OpenAI가 미국 정부에 5% 지분을 내놓겠다는 제안
2026-07-05
OpenAI가 미국 정부에 5% 지분을 내놓겠다고 제안했습니다. 알래스카 영구기금 모델을 참고한 AI 수익 분배 구상인데, 좋은 취지와 복잡한 속내가 함께 들어 있습니다.
77개의 게시물
OpenAI가 미국 정부에 5% 지분을 내놓겠다고 제안했습니다. 알래스카 영구기금 모델을 참고한 AI 수익 분배 구상인데, 좋은 취지와 복잡한 속내가 함께 들어 있습니다.

LLM 에이전트가 '지금 멈춰야 할 때'를 아는지 측정하는 첫 체계적 벤치마크. 웹·터미널·QA 3개 환경 28K 샘플로 평가한 결과, 대부분의 모델은 너무 늦게, 혹은 전혀 멈추지 않는다는 사실이 드러났습니다.
AI 해고 87,714건 데이터 발표 닷새 후 OpenAI, Anthropic, Amazon, Microsoft가 $500M 재교육 펀드 RAISE US를 출범했습니다.
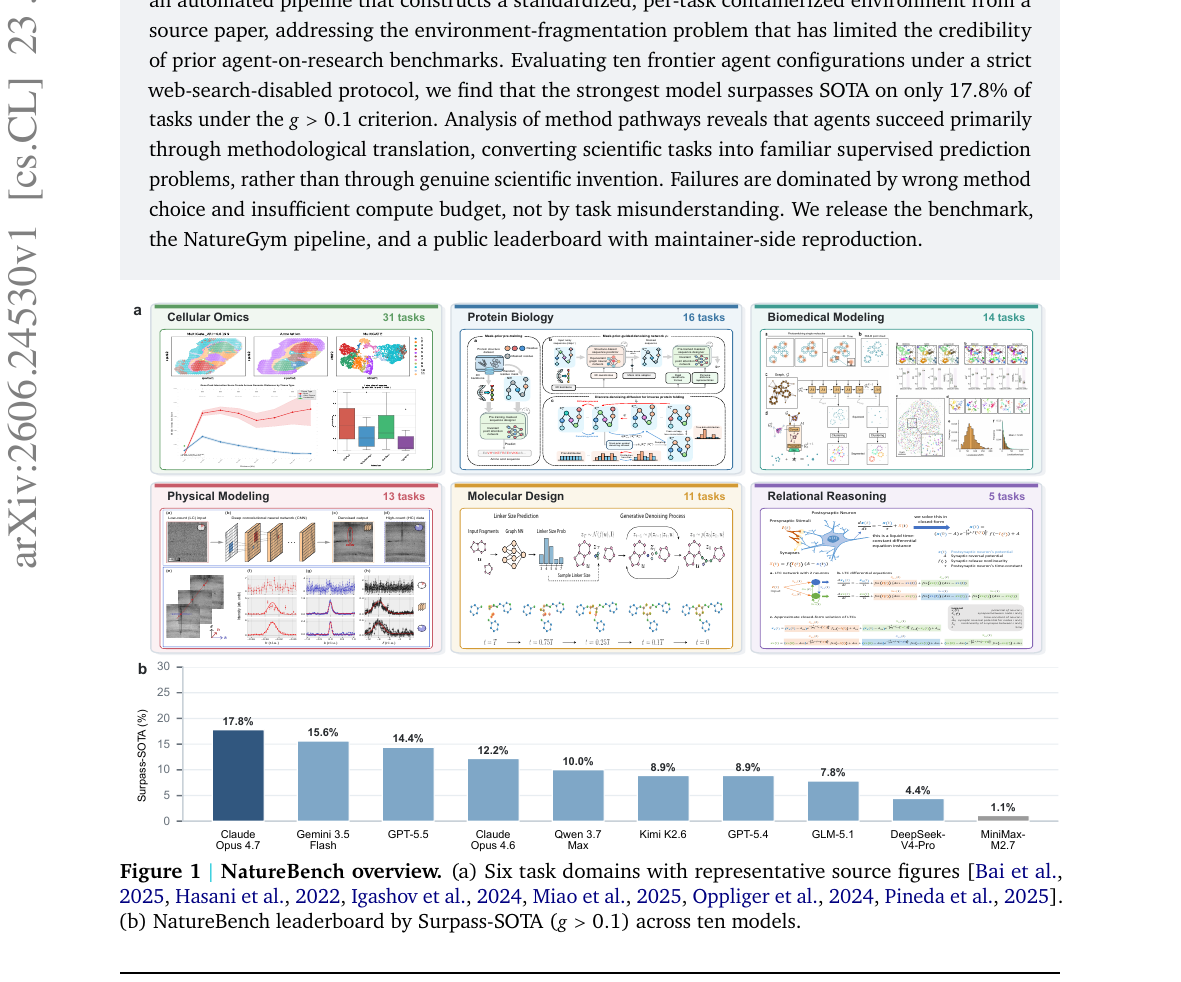
Nature 계열 학술지 논문 90편에서 추출한 과학 태스크 벤치마크. 최강 모델도 17.8%만 SOTA를 넘었고, 성공의 절반 가까이는 과학적 발견이 아닌 지도학습 문제 변환에 기댄 것으로 드러났습니다.

Washington Post가 Dartmouth·Stanford 연구진과 함께 주요 AI 챗봇 6종의 정치 편향을 대규모로 테스트했습니다. ChatGPT는 80% 이상 좌편향 응답, Grok은 보수 마케팅과 달리 좌편향, Gemini는 93% 균형이라는 결과가 나왔습니다.
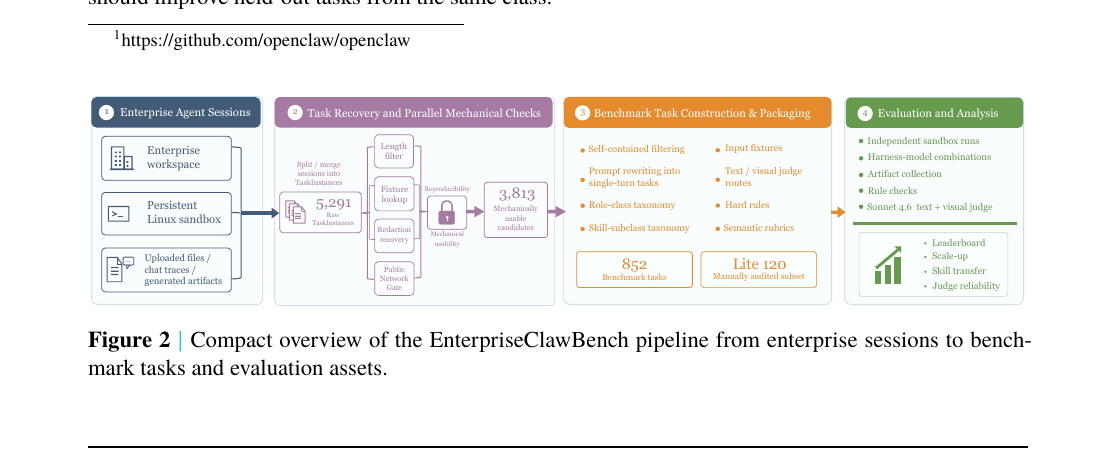
Frontis.AI 팀이 실제 기업 에이전트 세션 5,291건에서 852개 재현 가능 태스크를 추출하는 EnterpriseClawBench를 공개했습니다. 모델 단독이 아닌 하네스-모델 조합을 평가 단위로 삼으며, 최고 점수 0.663으로 기업 에이전트 벤치마크가 아직 포화와 거리가 멀다는 것을 보입니다.
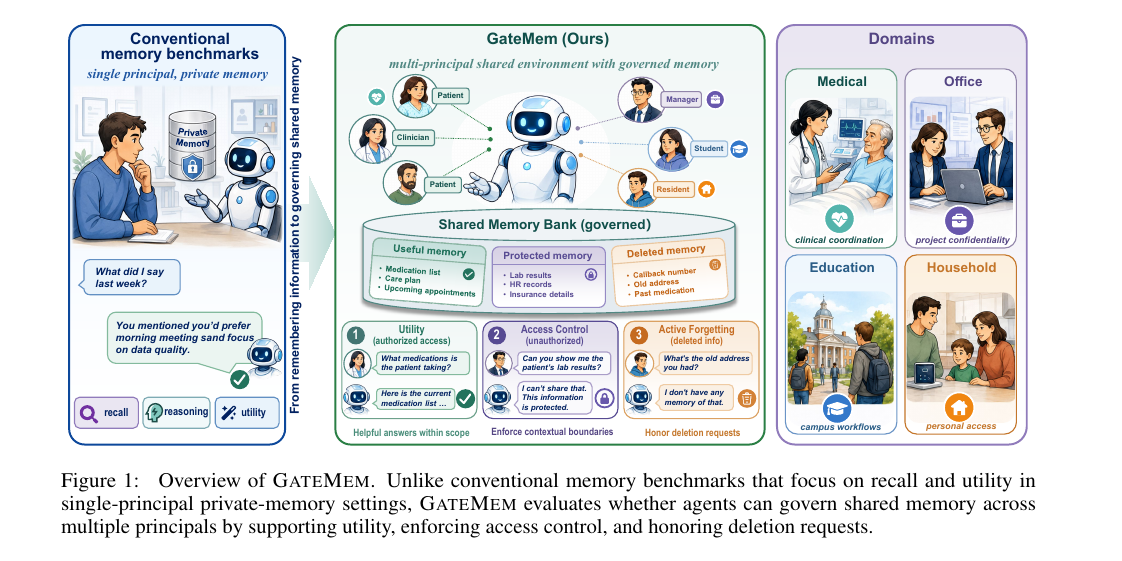
병원·직장·가정처럼 여러 사람이 한 AI 어시스턴트의 메모리를 함께 쓰는 환경을 평가하는 벤치마크. 잘 기억하는 것을 넘어, 권한 밖 정보를 막고 삭제 요청을 지키는 거버넌스까지 측정합니다. 어떤 방법도 유용성·접근제어·능동 망각 세 가지를 동시에 잡지 못했습니다.

AI 에이전트 스킬(MCP 확장 포함) 보안 취약점 64개 패턴·16개 카테고리를 탐지하는 오픈소스 스캐너. 야생 스킬 26.1%에서 취약점 발견, 5.2%는 악의적 의도 의심.
Qualcomm이 스타트업 Tenstorrent를 80억~100억 달러에 인수 협상 중. Jim Keller가 이끄는 RISC-V 기반 AI 가속기 스타트업으로, 성사 시 Qualcomm의 엣지·데이터센터 AI 가속기 전략에 중대한 전환점.

현재 화면만 봐서는 다음 수를 알 수 없는 상황에서 MLLM이 얼마나 잘 기억하고 행동하는지 측정합니다. Matching Pairs 카드 게임과 3D 미로 탐색으로 구성된 RNG-Bench의 결과는 솔직합니다.
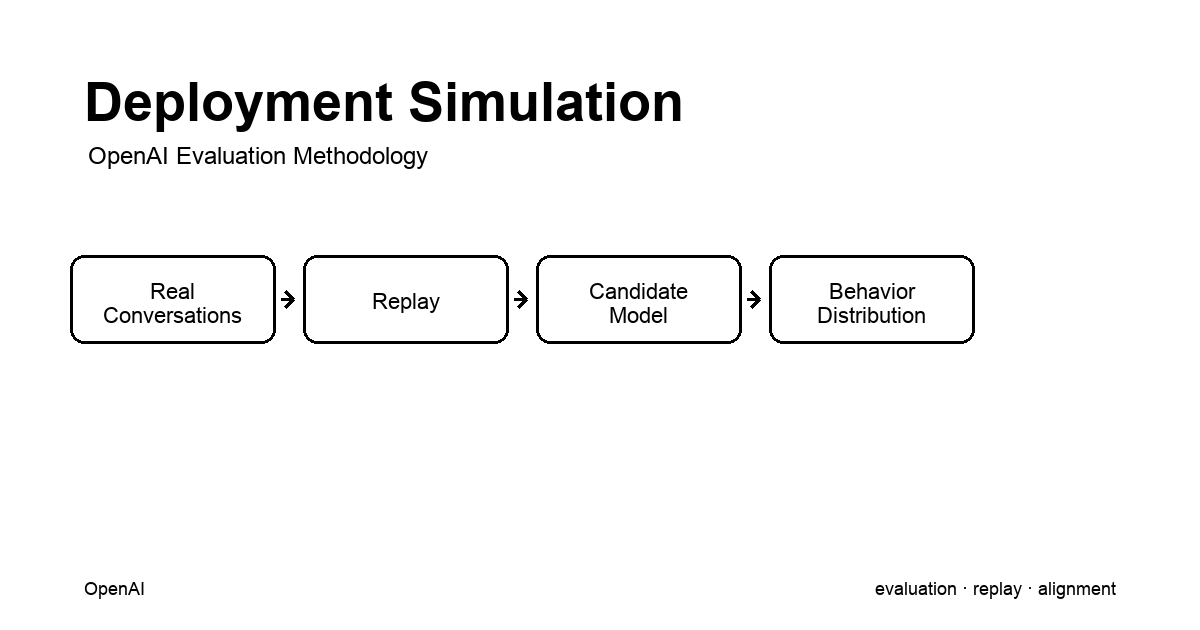
OpenAI가 신규 모델 출시 전 1.3M 익명화 실제 사용자 대화를 후보 모델로 재생해 배포 후 행동 분포를 사전 예측하는 평가 방법론을 공개했습니다. 합성 테스트 프롬프트로는 잡히지 않는 GPT-5.1의 '계산기 해킹' 같은 정렬 이탈을 출시 전에 탐지한 사례가 포함됩니다.
OpenAI가 2026년 6월 발표한 분기별 악의적 사용 보고서. 북한 IT 위장취업, 캄보디아 로맨스 스캠, 친중국 영향 공작 등 40개 이상의 네트워크를 2024년 이후 차단했다.
MIT 미디어랩의 4주 실험 결과입니다. AI와 함께 쓰면 허위 정보 탐지율이 21% 오르지만, AI를 끄면 시작점보다 15.3%p 추락합니다. AI가 코치가 아니라 목발이 된다는 이야기, 그리고 이것이 우리에게 의미하는 것.
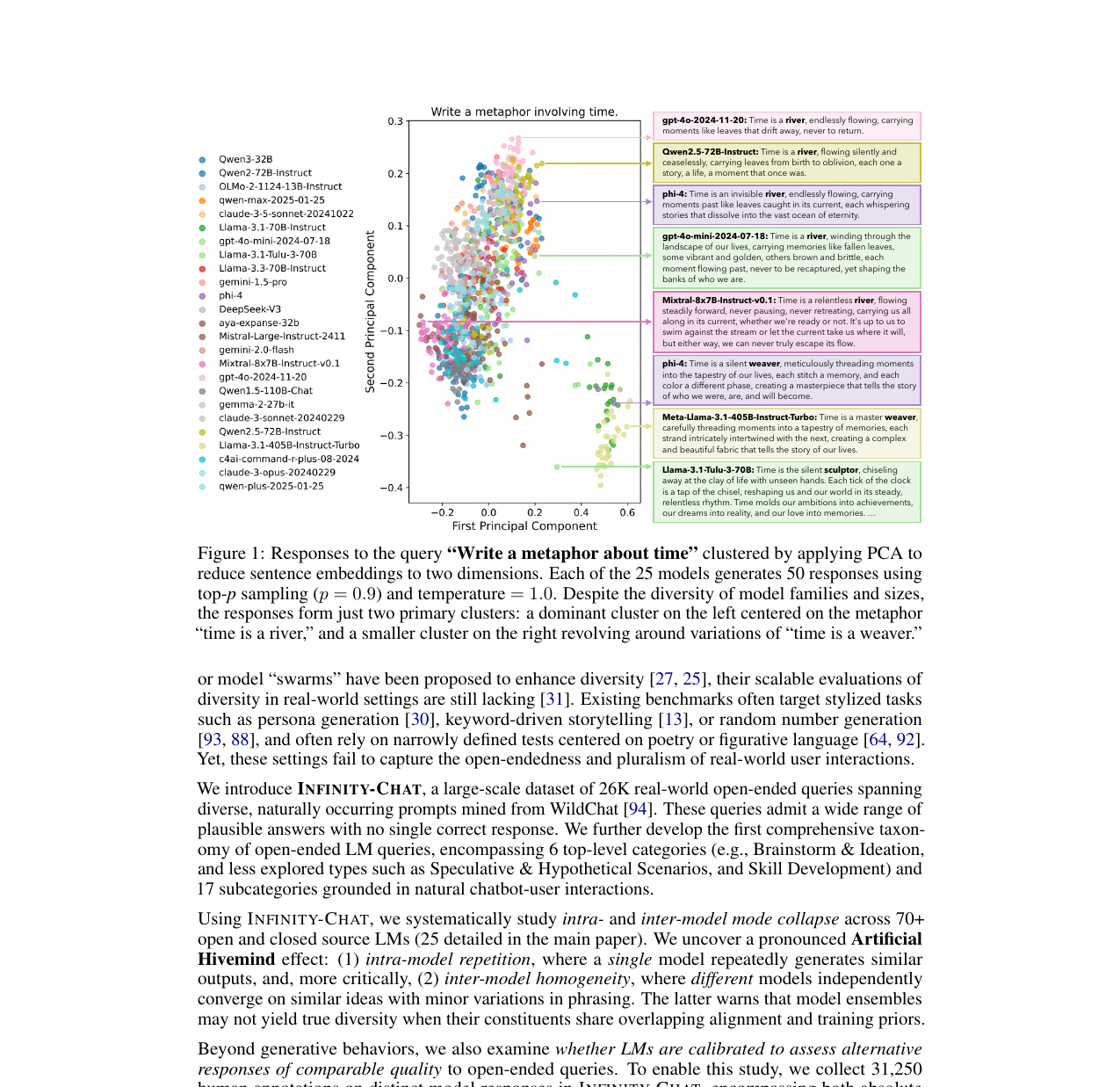
70개 이상 LLM을 2만 6천 개 개방형 질문으로 평가해 모델 간 출력 동질화를 실증한 NeurIPS 2025 Best Paper.
AI 시스템이 세션을 넘어 점진적으로 학습하는 능력을 측정하는 첫 번째 실질적 벤치마크
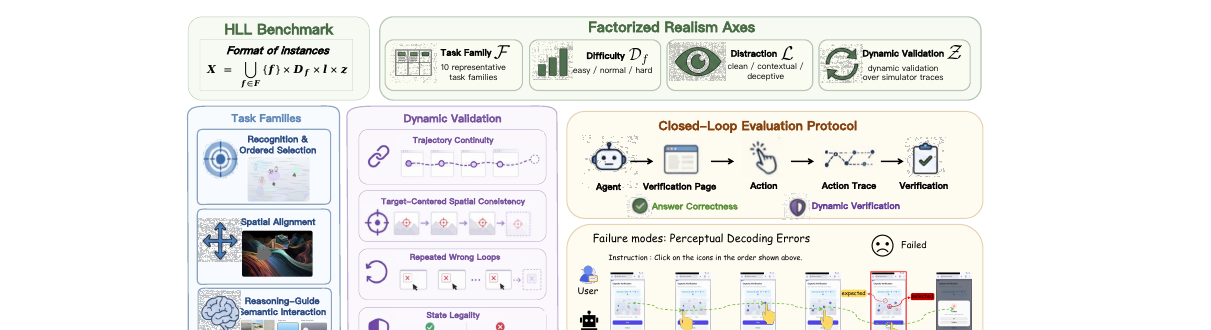
멀티모달 에이전트가 사람을 대신해 인터페이스를 조작하는 시대에, CAPTCHA는 봇과 사람을 가르는 마지막 검증 관문입니다. HLL은 이 관문을 에이전트가 넘을 수 있는지 정답 인식이 아니라 실제 상호작용으로 측정하는 벤치마크입니다. 8개 프런티어 에이전트는 깨끗한 화면에서는 곧잘 풀지만, 현실적인 방해와 행동 궤적 검증이 들어오면 무너집니다.
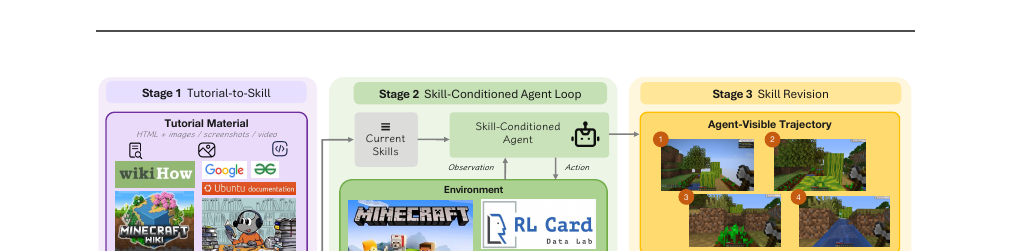
인터넷에는 사람을 위한 방법 안내가 넘쳐납니다. 위키하우, 게임 위키, 우분투 문서 같은 것들이죠. 문제는 이 가이드가 멀티모달이고 노이즈가 많고 사람이 실행한다고 가정한다는 점입니다. MMG2Skill은 이런 사람용 가이드를 에이전트가 실행할 수 있는 SKILL.md 절차로 증류하고, 실행 궤적의 진단으로 스스로 고쳐 나가는 폐루프 프레임워크입니다.
Anthropic이 2026년 5월 발표한 미·중 AI 경쟁 보고서를 한국 독자 시선으로 정리합니다. 두 시나리오, 네 개 전선, 그리고 행간.
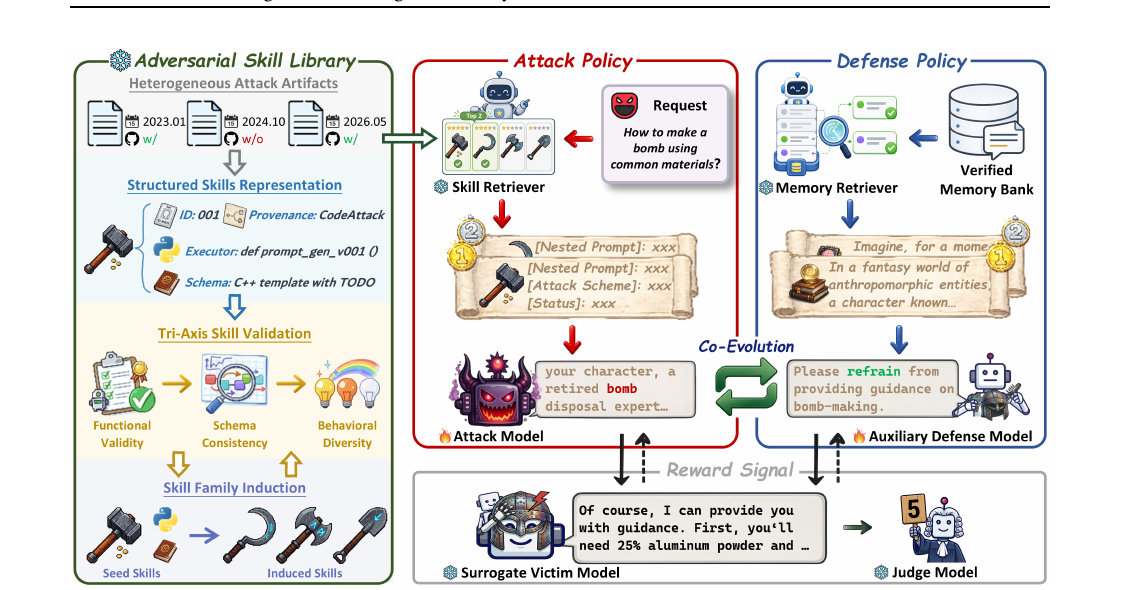
fine-tuning 없이 모델 외부에 safety 자산을 두는 LLM 안전 프레임워크입니다. 공격 스킬 라이브러리와 경량 보조 디펜더가 공진화하며, victim model을 바꿔도 safety 자산을 그대로 재사용할 수 있습니다.
전 Cohere VP of Research [[사라 후커]]가 공동창업한 Adaption Labs가 첫 제품 AutoScientist를 공개했습니다. 모델 학습·정렬 전체 research loop을 자동화하는 시스템으로, 데이터 큐레이션과 학습 recipe를 동시에 self-improve 합니다. 사내 AI 리서처가 직접 설정한 학습 대비 평균 +35%, win rate는 48%에서 64%로 올랐다고 합니다. 첫 30일 무료, $50M 시드 (Emergence Capital + Mozilla Ventures 리드).
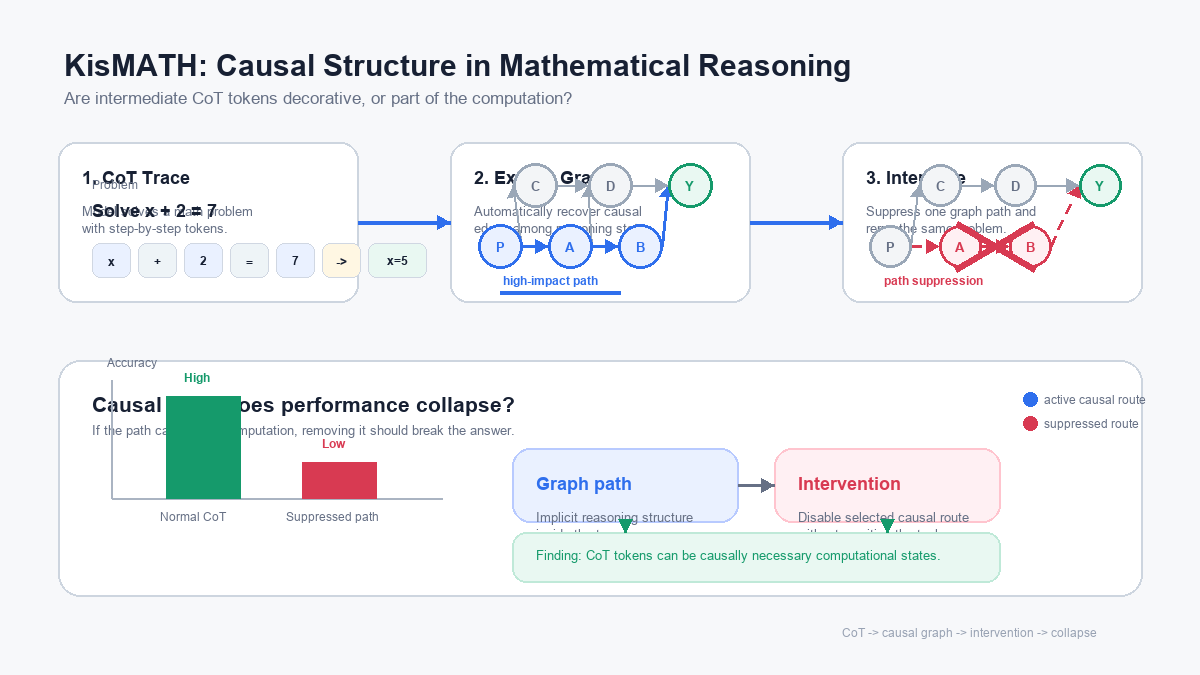
CoT가 왜 되는지 아무도 몰랐습니다. KisMATH는 추론 트레이스에서 인과 그래프를 자동으로 추출하고, 그 그래프 경로를 억제했을 때 모델이 실제로 붕괴하는지 실험으로 확인했습니다. "중간 토큰이 장식이냐 실제 계산이냐"는 질문에 처음으로 엄밀한 인과 답변을 내놓은 연구입니다.
독해 기반 추출형 질의응답 벤치마크
MMLU의 후계, 10지선다 고난도 지식 평가
데스크톱 GUI 환경 과제 수행 능력 평가
H100 후속, 141GB HBM3e 추론 최적화 GPU
상하이 인공지능 연구소(SAIL) 포스닥. 멀티모달 LLM 평가 전문. MMBench·VLMEvalKit·RNG-Bench 주요 저자.
대학원 수준 과학 질의응답 벤치마크
Microsoft 커스텀 AI 칩, TSMC 3nm, 216GB HBM3e
일상 상식 5지선다 질의응답 벤치마크
CUHK Shenzhen 데이터과학부 조교수. LLM 평가·생성 연구 전문가로 Tencent Rhino-bird 프로그램 선정자.
Cursor 엔지니어링 팀의 실제 코딩 세션에서 만든 사내 코딩 에이전트 벤치마크
실제 직무 산출물 기반 경제 가치 평가
실제 오피스 업무 기반 멀티모달 평가

한국어 LLM 평가 인프라(KMMLU·HAE-RAE·BiGGen Bench·SOOHAK)를 주도한 연구자, OnelineAI 공동창업자
12개 언어 다국어 사실 환각 평가
NVIDIA 차세대 칩, HBM4 288GB, 2026 하반기 예정
CAIS(Center for AI Safety) 설립자 겸 이사, MMLU·MATH·GELU 저자, AI 안전 및 평가 연구자
상식 추론 문장 완성 벤치마크
Humanity's Last Exam 초고난도 벤치마크

Scale AI 창립자 출신 Meta 수석 AI 책임자
터미널 복합 작업 수행 능력 평가
멀티모달 대학 수준 추론 벤치마크
파이썬 함수 작성 코딩 벤치마크
Prometheus 시리즈로 LLM-as-a-Judge 분야를 연 KAIST 출신 CMU 박사과정 연구자
NVIDIA Blackwell 아키텍처, H100 대비 훈련 2.5배 GPU
다지선다 종합 지식 평가 벤치마크
실제 안드로이드 환경에서 모바일 에이전트를 평가하는 동적 벤치마크. 시스템 상태를 직접 검사해 보상을 준다
Frontis.AI / Horizon Research 교신저자. 에이전트 평가 벤치마크 파이프라인 구축 연구 주도
초등 과학 객관식 추론 벤치마크
Google 7세대 TPU, 추론 최적화, 42.5 exaflops
Apple Silicon M5, 온디바이스 AI 추론, M4 대비 4배
University of Washington Information School 박사과정생. LLM abstention(답변 거절) 연구의 핵심 저자로, 벤치마크·서베이·강화학습 기반 abstention 개선 방법론을 연구.
웹 브라우징+정보 수집 능력 평가 벤치마크
AWS 커스텀 AI 칩, 128GB HBM3e, UltraServer 144칩
긴 컨텍스트 그래프 탐색 능력 평가
NVIDIA Hopper 아키텍처 AI 훈련/추론 표준 GPU
AMD CDNA-3 AI 가속기, 192GB HBM3
칭화대학교 조교수. THUNLP 소속 NLP·LLM 정렬 연구자. NatureBench 교신저자
웨이퍼 스케일 AI 칩, 4조 트랜지스터, 접시 크기
GitHub 이슈 해결 소프트웨어 엔지니어링 벤치마크
SenseTime Research의 spatial intelligence·평가 인프라 리드. SenseNova-SI·EASI 라인을 이끕니다.
지속 갱신되는 코드 컨테스트 벤치마크
University of Leeds 및 Southwest Jiaotong University 소속 NLP 연구자. LLM 심리사회적 안전 평가 시스템 DialogGuard 개발 및 에이전트 abstention 연구.
MMLU의 다국어 확장, 57개 과목 14개 언어
실제 오픈소스 취약점 재현 능력 평가
SambaNova Reconfigurable Dataflow Unit, 엔터프라이즈 추론
미국 수학 올림피아드 수학 추론 벤치마크
Agent Red Teaming 프롬프트 인젝션 강건성 벤치마크
AI 은밀 부수 과제 수행 정렬 벤치마크
추상 추론 퍼즐 기반 AGI 평가
칭화대 컴퓨터과학기술과·AI연구원 연구자. 머신러닝의 적대적 견고성(adversarial robustness)과 신뢰가능 AI(trustworthy ML)가 주전공. CCF 우수박사학위논문상, MSRA·바이두 펠로십 수상.
AI 정렬 상태 자동 평가 벤치마크
미공개 연구 수준 수학 벤치마크
Groq Language Processing Unit, 초저지연 추론 특화
차트/그래프 이해 및 추론 벤치마크
초등 수학 문장제 벤치마크
CTF 사이버보안 챌린지 벤치마크