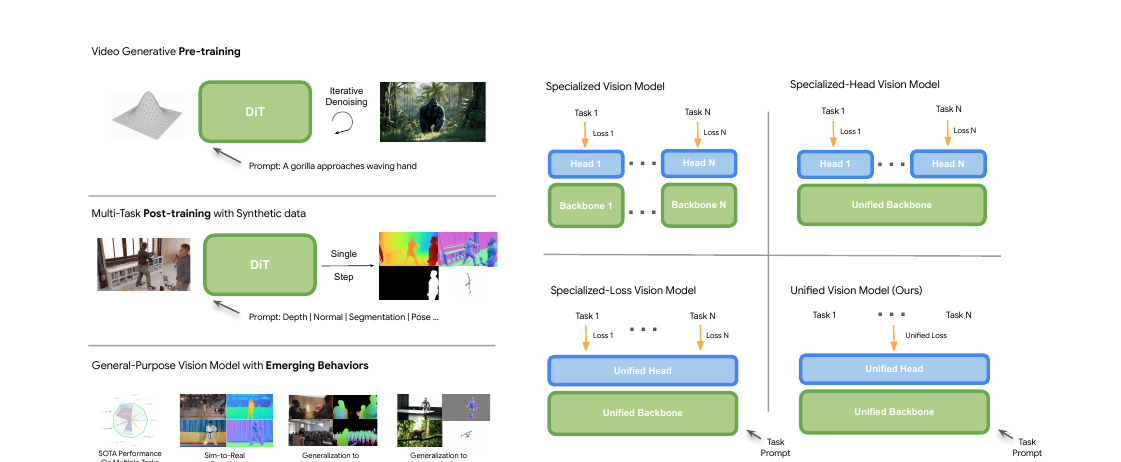
비디오 생성 모델의 사전학습 표현을 활용해 깊이·법선·분할·포즈 등 다양한 비전 과제를 단일 피드포워드 모델로 처리하는 GenCeption을 제안한다. WAN 2.1 기반으로 V-JEPA·VideoMAE를 큰 폭으로 앞서며, 7x~500x 적은 데이터로 전문 모델에 준하는 성능을 냈다.
태그: 확산모델
34개의 게시물
-
-
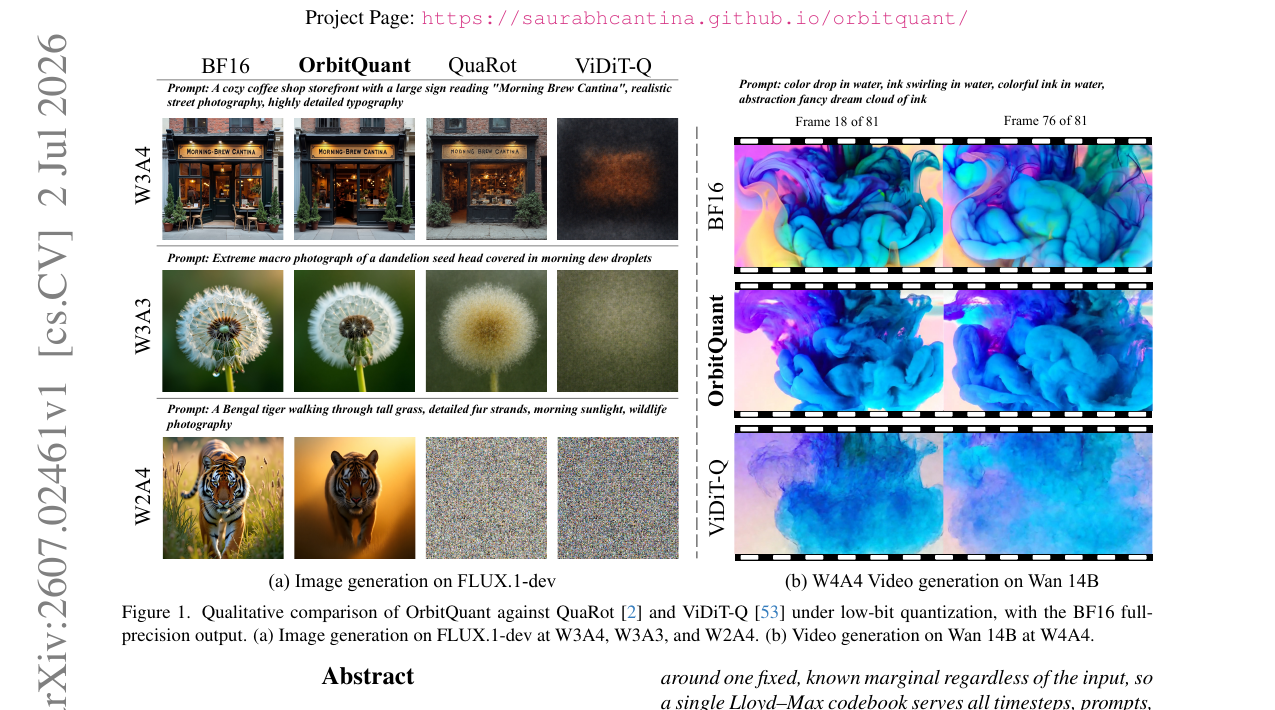
DiT 활성화의 타임스텝·프롬프트별 드리프트 문제를 RPBH 회전으로 정규화된 분포로 고정하고, 단일 Lloyd-Max 코드북으로 캘리브레이션 없이 가중치와 활성화를 동시에 양자화합니다. GenEval W2A4에서 기존 방법들이 모두 붕괴할 때 유일하게 생성 가능한 품질을 유지합니다.
-
 Multi-Resolution Flow Matching - Training-Free Diffusion Acceleration via Staged Sampling 2026-07-05
Multi-Resolution Flow Matching - Training-Free Diffusion Acceleration via Staged Sampling 2026-07-05재훈련 없이 FLUX·Qwen-Image 같은 플로우 매칭 확산 모델을 10× 가속하는 MrFlow를 제안합니다. 초반 스텝은 저해상도 잠재 공간에서 처리하고, 픽셀 공간 GAN 슈퍼해상도를 거쳐 단 1스텝 고해상도 정제로 마무리하는 단계별 파이프라인입니다.
-
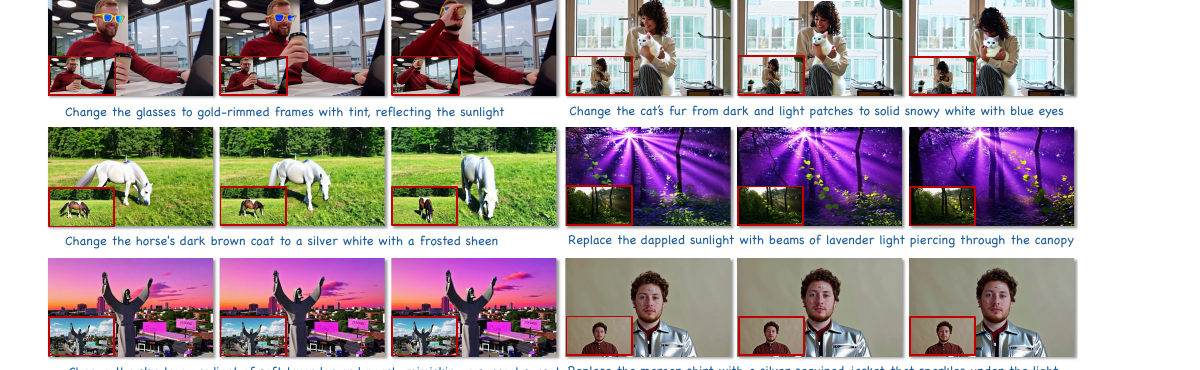
청화대와 HKUST가 공동으로 제안한 스트리밍 비디오 편집 프레임워크. 3단계 확산 모델 증류와 AR-oriented Mask Cache를 조합해 InsV2V 대비 97.38배 지연을 단축하고, 12.66 FPS 실시간 편집을 달성합니다.
-
 Improved Large Language Diffusion Models 2026-06-30
Improved Large Language Diffusion Models 2026-06-30자기회귀 없이 완전 양방향 어텐션으로 LLM을 처음부터 학습하는 마스크드 확산 언어 모델 iLLaDA — 12T 토큰 사전학습과 25B 지시문 미세조정으로 Base 성능에서 Qwen2.5 7B를 처음으로 따라잡습니다.
-
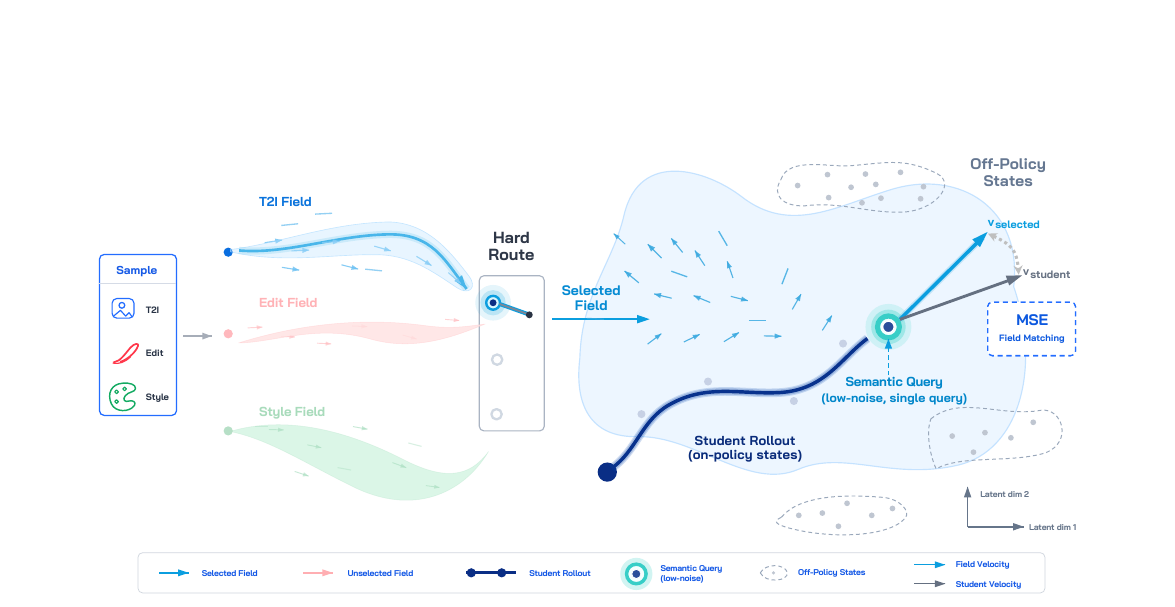
ByteDance Seed와 NUS가 제안한 on-policy 생성 필드 증류 프레임워크. 하나의 flow-matching 학생 모델에 T2I, 로컬 편집, 글로벌 편집 능력을 충돌 없이 합성하는 세 가지 설계 원칙을 제시합니다.
-

베이징대학교 MSALab과 ByteDance가 만든 멀티모달 확산 언어 모델. 자기회귀가 영역을 하나씩 순차로 캡셔닝하는 한계를 깨고, 한 번의 디노이징으로 여러 영역을 동시에 설명합니다. 구조적 어텐션 마스킹으로 영역 간 간섭을 막으면서 최대 3.5배 빠른 추론을 보입니다.
-
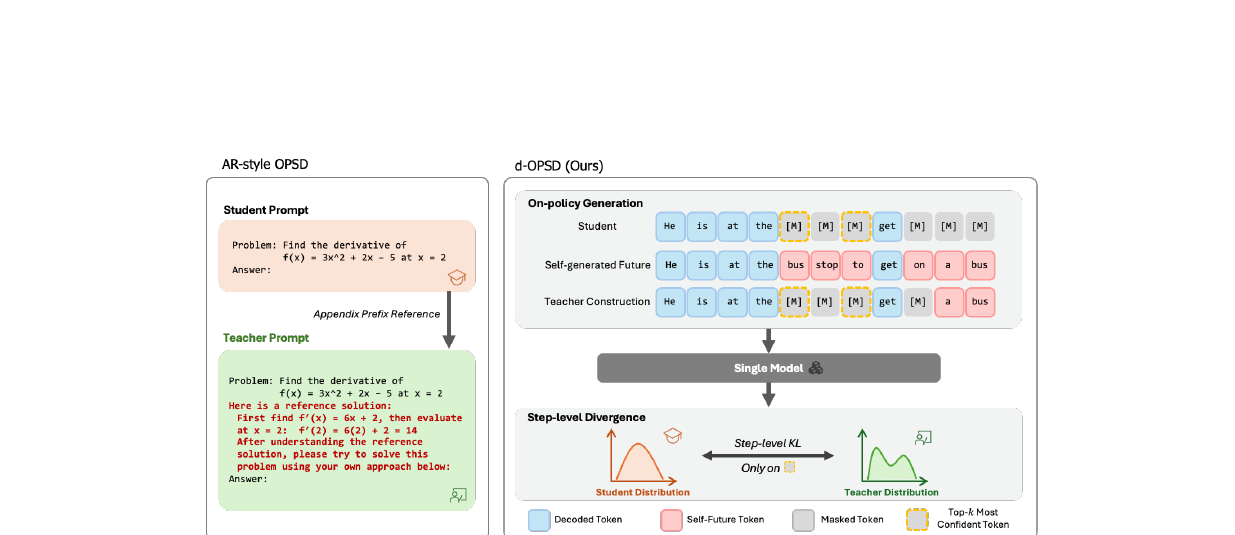
확산 LLM(dLLM)에 온폴리시 자기증류를 처음 적용한 d-OPSD. 모델이 스스로 완성한 미래 답변을 suffix로 조건화해 RLVR 대비 약 10% 최적화 스텝으로 동급 성능을 달성합니다.
-
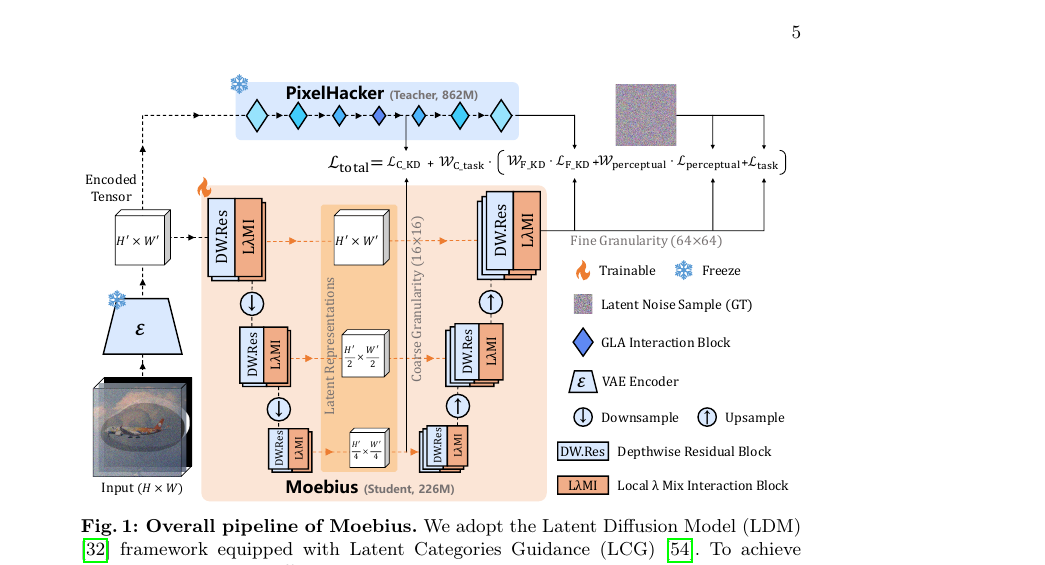
0.22B 파라미터로 11.9B짜리 FLUX.1-Fill-Dev와 맞먹는 이미지 인페인팅을 구현한 Moebius. 표현 병목을 깨기 위해 Local-λ Mix Interaction 블록과 잠재 공간 다중 입도 증류를 결합했습니다.
-
알리바바 AMAP-ML DreamX Team이 공개한 5B 파라미터 인터랙티브 월드 모델. E-PRoPE 카메라 제어, 기하학 기반 메모리 검색, 이벤트 합성 제어를 갖추고 8B·14B 경쟁 모델을 전체 스코어에서 앞섰습니다.
-

장기 영상 생성에서 반복 등장 인물의 정체성을 유지하기 위해 메모리 기반 피사체 재구성을 보조 학습 목표로 삼는 Memento 프레임워크. 이중 경로 메모리(story query + shot query)로 장기 아이덴티티 단서와 단기 문맥을 분리해, 샷 단위 자기회귀 생성에서 일관된 인물 외형을 유지합니다.
-

쾌수 Kling 팀이 제안한 멀티샷 카메라 클로닝 프레임워크입니다. 레퍼런스 비디오의 카메라 파라미터를 3D 빈 공간 그리드 영상으로 변환해 크로스 페어드 데이터 없이도 복잡한 카메라 모션을 클로닝합니다.
-
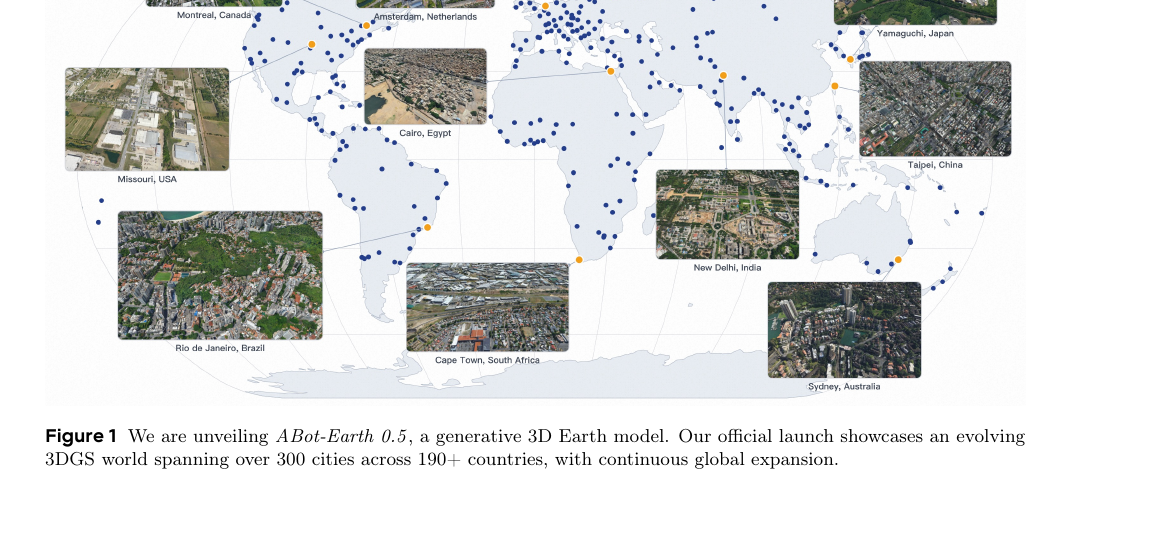 ABot-Earth 0.5 - Generative 3D Earth Model 2026-06-16
ABot-Earth 0.5 - Generative 3D Earth Model 2026-06-16알리바바 AMAP CV Lab의 생성형 3D 지구 모델입니다. 위성 영상만으로 도시 규모 3DGS 장면을 10분/km² 속도로 생성하며, 3.2조 개의 Gaussian primitive로 전 세계를 커버하는 지구 규모 배포 시스템을 함께 제시합니다.
-
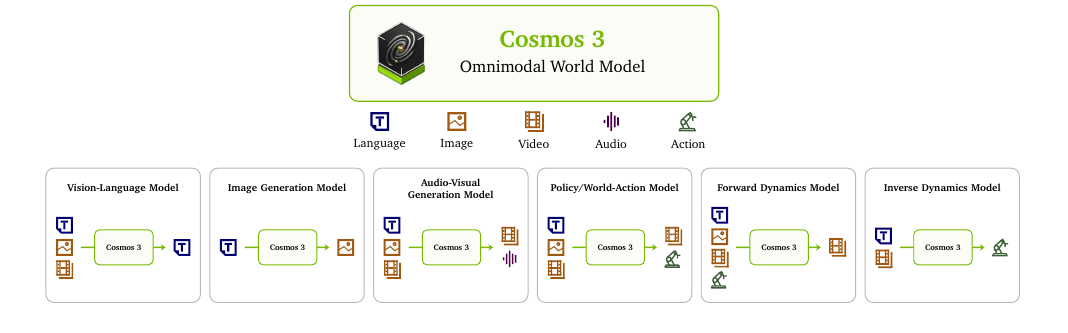
NVIDIA가 공개한 옴니모달 월드 모델 Cosmos 3를 분석합니다. 언어, 이미지, 비디오, 오디오, 행동을 한 Mixture-of-Transformers 구조로 처리하고 생성하며, 자기회귀 추론 타워와 확산 생성 타워를 결합해 비전언어모델, 비디오 생성기, 월드 시뮬레이터, 월드 액션 모델을 하나의 백본으로 흡수합니다.
-
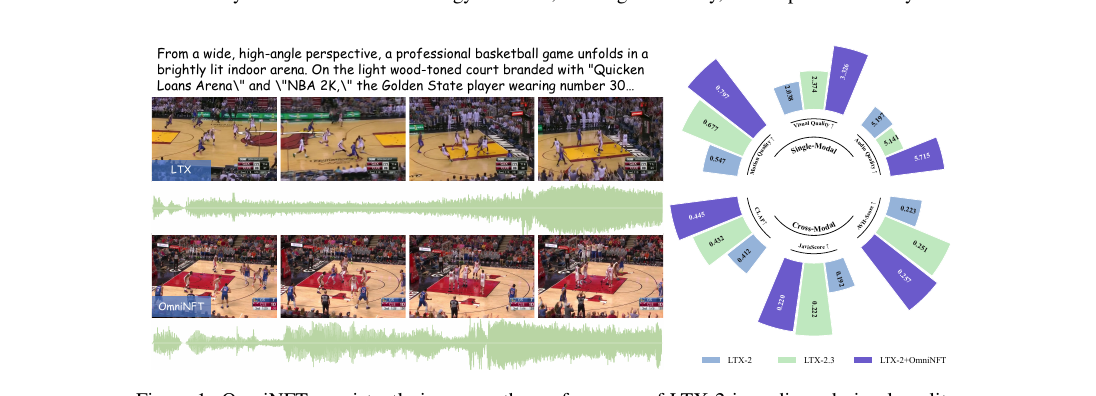
19B 규모 joint audio-video diffusion 모델 LTX-2 위에 RL fine-tuning을 얹어 영상 품질·음향 품질·립싱크를 동시에 끌어올린 OmniNFT를 정리합니다. modality-wise advantage routing, layer-wise gradient surgery, region-wise loss reweighting 세 디자인이 multi-modal RL의 reward hacking 양상을 어떻게 바꾸는지, 그리고 한국 비디오 생성 스타트업·후반 작업 도구 관점에서 어떤 의미를 갖는지 봅니다.
-
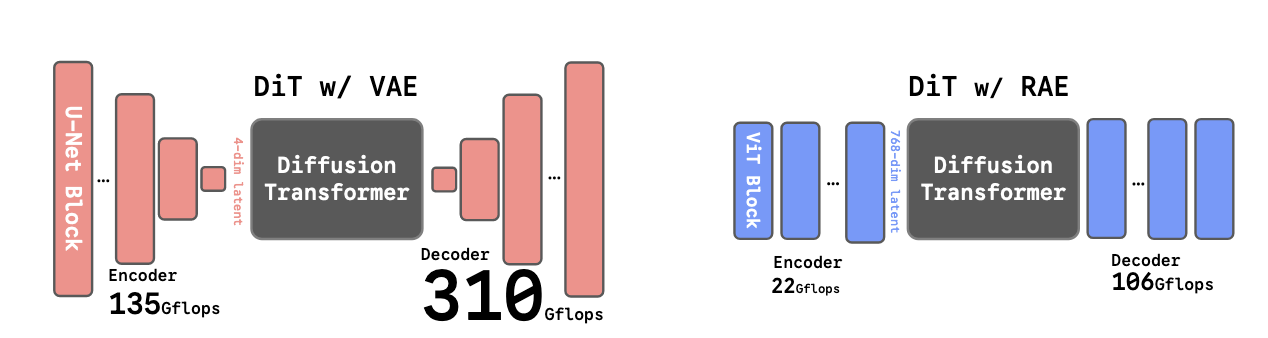
최근 이미지 생성 분야에서 Diffusion Transformer(DiT)는 픽셀 공간이 아닌 사전 학습된 오토인코더가 만든 잠재 공간(latent space)에서 확산 과정을 수행하는 것이 표준이 되었습니다. 하지만 대부분의 DiT는 여전히 원래의 VAE 인코더에 의존하고 있고, 이는 몇 가지 한계를 가지고 있습니다. 이 논문은 VAE를 사전 학습된 표현 인코더(DINO, SigLIP, MAE 등)와 학습된 디코더로 구성된 Representation Autoencoder(RAE)로 대체하는 새로운 접근을 제안합니다.
-
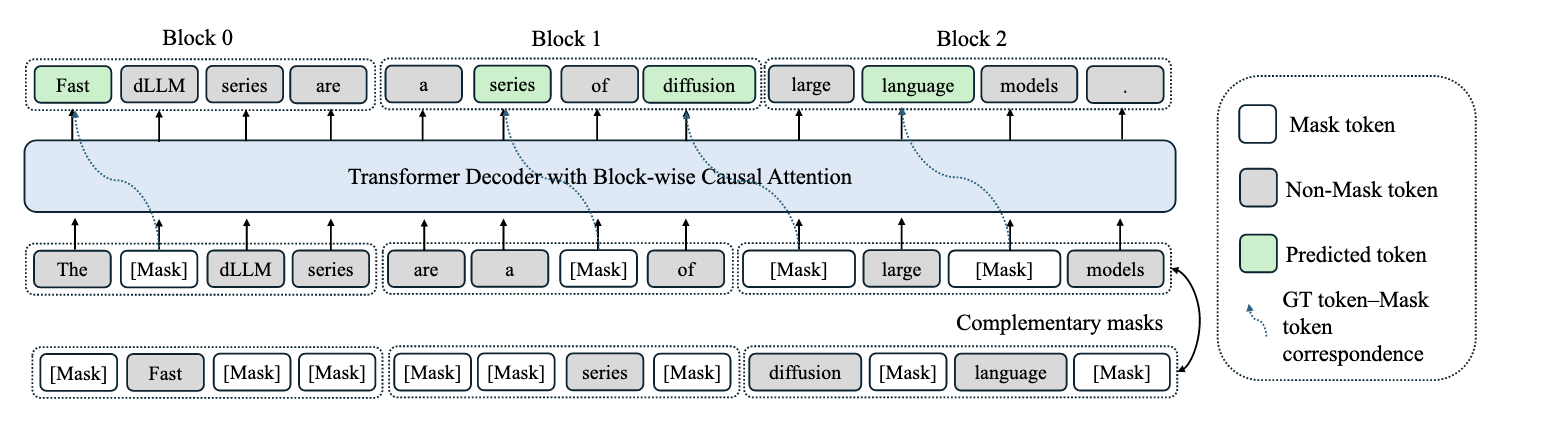 FAST-DLLM V2 Efficient Block-Diffusion LLM 2025-10-09
FAST-DLLM V2 Efficient Block-Diffusion LLM 2025-10-09NVIDIA의 힘은 GPU가 다가 아니죠. 명실상부 LLM 선두주자의 새로운 논문입니다. 자연어 처리 모델이 토큰을 생성하는 기본적인 방법인 자기회귀(AR)의 한계를 극복하는 병렬 텍스트 생성 모델입니다. 적은 토큰으로도 파인 튜닝이 가능하고 500배 적은 학습 데이터로 기존 Dream 모델과 동일한 성능을 달성합니다.
-

알리바바 AMAP-ML 연구원으로 minWM 프레임워크·Omni-WorldBench·AngelSlim 등 인터랙티브 월드 모델과 효율 추론 전반에 기여
-
ByteDance Seed Vision 팀 연구과학자. Seedream 4.0/4.5 이미지 생성·편집 공동 훈련 알고리즘 설계를 이끈 연구자.
-
알리바바 AMAP-ML 연구원으로 "There is No VAE" 픽셀공간 생성 모델과 DreamX-World 1.0 인터랙티브 월드 모델의 핵심 기여자
-
화중과기대(HUST) 박사과정 연구원. 이미지 인페인팅 특화. PixelHacker(2504.20438), Moebius(2606.19195) 제1저자.
-
싱가포르국립대학교(NUS) Show Lab 소속, MeissonFlow Research 리드. 마스크드 생성 모델·통합 멀티모달 생성 연구. Muddit·Meissonic 저자
-
지린대학교 소속 머신러닝 연구자. 확률적 방법·심층 생성 모델·표현학습·최적수송 연구. GateMem 교신저자
-
샤먼대학 박사과정생으로 Baidu ERNIE Team 인턴 중 Memento 장기 영상 생성 프레임워크를 공동 개발한 제1저자
-
중국인민대학교 고링 인공지능학원 부교수. 생성 모델·확산 모델·베이즈 딥러닝 전문가. LLaDA·iLLaDA 교신저자
-
USTC 박사과정. [[자오펑]] 연구실에서 image restoration·diffusion·flow-based generative model을 연구. OmniNFT 공저자.
-
화중과기대(HUST) Vision Lab 연구원. 이미지 인페인팅 분야. PixelHacker(2504.20438)·Moebius(2606.19195) 공동 제1저자.
-
NVIDIA Research Santa Clara 연구 과학자. 공간 전파 네트워크 및 4D 장면 생성 전문가.
-
알리바바 그룹 산하 지도 서비스 부문 AMAP(高德地图)의 컴퓨터비전 연구팀. 위성 영상 기반 3D 장면 생성과 대규모 지리공간 AI 연구를 수행합니다.
-
쾌수(Kuaishou) 소속 Kling 비디오 생성 모델 팀. 영상 생성 연구 및 상용 모델 개발.
-
Baidu ERNIE Team 연구자로 Memento 장기 영상 생성 프로젝트를 이끈 Project Lead
-
Princeton 전기컴퓨터공학과 박사후연구원, Gen-Verse 리더, 확산 모델과 에이전트 RL 연구
-
베이징대학교 소속, ByteDance 협업 멀티모달 연구자. PerceptionDLM 공동 1저자, Sa2VA 공저자
-
샤먼대학 교수로 Memento 장기 영상 생성 연구의 교신저자이며 영상 생성·인식 분야를 연구