OverFeat - Integrated Recognition, Localization and Detection using Convolutional Networks
P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun, "OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks," arXiv:1312.6229, 2014.
2012년 AlexNet이 ImageNet 분류 부문을 가져간 직후입니다. 분류 다음은 무엇인가라는 질문이 분명한 시점이었고, 다음 단계는 물체의 위치까지 동시에 찾는 것이었습니다. OverFeat은 그 다음 단계를 한 망으로 푸는 방법을 1년 만에 정식화하고 ILSVRC 2013 위치 추정 부문에서 우승한 연구입니다.
이 글의 한 마디 요지는 합성곱 망 자체가 슬라이딩 윈도우다입니다. 분류용으로 학습한 합성곱 망을 더 큰 이미지에 그대로 통과시키면 위치별 분류 점수 지도가 자동으로 나옵니다. 1989년 손글씨 우편번호 연구에서 얀 르쿤 본인이 한 번 사용했고, 1998년 LeNet-5 논문 §VII Space Displacement Neural Network에서 한 번 더 정리했던 그 발상을 ImageNet 스케일에서 다시 꺼낸 것이 OverFeat입니다.
저자
저자 여섯 명은 모두 NYU Courant Institute의 CILVR(Computational Intelligence, Learning, Vision, and Robotics) 연구실 소속이었습니다. 얀 르쿤과 롭 퍼거스가 시니어 지도자, 나머지 네 명은 박사과정 학생들이었습니다.
1저자 피에르 세르마네는 박사 과정 막바지였습니다. 그가 이전에 같은 합성곱 망을 교통 표지 인식(2011)과 보행자 검출(2013)에 적용해본 경험이 본 논문의 직접적 토대가 되었습니다. 두 작업 모두 다중 스케일 슬라이딩 윈도우를 합성곱으로 효율화한 것이었고, 본 논문은 같은 발상을 1000클래스 ImageNet에 확장한 것입니다.
데이비드 아이겐은 롭 퍼거스 지도 학생으로 단일 이미지 깊이 추정을 표준화한 인물입니다. 본 논문에서는 바운딩 박스 회귀 망을 담당하였습니다. 마지막 단을 4차원 좌표 회귀로 바꾸고 \(\ell_2\) 손실로 학습시키는 위치 추정 회귀기가 그의 작업입니다. 샹 장과 미카엘 마티외는 얀 르쿤 지도 학생들로 학습 인프라와 ImageNet 대규모 실험을 맡았습니다. 마티외는 같은 해 Fast Training of Convolutional Networks through FFTs(ICLR 2014)로 FFT 기반 합성곱 가속을 제안하였는데, 본 논문의 학습 속도가 그 작업의 직접적 수혜자입니다.
롭 퍼거스가 같은 시기 Visualizing and Understanding Convolutional Networks(Zeiler & Fergus, 같은 ILSVRC 2013에서 분류 부문 우승)를 발표하고 있었다는 점이 흥미롭습니다. 같은 연구실 같은 시기에 분류 성능을 끌어올리는 방향과 분류 다음 단계로 확장하는 방향이 동시에 진행되고 있었습니다.
배경
2012년 AlexNet은 ImageNet 분류 부문을 가져갔습니다. 같은 팀이 위치 추정 부문에도 인상적인 성과를 보였지만 그 방법을 따로 발표하지는 않았습니다. 저자들이 §1에서 명시적으로 적는 것이 우리 논문이 합성곱 망을 ImageNet 위치 추정과 검출에 어떻게 쓰는지 설명한 첫 글이다입니다.
2013년 ImageNet Challenge는 세 가지 부문으로 늘었습니다. 분류는 이미지 한 장에 라벨 5개 추측을 허용하고 그중 정답이 있으면 맞은 것으로 칩니다. 위치 추정은 같은 5번 기회에 라벨과 함께 바운딩 박스도 같이 반환해야 하고, 박스가 PASCAL 기준(IoU 0.5 이상)으로 맞아야 인정합니다. 검출은 한 장에 임의 개수의 물체가 있을 수 있고, false positive가 평균 정밀도(mAP)로 패널티를 받습니다. 분류에서 검출로 갈수록 작업이 어려워지고 학습 데이터의 성격도 달라집니다.
본 논문이 새로 푸는 문제는 두 가지입니다. 첫째, 이미지 안에 물체가 어디 있는지 모를 때 분류를 어떻게 정확히 할 것인가. ImageNet 분류 데이터는 물체가 화상 한가운데를 채우는 깔끔한 이미지가 대부분이지만, 위치 추정·검출 데이터는 작은 물체나 모서리 근처 물체가 흔합니다. 둘째, 분류 망을 어떻게 위치 추정·검출 망으로 재활용할 것인가. 새 망을 처음부터 학습시키는 대신 이미 학습된 합성곱 표현을 공유하면 학습 비용도 줄고 일반화도 좋아집니다.
합성곱이 곧 슬라이딩 윈도우다
본 논문의 핵심 통찰은 합성곱 망 자체가 슬라이딩 윈도우 분류기라는 것입니다. 분류용으로 \(221 \times 221\) 입력에 학습한 망에 더 큰 입력을 그대로 통과시키면, 마지막 완전연결 층을 \(1 \times 1\) 합성곱으로 재해석할 수 있어 출력이 위치별 클래스 점수 지도가 됩니다.
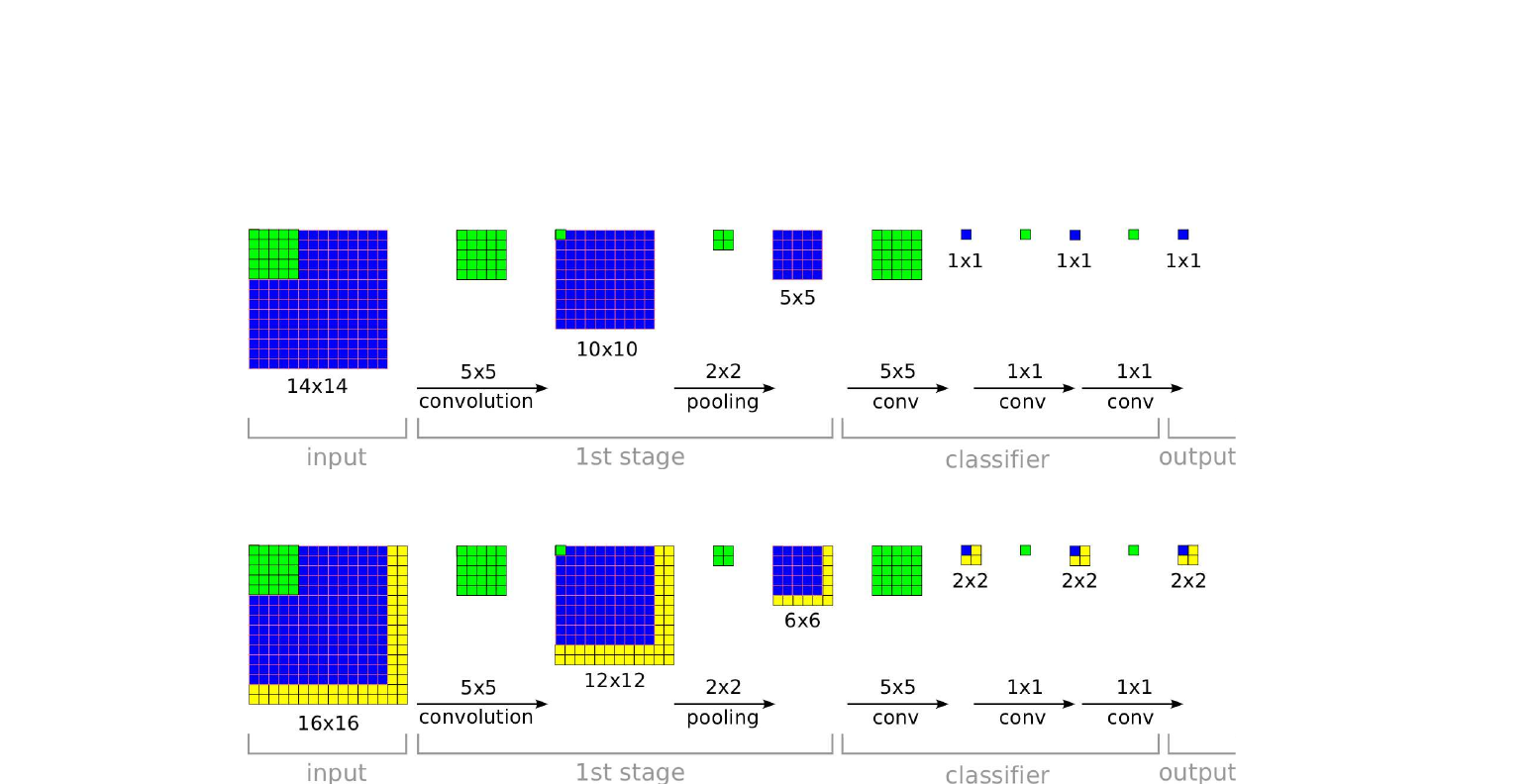
위 그림에서 윗줄은 학습 시 동작입니다. \(14 \times 14\) 입력이 5층을 거쳐 \(1 \times 1\) 출력으로 줄어듭니다. 아랫줄은 추론 시 동작입니다. 같은 망에 \(16 \times 16\) 입력을 그대로 넣으면 \(2 \times 2\) 출력 지도가 나옵니다. 추가된 노란 영역만 새로 계산하면 되니, 큰 입력 전체에 분류기를 슬라이딩 윈도우로 돌리는 비용보다 훨씬 쌉니다. 인접한 윈도우 사이의 공통 계산이 합성곱 구조 덕분에 자동으로 공유되기 때문입니다.
이 발상 자체는 1989년 손글씨 인식 작업까지 거슬러 올라가고 1998년 LeNet-5 논문 §VII에서 Space Displacement Neural Network로 정식화된 것입니다. OverFeat은 그 발상을 ImageNet 스케일에서 제대로 작동시키는 데 필요한 두 가지를 추가합니다. 다중 스케일 평가와 미세 스트라이드 풀링입니다.
미세 스트라이드와 다중 스케일
다중 스케일은 단순합니다. 한 입력을 6개의 해상도(245~461 픽셀)로 만들어 망에 각각 통과시키고, 출력 지도들을 결합합니다. 작은 물체는 큰 스케일에서, 큰 물체는 작은 스케일에서 잘 잡힙니다. AlexNet이 사용한 10-view voting(네 모서리 + 중심 + 좌우 반전)이 사실상 한 스케일에서 10개 윈도우만 본 것이라면, OverFeat은 여러 스케일 × 모든 위치를 봅니다.
문제는 합성곱 망의 총 다운샘플링 비율이 약 36배라는 점입니다. 입력에서 1픽셀 움직여도 출력 지도에서는 같은 위치에 떨어집니다. 즉 36픽셀 단위로만 분류 점수가 나옵니다. 이렇게 듬성듬성하면 다중 스케일 결합이 의미가 없습니다.
저자들의 해법이 Fine Stride Pooling입니다. 마지막 풀링 층의 시작 오프셋을 \(\Delta_x, \Delta_y \in \{0, 1, 2\}\)로 바꿔서 \(3 \times 3 = 9\) 가지 풀링 결과를 만들고, 이들을 합칩니다.
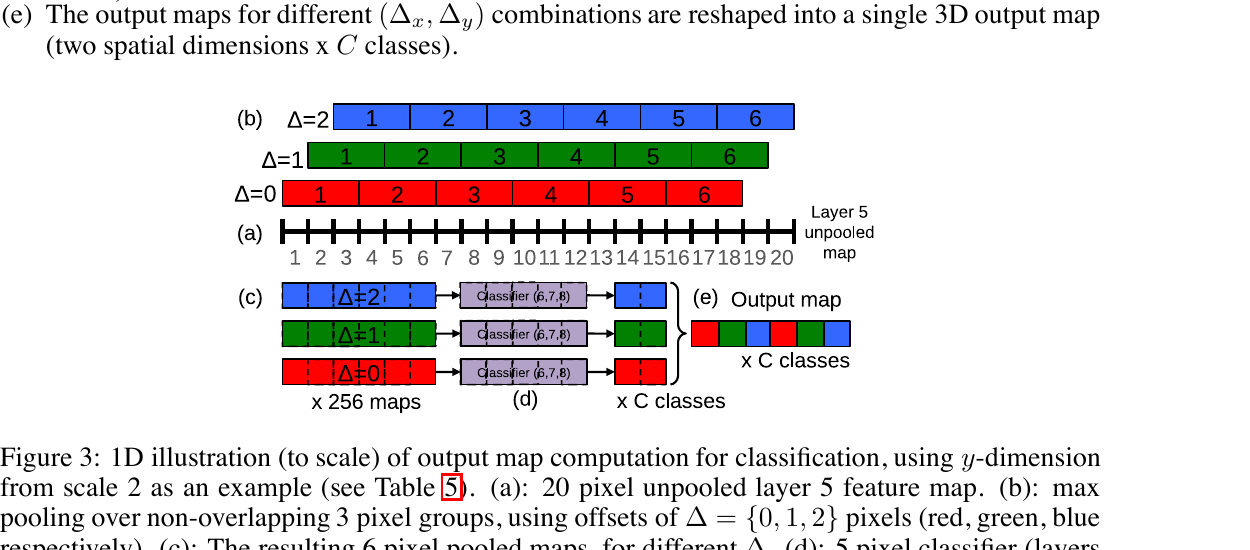
위 그림은 1차원에서의 도식입니다. (a) 길이 20의 풀링 전 특징 지도가 있습니다. (b) 비겹침 3픽셀 풀링을 \(\Delta = 0, 1, 2\) 세 가지 시작점에서 각각 적용해 길이 6의 풀링 결과 세 개를 만듭니다. (c) 분류기를 슬라이딩 윈도우로 각각에 적용해 길이 5의 클래스 점수 지도 세 개를 얻습니다. (e) 세 지도를 교차 배치로 합치면 길이 \(5 \times 3 = 15\), 즉 원래의 1/4 해상도의 출력 지도가 됩니다. 총 다운샘플링이 36배에서 12배로 줄어듭니다.
분류 학습 자체는 \(221 \times 221\) 입력에 비공간적 모드로 진행합니다. 출력이 \(1 \times 1 \times 1000\)이 되도록 망을 짜고, \(\mu = 0\), \(\sigma = 10^{-2}\)로 가중치를 초기화한 다음 미니배치 크기 128로 SGD(모멘텀 0.6, 가중치 감쇠 \(1 \times 10^{-5}\))로 학습합니다. 학습률은 \(5 \times 10^{-2}\)로 시작해 30·50·60·70·80 epoch마다 절반으로 줄입니다. Dropout 비율 0.5를 마지막 두 완전연결 층에 둡니다. 추론 모드에서만 큰 입력을 다중 스케일로 통과시켜 위치별 분류 점수 지도를 만듭니다.
저자들은 빠른 모델과 정확한 모델 두 가지를 함께 발표합니다. 두 모델의 차이는 다음과 같습니다.
모델 |
층 수 |
파라미터 |
연결 수 |
1층 stride |
|---|---|---|---|---|
AlexNet (Krizhevsky) |
8 |
6천만 |
미공개 |
4 |
OverFeat fast |
8 |
1.45억 |
28억 |
4 |
OverFeat accurate |
9 |
1.44억 |
54억 |
2 |
AlexNet 대비 두 모델 모두 contrast normalization을 빼고 비겹침 풀링을 씁니다. Accurate 모델은 1층 stride를 2로 줄여 1·2층 특징 지도를 더 크게 만들고 합성곱 단계를 한 단 더 추가합니다.
위치 추정과 검출
분류 망이 잘 학습되면 그 위에 위치 추정을 얹습니다. 합성곱 추출층 1~5를 고정한 채로 6~8층을 바운딩 박스 회귀기로 바꿉니다. 회귀 망은 4096·1024 두 완전연결 은닉층을 거쳐 4차원 좌표(top, left, bottom, right)를 출력합니다. 학습은 분류 망의 클래스별 활성화가 가리키는 위치마다 해당 위치 윈도우에서 본 ground-truth 박스를 타깃으로 하는 \(\ell_2\) 손실입니다.
다중 스케일 × 모든 위치에서 박스가 잔뜩 나오기 때문에 병합이 필요합니다. 저자들의 그리디 알고리즘은 다음과 같습니다. 각 스케일에서 클래스별 상위 점수 박스 집합을 모은 다음, 가장 가까운 두 박스 \(b_1, b_2\)를 골라 중심 거리 + 교집합 면적으로 정의된 match_score로 점수를 매기고, 점수가 임계값 이하면 두 박스를 평균으로 합칩니다. 더 이상 합칠 박스가 없을 때까지 반복합니다. 최종 박스의 신뢰도는 해당 박스에 합쳐진 모든 윈도우의 분류 점수 합으로 계산합니다.
이 박스 누적 방식이 본 논문의 두 번째 기여입니다. 전통적인 Non-Maximum Suppression은 신뢰도가 낮은 박스를 제거합니다. OverFeat은 반대로 합칩니다. 한 물체에 모인 박스가 많을수록 신뢰도가 올라가고, 한두 윈도우만 잘못 흥분한 false positive는 자연스럽게 합산 점수가 낮아집니다. 모든 위치에 일관된 박스가 모이는지가 곧 증거의 응집도가 됩니다.
검출은 위치 추정에 배경 클래스를 더한 것입니다. 종래의 bootstrapping 절차(어려운 음성 예제를 모아 다시 학습) 대신, 온라인으로 무작위 음성 예제를 골라 학습합니다. 비용은 더 들지만 학습 파이프라인이 단순해집니다.
결과
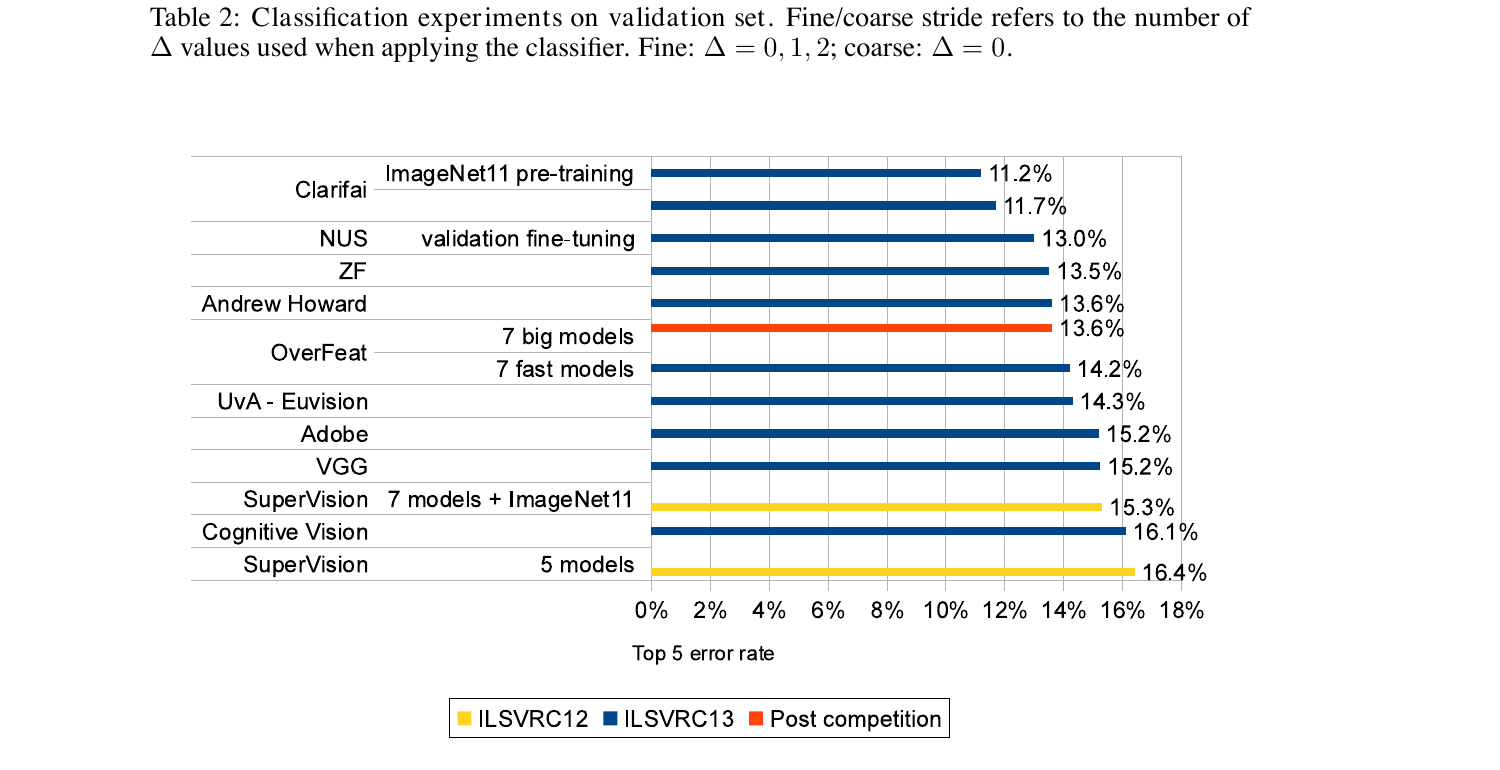
ILSVRC 2013 분류 결과는 다음과 같습니다.
시스템 |
top-5 오류율 (%) |
|---|---|
Clarifai (ImageNet11 pre-training) |
11.2 |
Clarifai |
11.7 |
NUS (validation fine-tuning) |
13.0 |
ZF |
13.5 |
Andrew Howard |
13.6 |
OverFeat (7 big models, post-competition) |
13.6 |
OverFeat (7 fast models) |
14.2 |
UvA-Euvision |
14.3 |
Adobe / VGG |
15.2 |
SuperVision (AlexNet 7 모델, ImageNet11) |
15.3 |
Cognitive Vision |
16.1 |
SuperVision (AlexNet 5 모델) |
16.4 |
OverFeat 경쟁 출품은 fast 모델 7개 평균으로 \(14.2\%\)였고, 대회 5위였습니다. 우승은 롭 퍼거스 그룹의 Clarifai(ZFNet 기반)였습니다. 본 논문이 발표될 때(2014년 2월) 저자들이 추가로 학습시킨 7개 큰 모델 평균이 \(13.6\%\)로 Clarifai와 약 2%p 차이를 줄였습니다. AlexNet의 \(16.4\%\) 대비로는 큰 폭의 개선이고, 본 논문 단일 모델 정확형의 \(14.18\%\) 역시 AlexNet 7-모델 앙상블보다 낫습니다.
위치 추정 결과는 더 명확합니다.
시스템 |
top-5 오류율 (%) |
|---|---|
OverFeat (4 scales, single-class regression) |
29.9 |
SuperVision (ImageNet11 pre-training) |
33.5 |
SuperVision |
34.2 |
Oxford VGG |
46.4 |
ISI |
53.6 |
OverFeat이 ILSVRC 2013 위치 추정 부문 우승입니다. 단일 스케일 중앙 크롭만 쓰면 \(40\%\)지만, 두 스케일을 합치면 \(31.5\%\), 네 스케일로 \(30.0\%\), 미세 스트라이드까지 적용해 \(29.9\%\)입니다. 다중 스케일과 다중 위치의 결합이 결정적이라는 본 논문의 주장이 표 안에 그대로 들어와 있습니다.
검출 부문은 post-competition에서 \(24.3\%\) mAP로 1위, 대회 당시는 \(19.4\%\)로 3위였습니다. 대회 1위 UvA의 \(22.6\%\)와의 차이는 분할 기반 후보 영역 제안 사용 여부였습니다. UvA는 Selective Search로 약 2000개 후보를 만들어 분류했고, OverFeat은 밀집 슬라이딩 윈도우를 그대로 썼습니다. 저자들은 제안 단계를 결합하면 더 좋아질 수 있다고 §6에서 직접 언급합니다.
회고
저자들이 §6 Discussion에서 직접 정리한 세 가지 개선 방향이 있습니다. 첫째, 위치 추정 학습 때 전체 망을 역전파하지 않는다. 합성곱 추출층은 분류 학습 결과를 고정한 채 회귀기만 학습합니다. 이를 풀면 더 좋아질 가능성이 있습니다. 둘째, \(\ell_2\) 손실이 아니라 IoU 자체를 직접 최적화하는 것이 평가 기준과 일치합니다. IoU는 미분 가능하므로 가능합니다. 셋째, 바운딩 박스 좌표 4개를 독립적으로 회귀하지 말고 상관관계를 줄이는 매개변수화를 쓰면 학습이 안정화될 수 있습니다.
이 세 가지가 거의 그대로 Faster R-CNN(2015)과 YOLO(2016)의 출발점이 됩니다. 영역 제안 망과 분류 망을 함께 학습하는 방향이 첫째 항목, IoU 손실은 GIoU·DIoU·CIoU 계열로 발전합니다. 바운딩 박스의 anchor나 center+size 매개변수화는 셋째 항목의 정확한 후속입니다.
본 논문이 살짝 비켜간 한 가지가 있습니다. Per-class regression과 Single-class regression 비교입니다. 1000개 클래스마다 회귀기 마지막 층을 따로 두면 클래스별 정밀도가 올라갈 것 같지만, 실제로는 Single-class regression(전 클래스 공유 회귀기)이 \(31.3\%\)로 더 좋고 Per-class는 \(44.1\%\)입니다. 이유는 클래스당 바운딩 박스 학습 표본이 너무 적기 때문이라고 본문에 적습니다. 1000배 더 많은 마지막 층 파라미터를 채우려면 표본도 1000배 필요한데, 그게 없습니다. 검출 단계에서 같은 함정에 빠지지 말라는 단서입니다.
정리
OverFeat의 자리는 두 가지입니다. 첫째, 분류 다음의 시각 작업을 합성곱 망으로 어떻게 푸는지를 ImageNet 스케일에서 처음 정식화한 글입니다. 둘째, 합성곱 망 자체가 슬라이딩 윈도우라는 1989년의 발상을 ImageNet 시대에 다시 살린 글입니다.
여기서 도입된 다중 스케일 밀집 평가는 AlexNet의 10-view voting을 한참 넘어선 다음 단계였고, 바운딩 박스 누적은 후속 Non-Maximum Suppression의 학습 가능 버전이 됩니다. 위치 추정·검출을 분류 망 위에 작은 회귀 머리만 얹어 푸는 방식은 1년 뒤 R-CNN과 Fast R-CNN에서 영역 제안 기반으로 분기하고, 2년 뒤 Faster R-CNN과 YOLO에서 완전히 자리잡습니다. 검출·분할·자세 추정의 백본 + 헤드 분리 구조의 시작점이 본 논문입니다.
이 논문이 Krizhevsky 등의 작업을 ImageNet 2012에서 어떻게 했는지 설명한 후속작이 없다는 솔직한 한 줄로 시작한다는 점이 흥미롭습니다. 분류 다음을 어떻게 풀지는 그때까지 발표된 적이 없는 영역이었고, OverFeat이 그 자리에 깃발을 꽂은 것입니다.