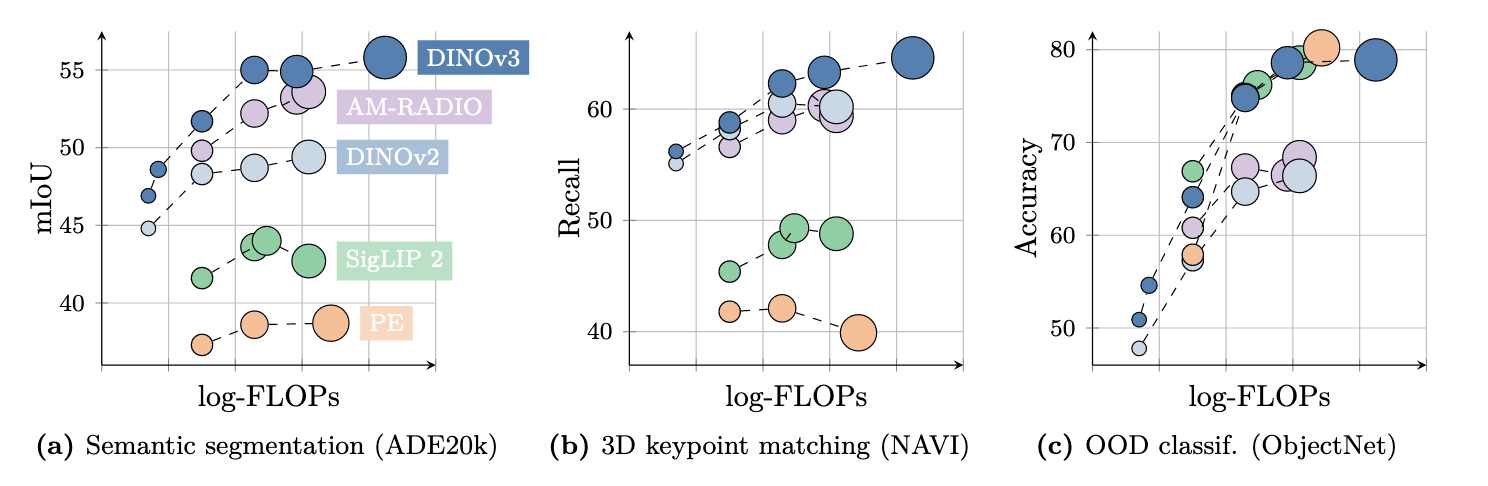
Meta AI의 70억 파라미터 자기지도학습 모델 DINOv3 논문을 요약합니다. 라벨 없이 이미지 특징을 학습하는 이 모델의 거대한 아키텍처, 데이터 큐레이션 전략, 그리고 패치 일관성을 유지하는 혁신 기술 'Gram Anchoring'을 중심으로 설명합니다.
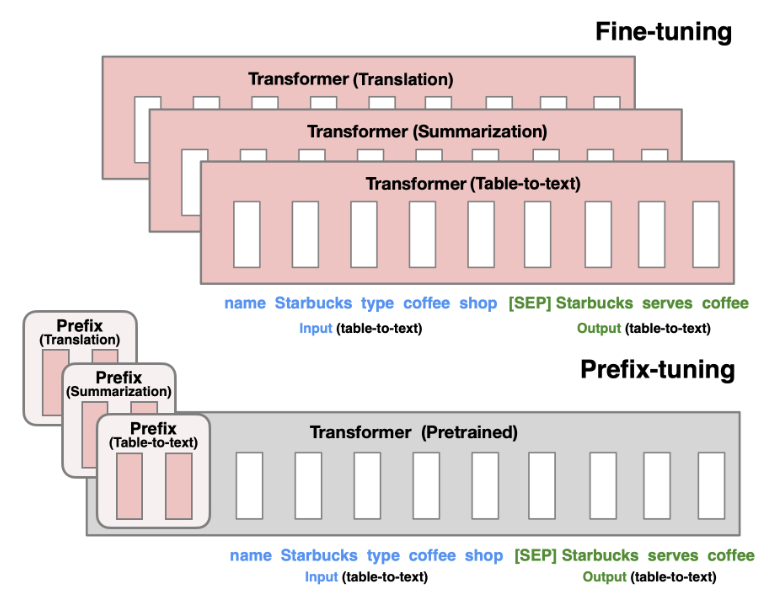
Prefix-Tuning 논문을 요약하며, 대형 언어모델의 파라미터를 고정한 채 작은 연속적 프롬프트(prefix)만 최적화하는 효율적인 튜닝 방법을 설명합니다. 전체 파인튜닝 대비 적은 파라미터로 경쟁력 있는 성능을 내는 원리와 장점을 다룹니다.
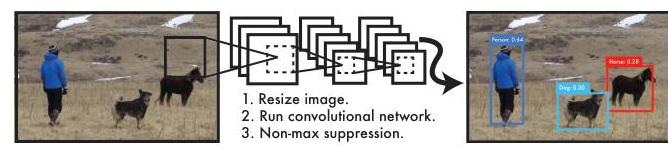
실시간 객체 탐지의 시대를 연 YOLO(You Only Look Once) 논문을 요약합니다. 전체 이미지를 단일 신경망에 한 번만 통과시켜 객체의 경계 상자와 클래스를 동시에 예측하는 혁신적인 통합 아키텍처의 원리와 성능을 설명합니다.
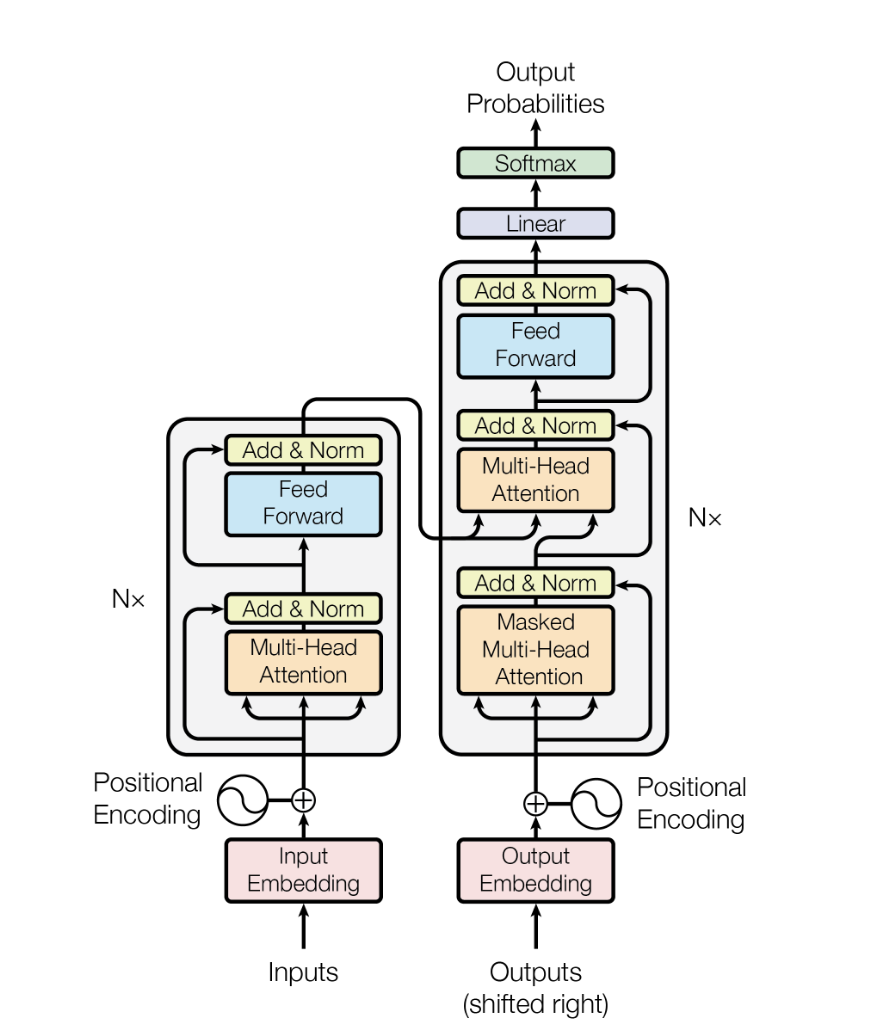
'Attention Is All You Need'는 RNN을 버리고 셀프 어텐션만으로 시퀀스를 처리하는 Transformer 아키텍처를 제안한 2017년 논문입니다. 기계 번역에서 당시 SOTA를 경신했고, 이후 BERT·GPT·Claude를 포함한 거의 모든 대형 언어 모델의 기반이 되었습니다.