5장 - LLM 튜닝
5장. LLM 튜닝
SFT는 모델에게 "이렇게 생성하라"고 가르친다. 하지만 "이렇게 생성하지 마라"는 가르치지 못한다. 선호도 튜닝은 바로 이 부정적 신호를 주입할 수 있는 단계다. — 아프신 아미디
5.1 선호도 튜닝의 동기
LLM 훈련의 전체 파이프라인을 복습하자. 1단계인 사전 훈련(pre-training)에서는 대규모 텍스트 데이터로 언어의 구조를 학습한다. 2단계인 지도 미세 조정(SFT, Supervised Fine-Tuning)에서는 고품질의 소규모 데이터셋으로 모델이 특정 과제에 맞게 행동하도록 가르친다. 그리고 오늘 다루는 3단계가 **선호도 튜닝(preference tuning)**이다. SFT를 거친 모델이 이미 원하는 과제를 수행하지만, 그 톤이나 안전성, 친절함 등이 충분하지 않을 수 있다. 선호도 튜닝은 이러한 측면을 조정한다.
구체적인 예시를 보자. SFT 모델에게 "테디베어와 함께 할 수 있는 새로운 활동을 제안해 줘"라고 물었을 때, 모델이 "테디베어에 시간을 많이 쓰지 않는 것을 권합니다"라고 답했다고 하자. 사실적으로 틀린 말은 아닐 수 있지만, 사용자의 기대와 어긋난다. 선호도 튜닝에서는 이 나쁜 응답과 좋은 응답("테디베어는 훌륭한 잠자리 친구일 뿐 아니라 재미있는 활동의 파트너가 될 수 있습니다! 예를 들어...")을 쌍으로 묶어 모델이 어떤 종류의 출력을 선호해야 하는지 가르친다.
왜 SFT만으로 충분하지 않은가
선호도 튜닝이 별도의 단계로 필요한 이유는 세 가지다.
첫째, 비교가 생성보다 쉽다. SFT 데이터셋을 구성하려면 각 프롬프트에 대해 완벽한 응답을 직접 작성해야 한다. 하지만 선호도 데이터에서는 두 개의 응답 중 어느 것이 더 나은지만 판단하면 된다. "훌륭한 시를 처음부터 써 달라"보다 "이 두 시 중 어느 것이 더 좋은지 골라 달라"가 훨씬 쉬운 작업이다.
둘째, 프롬프트 분포의 민감성이다. SFT 데이터셋에서는 프롬프트의 분포가 매우 중요하다. 특정 유형의 프롬프트가 과다하면 모델이 그 방향으로 편향된다. 모델이 잘못된 행동을 보일 때 SFT 데이터에 단순히 예시 하나를 추가하는 것은 전체 분포를 교란할 위험이 있다. 선호도 튜닝은 이러한 분포 민감성 문제에서 상대적으로 자유롭다.
셋째, 부정적 신호의 주입이다. SFT는 모델이 무엇을 생성해야 하는지만 가르친다. 무엇을 생성하지 말아야 하는지는 가르치지 못한다. 선호도 튜닝은 "이 응답은 좋다 / 저 응답은 나쁘다"라는 쌍을 통해 부정적 신호를 명시적으로 주입할 수 있다.
한 가지 주의할 점이 있다. 선호도 튜닝이 만능은 아니다. 모델이 심각하게 잘못 행동한다면, 그것은 SFT 데이터셋 자체에 문제가 있을 가능성이 높다. 선호도 튜닝보다 SFT 데이터셋을 점검하는 것이 우선이다.
LoRA와 선호도 튜닝은 상호 배타적이지 않다. LoRA는 파라미터 효율적 훈련 기법이고, 선호도 튜닝은 목적 함수의 변경이다. 선호도 튜닝 단계에서도 LoRA를 사용할 수 있다.
5.2 선호도 데이터 수집
선호도 튜닝을 위해서는 선호도 쌍(preference pair)이 필요하다. 프롬프트 하나에 대해 두 개의 응답이 있고, 그중 어느 것이 더 나은지 레이블이 달려 있는 데이터다. 선호도 데이터를 구성하는 방식은 세 가지로 분류된다.
방식 |
설명 |
난이도 |
|---|---|---|
점별(pointwise) |
각 응답에 독립적인 점수를 부여 (예: 0.9, 0.2) |
어렵다. 절대적 척도의 일관성 유지가 곤란 |
쌍별(pairwise) |
두 응답을 비교하여 어느 것이 더 나은지 판정 |
가장 쉽다. 실무에서 주로 사용 |
목록별(listwise) |
n개의 응답을 순위로 정렬 |
중간. 점별보다 쉽지만 쌍별보다 복잡 |
실무에서는 쌍별 선호도 데이터를 가장 많이 사용한다. 평가자에게 두 응답을 보여주고 단순히 "어느 것이 더 좋은가?"만 묻는다.
데이터 생성 절차
선호도 쌍을 얻는 구체적인 절차는 다음과 같다.
- 프롬프트 수집: 사용자 로그나 원하는 프롬프트 분포에서 프롬프트 \(x\)를 추출한다.
- 응답 생성: 동일한 프롬프트를 양의 온도(positive temperature)로 모델에 두 번 입력하여, 서로 다른 두 응답 \(y_1\)과 \(y_2\)를 생성한다.
- 비교 평가: 두 응답 쌍 \((x, y_1)\)과 \((x, y_2)\)를 평가자에게 제시하여 비교한다.
평가 방법으로는 인간 평가, LLM-as-a-Judge, BLEU/ROUGE 같은 규칙 기반 메트릭 등이 있다. 가장 단순한 방식은 이진 판정(더 좋다/더 나쁘다)이고, 더 세분화하면 "훨씬 좋다 / 좋다 / 약간 좋다 / 약간 나쁘다 / 나쁘다 / 훨씬 나쁘다"의 6단계 척도를 사용할 수도 있다. 하지만 많은 과제가 주관적이므로, 실무에서는 이진 척도가 가장 보편적이다.
또 다른 데이터 구성 방식은 모델 로그에서 나쁜 응답을 찾아 직접 좋은 응답으로 재작성(rewriting)하는 것이다. 이 방법은 생성 비용이 더 들지만, 원하는 품질의 데이터를 직접 통제할 수 있다는 장점이 있다.
5.3 RLHF 개요
선호도 데이터를 확보했다면, 이제 모델을 인간의 선호에 맞게 정렬해야 한다. 이를 위한 대표적인 방법이 RLHF(Reinforcement Learning from Human Feedback)다. 이름에서 알 수 있듯이 강화학습(RL)에 기반한다.
강화학습과 LLM의 대응 관계
강화학습의 기본 구조에서 에이전트는 환경과 상호작용한다. 시간 \(t\)에서 상태 \(s_t\)에 있는 에이전트는 정책(policy) \(\pi_\theta(a_t | s_t)\)에 따라 행동 \(a_t\)을 취하고, 보상(reward)을 받는다.
이 프레임워크를 LLM에 대응시키면 다음과 같다.
RL 개념 |
LLM 대응 |
|---|---|
에이전트 |
LLM |
상태 \(s_t\) |
현재까지의 입력 (프롬프트 + 지금까지 생성된 토큰) |
행동 \(a_t\) |
다음 토큰 예측 |
행동 공간 |
어휘(vocabulary) 전체 |
정책 \(\pi_\theta\) |
LLM의 출력 확률 분포 |
보상 |
선호도 데이터로부터 학습된 보상 모델의 점수 |
정리하면, LLM은 입력을 받아 다음 토큰을 예측하고, 생성된 전체 출력이 보상 모델로부터 점수를 받으며, 이 점수가 LLM의 파라미터를 갱신하는 데 사용된다. 보상은 토큰 단위가 아니라 전체 완성(completion) 단위로 부여된다. 따라서 RLHF는 SFT에 비해 신호가 희소(sparse)하다는 특성이 있다.
RLHF의 두 단계
RLHF는 두 단계로 구성된다.
1단계 — 보상 모델 훈련: 선호도 쌍 데이터를 사용하여, 프롬프트와 응답의 연결(concatenation)을 입력으로 받아 점수(스칼라 값)를 출력하는 모델을 훈련한다. 좋은 출력과 나쁜 출력을 구별하는 능력을 학습한다.
2단계 — 강화학습으로 정책 최적화: 훈련된 보상 모델(고정)을 활용하여, LLM이 더 높은 보상을 받는 출력을 생성하도록 정책(파라미터)을 갱신한다.
RLHF에서 "인간 피드백(Human Feedback)"이란, 보상 모델 훈련에 사용되는 선호도 레이블이 인간으로부터 온다는 뜻이다. 만약 선호도 레이블을 AI가 생성했다면, 이를 **RLAIF(Reinforcement Learning from AI Feedback)**라 부른다.
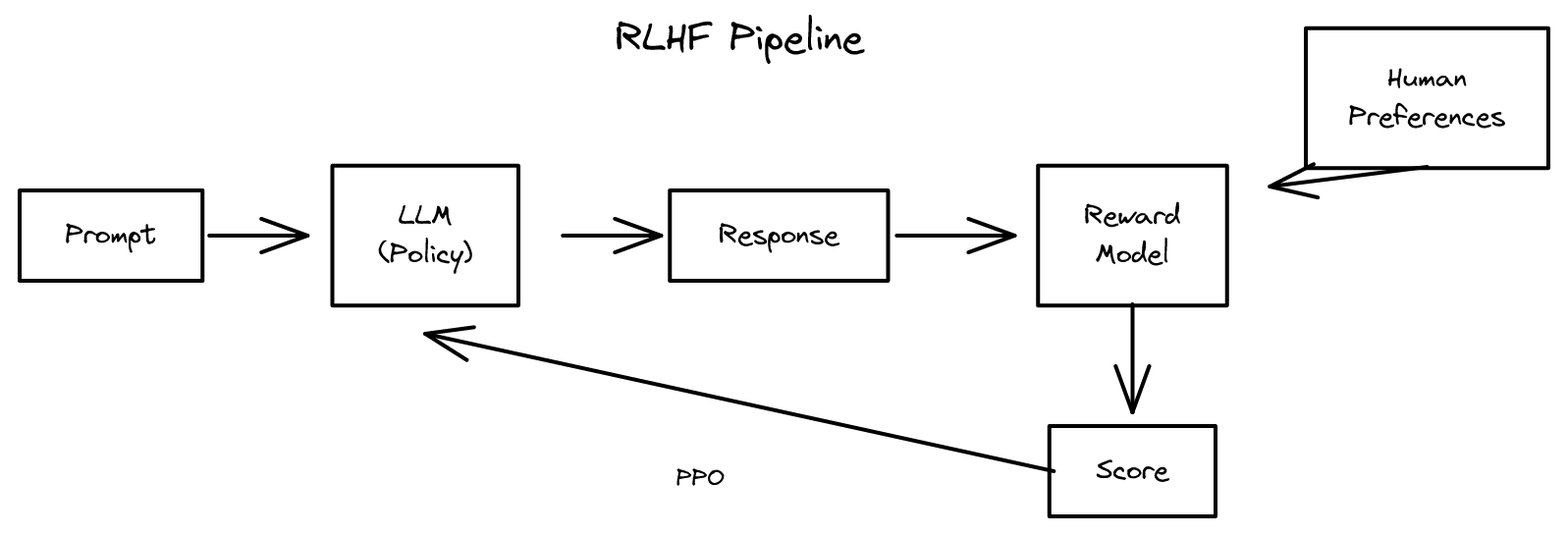
5.4 보상 모델
보상 모델(Reward Model, RM)은 프롬프트 \(x\)와 응답 \(y\)를 입력으로 받아 스칼라 점수 \(R(x, y)\)를 출력하는 모델이다. 좋은 응답에는 높은 점수(예: 0.8)를, 나쁜 응답에는 낮은 점수(예: -2)를 부여해야 한다.
Bradley-Terry 모델
보상 모델의 훈련에는 Bradley-Terry 모델이 사용된다. 이 모델은 출력 \(y_i\)가 출력 \(y_j\)보다 선호될 확률을 다음과 같이 정의한다.
P(y_i > y_j) = exp(R_i) / (exp(R_i) + exp(R_j))
= sigma(R_i - R_j)
여기서 \(\sigma\)는 시그모이드 함수로, \(\sigma(z) = 1 / (1 + \exp(-z))\)다. 시그모이드 함수는 입력이 \(-\infty\)이면 0에, \(+\infty\)이면 1에 수렴한다.
이 공식의 직관은 명확하다. 출력 \(y_i\)가 \(y_j\)보다 좋다면, \(R_i - R_j\)가 커야 하고, 따라서 \(\sigma(R_i - R_j)\)가 1에 가까워야 한다. 즉, 좋은 출력의 보상 \(R_i\)는 높아야 하고, 나쁜 출력의 보상 \(R_j\)는 낮아야 한다.
보상 모델의 손실 함수
\(n\)개의 선호도 쌍 \((y_w^{(i)}, y_l^{(i)})\)가 독립이라고 가정하자. 여기서 \(y_w\)는 선호된(winning) 출력, \(y_l\)은 비선호된(losing) 출력이다. 최대 우도 추정(MLE)의 원리에 따라, 이 데이터의 확률을 최대화하는 파라미터를 찾는다.
maximize prod_{i=1}^{n} P(y_w^(i) > y_l^(i))
= prod_{i=1}^{n} sigma(R(x^(i), y_w^(i)) - R(x^(i), y_l^(i)))
곱(product)은 수치적으로 불안정하므로 로그를 취한다. 최대화를 최소화로 바꾸기 위해 부호를 뒤집는다. 이를 정리하면 보상 모델의 손실 함수는 다음과 같다.
L_RM = -E[ log sigma( R(x, y_w) - R(x, y_l) ) ]
이 손실 함수의 핵심적인 특성이 있다. 훈련은 쌍별(pairwise)로 이루어지지만, 학습된 보상 모델은 **점별(pointwise)**로 동작한다. 즉, 추론 시에는 프롬프트 하나와 응답 하나만 입력하면 점수 하나가 나온다. 쌍이 필요 없다. 이것이 Bradley-Terry 모델의 우아한 점이다.
보상 모델의 구현
보상 모델의 아키텍처는 주로 두 가지 선택지가 있다.
- 디코더 전용 LLM + 분류 헤드: 현재 가장 보편적인 방식. 문장의 마지막 토큰 위치에 분류 헤드를 달아 점수를 예측한다.
- 인코더 전용 모델(예: BERT) + CLS 토큰 투영: 가능하지만 현재는 잘 사용되지 않는다.
훈련 데이터는 보통 수만 개 이상의 선호도 쌍이 필요하며, 레이블은 RLHF의 경우 인간 평가자로부터 얻는다. 보상 모델의 평가에는 RewardBench 같은 벤치마크가 사용된다.
보상은 특정 차원에 대해 정의된다는 점을 기억해야 한다. "유용한가", "친절한가", "안전한가"는 각각 다른 차원이며, 차원마다 별도의 보상 모델을 훈련할 수 있다. 통합적인 점수 하나를 사용할 수도 있지만, 어떤 차원을 측정하는지 명확히 정의해야 한다. 또한 인간 평가의 가이드라인은 가능한 한 객관적이어야 한다. 모호한 가이드라인은 노이즈가 큰 선호도 데이터를 만들어낸다.
5.5 강화학습을 통한 정책 최적화
보상 모델이 훈련되었으면, 이제 이 보상 모델을 사용하여 LLM을 정렬한다. 전체 절차는 다음과 같다.
- 프롬프트를 LLM에 입력한다.
- LLM이 **전체 응답(completion, 또는 rollout)**을 생성한다.
- 프롬프트와 생성된 응답을 보상 모델에 입력하여 점수를 얻는다.
- 이 보상 점수를 바탕으로 LLM의 파라미터를 갱신한다.
여기서 보상 모델은 **고정(frozen)**된다. 갱신 대상은 오직 LLM의 파라미터다.
보상 극대화와 제약 조건
목표는 높은 보상을 받는 출력을 생성하는 것이지만, 동시에 초기 모델(SFT 모델)에서 너무 멀어지지 않아야 한다. 이 제약이 필요한 이유는 세 가지다.
첫째, 사전 지식의 보존이다. 사전 훈련과 SFT를 통해 축적된 지식을 파괴적 망각(catastrophic forgetting)으로 잃지 않기 위함이다.
둘째, 보상 해킹(reward hacking)의 방지다. 보상 모델은 불완전하다. 보상 모델이 측정하는 것과 실제로 원하는 것 사이에는 괴리가 있다. 보상을 과도하게 최적화하면, 보상 모델의 허점을 악용하는 출력이 생성된다. 비유하자면, "강의를 유익하게 하라"는 목표에 대해 "강의 후 박수 소리의 크기"를 보상으로 설정했다고 하자. 이 보상을 극대화하면, 강사는 유익한 내용 대신 재미있는 농담만 하게 될 수 있다. 박수 소리는 최대화되었지만, 원래 목표는 달성되지 않는다. 이것이 보상 해킹이다.
셋째, 훈련 안정성이다. 지나치게 큰 갱신은 훈련의 불안정을 초래한다.
따라서 손실 함수는 두 가지 항으로 구성된다. 보상을 극대화하는 항과, 현재 정책이 기준 모델(reference model)에서 벗어나지 않도록 하는 항이다.
이 단계에서는 보상 모델 훈련보다 더 많은 데이터가 필요하다. 통상 10만 개 이상의 관측치가 사용되며, 레이블은 보상 모델이 부여한다. 훈련은 SFT 모델에서 시작한다.
5.6 PPO (Proximal Policy Optimization)
PPO는 가장 널리 알려진 정책 최적화 알고리즘이다. "Proximal(근접)"이라는 이름은 모델이 기준 모델에서 너무 멀어지지 않도록 한다는 뜻이다.
어드밴티지와 가치 함수
PPO에서 실제로 최적화하는 것은 보상 자체가 아니라 **어드밴티지(advantage)**다. 어드밴티지는 "현재 출력이 평균적으로 기대되는 수준 대비 얼마나 더 좋은가"를 나타낸다.
A(s, a) = Q(s, a) - V(s)
여기서: - \(Q(s, a)\): 상태 \(s\)에서 행동 \(a\)를 취했을 때 기대되는 총 보상 - \(V(s)\): 상태 \(s\)에서 현재 정책을 따를 때 기대되는 총 보상 (가치 함수)
보상 대신 어드밴티지를 사용하는 이유는 추정치의 분산을 줄이기 위함이다. 보상 자체는 절대적 크기가 크거나 변동성이 높을 수 있다. 보상에서 기준값(baseline)인 가치 함수를 빼면, 신호가 상대적 척도로 변환되어 훈련이 안정적으로 진행된다.
가치 함수(value function) \(V(s)\)는 보상 모델과 다른 수준에서 작동한다. 보상 모델은 전체 완성에 대해 하나의 점수를 부여하지만, 가치 함수는 토큰 수준에서 동작한다. 프롬프트와 부분적으로 생성된 토큰을 입력으로 받아, 현재 정책대로 생성을 계속했을 때 최종적으로 받게 될 보상을 예측한다.
가치 함수는 LLM에 **가치 헤드(value head)**를 추가하여 구현하며, 정책과 공동으로 훈련된다. 이것은 회귀(regression) 문제로, 최종 보상의 추정값을 출력한다.
어드밴티지의 실제 추정에는 일반화 어드밴티지 추정(GAE, Generalized Advantage Estimation) 방법이 사용된다. 자세한 수학적 유도는 Schulman et al.의 "High-Dimensional Continuous Control Using Generalized Advantage Estimation" 논문을 참고하라.
PPO-Clip
PPO의 첫 번째 변형은 PPO-Clip이다. 각 반복에서 정책의 갱신 폭을 클리핑으로 제한한다.
L_clip = min( r(theta) * A, clip(r(theta), 1 - epsilon, 1 + epsilon) * A )
여기서: - \(r(\theta) = \pi_\theta(a|s) / \pi_{\theta_{old}}(a|s)\): 현재 정책과 이전 반복의 정책 간 확률 비율 - \(A\): 어드밴티지 - \(\epsilon\): 클리핑 범위를 결정하는 하이퍼파라미터
주의할 점이 두 가지 있다. 첫째, 여기서 \(r(\theta)\)는 보상 모델의 \(R\)이 아니라 확률 비율이다. 둘째, 이 \(L_\text{clip}\)은 이름과 달리 최대화해야 하는 목적 함수다.
이 공식의 직관은 어드밴티지의 부호에 따라 나뉜다.
어드밴티지가 양수일 때 (\(A > 0\)): 생성된 출력이 기대보다 좋다는 뜻이다. 이 출력의 생성 확률을 높이고 싶으므로 \(r(\theta)\)를 키우려 한다. 하지만 \(1 + \epsilon\) 이상으로는 키울 수 없다. 클리핑이 지나치게 큰 갱신을 방지한다.
어드밴티지가 음수일 때 (\(A < 0\)): 생성된 출력이 기대보다 나쁘다는 뜻이다. 이 출력의 생성 확률을 낮추고 싶으므로 \(r(\theta)\)를 줄이려 한다. 하지만 \(1 - \epsilon\) 이하로는 줄일 수 없다. 역시 클리핑이 급격한 변화를 막는다.
요약하면, 좋은 출력은 강화하되 너무 많이 강화하지 않고, 나쁜 출력은 억제하되 너무 많이 억제하지 않는다. 여기서 "이전 반복(old)"이란 SFT 모델이 아니라, RL 훈련 과정의 직전 스텝을 의미한다. 이는 반복 간 갱신의 안정성을 보장하기 위함이다.
PPO-KL (KL 페널티)
PPO의 두 번째 변형은 PPO-KL이다. 클리핑 대신 KL 발산을 명시적으로 페널티 항으로 사용한다.
L_KL = r(theta) * A - beta * D_KL(pi_old || pi_theta)
여기서 \(\beta\)는 기준 모델에서의 이탈을 얼마나 강하게 제한할지 조절하는 하이퍼파라미터다.
**KL 발산(Kullback-Leibler divergence)**은 두 확률 분포 \(P\)와 \(Q\) 사이의 차이를 측정하는 지표다.
D_KL(P || Q) = sum_i P_i * log(P_i / Q_i)
KL 발산의 핵심 성질은 항상 0 이상이라는 것이다 (Jensen 부등식에 의해 증명). \(D_\text{KL}(P \| Q) = 0\)이 되는 경우는 \(P = Q\)일 때뿐이다. 주의할 점은 KL 발산은 대칭이 아니므로 엄밀한 의미의 거리(distance)가 아니다.
실무에서는 PPO-Clip과 PPO-KL을 혼합하여 사용하기도 한다. Clip은 반복 간 갱신 폭을 제한하고, KL 페널티는 기준(reference) 모델과의 거리를 직접 제한한다. 두 기법을 결합하면 안정성을 더욱 높일 수 있다.
PPO의 모델 구성
PPO를 사용한 RLHF에서는 동시에 네 개의 모델을 메모리에 유지해야 한다.
모델 |
역할 |
상태 |
|---|---|---|
정책 모델 \(\pi_\theta\) |
현재 훈련 중인 LLM |
갱신됨 |
가치 함수 \(V\) |
어드밴티지 추정을 위한 모델 |
갱신됨 (정책과 공동 훈련) |
보상 모델 \(R\) |
출력의 품질 점수 부여 |
고정 |
기준 모델 \(\pi_\text{ref}\) |
SFT 모델. KL 발산 계산의 기준 |
고정 |
이 네 모델을 모두 GPU 메모리에 올려야 하므로, PPO 기반 RLHF는 상당한 연산 자원을 요구한다.
5.7 RLHF의 도전 과제
RLHF에는 여러 실질적인 어려움이 존재한다.
2단계 의존성: 보상 모델을 먼저 훈련하고, 그 위에서 정책을 최적화한다. 만약 정책 최적화 도중 보상 모델에 문제가 발견되면, 모든 것을 처음부터 다시 해야 한다.
하이퍼파라미터의 많음: PPO-KL의 \(\beta\), PPO-Clip의 \(\epsilon\), GAE의 하이퍼파라미터 등 조정해야 할 요소가 많다. 하이퍼파라미터 탐색에 실패하면 전체 과정을 재수행해야 한다.
훈련 불안정성: 반복 간 갱신을 제한해도 불안정이 발생할 수 있다. 모니터링 지표로는 평균 보상을 사용하지만, 이것이 모델 품질의 완벽한 지표는 아니다. 사전 훈련이나 SFT에서는 교차 엔트로피 손실이 명확한 지표 역할을 하지만, RLHF에서는 그에 상응하는 깔끔한 지표가 없다.
탐색의 필요성: RL 훈련 루프에서 모델은 매 반복마다 출력을 생성한다. 이때 생성되는 출력들이 충분히 다양해야 한다. 매번 비슷한 출력만 생성하면 가능한 완성 공간을 제대로 탐색하지 못한다. 모델이 일정 수준의 탐색(exploration)을 수행하도록 유도해야 한다.
높은 연산 비용: 네 개의 모델을 동시에 메모리에 유지해야 하며, 매 반복마다 모델이 출력을 생성해야 하므로 연산 비용이 크다.
GRPO(Group Relative Policy Optimization)는 PPO의 대안으로 떠오르고 있는 알고리즘이다. DeepSeek 팀이 "DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models" 논문에서 제안했으며, 가치 함수 없이도 작동하여 모델 수를 줄인다. 이에 대해서는 6장에서 다룬다.
5.8 On-Policy vs Off-Policy
RLHF에서 자주 등장하는 구분이 **온-폴리시(on-policy)**와 **오프-폴리시(off-policy)**다.
온-폴리시 훈련: 현재 훈련 중인 모델이 직접 출력을 생성하고, 그 출력에 대해 최적화한다. PPO가 대표적인 온-폴리시 알고리즘이다. 매 반복마다 현재 정책으로 샘플을 생성하고, 그 샘플로부터 학습한다.
오프-폴리시 훈련: 훈련 중인 모델이 아닌 다른 모델(또는 이전 버전의 모델)이 생성한 데이터로 학습한다. SFT가 대표적인 예시다. SFT에서는 미리 구성된 데이터셋의 응답을 모방할 뿐, 모델 자신이 생성한 출력으로 학습하지 않는다.
핵심 차이는 이것이다. SFT에서는 "이 프롬프트가 주어지면 이 응답을 생성하라"고 가르친다. RLHF에서는 "이 프롬프트가 주어지면 네가 생성한 응답이 얼마나 좋은지 피드백을 줄 테니, 그걸 바탕으로 개선하라"고 한다. 모델 자신의 생성물에 대해 학습하느냐 아니냐가 핵심 구분이다.
5.9 Best-of-N
보상 모델은 있지만 RL 훈련은 하고 싶지 않은 경우의 대안이 **Best-of-N(BoN)**이다. RL의 복잡성과 비용을 피하면서도 보상 모델을 활용할 수 있다.
절차는 단순하다.
- 프롬프트를 SFT 모델에 N번 입력하여 N개의 응답을 생성한다 (양의 온도 사용).
- 각 응답을 보상 모델에 입력하여 점수를 매긴다.
- 가장 높은 점수를 받은 응답을 최종 결과로 반환한다.
예를 들어, "테디베어와 함께 할 수 있는 새로운 활동을 제안해 줘"에 대해 세 개의 응답을 생성했다고 하자.
응답 |
보상 점수 |
|---|---|
"테디베어는 훌륭한 동반자입니다! 함께 피크닉을 가거나..." |
0.8 |
"테디베어에 시간을 많이 쓰지 마세요" |
-2.0 |
"테디베어를 피크닉에 데려가 보세요" |
0.3 |
Best-of-N은 점수 0.8인 첫 번째 응답을 반환한다.
이 방법의 장점은 LLM의 가중치를 전혀 수정하지 않으므로 RL 훈련의 복잡성이 완전히 제거된다는 것이다. 보상의 스케일도 신경 쓸 필요가 없다. 상대 순서만 중요하므로, 정규화 방식에 관계없이 가장 높은 점수의 응답이 선택된다.
하지만 핵심 단점은 추론 비용이다. 하나의 프롬프트에 대해 N번의 생성을 수행해야 한다. 무한한 연산 자원이 있어 모든 생성을 병렬로 실행하더라도, N개 생성 중 가장 느린 것을 기다려야 하므로 지연 시간(latency)이 증가한다. 지연 시간 분포의 최댓값은 단일 생성의 지연 시간보다 항상 오른쪽으로 치우친다. 대규모 트래픽을 처리해야 하는 서빙 환경에서는 비용이 N배로 증가한다.
Best-of-N을 채택하기 전에 예상 추론 트래픽과 훈련 비용을 비교하여 어느 쪽이 더 경제적인지 평가해야 한다.
5.10 DPO (Direct Preference Optimization)
RLHF의 복잡한 2단계 과정과 Best-of-N의 추론 비용 문제를 모두 해결하려는 시도가 **DPO(Direct Preference Optimization)**다. DPO는 보상 모델을 별도로 훈련하지 않고, 선호도 쌍으로부터 정책을 직접 최적화한다.
유도 과정
DPO의 유도는 PPO의 목적 함수에서 출발한다.
maximize E[R(x, y)] - beta * D_KL(pi_theta || pi_ref)
이 목적 함수의 최적 정책 \(\pi^*\)를 해석적으로 풀면 다음을 얻는다.
pi*(y|x) = (1/Z(x)) * pi_ref(y|x) * exp(R(x, y) / beta)
여기서 \(Z(x)\)는 정규화를 위한 분할 함수(partition function)다. 이 식을 \(R\)에 대해 정리하면 다음과 같다.
R(x, y) = beta * log(pi*(y|x) / pi_ref(y|x)) + beta * log Z(x)
핵심 통찰은 여기서 나온다. 보상 \(R\)을 정책의 함수로 표현할 수 있다는 것이다. 이 표현을 Bradley-Terry 모델의 확률 공식에 대입한다.
P(y_w > y_l | x) = sigma(R(x, y_w) - R(x, y_l))
\(R\)을 정책의 함수로 치환하면, \(Z(x)\) 항은 차이에서 상쇄되어 사라진다. 최종적으로 DPO의 손실 함수를 얻는다.
L_DPO = -E[ log sigma( beta * (log(pi_theta(y_w|x) / pi_ref(y_w|x)) - log(pi_theta(y_l|x) / pi_ref(y_l|x))) ) ]
이 공식에는 \(R\)이 전혀 등장하지 않는다. 오직 현재 정책 \(\pi_\theta\), 기준 정책 \(\pi_\text{ref}\), 그리고 선호도 쌍 \((y_w, y_l)\)만 있다.
DPO 논문의 제목은 "Your Language Model Is Secretly a Reward Model"이다. 정책 자체가 암묵적으로 보상 모델의 역할을 수행하기 때문이다. 보상에 해당하는 항, \(\beta \log(\pi_\theta(y|x) / \pi_\text{ref}(y|x))\)가 정책의 함수로만 표현된다.
DPO의 \(\beta\)
\(\beta\)는 PPO 목적 함수의 KL 페널티 항에서 온 것과 동일한 하이퍼파라미터다. 기준 모델에서의 이탈을 얼마나 강하게 제한할지 조절한다. 실무에서 \(\beta\)는 보통 0.1 부근의 값을 사용한다.
RLHF vs DPO 비교
측면 |
RLHF (PPO) |
DPO |
|---|---|---|
단계 |
2단계 (보상 모델 훈련 → RL 최적화) |
1단계 (직접 최적화) |
필요 모델 수 |
4개 (정책, 가치 함수, 보상 모델, 기준 모델) |
2개 (정책, 기준 모델) |
학습 방식 |
온-폴리시 (모델이 생성한 출력으로 학습) |
지도 학습 방식 (선호도 쌍 데이터로 직접 학습) |
훈련 안정성 |
불안정할 수 있음. 하이퍼파라미터 조정 어려움 |
상대적으로 안정. 설정이 단순 |
최종 성능 |
일반적으로 더 높음 |
PPO보다 약간 낮은 경향 |
분포 이동 |
온-폴리시이므로 분포 이동 문제 없음 |
오프-폴리시 특성으로 분포 이동(distribution shift) 발생 가능 |
DPO의 핵심 한계는 분포 이동(distribution shift) 문제다. DPO는 기존 선호도 데이터셋에 대해 지도 학습을 수행하므로, 훈련에 사용된 데이터의 분포와 실제 모델이 생성하는 출력의 분포가 다를 수 있다. 이는 PPO가 온-폴리시로 작동하여 현재 정책의 생성물에 대해 직접 최적화하는 것과 대조된다.
이 문제를 완화하려면 선호도 데이터를 모델 자체로 생성하거나, 선호도 데이터에 대해 SFT를 먼저 수행한 뒤 DPO를 적용하는 등의 추가 작업이 필요하다. 하지만 이 역시 추가 비용이다.
실무에서의 선택
PPO와 DPO 중 어느 것을 선택할지는 목표와 자원에 달려 있다. 빠르게 선호도 튜닝을 적용하고 싶고 합리적인 성능이면 충분하다면 DPO가 적합하다. 강화학습에 대한 전문 지식이 있고 최대 성능을 원한다면 PPO가 더 나은 선택이다.
선호도 튜닝의 효과 예시
선호도 튜닝의 효과를 구체적으로 보자. "테디베어를 세탁기에 넣어도 될까요?"라는 질문에 대해:
- SFT 모델의 응답: "안 됩니다. 손상될 수 있습니다. 대신 손세탁을 해 보세요." — 사실적으로 정확하지만 톤이 무뚝뚝하다.
- 선호도 튜닝 후 응답: "테디베어가 다칠 수 있으니, 부드러운 손세탁이 더 안전합니다." — 동일한 정보를 전달하되, 테디베어를 아끼는 사용자의 감정을 고려한 부드러운 톤이다.
선호도 튜닝은 새로운 사실을 가르치는 것이 아니다. 기존 지식의 표현 방식, 즉 출력의 분포를 인간의 선호에 맞게 조정하는 것이다.
핵심 정리
개념 |
핵심 |
|---|---|
선호도 튜닝 |
SFT 후 3단계. 부정적 신호 주입 가능. 비교가 생성보다 쉽다 |
데이터 수집 |
쌍별(pairwise) 선호도 데이터가 표준. 이진 판정이 가장 보편적 |
RLHF |
2단계: 보상 모델 훈련 → RL로 정책 최적화. 인간 피드백 기반 |
Bradley-Terry |
\(P(y_w > y_l) = \sigma(R_w - R_l)\). 쌍별 훈련, 점별 추론 |
보상 모델 손실 |
\(L = -\mathbb{E}[\log \sigma(R(x, y_w) - R(x, y_l))]\) |
PPO |
근접 정책 최적화. 어드밴티지 기반. Clip과 KL 두 변형 |
PPO-Clip |
확률 비율을 \([1-\epsilon, 1+\epsilon]\)로 클리핑하여 갱신 폭 제한 |
PPO-KL |
KL 발산 페널티로 기준 모델과의 거리 직접 제한. \(\beta\) 조절 |
보상 해킹 |
불완전한 보상 모델의 허점을 악용. KL 제약으로 완화 |
On/Off-Policy |
온-폴리시: 자기 생성물로 학습 (PPO). 오프-폴리시: 외부 데이터로 학습 (SFT) |
Best-of-N |
N개 생성 후 최고 점수 반환. RL 없이 보상 모델 활용. 추론 비용 N배 |
DPO |
보상 모델 없이 선호도 쌍에서 직접 최적화. 2개 모델만 필요. 분포 이동 주의 |
다음 장: 6장 - LLM 추론