DreamX-World 1.0 - A General-Purpose Interactive World Model
DreamX Team, "DreamX-World 1.0: A General-Purpose Interactive World Model," arXiv:2606.16993, 2026.
저자
DreamX-World 1.0은 알리바바 AMAP의 연구팀인 DreamX Team이 공개한 논문입니다. 저자 명단은 알파벳 순으로 나열되어 있으며, Yancheng Bai, Rui Chen, 추샹샹, Rujing Dang, Hao Dou, Bingjie Gao, Qiwen Gu, Siyu Hong, 레이자첸, Geng Li, Jifan Li, Ruimin Lin, Qingfeng Shi, Bingze Song, Lei Sun, Jing Tang, Ruitian Tian, Jun Wang, Jiahong Wu, Pengfei Zhang, Shen Zhang, 주자슈 등 총 22명입니다.
추샹샹는 AMAP의 Senior Director로, FairNAS, Twins, CPVT 등 아키텍처 연구부터 최근 FingER(ACM MM 2025), AngelSlim, Omni-WorldBench, GPG(ICLR 2026)까지 이 팀 연구 전반의 시니어 이름입니다. 2023년 AMiner Top 100 AI Scholar에 선정됐습니다. 레이자첸는 "There is No VAE: End-to-End Pixel-Space Generative Modeling"(ICLR 2026)를 통해 VAE 없는 픽셀 공간 생성 모델을 제안한 연구자이고, 주자슈는 minWM 프레임워크와 AngelSlim 모델 압축 도구를 이끌었습니다. 세 사람 모두 세계 모델 평가 벤치마크인 Omni-WorldBench의 공동 저자이기도 합니다.
배경
비디오 생성 모델은 짧은 클립을 합성하는 도구에서 사용자 입력에 실시간으로 반응하는 인터랙티브 시뮬레이터로 진화하고 있습니다. HY-WorldPlay 1.5, LingBot-World, Matrix-Game 3.0, Yume-1.5 같은 시스템들이 잇따라 등장하는 분야입니다.
이 방향에는 세 가지 결합된 기술적 난관이 있습니다. 첫째, 카메라 제어입니다. 지정된 궤적을 씬 전반에 걸쳐 일관된 시점 변화로 변환해야 하는데, 이를 위한 컨디셔닝이 비디오 백본의 계산 비용을 크게 늘려서는 안 됩니다. 둘째, 씬 지속성입니다. 모델은 로컬 컨텍스트 창을 벗어난 영역을 재방문했을 때도 이전에 생성한 씬의 레이아웃과 정체성을 유지해야 합니다. 자동회귀 생성에서 작은 예측 오차는 청크를 거듭하면서 외형, 스타일, 색상을 변질시킵니다. 셋째, 실시간 지연입니다. 오프라인 비디오 생성과 달리 인터랙티브 시스템은 낮은 지연이 필수입니다.
DreamX Team은 이 논문에서 세 가지 난관을 데이터, 학습, 평가, 추론 가속까지 포괄하는 풀스택 관점으로 동시에 풉니다. 결과물인 DreamX-World-1.0-5B는 5B 파라미터로 8B와 14B 경쟁 모델을 기본·장기·메모리 평가 전 축에서 앞섭니다.
어떻게 만들었나
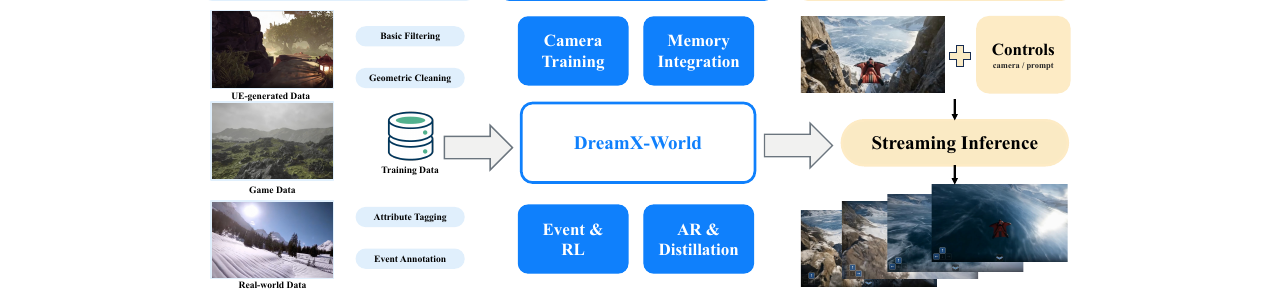
DreamX-World 1.0은 Wan2.2-TI2V를 베이스 모델로 삼고, 카메라 컨디셔닝 → 메모리 통합 → 이벤트 제어 → 자동회귀 증류·RL 순서의 점진적 학습 파이프라인을 거칩니다.
데이터
세 가지 소스를 조합해 광역 시각 도메인(포토리얼리스틱, 게임 스타일, 양식화)에 걸친 학습 데이터를 구축합니다.
- Unreal Engine 5: 1인칭·3인칭 자유 카메라 엔진을 통해 씬 탐색, 경로 검증, 오프라인 렌더링, 정밀 카메라 포즈 생성까지 5단계 파이프라인을 자체 운영합니다.
- 게임 레코딩: 액션 리치한 게임 영상을 수집합니다.
- 실세계 영상: 카메라 포즈를 복원한 실사 비디오를 사용합니다.
세 소스 모두 기하학적 필터링과 정규화를 거쳐 공통 표현으로 통합합니다.
E-PRoPE
PRoPE는 카메라 인트린식·익스트린식을 DiT 셀프어텐션에 프로젝티브 상대 위치 인코딩으로 주입하는 방식입니다. 학습·추론 비용이 높다는 단점이 있습니다.
DreamX Team은 E-PRoPE(Efficient PRoPE)를 도입해 이 문제를 완화했습니다. 핵심 아이디어는 PRoPE 어텐션 입력 토큰 \(X^{PRoPE} \in \mathbb{R}^{N \times d'}\)을 공간 방향으로 다운샘플해 저차원 쿼리/키/값 공간에서 프로젝티브 어텐션을 수행한 뒤 원래 해상도로 업샘플하는 것입니다. 5초 720P 비디오를 기준으로 Wan2.2 5B의 VAE는 \(S = 18480\)개 토큰을 출력하는데, E-PRoPE는 이를 \(N = 4096\)개로 줄여 처리합니다. 결과적으로 학습·추론 시간이 각각 약 50%, 30% 감소합니다.
또한 E-PRoPE는 원래 PRoPE의 \(D_s^{RoPE}\) 성분을 제거하고 프로젝티브 성분 \(D_s^{Proj}\)만 사용합니다. DiT 백본의 셀프어텐션이 이미 충분한 시공간 귀납적 편향을 제공하기 때문입니다. 인퍼런스 시 E-PRoPE 없이 학습된 모델에서도 PRoPE 모듈을 플러그앤플레이로 활용할 수 있다는 점도 확인했습니다.
Memory-Conditioned Scene Persistence
씬을 떠났다가 돌아왔을 때 이전과 동일한 장소처럼 보이게 하는 단계입니다.
메모리 프레임 \(z_\mathcal{M}\)(이전 히스토리에서 검색한 클린 잠재), 최근 히스토리 프레임 \(z_\mathcal{H}\), 타겟 프레임 \(z_\mathcal{C}^\tau\)를 하나의 시퀀스로 묶어 DiT 셀프어텐션에 통과시킵니다.
\[z_\text{pack} = [z_\mathcal{M} \mid z_\mathcal{H} \mid z_\mathcal{C}^\tau]\]
메모리 프레임을 선택할 때는 단순한 시간 근접성이 아니라 카메라 포즈와 뷰 오버랩 기반의 기하학적 검색을 수행합니다. 목표 뷰와 높이 겹치는 이전 프레임을 우선 선택하고, 해당 프레임에는 원래 시간적 위치에 해당하는 RoPE 임베딩을 부여해 시간적으로 인접한 프레임처럼 처리되지 않도록 합니다.
노출 편향 문제는 Stable Video Infinity의 오류 주입 방식으로 완화합니다. 학습 시에는 클린 프레임을 컨디셔닝하지만 추론 시에는 오류 있는 생성 프레임을 사용하는 불일치를 줄이기 위해, 컨디셔닝 토큰에 예측 오차를 섞어 모델이 불완전한 메모리에도 강인하게 학습됩니다.
이벤트 합성 제어
기존 시스템은 단일 객체·단일 이벤트 수준의 제어가 주를 이룹니다. DreamX-World 1.0은 하나의 포워드 패스에서 여러 객체가 동시에 등장하고, 행동하고, 상호작용하는 합성 이벤트를 처리하는 Event Instruction Tuning 단계를 추가합니다. 사용자는 각 객체의 등장 위치, 행동, 상호작용 방식을 구조화된 이벤트 지시문으로 기술합니다.
모델 |
프롬프터블 이벤트 |
객체 수준 이벤트 |
영역 가이드 이벤트 |
다중 개체 합성 |
객체간 상호작용 |
|---|---|---|---|---|---|
LingBot-World |
O |
O |
△ |
△ |
X |
HY-WorldPlay 1.5 |
O |
X |
X |
△ |
X |
Matrix-Game 3.0 |
X |
X |
X |
X |
X |
Yume-1.5 |
O |
O |
X |
X |
X |
DreamX-World 1.0 |
O |
O |
O |
O |
O |
△는 구조화된 이벤트 지시 없이 부분 지원을 나타냅니다.
자동회귀 증류와 RL 정렬
양방향 비디오 생성기를 스트리밍 자동회귀 월드 모델로 변환하는 과정은 두 단계입니다.
Causal Forcing으로 대규모 고품질 데이터에서 자동회귀 학습을 수행하고, Infinity-RoPE로 롱 컨텍스트를 지원하는 긴 롤아웃 학습을 거칩니다. 이어서 DMD 스타일 증류로 양방향 E-PRoPE 교사 모델에서 소수 스텝 자동회귀 학생 모델을 만들고, 장기 비디오에서 샘플한 로컬 시간 창 위에서 교사를 추종하도록 반복 훈련합니다.
DMD 증류 이후 RL 단계를 추가합니다. 두 보상 모델(카메라 제어 정확도, 시각 품질)을 사용해 DiffusionNFT 소프트 업데이트로 모델을 정렬합니다. KL 정규화가 증류된 사전 분포 근처에 모델을 유지합니다. 전체 롤아웃은 컨텍스트를 보존하고 단기 클립을 샘플해 보상을 계산함으로써 GPU 메모리를 실용 범위 안에 유지합니다.
추론 가속
실시간 배포를 위해 여러 기법을 결합합니다. DiT 어텐션 레이어에는 INT8 SageAttention, FFN 레이어에는 AngelSlim FP8 양자화를 적용합니다. 긴 시공간 시퀀스는 시퀀스 병렬처리로 GPU 간에 분산합니다. VAE 디코딩은 Matrix-Game 3.0 VAE를 75% 프루닝해 단일 청크 디코딩 시간을 약 0.25초로 줄이고, ParaVAE로 GPU 간 병렬 처리합니다. TeaCache의 잔차 재사용이 안정적인 타임스텝에서 Transformer 블록 포워드 패스를 생략합니다. 비동기 파이프라인 병렬처리로 청크 \(k\)의 VAE 디코딩과 청크 \(k+1\)의 DiT 추론을 오버랩합니다. 결과적으로 8×RTX 5090에서 최대 16 FPS를 달성합니다.
결과
비교 대상은 HY-WorldPlay 1.5(8B)와 LingBot-World(14B)입니다. 평가는 기본(5초), 장기(30초), 메모리 일관성(10초, 재방문 기반) 세 축으로 진행됩니다. 모든 점수는 [0, 100] 구간으로 정규화됩니다.
기본 평가 (5초 클립)
모델 |
파라미터 |
카메라↑ |
화질↑ |
전환↑ |
플리커↑ |
부드러움↑ |
역동성↑ |
아티팩트↑ |
전체↑ |
|---|---|---|---|---|---|---|---|---|---|
HY-WorldPlay 1.5 |
8B |
65.12 |
68.23 |
98.33 |
96.45 |
99.05 |
66.67 |
71.66 |
80.79 |
LingBot-World |
14B |
71.73 |
67.76 |
85.00 |
94.94 |
97.06 |
88.33 |
66.75 |
80.45 |
DreamX-World-1.0-5B |
5B |
73.75 |
66.75 |
98.33 |
96.17 |
98.79 |
85.83 |
73.75 |
84.76 |
DreamX-World-1.0-5B는 카메라 제어(73.75)와 아티팩트 감지(73.75)에서 두 경쟁 모델을 앞서고, 전체 점수(84.76)에서도 가장 높습니다. 파라미터 수는 경쟁 모델의 절반 이하(5B)입니다.
장기 생성 평가 (30초 롤아웃)
모델 |
파라미터 |
카메라↑ |
화질↑ |
전환↑ |
플리커↑ |
부드러움↑ |
역동성↑ |
아티팩트↑ |
전체↑ |
|---|---|---|---|---|---|---|---|---|---|
HY-WorldPlay 1.5 |
8B |
65.86 |
63.02 |
91.00 |
97.00 |
99.11 |
52.00 |
14.00 |
68.85 |
LingBot-World |
14B |
63.76 |
60.81 |
54.00 |
96.59 |
97.86 |
87.00 |
12.00 |
67.43 |
DreamX-World-1.0-5B |
5B |
62.03 |
64.11 |
80.00 |
96.35 |
98.41 |
75.00 |
17.00 |
70.41 |
30초 롤아웃에서 전체 점수는 70.41로 두 경쟁 모델(68.85, 67.43) 모두를 앞섭니다. 특히 전환 점수(80.00 vs LingBot-World 54.00)와 역동성(75.00 vs HY-WorldPlay 1.5 52.00)에서 차이가 크게 납니다. 강제 기반 학습과 롱 롤아웃 훈련이 장기 생성 안정성에 실질적으로 기여함을 보여줍니다.
메모리 일관성 평가
메모리 평가는 모델이 이전에 생성한 영역으로 돌아왔을 때 얼마나 동일한 씬을 유지하는지를 픽셀, 지각, 의미, 장소 인식, 기하 구조 5개 축으로 측정합니다. 기준선 대비 이득(gain)으로 보고합니다.
모델 |
ΔPSNR↑ |
ΔSSIM↑ |
ΔLPIPS↑ |
ΔDINO-Sim↑ |
ΔVPR-Sim↑ |
ΔSP-Match↑ |
CLIP-V↑ |
|---|---|---|---|---|---|---|---|
LingBot-World |
0.61 |
0.019 |
0.039 |
0.090 |
0.100 |
0.088 |
0.987 |
HY-WorldPlay 1.5 |
3.19 |
0.079 |
0.202 |
0.200 |
0.110 |
0.251 |
0.992 |
DreamX-World-1.0-5B |
3.92 |
0.098 |
0.232 |
0.246 |
0.142 |
0.216 |
0.991 |
DreamX-World-1.0-5B는 픽셀 수준(ΔPSNR 3.92, ΔSSIM 0.098), 지각적 일관성(ΔLPIPS 0.232), 의미 정체성(ΔDINO-Sim 0.246), 장소 인식(ΔVPR-Sim 0.142) 전 항목에서 가장 높습니다. 기하 구조 일치(ΔSP-Match)와 CLIP-Video에서는 HY-WorldPlay 1.5가 앞서지만, 나머지 4개 지표에서는 DreamX가 우위입니다. 인간 선호도 조사에서는 HY-WorldPlay 1.5 대비 57.5% 승률, LingBot-World 대비 61.9% 승률을 기록했습니다.
회고
저자들이 §7에서 솔직하게 인정한 한계 세 가지입니다.
장기 시각·기하학적 일관성이 여전히 어렵습니다. 오랜 상호작용 후 생성 씬의 객체 외형이나 레이아웃이 크게 달라질 수 있습니다. Memory-Conditioned Scene Persistence가 도움을 주지만 완전한 해결책은 아닙니다.
제어 신호 간 충돌도 남습니다. 이벤트가 생성한 시각 콘텐츠가 캡션에 명시된 씬 설정과 양립하지 않는 경우 모델이 혼란을 겪습니다. 카메라, 이벤트, 텍스트 세 가지 신호가 동시에 작동할 때 충돌 해소 메커니즘이 필요합니다.
자동 평가 지표의 불완전성도 지적합니다. Omni-WorldBench V2 같은 벤치마크가 중요하지만, 열린 상호작용에서는 인간 평가가 여전히 필수적입니다. 세계 모델 평가 방법론 자체가 아직 성숙하지 않았다는 점을 스스로 인정하고 있습니다.
미래 연구 방향으로는 캐릭터 중심 월드 모델(지속적 캐릭터 정체성, 다중 캐릭터 상호작용)과 네이티브 오디오-비주얼 월드 모델(동기화된 음성과 주변 음향)을 제시합니다.
정리
- DreamX-World-1.0-5B는 5B 파라미터로 8B HY-WorldPlay 1.5와 14B LingBot-World를 기본, 장기, 메모리 평가 전 축에서 앞섭니다. 규모 확장보다 풀스택 설계가 효과적임을 보여주는 사례입니다.
- E-PRoPE는 PRoPE의 카메라 제어 능력을 유지하면서 추론 지연을 약 30% 줄였습니다 (80초에서 59초로, 5초 720P 기준 8×H20 GPU).
- Memory-Conditioned Scene Persistence는 기하학 기반 검색과 오류 주입 조합으로 재방문 일관성에서 경쟁 모델을 앞섭니다.