DragMesh-2 - Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects
T. Zhang, Y. Duan, Y. Li, Z. Zhang, and H. Tang, "DragMesh-2: Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects," arXiv:2606.15133, 2026.
저자
Tianshan Zhang, Yijia Duan, Yanjun Li 세 명이 공동 1저자로 참여했습니다. Zeyu Zhang이 프로젝트 리더를 맡았으며, 교신저자는 Hao Tang입니다. 전원 베이징대학교(PKU) 컴퓨터과학대학 소속입니다. Tang은 2024년 7월 PKU에 조교수로 부임해 Embodied and Generative Intelligence Lab을 이끌고 있습니다. 이번 논문은 같은 팀이 2025년 발표한 DragMesh 1의 문제의식을 물리 기반 로보틱스로 확장한 결과물입니다. DragMesh 1은 사용자의 드래그 인터랙션으로 관절 운동을 생성하는 객체 중심(object-centric) 방식이었고, 여기서 한 발 더 나아가 실제 손이 물체를 접촉해 움직이는 구조로 바꾸었습니다.
배경
서랍을 당기거나 냉장고 문을 여는 동작은 사람에게는 자연스럽지만 로봇에게는 구조적으로 까다롭습니다. 관절형 오브젝트의 가동 부위는 직접 명령으로 제어할 수 없습니다. 손이 핸들에 닿아야 하고, 그 접촉을 유지해야만 부위가 움직입니다. 접촉이 끊기면 진행이 멈추고, 힘을 가하는 방향이 조금만 틀어져도 손이 핸들에서 미끄러집니다.
기존 강화학습 기반 방법들은 태스크 완료를 유일한 목표로 최적화합니다. 이 방식의 문제는 공칭(nominal) 감쇠 조건에 과적합한다는 점입니다. 학습 시 설정한 감쇠가 2배, 4배로 커지면 성능이 급격히 떨어집니다. 접촉을 유지하는 안정적인 행동을 배운 게 아니라, 명목상 성공하는 지름길을 배웠기 때문입니다.
논문은 이를 "명목 성공이 안정적 접촉 행동을 보장하지 않는다"는 핵심 관찰로 정식화합니다. 그리고 물리 신호를 정책 학습에 직접 주입해 접촉 조건이 바뀌어도 버티는 정책을 만드는 방향을 제안합니다.
어떻게 만들었나
접촉 주도 과제 정식화
DragMesh-2는 51-DoF SMPL-X 손(가상 손목 6개 + 손가락 관절 45개)을 사용합니다. 정책의 행동 공간은 손 관절 위치에 대한 51차원 증분이며, 물체 관절에 대한 직접 제어 채널은 없습니다. 가동 부위는 오직 시뮬레이션 물리 엔진 안에서 손이 핸들과 접촉함으로써만 움직입니다.
각 GAPartNet 오브젝트에서 운동 범위가 가장 큰 관절을 목표로 선택합니다. 성공 기준은 기준 궤적의 최소-최대 범위를 기준으로 정의되므로 서랍(프리즘 관절), 문(회전 관절), 슬라이더를 동일한 척도에서 비교할 수 있습니다:
\[q_{\text{done}} = q_{\min}^{\text{traj}} + \rho\left(q_{\max}^{\text{traj}} - q_{\min}^{\text{traj}}\right)\]
태스크 진행도는 오브젝트별 운동 범위로 정규화합니다:
\[p_t = \max\left(0,\, \frac{q_t^o - q_{\text{start}}}{q_{\text{goal}} - q_{\text{start}}}\right)\]
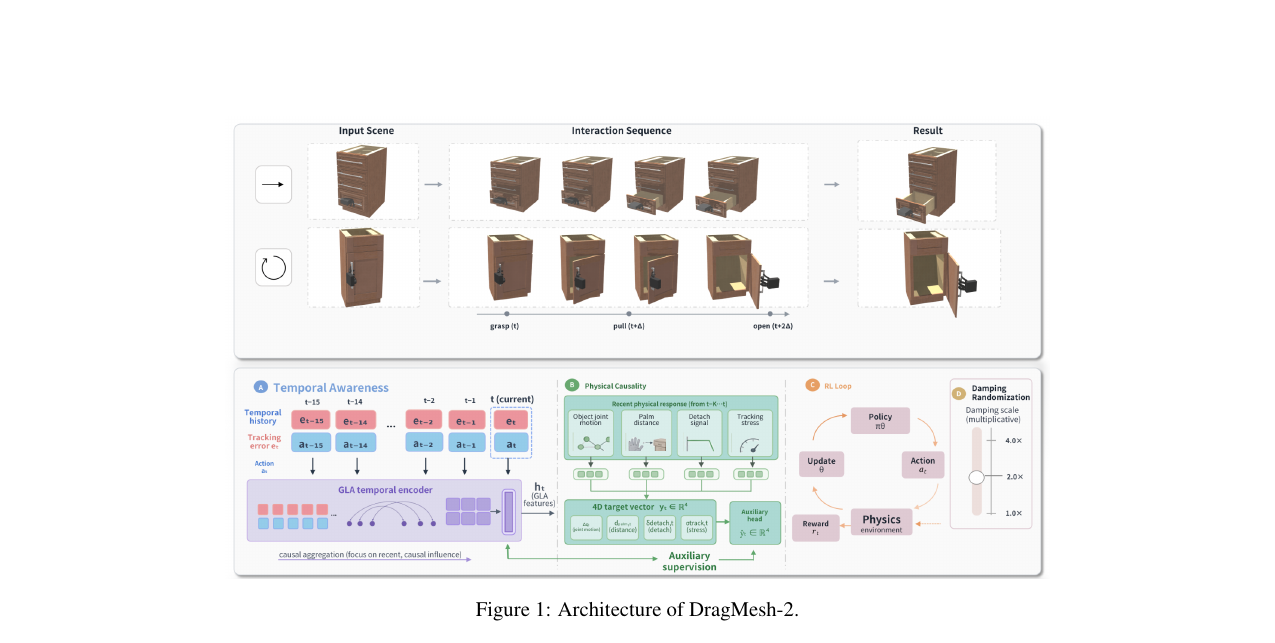
PICA: 물리 인지 접촉 인식 학습
PICA(Physically Informed Contact-Aware)는 기존 PPO 프레임워크에 네 가지 물리 신호를 결합합니다.
접촉 유지 보상과 행동 경계 정규화. 손-핸들 거리 \(d_t\)가 안전 거리 \(d_{\text{safe}}\)를 넘으면 페널티를 부과합니다. 행동 크기가 포화 임계값 \(a_{\text{sat}}\)을 초과하면 추가 페널티를 부과해 포화 상태로 밀어붙이는 지름길을 억제합니다:
\[r_{\text{bound}} = -w_{\text{bound}} \, \text{mean}\!\left(\max(|a_t| - a_{\text{sat}},\, 0)^2\right)\]
\[r_{\text{contact}} = -w_{\text{contact}} \, \max(d_t - d_{\text{safe}},\, 0)^2\]
이를 포함한 전체 보상은 다음과 같습니다:
\[r_t = r_{\text{task}} + r_{\text{dist}} + r_{\text{act}} + r_{\text{time}} + r_{\text{detach}} + r_{\text{success}} + r_{\text{bound}} + r_{\text{contact}}\]
감쇠 무작위화. 훈련 시 매 에피소드 시작 시 감쇠 배율을 \([1.0, 2.0]\) 범위에서 무작위로 샘플링합니다. 다양한 저항 조건에서 당기기 응답을 경험하게 함으로써 단일 역학 조건 의존을 줄이고, 평가에서 사용하는 ×4 감쇠에 대한 OOD 강건성의 기반이 됩니다.
GLA 시간적 인코더와 접촉 이력 감독. 단일 프레임 관측으로는 접촉이 안정적인지, 손이 핸들에서 이탈하려는지를 추론하기 어렵습니다. PICA는 최근 제어 이력 \(H_t = [h_{t-L+1}, \ldots, h_t]\)를 GLA(Gated Linear Attention) 인코더로 처리합니다. 각 이력 토큰은 PD 추적 오차와 이전 행동으로 구성됩니다:
\[h_t = [e_t,\, a_{t-1}], \quad e_t = q_t^{\text{PD}} - q_t^h\]
GLA 인코더가 만든 접촉 이력 특징 \(z_t^{\text{hist}}\)는 보조 헤드를 통해 인과 윈도우 내 접촉 응답을 예측하도록 추가 감독됩니다:
\[y_t = \left[q_t^o - q_{t-K}^o,\; \max_{\tau \in [t-K,t]} d_\tau,\; \mathbb{1}\!\left(\max_\tau d_\tau > d_{\text{detach}}\right),\; \max_{\tau \in [t-K,t]} \|e_\tau\|_2 \right]\]
네 채널은 각각 최근 물체 관절 응답, 최대 손-핸들 거리, 이탈 위험, 추적 스트레스입니다. 이 보조 손실과 PPO 손실을 합산한 전체 정책 손실은 다음과 같습니다:
\[\mathcal{L} = \mathcal{L}_{\text{PPO}} + c_v \mathcal{L}_V + c_b \mathcal{L}_{\text{bounds}} + w_{\text{aux}} \mathcal{L}_{\text{aux}}\]
데이터셋
학습의 출발점이 되는 기준 접촉 궤적은 별도의 학습 없이 GAPartNet의 기하학과 모빌리티 주석만으로 생성합니다. 손 접근, 파악, 당기기, 놓기의 4단계로 구성된 277개 궤적이 7개 카테고리에 걸쳐 생성됩니다. 이 데이터셋은 정책이나 물리 엔진에 독립적이라 재사용과 재생성이 용이합니다.
결과
7개 GAPartNet 오브젝트(식기세척기, StorageFurniture, 마이크로웨이브 등 3개 카테고리)를 대상으로 세 가지 감쇠 배율에서 평가했습니다. ×1은 공칭, ×2는 완만한 OOD, ×4는 강한 OOD 조건입니다. 각 조건마다 20개 에피소드씩, 결정론적(Gaussian 평균)과 확률적(정책 샘플링) 두 모드로 평가합니다.
방법별 성공률 (결정론적 / 확률적, 7객체 평균)
방법 |
×1 |
×2 |
×4 |
|---|---|---|---|
Trajectory Tracking |
1.00 / - |
0.71 / - |
0.71 / - |
GT Parallel-Jaw |
0.14 / - |
0.14 / - |
0.14 / - |
State-only PPO |
0.58 / 0.44 |
0.44 / 0.35 |
0.27 / 0.26 |
Flat-history PPO |
0.43 / 0.34 |
0.36 / 0.19 |
0.32 / 0.21 |
GRU-PPO |
0.51 / 0.44 |
0.33 / 0.27 |
0.28 / 0.28 |
Transformer-PPO |
0.35 / 0.25 |
0.23 / 0.11 |
0.11 / 0.04 |
PICA (Ours) |
0.89 / 0.82 |
0.80 / 0.72 |
0.56 / 0.43 |
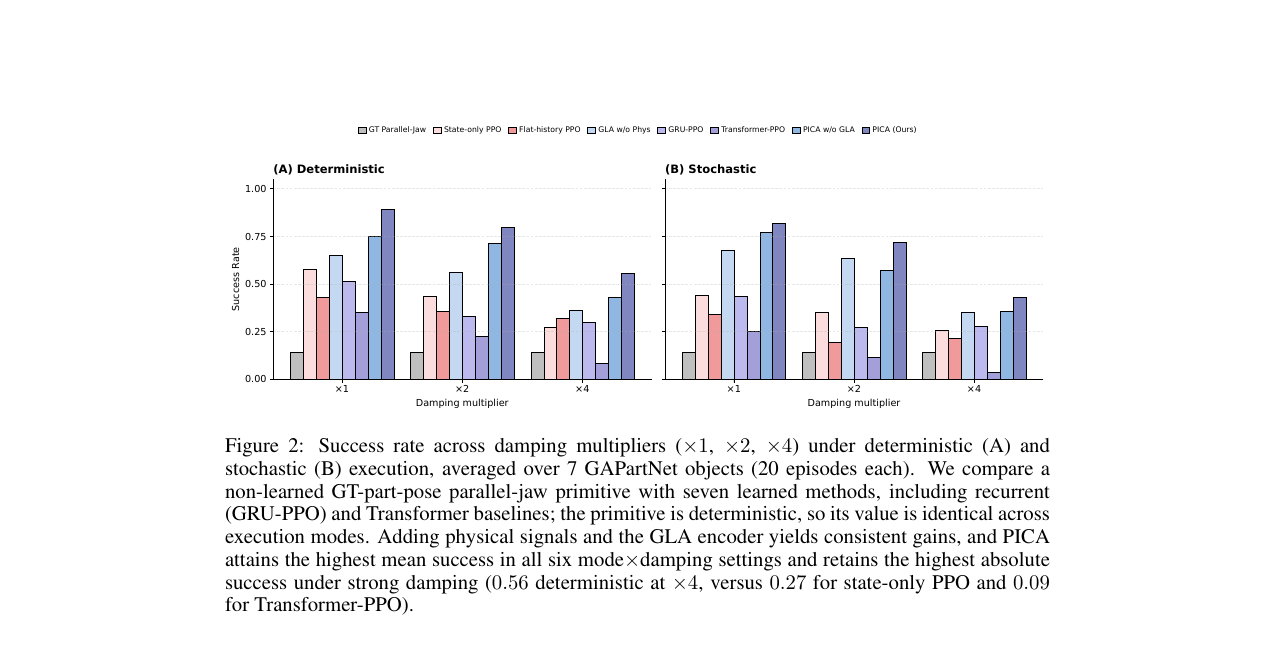
패턴이 뚜렷합니다. 궤적 추적 기준선은 ×1에서는 완벽(1.00)하지만 ×2, ×4에서 두 오브젝트가 접촉을 잃으며 0.71로 떨어집니다. 개루프 방식이 접촉 역학을 모델링하지 못하는 한계입니다. GRU나 Transformer 같은 더 풍부한 시간적 인코더도 물리 신호 없이는 격차를 좁히지 못합니다. GRU-PPO는 ×4에서 0.28로 State-only PPO(0.27)와 큰 차이가 없습니다.
절제 실험에서 두 구성 요소의 기여가 서로 다른 축에서 나타납니다.
절제 실험 (결정론적 / 확률적 평균)
구성 |
×1 |
×2 |
×4 |
|---|---|---|---|
w/o PICA (GLA만) |
0.65 / 0.68 |
0.56 / 0.64 |
0.36 / 0.35 |
w/o GLA (PICA만) |
0.75 / 0.77 |
0.71 / 0.57 |
0.43 / 0.36 |
PICA (전체) |
0.89 / 0.82 |
0.80 / 0.72 |
0.56 / 0.43 |
물리 신호는 공칭 조건(×1)에서 더 강한 기여를 보이고, GLA 인코더는 확률적 실행과 중간 감쇠에서 두드러집니다. 상호 보완적인 기여이기에 어느 하나를 제거하면 ×4에서 13~20%p 이상 성능이 떨어집니다.
회고
가장 인상적인 발견은 학습 길이 연구입니다. 기본 정책을 150 에폭에서 500 에폭으로 길게 학습하면 공칭(×1) 성공률이 0.90에서 1.00으로 올라가지만, 강한 감쇠(×4) 성공률은 0.55에서 0.10으로 무너집니다. 동시에 행동 포화 지표 clip099(최대 행동 크기가 0.99를 초과하는 롤아웃 스텝 비율)는 0.90에서 0.99로 상승합니다. 오래 학습할수록 접촉 안정성 대신 포화 행동으로 밀어붙이는 지름길을 굳히기 때문입니다. 논문은 이를 "명목 성공이 OOD 강건성을 오해하게 만드는 함정"으로 지목하며, 체크포인트 선택을 학습 보상 대신 OOD 감쇠 성공률로 해야 한다고 결론냅니다.
첫 번째 구조적 한계는 행동 포화입니다. ×4에서도 성공률이 0.56에 그치는 이유로 저자들은 위치 증분 행동 인터페이스 자체를 지목합니다. 접촉 저항이 크면 정책이 그립을 재조정하는 대신 최대 크기 행동을 계속 발행하는 경향이 있습니다. 향후 손목 힘-토크나 촉각 피드백을 추가해 정책이 그립 힘을 직접 조절할 수 있도록 하는 방향이 제시됩니다.
두 번째 한계는 전문가 파악 상태 시작입니다. 모든 에피소드가 전문가 수준 파악(expert grasp)에서 시작하므로, 실제 로봇이 물체에 접근하고 핸들을 잡는 과정은 이 연구 범위 밖입니다. 저자들은 이 상체 접촉 연구를 전신 제어(whole-body loco-manipulation)와 결합하는 방향을 차기 과제로 밝혔습니다.
세 번째 한계는 오브젝트별 이질성입니다. Table 2를 보면 특정 오브젝트에서는 한 방법이 압도적으로 잘 작동하지만 다른 오브젝트에서는 역전됩니다. 단일 정책이 모든 인스턴스를 지배하지 못하는 문제는 열린 과제로 남겨졌습니다.
정리
- DragMesh-2는 관절형 오브젝트의 가동 부위가 오직 물리적 손-핸들 접촉을 통해서만 움직이도록 과제를 정식화합니다. 정책은 손만 제어하며, 기하학적 궤적 재생으로 대체할 수 없는 접촉 역학을 다룹니다.
- PICA는 접촉 유지 보상, 행동 경계 정규화, 감쇠 무작위화, GLA 시간적 인코더를 PPO에 결합합니다. 강한 감쇠(×4) 조건에서 State-only PPO 대비 결정론적 성공률이 0.27에서 0.56으로 두 배 이상 향상됩니다.
- 277개 순수-기하학 궤적 데이터셋을 공개해 인간형 로봇의 로코-매니퓰레이션 연구를 지원합니다. 코드: github.com/AIGeeksGroup/DragMesh-2.