Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos
X. Feng, J. Zhu, M. Wu, C. Chen, F. Mao, H. Guo, J. Wu, X. Chu, and K. Huang, "Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos," arXiv:2605.18233, 2026.
비디오 디퓨전 모델은 보통 16~81프레임짜리 짧은 클립을 위해 학습됩니다. 그런데 영화·게임 개발·월드 시뮬레이션처럼 길고 일관된 영상이 필요한 응용은 따로 모델을 처음부터 학습하기에 비용이 너무 큽니다. 그래서 등장한 흐름이 train-free long video generation, 즉 기성 foundation 모델을 그대로 두고 추론 시점에만 긴 영상을 뽑아내는 방법입니다. FIFO-Diffusion이 이 흐름의 대표 주자로, queue 길이만큼 메모리를 고정한 채 무한 길이의 영상을 만들 수 있다는 장점이 있습니다.
MIGA는 이 FIFO 계열의 두 가지 약점을 정면으로 다룹니다. 첫째, 학습-추론 노이즈 갭. 학습할 때는 한 클립의 모든 프레임이 같은 noise level을 받지만, FIFO 추론에서는 한 큐 안에서 프레임마다 noise level이 다 다릅니다. 둘째, 장기 일관성 모델링 부재. FIFO는 인접 chunk 간 lookahead만 하지 멀리 떨어진 프레임을 묶지 않습니다. MIGA는 Two-Stage Training-Inference Alignment(TTA)와 Dual Consistency Enhancement(DCE) 두 메커니즘으로 이 두 약점을 동시에 푸는 방식입니다. ICML 2026 accept.
저자
알리바바 AMAP 측 8명과 학계 CASIA 측 1명이 묶인 형태입니다. 1저자 펑샤오쿤은 중국과학원 자동화연구소(CASIA) 박사과정 학생으로, 본 작업은 알리바바 AMAP 인턴 기간에 수행한 것입니다. 본 전공은 visual-language object tracking이라 프레임 간 일관성 평가를 추적 도메인 감각으로 다룹니다. 본 논문의 self-reflection이 cosine similarity 기반 anomaly detection으로 풀린 점이 그 출신과 잘 맞아 떨어집니다.
corresponding author는 두 명입니다. CASIA 측은 황카이치 정교수로 시각 추적 분야 시니어 PI이고, 알리바바 AMAP 측 시니어는 추샹샹 Senior Director로 FairNAS·Twins·CPVT 등 영향력 있는 아키텍처 논문 저자입니다. project lead는 우자홍가 맡았고, AMAP-ML GitHub org에 공개된 S²-Guidance, VMBench, MACE-Dance, Omni-Effects, ImagerySearch 같은 train-free·평가 시리즈와 직접 이어집니다.
저자들은 conflict of interest 공시에서 흥미로운 지점을 짚어 둡니다. 실험에 쓴 foundation 모델 중 하나인 Wan2.1은 같은 알리바바 산하지만 Tongyi Lab이 독립적으로 개발했고, 저자들은 공개 오픈소스 릴리스 이외에는 별도 접근 권한이 없었다는 점입니다. VBench·NarrLV 표준 프로토콜로 평가했다는 공정성 선언이기도 합니다.
배경

train-free long video generation은 크게 두 방향이 있었습니다.
첫 번째는 입력 latent를 더 많이 넣자는 방향입니다. FreeNoise는 window-based fusion으로 noise 재구조화, FreeLong은 frequency 영역에서 long/short 통합, FreePCA는 principal component 분석으로 global/local 합치기. 메모리가 프레임 수에 선형으로 늘어나서 minute-long video를 만들기 어렵습니다.
두 번째는 frame-level autoregressive 방향입니다. Diffusion-Forcing, AR-Diffusion은 프레임마다 다른 noise level을 할당해 autoregressive 생성을 가능하게 했습니다. 그중 FIFO-Diffusion(NeurIPS 2024)이 핵심입니다. noise level이 증가하는 큐를 유지하면서 한 끝에서 깨끗한 프레임을 꺼내고 다른 끝에서 새로운 가우시안 프레임을 넣는 first-in-first-out 구조라, 메모리를 고정한 채 무한 길이 영상을 만들 수 있습니다.
문제는 FIFO도 두 약점이 남는다는 것입니다. 학습 때는 한 클립의 모든 프레임이 single noise level을 보지만, 추론 때 큐 안에는 \(f_0\)만큼의 noise level이 동시에 들어 있습니다. 이 노이즈 스팬이 모델 입장에서는 학습 분포 밖이라 content drift, visual artifact가 나옵니다. 또 FIFO의 lookahead는 인접 chunk만 묶지, 멀리 떨어진 프레임끼리는 정보가 안 통합니다. MIGA는 이 두 곳을 각각 TTA와 DCE로 봉합합니다.
기존 데이터셋·방법론과의 위치는 다음과 같이 정리됩니다.
방법 |
Infinite |
핵심 아이디어 |
|---|---|---|
FreeNoise |
X |
window-based noise rescheduling |
FreeLong |
X |
dual-frequency attention |
FreePCA |
X |
principal component 분석 |
FIFO-Diffusion |
O |
FIFO queue, diagonal denoising |
ScalingNoise |
O |
DINO 기반 reward로 test-time search |
MIGA (본 논문) |
O |
TTA + DCE (zigzag + self-reflection + long guidance) |
어떻게 만들었나
MIGA의 코어는 TTA와 DCE 두 메커니즘입니다. 베이스가 FIFO-Diffusion이라는 점만 알면 차이를 따라가기 쉽습니다.
Two-Stage Training-Inference Alignment (TTA)
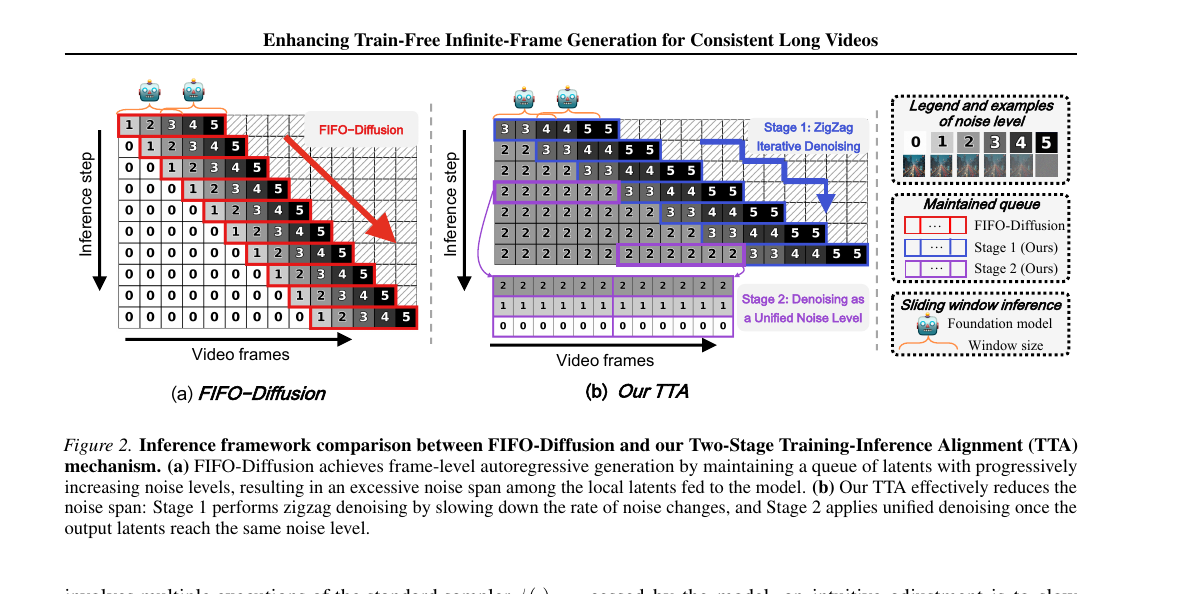
FIFO-Diffusion의 큐는 매 프레임마다 noise level이 한 칸씩 다릅니다. 그러면 한 inference step이 처리해야 하는 noise span은 \(f_0\) 만큼 넓습니다. MIGA는 이 span을 두 단계로 좁힙니다.
Stage 1: Zigzag Iterative Denoising. 큐를 \(L_{\text{zig}}\) 단위로 묶어, 같은 블록 안에서는 같은 noise level을 공유하게 만듭니다. 식으로 쓰면
\[\mathcal{Q}_{s_1} = \{ \underbrace{\mathbf{z}^1_{\tau_e}, \ldots, \mathbf{z}^{L_{\text{zig}}}_{\tau_e}}_{L_{\text{zig}}}, \underbrace{\mathbf{z}^{L_{\text{zig}}+1}_{\tau_{e+1}}, \ldots}_{L_{\text{zig}}}, \ldots \}.\]
매 iteration에서 큐 앞쪽 \(L_{\text{zig}}\) latent를 dequeue하고 새 가우시안 noise \(L_{\text{zig}}\)개를 큐 뒤에 enqueue합니다. 매 frame마다가 아니라 \(L_{\text{zig}}\) 단위로 noise level이 바뀌므로 입력 span이 줄어듭니다.
Stage 2: Denoising at a Unified Noise Level. Stage 1을 충분히 돌리면 모든 프레임이 동일한 시간단계 \(\tau_{e-1}\)에 도달합니다. 그러면 그때부터는 학습 때와 동일하게 single noise level 큐 \(\mathcal{Q}_{s_2} = \{ \mathbf{z}^1_{\tau_{e-1}}, \ldots, \mathbf{z}^{nL_{\text{zig}}}_{\tau_{e-1}} \}\)로 sliding-window denoising만 돌리면 됩니다. 이 단계가 학습-추론 갭을 완전히 0으로 만듭니다.
핵심 통찰은 한 가지입니다. Stage 1만 돌리면 자기회귀 성격은 유지되지만 noise span이 여전히 남고, Stage 2만 돌리면 noise span은 0이지만 큐 안 latent 간 상관이 사라져 일관성이 깨집니다. 둘을 순서대로 쓰면 Stage 1이 latent 간 implicit 정보 전이를 만든 뒤 Stage 2가 깨끗하게 마무리하는 시너지가 생깁니다. Stage 2만 돌린 ablation은 O.S. 95.02 → 94.25로 떨어지는 게 그 증거입니다.
Dual Consistency Enhancement (DCE)
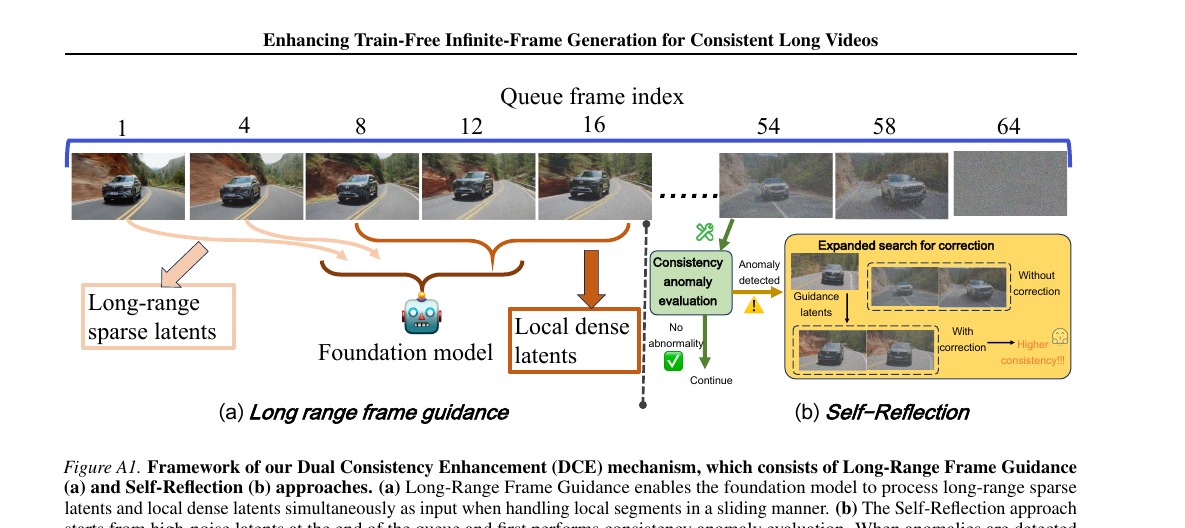
TTA가 세로축(큐 단위 추론) 일관성을 잡았다면 DCE는 가로축(프레임 단위 슬라이딩) 일관성을 잡습니다. 두 갈래입니다.
Self-Reflection. 큐의 끝쪽(=high-noise 신참 프레임)이 갑자기 이전 chunk와 어긋나는 anomaly를 잡아 즉시 보정합니다. 외부 평가 모델(DINO 같은) 없이 latent 자기 자신의 코사인 similarity로 평가합니다. evaluation latent \(\mathbf{q}_{\text{eval}}\)과 reference latent \(\mathbf{q}_{\text{ref}}\)에 대해
\[\mathbf{q}'_{\text{eval}} = \text{norm}_1(\text{mean}_2(\mathbf{q}_{\text{eval}})), \quad \mathbf{q}'_{\text{ref}} = \text{norm}_1(\text{mean}_2(\mathbf{q}_{\text{ref}})),\]
\[C_{\text{score}} = \text{mean}_1 \big( \text{mean}_2 (\mathbf{q}'_{\text{eval}} \mathbf{q}'^{\,\top}_{\text{ref}}) \big).\]
인접 chunk 간 \(C_{\text{score}}\) 변화가 임계 \(\delta_{\text{adju}}\)를 넘으면 expanded search를 트리거합니다. \(n_{\text{samp}}\)개의 후보 noise를 새로 뽑아 다시 denoising하고, 그중 가장 높은 \(C_{\text{score}}\)를 내는 sample로 교체합니다. 핵심은 clean latent를 거치지 않고 latent 공간에서 직접 평가한다는 점입니다. ScalingNoise처럼 DINO·VAE decode 패스를 매번 돌릴 필요가 없어 비용이 가볍습니다.
Long-Range Frame Guidance. 큐 앞쪽(=low-noise, 거의 깨끗한 프레임)을 멀리 떨어진 위치에서 sparse하게 뽑아 현재 sliding-window의 컨텍스트로 끼워 넣습니다. 모델이 한 번에 보는 입력은
\[q_{\text{input}} = [z^1, \ldots, z^{m_{\text{guid}}}, z^l, \ldots, z^{l+f_0-m_{\text{guid}}-1}].\]
앞쪽 \(m_{\text{guid}}\)개는 멀리 떨어진 guidance, 뒤쪽 \(f_0 - m_{\text{guid}}\)개는 현재 local window입니다. FIFO가 인접 chunk만 묶었다면 이 메커니즘은 수십~수백 프레임 떨어진 프레임끼리 attention을 통해 직접 영향을 주고받게 합니다.
기반 모델 호환성
저자들은 MIGA를 VideoCrafter2(default 16 latent)와 Wan2.1-1.3B(default 21 latent)에 모두 적용합니다. VideoCrafter2-MIGA는 \(T = 64\), \(L_{\text{zig}} = 4\), \(\tau_e = 10\), \(\delta_{\text{adju}} = 0.01\), \(m_{\text{guid}} = 6\). Wan2.1-MIGA는 \(T = 54\), \(L_{\text{zig}} = 7\), \(\tau_e = 10\), \(\delta_{\text{adju}} = 0.01\), \(m_{\text{guid}} = 4\). CogVideoX-5B 같은 MMDiT 구조에는 깔리지 않습니다. text feature가 video token과 함께 noise 조건과 상호작용하기 때문에 frame별 noise level을 다르게 줄 수가 없습니다. 저자들이 이 한계를 부록 A.4에 명시합니다.
결과
평가는 VBench (subject/background/motion/temporal flicker/overall 5개 지표)와 NarrLV (narrative-centric, TNA=2/3/4 세 난이도) 두 벤치마크에서 진행합니다.
VBench (메인 결과)
VideoCrafter2 기준 128프레임, Wan2.1 기준 161프레임 영상을 생성한 결과입니다.
베이스 |
방법 |
Infinite |
S.C. |
B.C. |
M.S. |
T.F. |
O.S. |
|---|---|---|---|---|---|---|---|
VideoCrafter2 |
FreePCA |
X |
93.57 |
95.24 |
93.73 |
91.27 |
93.45 |
VideoCrafter2 |
FreeLong |
X |
95.72 |
96.42 |
98.38 |
97.28 |
96.95 |
VideoCrafter2 |
FIFO-Diffusion |
O |
92.92 |
95.01 |
97.89 |
94.94 |
95.02 |
VideoCrafter2 |
ScalingNoise |
O |
94.29 |
95.52 |
97.86 |
96.12 |
95.95 |
VideoCrafter2 |
MIGA |
O |
97.66 |
96.99 |
98.60 |
98.03 |
97.82 |
Wan2.1 |
FIFO-Diffusion |
O |
92.67 |
93.37 |
98.03 |
97.09 |
95.29 |
Wan2.1 |
MIGA |
O |
96.46 |
95.50 |
98.85 |
98.14 |
97.24 |
S.C.=Subject Consistency, B.C.=Background Consistency, M.S.=Motion Smoothness, T.F.=Temporal Flicker, O.S.=Overall Score.
VideoCrafter2 기준 MIGA는 같은 베이스의 FIFO-Diffusion 대비 S.C. +4.74, B.C. +1.98, O.S. +2.80을 얻습니다. 더 강한 baseline인 FreeLong(non-infinite)까지 모든 지표에서 넘어섭니다. Wan2.1 기준에서도 FIFO-Diffusion 대비 S.C. +3.79, B.C. +2.13. 흥미로운 점은 Wan2.1-MIGA가 VideoCrafter2-MIGA보다 S.C./B.C.에서 약간 낮다는 사실입니다. 저자 설명은 VideoCrafter2가 애니메이션풍을 잘 만들어 일관성이 상대적으로 쉽고, Wan2.1은 사실적 텍스처를 잘 만들어 일관성이 어렵다는 트레이드오프 때문이라는 것입니다.
NarrLV (narrative-centric, varying TNA)
NarrLV는 텍스트 narrative complexity(TNA=temporal narrative atom count)별로 평가합니다. 행=시스템, 열=난이도/지표:
방법 |
TNA=2 (s/t_att/t_act) |
TNA=3 |
TNA=4 |
|---|---|---|---|
FIFO-Diffusion (VC2) |
67.02 / 63.55 / 58.29 |
61.15 / 60.64 / 58.42 |
66.09 / 66.01 / 54.66 |
MIGA (VC2) |
69.78 / 63.94 / 59.01 |
63.53 / 61.05 / 59.52 |
68.87 / 68.77 / 55.78 |
FIFO-Diffusion (Wan2.1) |
67.77 / 64.25 / 65.40 |
55.42 / 59.02 / 58.91 |
57.43 / 56.10 / 53.89 |
MIGA (Wan2.1) |
79.32 / 67.87 / 67.94 |
69.48 / 66.33 / 63.86 |
75.05 / 72.31 / 62.90 |
Wan2.1 기준 TNA=4의 s_att가 57.43 → 75.05(+17.6점)로 가장 큰 폭. 복잡한 narrative일수록 baseline이 더 무너지고 MIGA가 더 살린다는 패턴입니다. Wan2.1-MIGA가 narrative expressiveness에서는 VideoCrafter2-MIGA를 큰 폭으로 앞서는데, Wan2.1이 좀 더 강한 텍스트 추종 능력을 갖고 있기 때문으로 보입니다.
어블레이션 (TTA · DCE 기여 분리)
VideoCrafter2 + VBench 기준입니다.
TTA |
DCE |
S.C. |
B.C. |
M.S. |
T.F. |
O.S. |
|---|---|---|---|---|---|---|
92.92 |
95.01 |
97.19 |
94.94 |
95.02 |
||
✓ |
96.74 |
96.75 |
97.57 |
97.12 |
97.05 |
|
✓ |
96.10 |
96.47 |
97.88 |
96.56 |
96.75 |
|
✓ |
✓ |
97.66 |
96.99 |
98.60 |
98.03 |
97.82 |
TTA 단독 +2.03, DCE 단독 +1.73, 둘 다 +2.80 (O.S. 기준). 두 메커니즘이 겹치지 않는 축을 잡고 있어 합쳐서 거의 합산만큼 오릅니다. \(L_{\text{zig}}\) ablation은 \(L_{\text{zig}}=4\)에서 O.S. 최고를 찍고 그 위는 saturate, \(m_{\text{guid}}\) ablation은 \(m_{\text{guid}}=6\)에서 최고. Stage 2 step 수는 25 부근에서 최고를 찍고 64(=Stage 2 only)에서 O.S. 95.80 → 94.25로 무너집니다.
트레이닝-기반 모델과의 비교 (참고용)
train-free MIGA가 train-based 모델과도 견줄 수 있는지 부록 B.4에서 따로 확인합니다.
방법 |
학습 여부 |
S.C. |
B.C. |
M.S. |
T.F. |
O.S. |
|---|---|---|---|---|---|---|
CausVid |
trained |
97.89 |
96.53 |
98.03 |
96.49 |
97.24 |
Self-Forcing |
trained |
97.13 |
96.02 |
98.44 |
96.96 |
97.14 |
LongLive |
trained |
98.00 |
96.76 |
98.74 |
97.34 |
97.71 |
Infinity-RoPE |
trained |
98.61 |
97.03 |
98.89 |
97.79 |
98.08 |
Reward Forcing |
trained |
96.44 |
95.66 |
98.40 |
96.42 |
96.73 |
MIGA (VC2) |
train-free |
97.66 |
96.99 |
98.60 |
98.03 |
97.82 |
MIGA (Wan2.1) |
train-free |
96.46 |
95.50 |
98.85 |
98.14 |
97.24 |
T.F.(Temporal Flicker)와 M.S.(Motion Smoothness)에서는 train-free MIGA가 train-based 모델 다섯을 다 넘습니다. S.C./B.C./O.S.도 Infinity-RoPE 정도만 분명히 앞설 뿐, 나머지와는 어깨를 나란히 합니다. 학습 비용 0인 train-free 접근이 large-scale 학습 모델과 동급이라는 점이 이 논문의 가장 무거운 메시지입니다.
효율
VideoCrafter2 베이스에서 프레임당 생성 시간 \(M_t\):
방법 |
\(M_t\) (s) |
O.S. |
|---|---|---|
FIFO-Diffusion |
7.48 |
95.02 |
MIGA w/o DCE |
7.53 |
96.75 |
MIGA (full) |
9.16 |
97.82 |
TTA만 켜면 비용 거의 동일(+0.05s)에 +1.73 O.S. DCE까지 켜면 +1.68s에 +1.07 O.S. 추가. 메모리는 1000~2000프레임으로 늘려도 9929 → 9985 MiB로 거의 안 오릅니다(베이스 9919 대비 +0.10~+0.66%). 무한 프레임 약속이 메모리적으로도 실제로 지켜집니다.
사용자 평가
48 prompt × 8 annotator pairwise 비교. MIGA가 4개 차원에서 FIFO-Diffusion보다 일관되게 선호됩니다.
차원 |
MIGA Better |
Tie |
FIFO Better |
|---|---|---|---|
Subject Consistency |
62.23 |
21.88 |
15.89 |
Background Consistency |
61.72 |
20.83 |
17.45 |
Motion Smoothness |
66.14 |
19.79 |
14.06 |
Temporal Flicker |
66.14 |
17.70 |
16.15 |
회고
저자들이 부록 A.4·B.2·C에서 직접 적은 한계는 셋입니다.
첫째, MMDiT 구조 호환 실패. CogVideoX-5B 같은 모델은 text feature와 video token이 한 attention에서 noise condition과 함께 상호작용합니다. 그래서 프레임마다 noise level을 다르게 줄 수가 없습니다. 부록 Figure A3에 CogVideoX로 마이그레이션을 시도한 결과가 실려 있는데, 거의 노이즈만 남은 결과입니다. MIGA는 cross-attention으로 text를 받는 모델 군(VideoCrafter2, Wan2.1)에만 깔립니다.
둘째, 장기 hallucination. 부록 Figure A5에 cat이 천천히 걷는 영상에서 어느 순간 머리와 꼬리가 갑자기 자리를 바꾸는 케이스가 정직하게 실립니다. 일관성 메커니즘으로 chunk-level 변동은 잡지만 물리적 plausibility 자체는 베이스 모델의 한계라는 점입니다. 저자들은 future work로 text를 넘는 추가 conditioning(예: pose, depth)이 필요하다고 적습니다.
셋째, 베이스 모델 의존성. Wan2.1-MIGA의 S.C./B.C.가 VideoCrafter2-MIGA보다 낮은 이유가 Wan2.1이 사실적이라 일관성이 어려운 데이터 분포 때문이라는 설명은, 뒤집어 보면 MIGA가 어떤 베이스를 쓰느냐에 결과 천장이 묶여 있다는 뜻이기도 합니다. train-free의 본질적 한계입니다.
정리
- MIGA는 FIFO-Diffusion 계열 train-free long video generation의 두 약점(학습-추론 noise gap, 장기 일관성 부재)을 TTA와 DCE 두 메커니즘으로 동시에 봉합합니다.
- VideoCrafter2·Wan2.1 두 베이스 모두에서 같은 베이스의 FIFO 대비 O.S. +1.95~+2.80, Subject Consistency +3.79~+4.74. train-based 모델 다섯과도 T.F./M.S.에서는 앞서고 S.C./O.S.는 동급입니다.
- 메모리는 1,000~2,000프레임까지 거의 일정, 프레임당 생성 시간은 FIFO 대비 +1.7초 정도. MMDiT 구조 비호환과 물리적 plausibility 한계는 베이스 모델 측 숙제로 남깁니다.