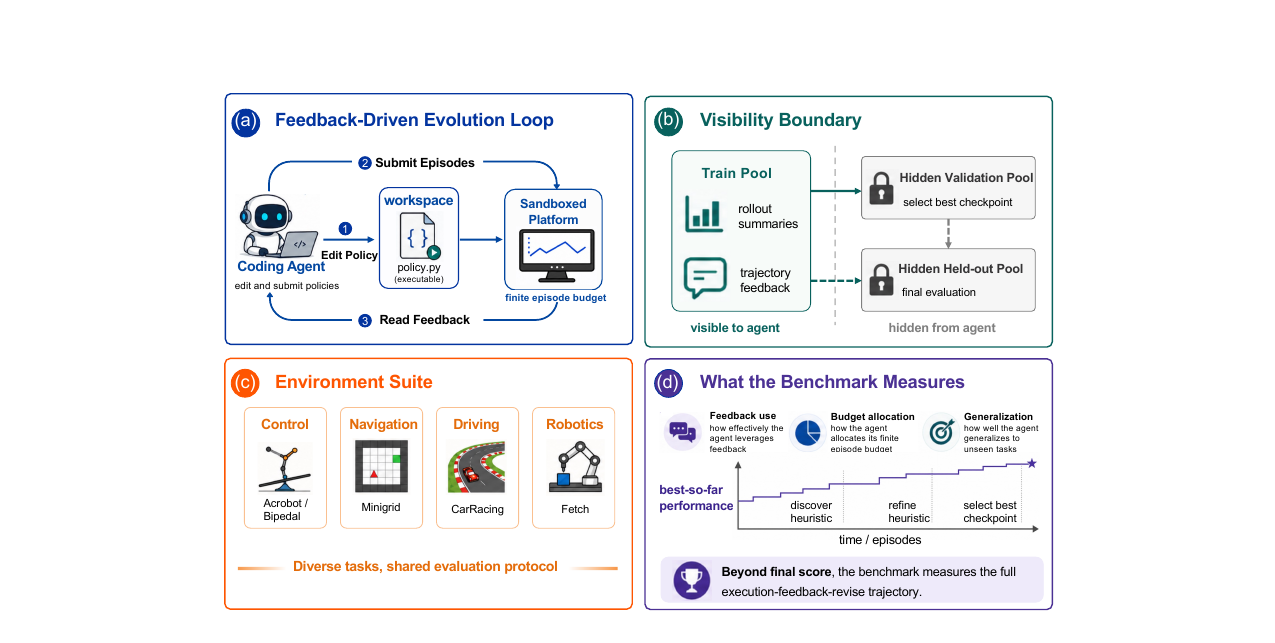
에이전트가 실행 가능한 정책 코드를 128회 에피소드 예산 안에서 반복 개선하는 능력을 측정하는 벤치마크. GPT-5.5가 Core16 16개 환경 모두 Top-2, Claude Opus 4.7이 MiniGrid에서 가장 강한 두각을 보입니다.
태그: 강화학습
64개의 게시물
-
-
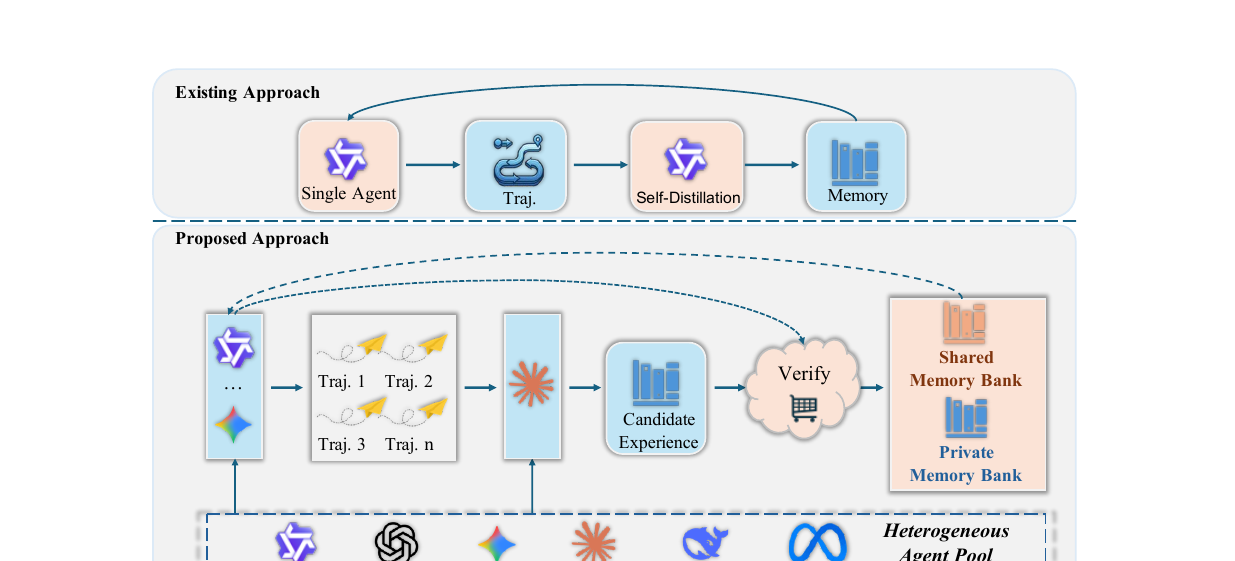
단일 에이전트 경험 학습의 구조적 결함인 Self-Confirmation Trap을 공식화하고, 이종 병렬 실행·제3자 증류·합의 기반 검증의 EDV 프레임워크로 해결합니다.
-
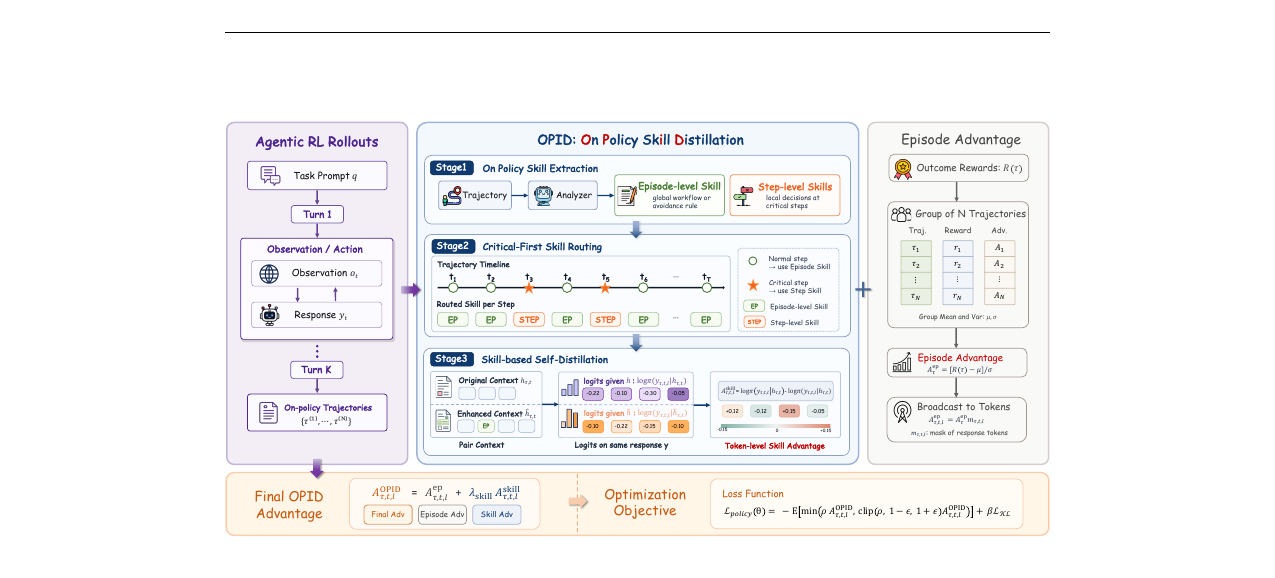
청화대·절강대·홍콩중문대가 공동 제안한 에이전틱 RL 프레임워크. GRPO의 희박한 결과 보상을 보완하기 위해 완료된 온-폴리시 궤적에서 에피소드·스텝 두 계층의 스킬을 추출하고, 이를 token-level 자기 증류 신호로 변환합니다. 추론 시에는 외부 스킬 라이브러리가 필요 없습니다.
-
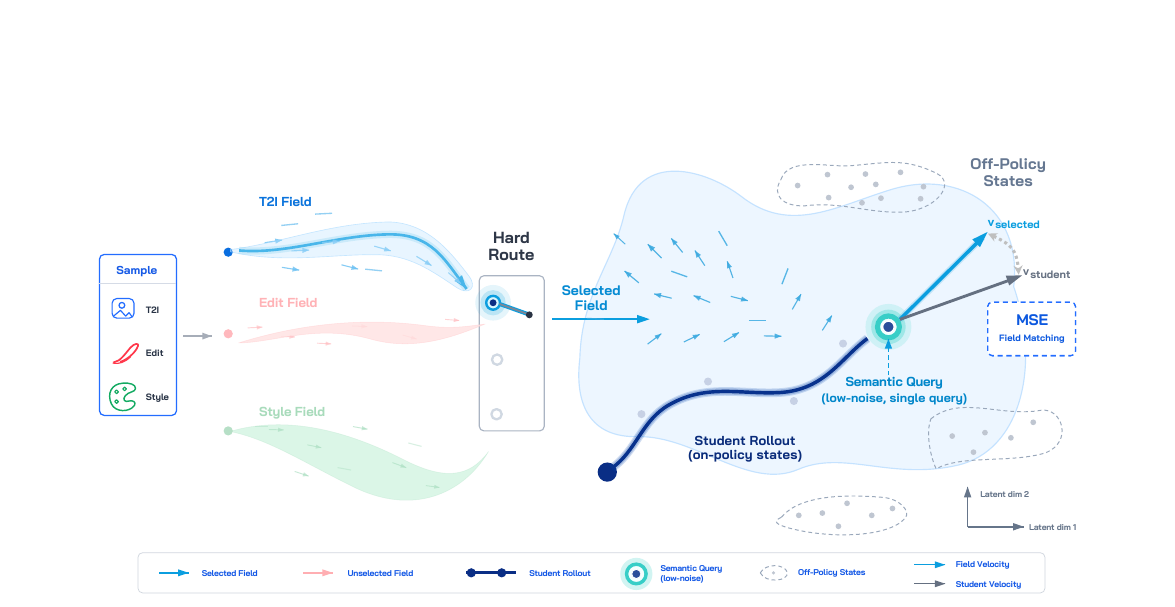
ByteDance Seed와 NUS가 제안한 on-policy 생성 필드 증류 프레임워크. 하나의 flow-matching 학생 모델에 T2I, 로컬 편집, 글로벌 편집 능력을 충돌 없이 합성하는 세 가지 설계 원칙을 제시합니다.
-
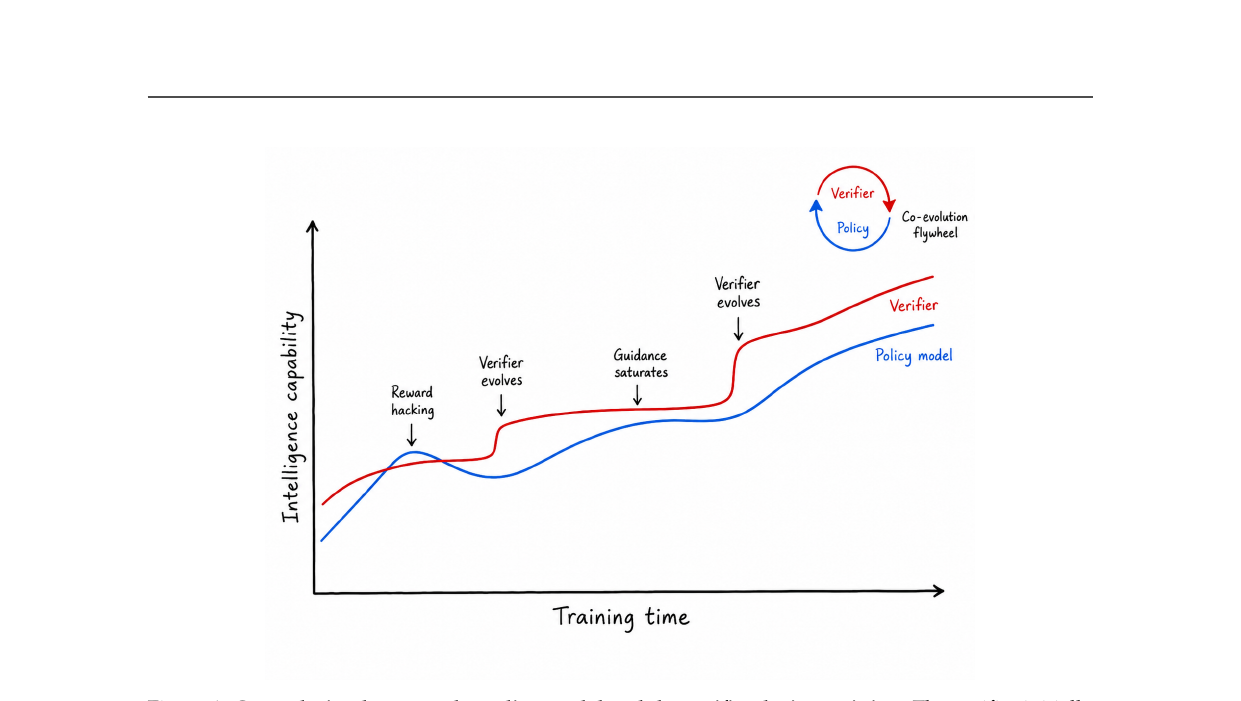
Qwen 팀이 코딩 에이전트 보상 설계의 실전 경험을 정리한 논문. 테스트 통과, 시각 판정, 사용자 피드백, 에이전트 평가자 네 가지 방식을 분석하고, 어떤 단일 검증 함수도 모델이 강해질수록 결국 부족해진다고 주장합니다.
-
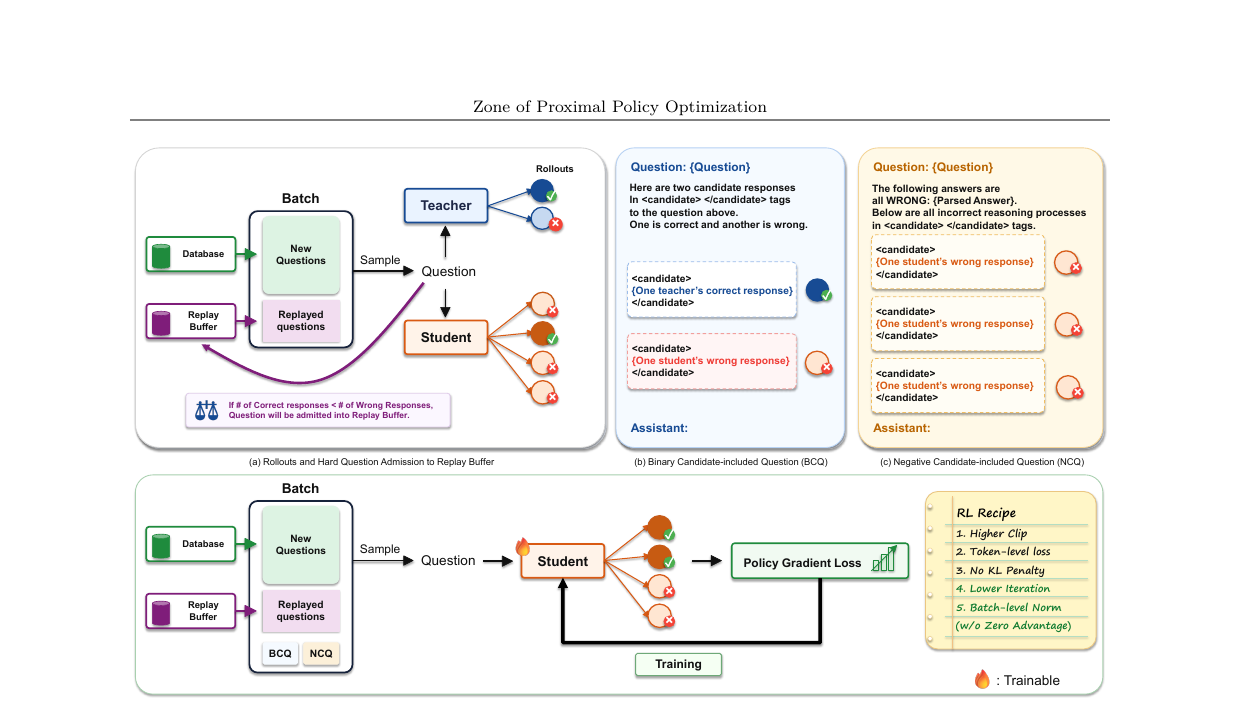
교사를 그래디언트가 아닌 프롬프트 안에 가두는 소형 VLM 포스트 트레이닝 방법론 ZPPO. 지식 증류가 OOD 일반화를 훼손하는 반면 ZPPO는 0.8B 학생에서 VLM 벤치마크 +9.3pp를 달성하면서 동시에 훈련 외 도메인도 개선합니다.
-
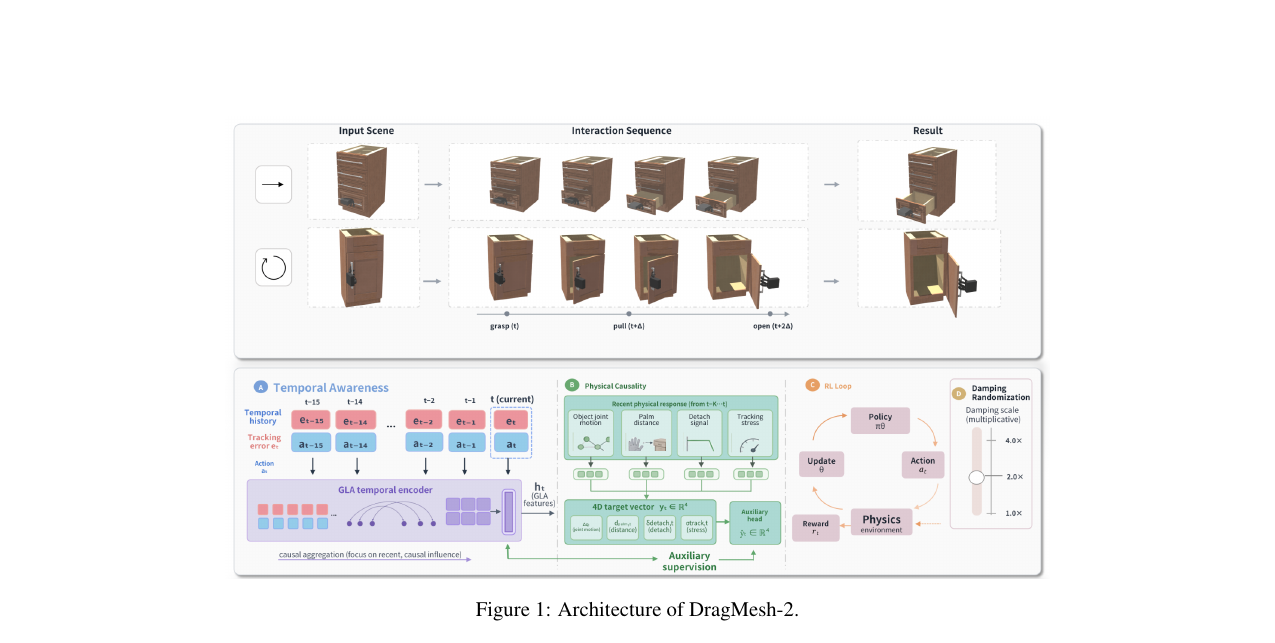 DragMesh-2 - Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects 2026-06-22
DragMesh-2 - Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects 2026-06-22관절형 오브젝트(서랍, 문)의 가동 부위를 손-핸들 접촉만으로 움직이는 접촉 주도 프레임워크 DragMesh-2. PICA는 물리 신호를 PPO에 주입해 감쇠 4배 조건에서 State-only PPO 대비 두 배 이상의 성공률을 달성합니다.
-
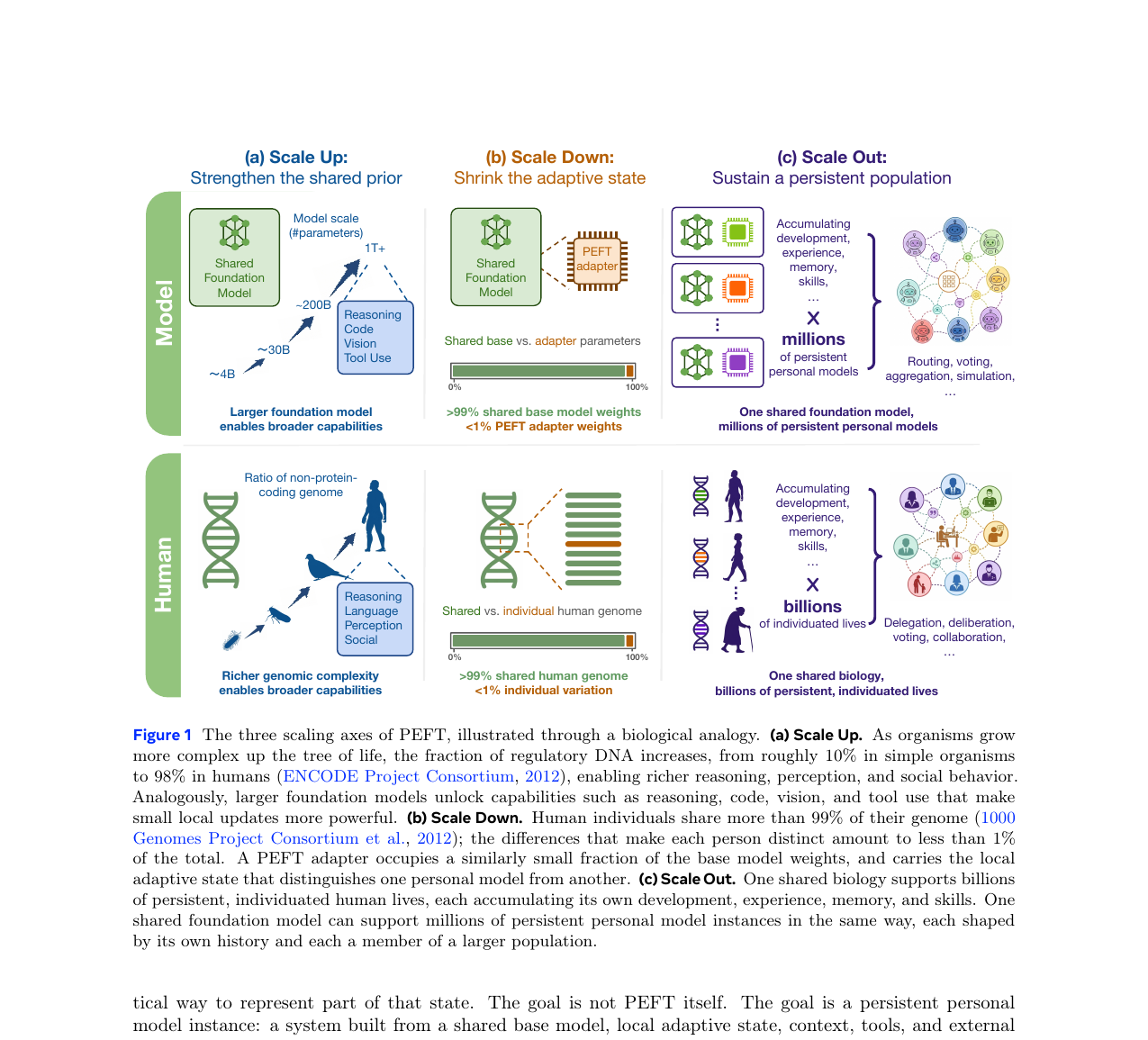
PEFT를 비용 절감 수단이 아닌 수백만 개의 퍼스널 모델을 운용하는 스케일링 메커니즘으로 재정의한 Mind Lab의 연구입니다. Scale Up, Scale Down, Scale Out 세 축의 의존 구조와 MinT 인프라를 제시합니다.
-
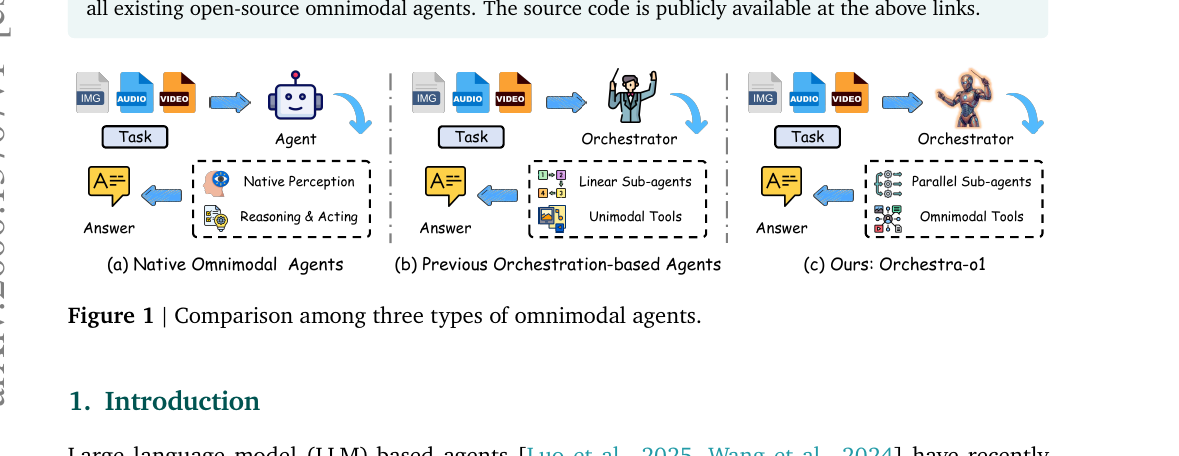 Orchestra-o1 - Omnimodal Agent Orchestration 2026-06-16
Orchestra-o1 - Omnimodal Agent Orchestration 2026-06-16CUHK·LIGHTSPEED·PKU·THU 공동 연구팀이 제안한 Orchestra-o1은 텍스트·이미지·오디오·영상을 넘나드는 복합 태스크를 오케스트레이터-서브에이전트 구조로 처리하는 옴니모달 에이전트 프레임워크입니다. OmniGAIA 벤치마크에서 Gemini-3-Pro 대비 10.3%p 높은 72.8%를 기록하며 SOTA를 세웠고, 오픈소스 모델 Orchestra-o1-8B도 30.0%로 이전 최고 기록을 9.2%p 앞질렀습니다.
-
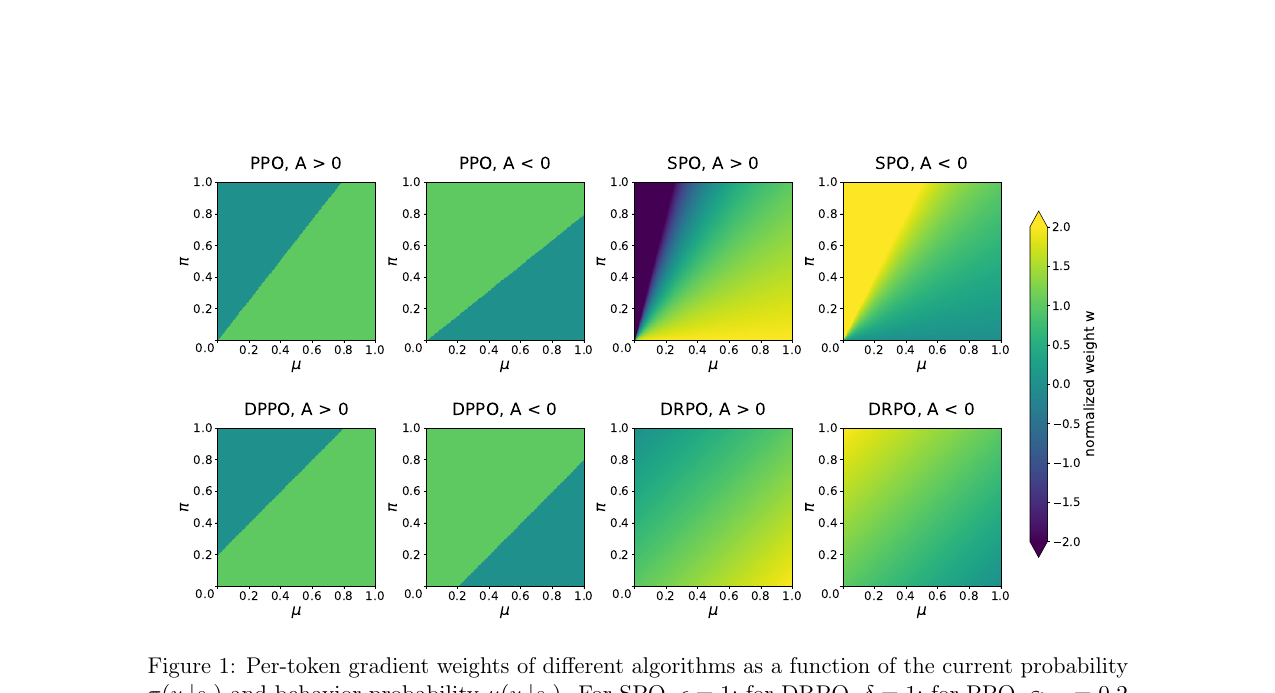
PPO와 GRPO가 long-tail 어휘에서 흔들리는 이유를 파헤치고, hard mask 대신 smooth regularizer로 trust region을 구현한 DRPO를 소개합니다. 6가지 실험 설정에서 일관되게 안정적인 학습을 보여주었습니다.
-
 DRPO 2026-06-13
DRPO 2026-06-13LLM 강화학습에서 비율 클리핑의 구조적 한계를 지적하고, 부드러운 정규화로 대체하는 DRPO(Divergence Regularized Policy Optimization) 방법론을 살펴봅니다
-
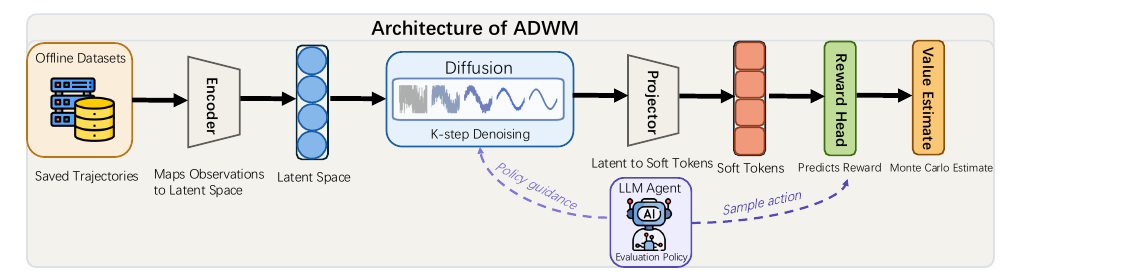
새 LLM 에이전트를 실제 환경에 굴려보지 않고 과거 로그만으로 성능을 가늠하는 오프폴리시 평가 프레임워크 ADWM을 에모리대와 상하이교통대 연구진이 내놨습니다. 핵심은 월드 모델 자체를 디퓨전 과정으로 세우고, 정책 유도 궤적 법칙을 단일 스텝 조건부로 정확히 분해해 평가 정책이 매 디노이징 스텝을 조종하게 한 것. 네 개 멀티턴 벤치마크에서 ADWM만 모든 셀에서 양의 순위 상관을 냈습니다.
-
짐 판 2026-06-06
NVIDIA AI 디렉터이자 Distinguished Scientist. GEAR Lab 공동 리더이자 휴머노이드 프로젝트 GR00T의 공동 책임자로 Physical AI를 연구합니다.
-
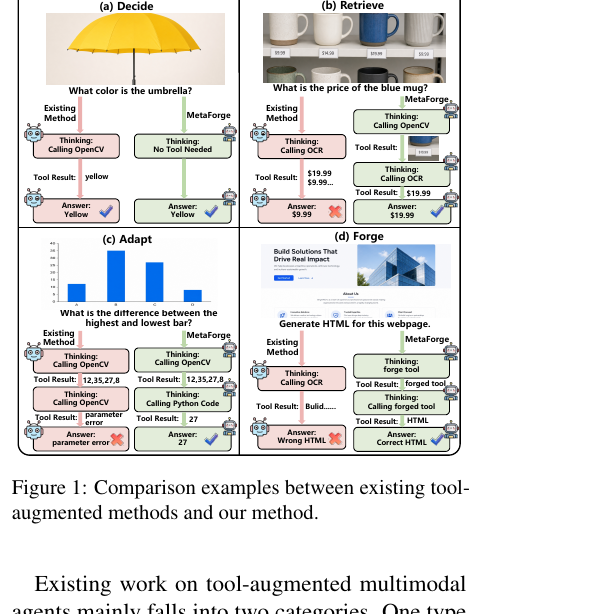 MetaForge - A Self-Evolving Multimodal Agent that Retrieves, Adapts, and Forges Tools On Demand 2026-06-04
MetaForge - A Self-Evolving Multimodal Agent that Retrieves, Adapts, and Forges Tools On Demand 2026-06-04멀티모달 에이전트는 도구를 써서 복잡한 추론을 풀지만, 미리 정해진 도구 목록은 처음 보는 상황에 일반화되지 못하고 도구를 마구 부르면 비용과 오류만 늘어납니다. MetaForge는 에이전트의 행동을 Decide, Retrieve, Adapt, Forge 네 단계로 나누고, 도구를 언제 쓸지와 도구를 어떻게 늘릴지를 강화학습으로 함께 배우게 합니다.
-
Composer 2.5 2026-05-19
Cursor가 공개한 코딩 에이전트 모델 Composer 2.5의 학습 방법과 벤치마크를 정리합니다
-
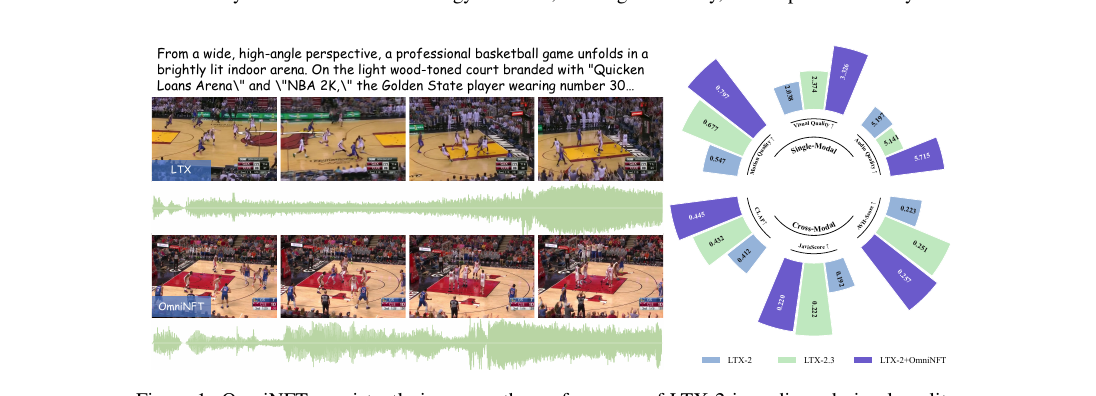
19B 규모 joint audio-video diffusion 모델 LTX-2 위에 RL fine-tuning을 얹어 영상 품질·음향 품질·립싱크를 동시에 끌어올린 OmniNFT를 정리합니다. modality-wise advantage routing, layer-wise gradient surgery, region-wise loss reweighting 세 디자인이 multi-modal RL의 reward hacking 양상을 어떻게 바꾸는지, 그리고 한국 비디오 생성 스타트업·후반 작업 도구 관점에서 어떤 의미를 갖는지 봅니다.
-
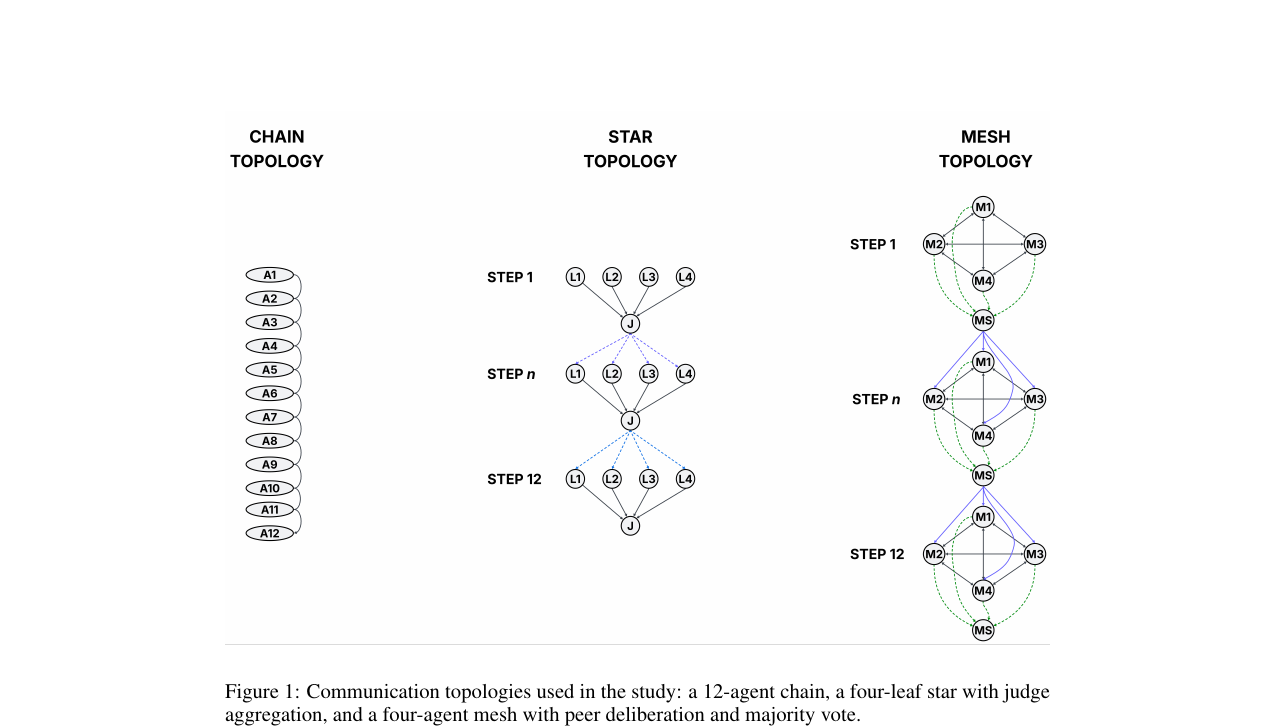
멀티에이전트 LLM 시스템의 chain·star·mesh 토폴로지를 추론을 돌리기 전에 단 세 개의 고윳값으로 진단하자는 제안. successor representation을 통신 그래프에 얹어 drift·consensus·robustness를 closed-form으로 풉니다.
-
선형 이차 조절기 2026-04-10
선형 동역학 시스템에서 이차 비용 함수를 최소화하는 최적 제어기
-
RLHF 2026-04-10
인간의 선호도 피드백으로 훈련된 보상 모델을 사용해 LLM을 정렬하는 기법
-
벨만 방정식 2026-04-10
현재 상태의 가치를 즉각 보상과 다음 상태 가치의 합으로 재귀적으로 표현하는 방정식
-
부분 관측 마르코프 결정 과정 2026-04-10
에이전트가 환경의 완전한 상태를 관측할 수 없는 강화 학습 프레임워크
-
가치 반복 2026-04-10
벨만 방정식을 반복 적용하여 최적 가치 함수를 구하는 동적 프로그래밍 알고리즘
-
적합 가치 반복 2026-04-10
연속 상태 공간에서 가치 함수를 함수 근사기로 표현하는 강화 학습 알고리즘
-
마르코프 결정 과정 2026-04-10
상태, 행동, 전이 확률, 보상으로 구성되는 강화 학습의 수학적 프레임워크
-
직접 정책 탐색 2026-04-10
가치 함수를 거치지 않고 정책 매개변수를 직접 최적화하는 강화 학습 접근법
-
가치 함수 2026-04-10
강화 학습에서 특정 상태 또는 상태-행동 쌍의 장기적인 기댓값을 나타내는 함수
-
이산화 2026-04-10
연속 상태 공간을 유한한 이산 격자로 나눠 표 형태의 강화 학습을 적용하는 기법
-
강화 학습 2026-04-10
환경과 상호작용하며 보상을 최대화하는 정책을 학습하는 머신러닝 패러다임
-
정책 반복 2026-04-10
정책 평가와 정책 개선을 교대로 수행하여 최적 정책을 찾는 강화 학습 알고리즘
-
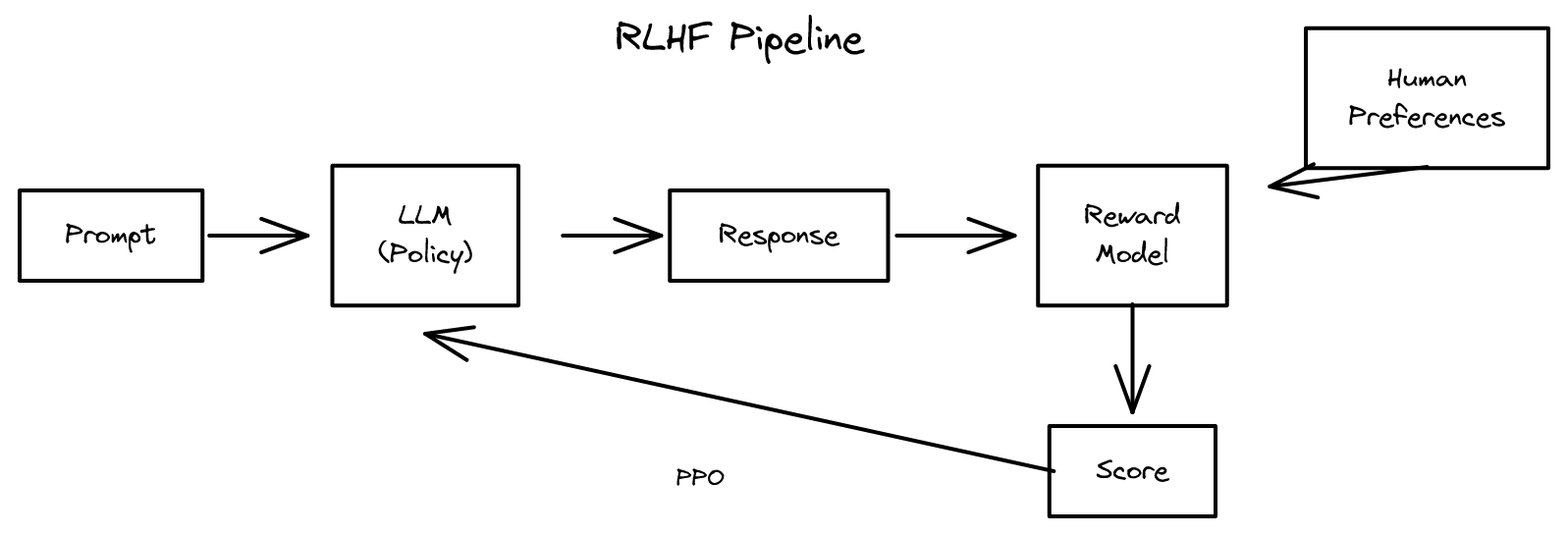 5장 - LLM 튜닝 2026-04-09
5장 - LLM 튜닝 2026-04-09인간 선호도로 LLM을 정렬하는 RLHF 파이프라인과 보상 모델, PPO를 이용한 정책 최적화, 그리고 대안인 DPO의 원리를 다룹니다
-
 16장 - 독립 성분 분석과 강화 학습 2026-03-29
16장 - 독립 성분 분석과 강화 학습 2026-03-29칵테일 파티 문제를 푸는 독립 성분 분석을 마무리하고, 마르코프 결정 과정을 중심으로 강화 학습의 기본 틀과 정책 개념을 소개합니다
-
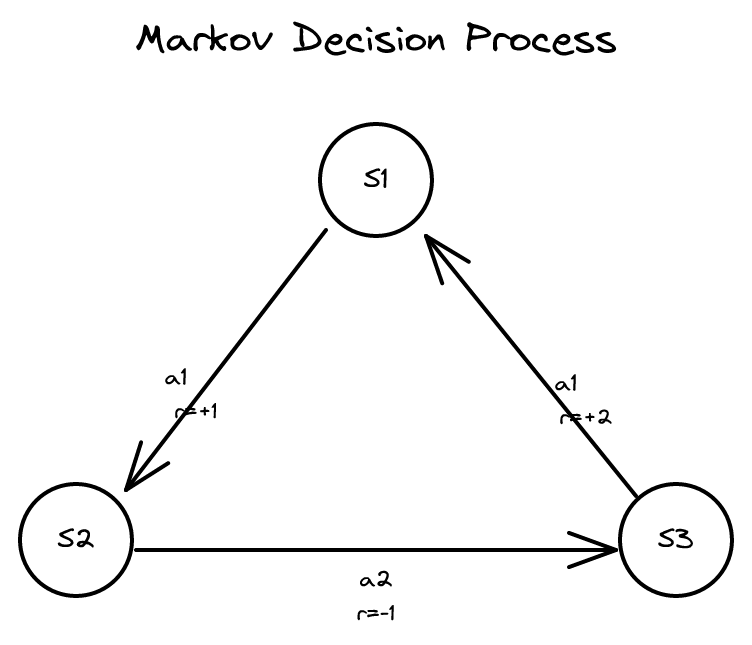 17장 - MDP와 가치 및 정책 반복 2026-03-28
17장 - MDP와 가치 및 정책 반복 2026-03-28마르코프 결정 과정의 가치 함수를 정의하고, 최적 정책을 구하는 가치 반복과 정책 반복 알고리즘, 상태 전이 확률 추정 방법을 다룹니다
-
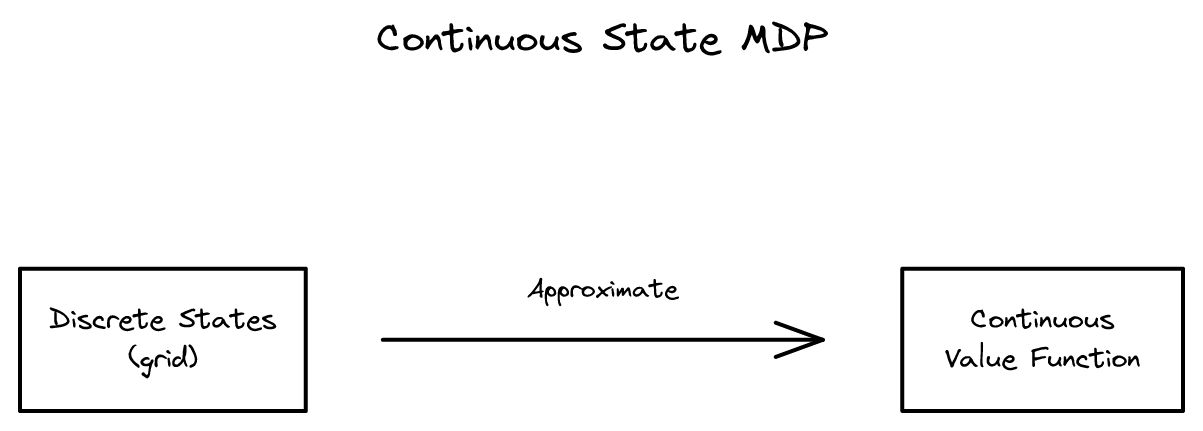 18장 - 연속 상태 MDP와 모델 시뮬레이션 2026-03-27
18장 - 연속 상태 MDP와 모델 시뮬레이션 2026-03-27연속 상태 공간을 다루는 이산화 기법의 한계를 짚고, 모델 기반 강화 학습과 시뮬레이터 구축을 거쳐 적합 가치 반복 알고리즘을 유도합니다
-
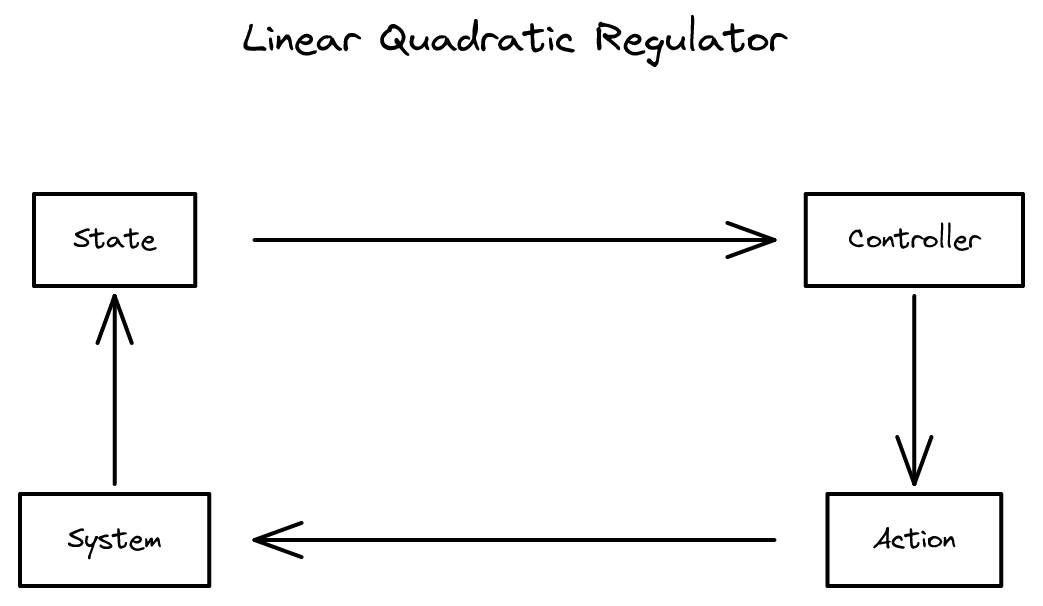 19장 - 보상 모델과 선형 동적 시스템 2026-03-26
19장 - 보상 모델과 선형 동적 시스템 2026-03-26상태 행동 보상과 유한 지평 MDP로 프레임워크를 확장한 뒤, 선형 동적 시스템에서 근사 없이 최적 정책을 계산하는 LQR을 유도합니다
-
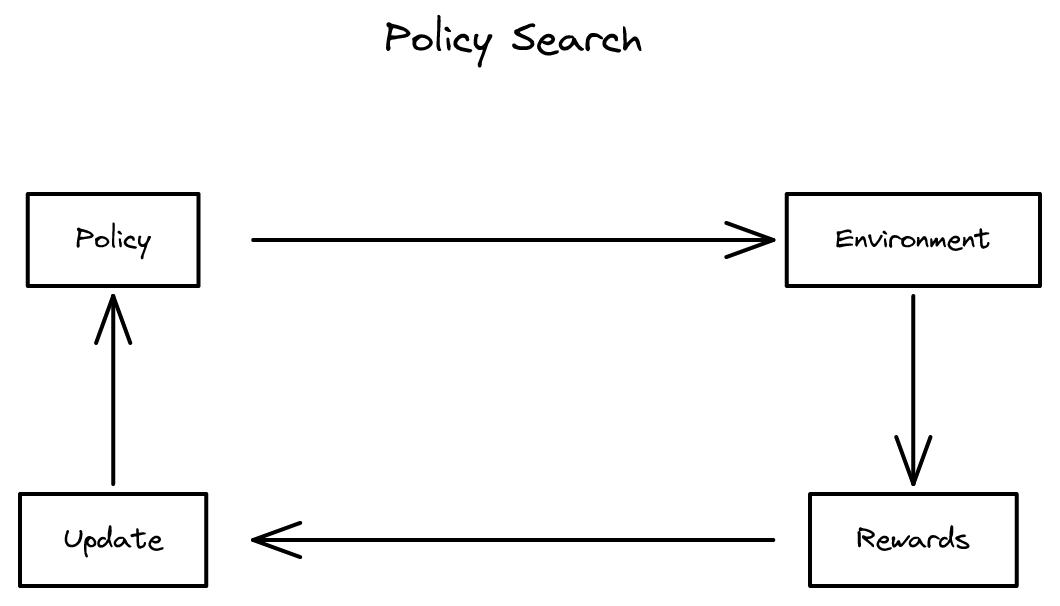 20장 - 강화 학습 디버깅과 진단 2026-03-25
20장 - 강화 학습 디버깅과 진단 2026-03-25강화 학습 프로젝트에서 시뮬레이터, 보상 함수, 알고리즘 중 병목을 진단하는 체계적 방법과, 직접 정책 탐색인 REINFORCE 알고리즘을 다룹니다
-
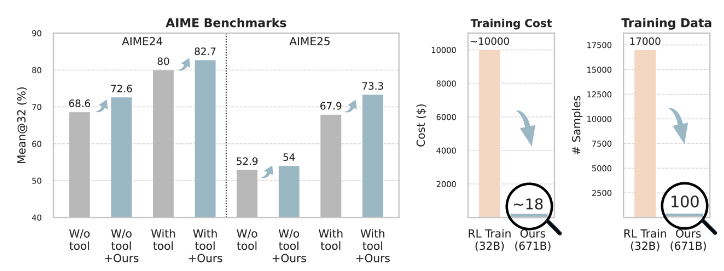
LLM의 성능 향상을 위해 강화 학습을 흔히 사용하죠. 강화 학습 훈련을 위해서는 높은 학습 비용이 필요합니다. 이 논문은 훈련 없이 프롬프트만으로 훈련 없이 강화 학습 정책을 변경합니다.
-
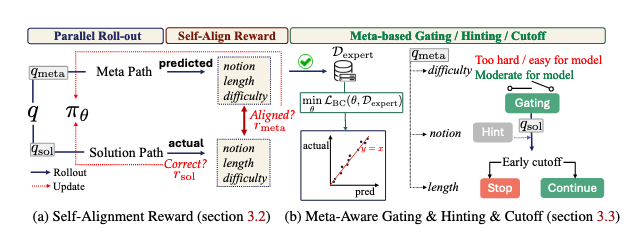
대한민국 KAIST에서 제안하는 추론 모델의 메타 인지(meta-awareness) 능력 향상 방법입니다. 이 논문은 모델이 예측한 메타 정보와 실제 추론 과정 사이의 정렬(alignment)을 통해 메타 인지 능력을 향상시키는 MASA(Meta-Awareness via Self-Alignment) 프레임워크를 제안합니다. Qwen3를 기반으로 외부 소스 없이 메타 인지를 학습합니다.
-
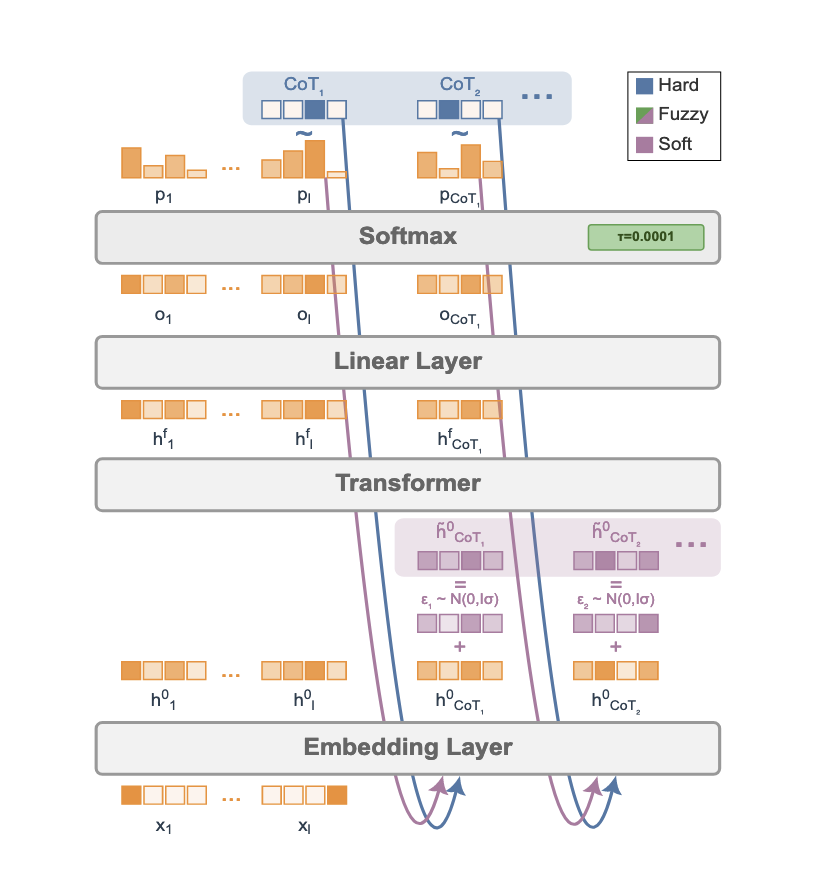 Soft Tokens, Hard Truths 2025-09-23
Soft Tokens, Hard Truths 2025-09-23대형 언어 모델(LLM)의 추론 능력은 Chain-of-Thought(CoT) 기법을 통해 크게 향상되었지만, 기존의 discrete token 기반 접근법은 여러 추론 경로를 동시에 탐색하는 데 한계가 있습니다. 이러한 한계를 극복하기 위해 continuous token을 사용한 새로운 강화학습 기반 훈련 방법을 제안합니다.
-
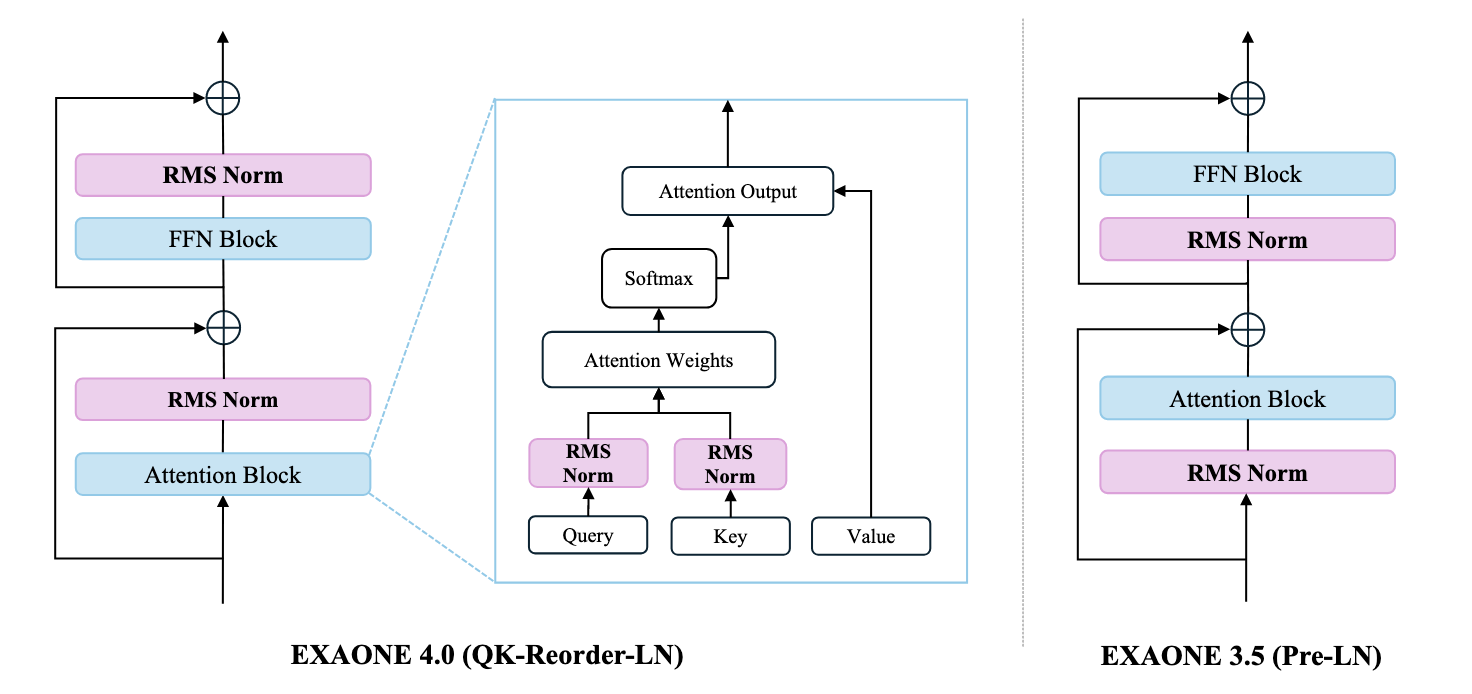
LG AI Research의 EXAONE 4.0 논문을 요약합니다. 빠른 응답의 'Non-reasoning' 모드와 깊은 사고의 'Reasoning' 모드를 통합한 하이브리드 아키텍처가 특징입니다. 모델 구조, 훈련 데이터, 혁신적인 AGAPO 강화학습 알고리즘을 중심으로 설명합니다.
-
Tianjin University 연구자. LLM 강화학습 훈련 안정성과 off-policy RFT 전문.
-
UCLA 컴퓨터과학과 부교수, UCLA AGI Lab 대표, 통계적 머신러닝과 딥러닝 이론 전문가
-
청화대학교 자동화학과 박사과정. 에이전틱 RL과 LLM 에이전트 훈련을 연구하며 SPARK, SDAR, OPID 등을 발표한 연구자.
-

DrLIM·연속 학습·로봇 RL의 권위자, Google DeepMind VP of Research, 인문학 학부에서 ML 박사로 전환한 이력
-
Google DeepMind 디스팅귀시드 리서치 사이언티스트. TrueSkill 개발자, AlphaGo 공저자. 2025년 복귀 후 post-AGI 미래 팀을 이끌고 있습니다.
-
미국 수학자·전산학자. 노스이스턴대 교수. 역전파 1986 Nature 논문 3저자이자 REINFORCE 정책 그래디언트의 창시자.
-
텐센트 AI Applications 디렉터. MOBA 게임을 심층강화학습으로 정복한 JueWu(絕悟)로 알려진 대규모 ML·AI 에이전트 연구자. NTU 박사.
-
USTC 박사과정. masked image generation·autoregressive image generation에 GRPO 계열 정책 최적화를 적용해온 1저자로, OmniNFT에서는 joint audio-video diffusion으로 RL 프레임워크를 확장.
-
Tianjin University 부연구원. Deep RL 불안정성(plasticity loss, policy churn) 연구자.
-
Group Relative Policy Optimization. 가치 함수 없이 그룹 내 상대 보상으로 정책을 갱신하는 강화학습 기법
-
상하이교통대(SJTU) 컴퓨터과학부 교수. 강화학습·에이전트 AI·임바디드 AI 분야의 대가로 논문 200편 이상, 피인용 3만 회를 넘습니다.
-
상하이교통대 John Hopcroft Center 테뉴어트랙 부교수. 강화학습·레스트리스 밴딧·온라인 순차 의사결정·에이전트를 연구하며 하버드 박사후연구원을 거쳤습니다.
-
ServiceNow AI 수석 연구 과학자, Mila 겸임 교수. 멀티모달 지각과 세계 표현 연구.
-
Moonshot AI 공동 창업자 겸 CEO, Transformer-XL·XLNet 제1저자, Kimi 시리즈 총괄
-
UC 버클리 박사과정 연구자. 오프라인·비지도 강화학습과 RL 확장성 연구자.
-
천진대학교 교수. Deep Reinforcement Learning Lab 주재. 다중 에이전트·LLM RL 연구.
-
Princeton 전기컴퓨터공학과 교수, 강화학습 이론과 LLM 에이전트 학습 연구
-
H Company의 모델링 총괄. Holo 컴퓨터 유즈 VLM 라인업을 이끄는 연구자
-
Tencent Hunyuan 수석 연구과학자. 멀티모달 RL 테크리드. 생성 모델·강화학습·신뢰할 수 있는 AI 전문가.
-
미국 에모리대 컴퓨터과학과 교수. 오프라인 강화학습과 오프폴리시 평가(OPE)를 의료 의사결정에 적용해 온 연구자입니다.
-

UC 버클리 교수. 박사 시절 강화학습으로 헬리콥터에게 틱톡, 카오스 등 최상위 인간 조종사급 곡예비행을 가르쳤다
-
싱가포르국립대(NUS) 연구원. LLM 강화학습의 trust region 문제 전문가. DPPO 제안자.
-
천진대학교 특별채용 부교수. RL, 구현 AI, LLM 에이전트 연구. 60편 이상의 주요 학회 논문.
-
Princeton 전기컴퓨터공학과 박사후연구원, Gen-Verse 리더, 확산 모델과 에이전트 RL 연구
-
미국 에모리대 컴퓨터과학과 연구자. LLM 에이전트의 오프폴리시 평가와 디퓨전 월드 모델을 연구합니다.