HYDRA-X - Native Unified Multimodal Models with Holistic Visual Tokenizers
G. Zhang, X. Qiu, Y. Cui, T. Song, et al., "HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers," arXiv:2606.13289, 2026.
저자
장궈전, 치우쉐루이, Yutao Cui가 공동 제1저자로 참여했습니다. 세 사람 모두 난징대학(Nanjing University) 왕리민 교수 그룹 소속입니다. 치우쉐루이는 중국과학원(CASIA)과 중관촌학원을 겸하는 박사과정생으로, 뉴로모픽 컴퓨팅과 LLM 양자화 경험을 시각 토크나이저 설계에 접목했습니다. Tencent Hunyuan, Shanghai AI Lab 소속 공동저자 10인이 가세해 모델 훈련과 평가 인프라를 뒷받침했습니다.
왕리민 교수는 비디오 이해·행동 인식 분야의 권위자로, TSN(Temporal Segment Networks) 등 장기 비디오 표현 연구로 이름을 알렸습니다. 이번 HYDRA-X는 그의 비디오 이해 전문성이 시각 통합 생성 모델로 확장된 결과물입니다.
배경
멀티모달 모델이 "무엇이든 이해하고 생성한다"고 광고하지만, 내부를 들여다보면 대부분 이해용 인코더와 생성용 디코더가 별도로 붙어 있는 구조입니다. Janus, Show-o, GILL 같은 통합 시도들도 이해와 생성에 서로 다른 시각 토크나이저를 씁니다. 하나가 다른 것의 대체물이 되지 못하는 이유는 간단합니다. 이해에 최적화된 연속형 특징(continuous feature)은 생성에 필요한 이산형 토큰(discrete token)과 구조적으로 다릅니다.
편집(image editing)은 그 위에 또 다른 층위를 요구합니다. 기존 구조를 유지하면서 특정 부분만 바꾸는 작업은, 이해와 생성 어느 쪽 토크나이저도 혼자서는 처리하기 어렵습니다.
HYDRA-X는 이 세 가지 역할을 단 하나의 시각 토크나이저(HYDRA-XTok)로 통합하겠다는 접근입니다. 토크나이저를 하나로 줄이면 모델 전체가 하나의 표현 공간에서 움직이고, 이해·생성·편집이 진정한 의미의 네이티브 통합을 이룰 수 있다는 것이 핵심 주장입니다.
어떻게 만들었나
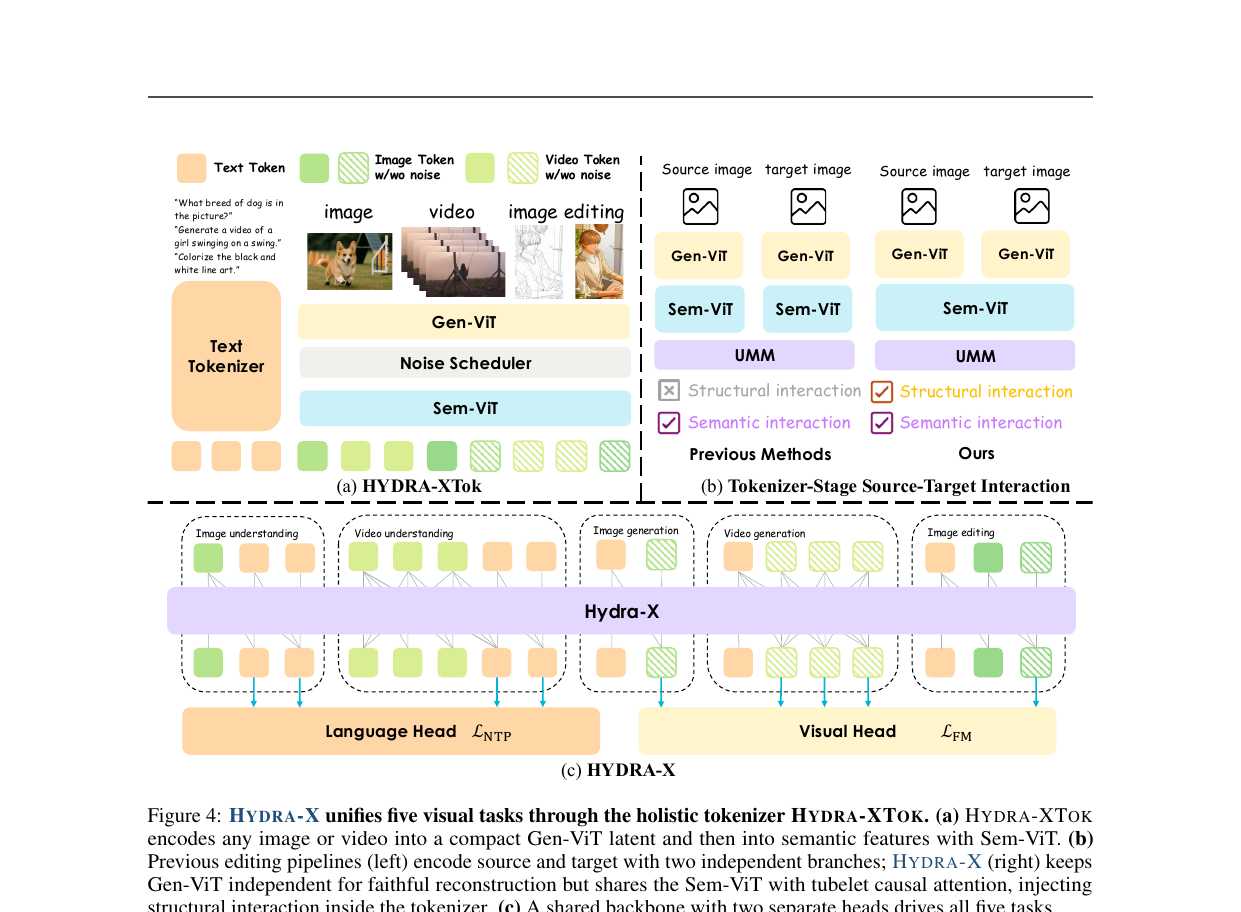
HYDRA-X는 크게 HYDRA-XTok(시각 토크나이저)과 7B LLM 백본, 그리고 STI(State Token Injection) 편집 메커니즘으로 구성됩니다.
HYDRA-XTok의 세 가지 반직관적 발견
설계 과정에서 저자들이 실험으로 밝힌 세 가지 발견이 눈에 띕니다.
첫째, 전체 시공간 어텐션보다 튜블릿 인과 어텐션이 낫습니다. 영상 시퀀스 전체에 걸쳐 어텐션을 계산하는 대신, 2-프레임 인과 윈도우(tubelet causal attention)만 써도 재구성 품질이 더 높습니다. 직관적으로는 더 넓은 문맥을 보는 편이 유리해 보이지만, 인과 방향을 고정하면 시간 순서 의존성이 학습하기 쉬워진다는 점이 실험에서 드러났습니다.
둘째, 한 번에 4×로 패치를 압축하는 것보다 계층적으로 2×씩 두 번 줄이는 편이 품질이 높습니다. 단일 4×4 패치파이(patchify) 방식은 공간 정보를 급격하게 손실시키는 반면, 계층적 2×2 패치파이는 중간 해상도를 거쳐 점진적으로 압축해 세밀한 텍스처를 더 잘 보존합니다.
셋째, 편집에서 STI는 LLM 레벨이 아닌 잠재 공간(latent) 레벨에서 주입해야 합니다. 원본 이미지 정보를 LLM 입력 단계에서 토큰으로 넣는 방식은 편집 일관성이 떨어집니다. 대신 VQVAE 디코더 레이어에 직접 잠재 상태를 주입하면, LLM이 자유롭게 편집 지시를 따르면서도 디코더가 원본의 구조적 정보를 참조할 수 있습니다.
STI (State Token Injection)
편집 과정을 따라가면 STI의 역할이 명확해집니다. 원본 이미지를 HYDRA-XTok으로 인코딩해 잠재 토큰을 얻습니다. LLM은 편집 지시를 받아 새로운 잠재 토큰을 생성하고, 디코더가 STI를 통해 원본 잠재 상태를 참조하면서 이 토큰을 픽셀로 복원합니다. LLM 단계에서는 편집 내용에 집중하고, 원본 구조 보존은 디코더가 맡는 역할 분리가 핵심입니다.
전체 아키텍처
HYDRA-XTok이 이미지와 영상 모두를 하나의 이산 토큰 공간으로 인코딩하면, 7B LLM이 이 토큰을 텍스트와 동등하게 다룹니다. 이해 태스크(이미지·영상 질문응답)에서는 시각 토큰을 입력으로 받아 텍스트를 출력하고, 생성과 편집에서는 텍스트 지시를 받아 시각 토큰을 출력한 뒤 디코더가 픽셀로 변환합니다. 하나의 토크나이저가 모든 방향의 변환을 매개한다는 점이 "네이티브 통합"의 실체입니다.
결과
재구성 품질
방법 |
이미지 PSNR |
이미지 SSIM |
rFID |
rFVD |
|---|---|---|---|---|
MAGVIT-v2 |
25.16 |
0.8195 |
1.15 |
25.2 |
Open-MAGVIT2 |
25.72 |
0.8261 |
1.17 |
24.7 |
VQVAE (기준) |
29.11 |
0.8704 |
0.48 |
18.3 |
HYDRA-XTok |
31.73 |
0.8936 |
0.329 |
11.19 |
재구성 단계에서 HYDRA-XTok은 이미지 PSNR 31.73, SSIM 0.8936, rFID 0.329, rFVD 11.19로 비교 대상 중 모든 지표에서 가장 좋은 수치를 기록했습니다. 특히 rFVD 11.19는 비디오 재구성 품질이 기존 MAGVIT 계열 대비 크게 향상되었음을 보여줍니다.
이미지 이해
벤치마크 |
HYDRA-X |
Janus-Pro-7B |
Emu3-Chat |
|---|---|---|---|
AI2D |
86.5 |
79.2 |
70.0 |
MME |
2350 |
2134 |
- |
MVBench (비디오) |
59.1 |
- |
- |
VideoMME |
60.0 |
- |
- |
이미지 이해에서 AI2D 86.5, MME 2350으로 동급 7B 통합 모델 대비 선두를 차지했습니다. 비디오 이해에서도 MVBench 59.1, VideoMME 60.0로 경쟁력 있는 수준을 유지했습니다.
생성과 편집
태스크 |
지표 |
HYDRA-X |
비교 대상 최상위 |
|---|---|---|---|
이미지 생성 |
GenEval |
0.88 |
FLUX.1-dev 0.84 |
이미지 편집 |
ImgEdit-Bench |
4.04 |
OmniCreator 3.78 |
이미지 편집 |
GEdit-Bench |
7.80 |
InstructPix2Pix 6.21 |
생성에서는 GenEval 0.88로 FLUX.1-dev(0.84)를 넘어섰고, 편집에서는 ImgEdit-Bench와 GEdit-Bench 모두 비교 대상 중 최고 점수를 기록했습니다. 단일 토크나이저로 생성과 편집을 동시에 처리하면서도 전문 모델과 견줄 만한 성능을 보인다는 점이 주목할 부분입니다.
회고
저자들이 직접 밝힌 한계가 세 가지입니다.
첫째, 훈련 스케일 제약입니다. 7B 밀집 LLM(dense LLM) 하나에 묶인 구조라 모델 크기를 키우거나 MoE(Mixture-of-Experts)로 확장하는 데 별도 작업이 필요합니다. 대형 통합 모델의 훈련 비용이 여전히 병목입니다.
둘째, 긴 비디오 생성과 편집을 지원하지 않습니다. 현재 HYDRA-X는 고정 길이 비디오를 대상으로 하며, 분 단위 이상의 장기 비디오 생성·편집은 이번 버전에서 다루지 않았습니다.
셋째, STI 편집 방식의 적용 범위입니다. 현재 STI는 이미지 편집에 특화되어 있고, 비디오 편집에 동일한 방식을 적용하는 것은 아직 탐색 중입니다.
정리
- 단일 시각 토크나이저(HYDRA-XTok)가 이해·생성·편집 세 역할을 모두 처리하는 네이티브 통합 방식
- 튜블릿 인과 어텐션, 계층적 2×2 패치파이, 잠재 공간 STI 세 가지 설계 선택이 각각 기존 직관을 뒤집은 실험 결과에 기반
- 이미지 생성 GenEval 0.88, 편집 ImgEdit-Bench 4.04로 전문 모델과 동급, 이해 AI2D 86.5로 7B 통합 모델 중 선두