Learning Hierarchical Features for Scene Labeling
C. Farabet, C. Couprie, L. Najman, and Y. LeCun, "Learning Hierarchical Features for Scene Labeling," IEEE Trans. Pattern Anal. Mach. Intell., vol. 35, no. 8, pp. 1915-1929, August 2013.
2013년 IEEE TPAMI 한 호에 실린 정본입니다. 같은 작업이 1년 전 ICML 2012에 Scene Parsing with Multiscale Feature Learning, Purity Trees, and Optimal Covers라는 제목의 학회 압축본으로 먼저 나왔습니다. 본문은 두 글을 함께 다룹니다. ICML 2012가 학회 압축본, TPAMI 2013이 저널 정본의 관계입니다.
이 논문이 푸는 문제는 장면 분할(scene labeling) 또는 *의미적 분할(semantic segmentation)*입니다. 한 이미지의 모든 픽셀에 클래스 라벨을 붙이는 작업이고, 검출·분할·인식 세 가지가 한꺼번에 들어가야 합니다. 사람 얼굴이 보이는 픽셀이면 얼굴이고, 그 옆 회색 픽셀은 도로인지 건물인지 하늘인지가 주변 맥락에 따라 결정됩니다. 짧은 거리 정보와 긴 거리 정보가 동시에 필요한 작업입니다.
저자들이 푸는 방식은 두 갈래입니다. 한 갈래는 큰 맥락을 한 번에 보는 다중 스케일 합성곱 망이고, 다른 한 갈래는 영상 경사 위에서 만든 분할 트리에서 클래스 순도를 최소화하는 영역 선택입니다. 두 갈래가 만나는 자리에서 학습 가능한 표현과 도메인 특수적인 경사 정보가 동시에 작동합니다.
저자
저자 네 명은 두 곳에서 공동으로 일하던 그룹입니다. NYU Courant Institute의 얀 르쿤 연구실 한쪽, Université Paris-Est의 로랑 나즈만 A3SI 팀이 다른 한쪽입니다. 1저자 클레망 파라베가 두 연구실 공동 박사과정 학생이었고, 본 논문의 구현 전체를 Torch7로 작성하였습니다. 그가 박사 시절 같이 만든 NeuFlow FPGA가 한 장 처리 시간을 60ms로 줄여 실시간 장면 분할을 처음으로 보여줍니다.
카미유 쿠프리는 같은 나즈만 지도로 2011년 박사 학위를 받은 직후 NYU 얀 르쿤 그룹에 포스닥으로 합류한 인물입니다. 박사 논문이 Power Watersheds로, 그래프 컷·랜덤 워크·워터셰드를 같은 최적화 식 안에 묶은 작업이었습니다. 그 박사 시절의 그래프 기반 분할 노하우가 본 논문의 segmentation tree와 optimal cover 후처리 단으로 곧장 들어옵니다.
로랑 나즈만은 ESIEE Paris 정교수로, 수리형태학과 워터셰드의 권위자입니다. 본 논문에서 그가 가져온 것은 영상 경사 그래프 위의 최소 신장 트리로 분할 트리를 만드는 이론적 토대입니다. 얀 르쿤이 시니어 지도자로 합성곱 망 쪽을, 나즈만이 수리형태학 쪽을 받쳐주는 구도입니다.
네 사람이 한 논문에 모인 이유는 분할 작업의 두 갈래가 동시에 필요하기 때문입니다. 합성곱 망 혼자서는 픽셀 경계를 정확히 못 그리고, 수리형태학 혼자서는 픽셀에 의미를 못 붙입니다. 두 쪽이 만나야 실시간으로 픽셀에 정확한 라벨이 붙는 시스템이 나옵니다.
배경
2012년은 AlexNet이 ImageNet 분류를 가져간 직후입니다. 같은 시기 장면 분할 분야는 다른 흐름을 따르고 있었습니다. 주류 방법은 (1) 영상을 superpixel이나 분할 후보 집합으로 over-segmentation하고, (2) 각 후보의 수작업 특징(SIFT, HOG, 텍스처)을 추출해, (3) MRF나 CRF 같은 그래프 모델로 라벨의 전역 일관성을 강제하는 세 단계 파이프라인이었습니다.
저자들이 §I에서 정리하는 두 가지 핵심 질문이 있습니다. 첫째, 시각 정보의 좋은 내부 표현을 어떻게 만들 것인가. 둘째, 맥락 정보를 어떻게 활용해 해석의 자기 일관성을 보장할 것인가. 본 논문이 두 질문에 한 가지 답을 제시합니다. 큰 입력 윈도우 위에서 작동하는 합성곱 망이 두 질문을 동시에 해결한다는 것입니다.
같은 시기 ConvNet을 장면 분할에 적용한 선행 작업은 Grangier et al.(ICML 2009 Deep Learning Workshop) 정도가 있었지만, 정확도는 미흡했고 수작업 특징을 완전히 대체하지 못했습니다. 본 논문은 원시 픽셀에서 끝까지 학습된 특징만으로 그 시점 모든 방법을 따라잡습니다.
다중 스케일 합성곱 망
본 논문의 첫 갈래는 다중 스케일 합성곱 망입니다. 같은 합성곱 망 \(f_{\theta_0}\)를 Laplacian 피라미드의 세 해상도 입력 \(\mathbf{X}_1, \mathbf{X}_2, \mathbf{X}_3\)에 가중치를 공유한 채로 적용합니다.
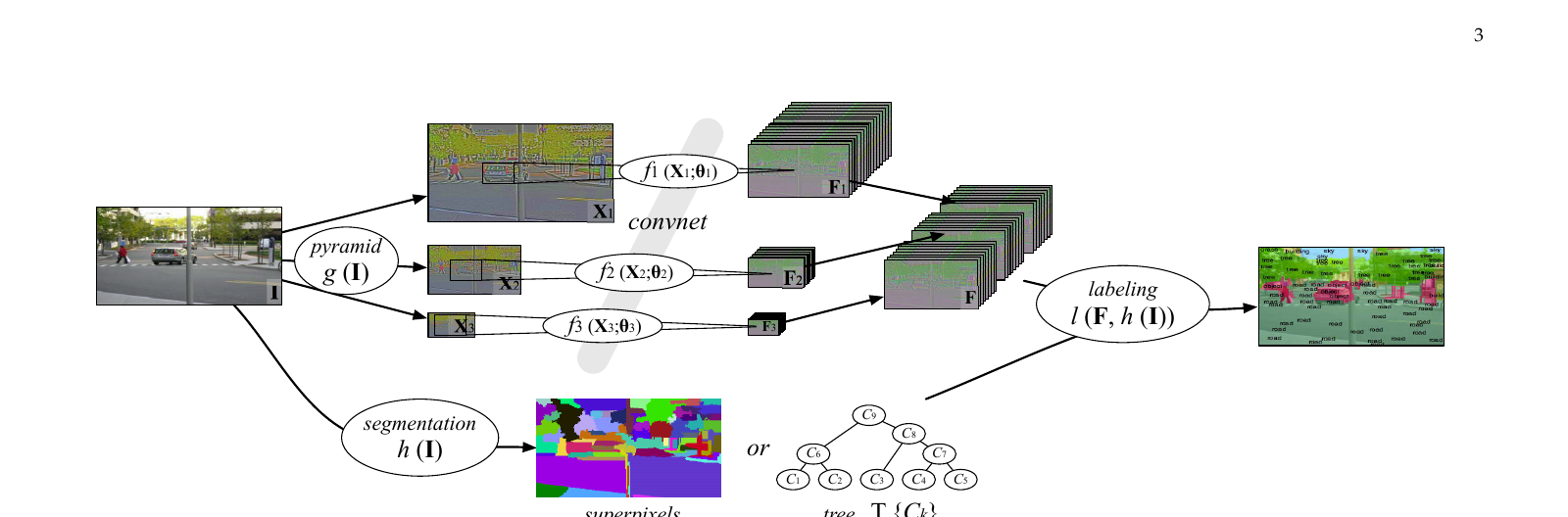
가중치 공유의 동기는 두 가지입니다. 첫째, 영상 통계는 스케일 불변이라는 가정으로 같은 함수가 모든 스케일에서 작동해야 자연스럽습니다. 둘째, 세 스케일을 동시에 학습 데이터로 쓰는 셈이라 일반화에 유리합니다. 저자들이 §3.1 끝에서 가중치 공유를 풀면 성능이 떨어진다고 명시합니다.
세 스케일의 출력 \(f(\mathbf{X}_s; \theta_0)\)를 가장 큰 해상도로 업샘플링해 채널 방향으로 이어붙이면, 픽셀 한 점당 세 가지 크기의 맥락 윈도우에서 본 특징 벡터가 나옵니다. 본 논문의 실험 설정으로는 \(46 \times 46\), \(92 \times 92\), \(184 \times 184\) 입력 윈도우입니다. 가장 큰 윈도우는 \(320 \times 240\) 영상의 거의 전체에 해당합니다.
망 자체는 3단 합성곱입니다. 첫 두 단은 \(7 \times 7\) 필터 + \(\tanh\) + \(2 \times 2\) 최대 풀링, 마지막 단은 필터만 있습니다. 입력은 YUV 변환 후 지역 평균·분산 정규화된 \(15 \times 15\) 패치 단위로 처리됩니다. 채널 차원은 \(3 \to 16 \to 64 \to 256\)으로 증가합니다. 세 스케일을 이어붙이면 한 픽셀당 \(256 \times 3 = 768\)차원 특징 벡터가 나옵니다.
학습은 우선 픽셀 단위 분류 손실로 진행합니다.
\[L_{\text{cat}} = -\sum_{i \in \text{pixels}} \sum_{a \in \text{classes}} c_{i,a} \ln(\hat{c}_{i,a}), \qquad \hat{c}_{i,a} = \frac{e^{w_a^\top \mathbf{F}_i}}{\sum_{b} e^{w_b^\top \mathbf{F}_i}}.\]
여기서 \(\mathbf{F}_i\)가 픽셀 \(i\)의 특징 벡터, \(w_a\)는 학습 보조용 임시 선형 분류기 가중치입니다. 학습이 끝나면 이 임시 분류기는 버리고 \(\mathbf{F}\)만 남깁니다. 클래스 불균형이 큰 데이터셋에서는 클래스 빈도 균형 샘플링이 결정적입니다. 자연 빈도로 학습하면 작은 물체를 놓치고, 균형 빈도로 학습하면 작은 물체까지 잡아냅니다.
이 단계만으로도 \(320 \times 240\) 영상의 픽셀별 분류 점수 지도가 나옵니다. 단순히 최대 점수 클래스를 픽셀에 붙이면 그게 곧 장면 분할입니다. Stanford Background에서 원시 다중 스케일 망 자체로 픽셀 정확도 \(78.8\%\), 클래스 평균 \(72.4\%\)가 나옵니다. 이 숫자만으로도 본 논문 이전의 모든 방법을 이깁니다.
문제는 시각적 정밀도입니다. 합성곱 망은 풀링 때문에 물체 경계를 정확히 못 그립니다. 곡선이 둥글게 뭉개지고, 작은 물체가 사라집니다. 픽셀 정확도가 같아도 경계가 어긋난 분할은 사용자가 받아들이기 어렵습니다. 그래서 후처리 단이 필요합니다.
분할 트리와 optimal cover
본 논문의 두 번째 갈래가 후처리입니다. 합성곱 망의 출력을 영상 경사에 맞춰 정렬시키는 단계인데, 저자들이 세 가지 전략을 §4에서 비교합니다.
가장 단순한 전략은 superpixel입니다. 영상을 색상 일관 영역으로 over-segmentation(Felzenszwalb 방법)한 다음, 각 superpixel 안의 픽셀들이 합성곱 망 점수를 평균하여 한 표를 던지게 합니다. 영역 단위 다수결이라 빠르고, Stanford Background에서 0.7초 만에 끝나면서 픽셀 정확도가 \(80.4\%\)로 올라갑니다.
두 번째 전략은 superpixel 위의 CRF입니다. 단항 항으로 합성곱 망 점수를 쓰고, 쌍항 항으로 영상 경사 크기를 쓰는 표준 CRF를 \(\alpha\)-확장으로 푼다. Stanford Background에서 \(81.4\%\)로 가장 높은 픽셀 정확도가 나오지만 60초가 걸립니다.
세 번째이자 본 논문의 진짜 기여가 Optimal Purity Cover입니다. 고정된 분할 한 장을 쓰지 않고 *분할의 가족(family)*에서 골라 쓰자는 발상입니다. 작은 물체 픽셀은 작은 분할 영역에서, 큰 물체 픽셀은 큰 분할 영역에서 가져옵니다. 이 가족을 만드는 가장 쉬운 구조가 분할 트리입니다.
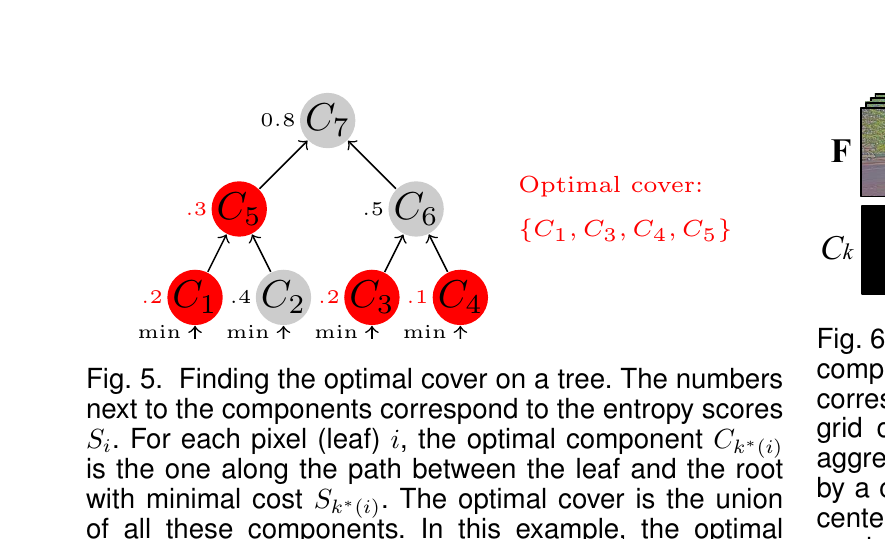
분할 트리는 영상 경사 그래프 위에서 최소 신장 트리 기반의 영역 합병 결과입니다. 각 트리 노드 \(C_k\)는 영상의 한 가능한 분할 영역에 대응합니다. 각 노드에 비용 \(S_k\)가 붙는데, 본 논문에서는 해당 영역 안의 합성곱 망 클래스 분포의 엔트로피로 정의합니다. 엔트로피가 낮으면 영역 안 픽셀이 한 클래스에 몰려 있다는 뜻으로, 그 영역이 순수(pure) 합니다.
각 픽셀 \(i\)에 대해 루트에서 잎까지의 경로 위에서 비용이 가장 낮은 노드 \(k^*(i) = \arg\min_{k \mid i \in C_k} S_k\)를 고릅니다. 이 노드가 그 픽셀을 가장 잘 설명하는 분할 단위입니다. 모든 픽셀이 고른 노드의 합집합이 곧 optimal cover이고, 영상을 균일하지 않은 크기의 영역으로 분할한 결과가 됩니다.
이때 \(S_k\)를 어떻게 계산할 것인가가 학습 문제입니다. 학습 시점에는 ground-truth 라벨이 있으므로 엔트로피를 직접 계산할 수 있습니다. 추론 시점에는 ground-truth가 없으니 합성곱 망 특징 벡터로부터 엔트로피를 예측하는 2층 신경망 \(c\)를 따로 학습합니다.
\[y_k = \mathbf{W}_2 \tanh(\mathbf{W}_1 \mathbf{O}_k + \mathbf{b}_1), \qquad \hat{d}_{k,a} = \frac{e^{y_{k,a}}}{\sum_b e^{y_{k,b}}}, \qquad S_k = -\sum_{a} \hat{d}_{k,a} \log(\hat{d}_{k,a}).\]
\(\mathbf{O}_k\)는 영역 \(C_k\) 안의 특징 벡터들을 \(3 \times 3\) 격자 위에 max-pooling해 얻은 스케일 불변 영역 기술자입니다. 영역 크기에 상관없이 같은 차원 표현이 나오므로 한 분류기로 다양한 크기 영역을 처리할 수 있습니다.
학습 손실은 예측 분포 \(\hat{d}_k\)와 ground-truth 분포 \(d_k\) 사이의 KL 발산입니다.
\[L_{\text{div}} = \sum_a \hat{d}_{k,a} \ln \frac{\hat{d}_{k,a}}{d_{k,a}}.\]
전체 학습은 두 단계입니다. 첫 단계는 합성곱 망 \(f_{\theta_0}\)를 픽셀 단위 분류 손실로 학습합니다. 둘째 단계는 그 망을 고정한 채 영역 분류기 \(c_{\theta_c}\)만 학습합니다. 두 단계 학습이 끝나면 시스템 전체에 조정할 임계값이나 노브가 없습니다. 저자들이 parameter-free라고 강조하는 이유가 이것입니다.
결과
본 논문이 결과를 보고하는 세 데이터셋입니다.
데이터셋 |
클래스 수 |
학습/테스트 |
|---|---|---|
Stanford Background |
8 |
5-fold 교차 검증 (572/143) |
SIFT Flow |
33 |
2{,}488 / 200 |
Barcelona |
170 |
14{,}871 / 279 |
Stanford Background 결과는 다음과 같습니다.
방법 |
픽셀 정확도 (%) |
클래스 평균 (%) |
처리 시간 (s) |
|---|---|---|---|
Gould et al. 2009 |
76.4 |
- |
10~600 |
Munoz et al. 2010 |
76.9 |
66.2 |
12 |
Tighe et al. 2010 |
77.5 |
- |
10~300 |
Socher et al. 2011 |
78.1 |
- |
- |
Kumar et al. 2010 |
79.4 |
- |
<600 |
Lempitzky et al. 2011 |
81.9 |
72.4 |
|
단일 스케일 ConvNet |
66.0 |
56.5 |
0.35 |
다중 스케일 ConvNet |
78.8 |
72.4 |
0.6 |
ConvNet + superpixels |
80.4 |
74.56 |
0.7 |
ConvNet + gPb + cover |
80.4 |
75.24 |
61 |
ConvNet + CRF on gPb |
81.4 |
76.0 |
60.5 |
요지는 두 가지입니다. 첫째, 다중 스케일 ConvNet 단독이 단일 스케일 대비 픽셀 정확도를 \(66.0\%\)에서 \(78.8\%\)로 끌어올립니다. 큰 맥락 윈도우가 결정적이라는 본 논문 주장이 이 한 줄에 들어옵니다. 둘째, superpixel 후처리만으로 0.7초 안에 \(80.4\%\)를 달성합니다. 이 시점 최고 기록(Lempitzky \(81.9\%\))에 픽셀 정확도는 약간 못 미치지만 처리 시간이 100배 빠르고 클래스 평균은 오히려 더 높습니다.
SIFT Flow(33클래스)에서는 클래스 불균형이 더 두드러집니다. 자연 빈도 샘플링과 균형 빈도 샘플링 두 가지로 학습한 결과가 흥미롭게 갈립니다.
방법 |
픽셀 정확도 (%) |
클래스 평균 (%) |
|---|---|---|
Liu et al. 2009 |
74.75 |
- |
Tighe et al. 2010 |
76.9 |
29.4 |
원시 다중 스케일 ConvNet |
67.9 |
45.9 |
ConvNet + superpixels (균형) |
71.9 |
50.8 |
ConvNet + cover (균형) |
72.3 |
50.8 |
ConvNet + cover (자연) |
78.5 |
29.6 |
자연 빈도로 학습하면 큰 영역만 잘 잡아 픽셀 정확도가 \(78.5\%\)로 최고지만, 작은 클래스는 다 놓쳐 클래스 평균이 \(29.6\%\)로 떨어집니다. 균형 빈도로 학습하면 픽셀 정확도가 \(72.3\%\)로 내려가지만 클래스 평균은 \(50.8\%\)로 종래 기법의 두 배에 가깝게 올라갑니다. 어느 쪽이 정답인가는 어떤 작업에 쓸 것인가에 달려 있다고 저자들이 §5.2에서 명시합니다.
Barcelona(170클래스)는 작은 클래스가 워낙 많아 균형 빈도가 망가집니다. 이 경우에는 자연 빈도 + cover로 픽셀 정확도 \(67.8\%\)가 가장 높고, 그것이 종래 최고였던 Tighe의 \(66.9\%\)를 살짝 넘긴 결과입니다.
처리 시간도 결정적입니다. 다중 스케일 ConvNet 추론이 4코어 Intel i7 노트북에서 1초 미만, 같은 망을 NeuFlow FPGA에 올리면 60ms입니다. 본 논문 이전 모든 방법이 한 장에 10초~10분이 걸리던 데서 10배에서 1000배 빠른 셈입니다. 실시간 장면 분할이 처음 가능해진 자리입니다.

Stanford Background의 결과 한 장입니다. (b) superpixel만으로는 작은 풀잎이 나무나 물체로 잘못 잡힙니다. (d) gPb 분할 트리의 한 고정 임계값에서 자른 결과도 비슷한 문제가 있습니다. (f) optimal cover는 작은 소(cow) 영역까지 정확히 물체 라벨로 잡으면서 큰 풀밭은 grass로 묶습니다. 영역 크기를 적응적으로 골라내는 효과가 그림에 그대로 드러납니다.
회고
저자들이 §6 Discussion에서 직접 정리한 다섯 가지 요점이 있습니다.
첫째, 원시 픽셀에서 학습된 고차원 특징 시스템이 수작업 특징과 동등하거나 더 낫다. 분할 가설 생성과 후처리가 단순하거나 없어도 그렇다.
둘째, 큰 맥락 윈도우가 결정적이다. 표 1의 단일 스케일 vs 다중 스케일 비교가 그 증거이다.
셋째, 큰 맥락이 이미 픽셀 라벨 자체에 들어가면 후처리의 역할이 크게 줄어든다. superpixel 안 다수결이라는 단순한 방법만으로도 최신 정확도가 나온다는 점이 그 증거이다.
넷째, 복잡한 후처리는 단순한 후처리보다 훨씬 나아지지는 않는다. CRF가 cover보다 약간 낫지만 그 차이는 경계 정확도와 분할 가설에서 오는 것이지 맥락 일관성 시스템에서 오는 것이 아니다.
다섯째, 빠른 전방향 픽셀 분류기에 의존하고 후처리를 최소화하는 전략이 추론 시간을 극적으로 단축한다. 1초 vs 60초의 차이가 여기서 나온다.
저자들이 향후 작업으로 언급한 항목이 흥미롭습니다. 합성곱 망과 후처리 단을 함께 학습하면 더 나아질 가능성이 있고, 이를 Graph Transformer Network 모델과 같은 비정규화 그래프 모델로 보면 자연스럽다고 명시합니다. 이전 글 LeNet-5 논문에서 얀 르쿤 본인이 정식화한 GTN의 발상이 15년 뒤 다시 장면 분할 시스템의 다음 단계로 호명되는 셈입니다. 다만 예비 실험에서 과적합 때문에 테스트 정확도가 떨어졌다는 솔직한 단서가 같은 자리에 붙어 있습니다.
다른 한 가지 솔직함은 §7에서 등장합니다. 픽셀 단위 정확도가 시각적·실용적 품질의 부정확한 척도라는 것입니다. 하늘 픽셀의 경계를 완벽히 그리는 것보다 작은 물체를 정확히 짚어내는 것이 종종 더 중요한데, 픽셀 평균은 큰 클래스에 가중치가 쏠립니다. 장면 분할의 평가 방식 자체가 개선되어야 한다는 문제 제기를 결론에 남깁니다.
정리
이 논문의 자리는 세 가지입니다. 첫째, 원시 픽셀에서 학습된 다중 스케일 합성곱 망만으로 장면 분할 최신 기록을 세운 첫 글입니다. 둘째, 영상 경사 분할 트리에서 클래스 순도 기반 영역 선택을 정식화한 글입니다. 셋째, 실시간 장면 분할을 노트북에서 1초, 전용 하드웨어에서 60ms로 처음 보여준 글입니다.
여기서 도입된 백본 + 후처리 분리 구조와 영역 단위 특징 풀링은 1년 뒤 R-CNN과 OverFeat에서 검출 시스템으로 일반화됩니다. 더 멀리는 Fully Convolutional Networks(2015)와 U-Net(2015)이 후처리 없이 합성곱 망 한 번에 장면 분할을 끝내는 방향으로 이 작업을 흡수합니다. 본 논문이 후처리를 단순화할수록 좋다고 결론에서 적은 그 방향이 정확히 다음 세대로 이어집니다.
얀 르쿤 시리즈 안에서 보면 본 논문은 두 가지 흐름이 만나는 자리이기도 합니다. 1989년 손글씨 인식에서 시작한 합성곱 망의 산업 응용 흐름과, 1998년 LeNet-5 논문에서 정식화된 학습 가능한 그래프 후처리 흐름이 장면 분할이라는 한 문제에서 다시 만납니다. 그리고 그 결과를 NYU 박사과정 학생과 ESIEE 수리형태학자가 Torch7과 FPGA로 함께 만든 것이 본 논문입니다.