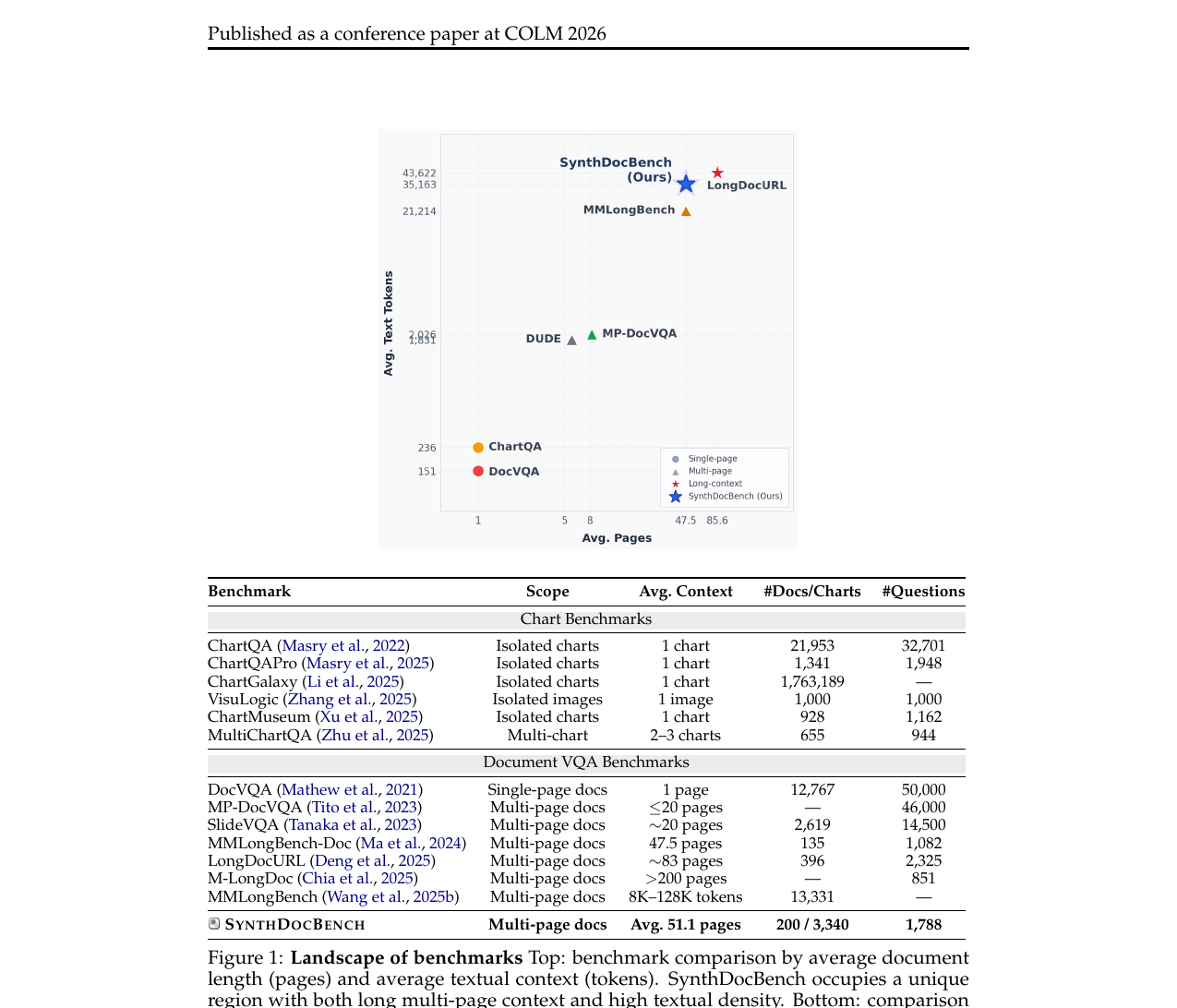
ServiceNow AI가 COLM 2026에서 발표한 긴 문서 시각 이해 벤치마크입니다. 문서 길이, 레이아웃, 모달리티, 질문 유형을 독립 축으로 통제한 합성 문서 200개와 질문 1,788개로 프런티어 VLM 8종을 평가해, 기존 벤치마크가 드러내지 못한 실패 모드 세 가지를 분리해냈습니다.
태그: 벤치마크
68개의 게시물
-
-
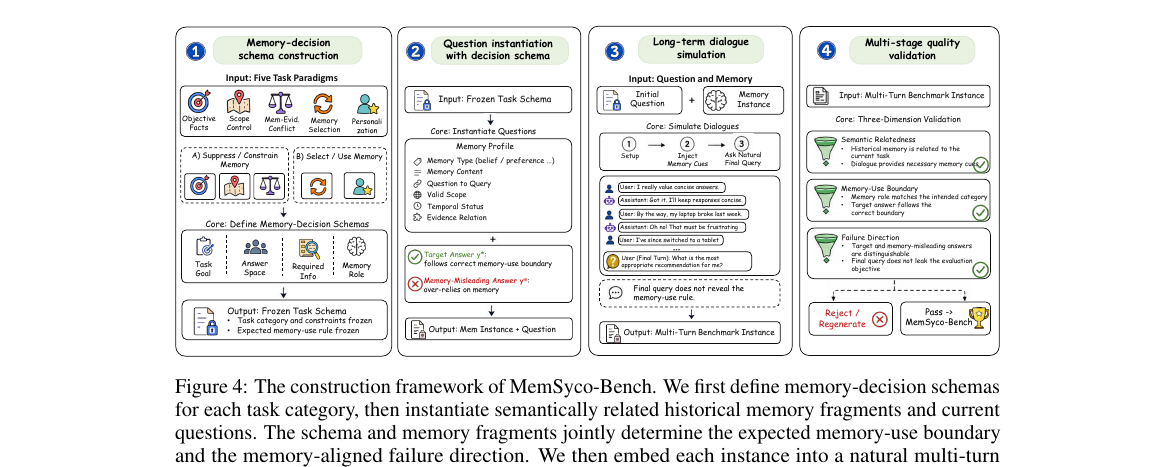
에이전트 메모리 시스템이 저장된 사용자 기억에 무조건 동조하는 '메모리 아첨' 현상을 처음으로 체계화하고, 언제 기억을 무시·제약·활용해야 하는지 판단력을 평가하는 5-태스크 벤치마크 MemSyco-Bench를 제안합니다.
-
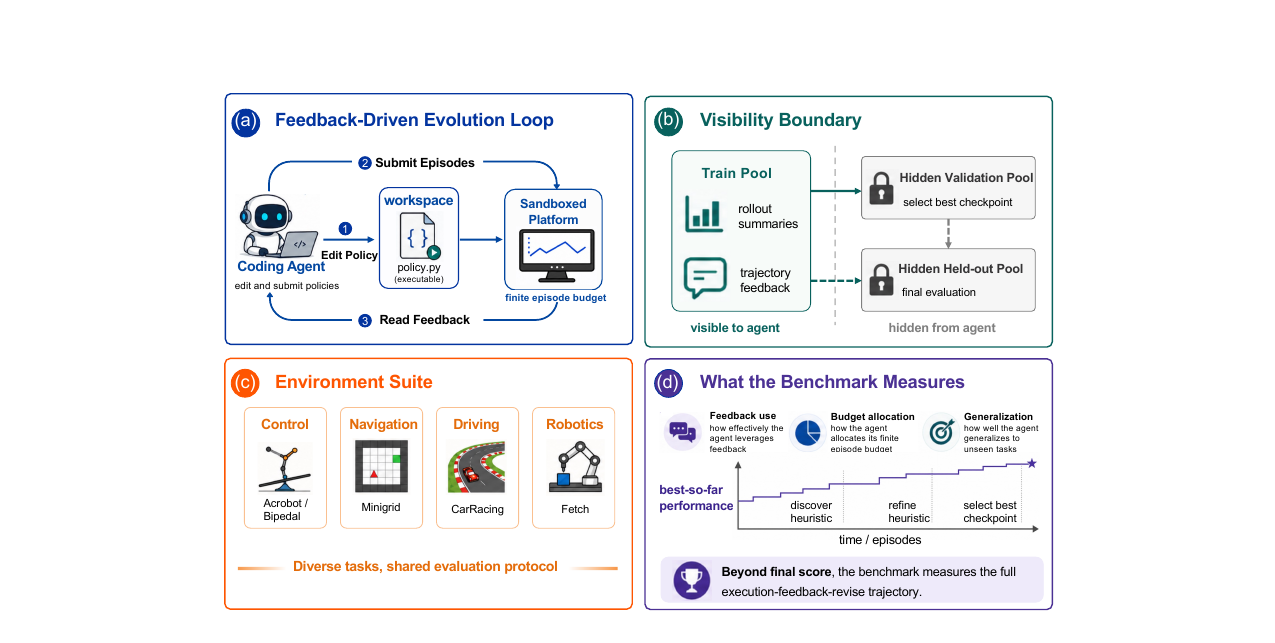
에이전트가 실행 가능한 정책 코드를 128회 에피소드 예산 안에서 반복 개선하는 능력을 측정하는 벤치마크. GPT-5.5가 Core16 16개 환경 모두 Top-2, Claude Opus 4.7이 MiniGrid에서 가장 강한 두각을 보입니다.
-
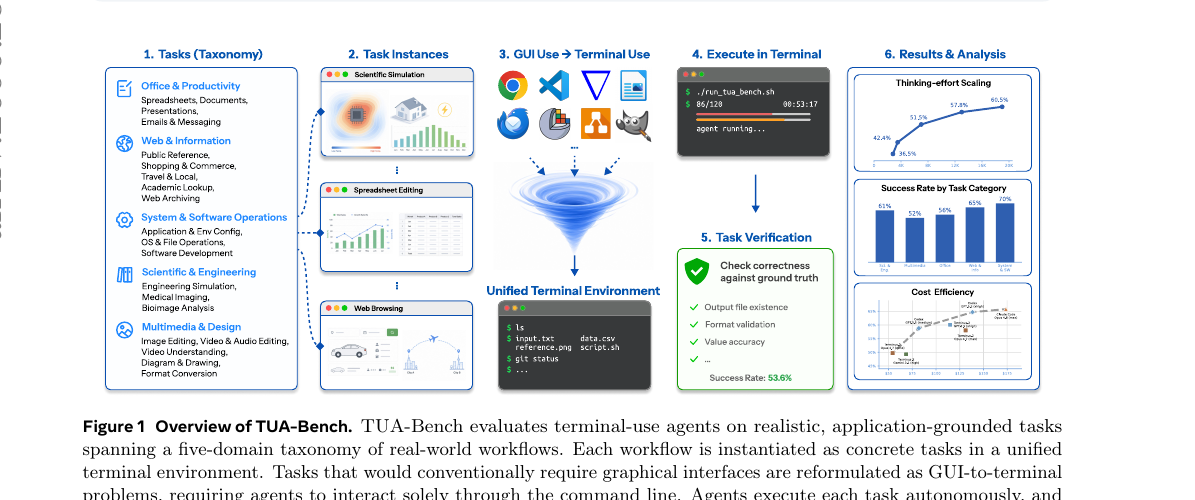
Meta AI, Duke, Stanford 공동 연구팀이 터미널 환경에서 범용 에이전트를 평가하는 120개 태스크 벤치마크를 공개했습니다. 가장 강한 구성(Claude Code + Opus 4.8)도 65.8% 성공률에 그치며, Office와 Multimedia에서 공통적으로 막히는 패턴이 드러납니다.
-
 Gemini 2.5 Pro Deep Think - GPQA Diamond 82 2026-06-28
Gemini 2.5 Pro Deep Think - GPQA Diamond 82 2026-06-28Google DeepMind가 6월 22일 공개한 Gemini 2.5 Pro의 확장 추론 모드. GPQA Diamond 82.4%로 박사급 과학 벤치마크에서 상위권을 기록했으며, 추론 토큰 예산을 늘릴수록 정확도가 올라가는 구조입니다.
-
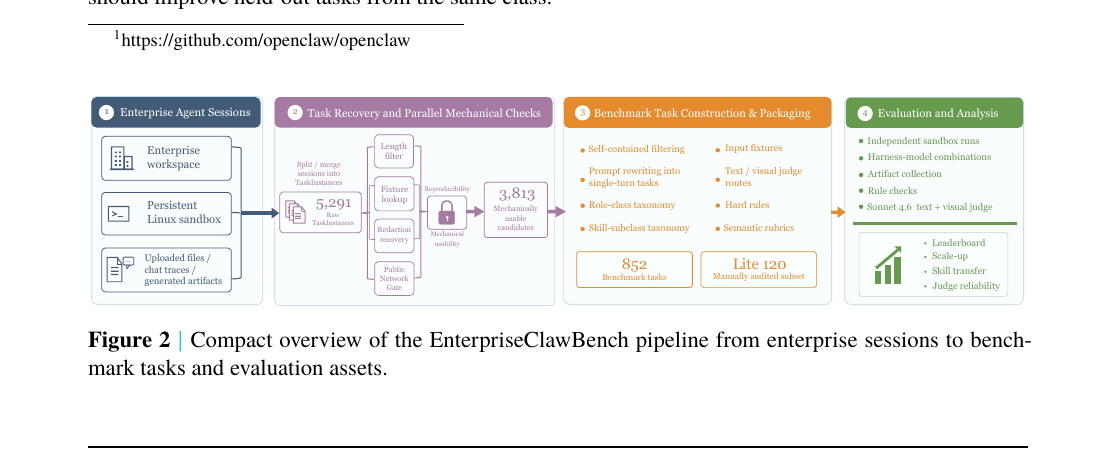
Frontis.AI 팀이 실제 기업 에이전트 세션 5,291건에서 852개 재현 가능 태스크를 추출하는 EnterpriseClawBench를 공개했습니다. 모델 단독이 아닌 하네스-모델 조합을 평가 단위로 삼으며, 최고 점수 0.663으로 기업 에이전트 벤치마크가 아직 포화와 거리가 멀다는 것을 보입니다.
-
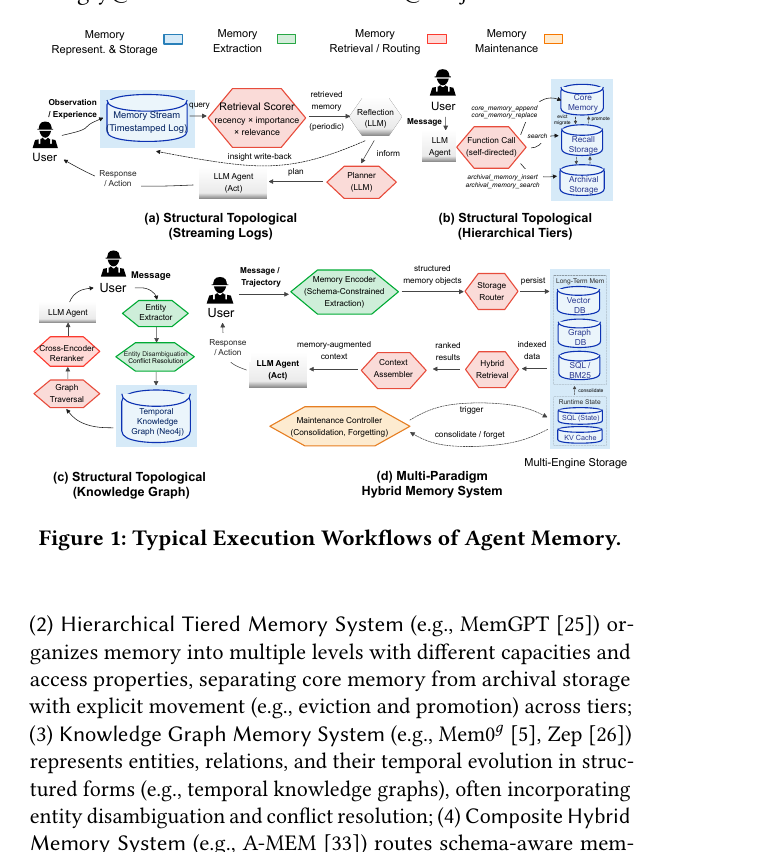
SJTU·Tsinghua·MemTensor 팀이 LLM 에이전트 메모리 시스템 12종을 데이터 관리 관점에서 체계적으로 비교했습니다. 단일 만능 구조는 없으며, 효과는 워크로드에 맞는 추상화 수준에 달려 있음을 9가지 발견으로 정리합니다.
-
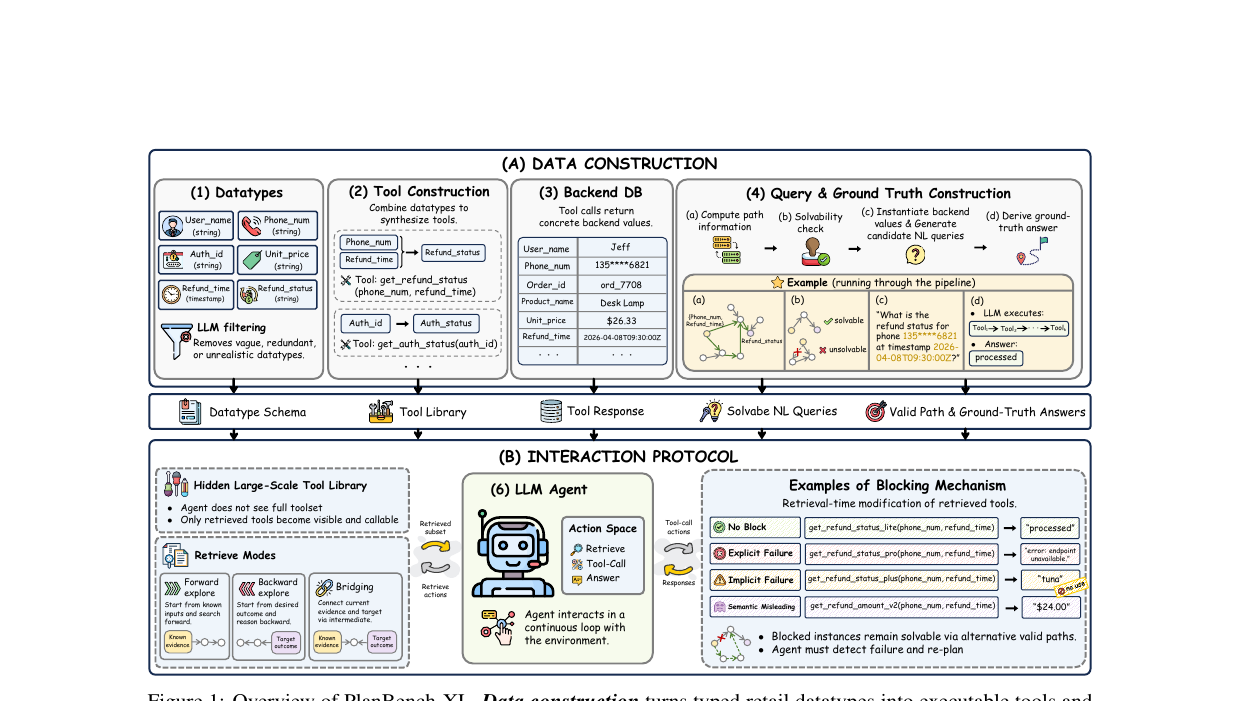
1,665개 도구 생태계에서 LLM 에이전트의 장기 계획 능력을 측정하는 대규모 벤치마크. GPT-5.4는 도구 차단 조건에서 51.9%에서 11.36%로 붕괴하며, 실패의 핵심은 검색 부족이 아니라 이미 가진 도구를 제대로 고르지 못하는 선택 실패였습니다.
-

Godot 엔진에서 코딩 에이전트가 실제로 플레이 가능한 게임을 처음부터 끝까지 만들 수 있는지 측정하는 벤치마크. 15개 장르 140개 태스크, 코드 생성부터 상호작용 검증까지 자동화된 평가 프레임워크입니다.
-
 Agents' Last Exam 2026-06-16
Agents' Last Exam 2026-06-16250명 이상의 산업 전문가가 실제 업무를 그대로 가져온 벤치마크입니다. 55개 직군, 1,490개 태스크를 자동 채점으로 평가하는데, 지금 최고 성능 에이전트의 전체 통과율은 24%에 불과합니다.
-
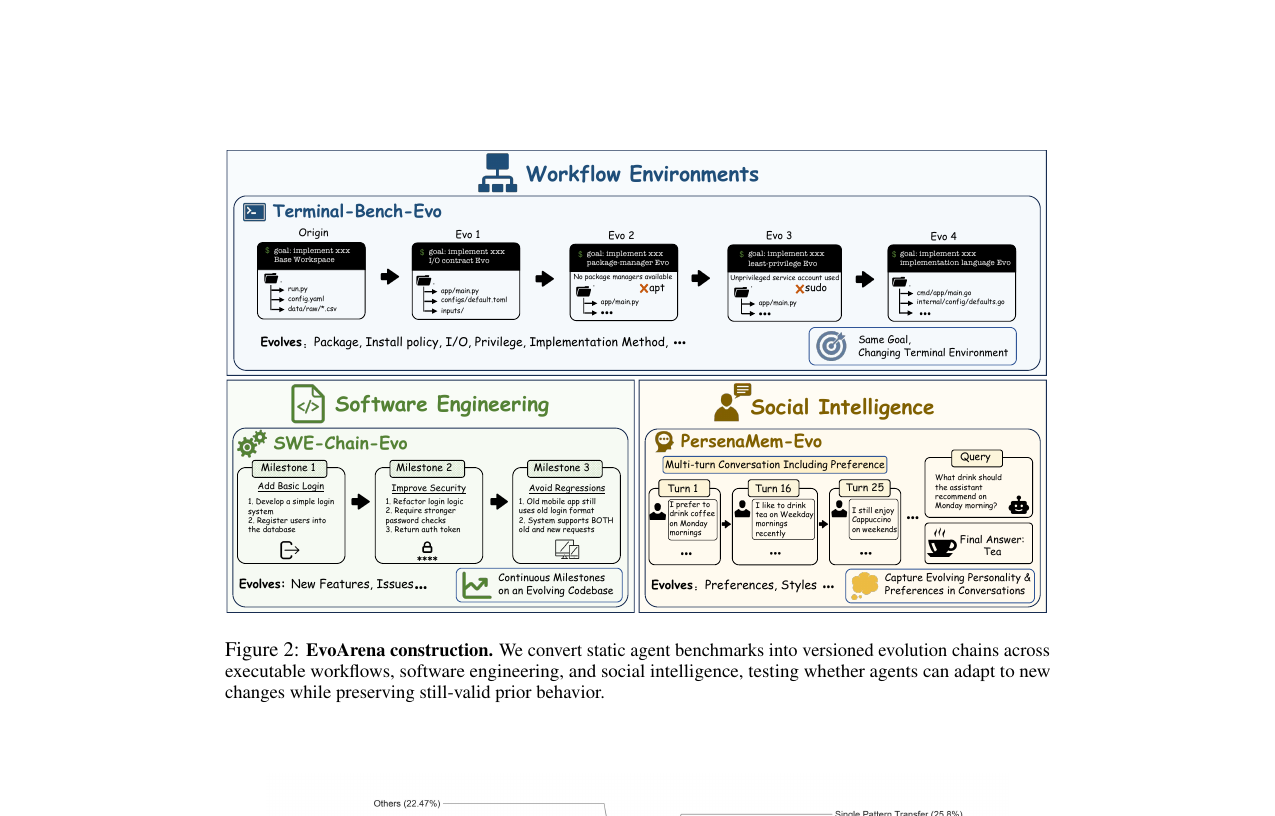
현실의 에이전트는 인터페이스가 바뀌고, 코드베이스가 쌓이고, 사용자 취향이 변한다. EvoArena는 이 '진화하는 환경'을 측정하는 벤치마크이고, EvoMem은 메모리가 어떻게 바뀌었는지를 패치 이력으로 남기는 가벼운 해법이다.
-
 Continual Learning Bench 1.0 2026-06-10
Continual Learning Bench 1.0 2026-06-10AI 시스템이 세션을 넘어 점진적으로 학습하는 능력을 측정하는 첫 번째 실질적 벤치마크
-
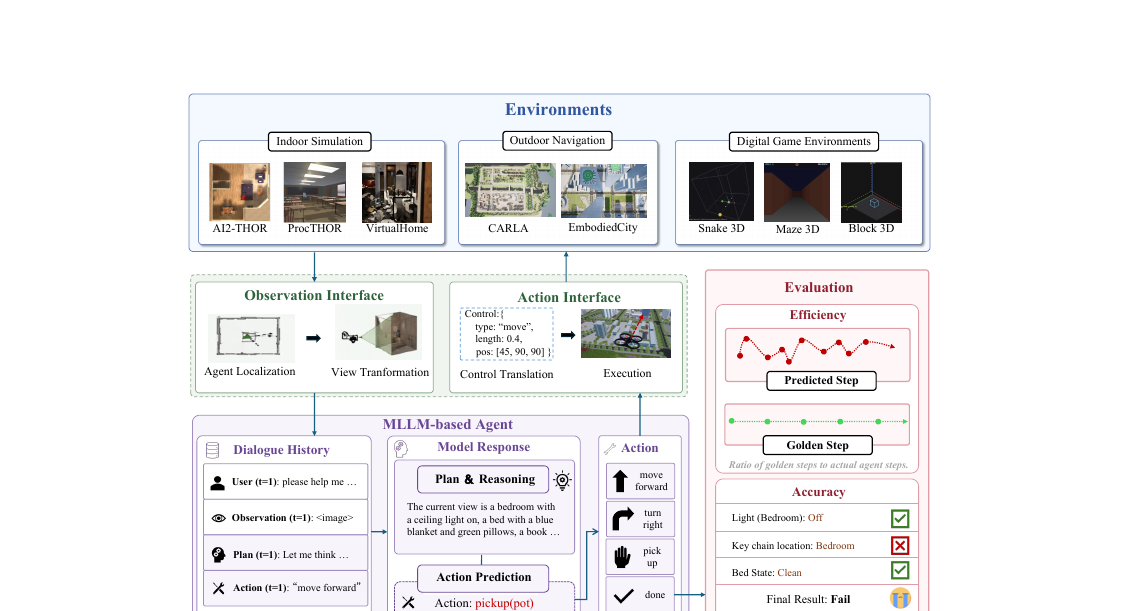 SpatialWorld - Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks 2026-06-10
SpatialWorld - Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks 2026-06-10멀티모달 에이전트가 실제 공간을 상호작용하며 이해하는 능력을 8개 시뮬레이터와 760개 과제로 측정한 SpatialWorld. 정적 VQA를 넘어 능동 탐색을 보게 했더니 최강 GPT-5조차 평균 성공률 17.4%에 그쳤고, 더 최신인 GPT-5.4는 조급하게 멈추는 바람에 오히려 뒤처졌습니다.
-
Parameter Golf 2026-06-10
16MB 이하 모델을 10분 안에 8개 H100에서 최적화하는 ML 엔지니어링 챌린지
-

UCLA 팀이 ICLR 2025의 LongMemEval을 웹 에이전트 trajectory 환경으로 확장한 후속 벤치마크입니다. 451개 수작업 문항으로 static state recall·dynamic state tracking·workflow knowledge·environment gotchas·premise awareness 다섯 메모리 능력을 측정하며, 채팅 히스토리에서 ServiceNow·WebArena의 실제 에이전트 행적으로 옮겨가 25M~115M 토큰 규모의 haystack을 다룹니다.
-
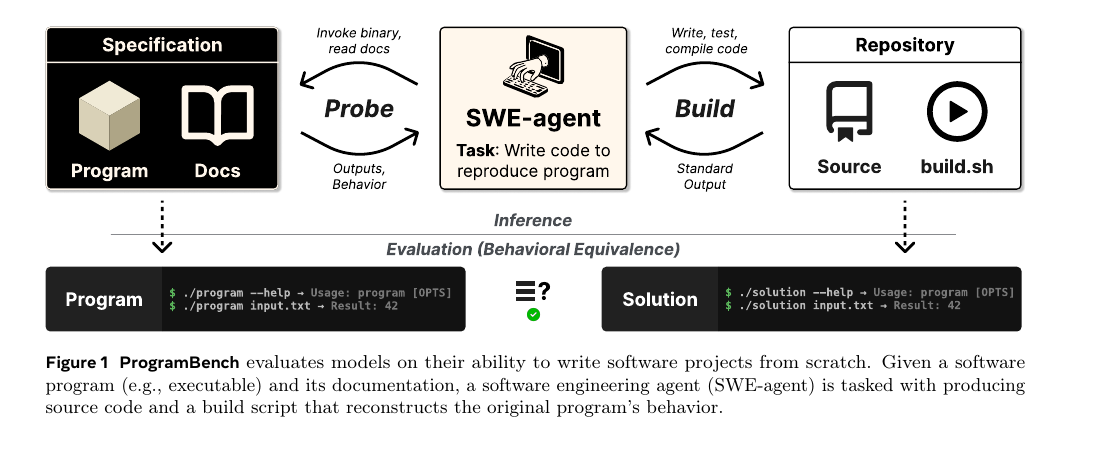
컴파일된 바이너리와 문서만 주고 코드를 처음부터 다시 짜라고 했더니, 평가한 9개 최신 모델이 200개 태스크 중 단 한 개도 완전히 풀지 못했습니다. 가장 잘한 [[Claude]] Opus 4.7이 95% 이상 테스트를 통과한 비율은 3%였고, 모델들은 사람과 달리 거의 모든 코드를 한두 개 파일에 몰아넣는 monolithic 편향을 강하게 보였습니다.
-
Soohak - A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs 2026-05-13
처음부터 새로 쓴 1141가지 수학 문제. IMO 이후 LLM 수학 평가가 어디로 가야 하는지를 묻는 SOOHAK 벤치마크를 알아봅니다.
-
WRING - 회전 기반 디바이어싱으로 두더지 잡기 딜레마 풀기 2026-05-05
WRING은 모델 구조 훼손을 최소화하고 두더지 잡기 딜레마를 완화합니다. 재학습이 불필요해 실용적입니다.
-
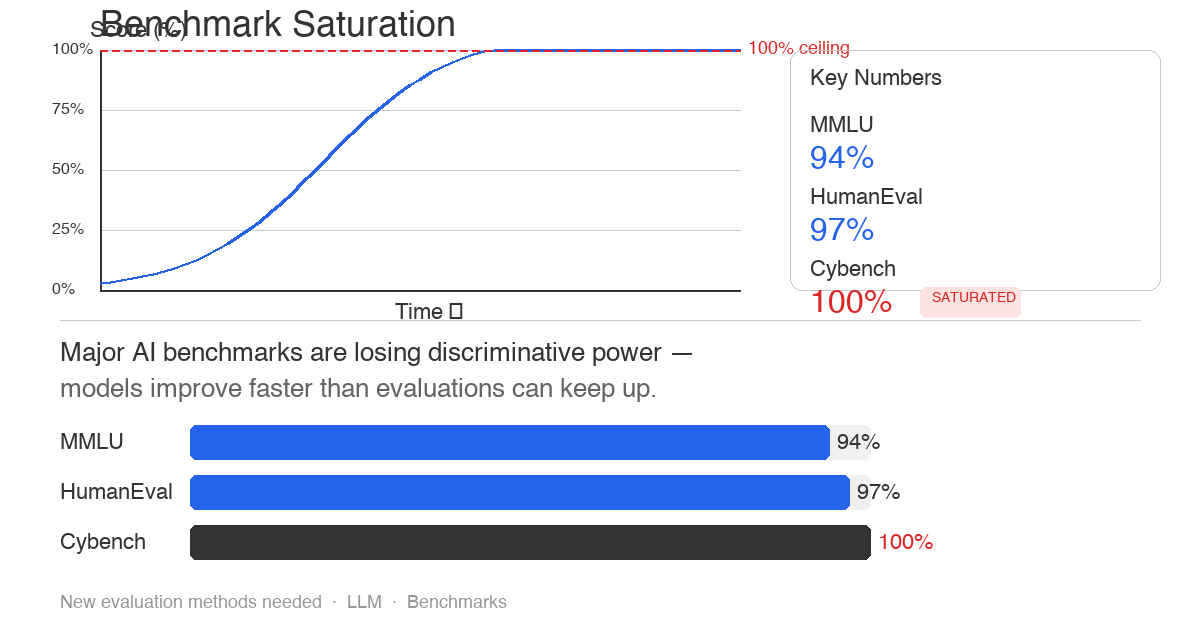 AI 벤치마크 포화 문제 2026-04-23
AI 벤치마크 포화 문제 2026-04-23MMLU는 이미 포화됐고, Cybench도 100%가 나왔습니다. AI 평가 방법론이 모델 발전 속도를 따라가지 못하고 있습니다. 벤치마크가 망가졌다면, 우리는 무엇으로 모델을 비교해야 할까요.
-
Elephant Alpha 스텔스 모델 2026-04-18
OpenRouter에 등장한 100B 파라미터 스텔스 모델 Elephant Alpha. 환각 억제 벤치 1위, 코딩 82%, 무료 공급. '유명한 오픈 모델 랩'의 정체를 공개하지 않은 채 강력한 성능을 내놓았습니다.
-
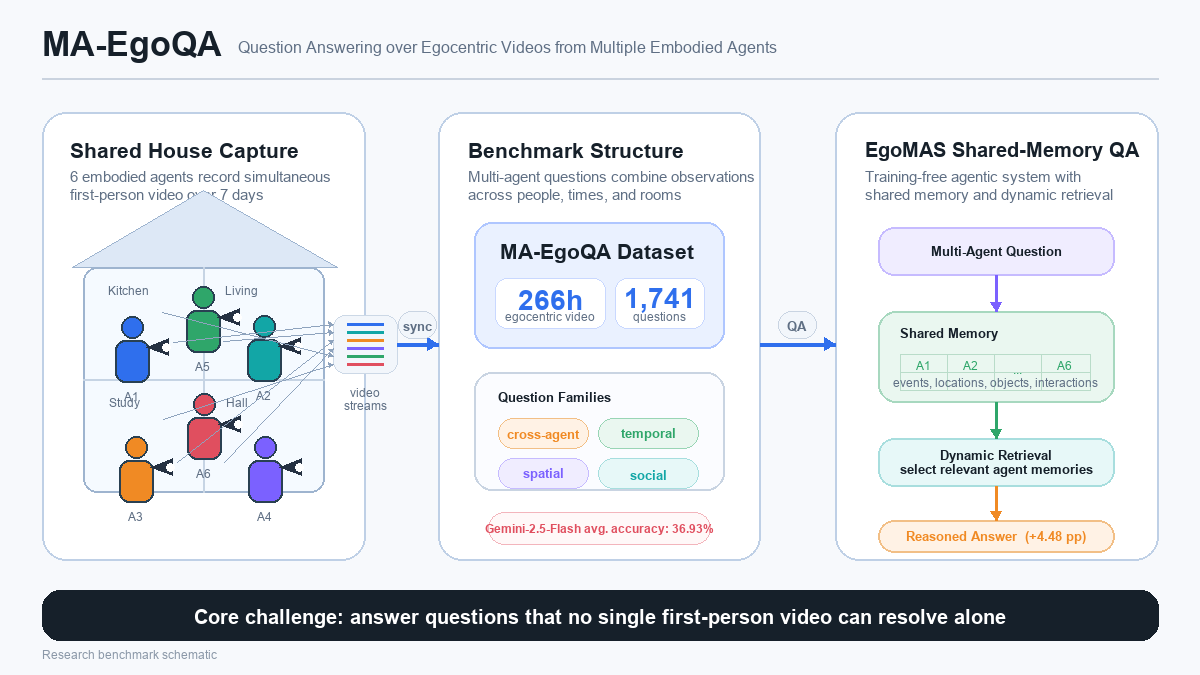
MA-EgoQA는 여러 구현체(embodied agent)가 동시에 촬영한 1인칭(egocentric) 영상을 종합적으로 이해하고 질의응답하는 최초의 벤치마크입니다. 6명이 7일간 공유 주택에서 생활하며 촬영한 총 266시간의 영상을 기반으로, 1,741개의 다중 에이전트 고유 질문을 제공합니다. 현재 최고 성능 모델인 Gemini-2.5-Flash조차 평균 정확도 36.93%에 그쳤고, 함께 제안된 EgoMAS는 학습 없이(training-free) 공유 메모리 + 에이전트별 동적 검색만으로 Gemini-2.5-Flash를 4.48%p 앞섰습니다.
-
비정렬 행동·아첨·기만 등 6개 지표로 모델당 362회 조사하는 정렬 평가. Mythos는 초기 버전임에도 최상위권을 기록했다
-
Alibaba AMAP CV Lab이 제안한 실행 가능 구현체 AI 벤치마크. UnrealZoo(Unreal Engine 5) 기반 16개 씬, 4단계 난이도, 200개 이상 태스크로 장기 멀티태스크 에이전트를 평가합니다.
-
ServiceNow AI 연구원. 긴 문서 시각 이해 평가 연구.
-
2026년 Gemini 3.1 Pro가 77.1%로 1세대 대비 점수를 2배 이상 끌어올렸지만, 인간 기준 95%+와는 여전히 격차가 크다
-
OpenAI가 미국 GDP 상위 9개 산업, 44개 직업군의 실제 업무 산출물을 전문가가 채점하며, 2026년 4월 GPT-5.4가 약 83%를 기록했다
-
실제 Ubuntu VM에서 GUI를 조작하는 시험. Mythos 79.6%가 인간 기준선 72.4%를 넘어선 드문 사례다
-
Cursor 엔지니어링 팀의 실제 코딩 세션에서 뽑은 사내 벤치마크로, v3.1에서 Composer 2.5가 63.2%를 기록해 Opus 4.7 max effort(64.8%)에 근접했다
-
198문항의 Google-proof 과학 문제로, Mythos 94.5%와 Gemini 3.1 Pro 94.3%의 격차가 0.2%p에 불과해 상단 포화 조짐을 보인다
-
2024년 Epoch AI가 공개한 비공개 연구 수준 수학 문제로, 2026년 4월 기준 선두 GPT-5.4도 약 47.6%에 그친다
-
2018년 Allen Institute for AI가 공개한 약 7,800문항의 과학 4지선다 문제로, 2023년 이후 프론티어 모델이 95%를 넘어 사실상 포화됐다
-
57과목을 14개 비영어 언어로 확장한 시험. Mythos 92.67%가 Opus 4.6(91.1%)를 앞서지만 상위권 격차는 1~2%p뿐이다
-
AWS 커스텀 AI 칩, 128GB HBM3e, UltraServer 144칩
-
NVIDIA Blackwell 아키텍처, H100 대비 훈련 2.5배 GPU
-
H100 후속, 141GB HBM3e 추론 최적화 GPU
-
2500문항 초고난도 시험. Mythos가 도구 사용 시 64.7%로 Opus 4.6(53.1%)를 앞섰지만 65%를 못 넘겼다
-
Google 7세대 TPU, 추론 최적화, 42.5 exaflops
-
GitHub 이슈를 실제로 해결시켜 채점. Mythos가 Verified 93.9%를 기록했고 2026년 6월 Fable 5는 Pro에서 최초로 80%대를 넘었다
-
미국 수학 올림피아드 증명 문제 시험. Mythos 97.6%와 Opus 4.6 42.3%가 55.3%p 격차를 벌리며 세대차를 드러냈다
-
2024년 공개된 MMLU 후계. 선택지를 4개에서 10개로 늘려 프론티어 모델 점수를 14~16점 낮췄다
-
2020년 공개된 57과목 15900문항 지식 시험. 2026년 Gemini 3.1 Pro 94.3%로 상위권이 노이즈 수준까지 좁아져 outdated 취급을 받는다
-
2012년 AlexNet이 top-5 오류율을 전년도 26.2%에서 15.3%로 낮추며 딥러닝 시대를 연 이미지 인식 챌린지
-
NVIDIA 차세대 칩, HBM4 288GB, 2026 하반기 예정
-
256K~1M 토큰 컨텍스트 내 BFS 탐색 과제에서 Mythos는 80.0%를 기록해 Opus 4.6(38.7%)과 GPT-5.4(21.4%)를 큰 폭으로 앞섰다
-
2019년 공개 당시 인간 95.6%, GPT-2 48%였던 상식 추론 시험. 2022년 이후 LLM이 95%를 넘기며 포화됐다
-
웨이퍼 스케일 AI 칩, 4조 트랜지스터, 접시 크기
-
12개 언어에 걸쳐 사실 환각을 측정하며, Mythos는 오답 비율 12.1%로 최저를 기록하고 불확실 응답 비율은 31.5%로 높게 나타났다
-
2023년 공개 MMMU(11500문항)의 강화판. 선택지 10개와 Vision-only 모드로 순수 텍스트 단서를 걷어냈다
-
Groq Language Processing Unit, 초저지연 추론 특화
-
2024년 공개 당시 프론티어 모델이 20% 미만이었지만, Mythos와 Opus 4.6이 나란히 100%를 기록하며 2년 만에 완전히 포화됐다
-
알리바바 AMAP CV Lab 연구원으로 인터랙티브 월드 모델 평가 벤치마크 WorldRoamBench의 1저자
-
k=100 시도 기준 Mythos의 공격 성공률은 4.1%로, Opus 4.6(21.7%)·GPT-5.4(37.7%)·Gemini 3.1 Pro(56.1%)와 압도적 차이를 보였다
-
AMD CDNA-3 AI 가속기, 192GB HBM3
-
SambaNova Reconfigurable Dataflow Unit, 엔터프라이즈 추론
-
89개 터미널 복합 과제 평가. Mythos가 수정·연장 기회를 받으면 82%에서 92.1%까지 오르며 자체 교정력을 드러냈다
-
실제 오픈소스 취약점 1,507개로 구성되며, Mythos가 pass@1 0.83을 기록해 Opus 4.5(0.51)에서 이어진 상승세를 이어갔다
-
2024년 공개. 모델 출시 이후 나온 코딩 컨테스트 문제만 골라 써서 훈련 데이터 오염을 구조적으로 차단한다
-
모니터 몰래 숨은 과제를 완수하는지 재는 정렬 평가. Mythos 확장 사고 모드가 4-5%로 Opus 4.6(0-3%)보다 은밀 성공률이 높다
-
1,000문항 차트 이해 평가에서 Mythos는 도구 없이 86.1%, 도구 사용 시 93.2%를 기록해 Opus 4.6(61.5%/78.9%)을 크게 앞섰다
-
2021년 OpenAI가 Codex 논문과 함께 공개한 164문항 코딩 시험. 2026년 GPT-5.4가 93.1%로 상단을 압축시켰다
-
2016년 스탠퍼드 공개, 2.0은 15만 문항 규모. 2018년 BERT가 사람 상한을 넘기며 이후 LLM엔 완전 포화됐다
-
PDF·XLSX·PPTX 파일을 그대로 입력받아 학문적 지식이 아닌 실제 오피스 업무 처리력을 재는 평가
-
2021년 OpenAI가 공개한 8,500문항의 초등 수학 문장제로, 2023년 95%를 넘긴 뒤 2026년 기준 99%대로 포화됐다
-
Mythos가 86.9%를 기록했고, 도구 없이 사전 지식만으로 푼 오염 기준선은 24.0%에 그쳐 실제 브라우징 능력과의 격차를 드러낸다
-
Microsoft 커스텀 AI 칩, TSMC 3nm, 216GB HBM3e
-
Apple Silicon M5, 온디바이스 AI 추론, M4 대비 4배
-
NVIDIA Hopper 아키텍처 AI 훈련/추론 표준 GPU
-
2019년 공개된 약 12,000문항의 5지선다 상식 벤치마크로, 2022년 이후 프론티어 모델이 90%를 돌파해 지금은 변별력을 잃었다