SenseNova-U1 - Unifying Multimodal Understanding and Generation with NEO-unify Architecture
H. Diao, P. Wu, H. Deng, J. Wang, et al., "SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture," arXiv:2605.12500, 2026.
멀티모달 모델은 오래 이중적인 구조를 끌고 왔습니다. 이해(understanding) 쪽은 사전학습된 vision encoder(CLIP·SigLIP·DINOv2 같은)가 이미지를 의미 토큰으로 바꾸고, 생성(generation) 쪽은 VAE가 픽셀을 latent로 압축해 diffusion이 그 위에서 돕니다. 같은 트랜스포머 백본에 둘을 얹어도 토크나이저·헤드·학습 목표가 갈라져 있어서 진짜로 하나의 시스템이라고 말하긴 어려웠습니다.
SenseTime의 디아오 하이웬가 끌고 온 SenseNova-U1은 그 두 다리를 둘 다 잘라 버립니다. vision encoder도, VAE도 없습니다. 픽셀과 단어를 처음부터 한 트랜스포머 안의 같은 스트림으로 보고, 32×32 패치 단위로 자르고, 32× 압축률로 X2I(any-to-image) 생성까지 같이 합니다. 2026년 5월 12일 arXiv 공개, Apache 2.0 라이선스, dense 8B와 30B-A3B MoE 두 변종을 동시에 풀었습니다.
저자
Project Sponsor and Advisor는 린 다후아 단독 1인입니다. CUHK MMLab을 끌고 SenseTime을 공동창업한 인물이 모델·데이터·평가 전체에 우산을 씌운 구조입니다. Senior Project Lead 6명에는 NTU MMLab의 리우 즈웨이, SenseTime Research의 루 르웨이·Quan Wang·Wenxiu Sun, spatial intelligence 라인의 양 레이, 경량화·서빙 라인의 공 루이하오이 들어갔습니다. Project Lead는 디아오 하이웬 한 명입니다.
이 명단을 보면 합류 동기가 비교적 선명하게 읽힙니다. 디아오 하이웬는 EVE·EVEv2·NEO·NEO-unify로 본인이 끌고 온 encoder-free 노선의 산업적 결정판을 린 다후아 우산 아래 만들고 싶었던 것이고, 루 르웨이·공 루이하오 라인은 SenseTime 내부의 LIGHTLLM·LIGHTX2V·Phased DMD 같은 추론 인프라를 native unified 위에 얹는 역할입니다. 양 레이은 SenseNova-SI에서 쌓은 spatial intelligence 평가 자산을 U1 평가에 그대로 끌어들였습니다.
배경
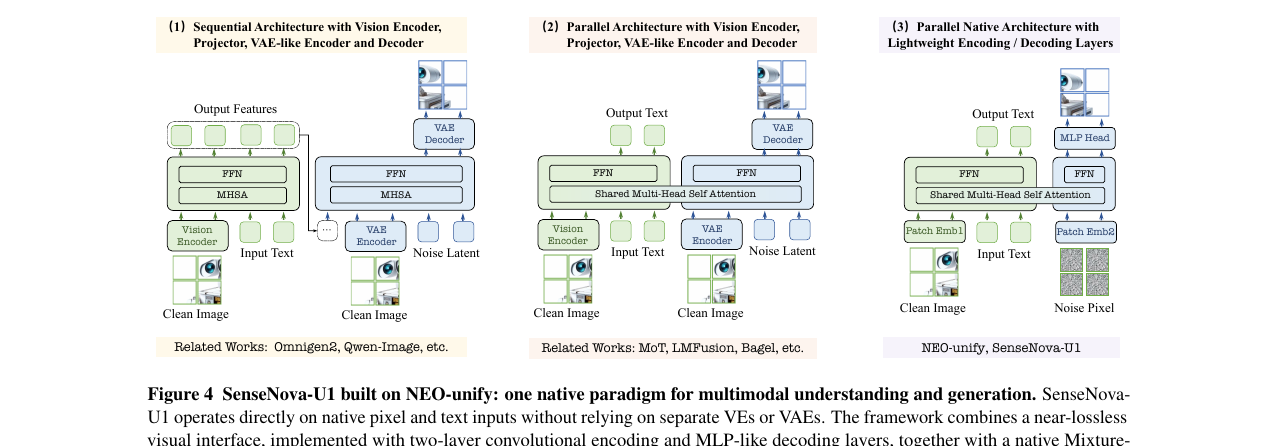
UMM(unified multimodal model) 줄기는 크게 두 갈래로 갈라져 있었습니다. 하나는 모든 모달리티를 discrete token으로 떨어뜨려 autoregressive로 묶는 노선입니다. Chameleon, Emu3, Janus가 여기에 가깝습니다. 시각이 lossy하게 압축되는 게 약점입니다. 다른 하나는 continuous한 시각 인터페이스를 가져가는 노선입니다. Show-o, OmniGen, BAGEL이 여기에 있고, 일부는 공유 tokenizer를, 일부는 representation autoencoder를 두지만, 결국 중간 표현이 의미와 픽셀 정밀도를 동시에 만족시키지 못한다는 본질적 한계는 그대로였습니다.
이 와중에 픽셀 공간에서 직접 모델링이 가능하다는 신호가 두 군데서 동시에 나왔습니다. 하나는 디아오 하이웬 본인의 EVE 계열이 "vision encoder 없이도 디코더만으로 vision-language가 된다"를 증명한 흐름, 다른 하나는 Tianhong Li·Kaiming He의 JiT·PixelFlow 계열이 "VAE latent 없이 픽셀에서 직접 diffusion이 된다"를 보인 흐름입니다. SenseNova-U1은 이 두 신호를 한 모델 안에서 동시에 실현한 첫 사례입니다. 그래서 논문이 굳이 "first principles로 돌아간다"는 표현을 반복합니다.
NEO-unify 디자인
핵심은 세 가지입니다.
Near-lossless visual interface. 패치 인코딩은 GELU를 끼운 2-layer convolution + 2D sinusoidal positional encoding으로 끝납니다. stride가 16·2라 토큰 하나가 32×32 픽셀 패치 하나에 대응합니다. 패치 디코딩은 MLP head 한 장이 다입니다. deep diffusion head도 VAE decoder도 없습니다.
Native Mixture-of-Transformers. 한 시퀀스 안에 understanding stream(clean image + text)과 generation stream(noise-conditioned input)이 같이 살고, self-attention은 둘이 공유하지만 projection·normalization·FFN은 stream별로 완전히 분리합니다. text는 causal로, image는 같은 블록 안에서 양방향으로 attention하고, noise 토큰은 clean 토큰을 볼 수 있지만 그 반대는 안 됩니다.
Pixel-space flow matching. 생성은 JiT 계열을 따라 픽셀 공간에서 v-loss로 학습합니다. 해상도에 따라 SNR이 안 어긋나도록 noise scale을 σR = σ₀ √(N(H,W)/N₀)로 잡고, timestep 임베딩과 같이 묶어 conditioning으로 넣습니다.
비교 대상이 명확합니다. Show-o·Janus는 VAE encoder + VAE decoder를 그대로 두고 별도 visual encoder까지 두는 sequential·parallel 구조이고, Chameleon·Emu3는 visual을 discrete token으로 떨궈 autoregressive에 넣는 노선입니다. SenseNova-U1은 그 둘과 달리 노이즈 픽셀과 텍스트가 처음부터 같은 dense backbone 안에서 만나는 형태입니다. 논문 자체가 이걸 3번째 카테고리 — "Parallel Native Architecture with Lightweight Encoding/Decoding Layers" — 로 분류하고 자기 자리만 거기에 둡니다.
학습은 6단계입니다. understanding warmup, generation pre-training 3개 phase, unified mid-training, unified SFT, Flow-GRPO 기반 T2I RL, DMD2 기반 step distillation. mid-training에서는 understanding 0.33, T2I 0.37, editing 0.24, interleaved 0.06으로 sampling하고, loss weight는 CE:MSE = 0.1:1.0입니다. understanding은 작은 가중치만 받지만 MoT의 파라미터 분리 덕에 generation이 understanding을 망가뜨리지 않습니다. RL 보상은 PaddleOCR로 텍스트 IoU를 재는 rendering reward, VLM judge가 1-4점으로 매기는 style reward, HPSv3가 매기는 aesthetic reward 세 갈래로, aesthetic 그룹이 어두운 배경을 선호하는 reward hacking이 있다는 것까지 본문에 솔직하게 적어놓았습니다.
결과
이해 쪽에서, 8B-Think 변종이 같은 backbone을 쓰는 Qwen3VL-8B-Think를 일관되게 앞섭니다.
벤치마크 |
SenseNova-U1-8B-Think |
Qwen3VL-8B-Think |
|---|---|---|
MMMU |
74.78 |
74.10 |
MathVista |
84.20 |
81.40 |
MathVision |
75.82 |
62.70 |
OCRBench |
82.10 |
81.90 |
Spatial intelligence(VSI-Bench, ViewSpatial, MindCube-Tiny, 3DSR-Bench) 트랙은 양 레이 라인이 끌고 들어와 32-frame 기준으로 Qwen3VL을 추월합니다. Qwen3VL이 128-frame을 써야 비교 가능한 점수를 내는 항목들이 따로 별표로 표시돼 있습니다.
생성 쪽 핵심 지표는 다음과 같습니다.
벤치마크 |
SenseNova-U1 |
비교군 |
|---|---|---|
GenEval |
0.91 |
Qwen-Image 0.87 / BAGEL 0.82 / Lumina-DiMOO 0.88 |
LongText-Bench-EN |
0.979 |
Seedream 4.5·Nano-Banana-Pro와 동급 |
CVTG-2K (word acc.) |
0.940 |
Seedream 4.5·Nano-Banana-Pro와 동급 |
BizGenEval Hard (8B) |
39.7 |
Emu3.5 28.2 (오픈소스 2위) |
DPG-Bench·OneIG·TIIF에서도 1등 또는 1등급. 인포그래픽 트랙(BizGenEval Hard)에서는 오픈소스 2위 Emu3.5와 11점 이상 격차가 벌어집니다.
reasoning-driven generation에서 CoT 효과가 뚜렷합니다.
- WISE: A3B-MoT-SFT CoT 0.81 → Seedream 4.0 0.78, Emu3.5 0.69
- RISEBench Logical (image editing): CoT off 7.1 → CoT on 20.0
추론을 명시적으로 흘려보내 편집을 분해하는 행동이 정말 데이터에 들어 있다는 신호입니다.
unified만의 강점은 RealUnify 트랙에서 또렷합니다.
모델 |
UEG |
GEU |
|---|---|---|
SenseNova-U1-8B-MoT-SFT |
55.7 |
47.5 |
BAGEL |
47.7 |
35.8 |
OneCAT |
39.0 |
29.2 |
understanding이 generation을 돕고, generation이 understanding을 돕는다는 양방향 synergy가 단순한 colocation이 아니라 정량적으로 확인됩니다.
회고
논문이 솔직하게 적어둔 한계가 셋 있습니다.
첫째, 이미지 편집의 전용 모델 대비 격차. ImgEdit Overall 비교는 다음과 같습니다.
모델 |
ImgEdit Overall |
|---|---|
Qwen-Image-Edit-2511 |
4.51 |
Emu3.5 |
4.41 |
SenseNova-U1-A3B |
3.91 |
SenseNova-U1-8B |
3.83 |
저자들도 현재의 editing 데이터가 open-source resource에 의존돼 있고 large-scale preference-aligned optimization이 부족하다고 본문에 명시했습니다.
둘째, A3B 변종의 RL 미완료. 8B는 unified general RL을 1,600 epoch 돌렸지만 A3B는 200 epoch에서 멈췄습니다. OneIG·DPG·LongText에서 A3B가 8B보다 일부 낮게 나오는 결과가 이 미완료의 흔적입니다.
셋째, MLP head 한 장이 32×32 패치를 독립적으로 그려서 grid artifact가 생긴다는 디자인 자체의 결함. RL 단계에서 마지막 3개 layer와 MLP head를 freeze해 회피했지만, 본인들이 본문에 PixelShuffle + 2-layer convolution으로 갈아 끼우는 게 promising direction이라고 미래 작업으로 미뤘습니다.
VLA(vision-language-action)와 World Modeling 실험은 정성적 수준의 preliminary 단계입니다. 로봇 매니퓰레이션 영상에서 네 프레임을 뽑아 행동 trajectory를 설명하게 하고, 행동 지시를 주면 시각 결과를 예측하는 식인데, 정량 벤치마크 점수는 없습니다. "이 아키텍처가 거기까지 확장될 수 있다"의 시그널이고, "거기서 SOTA를 찍었다"는 주장이 아닙니다. native unified가 시퀀스 의사결정으로 진입할 수 있다는 가능성 시연이고, world model로서의 양적 평가는 후속 작업으로 남아 있습니다.
숫자 주의와 활용
abstract와 본문에서 다른 숫자가 자주 잡힙니다. preprint니까 검증이 필요합니다. abstract는 "rival top-tier understanding-only VLMs"라고 표현했지만, Table 4의 Tau2(Tau-Bench)에서 SenseNova-U1-8B는 71.70, Qwen3.5-9B는 79.10으로 격차가 있습니다. agent benchmark는 동급이 아니라는 게 본문 §5.1.2에 솔직하게 적혀 있습니다. "32× compression ratio"라는 표현도 abstract와 본문에서 같이 쓰이지만, 실제로는 이미지 한 변당 32× downsample(32×32 patch)이지 토큰 차원 32× 압축이 아닙니다.
한국 기업 시각에서 흥미로운 자리는 두 곳입니다. 하나는 인포그래픽·문서 생성입니다. BizGenEval Hard에서 SenseNova-U1-8B가 39.7로 오픈소스 1등인데, 한글 차트·다이어그램·포스터 생성이 가능한 베이스 모델로서의 가치가 큽니다. 다른 하나는 VLA 사전학습입니다. 본문의 preliminary VLA 결과를 그대로 믿진 않더라도, native unified backbone을 자기 로봇·자율주행 데이터로 다시 SFT하는 시작점으로 쓰기는 좋습니다. Emu3.5는 BAAI 라이선스, BAGEL은 비상업 제약이 있는 반면 U1은 Apache 2.0이라 상업 이용·셀프호스팅·파인튜닝이 다 가능합니다.
정리
- VAE와 vision encoder를 둘 다 들어내고 픽셀과 단어를 한 dense MoT backbone 안에서 같이 학습하는 first-principle native unified 모델. dense 8B·30B-A3B MoE 두 변종, Apache 2.0.
- understanding은 같은 Qwen3VL backbone 모델 대비 일관된 우위, generation은 GenEval 0.91·LongText-Bench-EN 0.979·BizGenEval Hard 39.7으로 오픈소스 1위, RealUnify에서 양방향 understanding-generation synergy가 정량적으로 확인.
- 이미지 편집은 전용 모델 대비 한 단 낮고, A3B RL은 200 epoch에서 멈췄으며, VLA·World Modeling은 정성 수준의 preliminary 단계라는 점은 본문이 솔직하게 적어두고 후속 작업으로 미뤘습니다.