Improved Large Language Diffusion Models
S. Nie, Q. Min, S. Xu, Z. Huang, Y. Song, Y. Shan, Y. Lin, W. X. Zhao, C. Li, and J.-R. Wen, "Improved Large Language Diffusion Models," arXiv:2606.25331, 2026.
저자
iLLaDA는 Chongxuan Li와 Ji-Rong Wen이 교신저자로 이끄는 중국인민대학교 고링 인공지능학원의 팀이 ByteDance Seed와 함께 만들었습니다. 제1저자 Shen Nie는 ByteDance Seed 인턴십 중 이 작업을 완성했고, Wayne Xin Zhao 교수도 저자 목록에 이름을 올렸습니다. 이 팀은 전작 LLaDA(Large Language Diffusion with mAsking, 2026 NeurIPS)를 발표했고, 이번 iLLaDA는 그 개선판입니다. "비-자기회귀 언어 모델이 GPT 계열을 따라잡을 수 있는가"라는 긴 호흡의 질문에 답하는 시리즈입니다.
배경
현재 LLM의 지배적 패러다임은 자기회귀(autoregressive, AR)입니다. 왼쪽에서 오른쪽으로 토큰을 하나씩 예측하는 인과 어텐션(causal attention) 구조 덕분에 학습과 추론이 효율적이지만, 두 가지 구조적 제약이 있습니다. 첫째, 미래 토큰을 참조할 수 없어 양방향 문맥 이해가 어렵습니다. 둘째, 반복 학습(동일 데이터를 여러 에폭)에서 수렴이 빨라 데이터 효율이 낮습니다.
확산 언어 모델(Diffusion Language Model)은 대안으로 주목받아 왔습니다. 입력을 임의로 마스킹한 뒤 복원하는 마스크드 확산 목표를 쓰고, 완전 양방향 어텐션(fully bidirectional attention)으로 좌우 문맥을 모두 봅니다. LLaDA가 2.3T 토큰 규모에서 비-자기회귀 모델도 핵심 LLM 능력을 습득할 수 있다는 개념 증명을 제시했지만, Qwen2.5 같은 강력한 AR 모델에는 여전히 뒤처졌습니다. iLLaDA는 이 격차가 구조적 한계가 아니라 스케일·학습 레시피의 차이임을 보이려 합니다.
어떻게 만들었나
사전학습
iLLaDA의 마스크드 확산 학습 목표는 LLaDA와 동일합니다. 길이 \(L\)의 클린 시퀀스 \(x_0\)에서 마스킹 비율 \(t \sim \mathcal{U}[0,1]\)를 샘플링하고 각 토큰을 확률 \(t\)로 마스크 토큰 \(M\)으로 대체해 손상 시퀀스 \(x_t\)를 만듭니다. 손실은 마스킹된 위치에서만 계산합니다:
\[\mathcal{L}(\theta) \triangleq -\mathbb{E}_{t, x_0, x_t}\!\left[\frac{1}{t}\sum_{i=1}^L \mathbf{1}[x_t^i = M]\log p_\theta(x_0^i \mid x_t)\right]\]
아키텍처는 LLaDA와 차별화되는 두 가지 변경이 있습니다. 그룹화 쿼리 어텐션(GQA): LLaDA의 MHA(32 KV 헤드)를 GQA(8 KV 헤드)로 대체해 KV 캐시 메모리를 줄입니다. 향후 KV-캐시 스타일 추론이 확산 LLM에도 적용되는 추세에 대비한 선택입니다. 임베딩·LM 헤드 공유: 입력 임베딩과 출력 LM 헤드 파라미터를 묶어 7.62B 파라미터로 LLaDA(8.02B)보다 오히려 작게 유지합니다.
항목 |
iLLaDA 8B |
LLaDA 8B |
|---|---|---|
KV 헤드 |
8 |
32 |
FFN 차원 |
14,336 |
12,288 |
최대 시퀀스 길이 |
8,192 |
4,096 |
임베딩/LM 헤드 |
공유 |
분리 |
총 파라미터 |
7.62B |
8.02B |
사전학습은 12T 토큰(LLaDA 2.3T의 5배 이상)으로 확장했습니다. 손실 정체 시점을 감지해 코사인 감쇠 스케줄로 전환하는 두 단계 학습률 계획도 사용했습니다.
지시문 미세조정
기존 SFT 방식은 프롬프트를 유지하고 응답 부분에만 마스크를 적용합니다. iLLaDA는 이를 바꿔 사전학습과 동일한 방식 — 전체 시퀀스에 랜덤 마스크를 적용합니다. 예시들을 연속으로 이어 붙인 25B 토큰 지시문 코퍼스에서 8,192 토큰 단위로 샘플링하고 12 에폭 학습합니다. 이 형식은 길이 고정 없는 가변 길이 생성을 자연스럽게 지원하는 장점이 있습니다.
추론
가변 길이 블록 생성: 프롬프트 뒤에 마스크 블록을 붙이고 확산 샘플러를 돌립니다. 신뢰도 낮은 위치는 다시 마스킹하고, EOS가 나오면 종료하거나 새 블록을 추가합니다.
신뢰도 기반 채점(다중 선택): 후보 답변 \(y\)에 대해 가장 신뢰도 높은 토큰부터 순차적으로 드러내며 누적 로그 확률로 점수를 산출합니다:
\[S_\text{conf}(y \mid p) = \sum_{k=1}^L \log p_\theta\!\left(y^{i_k} \mid p, \tilde{y}_{k-1}\right), \qquad i_k = \arg\max_{i \in M_{k-1}} p_\theta(y^i \mid p, \tilde{y}_{k-1})\]
이 방식은 정확한 가능도 추정이 아니라 선택지 비교를 위한 순위 결정 프록시입니다.
결과
Base 성능
모델 |
방식 |
학습 토큰 |
MMLU |
BBH |
ARC-C |
GSM8K |
MATH |
HumanEval |
MBPP |
평균 |
|---|---|---|---|---|---|---|---|---|---|---|
LLaDA 8B |
확산 |
2.3T |
65.9 |
49.7 |
45.9 |
70.3 |
31.4 |
35.4 |
40.0 |
51.1 |
Dream 7B |
확산 |
18T+0.6T |
69.5 |
57.9 |
59.8 |
77.2 |
39.6 |
57.9 |
56.2 |
61.4 |
Qwen2.5 7B |
AR |
18T |
71.9 |
63.9 |
51.5 |
78.9 |
41.1 |
56.7 |
63.6 |
63.3 |
iLLaDA 8B |
확산 |
12T |
74.8 |
71.3 |
60.8 |
81.9 |
38.4 |
50.0 |
57.8 |
63.9 |
iLLaDA-Base는 평균 63.9로 Qwen2.5 7B Base(63.3)를 처음으로 앞섰습니다. 특히 BBH(+21.6 vs LLaDA, +7.4 vs Qwen2.5)와 ARC-Challenge(+14.9 vs LLaDA)에서 큰 차이를 보입니다. HumanEval에서는 Dream이 여전히 앞서는데, Dream은 Qwen2.5로 초기화한 뒤 확산으로 파인튜닝했기 때문입니다.
Instruct 성능
모델 |
MMLU |
MMLU-Pro |
MMLU-Redux |
GSM8K |
MATH |
HumanEval |
MBPP |
평균 |
|---|---|---|---|---|---|---|---|---|
LLaDA 8B |
65.5 |
37.0 |
68.9 |
77.5 |
42.2 |
49.4 |
41.0 |
54.5 |
Dream 7B |
67.0 |
43.3 |
76.3 |
81.0 |
39.2 |
55.5 |
58.8 |
60.2 |
Qwen2.5 7B |
76.6 |
56.3 |
75.7 |
91.6 |
75.5 |
84.8 |
79.2 |
77.1 |
iLLaDA 8B |
71.6 |
52.3 |
76.4 |
89.0 |
56.7 |
65.9 |
58.0 |
67.1 |
Instruct 설정에서는 Qwen2.5 7B Instruct(77.1)와 격차가 10포인트 남습니다. 논문은 이 격차의 주된 원인이 Qwen2.5가 SFT 이후에 추가로 RL 정렬을 거쳤기 때문이라고 봅니다. Base에서의 성능 동등함을 고려하면 이 해석은 설득력이 있습니다.
SFT 에폭 절제
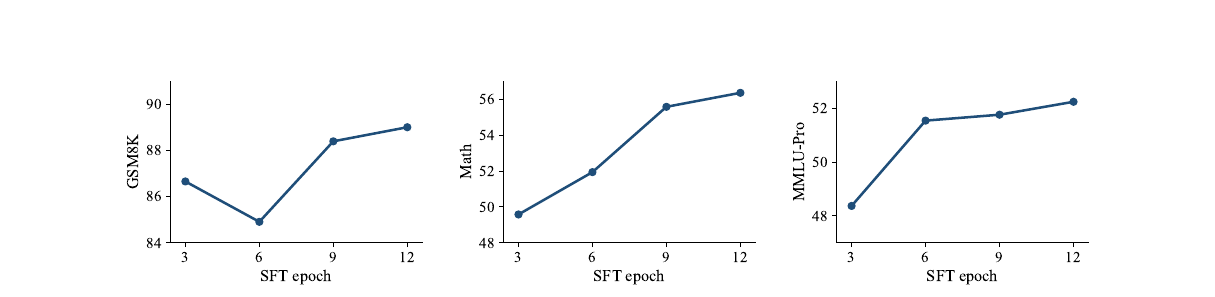
SFT 에폭이 늘수록 성능이 꾸준히 올라갑니다. GSM8K는 6에폭에서 일시 하락이 있지만 9에폭 이후 회복해 12에폭에서 정점에 닿습니다. MATH와 MMLU-Pro는 단조 상승합니다. 확산 언어 모델이 반복 학습에서 수렴이 느리다는 특성이 SFT에도 유효하며, 12에폭으로도 아직 포화 조짐이 없습니다.
신뢰도 기반 채점도 다중 선택 성능을 개선합니다. PIQA에서 가능도 기반 대비 1.3, HellaSwag에서 2.3포인트 높습니다.
회고
논문이 명시하는 한계 두 가지입니다. RL 정렬 미적용: VRPO, diffu-GRPO, MDPO 같은 확산 LLM용 RL 방법이 이미 존재하지만 iLLaDA에는 아직 적용하지 않았습니다. Instruct 격차의 원인으로 지목하면서도 후속 작업으로 남겼습니다. 8B 단일 스케일: 컴퓨팅 제약으로 스케일링 실험이 없어 확산 방식이 더 큰 모델에서도 AR과 경쟁하는지 검증되지 않았습니다.
학습 데이터 구성은 공개되지 않았습니다. 12T 사전학습 코퍼스와 25B 지시문 코퍼스의 출처와 혼합 비율이 없어 재현 가능성이 제한됩니다.
GSM8K의 6에폭 성능 하락(84.5 추정)은 설명 없이 넘어갑니다. 데이터 순서나 배치 구성의 불안정인지, 아니면 체크포인트 선택의 문제인지 명확하지 않습니다.
정리
- 완전 양방향 마스크드 확산 언어 모델도 충분한 스케일(12T 토큰, 25B SFT, 12에폭)이 주어지면 Base 성능에서 Qwen2.5 7B와 동등해집니다. "비-자기회귀 = 성능 열위"는 이제 스케일 전의 이야기입니다.
- 확산 언어 모델은 반복 학습에서 포화가 느립니다. 이는 데이터 희소 환경에서 강점이 됩니다.
- RL 정렬 미적용이 현재의 병목입니다. 이것이 해결되면 Instruct 격차도 상당 부분 좁혀질 가능성이 있습니다.