Optical Reasoning - Rethinking Images as an Expressive Reasoning Medium Beyond Text
Y. Bian, D. Cheng, H. Xia, Y. Li, and W. Li, "Optical Reasoning: Rethinking Images as an Expressive Reasoning Medium Beyond Text," arXiv:2606.09585, 2026.
저자
볜위통이 제1저자입니다. 리원제 교수 지도 아래 홍콩 이공대학교(PolyU) NLP 그룹에서 나온 논문입니다. Bian은 멀티모달 추론 효율화를 주제로 연구하면서, 이미지가 텍스트만큼 좋은 추론 공간이 될 수 있는지를 오랫동안 탐색해 왔습니다. 이 논문은 그 물음을 정면으로 파고든 결과입니다.
배경
Chain-of-Thought(CoT)가 언어 모델 성능을 높이는 데 효과적이라는 것은 이제 상식입니다. 최근 흐름은 여기서 한 발 더 나아가 "interleaved-modal reasoning"으로 확장됩니다. 추론 중간 단계에 텍스트뿐 아니라 시각 정보도 섞어 넣는 방식입니다.
그런데 이 논문은 훨씬 더 급진적인 질문을 던집니다. 이미지만으로 추론을 할 수 있는가? 텍스트 스크래치패드 대신, 이미지 자체가 사고 공간이 될 수 있는가?
이 발상이 흥미로운 이유가 있습니다. 이미지는 텍스트와 달리 수식·그래프·공간 관계·다이어그램을 자연스럽게 담는 매체입니다. 텍스트보다 "표현력이 높거나 낮다"는 문제가 아니라, 다른 종류의 표현 매체입니다. 동일한 정보를 더 밀도 높게 담을 수 있다면 토큰도 아낄 수 있습니다.
어떻게 만들었나

논문은 이 아이디어를 Optical Reasoning으로 이름 짓고 두 가지 방식으로 구현합니다.
타이포그래픽 방식 (T-OR)
텍스트 추론 과정을 이미지로 렌더링하는 방식입니다. XeLaTeX로 글자 크기·줄 간격·여백·텍스트 폭을 조절해 정해진 토큰 예산 안에서 정보 밀도를 최대화하는 레이아웃을 찾습니다.
레이아웃 집합 \(\mathcal{C} = \mathcal{W} \times \mathcal{S}\) (텍스트 폭 집합 × 글자 크기 집합)에서 후보를 탐색하고, 점수 함수로 최적 레이아웃 \(\ell^*\)를 고릅니다:
\[S(\ell) = \rho(\ell) - \lambda \cdot \varepsilon(\ell)\]
여기서 \(\rho(\ell)\)은 이미지 채움 비율(fill ratio), \(\varepsilon(\ell)\)는 레이아웃 품질 페널티, \(\lambda\)는 균형 가중치입니다. 모델이 수용하는 토큰 예산 \(B\) 이하를 만족하는 후보 중 가장 점수가 높은 레이아웃을 씁니다.
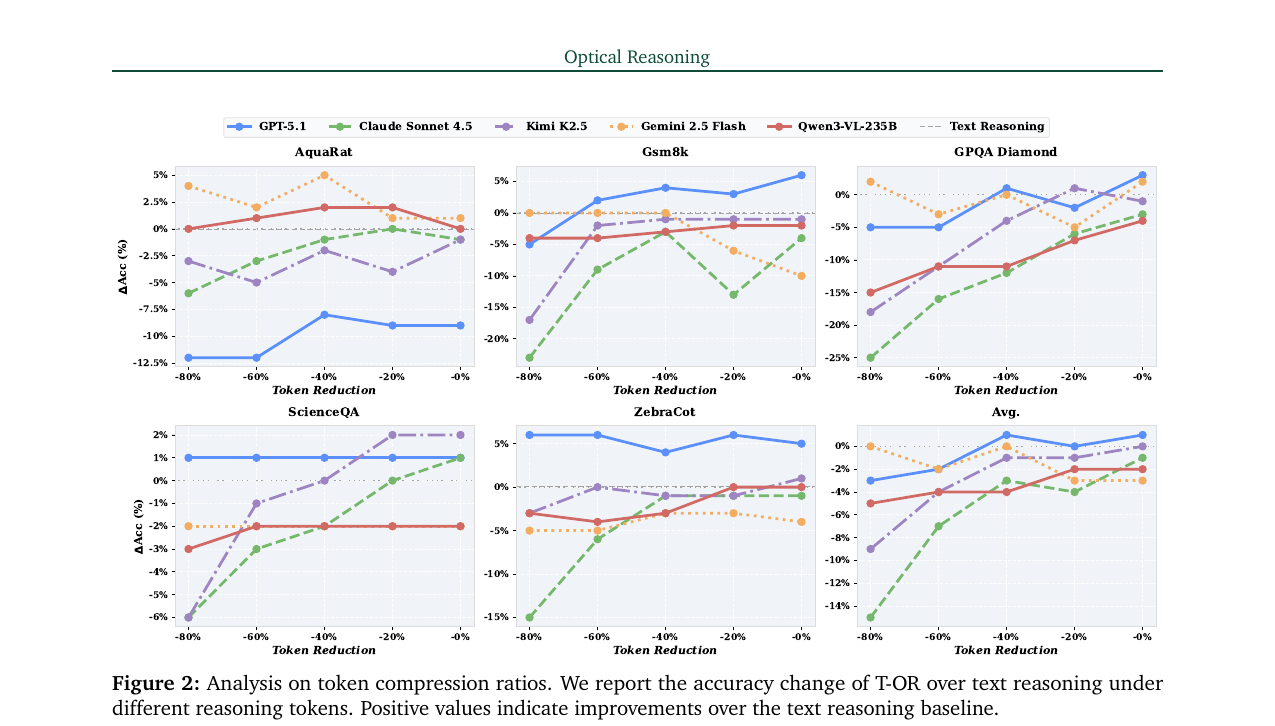
이 방식의 핵심은 토큰 예산을 파라미터로 쓴다는 점입니다. \(-80\%\)부터 \(-0\%\)까지 토큰 감축 비율을 조절하면서 정확도-효율성 트레이드오프를 실험할 수 있습니다.
그래픽 방식 (G-OR)
텍스트와 그래픽 요소를 하나의 시각적 캔버스로 합성합니다. Nano Banana 2 모델이 추론 단계를 분해해서 각 단계를 패널로 배치하고, 핵심 수식·텍스트를 유지하면서 개념을 시각 구조로 표현합니다.
T-OR이 텍스트를 그냥 이미지로 찍어주는 방식이라면, G-OR은 추론 과정 자체를 다이어그램·그래프 언어로 재표현하는 방식입니다.
추론 흐름 공식화
텍스트 추론에서 모델은 질문 토큰 \(\mathbf{q}\)와 텍스트 추론 과정 \(r_{\text{txt}}\)로부터 답을 도출합니다:
\[\mathbf{a} \sim \pi_\theta(\cdot \mid \mathbf{q}, \mathbf{r}_{\text{txt}})\]
Optical Reasoning은 \(r_{\text{txt}}\) 대신 렌더러 \(f\)가 만든 이미지 토큰 \(\mathbf{z}_{\text{vis}}\)를 씁니다:
\[\mathbf{a} \sim \pi_\theta(\cdot \mid \mathbf{q}, \mathbf{z}_{\text{vis}})\]
여기서 \(\mathbf{z}_{\text{vis}} = \phi(f(\mathbf{r}_{\text{mix}}))\)이고, \(\phi(\cdot)\)는 비전 인코더, \(\mathbf{r}_{\text{mix}}\)는 원래 interleaved 추론 과정입니다.
결과
T-OR 주요 결과
5개 프런티어 모델(GPT-5.1, Kimi K2.5, Gemini 2.5 Flash, Qwen3-VL-235B, Claude Sonnet 4.5)을 수학·과학·멀티모달 벤치마크 5개에서 평가했습니다.
효율성 지표로 **MAG (Marginal Accuracy Gain)**을 씁니다. 추론 토큰 1,000개당 no-reasoning 대비 정확도 향상을 나타냅니다:
\[\text{MAG}_m = \frac{Acc_m - Acc_{\text{no}}}{N_m}\]
토큰 감축 \(-80\%\) 조건에서의 T-OR 결과를 텍스트 추론과 비교하면 다음과 같습니다:
모델 |
설정 |
평균 정확도 |
MAG |
|---|---|---|---|
GPT-5.1 |
텍스트 추론 (257.8 tok) |
0.7715 |
1.27 |
GPT-5.1 |
T-OR \(-80\%\) (51.8 tok) |
0.7404 |
5.72 |
Kimi K2.5 |
텍스트 추론 |
0.8296 |
1.07 |
Kimi K2.5 |
T-OR \(-80\%\) |
0.7378 |
3.55 |
Gemini 2.5 Flash |
텍스트 추론 |
0.8309 |
1.21 |
Gemini 2.5 Flash |
T-OR \(-80\%\) |
0.8279 |
5.95 |
Qwen3-VL-235B |
텍스트 추론 |
0.8281 |
1.33 |
Qwen3-VL-235B |
T-OR \(-80\%\) |
0.7766 |
5.63 |
Claude Sonnet 4.5 |
텍스트 추론 |
0.8545 |
1.06 |
Claude Sonnet 4.5 |
T-OR \(-80\%\) |
0.7034 |
2.37 |
전체적으로 T-OR은 평균 MAG 1.96×를 달성합니다. 토큰을 80% 줄여도 Gemini 2.5 Flash는 정확도가 거의 같고(0.8279 vs 0.8309), GPT-5.1은 MAG 5.72로 토큰 대비 정보 효율이 텍스트의 4.5배에 달합니다.
언어 태스크에서는 평균 28.57% 토큰 절감, 멀티모달 태스크에서는 16% 절감하면서 동등한 정확도를 유지합니다.
G-OR 결과 (AquaRat)
AquaRat 데이터셋에서의 비교입니다:
설정 |
정확도 |
|---|---|
No reasoning |
0.689 |
텍스트 추론 |
0.732 |
T-OR \(-40\%\) (최고점) |
0.784 |
G-OR |
0.815 |
G-OR이 텍스트 추론(0.732)과 T-OR 최고점(0.784)을 모두 앞섭니다. 수학 추론에서 다이어그램·그래픽 표현이 순수 텍스트보다 더 많은 정보를 담는다는 증거입니다.
극한 압축
흥미로운 실험 결과가 하나 더 있습니다. T-OR을 \(-98.75\%\)까지 극단적으로 압축해도 추론 기능이 유지됩니다. 예제당 평균 7.2 토큰만 써도 풀버짓 텍스트 추론을 앞서는 케이스가 나옵니다.
이것은 이미지가 텍스트보다 정보 압축 효율이 높다는 강력한 증거입니다.
레이아웃 세부 분석
레이아웃 선택이 성능에 영향을 미칩니다: - 빨간색 텍스트 > 검정 기준선: 0.793 vs 0.773 (GPT-5.1, GPQA Diamond) - Heros 폰트 패밀리가 최고 성능: 0.778 - 매우 작은 폰트(8pt)는 정확도를 크게 낮춤: 0.722 - 좁은 텍스트 폭이 넓은 레이아웃보다 성능이 높음
모델마다 선호하는 렌더링 방식이 다릅니다. Qwen3-VL은 XeLaTeX, Gemini는 Matplotlib 렌더링을 더 잘 읽습니다. 이는 비전 인코더의 훈련 분포 차이에서 비롯됩니다.
회고
저자들이 솔직하게 적은 한계 두 가지입니다.
모델 의존성. T-OR 효과가 모델마다 크게 다릅니다. Claude Sonnet 4.5는 \(-80\%\) 압축에서 MAG가 2.37로 낮아지는 반면, Gemini 2.5 Flash는 5.95에 달합니다. 해상도 민감도, 레이아웃 밀도 처리 방식이 모델마다 다르기 때문입니다. 어떤 모델에 어떤 레이아웃이 맞는지 사전 검증이 필요합니다.
그래픽 환각. G-OR에서 생성된 다이어그램이 기하학적 제약을 어기거나 시각적으로 부정확한 경우가 있습니다. 언어 모델이 그린 도형이 실제 수식 관계를 정확히 반영하지 못할 수 있습니다.
정리
- 이미지는 텍스트 추론 공간을 대체할 수 있고, 잘 설계된 레이아웃으로 평균 \(1.96\times\) 높은 토큰 효율(MAG)을 달성합니다.
- T-OR(타이포그래픽)은 토큰 예산 제어가 가능한 범용 방식이고, G-OR(그래픽)은 수학처럼 시각화 이점이 뚜렷한 도메인에서 텍스트 추론을 직접 앞섭니다.
- 비전 인코더가 더 강해질수록 이 접근법의 효과도 커질 것으로 예상됩니다. 추론 토큰 비용 절감이 중요해지는 에이전트 시대에 실용적인 시사점을 줍니다.