Moebius - 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
K. Duan, Z. Xu, W. Liu, X. Ruan, X. Chen, and X. Wang, "Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance," arXiv:2606.19195, 2026.
저자
Kangsheng Duan과 Ziyang Xu가 공동 제1저자이며 Xinggang Wang 교수가 교신저자를 맡았습니다. 세 명 모두 화중과학기술대학교(HUST) Vision Lab 소속입니다. Xiaohu Ruan과 Xiaoxin Chen은 VIVO AI Lab에서 합류했습니다.
Ziyang Xu는 2025년 4월 선행 연구인 PixelHacker를 발표한 바 있으며, Moebius는 그 직계 후속작입니다. 즉, 교사 모델을 직접 개발한 팀이 학생 모델까지 만든 셈입니다. 이 점이 이 연구를 특별하게 합니다. 자신이 설계한 교사의 내부 구조를 속속들이 알고 있으므로, 어디를 얼마나 압축해도 되는지 판단하기 유리한 위치에 있었습니다.
배경
이미지 인페인팅(Image Inpainting)은 사진에서 지운 영역을 자연스럽게 채우는 작업입니다. 객체 제거, 사진 복원, 편집 등 일상적으로 쓰이는 기능이지만, 최근 몇 년 새 이 작업을 잘 수행하는 모델들이 FLUX.1-Fill-Dev(11.9B)나 SD3.5 Large(8.1B) 같은 거대 파운데이션 모델이 되어버렸습니다.
문제는 현실적인 배포입니다. 11.9B 파라미터 모델은 소비자용 GPU에서 실시간으로 돌리기 어렵습니다. "태스크 특화 경량 모델을 만들면 되지 않느냐"는 질문이 자연스럽게 나오지만, 기존 연구들이 이 방향을 시도했을 때 공통적으로 맞닥뜨린 벽이 있었습니다. 극단적 압축, 즉 파라미터를 1% 수준까지 줄이면 모델의 표현력이 급락합니다. 저자들은 이를 "표현 병목(Representation Bottleneck)"이라고 부릅니다.
Moebius의 핵심 질문은 이것입니다. "표현 병목을 구조적으로 풀면서도 파라미터를 2% 수준까지 줄일 수 있는가?"
어떻게 만들었나
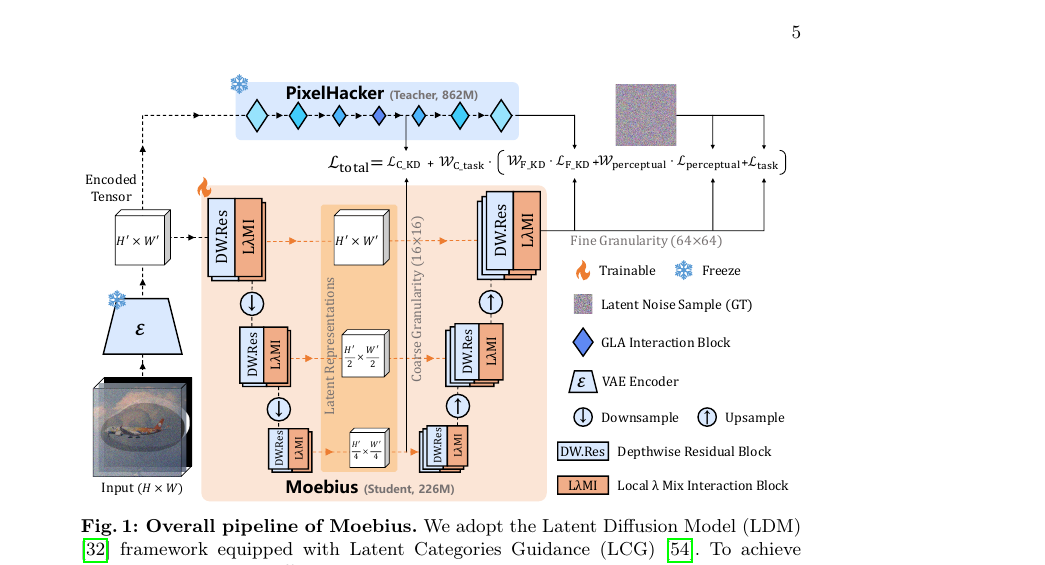
전체 파이프라인은 Latent Diffusion Model(LDM) 위에 Latent Categories Guidance(LCG) 패러다임을 얹은 구조입니다. 교사 모델 PixelHacker(862M)가 이미 LCG를 사용하므로 학생(Moebius, 226M)도 같은 방식으로 글로벌 시맨틱 임베딩 \(E_{LCG}\)를 주입받습니다.
LλMI 블록: 선형 행렬로 attention을 대체하기
표현 병목의 근본 원인은 기존 경량화 기법이 attention 연산을 단순히 대체했을 뿐, 어떻게 대체해야 하는지 수학적 근거가 부족했다는 데 있습니다. Moebius는 Local-λ Mix Interaction(LλMI) 블록을 제안해 이를 해결합니다.
Local-λ: 자기 어텐션 대체
입력 잠재 표현 \(X_l \in \mathbb{R}^{B \times H' \times W' \times C}\)를 \(1 \times 1\) 합성곱으로 Query, Key, Value로 분해합니다. 메모리를 잡아먹는 \(Q K^\top\) 점적 어텐션 대신, 컨텍스트를 고정 크기 선형 행렬 \(\lambda^l\)로 압축합니다.
\[\lambda^l_c = \text{softmax}(K^l)^\top V^l, \quad \lambda^l_p = \text{Conv3D}^{\text{pos}}_{1 \times r \times r}(V^l)\]
- \(\lambda^l_c\): 시맨틱 컨텐츠 매핑 (소프트맥스로 정규화한 Key와 Value의 행렬곱)
- \(\lambda^l_p\): 위치 매핑 (지역 인식 창 크기 \(r=15\)의 3D 합성곱)
최종 출력은 \(Y^l = Q^l \lambda^l_c + Q^l \lambda^l_p\)입니다. 쿼리가 두 개의 컴팩트한 행렬과 선형 연산을 하므로 계산 복잡도가 입력 크기에 선형으로 비례합니다.
Interactive-λ: 교차 어텐션 대체
LCG 임베딩 \(E_{LCG}\)는 잠재 표현보다 훨씬 작은 공간 스케일을 가집니다. 이 스케일 차이 탓에 GLA(Gated Linear Attention)는 수학적으로 교차 어텐션을 처리하지 못합니다. Interactive-λ는 이 문제를 풀기 위해 설계됩니다.
\[\lambda^i_c = \text{softmax}(K^i)^\top V^i, \quad \lambda^i_p = E_{\text{pos}} V^i, \quad Y^i = Q^i \lambda^i_c + Q^i \lambda^i_p\]
여기서 \(E_{LCG}\)를 Key와 Value로 투영하고, 공간 레이아웃 정보를 명시적으로 주입하는 위치 임베딩 \(E_{\text{pos}}\)를 덧붙입니다.
LλMI 블록 전체 순전파는 세 연산의 잔차 연결로 정의됩니다.
\[\begin{aligned} X_1 &= \text{Local-}\lambda(\text{LN}(X_{in})) + X_{in} \\ X_2 &= \text{Interactive-}\lambda(\text{LN}(X_1), E_{LCG}) + X_1 \\ X_{out} &= \text{Mix-FFN}(\text{LN}(X_2)) + X_2 \end{aligned}\]
Mix-FFN은 밀집 선형 투영 대신 깊이별 합성곱을 쓰는 경량 FFN입니다. 이 조합이 파라미터를 226M까지 낮춥니다.
적응적 다중 입도 증류
LλMI 블록만으로는 부족합니다. 실험에서 표준 예측 손실만 쓰면 FID 33.42로 수렴이 막힙니다. 증류(distillation)가 필수입니다.
Moebius는 픽셀 공간 디코딩 없이 잠재 공간 내에서만 증류를 수행합니다. 이유는 단순합니다. 경량 모델이 훈련 중에 고해상도 잠재 표현을 픽셀 공간으로 디코딩했다 다시 올리면 메모리 부담이 너무 커집니다.
증류 목표는 세 가지입니다.
손실 |
입도 |
설명 |
|---|---|---|
\(\mathcal{L}_{C\_KD}\) |
거친 (16×16) |
교사의 중간 병목 표현과 학생의 마지막 다운샘플링 출력을 L2 정렬 |
\(\mathcal{L}_{F\_KD}\) + \(\mathcal{L}_{task}\) |
세밀한 (64×64) |
교사-학생 최종 출력 L2 정렬 + 정답 잠재 노이즈와의 L2 손실 |
\(\mathcal{L}_{perceptual}\) |
세밀한 (64×64) |
E-LatentLPIPS로 잠재 공간 내 지각적 정렬 |
이 네 손실의 스케일과 기울기 기여가 크게 다르므로, 정적 가중치를 쓰면 수렴이 불안정합니다. 저자들은 경사 기반 적응 가중치를 씁니다.
\[\mathcal{W}_{F\_KD} = \frac{\|G(\mathcal{L}_{task}, \theta_F)\|^2_2}{\|G(\mathcal{L}_{F\_KD}, \theta_F)\|^2_2}, \quad \mathcal{W}_{perceptual} = \frac{\|G(\mathcal{L}_{task}, \theta_F)\|^2_2}{\|G(\mathcal{L}_{perceptual}, \theta_F)\|^2_2}\]
각 손실의 기울기 노름 비율로 가중치를 동적으로 조정합니다. 총 손실은 다음과 같습니다.
\[\mathcal{L}_{total} = \mathcal{L}_{C\_KD} + \mathcal{W}_{C\_task} \cdot \mathcal{L}_{out}\]
여기서 \(\mathcal{L}_{out} = \mathcal{L}_{task} + \mathcal{W}_{F\_KD} \cdot \mathcal{L}_{F\_KD} + \mathcal{W}_{perceptual} \cdot \mathcal{L}_{perceptual}\)입니다.
학습 세팅
16개 NVIDIA L40S GPU에서 배치 크기 768, BF16 정밀도로 138K 이터레이션 증류합니다. 이후 Places2(4 GPU, 51K iter), CelebA-HQ(2 GPU, 60K iter), FFHQ(4 GPU, 117K iter)에서 각각 파인튜닝합니다. 옵티마이저는 Muon(weight decay 0.1)을 사용합니다.
결과
효율성 비교
모델 |
파라미터(B) |
TFLOPs |
ms/step |
스텝 수 |
총 시간(s) |
|---|---|---|---|---|---|
Moebius |
0.226 |
0.154 |
26.01 |
20 |
0.52 |
PixelHacker (교사) |
0.862 |
0.338 |
46.89 |
20 |
0.94 |
SD3.5 Large-Inp. |
8.057 |
8.657 |
151.02 |
28 |
4.23 |
FLUX.1-Fill-Dev |
11.902 |
9.927 |
161.01 |
50 |
8.05 |
단일 L40S GPU, 배치 크기 1, 512×512 기준입니다. FLUX.1 대비 총 추론 시간이 \(15 \times\) 이상 빠르며, 파라미터는 2% 미만입니다.
자연 장면 (Places2)
방법 |
Test FID↓ |
Test LPIPS↓ |
Large FID↓ |
Small FID↓ |
Small LPIPS↓ |
|---|---|---|---|---|---|
PixelHacker (교사) |
8.59 |
0.203 |
2.05 |
0.82 |
0.088 |
FLUX.1-Fill-Dev |
8.02 |
0.279 |
1.86 |
0.94 |
0.099 |
SD3.5 Large-Inp. |
37.33 |
0.237 |
10.94 |
3.02 |
0.105 |
MAT |
9.27 |
0.211 |
2.90 |
1.07 |
0.099 |
Moebius |
9.48 |
0.207 |
2.35 |
0.92 |
0.091 |
Moebius는 FLUX.1-Fill-Dev와 비슷하거나 Small 마스크 조건에서 앞섭니다. 가장 중요한 관찰은 SD3.5 Large(8.1B)를 거의 모든 항목에서 크게 능가한다는 점입니다.
인물 장면 (CelebA-HQ / FFHQ)
방법 |
CelebA-HQ FID↓ |
CelebA-HQ LPIPS↓ |
FFHQ FID↓ |
FFHQ LPIPS↓ |
|---|---|---|---|---|
PixelHacker (교사) |
4.75 |
0.115 |
6.35 |
0.229 |
FLUX.1-Fill-Dev |
10.13 |
0.141 |
11.19 |
0.268 |
SD3.5 Large-Inp. |
11.80 |
0.134 |
109.42 |
0.402 |
MAT |
4.86 |
0.125 |
9.04 |
0.232 |
Moebius |
5.39 |
0.122 |
8.15 |
0.231 |
인물 도메인에서 Moebius는 특히 강합니다. FLUX.1-Fill-Dev 대비 CelebA-HQ FID를 88% 개선하고, SD3.5 Large 대비 FFHQ FID를 1,243% 개선합니다.
사용자 연구
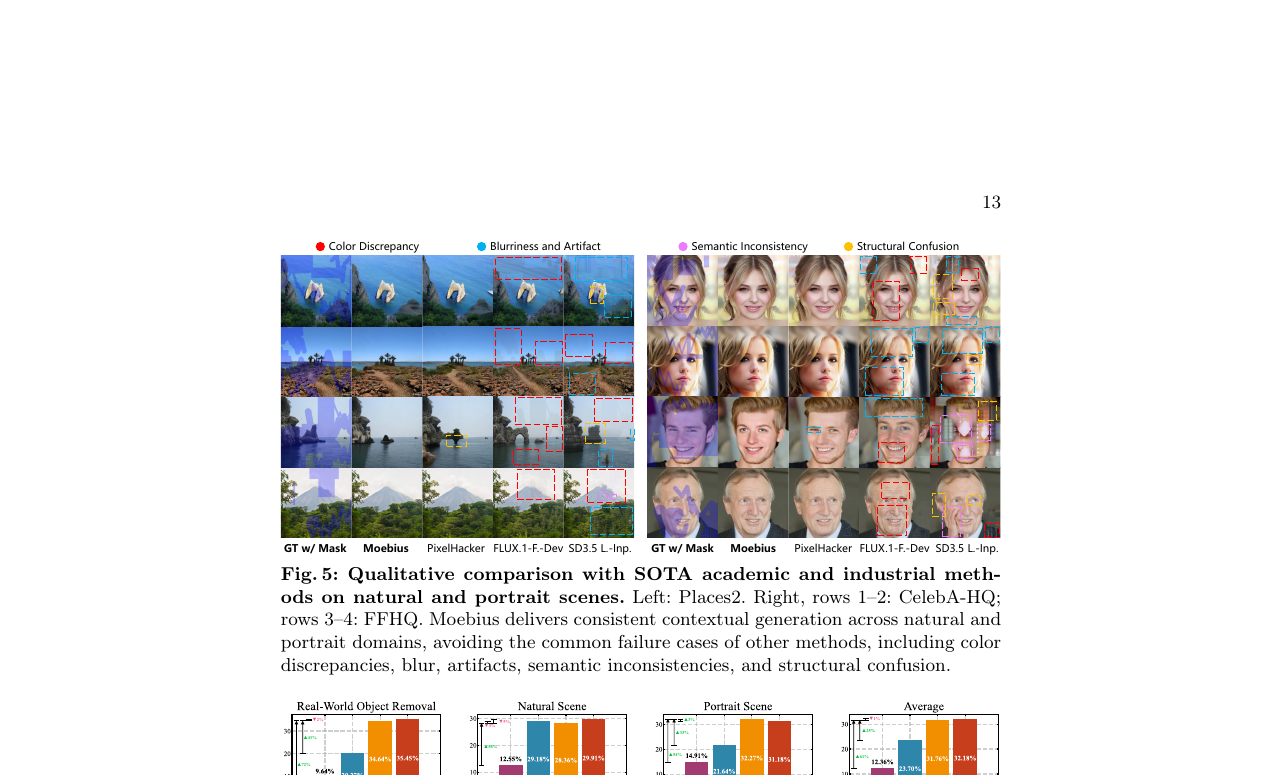
50가지 케이스, 22명(전문가 + 일반인) 이중 맹검 강제 선택 연구 결과입니다.
모델 |
평균 선호율 |
인물 장면 |
|---|---|---|
PixelHacker (교사) |
32.18% |
- |
Moebius |
31.76% |
32.27% |
FLUX.1-Fill-Dev |
23.70% |
- |
SD3.5 Large-Inp. |
12.36% |
- |
Moebius가 인물 장면에서 선호율 1위입니다. 0.22B 모델이 인지적으로 11.9B 모델보다 얼굴을 더 잘 복원한다는 결론입니다.
회고
저자들이 부록(Fig. 11)에서 직접 인정한 한계가 있습니다. 맥락이 극히 제한된 미세 배경 영역에서 교사 모델보다 디테일이 약간 떨어집니다. 0.22B라는 용량의 한계로, "허용 가능한 트레이드오프"라고 표현합니다.
한 가지 짚어볼 전제도 있습니다. Moebius는 Places2, CelebA-HQ, FFHQ에 각각 따로 파인튜닝됩니다. 비교 대상인 FLUX.1-Fill-Dev는 제로샷(zero-shot) 제너럴리스트입니다. 즉, Moebius는 도메인 특화 스페셜리스트이고 FLUX는 범용 모델인 상황에서의 비교입니다. 저자들도 이 사실을 숨기지 않고 "태스크 특화 스페셜리스트"로 포지셔닝하며 논문 전체를 이 프레임 안에서 씁니다. 스페셜리스트가 제너럴리스트를 이긴다는 메시지 자체가 이 논문의 핵심입니다.
또 하나: 파라미터 비교(0.22B vs 11.9B)는 두 모델 모두 VAE 인코더/디코더를 제외한 디노이징 U-Net 기준입니다. 공정한 비교이지만 이 점을 인지하고 읽어야 합니다.
정리
- LλMI 블록: attention 맵 대신 고정 크기 선형 행렬 \(\lambda\)로 공간·시맨틱 컨텍스트를 압축, 선형 복잡도로 추론
- 잠재 공간 다중 입도 증류: 픽셀 디코딩 없이 거친·세밀한 두 스케일에서 교사-학생 정렬, 경사 기반 적응 가중치로 안정화
- 0.22B로 FLUX.1-Fill-Dev(11.9B) 대비 \(>15\times\) 속도, 비슷하거나 더 나은 인페인팅 품질