Zone of Proximal Policy Optimization - Teacher in Prompts, Not Gradients
B.-K. Lee, X. Lu, S. Diao, M. Kang, S. Muralidharan, K. Sapra, A. Tao, P. Molchanov, Y. Choi, Y.-C. F. Wang, and R. Hachiuma, "Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients," arXiv:2606.18216, 2026.
저자
Byung-Kwan Lee가 프로젝트 리드로 이 연구를 이끌었습니다. NVIDIA Research Taiwan을 중심으로 Ximing Lu, Shizhe Diao, Minki Kang, Saurav Muralidharan, Karan Sapra, Andrew Tao, Pavlo Molchanov, Yejin Choi, Yu-Chiang Frank Wang, Ryo Hachiuma가 합류한 NVIDIA 11인 팀입니다. Yejin Choi는 자연어처리와 상식 추론 분야에서 MacArthur Fellow, Time100 AI 선정 이력을 가진 연구자로, 이번 논문에서는 소형 모델이 대형 교사의 지식을 더 효과적으로 흡수하도록 하는 방향의 연구에 함께했습니다.
배경
소형 언어 모델(0.8B~9B)을 스마트폰, AR/VR 글래스, 임베디드 로봇에 배포하려면 지식이 큰 모델에서 작은 모델로 넘어와야 합니다. 표준 레시피는 지식 증류(knowledge distillation)입니다. 그런데 이 방식은 학생이 교사보다 훨씬 작을 때 구조적 한계를 드러냅니다.
첫 번째 문제는 로짓 모방의 취약성입니다. 제한된 용량을 가진 0.8B 모델은 교사 분포를 넓게 흡수하지 못하고 교사의 가장 뾰족한 최고 확률 모드에만 집중합니다(mode-seeking bias). 결과로 나오는 학생은 훈련 데이터에서 교사 답을 외우지만, 훈련 범위 밖 벤치마크에서는 오히려 성능이 떨어집니다.
두 번째 문제는 RL의 하드 질문 맹점입니다. GRPO 같은 그룹 상대 보상 방식은 그룹 내 모든 롤아웃이 실패하면 그 질문에서 오는 그래디언트 신호가 0이 됩니다. 소형 학생에게 가장 필요한 것은 딱 그런 질문들인데, RL은 그 질문들을 조용히 버립니다.
이를 해결하는 자연스러운 시도가 "그래디언트 안에 교사를 넣기"입니다. 교사의 정답 롤아웃을 학생 롤아웃처럼 취급해 정책 그래디언트를 계산하는 방식입니다. 그런데 이 방법은 on-policy 가정을 깨뜨려 정책 드리프트를 일으킵니다. 논문의 출발점이 바로 이 세 가지 실패 모드입니다.
어떻게 만들었나
논문은 비고츠키(Vygotsky)의 근접발달영역(ZPD, Zone of Proximal Development) 개념에서 이름을 빌렸습니다. 학습자는 혼자서는 풀 수 없지만 조금의 안내가 있으면 풀 수 있는 과제의 구간에서 가장 빠르게 성장합니다. ZPPO는 이 구간을 교사를 그래디언트가 아닌 프롬프트 안에 두는 방식으로 구현합니다.
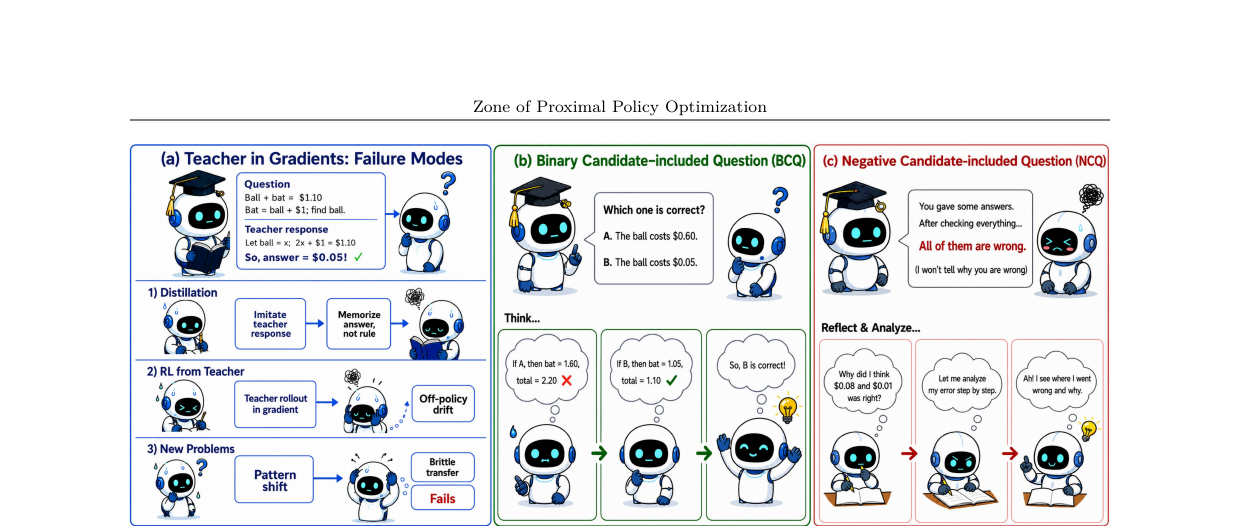
어려운 질문 정의
학생의 그룹 롤아웃 평균 정확도 \(\bar{r}_x\)를 기준으로 \(\bar{r}_x < 0.5\)인 질문을 어려운 질문(hard question)으로 정의합니다. 표준 그룹 상대 어드밴티지는 다음과 같습니다:
\[A^{(g)} = \frac{r(x, y_S^{(g)}) - \bar{r}_x}{\text{std}_x + \epsilon}\]
\(\bar{r}_x = 0\)이면 그룹이 전부 실패했고, \(A^{(g)} = 0\)이 되어 그래디언트 신호가 없어집니다. ZPPO의 목표는 이 구간에서 학습 신호를 복원하는 것입니다.
BCQ: 이진 후보 포함 질문
어려운 질문 \(x\)에 대해 교사 정답 롤아웃 하나 \(y_T^{(+)}\)와 학생 오답 롤아웃 하나 \(y_S^{(-)}\)를 무작위 순서로 익명의 <candidate> 태그 안에 넣어 프롬프트를 재구성합니다. 학생은 "둘 중 하나는 맞고 하나는 틀립니다. 어느 것이 맞는지 추론하세요"라는 질문을 받습니다.
이때 학생은 자신의 분포에서 새로운 롤아웃을 생성하므로 정책 그래디언트는 완전히 on-policy 상태로 유지됩니다. 교사 텍스트는 프롬프트 입력에만 포함되고, 그래디언트 계산 대상인 어시스턴트 응답에는 절대 들어가지 않습니다.
교육적 효과는 "교사 정답을 정답 레이블 없이 학생 오답 옆에 나란히 두기"에서 나옵니다. 학생은 두 후보 중 무엇이 옳은지를 추론하면서 스스로 차이를 발견합니다.
NCQ: 부정 후보 포함 질문
어려운 질문에서 학생의 모든 오답 롤아웃 \(\{y_S^{(-,g)}\}\)을 하나의 프롬프트 안에 집합시킵니다. "아래는 전부 틀린 답입니다. 틀린 추론 과정들을 분석하세요"라는 지시와 함께, 학생은 자신의 실패 패턴들을 동시에 봅니다.
표준 GRPO 훈련에서 각 롤아웃은 독립적인 그룹에 기여하기 때문에 학생은 같은 질문에서의 여러 실패들 사이의 공통 패턴을 볼 수 없습니다. NCQ는 훈련 루프에서 처음으로 그 시각을 학생에게 제공합니다.
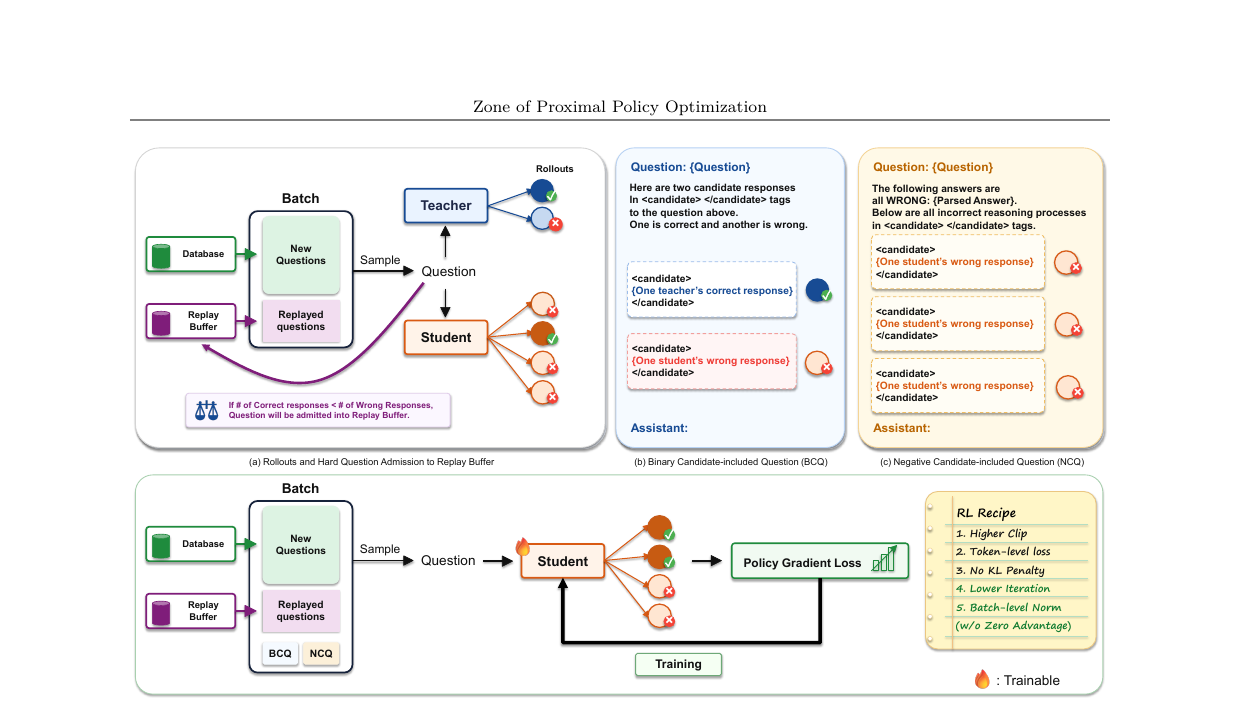
프롬프트 리플레이 버퍼
BCQ와 NCQ만으로는 부족합니다. 어려운 질문에 한 번만 BCQ/NCQ를 적용하면 학생이 아직 그 질문을 졸업하기 전에 지나쳐버립니다. 버퍼는 다음 방식으로 이 문제를 해결합니다.
- 입학: 현재 배치에서 \(\bar{r}_x < 0.5\)인 질문(이미지+텍스트만, 롤아웃 응답은 저장하지 않음)을 버퍼에 추가합니다.
- 졸업: 이후 배치에서 재노출된 질문의 \(\bar{r}_x\)가 0.5 이상이 되면 졸업(제거)합니다.
- FIFO 방출: 버퍼가 최대 용량을 초과하면 오래된 것부터 제거합니다.
버퍼는 항상 학생의 현재 ZPD를 추적합니다. 매 재방문마다 BCQ와 NCQ가 새로 샘플링되므로 학생은 같은 질문이라도 새로운 교사 후보와 새로운 자신의 오답 묶음을 봅니다.
RL 레시피 조정
BCQ/NCQ 외에도 두 가지 레시피 변경이 성능에 크게 기여합니다. 스텝당 반복 횟수를 표준 GRPO의 \(I = 16\)에서 \(I = 4\)로 줄입니다. 반복 횟수가 많으면 미니배치마다 현재 정책에서 더 멀어져 off-policy 드리프트가 쌓입니다. \(I = 4\)는 드리프트를 줄이면서도 스텝당 4번의 업데이트를 유지합니다.
배치 수준 어드밴티지 정규화에서 제로 어드밴티지 그룹을 제외합니다(Norm w/o Zero). 전부 정답이거나 전부 오답인 그룹은 학습 신호가 없지만, 그 제로 어드밴티지 값이 배치 표준편차를 줄여 다른 그룹의 어드밴티지를 부풀립니다. 이를 제외하면 정상 어드밴티지 추정이 더 안정됩니다.
결과
Qwen3.5 패밀리(0.8B, 2B, 4B, 9B)를 27B 교사로 포스트 트레이닝하고, 16개 VLM, 10개 LLM, 5개 Video 벤치마크 합산 31개 벤치마크에서 평가했습니다. VLM 16개 벤치마크는 훈련 도메인과 정렬된 분포이고, LLM 10개+Video 5개는 훈련 코퍼스 외부의 일반화 분포입니다.
모델 규모별 평균 성능 향상 (pp)
방법 |
VLM 16 (0.8B) |
OOD 15 (0.8B) |
VLM 16 (2B) |
OOD 15 (2B) |
|---|---|---|---|---|
Off-policy Distill |
+0.9 |
-2.5 |
+0.9 |
-1.8 |
On-policy Distill |
+0.7 |
-1.8 |
+0.6 |
-0.9 |
GRPO |
+3.8 |
+양수 |
+대략 양수 |
+양수 |
ZPPO |
*+9.3* |
*+6.8* |
*+5.2* |
*+4.3* |
가장 인상적인 발견은 증류와 ZPPO의 OOD 일반화 방향이 반대라는 점입니다. Off-policy 증류는 VLM 훈련 벤치마크에서 +0.9pp를 얻지만 LLM/Video OOD에서 -2.5pp를 잃습니다. On-policy 증류도 OOD에서 -1.8pp입니다. 증류가 훈련 코퍼스에 과적합하는 구체적 증거입니다. 반면 ZPPO는 훈련 정렬 VLM에서 +9.3pp를 얻으면서 OOD에서도 +6.8pp를 추가합니다.
가장 큰 이득이 가장 작은 스케일에서 나타납니다. 0.8B 학생에서 VLM +9.3pp, 2B에서 +5.2pp로 교사와 학생의 용량 차이가 클수록 ZPPO의 기여가 두드러집니다. 이는 BCQ의 교육적 효과가 학생이 교사보다 훨씬 약한 구간에서 극대화되기 때문입니다.
버퍼 내 졸업 비율도 이 효과를 뒷받침합니다. 정답률이 0%인 최하위 어려운 질문들에서 ZPPO는 28%(432/1568)를 졸업시키지만, GRPO†는 4%(73/2035)에 그쳤습니다. RL의 제로 어드밴티지 맹점을 BCQ가 메우는 것이 수치로 확인됩니다.
절제 실험(Table 3)에서 BCQ, NCQ, 버퍼 중 어느 하나를 빼도 매 스케일에서 성능이 저하됩니다. 버퍼와 재구성의 조합이 합산 이상의 효과를 냅니다. 버퍼 없이 BCQ/NCQ만 쓰면 하드 질문을 한 번만 보지만, 버퍼가 같은 질문을 반복 노출시켜 교정 신호를 쌓습니다.
회고
가장 명확하게 인정된 한계는 교사 경계 ZPD입니다. BCQ는 어려운 질문에서 교사가 최소 하나의 정답 롤아웃을 생성할 수 있어야 합니다. 교사도 틀리는 질문은 BCQ 후보가 없고 NCQ만 남습니다. 모델 스케일이 커질수록 이런 문제가 늘어나 BCQ의 기여가 줄어들고 ZPPO의 이득이 9B에서 2.8pp로 수렴합니다. 여러 교사를 앙상블하거나 합성 프롬프트로 ZPD를 확장하는 방향이 가장 중요한 열린 과제로 남겨졌습니다.
다이나믹 샘플링과의 긴장도 언급됩니다. DAPO 계열의 다이나믹 샘플링은 전부 정답이거나 전부 오답인 질문을 즉시 제거하는 반면, ZPPO는 전부 오답인 질문을 정확히 버퍼에 저장합니다. 두 방식을 단순 결합하면 버퍼의 질문이 다이나믹 샘플링에 의해 제거될 수 있습니다. 현재로서는 BCQ/NCQ 재구성 이후에 다이나믹 샘플링을 적용하는 직렬 방식을 제안하지만, 두 방식의 공식적인 통합은 후속 작업으로 남겨뒀습니다.
또한 ZPPO는 단일 턴 추론 정확도에 최적화되어 있어 멀티 스텝 에이전트 추론, 강건성, 대화 역량 같은 다른 축은 평가 범위 밖입니다.
정리
- ZPPO는 교사를 그래디언트 대신 프롬프트 안에 유지함으로써 on-policy 속성을 지키면서 어려운 질문에서 학습 신호를 복원합니다. BCQ는 교사 정답과 학생 오답을 나란히 놓아 학생이 스스로 차이를 추론하게 하고, NCQ는 학생 자신의 실패 패턴들을 한자리에 모아 공통 오류를 직면하게 합니다.
- 증류는 VLM 훈련 벤치마크를 소폭 끌어올리면서 LLM/Video OOD를 훼손하지만, ZPPO는 두 방향 모두를 개선합니다. 0.8B에서 VLM +9.3pp, OOD +6.8pp로 이득이 가장 작은 스케일에서 가장 큽니다.
- 한계는 교사 경계 ZPD입니다. 교사와 학생 모두 틀리는 질문에서 BCQ 후보가 없고, 이 한계가 대형 학생 스케일에서 ZPPO의 이득을 수렴시킵니다. 여러 교사나 합성 프롬프트로 ZPD를 확장하는 것이 가장 중요한 다음 단계입니다.