Cosmos 3 - Omnimodal World Models for Physical AI
NVIDIA, "Cosmos 3: Omnimodal World Models for Physical AI," arXiv:2606.02800, 2026.
식탁을 치우라는 명령을 받은 가정용 로봇을 떠올려 봅니다. 지금까지의 방식이라면 이 로봇은 서로 다른 모델을 이어 붙여야 합니다. 그릇이 어디 있는지 찾고 계획을 세우는 비전언어모델(VLM), 팔을 움직일 행동 시퀀스를 만드는 VLA나 월드 액션 모델(WAM), 그리고 그 행동의 결과를 미리 시뮬레이션하는 월드 모델. 인식, 시뮬레이션, 실행이 제각각 다른 모델에 흩어져 있습니다.
Cosmos 3는 이 조각들을 하나로 합칩니다. 언어, 이미지, 비디오, 오디오, 그리고 행동(action)까지 한 모델이 이해하고 생성합니다. NVIDIA는 이것을 "옴니모달 월드 모델(omnimodal world model)"이라 부르고, Physical AI를 위한 범용 백본으로 제안합니다.
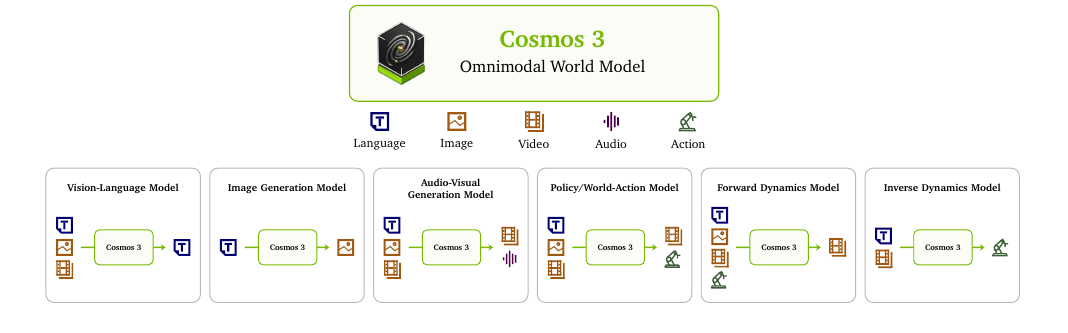
위 그림 한 장이 이 논문의 야심을 그대로 보여줍니다. 입출력 구성을 바꾸기만 하면 같은 모델이 비전언어모델이 되기도 하고, 이미지 생성기, 오디오 영상 생성기, 정책(policy) 모델, 순방향 동역학 모델, 역방향 동역학 모델이 되기도 합니다.
저자
저자 명단에 300명이 넘게 올라 있는 대형 기술 리포트입니다. 개인이 아니라 조직이 쓴 논문에 가깝고, 실제로 논문은 저자를 "NVIDIA"로 표기합니다. 그래서 여기서는 신상보다 어느 연구 축이 모였는지가 중요합니다.
프로젝트 전체는 밍유 리우가 이끄는 Cosmos Lab이 중심입니다. 그는 NVIDIA Research 부사장으로, "장면이 어떻게 보이는가"가 아니라 "기계가 어떻게 움직이는가"를 모델링한다는 월드 파운데이션 모델의 문제의식을 오래 밀어 온 사람입니다. 여기에 3D 비전과 공간 지능의 산야 피들러, 컴퓨터비전과 멀티모달 표현 학습의 얀 카우츠, 그리고 임바디드 에이전트와 휴머노이드 정책의 짐 판이 합류했습니다.
이 조합이 그대로 Cosmos 3의 설계를 설명합니다. 보는 것(비전), 만드는 것(생성), 움직이는 것(행동)을 따로 연구하던 세 축이 한 모델 안에서 만나야 한다는 것이 이 논문의 출발점입니다.
배경
기존 패러다임은 이해와 생성을 분리해 왔습니다. 인식과 추론은 VLM 같은 판별 모델이, 미래 시뮬레이션은 비디오 생성 모델과 순방향 동역학 모델이, 행동 예측은 VLA와 WAM이 맡았습니다.
논문은 이 분리가 근본적으로 비효율이라고 봅니다. 이해는 결국 세상이 앞으로 어떻게 변할지, 내 행동이 어떤 결과를 낳을지 추론하는 일입니다. 생성은 세상과 행동을 압축한 구조적 표현에 기댑니다. 둘은 같은 동전의 양면인데, 별개 모델로 쪼개 두면 표현을 공유하지 못하고 파이프라인만 무거워집니다.
그래서 질문이 이렇게 바뀝니다. 인식, 시뮬레이션, 실행에 필요한 능력을 한 모델이 네이티브로 다 처리할 수는 없을까. Cosmos 3는 여기에 "하나의 모델로 가능하다"고 답합니다.
어떻게 만들었나
핵심은 모달리티별 인코더, 구조화된 토큰 배치, 그리고 Mixture-of-Transformers(MoT) 백본 세 가지입니다.
먼저 인코더입니다. 이미지와 비디오는 용도에 따라 두 인코더를 씁니다. 이해용으로는 비전언어 정렬로 사전학습된 ViT를, 생성용으로는 Wan2.2의 비디오 VAE를 씁니다. ViT는 학습 중 백본과 함께 갱신되지만, 생성용 VAE는 얼려 둡니다(frozen). 오디오는 48kHz 스테레오를 hop size 1920으로 인코딩해 초당 \(25\)개 토큰으로 만듭니다. 행동은 별도의 토큰 클래스로 다루는데, 연속한 비디오 토큰 사이의 전이를 행동 토큰으로 봅니다. 자세는 절대값이 아니라 상대 변환 \(\Delta T_t = T_{t-1}^{-1} T_t\)로 표현하고, 회전은 6D 표현을 씁니다. 자율주행 차량, 카메라, 로봇 팔, 사람 손처럼 제어 공간이 제각각인 임바디먼트를 도메인별 입출력 프로젝션으로 묶어 공유 표현 공간에 올립니다.
토큰 배치가 이 모델의 묘수입니다. 입력 시퀀스는 두 덩어리로 나뉩니다. 앞쪽은 자기회귀(AR) 서브시퀀스로, 언어 토큰과 ViT가 인코딩한 이미지, 비디오 토큰이 들어가 추론과 이해를 담당합니다. 뒤쪽은 확산(diffusion) 서브시퀀스로, VAE가 인코딩한 이미지, 비디오, 오디오, 행동 토큰이 들어갑니다. 추론할 때 언어 토큰은 다음 토큰 예측으로, 나머지 모달리티는 반복적 디노이징으로 생성됩니다.
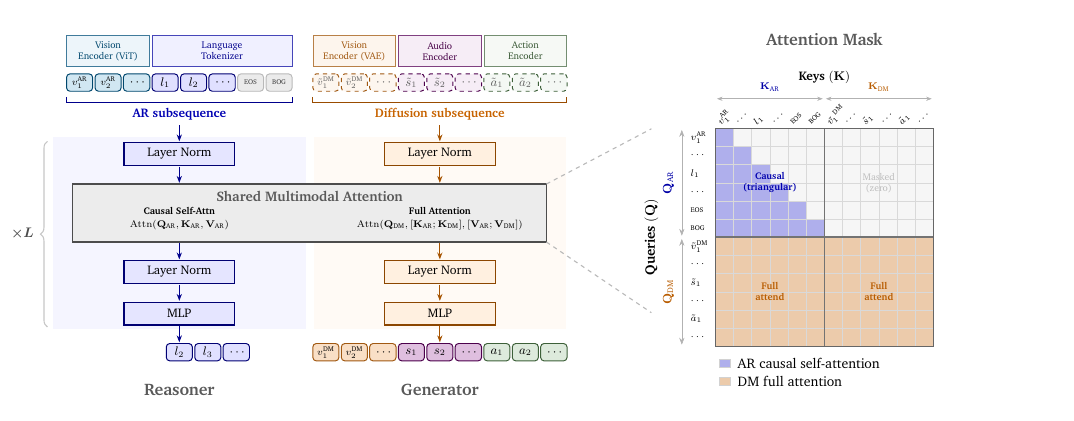
MoT 백본은 이 두 흐름을 한 네트워크에서 다룹니다. 각 트랜스포머 디코더 층은 파라미터 집합을 두 벌 가집니다. 하나는 AR 토큰을 처리하는 추론기(Reasoner), 다른 하나는 확산 토큰을 처리하는 생성기(Generator)입니다. 두 타워는 분리돼 있지만 매 층에서 공유 어텐션(joint attention)으로 서로를 봅니다. 어텐션 마스크가 핵심인데, AR 토큰끼리는 인과적(causal) 자기 어텐션을 쓰고, 확산 토큰은 풀 어텐션으로 AR 토큰까지 모두 참조합니다. 추론으로 맥락을 먼저 잡고, 그 맥락 위에서 생성을 펼치는 구조입니다. 위치 임베딩은 3D MRoPE를 써서 언어 생성과의 하위 호환을 유지합니다.
무엇으로 구성돼 있나
이번 공개에는 두 크기가 들어 있습니다. Cosmos3-Nano는 Qwen3-VL 8B 아키텍처를 가져와 LLM 부분이 36층, 히든 차원 4,096입니다. Cosmos3-Super는 Qwen3-VL 32B 기반으로 64층, 히든 차원 5,120입니다. 더 작은 온디바이스용 Cosmos3-Edge는 추후 릴리스로 미뤘습니다.
여기에 후속 학습(post-training)으로 전문가 변형을 만듭니다. Cosmos3-Super-Text2Image, Cosmos3-Super-Image2Video, 그리고 로봇 정책용 Cosmos3-Nano-Policy-DROID가 그것입니다. 즉 하나의 공통 백본을 두고, 목적별 데이터로 갈래를 쳐 특화 모델을 뽑는 방식입니다. 아키텍처를 바꾸지 않고도 합성 데이터 생성기로도, 로봇 정책으로도 변신합니다.
결과
가장 흥미로운 곳은 추론(이해) 벤치마크입니다. NVIDIA는 일반 지식, 로보틱스, 스마트 인프라, 자율주행 네 범주로 나눠 측정했습니다.
모델 |
General |
Robotics |
Smart infra. |
Driving |
|---|---|---|---|---|
Cosmos3-Super |
73.7 |
57.8 |
62.6 |
79.3 |
Cosmos3-Nano |
69.6 |
55.1 |
61.0 |
76.0 |
Gemini 3.1 Pro† |
77.5 |
58.2 |
58.6 |
47.2 |
Qwen3-VL-32B |
72.8 |
52.6 |
56.1 |
40.7 |
Gemma-4-31B |
69.8 |
51.0 |
51.3 |
36.6 |
† 비공개(closed) 모델. 굵게 표시는 각 컬럼 최고 점수.
표를 읽으면 강점과 한계가 동시에 드러납니다. Cosmos3-Super는 자율주행에서 79.3, 스마트 인프라에서 62.6으로 비공개 모델까지 포함해 1위입니다. 특히 자율주행은 Gemini 3.1 Pro의 47.2를 30점 넘게 앞섭니다. Physical AI에 직접 닿는 범주일수록 Cosmos 3가 크게 앞선다는 뜻입니다. 반면 일반 지식 추론(General)은 Gemini 3.1 Pro 77.5에 뒤지고, 로보틱스도 58.2 대 57.8로 근소하게 뒤집니다. 범용 추론에서는 아직 비공개 프런티어에 미치지 못합니다.
생성 쪽은 후속 학습한 전문가 변형이 끌고 갑니다. Cosmos3-Super-Text2Image는 텍스트-투-이미지에서 91.36점을 기록했고, NVIDIA는 리포트 작성 시점 기준으로 Artificial Analysis가 오픈소스 텍스트-투-이미지와 이미지-투-비디오 1위로, RoboArena가 정책 모델 1위로 매겼다고 밝힙니다. 생성 품질과 로봇 정책 양쪽에서 오픈 모델 중 선두라는 주장입니다.
회고
리포트는 자기 한계를 비교적 솔직하게 드러냅니다. 일반 지식 추론에서 비공개 Gemini 3.1 Pro에 뒤진다는 점이 표에 그대로 남아 있습니다. Cosmos 3의 우위는 어디까지나 Physical AI 특화 범주에 있고, 범용 멀티모달 추론으로 가면 격차가 좁혀지거나 역전됩니다.
읽을 때 주의할 점도 있습니다. 표의 일부 수치는 단일 base 모델이 아니라 후속 학습한 전문가 변형(표기 *)으로 측정한 값입니다. zero-shot 범용 성능과 특화 성능을 같은 줄에서 비교하면 오해할 수 있습니다. 또 arXiv 기술 리포트라 저널 리뷰를 거치지 않은 preprint입니다.
방법론 자체의 과제도 남습니다. Cosmos 3는 대규모 합성 데이터(SDG 데이터셋군)에 크게 기댑니다. 합성 환경으로 학습한 모델이 실제 세계로 넘어갈 때의 간극, 즉 sim-to-real 문제는 이 논문이 끝낸 숙제가 아니라 오히려 더 본격적으로 마주해야 할 지점입니다. 논문도 Cosmos 3를 "합성 세계와 실제 세계를 잇는 다리"로 표현하며, 그 다리를 건너는 일은 후속 연구에 남겨 둡니다.
정리
- 따로 놀던 VLM, 비디오 생성기, 월드 시뮬레이터, VLA를 하나의 Mixture-of-Transformers 백본으로 통합했습니다. 자기회귀 추론 타워와 확산 생성 타워가 공유 어텐션으로 맞물리는 구조가 핵심입니다.
- 자율주행과 스마트 인프라 같은 Physical AI 특화 추론, 그리고 오픈소스 생성 품질에서 강점을 보이지만, 범용 지식 추론은 비공개 프런티어 모델에 아직 못 미칩니다.
- 코드, 체크포인트, 합성 데이터셋, 평가 벤치마크를 OpenMDW-1.1 라이선스로 공개해 임바디드 에이전트 연구의 출발점을 낮췄습니다.