Learning from the Self-future - On-policy Self-distillation for dLLMs
Y. Luo, Z. Chen, H. Wang, X. Hu, Y. Zhang, Z. Sha, and S. Liu, "Learning from the Self-future: On-policy Self-distillation for dLLMs," arXiv:2606.18195, 2026.
저자
1저자는 칭화대학교의 Yifu Luo와 뮌헨 공과대학교(TU Munich)의 Zeyu Chen이 공동 담당했습니다. 지도교수 겸 교신저자는 ELLIS 튀빙겐과 막스 플랑크 지능 시스템 연구소에 재직 중인 Shiwei Liu입니다. 그는 희소성과 저랭크 근사를 통한 대형 모델 효율화 연구를 이끌어 왔으며, 이번 논문에서는 그 관심사를 dLLM 포스트 트레이닝으로 확장했습니다. 난양공대(NTU), 브리티시 컬럼비아 대학(UBC), UT 오스틴의 연구자들이 함께 참여한 다국적 협업 결과물입니다.
배경
확산 LLM(dLLM, diffusion large language model)은 텍스트를 왼쪽에서 오른쪽으로 순차 생성하는 자기회귀(AR) 모델과 달리, 모든 토큰을 마스킹한 채로 시작해 반복 노이즈 제거(denoising)로 전체 시퀀스를 완성합니다. 이 비자기회귀적 특성 덕분에 임의 순서 생성과 더 빠른 추론 속도가 가능합니다. LLaDA가 그 대표적 모델입니다.
dLLM의 추론 능력을 높이는 포스트 트레이닝 기법으로는 주로 RLVR(강화학습 기반 검증 보상)이 쓰였습니다. diffu-GRPO 같은 시도가 dLLM에도 GRPO를 적용해 수학 추론 정확도를 끌어올렸습니다. 하지만 RLVR은 희소한 결과 보상에 의존하고 계산 비용이 많이 드는 구조적 단점이 있습니다.
AR LLM 세계에서는 이 단점을 극복하는 방법으로 온폴리시 자기증류(OPSD, On-Policy Self-Distillation)가 주목받았습니다. 단일 모델이 교사와 학생을 동시에 수행하면서 자기 생성 경로를 통해 RLVR에 필적하는 성능을 훨씬 적은 스텝으로 달성합니다. 그런데 이 기법은 dLLM에 그대로 쓸 수 없습니다. AR용 OPSD는 정답 등 특권 정보를 프롬프트 앞(prefix) 에 붙여 교사를 구성하는데, dLLM은 왼쪽에서 오른쪽으로만 조건화하지 않기 때문입니다. 게다가 AR용 OPSD의 토큰 수준 KL 발산 감독은 dLLM의 디노이징 메커니즘과도 맞지 않습니다.
방법론
d-OPSD는 두 가지 핵심 아이디어로 이 문제를 풀었습니다.
자기 미래 조건화 (suffix conditioning)
dLLM은 양방향으로 조건화할 수 있습니다. 즉 \(p(\text{prefix}|\text{suffix})\)를 모델링할 수 있습니다. 이 능력을 교사 구성에 활용합니다.
학생은 현재 노이즈 상태 \(y_t\)만 보고 다음 스텝을 예측합니다:
\[y_{\text{student},t} = y_t\]
교사는 동일한 모델이지만, 최종 답변 \(y_0\)에서 일부 토큰을 선택적으로 드러낸 입력을 받습니다:
\[y^i_{\text{teacher},t} = \begin{cases} y^i_0, & \text{if } i \in \mathcal{S}_t \\ y^i_t, & \text{otherwise} \end{cases}\]
\(\mathcal{S}_t\)는 현재 마스킹된 위치에서 무작위로 고른 일부 인덱스입니다. 교사는 "완성된 미래 답변의 일부"를 suffix로 받는 셈이므로, 학생보다 더 나은 예측을 내놓을 수 있습니다. 모델이 10년 후 결과를 알고 오늘로 돌아온 상태로 생각하는 것과 유사합니다.
이 답변은 데이터셋의 참조 정답이 아닙니다. 모델 자신이 온폴리시로 생성한 답변을 그대로 씁니다.
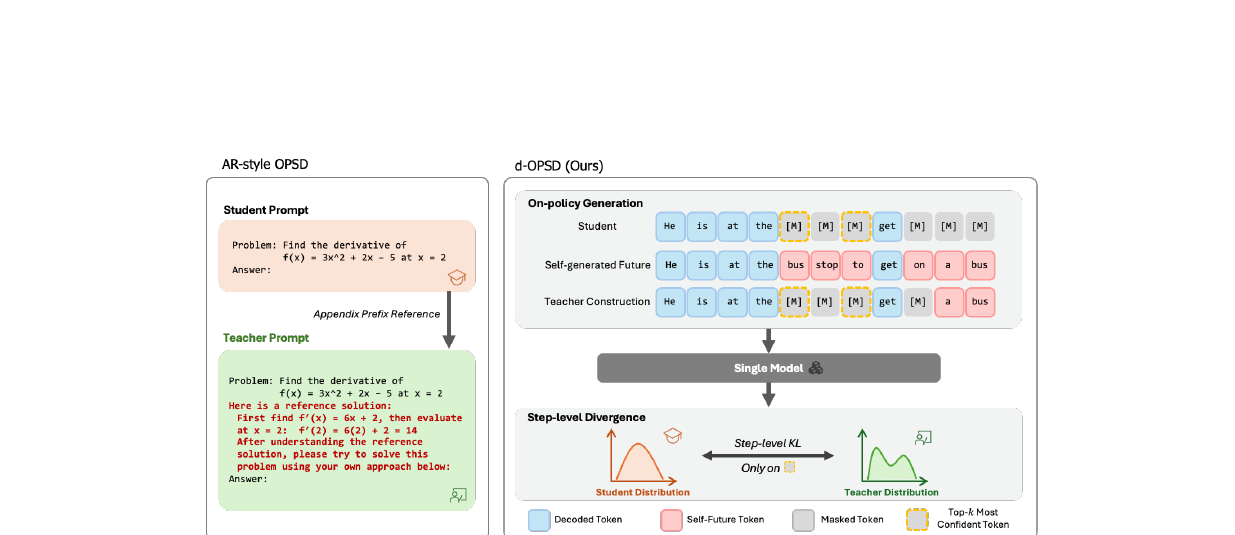
스텝 수준 발산 감독
dLLM의 각 디노이징 스텝에서 모델은 모든 마스킹 위치의 전체 분포를 동시에 계산합니다. 이 중 실제로 상태 전환에 기여하는 것은 top-\(k\)로 가장 확신도가 높은 토큰들입니다. 이 토큰 집합 \(\mathcal{K}_t\)에 대해서만 KL 발산을 계산합니다:
\[\mathcal{L}_t = \frac{1}{|\mathcal{K}_t|} \sum_{i \in \mathcal{K}_t} \mathcal{D}_{\text{KL}}\left(\mathcal{P}^i_{\text{student},t} \| \mathcal{P}^i_{\text{teacher},t}\right)\]
전체 트레이닝 목적함수는 이 스텝 수준 손실의 기대값입니다:
\[\mathcal{L}_{\text{OPSD}}(\theta) = \mathbb{E}_x\left[\frac{1}{T}\sum_{t=1}^T \frac{1}{|\mathcal{K}_t|}\sum_{i \in \mathcal{K}_t} \mathcal{D}_{\text{KL}}\left(p_\theta(y^i|y_{\text{student},t}, x) \| p_\theta(y^i|y_{\text{teacher},t}, x)\right)\right]\]
토큰 수준 감독 대신 스텝 수준 감독을 쓰는 이유는 명확합니다. dLLM은 토큰 하나씩 예측하는 것이 아니라 스텝마다 여러 토큰을 동시에 업데이트하므로, 스텝이 자연스러운 기본 단위입니다.
실용적인 구현 세부 사항도 있습니다. top-\(k\)를 학생 분포 기준이 아닌 교사 분포 기준으로 선택하면 성능이 더 좋았습니다. 교사가 확신하는 위치를 학습하는 것이 더 강한 신호를 제공하기 때문입니다. 추가로 어휘 수준 KL 발산에 pointwise clipping을 적용해 훈련 안정성을 높였습니다.
결과
실험에는 LLaDA-8B-Instruct를 기반 모델로 사용했으며, GSM8K, MATH500, Countdown, Sudoku 네 가지 추론 과제에서 평가했습니다.
성능 비교 (최고 결과 기준)
방법 |
GSM8K |
MATH500 |
Countdown |
Sudoku |
|---|---|---|---|---|
LLaDA-8B-Instruct (기준) |
79.5 |
36.2 |
19.1 |
6.9 |
SFT Variant |
81.1 |
34.8 |
14.5 |
8.5 |
diffu-GRPO (RLVR) |
81.9 |
39.2 |
31.3 |
12.9 |
VRPO (RLVR) |
81.5 |
34.8 |
21.1 |
9.6 |
d-OPSD (Ours) |
82.2 |
37.8 |
32.3 |
20.6 |
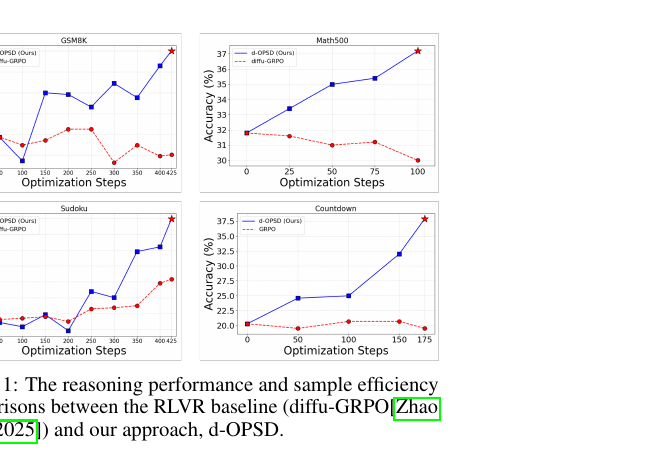
수치가 보여주는 패턴은 뚜렷합니다. Sudoku에서 d-OPSD는 RLVR 최고(diffu-GRPO 12.9) 대비 20.6으로 크게 앞섭니다. Countdown과 GSM8K에서도 최고 성능을 기록했습니다. MATH500에서는 diffu-GRPO의 39.2에 비해 37.8로 약간 낮지만, 이 경우도 SFT를 포함한 다른 기준선을 모두 앞섭니다.
샘플 효율성 비교 (필요한 최적화 스텝 수)
방법 |
GSM8K |
MATH500 |
Countdown |
Sudoku |
|---|---|---|---|---|
diffu-GRPO |
7,700 |
6,600 |
5,000 |
3,800 |
d-OPSD (Ours) |
425 |
100 |
175 |
425 |
샘플 효율성의 차이는 압도적입니다. GSM8K 기준으로 RLVR이 7,700 스텝을 필요로 하는 반면 d-OPSD는 425 스텝으로 수렴합니다. 약 18배 차이입니다. MATH500에서는 100 스텝으로 이미 수렴하니 66배 차이가 납니다.
d-OPSD가 왜 이렇게 효율적인가를 논문은 "교사가 학생에게 새로운 사고 패턴을 전달하기 때문"으로 설명합니다. AR-style OPSD와 비교한 실험이 이를 뒷받침합니다. Overlap Top-\(K_t\) 지표를 정의해 교사와 학생의 top-K 분포가 얼마나 겹치는지 측정했더니, AR-style OPSD는 겹침이 거의 1.0에 달해 교사가 학생에게 새로운 정보를 거의 주지 못한다는 것이 드러났습니다. 반면 d-OPSD의 suffix-based 교사는 적절한 수준의 겹침을 유지해 새로운 사고 패턴을 효과적으로 이전합니다.
회고
논문은 실패 사례를 숨기지 않습니다. RLVR과 마찬가지로 d-OPSD도 정책 붕괴(policy collapse) 가 발생합니다. Countdown 과제에서 훈련 중 성능이 피크를 찍은 뒤 급격히 떨어지는 현상이 관찰됩니다. 저자들은 이를 역KL 발산의 모드 탐색(mode-seeking) 특성이 지나치게 좁아지면서 생기는 문제로 추측하지만, 근본 원인은 아직 열린 문제로 남겨뒀습니다.
몇 가지 가정도 짚어볼 만합니다. pass@k 샘플링으로 정답이 나온 경로만 학습에 씁니다. 학습 효율이 높은 대신, 정답 경로가 전혀 나오지 않는 매우 어려운 문제에서는 교사를 구성할 수 없습니다. 또한 교사 정책을 초기 체크포인트로 고정해야 훈련이 안정된다는 점도 제약입니다. 교사를 함께 업데이트할 경우 성능이 미세하게 감소했습니다.
정리
- dLLM에 처음으로 온폴리시 자기증류를 적용했으며, 핵심은 자기 생성 답변을 suffix 조건으로 활용하는 교사 구성입니다.
- 스텝 수준 KL 감독이 dLLM의 디노이징 특성과 자연스럽게 맞아떨어집니다.
- GSM8K 기준 RLVR 대비 약 18배 적은 스텝으로 더 높은 성능에 도달했으며, 코드는 공개되어 있습니다(github.com/xingzhejun/d-OPSD).