베이징대학교 MSALab과 ByteDance가 만든 멀티모달 확산 언어 모델. 자기회귀가 영역을 하나씩 순차로 캡셔닝하는 한계를 깨고, 한 번의 디노이징으로 여러 영역을 동시에 설명합니다. 구조적 어텐션 마스킹으로 영역 간 간섭을 막으면서 최대 3.5배 빠른 추론을 보입니다.
태그: 멀티모달
76개의 게시물
-

-

현재 화면만 봐서는 다음 수를 알 수 없는 상황에서 MLLM이 얼마나 잘 기억하고 행동하는지 측정합니다. Matching Pairs 카드 게임과 3D 미로 탐색으로 구성된 RNG-Bench의 결과는 솔직합니다.
-

단일 시각 토크나이저 HYDRA-XTok으로 이미지·비디오 이해·생성·편집을 하나의 모델에 통합한 네이티브 멀티모달 프레임워크. 튜블릿 인과 어텐션과 계층적 패치파이, 잠재 공간 기반 STI 편집으로 다섯 가지 태스크를 단일 7B 모델에서 처리합니다.
-
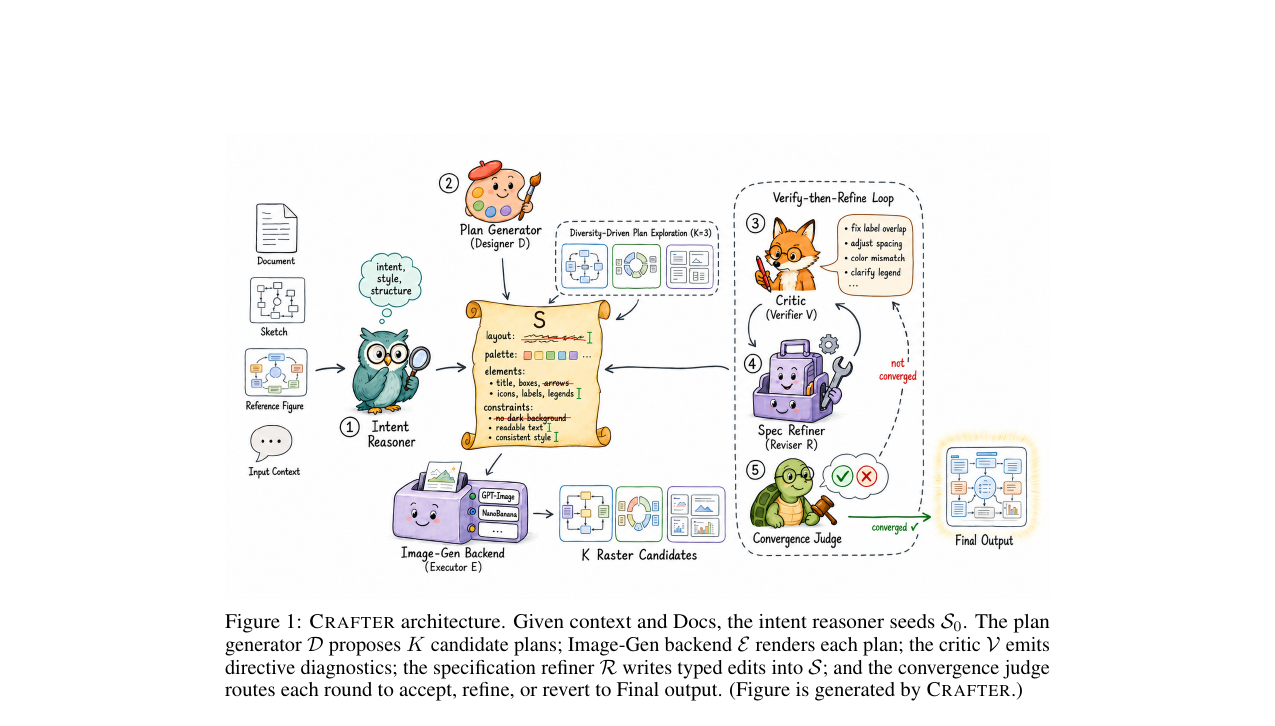 Crafter - A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs 2026-06-16
Crafter - A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs 2026-06-16과학 논문 피겨 생성에서 더 강한 생성 모델이 아닌 더 나은 오케스트레이션이 답이라는 주장입니다. 멀티에이전트 하네스로 3가지 피겨 유형, 4가지 입력 조건을 단일 구조로 처리합니다.
-
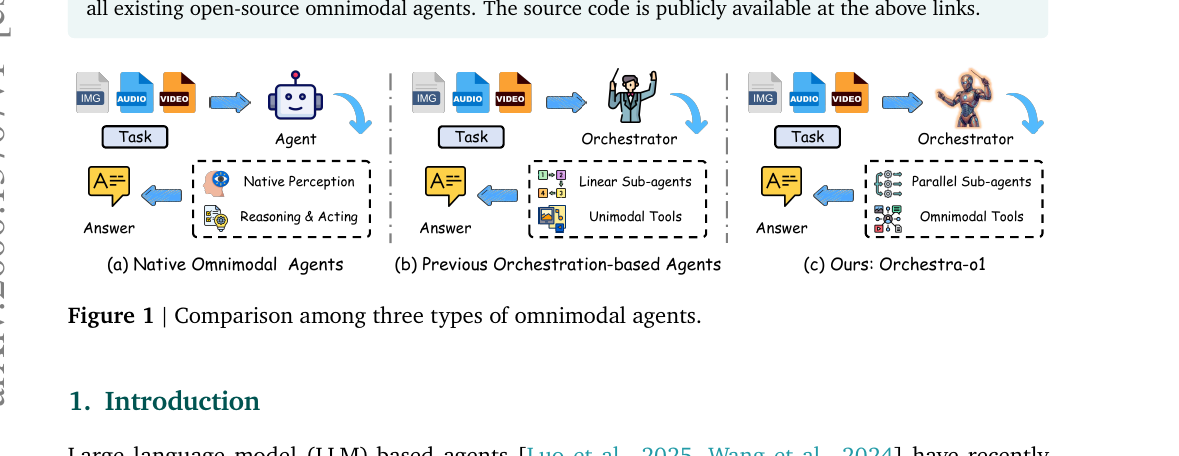 Orchestra-o1 - Omnimodal Agent Orchestration 2026-06-16
Orchestra-o1 - Omnimodal Agent Orchestration 2026-06-16CUHK·LIGHTSPEED·PKU·THU 공동 연구팀이 제안한 Orchestra-o1은 텍스트·이미지·오디오·영상을 넘나드는 복합 태스크를 오케스트레이터-서브에이전트 구조로 처리하는 옴니모달 에이전트 프레임워크입니다. OmniGAIA 벤치마크에서 Gemini-3-Pro 대비 10.3%p 높은 72.8%를 기록하며 SOTA를 세웠고, 오픈소스 모델 Orchestra-o1-8B도 30.0%로 이전 최고 기록을 9.2%p 앞질렀습니다.
-

추론 과정을 텍스트 대신 이미지 공간에 그려 넣는다. 수식·그래프를 시각적 스크래치패드로 쓰면 텍스트 추론과 동등한 정확도를 유지하면서 토큰을 평균 28.57% 아낄 수 있다는 논문.
-
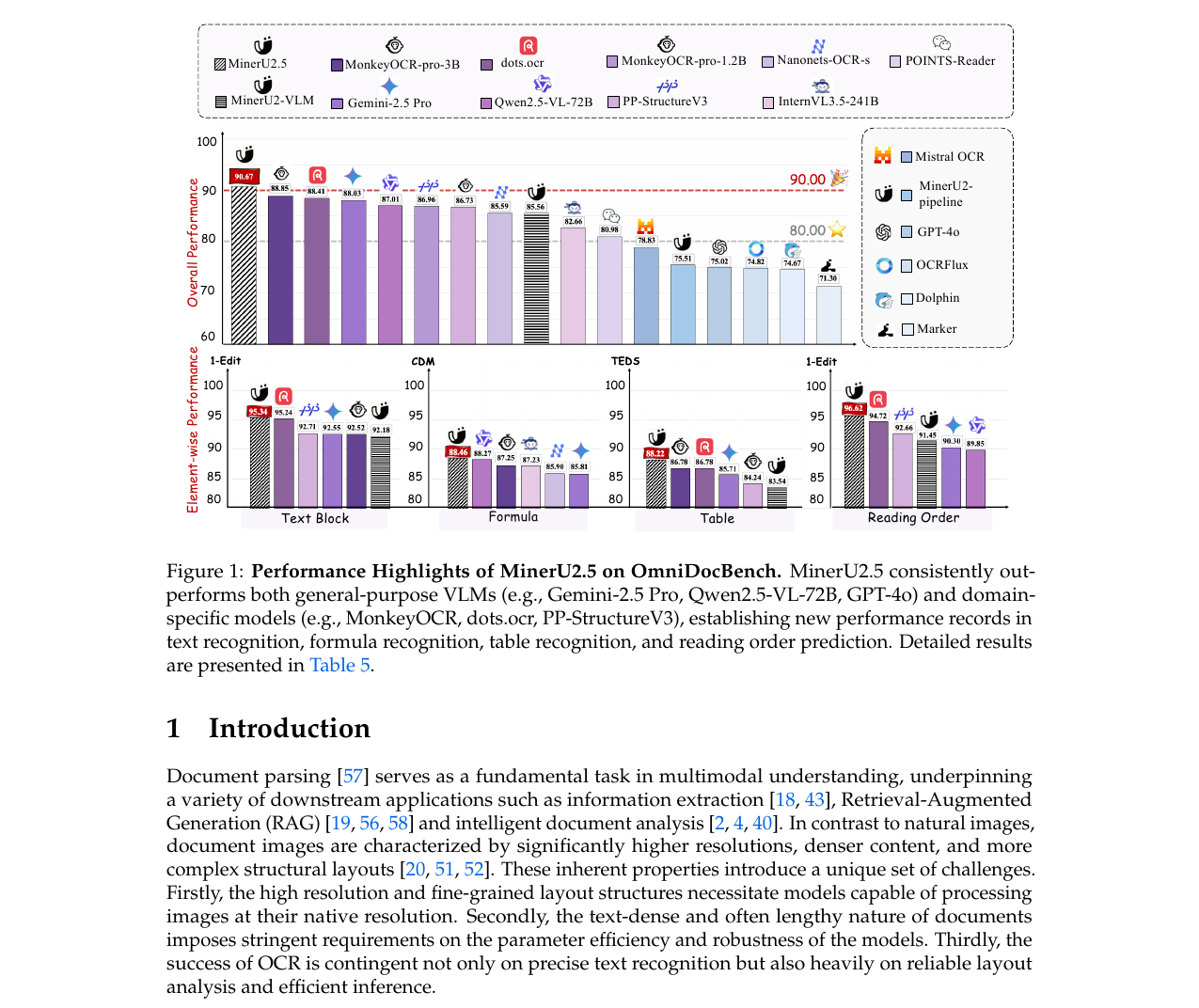
1.2B 파라미터로 고해상도 문서의 정확한 파싱을 달성한 MinerU2.5의 2단계 분리 아키텍처와 데이터 엔진을 분석합니다.
-
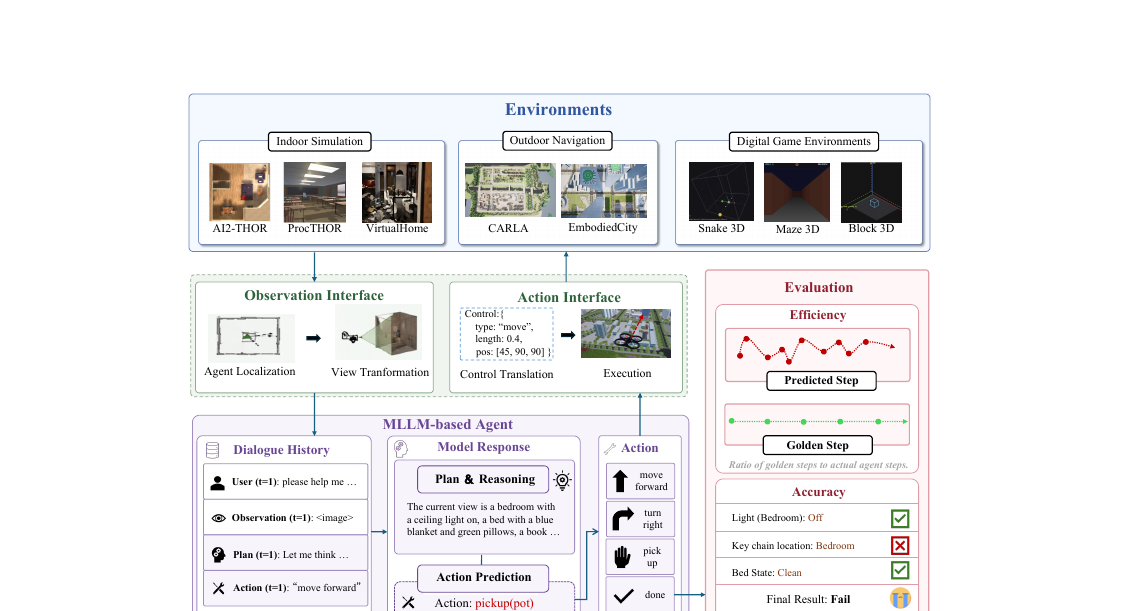 SpatialWorld - Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks 2026-06-10
SpatialWorld - Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks 2026-06-10멀티모달 에이전트가 실제 공간을 상호작용하며 이해하는 능력을 8개 시뮬레이터와 760개 과제로 측정한 SpatialWorld. 정적 VQA를 넘어 능동 탐색을 보게 했더니 최강 GPT-5조차 평균 성공률 17.4%에 그쳤고, 더 최신인 GPT-5.4는 조급하게 멈추는 바람에 오히려 뒤처졌습니다.
-
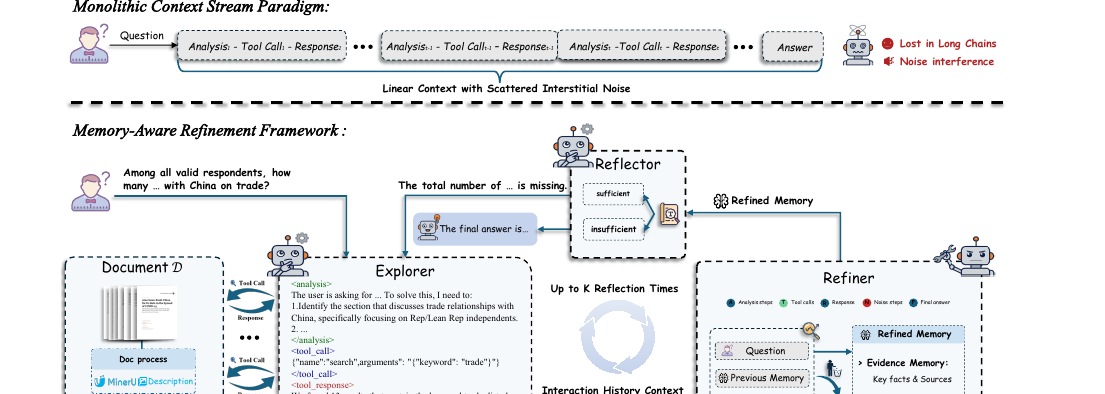
수십에서 수백 페이지짜리 멀티모달 문서를 읽는 QA 에이전트가 상호작용 기록을 하나의 거대한 맥락에 계속 쌓다 보면 정작 핵심 증거가 노이즈에 묻힙니다. 톈진대 연구진의 MARDoc은 탐색·정제·반성 세 에이전트가 구조화된 메모리(증거 메모리 + 추론 메모리)로 소통하는 루프로 그 문제를 풉니다. 오픈 Qwen3-30B만으로 DocAgent + Claude 3.5 Sonnet과 맞먹고, DocBench에서는 사람 기준선을 넘었습니다.
-
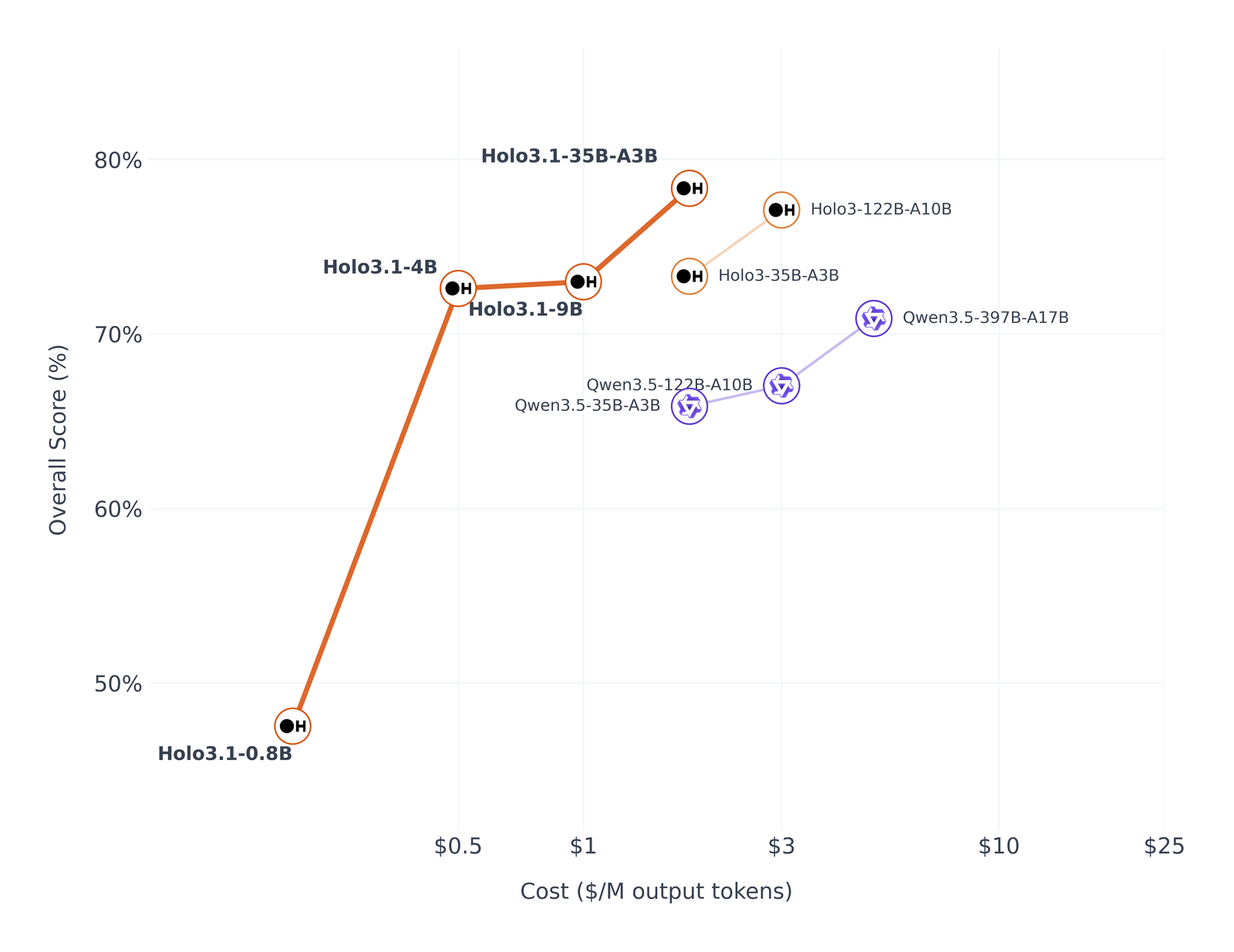 Holo3.1 - Fast and Local Computer Use Agents 2026-06-08
Holo3.1 - Fast and Local Computer Use Agents 2026-06-08화면을 보고 클릭하는 컴퓨터 유즈 에이전트를 클라우드가 아니라 내 기기에서 돌린다. H Company가 Holo3.1을 0.8B부터 35B-A3B까지 확장하고, FP8·NVFP4·Q4 GGUF 양자화 체크포인트로 온디바이스 GUI 자동화를 처음 본격 출하했다.
-
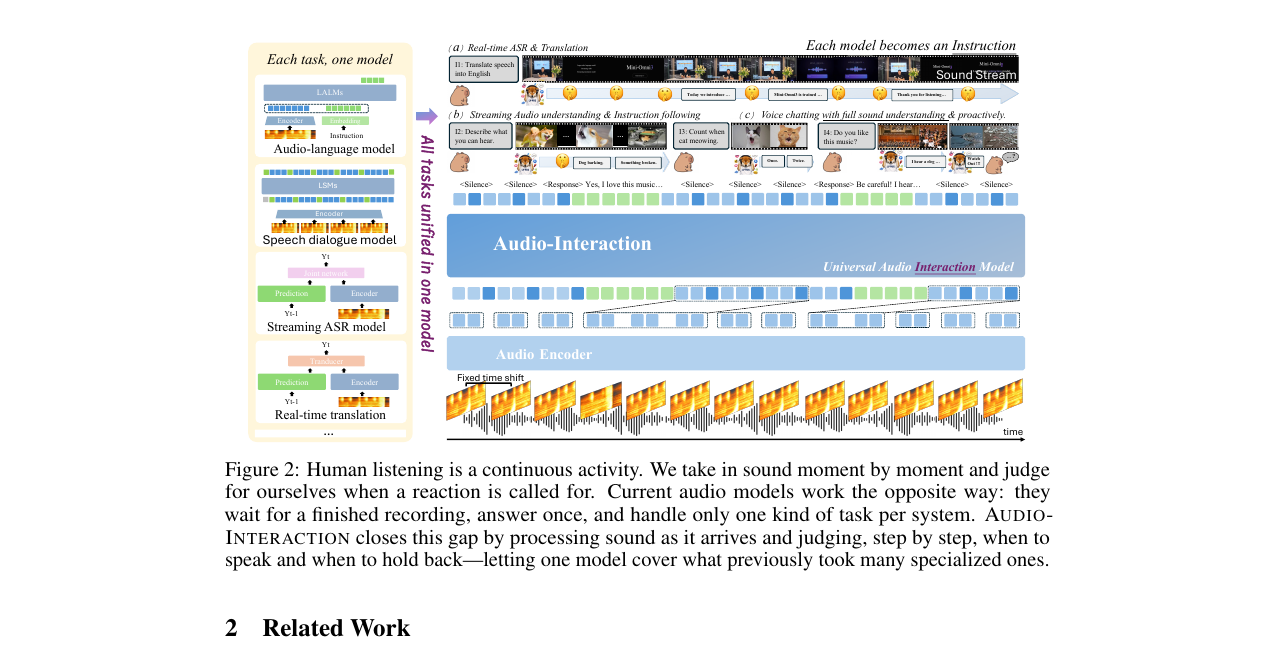 Audio Interaction Model 2026-06-07
Audio Interaction Model 2026-06-07오프라인 오디오 언어모델과 단일 과제 스트리밍 모델을 하나의 always-on 모델로 합친 Audio Interaction Model. 매 청크마다 말할지 침묵할지를 스스로 정하는 perceive-decide-respond 루프와 이를 데이터부터 추론까지 구현한 SoundFlow 프레임워크를 뜯어봅니다.
-
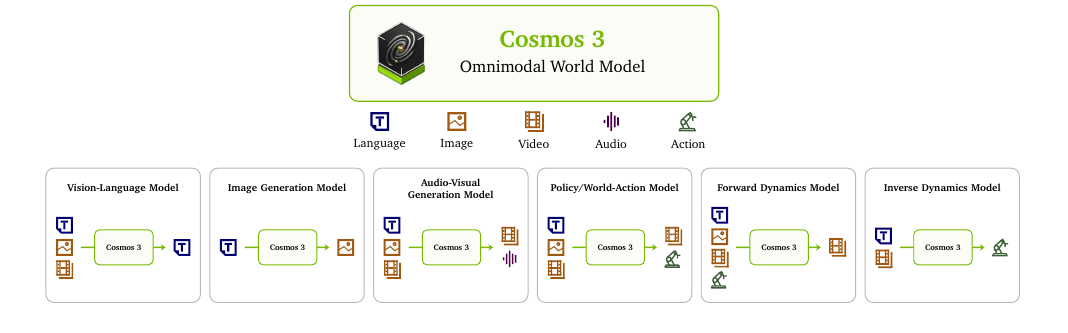
NVIDIA가 공개한 옴니모달 월드 모델 Cosmos 3를 분석합니다. 언어, 이미지, 비디오, 오디오, 행동을 한 Mixture-of-Transformers 구조로 처리하고 생성하며, 자기회귀 추론 타워와 확산 생성 타워를 결합해 비전언어모델, 비디오 생성기, 월드 시뮬레이터, 월드 액션 모델을 하나의 백본으로 흡수합니다.
-
 밍유 리우 2026-06-06
밍유 리우 2026-06-06NVIDIA Research 부사장이자 Cosmos Lab을 이끄는 연구자. Physical AI를 위한 월드 파운데이션 모델과 생성 모델 연구의 책임자입니다.
-
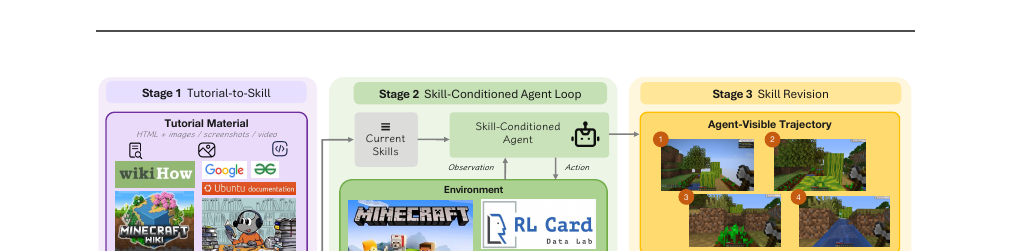
인터넷에는 사람을 위한 방법 안내가 넘쳐납니다. 위키하우, 게임 위키, 우분투 문서 같은 것들이죠. 문제는 이 가이드가 멀티모달이고 노이즈가 많고 사람이 실행한다고 가정한다는 점입니다. MMG2Skill은 이런 사람용 가이드를 에이전트가 실행할 수 있는 SKILL.md 절차로 증류하고, 실행 궤적의 진단으로 스스로 고쳐 나가는 폐루프 프레임워크입니다.
-
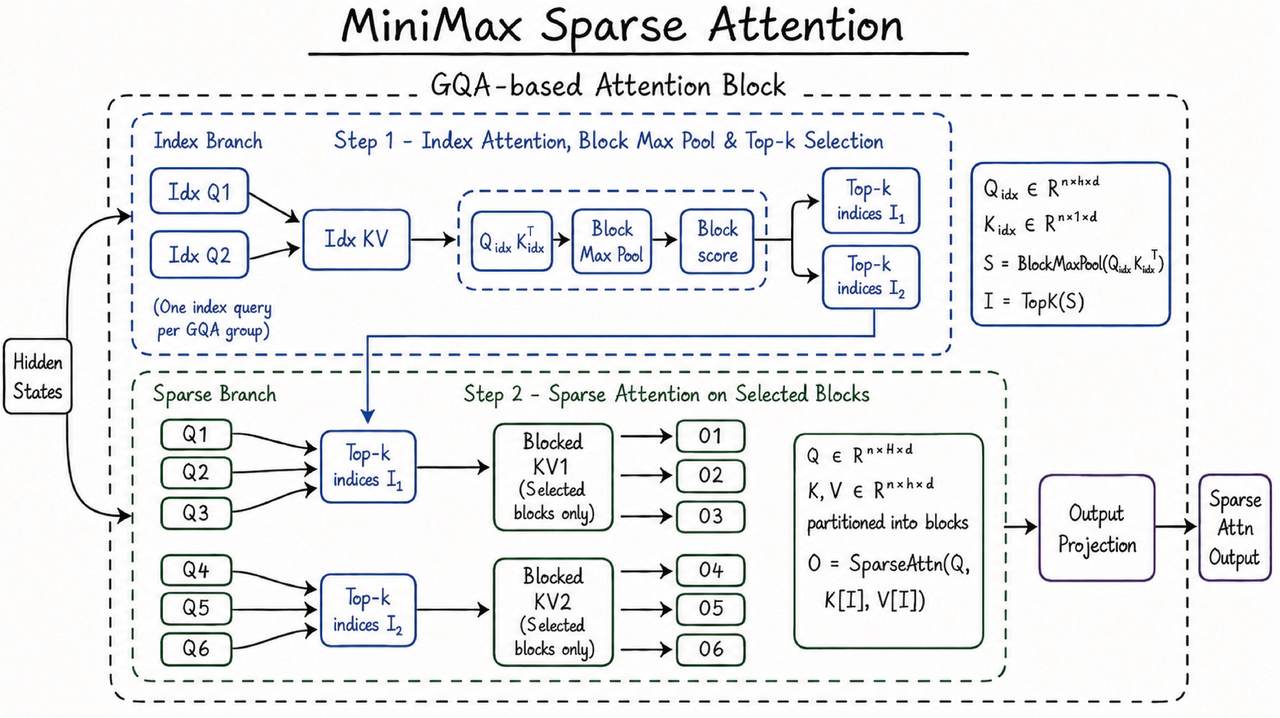 MiniMax M3 - 오픈웨이트 프런티어 모델 2026-06-04
MiniMax M3 - 오픈웨이트 프런티어 모델 2026-06-04프런티어 코딩과 1M 토큰 컨텍스트, 네이티브 멀티모달을 한 모델에 담은 첫 오픈웨이트 모델 MiniMax M3를 MSA 희소 어텐션 중심으로 뜯어봅니다
-
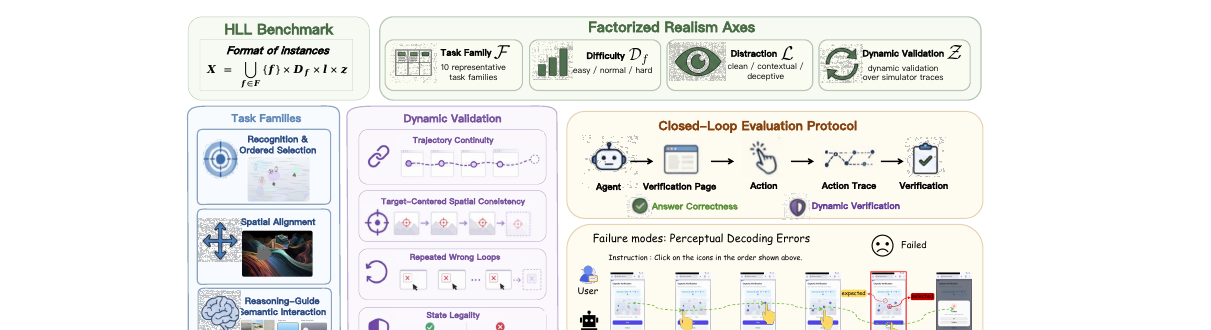
멀티모달 에이전트가 사람을 대신해 인터페이스를 조작하는 시대에, CAPTCHA는 봇과 사람을 가르는 마지막 검증 관문입니다. HLL은 이 관문을 에이전트가 넘을 수 있는지 정답 인식이 아니라 실제 상호작용으로 측정하는 벤치마크입니다. 8개 프런티어 에이전트는 깨끗한 화면에서는 곧잘 풀지만, 현실적인 방해와 행동 궤적 검증이 들어오면 무너집니다.
-
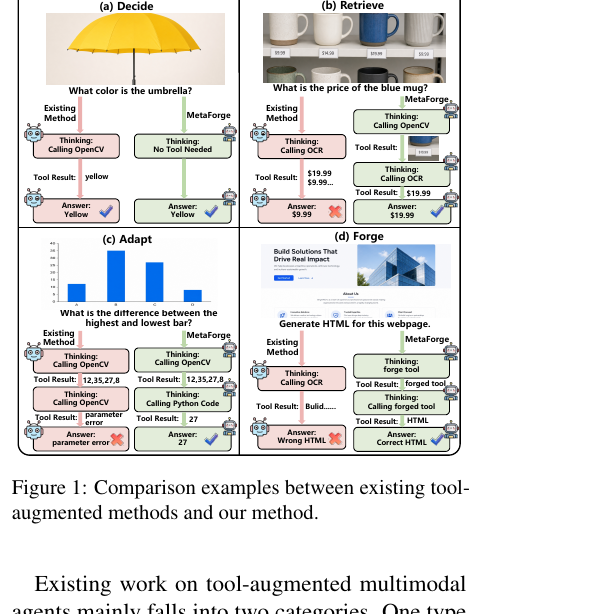 MetaForge - A Self-Evolving Multimodal Agent that Retrieves, Adapts, and Forges Tools On Demand 2026-06-04
MetaForge - A Self-Evolving Multimodal Agent that Retrieves, Adapts, and Forges Tools On Demand 2026-06-04멀티모달 에이전트는 도구를 써서 복잡한 추론을 풀지만, 미리 정해진 도구 목록은 처음 보는 상황에 일반화되지 못하고 도구를 마구 부르면 비용과 오류만 늘어납니다. MetaForge는 에이전트의 행동을 Decide, Retrieve, Adapt, Forge 네 단계로 나누고, 도구를 언제 쓸지와 도구를 어떻게 늘릴지를 강화학습으로 함께 배우게 합니다.
-
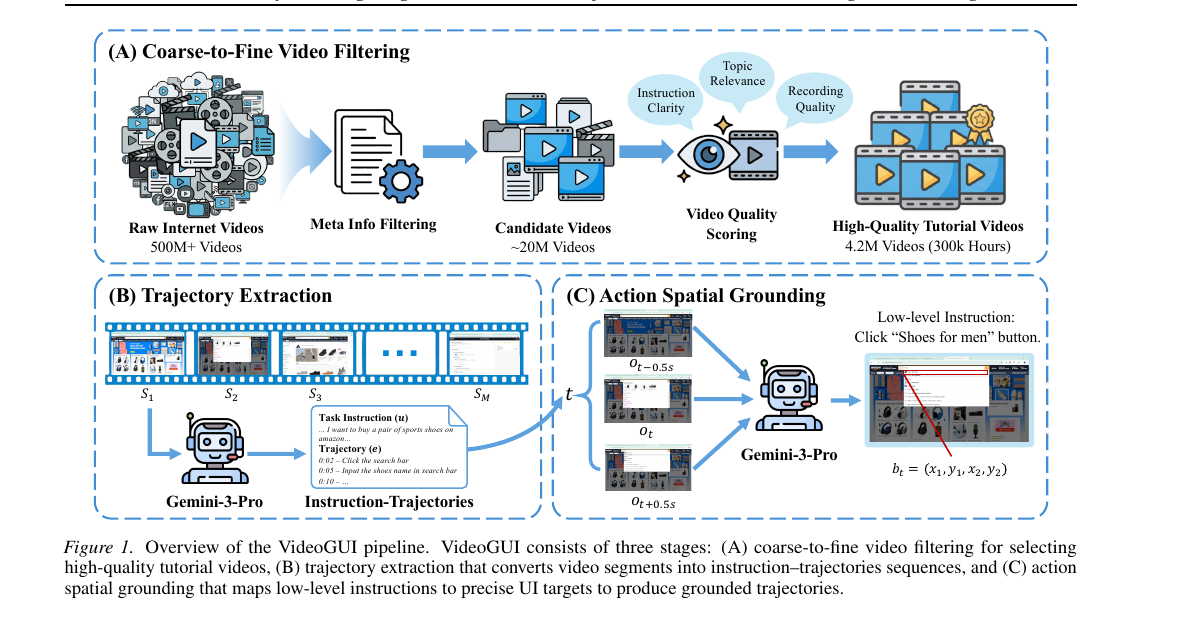 Video2GUI - Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining 2026-05-22
Video2GUI - Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining 2026-05-22라벨 없는 유튜브 비디오 5억 개에서 GUI 인터랙션 트래젝토리 1,200만 개를 자동 추출해 만든 WildGUI 데이터셋과 그 추출 파이프라인 Video2GUI. Qwen2.5-VL·MiMo-VL를 사전학습하면 ScreenSpot-Pro·OSWorld-G에서 15~20점 상승, 온라인 OSWorld·AndroidWorld까지 일관된 개선이 나타납니다.
-

학습 없이 기성 비디오 디퓨전 모델로 1,000프레임짜리 긴 영상을 생성하는 MIGA. FIFO-Diffusion 계열의 train-inference gap을 zigzag·unified 두 단계로 좁히고, self-reflection + long-range frame guidance로 장기 일관성을 끌어올려 VBench·NarrLV에서 SOTA를 찍습니다.
-
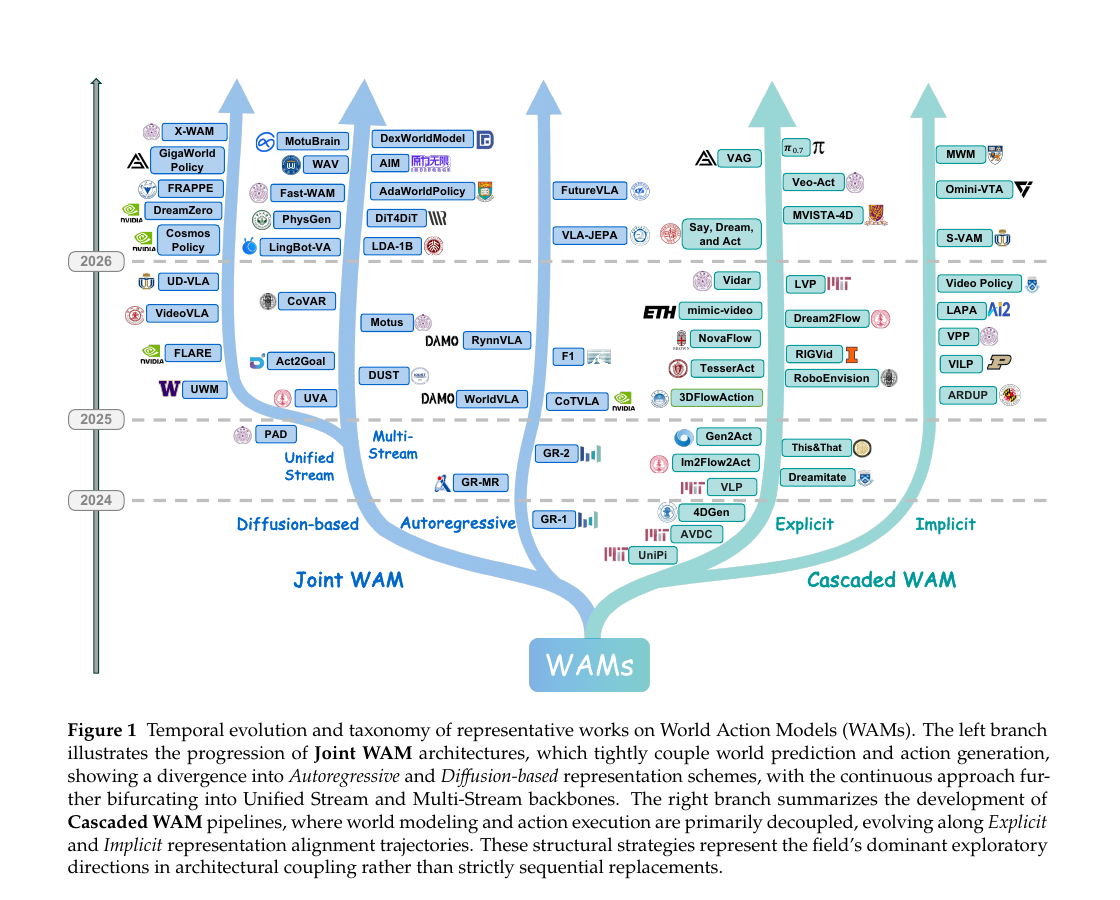
Vision-Language-Action 모델이 학습하는 reactive observation-to-action 매핑과 World Model 계열의 예측적 dynamics 모델링이 별도의 흐름으로 흘러오다가 한 모델 안에서 합쳐지기 시작했습니다. Fudan 신뢰성 임바디드 AI 연구소가 이 합류 지점을 World Action Models로 명명하고 정의·아키텍처·데이터·평가의 네 축으로 정리한 첫 서베이를 살펴봅니다.
-
라마를 버리고 Muse Spark를 꺼낸 메타 2026-05-14
Meta가 2026년 4월 Llama 오픈소스 노선을 사실상 끝내고, Meta Superintelligence Labs의 첫 사유 모델 Muse Spark를 공개했습니다. Yann LeCun이 떠나고 Alexandr Wang이 들어온 자리에서 만든 첫 결과물, Llama 4 Maverick 대비 1자릿수 이상 적은 컴퓨트로 같은 성능을 낸다고 주장하는 모델, 그리고 Apollo Research가 '관측한 모델 중 가장 evaluation awareness가 높다'고 평가한 안전성 이슈까지 전수 정리했습니다.
-
 SenseNova-U1 - Unifying Multimodal Understanding and Generation with NEO-unify Architecture 2026-05-14
SenseNova-U1 - Unifying Multimodal Understanding and Generation with NEO-unify Architecture 2026-05-14SenseTime이 Apache 2.0으로 공개한 SenseNova-U1은 VAE도 vision encoder도 들어내고 픽셀과 단어를 한 트랜스포머 안에서 같이 학습합니다. dense 8B와 30B-A3B MoE 두 변종으로 understanding-only VLM 수준 인지에 X2I 생성을 32배 압축률로 동시에 수행하는, native unified multimodal의 first-principle 결정판입니다.
-
WRING - 회전 기반 디바이어싱으로 두더지 잡기 딜레마 풀기 2026-05-05
WRING은 모델 구조 훼손을 최소화하고 두더지 잡기 딜레마를 완화합니다. 재학습이 불필요해 실용적입니다.
-
Meta Muse Spark 2026-04-11
Meta Superintelligence Labs의 첫 모델 Muse Spark. 네이티브 멀티모달 추론, 비주얼 CoT, 멀티에이전트 오케스트레이션을 갖춘 Meta의 AI 전략 전환점.
-
Llama 4 Scout 2026-04-11
Meta의 Llama 4 Scout — 17B 파라미터 오픈소스 멀티모달 MoE 모델. 단일 H100 GPU에서 10M 토큰 컨텍스트, Gemma 3와 Gemini Flash를 능가하는 성능.
-
비전-언어 모델 2026-04-10
이미지와 텍스트를 동시에 처리하여 시각적 내용에 대한 자연어 질의응답을 수행하는 멀티모달 모델
-

벌써 4.5가 나온다구요? 두 달 정도밖에 안 지났습니다. 아직 4.5는 테크니컬 리포트가 없습니다. 대신 4.0 테크니컬 리포트를 가져왔습니다. 2K 해상도 이미지를 1.4~1.8초 만에 생성하며, T2I 생성과 이미지 편집 작업을 단일 모델에서 공동 학습합니다. 특히 복잡한 텍스트 렌더링, 다중 이미지 참조, 인컨텍스트 추론 생성 등 기존 모델들이 취약했던 영역에서 강점을 보입니다.
-
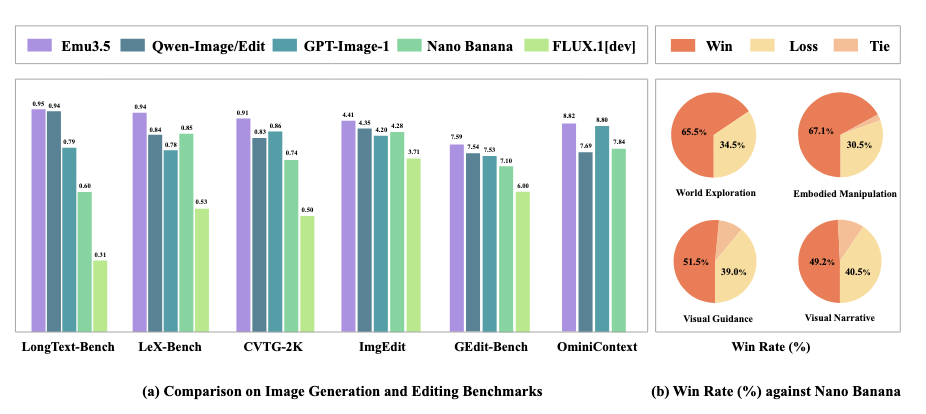
최신 멀티모달 모델의 화두는 세계를 이해하고 행동하는 모델입니다. BAAI(Beijing Academy of Artificial Intelligence)가 최근 공개한 Emu3.5는 이런 흐름을 타고 비전과 언어를 동시에 예측하는 '멀티모달 월드 모델'을 표방하며 장시간 순차적 추론과 실제 로봇 조작까지 가능하게 한다고 주장합니다.
-
 DeepSeek-OCR Contexts Optical Compression 2025-10-24
DeepSeek-OCR Contexts Optical Compression 2025-10-24긴 텍스트를 이미지로 변환해 LLM 컨텍스트를 압축하는 DeepSeek-OCR을 소개합니다. 10배 압축에서 97% 정확도를 유지하며, 광학적 컨텍스트 압축이라는 새 발상을 제시합니다.
-
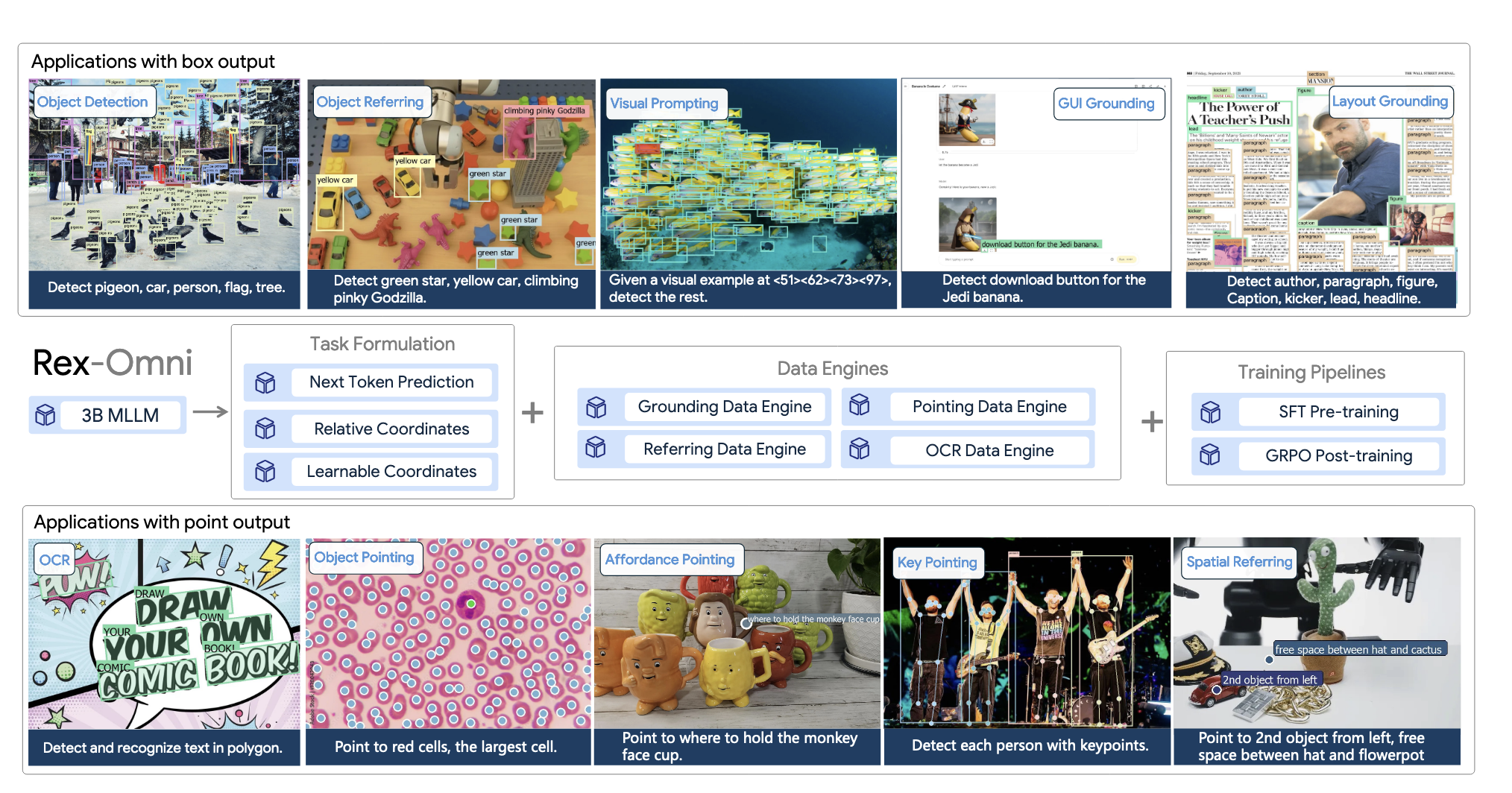 Detect Anything via Next Point Prediction 2025-10-22
Detect Anything via Next Point Prediction 2025-10-22멀티모달 LLM으로 객체 탐지에 도전한 모델입니다. Qwen과 대규모 영상 데이터로 학습해 각종 탐지 벤치마크에서 높은 성능을 보입니다.
-
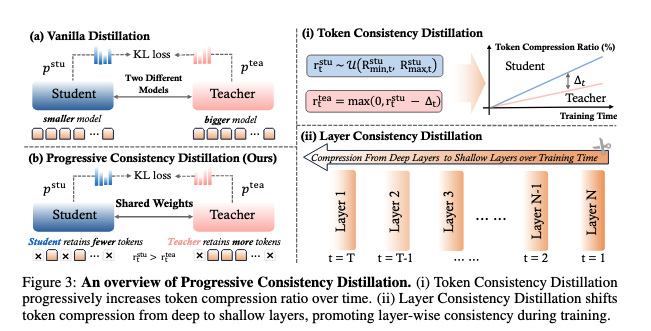
더 효율적인 멀티모달 LLM을 위한 다양한 시도가 이어집니다. 이미지와 텍스트를 동시에 다루는 모델은 이미지 처리에서 계산 비용이 많이 들어갑니다. 이 문제를 해결하기 위해 시각 토큰을 압축하는 방법이 중요합니다. 효율적인 시각 토큰 압축을 위한 학습 프레임워크를 제안한 논문을 소개합니다.
-

텐센트의 Hunyuan3D Studio 논문을 요약합니다. 단일 이미지나 텍스트에서 게임 엔진에 바로 사용할 수 있는 3D 에셋을 생성하는 7단계 AI 파이프라인을 설명합니다. 지오메트리 생성, UV 언래핑, 텍스처링, 애니메이션까지 전 과정을 자동화한 기술을 다룹니다.
-
Meta가 2026년 4월 공개한 첫 사유 AI 모델, Llama 라인업을 대체하는 Meta Superintelligence Labs의 첫 결과물
-
상하이 인공지능 연구소(SAIL) 포스닥. 멀티모달 LLM 평가 전문. MMBench·VLMEvalKit·RNG-Bench 주요 저자.
-
싱가포르국립대학교 NExT++ 연구소 공동 디렉터. 멀티모달 기반 모델, 추천 시스템, 신뢰 가능한 AI 분야 석학.
-
알리바바 AMAP의 Senior Director로 멀티모달·생성·기반 모델 라인을 이끄는 시니어 연구자이며 FairNAS·Twins·CPVT 등 영향력 큰 논문의 1저자
-
저장대 추스 석좌교수이자 인공지능연구원 원장. 멀티미디어 검색·머신러닝·지식그래프 연구
-
CUHK MMLab 교수. 컴퓨터비전·멀티모달 학습·Embodied AI 전공. ACE-Ego-0 교신저자.
-
Google DeepMind의 멀티모달 대규모 언어 모델, 장문맥·추론 강화
-
Alibaba Qwen2.5 시리즈의 대규모 멀티모달 비전-언어 모델
-
NTU S-Lab·MMLab@NTU를 이끄는 generative AI·멀티모달 연구자. SenseNova-U1 Senior Project Lead.
-
홍콩 이공대학교 NLP 교수. 텍스트 요약·질의응답·다중 문서 추론 연구로 H-Index 52, 인용 13,000회+를 쌓은 시니어 연구자.
-
Xiaomi LLM-Core 팀의 시니어 멤버로, MiMo 시리즈(MiMo-7B, MiMo-VL, MiMo-V2-Flash)의 핵심 기여자이자 학계와의 협업을 이끄는 코레스폰딩 저자
-
칭화대 College of AI 박사과정 연구자(ZenoMind AI 겸). 대규모 추론 모델, AI 에이전트, 통합 모델을 연구하며 특히 멀티모달 공간 과제에 집중. Spider2-V 공저자.
-
NVIDIA Research Taiwan Staff Research Scientist. Vision+X 멀티모달 AI 전문가로 SpatialClaw 논문의 시니어 저자.
-
TwelveLabs 공동창업자 겸 CEO. 영상 이해 멀티모달 AI 기업가.
-
UCLA CS Associate Professor, Amazon Scholar, VisualBERT·GLIP 등 비전-언어 모델과 NLP 편향 연구로 알려짐
-
베이징대학교 교수, MSALab(Multimedia Semantic Analytics Lab) 책임, 미디어 지능 컴퓨팅·멀티모달·확산 모델 연구. PerceptionDLM 교신저자
-
난양공대(NTU) 연구자. Mini-Omni 계열 오디오 언어모델의 핵심 저자로 실시간 음성 상호작용 모델을 연이어 내놓고 있습니다.
-
KAIST 전기및전자공학부 교수. 멀티모달·말하는 얼굴 생성·시청각 AI 연구자.
-
CUHK CSE 박사과정. LLM, 멀티모달 AI, 에이전트 시스템 전공. Orchestra-o1 공동 1저자.
-

USTC 자동화학과 정교수이자 컴퓨터 비전·대규모 멀티모달 모델 연구 그룹 지도교수. OmniNFT의 교신 저자로 [[장궈후이]]·[[위후]] 등 1저자 학생들의 시각 생성 + RL 라인을 총괄.
-
UIUC CS 박사과정. 과학 논문 피겨 자동 생성 연구. Crafter 제1저자.
-
싱가포르국립대학교(NUS) Show Lab 소속, MeissonFlow Research 리드. 마스크드 생성 모델·통합 멀티모달 생성 연구. Muddit·Meissonic 저자
-
2021년 설립된 중국 AI 스타트업. MiniMax-Text-01, M1, M2, M3 등 대형 멀티모달 언어 모델과 1M 토큰 장문 컨텍스트 기술로 알려져 있습니다.
-

OpenAI 기술 스태프. CLIP과 Whisper의 핵심 저자로 대규모 멀티모달 딥러닝을 이끄는 연구자.
-
홍콩중문대(CUHK) 오디오 생성 연구자. 범용 오디오 생성 파운데이션 모델 UniAudio의 1저자로, 음성·음향·음악·노래를 하나의 LLM으로 생성하는 흐름을 열었습니다.
-
CUHK CSE Choh-Ming Li 석좌교수. 의료 AI, 컴퓨터 비전, VR/XR 전공. Orchestra-o1 교신저자.
-
베이징대학교 소속, ByteDance 협업 멀티모달 연구자. PerceptionDLM 공동 1저자, Sa2VA 공저자
-
칭화대 CS 박사과정. TsinghuaNLP 소속. 데이터 중심 NLP, LLM 할루시네이션 연구. Crafter 공동 1저자.
-
JD.COM 산하 AI 연구 조직. Vision and Multimodal Lab을 [[두안난]] 디렉터가 이끌고 있으며, 비전·멀티모달 파운데이션 모델과 비디오 생성 라인을 외부 대학(USTC 등)과 공동 연구.
-
Google DeepMind의 멀티모달 네이티브 AI 모델 시리즈
-
홍콩 이공대학교 NLP 그룹 박사 연구원. 멀티모달 추론 효율화를 주제로 연구하며 Optical Reasoning(2026)의 제1저자.
-
난징대학 소속 연구자로 HYDRA-X 통합 멀티모달 모델의 공동 제1저자이며 시각 토크나이저와 멀티모달 생성 연구에 기여
-
SenseTime Research의 spatial intelligence·평가 인프라 리드. SenseNova-SI·EASI 라인을 이끕니다.
-
비전 기반 SQL 질문응답 벤치마크, 텍스트-이미지-테이블 결합
-
SenseTime·NEO·EVE 계열을 이끈 encoder-free vision-language 모델 연구자. SenseNova-U1의 Project Lead.
-
알리바바 AMAP의 비디오 생성 라인 project lead로 MACE-Dance·S²-Guidance·VMBench·Omni-Effects 등 train-free·평가 작업을 묶어 이끄는 연구자
-
중국과학원(CASIA)/중관촌학원 소속 박사과정생으로 뉴로모픽 컴퓨팅·컴퓨터비전·LLM 양자화를 넘나들며 HYDRA-X 통합 멀티모달 모델에서 공동 제1저자로 활약
-
SenseTime Research 디렉터. InternVL·SenseNova 라인의 멀티모달 시스템 엔지니어링을 이끕니다.
-

CUHK 교수·SenseTime 공동창업자·Shanghai AI Lab 핵심 연구자. CUHK MMLab과 OpenMMLab을 이끄는 컴퓨터비전·멀티모달 AI 대가.
-
중국 톈진대(Tianjin University) 연구자. 멀티모달 긴 문서 질의응답과 에이전트 메모리를 연구합니다.
-
Lightricks가 공개한 19B 파라미터 규모의 joint audio-video foundation model. asymmetric dual-stream(비디오·오디오) 구조에 bidirectional cross-attention으로 modality imbalance를 처리. OmniNFT의 backbone으로 사용됨.
-
OpenAI의 멀티모달 대규모 언어 모델, 텍스트·이미지·음성 이해 능력 제공
-
음성 입출력 기반 멀티모달 상호작용 모델, 실시간 음성 대화
-
HKU-NLP 박사과정 연구자로 멀티모달 LLM(MiMo-VL 등)과 LLM-as-a-Judge·In-context Learning 메커니즘 연구를 수행하며 EMNLP 2023 Best Paper 수상자