OmniDirector - General Multi-Shot Camera Cloning without Cross-Paired Data
J. Liu, S. Li, Z. Fang, X. Li, Y. Zhou, Z. Meng, Z. Zhang, Y. Luo, G. Zhang, Y.-S. Liu, and P. Wan, "OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data," arXiv:2606.13432, 2026.
저자
쾌수(Kuaishou Technology)의 Kling Team 소속 Jiwen Liu와 Shujuan Li가 공동 1저자이며, Yan Zhou가 교신저자입니다. 칭화대와 북경대 연구자들이 함께 참여한 산학 협업입니다. Kling은 쾌수가 2024년 내놓은 상업용 비디오 생성 모델입니다. 이 논문은 Kling의 핵심 기능인 카메라 제어를 한 단계 높이려는 연구로, 기존 시스템이 해결하지 못한 멀티샷 문제와 데이터 희소성 문제를 동시에 겨냥합니다.
배경
카메라 제어 방식에는 크게 두 계열이 있습니다.
첫 번째 계열은 플뤼커 좌표(Plücker coordinates)나 카메라 외재 파라미터 행렬을 직접 모델에 주입하는 명시적 방법입니다. 정밀하지만 사용자가 직접 카메라 경로를 지정해야 하고, 레퍼런스 씬과 생성 씬의 공간 스케일이 달라지면 기하학적 왜곡이 생깁니다.
두 번째 계열은 같은 카메라 모션을 다른 콘텐츠로 찍은 크로스 페어드 데이터로 학습하는 방법입니다. 스케일 문제를 피할 수 있지만, 이런 데이터가 현실에서 극히 드뭅니다. 게임 엔진으로 합성 데이터를 만들어도 실제 영상의 복잡한 촬영 맥락을 담기 어렵습니다.
두 계열 모두 컷 전환이 있는 영상, 즉 멀티샷을 다루지 못합니다.
카메라 그리드: 핵심 표현
OmniDirector의 답은 카메라 파라미터를 시각적 신호로 바꾸는 것입니다.
레퍼런스 비디오에서 카메라 외재 파라미터 시퀀스 \(P = \{R_i, t_i\}_{i=1}^T\)를 추출한 뒤, 이를 아무 오브젝트도 없는 빈 3D 방 안에서 카메라가 움직이는 영상으로 렌더링합니다. 천장과 바닥은 빨간색·파란색 격자, 벽은 노란색 수직선으로 표현합니다. 이 격자 영상이 카메라 그리드 \(G\)입니다.

이 표현의 세 가지 장점입니다.
- 범용성: 싱글샷, 멀티샷 모두 같은 방식으로 인코딩할 수 있습니다. 컷 전환 지점은 순백색 프레임으로 삽입합니다.
- 분리(Decoupling): 빈 장면이므로 카메라 신호에 외관·캐릭터 정보가 섞이지 않습니다.
- 확장성: 임의의 영상에서 카메라 그리드를 자동 생성할 수 있어 인터넷 규모 데이터 구축이 가능합니다.
카메라 그리드는 또한 특수 카메라 효과로 확장됩니다. 피쉬아이 렌즈는 Kannala-Brandt 모델로, 돌리 줌(히치콕 줌)은 줌 비율에 따라 크기가 변하는 사각 프레임으로 표현합니다.
아키텍처
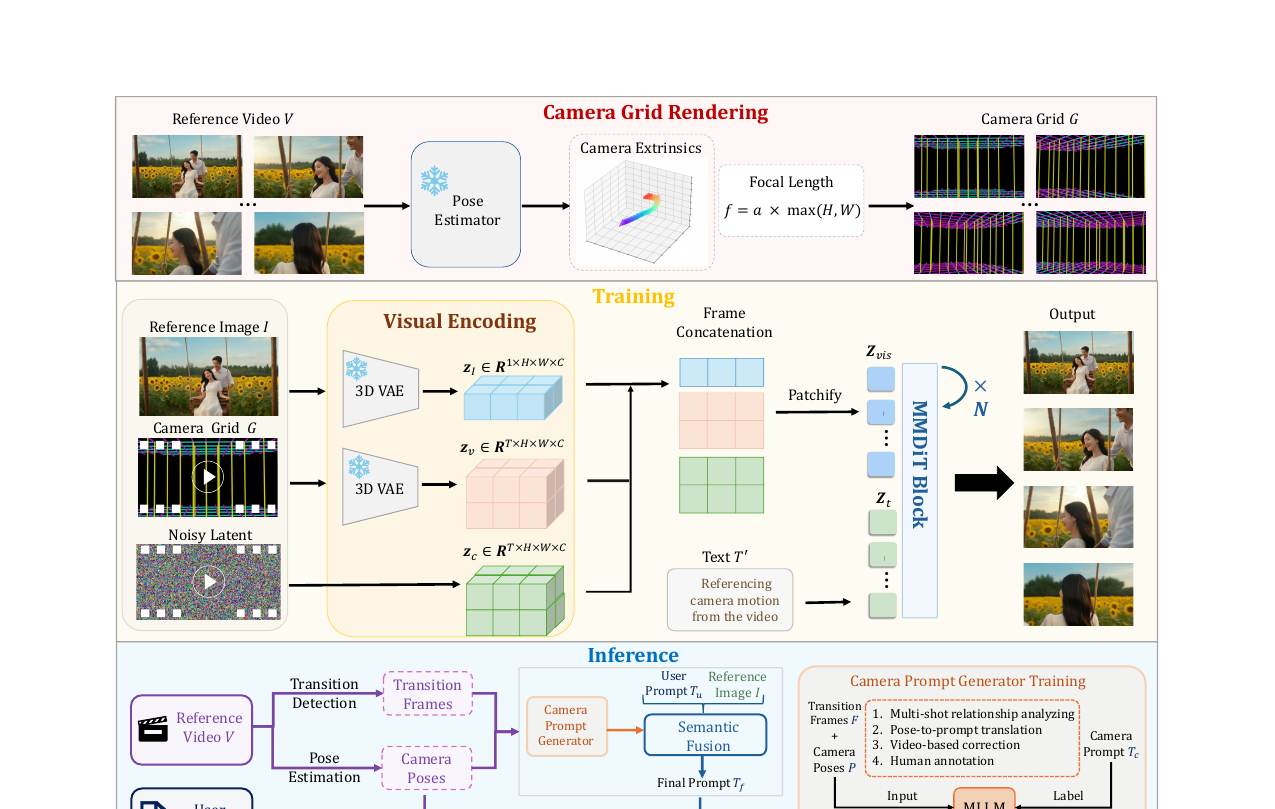
학습 단계에서는 카메라 그리드 \(G\), 레퍼런스 이미지 \(I\), 노이즈 비디오 잠재 \(Z_v\)를 프레임 차원으로 이어 붙입니다.
\[z_\text{vis} = \text{Concat}(z_I, z_v, z_c) \in \mathbb{R}^{(2T+1) \times H \times W \times C}\]
이를 3D 컨볼루션으로 패치화해 MMDiT(Multi-Modal Diffusion Transformer) 블록에 입력합니다. 텍스트 조건과 비주얼 토큰은 분리된 어텐션 경로에서 처리되고, 각 레이어에서 상호작용합니다.
훈련 샘플의 30%에는 자기 재구성 목표를 적용합니다. 타겟 비디오 대신 카메라 그리드 자체를 재구성하도록 훈련해 모델이 그리드의 기하 구조와 시간적 동역학을 명확히 파악하도록 강제합니다.
추론 단계에서는 계층적 프롬프트 확장 에이전트(PE Agent)가 여러 제어 신호를 하나의 텍스트 프롬프트로 통합합니다. - 샷 간(inter-shot) 프롬프트: 컷 전환 전후 프레임을 MLLM이 분석해 씬 간 관계 기술 - 샷 내(intra-shot) 프롬프트: 카메라 포즈 시퀀스를 텍스트 매칭으로 변환 후 레퍼런스 영상으로 교정 - Qwen3-VL이 카메라 프롬프트, 레퍼런스 이미지, 사용자 프롬프트를 최종 통합
또한 **적응형 CFG(Adaptive Classifier-Free Guidance)**를 적용합니다. 노이즈가 큰 초기 단계에는 카메라 그리드 신호만 주입해 전체 공간 구조를 잡고, 저노이즈 단계에서 나머지 신호를 투입해 세부 내용을 정제합니다. 카메라 그리드를 전 단계에 주입하면 다른 신호와 충돌해 카메라 제어 품질이 떨어집니다.
결과
1.8M 인터넷 영상(영화·광고 등)으로 학습, 1,094개 샘플 검증 세트로 평가했습니다.
카메라 정확도 및 컷 전환 정밀도
방법 |
RRE(\(\downarrow\)) |
R-Pre(%\(\uparrow\)) |
RTE(\(\downarrow\)) |
T-Pre(%\(\uparrow\)) |
Tem-Pre(%\(\uparrow\)) |
Sem-Pre(%\(\uparrow\)) |
프레임 누출(%\(\downarrow\)) |
|---|---|---|---|---|---|---|---|
Seedance2.0 |
8.33 |
56.49 |
49.98 |
29.07 |
4.17 |
2.20 |
4.43 |
CamCloneMaster |
4.11 |
74.14 |
27.45 |
52.21 |
- |
- |
1.60 |
LTX-LoRA |
5.67 |
66.34 |
26.96 |
52.07 |
38.94 |
29.55 |
15.04 |
OmniDirector |
2.64 |
83.18 |
16.84 |
72.74 |
96.52 |
83.79 |
0.51 |
T-Pre(병진 정밀도) 기준으로 2위인 CamCloneMaster 대비 39.3% 상대 향상입니다. 기존 방법들은 레퍼런스 씬과 생성 씬의 스케일 불일치 문제를 해결하지 못하기 때문입니다.
멀티샷 컷 전환의 의미론적 정밀도(Sem-Pre)는 83.79%로, LTX-LoRA(29.55%)와 큰 격차가 납니다. 특히 Seedance2.0과 CamCloneMaster는 멀티샷 자체를 지원하지 않습니다.
CamCloneMaster와 GSB 비교
차원 |
(Good+Same)/Total |
Good/(Good+Bad) |
|---|---|---|
카메라 정확도 |
88.52% |
86.29% |
영상 품질 |
95.69% |
90.82% |
내러티브 |
94.26% |
85.71% |
어블레이션
PE Agent의 시맨틱 융합을 제거하면 씬 누출률이 높아지고 전반적인 카메라 정확도가 하락합니다. 샷 간 프롬프트를 제거하면 컷 전환 후 씬이 레퍼런스 카메라 모션과 관계없이 랜덤한 씬으로 이어지는 문제가 발생해 Sem-Pre가 83.79%에서 38.45%로 급락합니다.
창발적 일반화
훈련 중 사용한 카메라 그리드 대신 원본 RGB 영상이나 캐니 엣지 영상으로 모델을 조건화해도 카메라 모션을 추론하고 복제합니다. 추가 학습 없이 돌리 줌 같은 특수 효과도 처리합니다. 카메라 그리드가 비디오와 유사한 시공간 의미를 공유하기 때문에 가능한 창발입니다.
논문이 명시한 한계입니다. 현재 구조는 카메라 그리드와 다른 시각 신호를 토큰 단순 결합(token concatenation)으로 통합합니다. 영상이 길어질수록 장기 메모리와 시간적 일관성을 유지하기 어렵습니다. 롱 컨텍스트 크로스 어텐션이나 메모리 뱅크 탐색을 후속 작업으로 제시합니다.
- 카메라 모션을 3D 빈 공간의 격자 움직임 영상으로 시각화하는 카메라 그리드는 크로스 페어드 데이터 없이 임의 영상에서 멀티샷 카메라를 클로닝 가능하게 합니다.
- 계층적 PE Agent가 샷 간/내 프롬프트와 시맨틱 융합으로 여러 제어 신호를 충돌 없이 통합합니다. 적응형 CFG는 고노이즈 단계에 카메라 신호만 주입해 글로벌 구조를 먼저 확립합니다.
- T-Pre 기준 2위 대비 39.3% 향상, Sem-Pre 83.79% vs LTX-LoRA 29.55%로 멀티샷 전환 품질이 특히 두드러집니다.