Memento - Reconstruct to Remember for Consistent Long Video Generation
X. Wei, L. Ji, G. Wang, X. Liu, Z. Zhang, S. Wang, Y. Sun, and Q. Hong, "Memento: Reconstruct to Remember for Consistent Long Video Generation," arXiv:2606.14667, 2026.
저자
웨이쉬안는 샤먼대학 박사과정생으로 Baidu ERNIE Team 인턴 중 이 연구를 이끌었습니다. Baidu ERNIE Team의 장전위이 Project Lead로 전체 실험 설계와 훈련 인프라를 담당했고, 샤먼대학 홍칭치 교수가 교신저자로 연구 방향을 감독했습니다. Longbin Ji, Guan Wang, Shuohuan Wang, Yu Sun 등 Baidu ERNIE Team 소속 연구자 다수가 Wan2.2 기반 비디오 생성 파이프라인 구축에 합류했습니다.
장기 영상 생성의 정체성 드리프트 문제는 최근 StoryMem, OneStory 같은 선행 연구에서도 해결하지 못한 공백으로 남아 있었습니다. Baidu의 ERNIE 비디오 생성 팀이 이 문제를 명시적 학습 목표로 전환하는 새로운 접근을 제안한 것이 이번 논문의 배경입니다.
배경
단일 샷 비디오 생성은 크게 나아졌지만, 여러 샷에 걸쳐 같은 인물이 반복 등장하는 장기 영상을 만드는 일은 여전히 어렵습니다. 얼굴, 의상, 체형이 샷마다 조금씩 달라지면 이야기의 일관성이 무너집니다.
기존 방법들은 크게 세 갈래였습니다. 스토리보드 기반은 키프레임을 먼저 만들고 클립을 애니메이션화하는데, 클립 간 연결이 느슨합니다. 다중 샷 동시 생성 방식은 공유 어텐션 맥락으로 정합성을 높이지만 맥락 창 제한에 걸립니다. 메모리 조건부 자기회귀 방식은 컴팩트한 기억으로 이전 영상을 요약하되, 메모리 선택이 일반적 시각 현저성이나 단기 압축에 의존해 정체성 단서가 희석되는 문제가 있었습니다.
Memento는 이 희석 문제를 다른 방향에서 공략합니다. "메모리가 진짜로 인물을 기억한다면, 그 메모리만으로 인물 외형을 재구성할 수 있어야 한다"는 직관 아래, 피사체 재구성을 명시적 보조 학습 목표로 삼습니다.
어떻게 만들었나
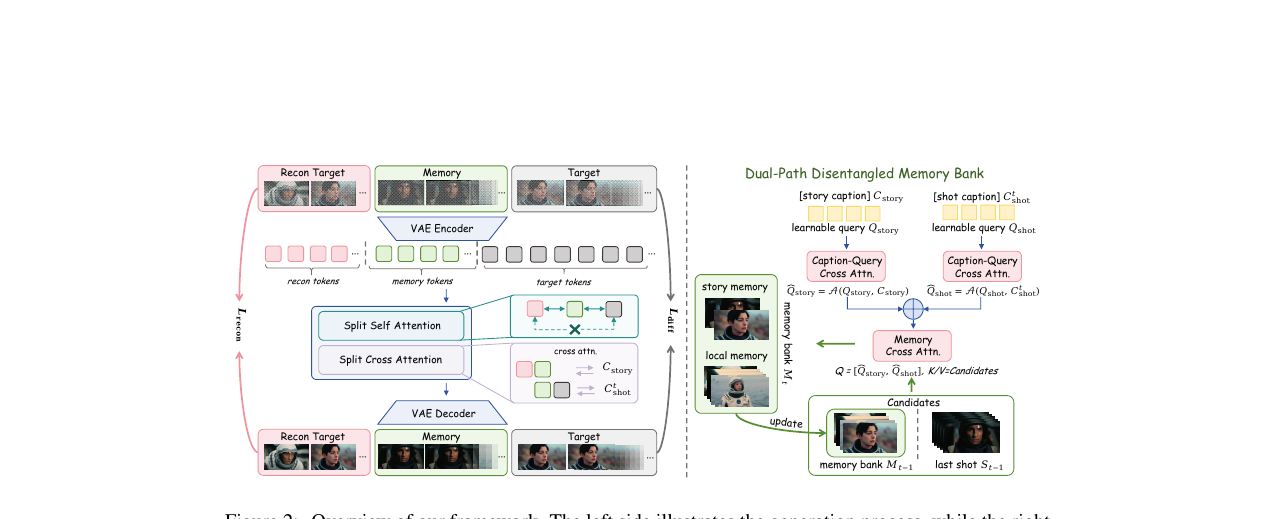
Memento는 세 가지 구성 요소로 이루어집니다.
피사체 인식 데이터 큐레이션 파이프라인
모델 훈련에는 인물 이름이 일관되게 고정된 캡션이 필요합니다. 일반 캡션은 "the man", "he" 같은 대명사를 써서 다른 샷의 같은 인물을 연결하기 어렵습니다. Memento는 세 단계 캡셔닝으로 이 문제를 해결합니다.
1단계(Story Caption): Qwen3-VL-8B로 전체 멀티샷 시퀀스를 보며 전역 스토리 캡션과 등장인물 인벤토리를 생성합니다. 각 인물에 고정된 대명사 없는 이름("[Person A]")을 부여하고, ByteTrack으로 주인공의 외형이 가장 잘 드러나는 2프레임을 재구성 타깃으로 선택합니다.
2단계(Shot Caption): 전역 스토리 캡션과 인물 인벤토리를 참조해 각 샷을 캡셔닝합니다. 대명사 사용 없이 고정된 인물 표기를 강제합니다.
3단계(Reconstruction Caption): 선택된 재구성 타깃 프레임을 캡셔닝해, 메모리 기반 피사체 재구성 학습을 위한 (이미지, 캡션) 쌍을 만듭니다.
총 2,033개 시퀀스, 20,227개 클립(시퀀스당 평균 9.95개, 평균 길이 45.9초)이 이 파이프라인을 거쳐 만들어졌습니다.
이중 경로 분리 메모리 뱅크
고정 크기 메모리는 확장성에 필수적이지만, 단일 선택 기준으로는 두 종류의 역사적 정보가 경쟁합니다. 피사체 재구성에는 장거리 아이덴티티 단서가 필요하고, 다음 샷 생성에는 최근 장면 문맥이 필요합니다.
생성 단계 \(t\)에서 메모리 후보 풀은 이전 메모리 \(M_{t-1}\)과 최근 샷의 VAE 특징을 합쳐서 만듭니다:
\[M_t^{cand} = [M_{t-1};\ E(S_{t-1})]\]
두 가지 학습 가능한 쿼리가 이 후보 풀에서 독립적으로 검색합니다:
\[\hat{Q}_{story} = A(Q_{story},\ \phi(C_{story})),\quad \hat{Q}_{shot} = A\!\left(Q_{shot},\ \phi(C_{shot}^t)\right)\]
\(Q_{story}\)는 전역 스토리 캡션으로 조건화되어 아이덴티티 관련 단서를 검색하고, \(Q_{shot}\)은 현재 샷 캡션으로 조건화되어 지역 문맥을 검색합니다. 각 쿼리가 후보 풀에서 top-\(K\) 토큰을 독립적으로 선택해 메모리 뱅크를 갱신합니다:
\[M_t = \left[\text{TopK}(M_t^{cand},\ s_{story});\ \text{TopK}(M_t^{cand},\ s_{shot})\right]\]
피사체 고정 다중 태스크 학습
다음 샷 생성 손실 \(\mathcal{L}_{diff}\)만으로는 메모리가 아이덴티티 단서를 충분히 보존하도록 강제할 수 없습니다. Memento는 메모리와 전역 캡션만으로 피사체를 재구성하는 보조 태스크 \(\mathcal{L}_{recon}\)을 더합니다:
\[\mathcal{L}_{total} = \mathcal{L}_{diff} + \lambda\,\mathcal{L}_{recon}\]
\(\lambda = 0.5\)로 두 목표를 균형 있게 결합합니다. 재구성 브랜치는 타깃 이미지에 직접 접근할 수 없고 오직 메모리와 스토리 캡션만 씁니다. 재구성에 성공하려면 메모리가 반드시 얼굴, 의상, 체형 같은 정체성 단서를 인코딩해야 합니다.
훈련은 Wan2.2 14B 기반 비디오 생성 백본으로 진행했으며, 16개 NVIDIA H100 GPU, AdamW 옵티마이저, 학습률 \(1\times10^{-5}\)를 사용했습니다. 해상도는 480×832입니다.
결과

정량 비교
방법 |
Aesthetic |
Story 일관성 |
Shot 일관성 |
BG 일관성 |
샷 간 |
샷 내 |
장면 간 |
|---|---|---|---|---|---|---|---|
StoryDiffusion+Wan2.2-I2V |
0.5310 |
0.2671 |
0.2689 |
0.9767 |
0.5525 |
0.8448 |
0.6732 |
StoryMem |
0.4937 |
0.2793 |
0.2681 |
0.9732 |
0.6606 |
0.8146 |
0.6692 |
HoloCine |
0.4568 |
0.2720 |
0.2854 |
0.9770 |
0.5791 |
0.8128 |
0.6594 |
Memento |
0.4977 |
0.3063 |
0.2893 |
0.9805 |
0.7338 |
0.8578 |
0.7268 |
Memento는 장기 피사체 일관성 세 지표(샷 간 0.7338, 샷 내 0.8578, 장면 간 0.7268)에서 모두 1위를 기록했습니다. 특히 샷 간 피사체 일관성에서 StoryMem 대비 0.073 포인트 향상이 두드러집니다. 심미 품질(Aesthetic)은 StoryDiffusion+Wan2.2-I2V에 이어 2위로, 피사체 보존 강화가 시각 품질을 크게 희생시키지 않음을 보여줍니다.
어블레이션
표 2의 어블레이션은 각 구성 요소의 기여를 확인합니다. 기준선(StoryMem)에서 learnable query만 추가하면 샷 간 일관성이 0.6606에서 0.7227로 뜁니다. 재구성 태스크를 추가하면 0.7489까지 더 오릅니다. 분리된 메모리를 도입하면 샷 간 수치가 0.7338로 소폭 내려가지만, 샷 내(0.8578)와 장면 간(0.7268)은 모두 개선됩니다. 분리 메모리가 즉각적인 다음 샷에 특화하지 않고 전체 영상에 걸쳐 아이덴티티를 보존하기 때문입니다.
사용자 연구
10명 참가자, 30개 생성 사례를 대상으로 한 쌍대 비교에서 Memento는 StoryMem 대비 크로스샷 일관성 Win 57.3%, HoloCine 대비 69.0%를 기록했습니다. 프롬프트 수행도에서도 StoryMem 대비 60.3%, HoloCine 대비 63.0%로 우위를 보였습니다.
회고
저자들이 명시한 한계는 두 가지입니다.
첫째, 자기회귀 생성의 오류 전파입니다. 품질이 떨어진 샷이 메모리에 기록되면 이후 생성에 계속 영향을 미칩니다. 메모리 필터링의 강건성이 과제로 남습니다.
둘째, 물리적 타당성 제약입니다. 중력, 물체 영속성, 강체 역학 같은 물리 법칙을 백본 모델이 명시적으로 모델링하지 않아, 물리적으로 어색한 장면이 생길 수 있습니다. 향후 물리 인식 생성이 연구 방향으로 제시되었습니다.
한 가지 더 주목할 것은 데이터셋 규모입니다. 20K 클립은 대규모 생성 모델 기준으로 적은 편이며, 이를 영화·다큐멘터리·애니메이션 영상에서만 수집한 점은 현실 세계의 다양한 촬영 환경에 대한 일반화 한계를 남깁니다.
정리
- "메모리가 피사체를 기억한다면 재구성도 가능하다"는 직관으로, 피사체 재구성을 명시적 보조 학습 목표(\(\mathcal{L}_{recon}\))로 삼아 정체성 보존을 최적화 가능한 문제로 전환
- 이중 경로 메모리(story query로 장기 아이덴티티, shot query로 단기 문맥)를 분리해 장기 일관성과 지역 연속성이 메모리 내에서 경쟁하지 않도록 설계
- 샷 간 피사체 일관성 0.7338로 StoryMem(0.6606) 대비 11%p 향상, 5분 영상 생성과 나이 변화를 포함한 정체성 보존 등 확장 가능성 실험으로 입증