MiniMax M3 - 오픈웨이트 프런티어 모델
MiniMax가 2026년 6월 1일 공개한 오픈웨이트 모델 MiniMax M3는 세 가지를 한 아키텍처에 담았다고 말합니다. 프런티어급 코딩, 1M 토큰 컨텍스트, 그리고 이미지와 비디오까지 받는 네이티브 멀티모달입니다.
그런데 발표 자료에서 진짜 눈여겨볼 건 이 조합 자체보다, 1M 컨텍스트에서 토큰당 연산을 이전 세대의 \(1/20\) 수준으로 줄였다는 새 어텐션 구조입니다. MiniMax는 이걸 MSA(MiniMax Sparse Attention)라고 부릅니다. 그리고 발표 시점에 한 가지 더 챙겨야 할 게 있습니다. 6월 1일 시점에는 가중치도 기술 리포트도 아직 안 나왔고, 모든 벤치마크 숫자가 MiniMax가 자기 인프라에서 직접 측정한 값이라는 점입니다. 이 글은 그 둘을 같이 봅니다.
MSA가 컨텍스트 비용을 줄이는 법
긴 컨텍스트가 비싼 이유는 표준 어텐션이 모든 토큰을 서로 다 보기 때문입니다. 시퀀스 길이 \(N\)에 대해 연산이 \(O(N^2)\)로 늘어나니, 1M 토큰이면 토큰 하나를 처리할 때마다 100만 개의 키-값을 전부 훑어야 합니다.
MSA는 여기서 "모든 KV를 보지 말고, 쓸 만한 블록만 골라서 보자"로 바꿉니다. 동작은 두 단계입니다. 먼저 가벼운 인덱스 분기가 GQA 그룹마다 공유하는 단일 키 헤드로 \(Q_{\text{idx}} \cdot K_{\text{idx}}^{\top}\)를 계산해 토큰별 점수를 거의 공짜로 뽑습니다. 그다음 이 점수를 약 64토큰짜리 블록 단위로 Block Max Pool해서 모으고, TopK로 각 쿼리 그룹이 실제로 볼 KV 블록을 추립니다. 같은 GQA 그룹의 쿼리들이 동일한 블록 선택을 공유하기 때문에, 한 번에 한 세트의 KV 블록만 SRAM에 올려 처리합니다.
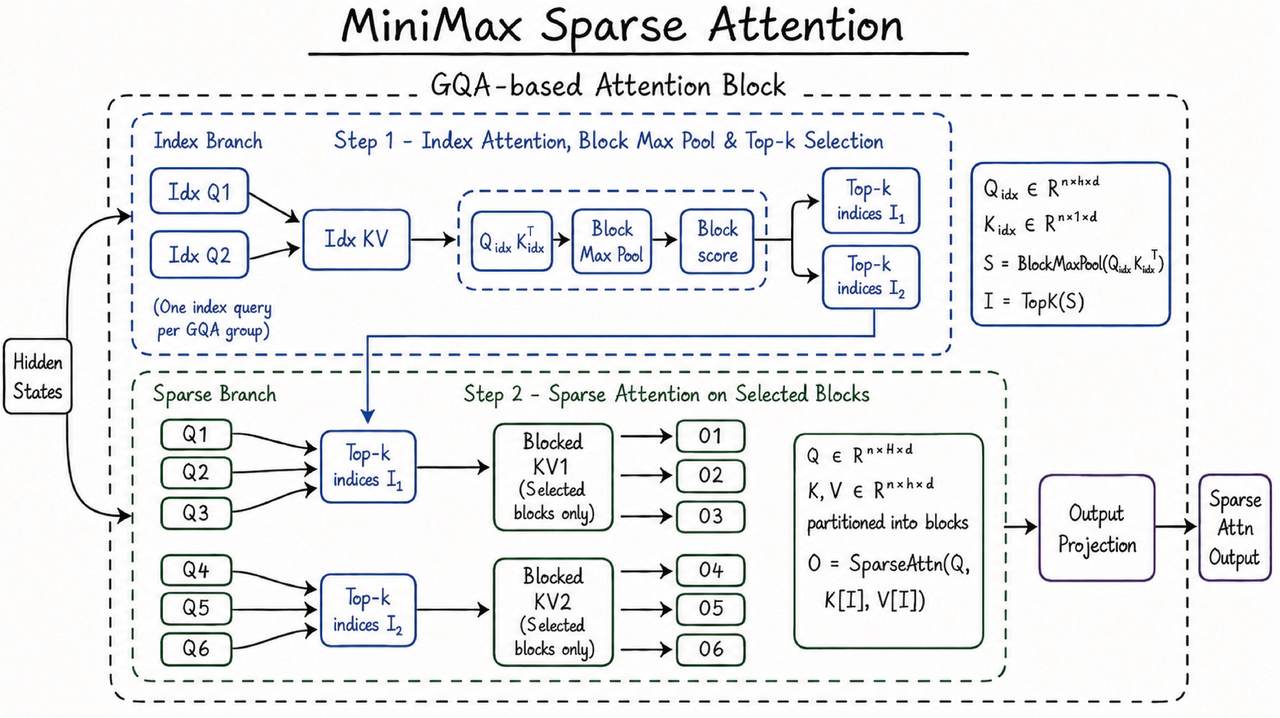
MiniMax가 공개한 MSA 구조도가 이 두 단계를 그대로 보여줍니다. 위쪽 인덱스 분기에서 Block Max Pool과 TopK로 어떤 KV 블록을 볼지 고르고, 아래쪽에서 그 선택된 블록 위에서만 어텐션을 계산해 출력으로 합칩니다.
핵심은 어텐션 자체는 원본 K/V 위에서 그대로 돈다는 점입니다. 압축된 KV로 근사하는 방식(CSA)과 달리 softmax 어텐션의 표현력을 그대로 두고, 대신 각 쿼리가 보는 블록 수를 줄여 메모리 대역폭 압력을 한 자릿수 가까이 떨어뜨립니다. DeepSeek의 DSA가 MLA latent 위에서 토큰 단위로 고르는 것과 달리 MSA는 표준 GQA로 돌아와 블록 단위로 고르고, NSA가 압축·선택·슬라이딩윈도우 세 분기를 두는 것과 달리 선택 분기 하나만 남깁니다.
MiniMax가 보고한 가속은 다음과 같습니다.
구간 |
M3(MSA) 대비 |
기준 |
|---|---|---|
1M 컨텍스트 토큰당 연산 |
\(1/20\) |
이전 세대 모델 |
prefill |
\(9\times\) 이상 |
이전 세대 모델 |
decoding |
\(15\times\) 이상 |
이전 세대 모델 |
처리 속도 |
\(4\times\) 이상 |
Flash-Sparse-Attention, flash-moba |
1M 컨텍스트에서 decode가 \(15.6\times\) 빨라진다는 수치를 64토큰 블록 가정으로 역산하면, 쿼리가 실제로 건드리는 블록은 전체의 6~7% 정도입니다. 유효 수용 영역이 6만~7만 토큰쯤 된다는 뜻이고, 이는 NSA 계열에서 보고된 희소도와 비슷한 수준입니다. 흥미로운 건 MiniMax가 이 희소 어텐션을 M2 세대에서 한 번 접었다가 M3에서 다시 꺼냈다는 점입니다.
왜 지금 이 조합인가
오픈웨이트, 롱컨텍스트, 멀티모달은 따로 보면 새롭지 않습니다. 셋이 한 모델에 같이 와야 의미가 생기는 건 에이전트 때문입니다.
코딩 에이전트나 컴퓨터 사용(computer-use) 에이전트는 한 작업을 끝내는 동안 레포 전체, 긴 실행 로그, 여러 번의 도구 호출 기록을 컨텍스트에 계속 쌓습니다. 1M 컨텍스트는 이 누적 기억을 한 번에 담기 위한 것이고, MSA는 그 긴 컨텍스트를 돌릴 때 비용이 폭발하지 않게 받쳐주는 장치입니다. 네이티브 멀티모달은 화면 스크린샷과 문서를 그대로 입력으로 받아 컴퓨터를 조작하기 위한 것입니다. M3는 이미지·비디오 입력과 데스크톱 조작을 함께 내세웁니다. 학습 단계부터 텍스트-이미지 인터리브 시퀀스로 100조 토큰 규모의 혼합 모달리티 학습을 했다고 밝혔습니다.
오픈웨이트는 이 모든 걸 자기 클러스터에서 돌리겠다는 선택지를 줍니다. 에이전트가 사내 코드와 화면을 통째로 컨텍스트에 넣는 상황에서 자체 호스팅 가능 여부는 실제 도입 결정을 가르는 조건이 됩니다. M3가 이 셋을 한 번에 묶어 "첫 오픈웨이트 프런티어"를 자처하는 이유입니다.
다만 발표 시점 기준으로 파라미터 수는 공개되지 않았습니다. 직전 M2가 총 \(229.9\)B 파라미터에 토큰당 \(9.8\)B를 활성화하는 MoE였다는 정도가 비교 기준으로 남아 있고, M3의 정확한 총/활성 파라미터는 기술 리포트를 기다려야 합니다.
벤치마크 숫자를 어떻게 읽을 것인가
MiniMax는 코딩과 에이전트 벤치마크에서 강한 숫자를 제시했습니다. SWE-Bench Pro \(59.0\)%로 GPT-5.5와 Gemini 3.1 Pro를 앞섰다고 보고했습니다. 다만 이 숫자들을 읽을 때 두 가지를 같이 봐야 합니다.
첫째, 모든 수치가 MiniMax 자체 인프라에서, 자사가 고른 에이전트 스캐폴딩으로 측정한 값입니다. 발표 시점에 Artificial Analysis나 LMArena 같은 독립 third-party 점수는 공개되지 않았습니다.
둘째, MiniMax가 비교 기준으로 삼은 모델이 Claude Opus 4.7입니다. 더 최근에 나온 Opus 4.8을 기준으로 두면 격차가 다시 벌어집니다.
벤치마크 |
M3(자체 측정) |
Opus 4.8 |
|---|---|---|
SWE-Bench Pro |
59.0 |
69.2 |
Terminal-Bench 2.1 |
66.0 |
74.6 |
OSWorld-Verified |
70.0 |
83.4 |
BrowseComp |
83.5 |
- |
M3가 GPT-5.5·Gemini 3.1 Pro를 앞섰다는 발표는 비교 대상을 Opus 4.7에 맞춘 결과이고, 현재 프런티어 천장인 Opus 4.8을 기준으로 보면 SWE-Bench Pro에서 10점 넘게, OSWorld에서는 13점가량 뒤집니다. 그렇다고 M3가 평범하다는 뜻은 아닙니다. 오픈웨이트로 풀리는 모델이 독점 프런티어에 한 자릿수~십수 점 차이까지 따라붙었고, 발표대로면 비용은 그 5~10% 수준이라는 점이 핵심입니다. 숫자 한 줄로 "프런티어 추월"을 받아들이기보다, 검증되지 않은 자체 측정값이라는 단서와 가격·오픈웨이트라는 강점을 같이 놓고 보는 게 맞습니다.
정리
- MiniMax M3는 프런티어 코딩, 1M 컨텍스트, 네이티브 멀티모달을 한 모델에 담은 오픈웨이트 모델입니다. 진짜 기여는 1M에서 토큰당 연산을 \(1/20\)로 줄이는 희소 어텐션 MSA입니다. 원본 K/V는 그대로 두고 볼 KV 블록만 TopK로 골라 decode를 \(15\times\) 이상 가속합니다.
- 발표 벤치마크(SWE-Bench Pro \(59.0\)% 등)는 전부 자체 측정이고 비교 기준이 Opus 4.7입니다. Opus 4.8 기준으로는 격차가 다시 벌어집니다. 다만 오픈웨이트로 그 수준에 근접한 비용 우위가 의미를 만듭니다.
- 6월 1일 시점에는 가중치·기술 리포트가 미공개였고 파라미터 수도 밝히지 않았습니다. MiniMax는 발표 후 약 10일 내(대략 6월 11일경) HuggingFace·GitHub에 가중치와 리포트를 공개하겠다고 했습니다. 정확한 아키텍처와 독립 검증 점수는 그 이후에 확인할 수 있습니다.