Gradient-Based Learning Applied to Document Recognition
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, "Gradient-Based Learning Applied to Document Recognition," Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, November 1998.
1998년 11월 Proceedings of the IEEE 한 호의 절반을 이 한 편이 차지합니다. 46페이지짜리 본문 안에 LeNet-5라는 이름이 처음 등장하고, MNIST라는 데이터셋 이름도 여기서 처음 정의됩니다. 또한 Graph Transformer Network라는 학습 가능한 모듈 그래프 개념이 정식으로 제안됩니다. 이름만 보면 LeNet-5 논문이지만 실제 내용은 합성곱 신경망부터 미국 은행 수표 판독 시스템까지 한 권에 묶은 정본입니다.
이전 글 두 편이 이 논문의 좌우 받침이었습니다. Handwritten Digit Recognition with a Back-Propagation Network(1989)가 9년 전의 출발점이고, Efficient BackProp(1998)은 학습 노하우의 정리본입니다. 본 글은 그 두 받침 위에 올라가는 정본 격입니다.
저자
저자 네 명은 모두 AT&T Labs-Research의 Speech and Image Processing Services Research Laboratory 소속이었습니다. AT&T가 1996년 두 번째로 분할되면서 그 자리에 만들어진 연구소이고, 얀 르쿤이 부서장이었습니다. 레옹 보투가 1995년 Bell Labs로 돌아온 직후, 요슈아 벤지오는 1992~1993년 박사후 시절 Bell Labs에서 시간을 보낸 적이 있고 본 작업에서는 Université de Montréal 객원 자격으로 합류하였습니다. 패트릭 하프너는 1995년 합류해 산업 배포를 맡았습니다.
네 사람이 한 논문에 모인 이유는 단순하지 않습니다. 얀 르쿤은 합성곱 신경망의 다음 단계, 즉 단일 문자를 넘어 문자열 전체를 다루고 싶었습니다. 레옹 보투는 SGD와 Graph Transformer Networks라는 새 학습 프레임을 들고 있었습니다. 요슈아 벤지오는 박사 논문에서 신경망과 HMM을 결합한 판별적 전방 학습을 정식화한 직후였습니다. 패트릭 하프너는 CNET 시절 Multi-State TDNN으로 음성 시퀀스를 단어 단위로 학습시킨 경험을 가지고 있었습니다. 이 네 사람이 만나야 손글씨 한 글자 인식에서 시작해 수표 한 장 전체 판독까지 한 시스템으로 묶을 수 있었습니다.
배경
1989년 우편번호 작업 이후 9년이 지난 시점입니다. 그 사이 무엇이 바뀌었는지를 §I.A에서 저자들이 직접 정리합니다. 첫째, 컴퓨터가 더 빨라졌습니다. 본 논문의 LeNet-5는 SGI Origin 2000의 단일 200MHz R10000에서 2~3일이면 학습이 끝납니다. 1989년에 LeNet-5 정도 망을 학습시키려면 몇 주가 필요했고, 그 때문에 시도조차 안 했다고 본문에 적혀 있습니다. 둘째, 데이터셋이 커졌습니다. 60000장짜리 MNIST가 본 논문에서 처음 정의됩니다. 셋째, 학습 알고리즘이 더 다듬어졌습니다. 같은 호에 실린 Efficient BackProp이 그 정리입니다.
그래서 본 논문의 한 마디 요지는 수작업 특징 추출은 더 이상 필요 없다입니다. 1989년에는 전체 학습 가능한 시스템도 잘 된다는 증명에 가까웠다면, 1998년에는 전체 학습 가능한 시스템이 손으로 설계한 특징보다 낫다는 단정입니다.
논문은 11개 절로 구성됩니다. §I~III이 LeNet-5와 MNIST에 대한 것이고, §IV~VIII이 Graph Transformer Network의 일반 이론, §IX~X이 두 산업 응용(온라인 손글씨 단어 인식, 은행 수표 판독)에 대한 보고입니다. 즉 절반은 단일 문자에 대한 글, 나머지 절반은 문자열 시스템에 대한 글입니다.
LeNet-5
본 논문의 핵심 아키텍처 LeNet-5는 입력을 제외하고 학습 가능한 가중치를 가진 층 7개로 구성됩니다. 입력은 \(32 \times 32\) 픽셀이고, 가장 큰 문자가 \(20 \times 20\) 안에 들어가도록 정규화한 다음 \(28 \times 28\) 안에 중심을 맞추고 그 바깥에 배경 패딩을 둡니다. 입력 픽셀은 흰색이 \(-0.1\), 검정이 \(1.175\)가 되도록 정규화해 평균을 0, 분산을 1 근처로 맞춥니다. 같은 호의 Efficient BackProp에서 입력은 평균 0, 분산 1로 정규화한다는 권장이 그대로 적용된 셈입니다.
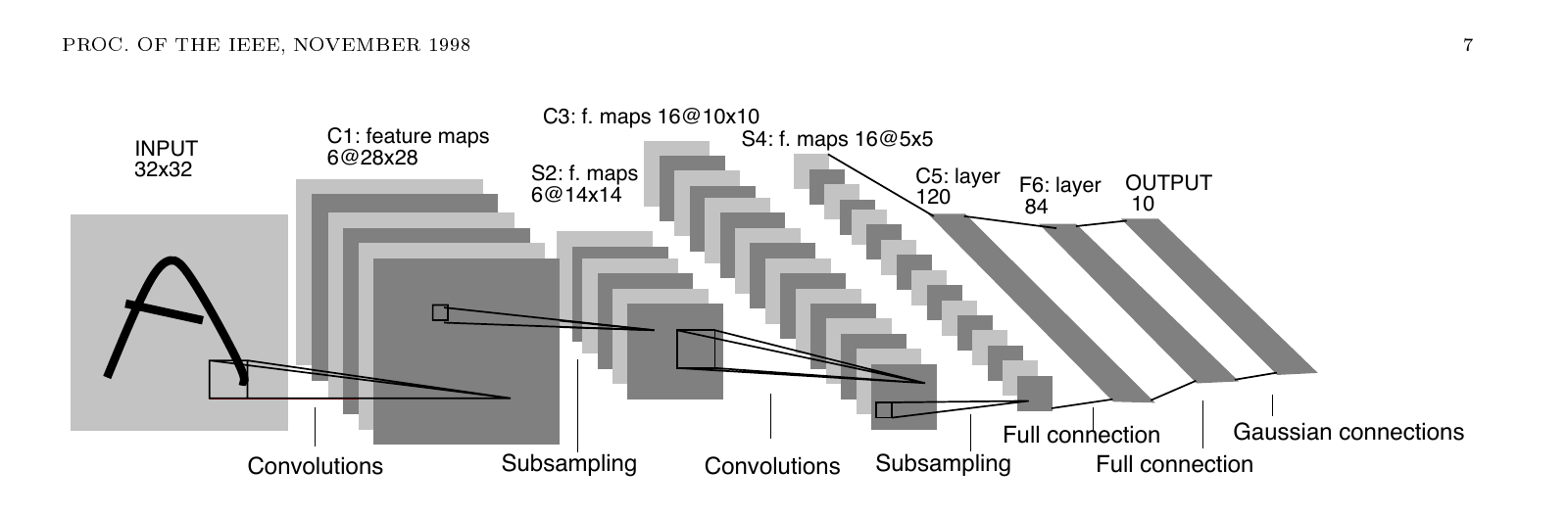
층 구성은 다음과 같습니다. C1이 합성곱층, S2가 부표본화층, C3이 합성곱층, S4가 부표본화층, C5가 합성곱층(사실상 완전연결), F6가 완전연결층, OUTPUT이 Euclidean RBF 층입니다.
층 |
종류 |
출력 크기 |
학습 파라미터 |
연결 수 |
|---|---|---|---|---|
C1 |
합성곱 (\(5 \times 5\)) |
\(6 @ 28 \times 28\) |
156 |
122{,}304 |
S2 |
부표본화 (\(2 \times 2\)) |
\(6 @ 14 \times 14\) |
12 |
5{,}880 |
C3 |
합성곱 (\(5 \times 5\)) |
\(16 @ 10 \times 10\) |
1{,}516 |
151{,}600 |
S4 |
부표본화 (\(2 \times 2\)) |
\(16 @ 5 \times 5\) |
32 |
2{,}000 |
C5 |
합성곱 (\(5 \times 5\)) |
\(120 @ 1 \times 1\) |
48{,}120 |
48{,}120 |
F6 |
완전연결 |
\(84\) |
10{,}164 |
10{,}164 |
OUTPUT |
Euclidean RBF |
\(10\) |
0 (고정) |
840 |
전체 학습 파라미터는 약 60{,}000개, 연결 수는 340{,}908개입니다. 가중치 공유 덕분에 파라미터가 연결 수의 1/6 수준에 머뭅니다.
C3 층에서 흥미로운 설계 결정이 하나 있습니다. C3의 각 특징 맵이 S2의 모든 6개 맵을 보지 않고, 미리 정해진 부분 집합만 봅니다. 첫 6개 C3 맵은 S2의 연속된 3개 맵에서 입력을 받고, 다음 6개는 연속된 4개에서, 그다음 3개는 불연속한 4개에서, 마지막 1개만 6개 전부에서 입력을 받습니다. 저자들이 이렇게 한 이유는 두 가지입니다. 첫째, 연결을 적게 두면 파라미터가 줄어듭니다. 둘째, 더 중요하게는 대칭을 깨야 서로 다른 맵이 보완적인 특징을 뽑게 됩니다. 모든 맵이 같은 입력을 받으면 같은 특징을 학습할 위험이 있습니다.
활성함수는 \(f(a) = A \tanh(Sa)\)로, \(A = 1.7159\), \(S = 2/3\)입니다. 이 두 상수는 \(f(1) = 1\), \(f(-1) = -1\)이 되도록, 그리고 비선형 영역의 가장자리에서 가장 큰 곡률을 가지도록 고른 값입니다. 출력층 직전 F6 층의 학습된 타깃이 \(\pm 1\)이므로, 시그모이드가 이 두 점에서 가장 잘 학습되도록 한 설계입니다.
출력층은 일반 신경망과 다릅니다. 클래스마다 하나씩 Euclidean RBF 유닛 10개를 두고, 각 유닛은 \(84\) 차원 입력 벡터 \(x\)와 해당 클래스의 고정된 파라미터 벡터 \(w_i\) 사이의 \(\|x - w_i\|^2\)을 출력합니다.
\[y_i = \sum_{j} (x_j - w_{ij})^2.\]
\(w_i\)는 학습되지 않고, \(\pm 1\) 값을 갖는 \(7 \times 12\) 비트맵으로 고정합니다. 비트맵은 해당 클래스 문자를 양식화한 그림입니다. 84라는 숫자가 \(7 \times 12\)에서 나온 이유가 이것입니다. 손글씨 숫자 10개만 인식할 때는 굳이 이런 분산 코드가 필요 없지만, 본 논문이 곧 95개 ASCII 문자까지 다룰 것이기에 서로 비슷한 문자에 비슷한 코드를 부여하는 분산 표현이 필요했습니다. 대문자 O와 소문자 o와 숫자 0이 비슷한 코드를 가지면, 후처리 단계에서 언어 모델이 셋 중에서 적절한 해석을 고를 수 있게 됩니다.
손실 함수는 단순한 MLE/MSE가 아니라 MAP 기준의 변형입니다.
\[E(W) = \frac{1}{P} \sum_{p=1}^{P} \left( y_{D^p}(Z^p, W) + \log(e^{-j} + \sum_{i} e^{-y_i(Z^p, W)}) \right).\]
정답 클래스의 RBF 출력 \(y_{D^p}\)를 끌어내리는 동시에 두 번째 항이 경쟁 역할을 합니다. 단순 MSE만 쓰면 RBF 파라미터를 적응시킬 경우 모든 출력이 0이 되어 학습이 망가지는 문제가 발생합니다. 이 붕괴(collapse) 현상에 대한 해법으로 본 논문이 처음 정식화한 것이 이 항이고, §VI에서 판별적 학습 일반론으로 확장됩니다.
MNIST와 결과
데이터셋도 본 논문에서 처음 정의됩니다. NIST의 두 데이터셋(SD-1, SD-3)을 섞어 학습/테스트 분포를 맞춘 것이 Modified NIST, 즉 MNIST입니다. SD-3은 미국 인구조사국 직원이 쓴 깔끔한 글씨, SD-1은 고등학생이 쓴 거친 글씨라 그대로 쓰면 학습셋과 테스트셋이 너무 다릅니다. 저자들은 SD-1을 둘로 갈라 학습셋과 테스트셋에 절반씩 배분하고, 부족한 양은 SD-3으로 채워 학습 60{,}000장, 테스트 10{,}000장의 균질한 데이터셋을 만들었습니다. 이미지는 종횡비를 보존하면서 \(20 \times 20\) 박스에 맞춘 뒤 \(28 \times 28\) 필드 안에서 무게 중심을 정중앙에 놓습니다.
학습은 20회 전체 데이터셋 통과로 끝납니다. 학습률은 첫 2회 \(0.0005\), 다음 3회 \(0.0002\), 다음 3회 \(0.0001\), 다음 4회 \(0.00005\), 그 이후 \(0.00001\)로 단조 감소시킵니다. 매 epoch마다 500장 표본으로 대각 헤시안을 추정해 Stochastic Diagonal Levenberg-Marquardt 방식으로 가중치마다 다른 유효 학습률을 적용합니다.
LeNet-5의 MNIST 테스트 오류율은 다음과 같습니다.
모델 |
테스트 오류율 |
|---|---|
LeNet-5 |
0.95% |
LeNet-5 (왜곡 증강) |
0.8% |
LeNet-4 |
1.1% |
LeNet-1 (16x16 입력) |
1.7% |
Boosted LeNet-4 (왜곡 증강) |
0.7% |
왜곡 증강은 평면 어파인 변환(수평·수직 이동, 스케일링, 압축, 전단)을 무작위로 적용해 60{,}000장에 540{,}000장을 더한 것입니다. 학습 자체는 같은 20회 epoch 동안 진행했으니 각 표본을 평균 2회씩만 본 셈인데, 그래도 오류율이 \(0.95\%\)에서 \(0.8\%\)로 떨어졌습니다.
비교 대상이 길게 나옵니다. Figure 9의 전체 비교표를 정리하면 다음과 같습니다.
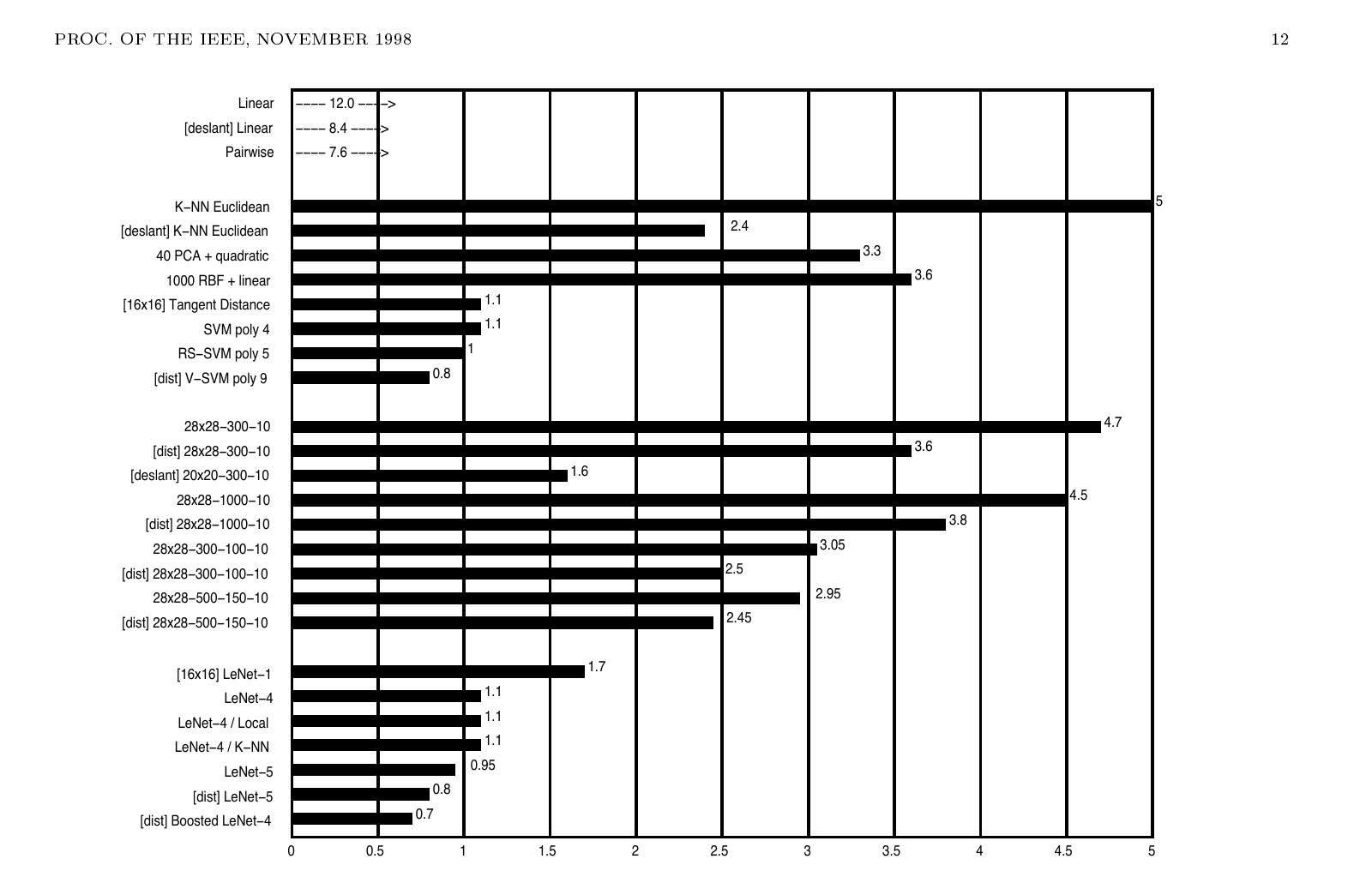
분류기 종류 |
대표 시스템 |
테스트 오류율 |
|---|---|---|
선형 |
Linear |
12.0 |
메모리 기반 |
K-NN Euclidean |
5.0 |
메모리 기반 (deslant) |
K-NN Euclidean |
2.4 |
다항/PCA |
40 PCA + quadratic |
3.3 |
RBF 네트워크 |
1000 RBF + linear |
3.6 |
Tangent Distance |
[16x16] TDC |
1.1 |
SVM |
SVM poly 4 |
1.1 |
RS-SVM |
RS-SVM poly 5 |
1.0 |
V-SVM (왜곡 증강) |
V-SVM poly 9 |
0.8 |
완전연결 신경망 |
28x28-300-10 |
4.7 |
완전연결 신경망 (대형) |
28x28-500-150-10 |
2.95 |
합성곱 신경망 |
LeNet-5 |
0.95 |
합성곱 신경망 (왜곡) |
LeNet-5 |
0.8 |
부스팅 |
Boosted LeNet-4 (왜곡) |
0.7 |
요지는 세 가지입니다. 첫째, 완전연결 신경망은 합성곱이 들어간 LeNet 계열보다 한참 떨어집니다. \(28 \times 28\) 입력에 두 은닉층을 둔 큰 완전연결망조차 \(2.95\%\)로, LeNet-5의 \(0.95\%\)의 세 배 가까운 오류를 냅니다. 국소 수용장 + 가중치 공유라는 구조적 사전 지식이 결정적이라는 본 논문의 주장이 표 한 장에 들어와 있습니다.
둘째, SVM은 LeNet-5와 비슷한 정확도를 보이지만 계산 비용이 차원이 다릅니다. SVM poly 4 한 번 추론에 약 1400만 곱셈-덧셈이 필요한 반면 LeNet-5는 약 40만 회면 됩니다. 메모리 측면에서도 V-SVM이 LeNet-5의 약 16배를 요구합니다.
셋째, 왜곡 증강과 부스팅이 신경망 쪽 한계를 더 밀어내는 추가 카드입니다. Boosted LeNet-4의 \(0.7\%\)는 본 논문 최고 기록이고, 단일 망 비용의 약 1.75배에 그칩니다.
LeNet-5가 틀린 82장은 Figure 8에 전부 실려 있습니다. 저자들은 그 대부분이 사람이 봐도 모호하거나, 학습셋에 부족하게 등장하는 스타일의 글자라고 분석합니다.
그래프 변환 망과 수표 판독
본 논문의 후반부 절반이 Graph Transformer Network입니다. 단일 문자 분류기를 문자열 시스템으로 확장하기 위한 학습 가능한 모듈 그래프입니다.
문제는 이렇습니다. 손글씨 단어를 읽으려면 먼저 글자를 분할해야 하는데, 분할이 완벽하지 않으면 분류기가 잘못된 입력을 받습니다. 종래 방식은 Heuristic Over-Segmentation, 즉 필요한 것보다 더 많이 자르고 그중 분류기 점수가 좋은 조합을 후처리로 고르는 것입니다. 이 방식의 문제는 분류기를 고립된 문자로만 학습시키기 때문에, 분할이 어긋난 입력에 분류기가 어떻게 반응할지 학습되지 않는다는 점입니다.
저자들의 해법은 시스템 전체를 문자열 단위의 손실로 한꺼번에 학습시키는 것입니다. 이를 위해 모듈 사이를 주고받는 정보를 고정 크기 벡터가 아닌 그래프로 정의합니다. 각 모듈은 그래프를 받아 그래프를 출력하고, 그래프의 호(arc)에 벡터·이미지·페널티가 붙습니다.
§IV~VIII에서 저자들은 이 그래프 위에서 역전파가 그대로 통한다는 것을 증명합니다. 핵심은 *일반화된 변환(generalized transduction)*이라는 합성 연산입니다. 두 입력 그래프(예: 인식 그래프와 문법 그래프)를 받아 출력 그래프를 만드는 Composition Transformer가 check(arc1, arc2), fprop(...), bprop(...) 세 메소드를 구현하면 됩니다. bprop이 미분 가능하면 그래프 위에서 그래디언트가 그대로 흐릅니다.
학습 손실로 두 가지를 다룹니다. 하나는 Viterbi training으로, 정답 라벨 시퀀스에 해당하는 최저 페널티 경로의 페널티를 줄입니다. 다른 하나는 Discriminative Forward training으로, 정답 경로의 forward score를 줄이면서 모든 경로의 forward score를 늘립니다.
\[E_{\text{dforw}} = C_{\text{cforw}} - C_{\text{forw}}.\]
여기서 \(C_{\text{cforw}}\)는 제약된 해석 그래프(정답 라벨 시퀀스만 통하는 부분 그래프)의 forward 페널티, \(C_{\text{forw}}\)는 전체 해석 그래프의 forward 페널티입니다. forward 페널티는 모든 경로의 페널티를 log-sum-exp로 모은 값입니다.
\[\text{logadd}(x_1, \ldots, x_n) = -\log \left( \sum_{i=1}^{n} e^{-x_i} \right).\]
이 판별적 손실이 위에서 본 LeNet-5의 RBF 손실과 본질적으로 같은 모양입니다. 정답을 끌어내리는 항과 경쟁을 끌어올리는 항의 차로 이루어집니다. 본 논문의 통일감이 이 지점에서 나옵니다.
§X에서 이 GTN이 실제 시스템으로 들어갑니다. Check Reader입니다.
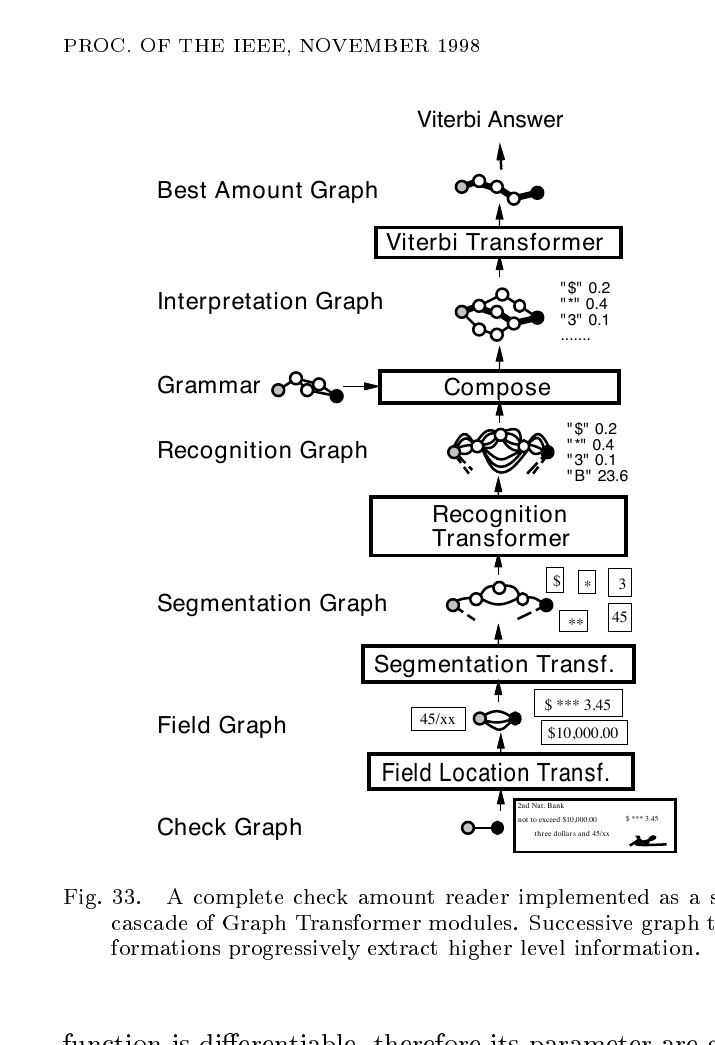
수표 한 장이 입력으로 들어오면 Field Location Transformer가 금액 후보 필드를 찾아 Field Graph를 만듭니다. Segmentation Transformer가 각 필드를 글자 후보들로 자르고, Recognition Transformer가 LeNet-5를 글자 후보마다 적용해 95개 ASCII 클래스 + 잡음 클래스의 점수를 매깁니다. Composition Transformer가 수표 금액 문법과 합성해 문법에 맞는 해석만 남기고, Viterbi Transformer가 최저 페널티 경로를 추출합니다.
학습은 수표 한 장 전체를 단위로 진행합니다. 분할 단계의 정답 라벨이 필요 없고, 수표 금액이라는 최종 라벨만 있으면 됩니다. 손실은 Discriminative Forward입니다. 사람이 분할 결과에 라벨을 붙이는 시간 소모적인 과정이 통째로 사라집니다.
논문이 출간되기 약 2년 전인 1996년 6월부터 이 시스템이 NCR을 통해 미국 여러 은행에 배포되었습니다. 본문 §X.D 보고에 따르면 영업용 수표(machine-print) 646장 테스트에서 82% 정확 인식, 1% 오답, 17% 거절을 달성하였고, 같은 데이터셋에서 이전 시스템은 68% 정확, 1% 오답, 31% 거절이었습니다. 거절률 절반 감소가 이 시스템의 진짜 가치였습니다. 그리고 그 핵심은 모든 모듈이 한 손실로 함께 학습되었다는 점입니다.
회고
저자들이 §XI 결론에서 직접 정리한 다섯 가지가 있습니다. 첫째, 학습 가능한 합성곱 신경망이 손으로 설계한 특징 추출기를 대체할 수 있다. 둘째, 분할 결정을 일찍 내리지 말고 경계 후보를 잔뜩 만들어 마지막에 함께 평가하라. 셋째, 분할된 문자에 사람이 일일이 라벨을 붙이는 것은 비싸고, 어차피 잘못 분할된 후보의 정답 라벨이 존재할 수 없으므로 문서 전체를 손실의 단위로 삼아야 한다. 넷째, 분할·인식·언어 모델 사이의 모호성을 통합적으로 풀어야 한다. 다섯째, 종래의 Space Displacement Neural Network처럼 분할을 아예 없애는 방식도 가능하지만 본 논문 시점에서는 Heuristic Over-Segmentation이 더 효율적이었다.
논문에는 작은 솔직함도 들어 있습니다. §VII.B에서 SDNN이 분할 없이 문자열을 읽는 데 성공한 예시(Figure 26)를 보여주면서도 §X.A에서 수표 시스템에는 Over-Segmentation을 채택했다고 적습니다. 이유로 영문 비흘림체에서 SDNN은 비용이 너무 크고, Over-Segmentation 휴리스틱이 영어 인쇄·필기 모두에서 충분히 잘 작동하기 때문이라고 밝힙니다. 가장 우아한 해법이 가장 실용적인 해법은 아니라는 인정입니다.
또 하나의 솔직함은 §VI.E에서 등장합니다. 비판별적 손실로 신경망/HMM 하이브리드를 학습시키면 붕괴 현상이 생기고, 본 논문이 도입한 판별적 손실은 그 문제를 회피하지만 정규화에 대한 명시적인 보장은 주지 않습니다. 저자들은 이것을 전통적 HMM과의 핵심 차이로 명시하고, 데이터 생성 모델과 최대우도 원리가 본 논문의 어떤 결정에도 동원되지 않았다는 점을 결론에서 굳이 강조합니다. HMM 진영의 정통 주장에 대한 반박이 마지막 페이지에 들어 있는 셈입니다.
정리
이 논문의 자리는 세 가지입니다. 첫째, 합성곱 신경망에 LeNet-5라는 정식 이름이 붙은 자리입니다. 둘째, MNIST라는 표준 벤치마크가 처음 정의된 자리입니다. 셋째, 학습 가능한 모듈을 그래프로 잇는다는 개념이 정식화된 자리입니다. 세 가지가 따로 떨어진 기여가 아니라 한 산업 시스템을 만들기 위해 같이 필요했던 것이라는 점이 본 논문의 통일감입니다.
LeNet-5의 약 60{,}000 파라미터는 14년 뒤 AlexNet에서 6천만 파라미터로 1000배 커지고, MNIST의 60{,}000장은 ImageNet의 1400만 장으로 200배 커지며, 본 논문의 GTN 개념은 end-to-end 학습이라는 이름으로 후속 시스템에 보편화됩니다. 다만 본 논문이 그 시점에 이미 1996년부터 미국 은행에서 매일 수백만 장의 수표를 자동 판독하고 있었다는 사실은, 딥러닝이 2012년부터 시작된 것이 아님을 기록으로 남깁니다.