DanceOPD - On-Policy Generative Field Distillation
W. Zhou, X. Zhu, Z. Xu, B. Dong, L. Gong, Y. Liang, M. Chu, L. Qu, L. Kong, W. Liu, and T.-S. Chua, "DanceOPD: On-Policy Generative Field Distillation," arXiv:2606.27377, 2026.
현대 이미지 생성 모델에는 세 가지 핵심 능력이 공존해야 합니다. 텍스트로 이미지를 만드는 T2I(text-to-image), 특정 요소만 바꾸는 로컬 편집, 전체 스타일이나 분위기를 바꾸는 글로벌 편집입니다. 문제는 이 세 능력이 근본적으로 충돌한다는 점입니다. 편집은 원본을 보존해야 하고, T2I는 자유로운 생성을 원하며, 로컬과 글로벌 편집은 보존 범위를 두고 서로 당깁니다.
ByteDance Seed와 NUS 연구팀이 6월 제안한 DanceOPD는 이 충돌을 "각 능력을 velocity field로 분리해 학생이 자신의 rollout에서 쿼리하도록 훈련"하는 방식으로 해결합니다.
저자
Wei Liu가 교신 저자이며, Tat-Seng Chua가 시니어 저자를 맡았습니다. Wei Zhou가 1저자로 ByteDance Seed에서 작업을 주도했습니다.
Wei Liu는 ByteDance Seed Vision 팀의 연구과학자로, Seedream 4.0과 4.5의 편집 데이터 파이프라인 및 공동 훈련 알고리즘 설계를 이끌어온 연구자입니다. Tat-Seng Chua는 NUS NExT++ 연구소를 공동 설립한 싱가포르 AI 분야 석학으로, 멀티모달 기반 모델과 신뢰 가능한 AI를 오랜 시간 연구해 왔습니다. Seedream을 실제로 훈련한 팀과 멀티모달 분야 최고 연구자가 손을 잡은 형태입니다.
배경
기존 다중 능력 합성 방법들은 크게 세 가지 접근을 취했습니다.
- 데이터 혼합 / 공동 훈련: 여러 능력을 하나의 학습으로 섞습니다. 능력별 감독 신호가 희석되고, 그레이디언트 충돌이 발생합니다.
- 파라미터 공간 병합: 여러 모델의 가중치를 합칩니다. 항상 타협점에서 멈춥니다.
- 추론 시 점수 합성: 각 능력 모델의 출력을 실시간으로 합산합니다. 합성이 배포된 학생 모델 바깥에서 일어나므로 추론 비용이 그대로 남습니다.
이 세 방법은 "어떤 상태에서 어떤 교사 필드를 쿼리하고 그 결과를 어떻게 학습에 반영할 것인가"라는 설계 문제를 회피합니다. DanceOPD는 그 설계 문제를 정면으로 다룹니다.
Generative Field란
DanceOPD는 각 능력 소스(T2I 모델, 편집 모델, 스타일 모델 등)를 velocity field로 정의합니다.
\[v_m(z_t, t, c), \quad m \in \{1, \ldots, M\}\]
여기서 \(z_t\)는 flow state, \(t\)는 timestep, \(c\)는 텍스트 프롬프트나 소스 이미지 같은 조건 정보입니다. 각 소스는 동일한 latent state space 위에 정의된 velocity field이므로, 능력 합성 문제는 이 필드들에 대한 field-query 문제로 바뀝니다.
세 가지 설계 질문이 파생됩니다. 어떤 필드가 각 샘플을 감독할 것인가, 어느 상태에서 필드를 쿼리할 것인가, 하나의 rollout에서 몇 개 상태를 사용할 것인가.
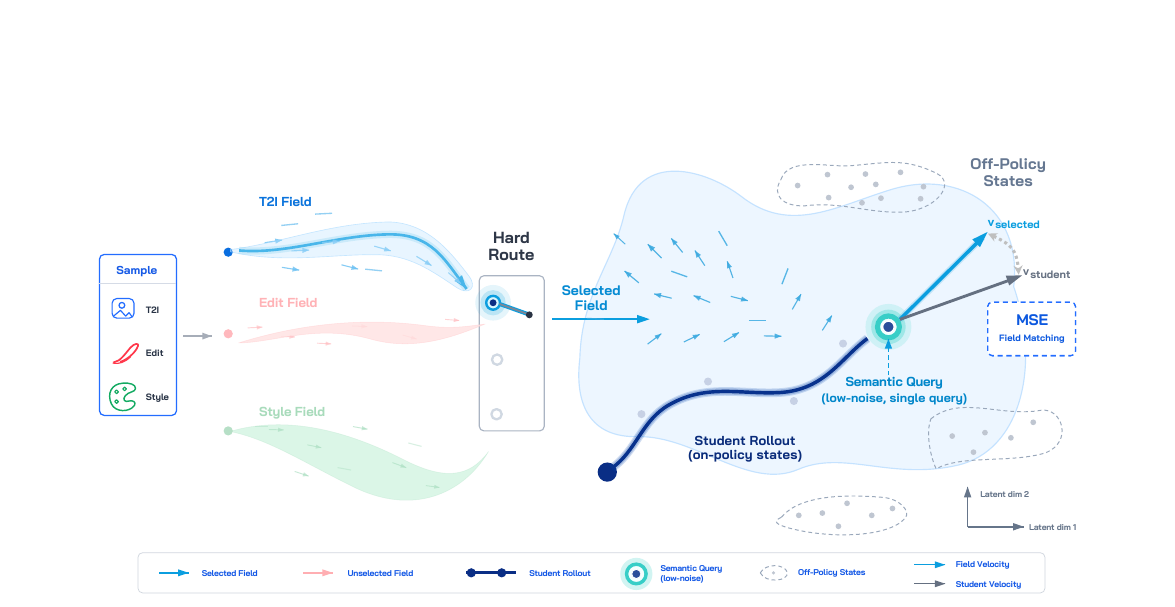
DanceOPD의 세 가지 설계 원칙이 각 질문에 대응합니다.
어떻게 만들었나
Hard-routed sample-wise field matching
첫 번째 문제: 어떤 필드가 샘플을 감독할 것인가.
나이브한 방법은 여러 필드를 하나의 타깃으로 평균하는 것입니다. 그러나 T2I와 편집 필드를 평균하면 그 결과는 어느 능력에도 대응하지 않는 방향이 됩니다. 멀티태스크 최적화 연구는 이를 "그레이디언트 방향이 나쁘게 정렬되면 평균이 어느 과제도 진전시키지 않는다"고 오래전부터 지적해 왔습니다.
DanceOPD는 각 학습 샘플을 정확히 하나의 능력 필드로 라우팅합니다.
\[m \sim \pi(m), \quad (x, c) \sim \mathcal{D}_m\]
T2I 샘플은 T2I 필드를, 편집 샘플은 편집 필드를 쿼리합니다. 라우팅 확률 \(\pi\)는 기본적으로 균일 분포(1:1)이며, 능력 합성은 샘플별 업데이트의 통계적 누적으로 달성됩니다. 개별 쿼리는 항상 의미론적으로 명확합니다.
On-policy field querying
두 번째 문제: 어느 상태에서 필드를 쿼리할 것인가.
현재 학생이 합성 능력을 학습하고 나면, 그 학생이 실제 생성 시 거치는 rollout 경로는 어떤 단일 교사 모델의 경로와도 다릅니다. 교사 경로나 데이터 상태에서 쿼리하면 훈련과 추론 사이에 상태 분포 불일치가 생깁니다.
DanceOPD는 현재 학생의 자체 rollout에서 상태를 뽑아 쿼리합니다.
\[z_{0:T}^\theta = \text{Rollout}(v_\theta; z_T, c), \quad z_T \sim p_T\]
stop-gradient 연산자를 적용해 \(\tilde{z}_t = \text{sg}(z_t^\theta)\)를 쿼리 상태로 삼습니다. 이 stop-gradient는 업데이트가 롤아웃 솔버 전체가 아닌 로컬 velocity 예측만 조정하도록 만듭니다. 이것이 flow-matching 모델에서의 on-policy distillation이 작동하는 핵심 원리입니다.
Semantic-side single query
세 번째 문제: 하나의 rollout에서 몇 개 상태를 사용할 것인가.
한 rollout의 여러 상태를 동시에 쓰면 상태들이 같은 초기 노이즈, 같은 프롬프트, 같은 학생 dynamics를 공유해 그레이디언트가 상관관계를 갖게 됩니다. 더 많은 쿼리가 더 독립적인 감독을 제공하지 않습니다.
DanceOPD는 rollout당 하나의 쿼리만 사용하되, 의미 정보가 가장 집중된 저노이즈 (semantic side) 상태를 선택합니다.
\[K = 1, \quad s \sim q_\text{sem}(s), \quad t = t(s)\]
고노이즈 상태는 범용적인 잡음 제거 신호가 지배적이어서 능력별 특이성이 약합니다. 저노이즈 상태에서 스타일, 조명, 국소 속성 같은 편집 관련 정보가 집중됩니다. 하나의 저노이즈 쿼리는 다중 고노이즈 쿼리보다 높은 정보 밀도를 가집니다.
목적 함수
훈련 목적 함수는 라우팅된 필드에 대한 단순 velocity MSE입니다.
\[\mathcal{L}_\text{DanceOPD} = \mathbb{E}_{m \sim \pi,\, (x,c) \sim \mathcal{D}_m,\, z_T \sim p_T,\, s \sim q_\text{sem}} \left[ \left\| v_\theta(\tilde{z}_t, t, c) - v_m(\tilde{z}_t, t, c) \right\|_2^2 \right]\]
Appendix §7.1에서 저자들은 이 MSE가 등방성 Gaussian 전이 커널 하에서 KL-스타일 로컬 매칭과 동일함을 보입니다. KL-가중 MSE, 일관성 매칭, DMD2 등 여러 대안과 비교했을 때도 plain MSE가 가장 안정적이고 평균 성능이 높았습니다(+2.8%~+4.5%).
동일한 공식이 operator-defined 필드에도 적용됩니다. Classifier-free guidance(CFG)는 다음과 같이 정의되는 guided velocity field로 볼 수 있습니다.
\[v_\alpha(z_t, t, c) = v_\emptyset(z_t, t) + \alpha\bigl(v_\text{cond}(z_t, t, c) - v_\emptyset(z_t, t)\bigr)\]
이 필드도 동일한 MSE로 학생에게 흡수시킬 수 있습니다. CFG를 추론 시마다 계산하는 대신 훈련으로 내재화하는 것입니다.
결과
Z-Image 기반 모델로 GEditBench (편집 품질)과 GenEval (T2I 품질)을 동시에 평가했습니다. 두 지표가 모두 높아야 하는 것이 핵심 과제입니다.
A. T2I + 편집 합성 결과
방법 |
GEditBench 평균 |
GenEval 종합 |
|---|---|---|
Joint Training |
4.617 |
0.808 |
Off-Policy Distill |
4.528 |
0.818 |
DiffusionOPD |
4.947 |
0.833 |
Flow-OPD |
4.681 |
0.822 |
DanceOPD (Ours) |
5.347 |
0.849 |
편집 교사 (참고) |
4.930 |
0.711 |
DanceOPD는 가장 강력한 OPD 베이스라인인 DiffusionOPD보다 GEditBench 평균 8.1% 높으며, GenEval에서도 비교 대상 중 최고입니다. 특히 배경 변경(+21.9%), 스타일 변경(+21.3%) 등 큰 시각적 변화가 필요한 편집 카테고리에서 격차가 두드러집니다.
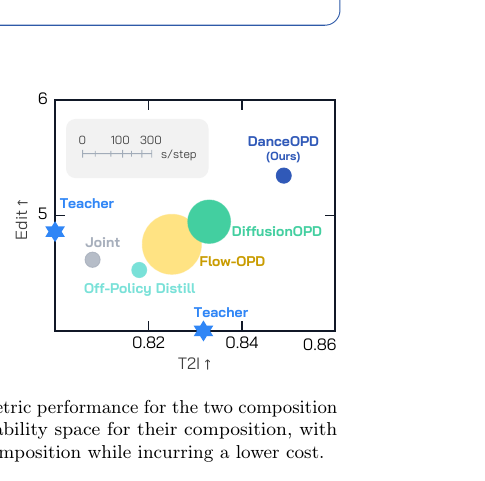
산점도에서 DanceOPD(파란 점)는 Edit 축과 T2I 축 모두에서 가장 높은 오른쪽 상단에 위치하며, 버블 크기(스텝당 훈련 비용)는 DiffusionOPD나 Flow-OPD보다 작습니다.
B. 로컬 + 글로벌 편집 합성 결과
방법 |
GEditBench 평균 |
GenEval 종합 |
|---|---|---|
Joint Training |
4.546 |
0.821 |
Off-Policy Distill |
~4.74 |
0.798 |
DiffusionOPD |
~4.66 |
0.818 |
Flow-OPD |
4.679 |
0.827 |
DanceOPD (Ours) |
5.498 |
0.848 |
로컬 편집(보존 강조)과 글로벌 편집(변환 강조)은 본질적으로 대립하는 능력입니다. DanceOPD는 최고 경쟁 베이스라인보다 GEditBench 평균 16.1% 높고, GenEval도 전 비교 모델 중 최고입니다. 배경 변경(+33.5%), 스타일 변경(+12.9%), 색상 변경(+11.6%)에서 특히 큰 폭으로 개선됩니다.
C. 리얼리즘 필드 흡수
SD3.5-M 모델에서 리얼리즘 지향 교사 필드를 흡수하는 실험입니다. Off-policy 증류 대비 realism reward 9.9% 향상, 학생-교사 gap의 85.3%를 회복했습니다. 동시에 T2I 점수는 off-policy 수준의 0.1% 이내를 유지합니다.
Ablation: 세 설계 선택 각각의 기여
비교 |
GEditBench 변화 |
|---|---|
Hard routing vs. 소프트 믹싱 (MSE) |
+15.2% |
Hard routing vs. 소프트 믹싱 (KL) |
+10.6% |
저노이즈 쿼리 vs. 중간 노이즈 |
+23.7% |
저노이즈 쿼리 vs. 고노이즈 |
+19.5% |
단일 쿼리 vs. 2개 쿼리 (K=2) |
+16.6% |
단일 쿼리 vs. 16개 쿼리 (K=16) |
+12.2% |
세 설계 선택(하드 라우팅, on-policy 쿼리 상태, 단일 저노이즈 쿼리)은 각각 독립적으로 큰 폭의 성능 향상을 가져옵니다. 밀집 쿼리(K=2, G=3)를 SDE rollout으로 보정하면 일부 회복되지만(+18.4%), 단일 쿼리 기본값보다 여전히 8.6% 낮습니다. 저자들은 이를 "부상당하지 않는 것이 치료보다 낫다"는 원칙의 실험적 확인으로 제시합니다.
회고
저자들은 §6에서 두 가지 한계를 솔직하게 인정합니다.
공유 필드 지원 가정. 현재 공식은 모든 능력 소스가 같은 backbone family에서 나온다고 전제합니다. 동일한 latent 표현, 동일한 스케줄러, 동일한 velocity 파라미터화가 필요합니다. 서로 다른 아키텍처 기반의 모델들을 합성하려면 공유 상태 공간을 맞추는 별도 작업이 선행되어야 합니다.
사전 정의 라우팅의 한계. DanceOPD의 라우팅은 데이터 타입이나 과제 정체성으로 미리 정해집니다. 이 방식은 T2I, 로컬 편집, 글로벌 편집처럼 경계가 명확한 경우에는 안정적입니다. 그러나 "리얼리즘 스타일로 황혼 무렵의 도심을 그려줘"처럼 단일 프롬프트가 여러 능력을 동시에 요구하면, 어느 필드로 라우팅해야 하는지 애매해집니다. 저자들은 verifier나 reward model을 결합하는 방향을 미래 연구로 남깁니다.
abstract와 본문 숫자 불일치: abstract는 T2I+편집 실험에서 GEditBench 개선을 "편집 소스 대비 8.5%, 베이스라인 대비 8.1%"로 적었고 본문 §4.1도 같은 수치를 씁니다. 일치합니다.
정리
- 능력은 평균이 아니라 라우팅으로 합성한다. 여러 velocity field를 하나의 샘플 타깃으로 섞으면 semantic identity가 사라지고 그레이디언트 충돌로 이어집니다. DanceOPD의 hard routing은 각 쿼리가 의미론적으로 명확한 상태를 유지하게 만듭니다.
- 학생 자신의 rollout이 쿼리 위치를 결정한다. 교사 경로나 데이터 상태에서 쿼리하면 훈련-추론 간 covariate shift가 남습니다. On-policy 쿼리는 이 간극을 닫습니다.
- 저노이즈 단일 쿼리가 다중 고노이즈 쿼리보다 강하다. Trajectory-query correlation을 피하면서 능력별 정보가 가장 집중된 구간을 쓰는 것이 핵심입니다.