Artificial Hivemind - The Open-Ended Homogeneity of Language Models (and Beyond)
L. Jiang, Y. Chai, M. Li, M. Liu, R. Fok, N. Dziri, Y. Tsvetkov, M. Sap, A. Albalak, and Y. Choi, "Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)," arXiv:2510.22954, 2025.
여러 AI에게 같은 질문을 던져본 적이 있다면, "어, 왜 다 비슷한 말을 하지?"라는 느낌을 받은 적이 있을 겁니다. 이 논문은 그 느낌이 착각이 아님을 2만 6천 개의 질문과 70개 이상의 LLM으로 증명합니다.
저자
장리웨이은 워싱턴 대학교 박사과정 연구자로, 이 논문의 1저자이자 핵심 설계자입니다. 언어 모델의 도덕 추론과 가치 정렬을 오랫동안 연구해온 그가 이번에는 범위를 넓혀 LLM 출력 전체의 다양성 붕괴를 정면으로 다뤘습니다.
교신저자 최예진는 Stanford HAI 교수이자 NVIDIA 수석 연구 과학자입니다. 상식 추론과 AI 가치 평가에서 쌓아온 연구 방향이 이 논문의 핵심 질문과 정확히 겹칩니다. "AI가 정말 다양한 관점을 갖고 있는가"라는 물음은 그의 연구실이 수년째 파고들어 온 문제입니다.
마르턴 삽은 CMU Language Technologies Institute 조교수이자 AI2 AI 안전 수석 연구 과학자로, 소셜 NLP와 AI 편향 진단 분야의 전문가입니다. Jiang과 Choi가 워싱턴 대학교에서 형성한 연구 협업 관계에서 이 논문이 나왔습니다.
배경
LLM의 다양성 문제는 오래전부터 지적돼 왔습니다. 특정 모델이 같은 질문에 비슷한 답을 반복한다는 "intra-model repetition"은 이미 알려진 현상이었습니다. 하지만 기존 연구는 대부분 좁은 설정에 머물렀습니다. 무작위 숫자 생성, 이름 생성, 시 쓰기처럼 실험실에서 설계한 합성 과제만 대상으로 했기 때문입니다.
진짜 문제는 다른 곳에 있었습니다. 실제 사용자들이 AI에게 던지는 질문은 그보다 훨씬 넓고 열려 있습니다. 그리고 모델들이 그런 개방형 질문에서도 서로 비슷한 답을 내놓는지는 제대로 측정된 적이 없었습니다. 특히 서로 다른 회사, 서로 다른 아키텍처의 모델들 사이에서 동질화가 일어나는지는 더더욱 그랬습니다.
앙상블 방법이나 "model swarm"이 다양성을 높인다는 주장도 이 가정 위에 세워져 있습니다. 각 모델이 독립적으로 다른 관점을 제공한다는 전제 말입니다. 이 논문은 그 전제를 테스트합니다.
Infinity-Chat

데이터셋 구축의 출발점은 WildChat입니다. 실제 사용자가 GPT-4에게 보낸 대화 100만 건 중에서 영어, 비유해, 15~200자, 단일 턴 쿼리를 필터링해 37,426개 후보를 추렸습니다. 이를 GPT-4o로 다시 분류해 단일한 정답이 있는 폐쇄형과 여러 유효한 답이 가능한 개방형으로 나눴습니다.
최종적으로 26,070개의 개방형 쿼리와 8,817개의 폐쇄형 쿼리가 남았습니다. 이것이 Infinity-Chat 데이터셋입니다.
taxonomy도 새로 만들었습니다. 100개 쿼리를 수동으로 분류하는 것에서 시작해 반자동으로 확장해 나간 결과, 6개 상위 분류와 17개 세부 분류 체계가 완성됐습니다. Creative Content Generation(58.0%), Alternative Writing Genres(38.5%), Concept Explanation(23.6%), Skill Development(23.5%), Analytical & Interpretive Questions(22.6%), Hypothetical Scenarios(22.2%) 순으로 분포합니다. Brainstorming & Ideation도 15.2%로 의미 있는 비중을 차지합니다. 사용자들이 AI를 아이디어 공급원으로 활용하는 비율이 생각보다 높다는 뜻이고, 이 지점이 동질화 위험과 가장 직접적으로 연결됩니다.
인간 검증도 거쳤습니다. Prolific에서 86명의 참여자가 100개 쿼리를 평가한 결과, 89%가 개방형으로 판정됐고(다수결 기준), 81.3%의 쿼리는 3개 이상의 유효한 답이 가능하다고 봤습니다.
군집 정신
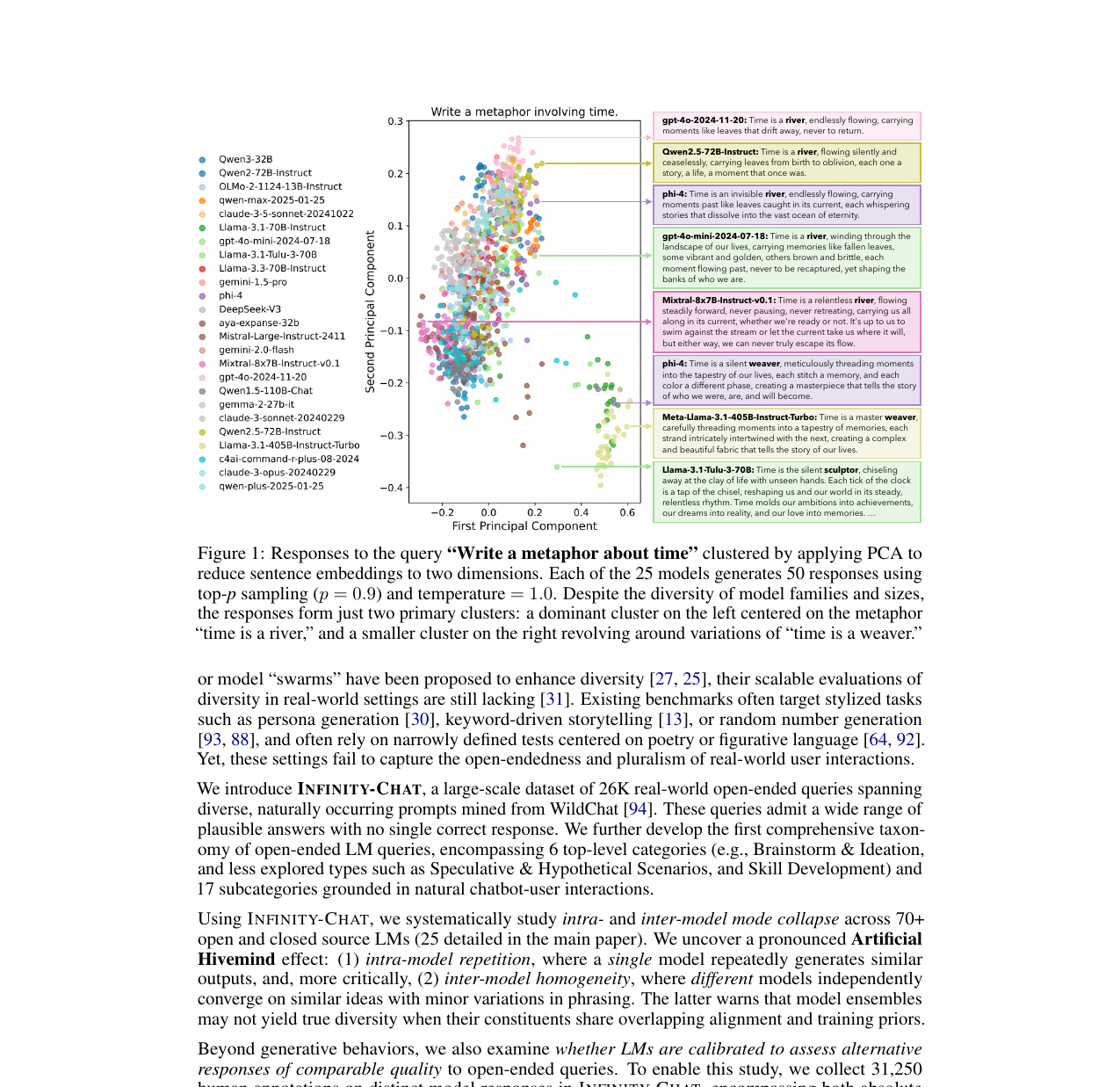
핵심 실험은 25개 모델(70+ LLM 중 주요 모델)에게 Infinity-Chat에서 뽑은 100개 개방형 쿼리를 던지는 것입니다. 각 모델은 쿼리당 50개 응답을 생성했습니다. 샘플링 파라미터는 top-p = 0.9, temperature = 1.0으로 최대한 다양성을 유도하는 설정을 썼습니다.
Intra-model repetition. 같은 모델이 같은 쿼리에 얼마나 비슷한 답을 내놓는가. 응답들 사이의 평균 문장 임베딩 유사도를 계산했더니, 79% 경우에서 평균 유사도가 0.8을 넘었습니다. 비교 기준으로, 무작위로 고른 두 응답은 유사도가 0.1~0.2 범위에 있습니다. "다양하게 뽑힌다"는 확률적 샘플링의 약속이 개방형 질문에서는 지켜지지 않았습니다.
min-p 디코딩은 어떨까요. 이 방법은 모델 자신감에 따라 샘플링 임계를 동적으로 조정해 다양성을 높인다고 알려진 방식입니다. 실험해봤더니 극단적 반복은 줄었지만, 응답 쌍의 81%가 여전히 유사도 0.7 이상, 61.2%가 0.8 이상이었습니다. 디코딩 방법을 바꿔도 근본 문제는 남는다는 뜻입니다.
Inter-model homogeneity. 서로 다른 모델끼리의 응답은 얼마나 다를까. 25개 모델 쌍 사이의 평균 유사도는 71%~82% 범위에 있었습니다. 일부 쌍은 더 높았습니다. DeepSeek-V3와 qwen-max-2025-01-25는 0.82, DeepSeek-V3와 gpt-4o-2024-11-20은 0.81을 기록했습니다. 서로 다른 회사가 만든, 서로 다른 아키텍처의 모델들이 내놓는 답이 80%를 넘는 유사도로 수렴하고 있습니다.
구체적인 예시가 충격적입니다. "Write a metaphor about time"이라는 쿼리에 25개 모델이 각각 50개 응답을 생성했을 때, PCA로 차원 축소한 임베딩 공간에서 두 개의 클러스터만 나타났습니다. 하나는 "time is a river", 다른 하나는 "time is a weaver". 모델 패밀리와 크기를 막론하고 거의 모든 응답이 이 두 표현을 중심으로 몰렸습니다. 어떤 경우에는 서로 다른 모델이 완전히 동일한 문장을 생성하기도 했습니다. qwen-max와 qwen-plus는 소셜 미디어 모토 생성 쿼리에서 "Empower Your Journey: Unlock Success, Build Wealth, Transform Yourself"라는 문장을 토씨 하나 다르지 않게 똑같이 출력했습니다.
상위 N개 가장 유사한 응답들의 출처를 보면, 여러 모델에서 골고루 나왔습니다. N=50으로 잘랐을 때 단일 모델 집중이 아니라 평균 8개 이상의 서로 다른 모델이 섞여 있었습니다. 앙상블의 기본 가정, "서로 다른 모델은 서로 다른 관점을 낸다"가 개방형 질문에서는 성립하지 않습니다.
보상 모델의 한계
논문은 한발 더 나갑니다. 모델들이 비슷한 답을 내놓는 것만이 문제가 아닙니다. 보상 모델(reward model)과 LM judge도 이 문제를 잡아내지 못합니다.
실험 설계는 이렇습니다. Infinity-Chat에서 50개 쿼리를 골라, 각 쿼리마다 15개의 모델 응답을 뽑고, 25명의 인간 평가자가 각 응답에 절대 점수(1~5점)를 매겼습니다. 동시에 쿼리당 10쌍의 응답 비교를 만들어, 역시 25명이 선호도를 평가했습니다. 총 31,250개의 인간 주석이 모였습니다.
이 데이터를 기준으로 LM 퍼플렉시티, 6개 최상위 보상 모델, 4개 LM judge(GPT-4o, Prometheus 변형 등)의 점수와 인간 평가의 Spearman 상관을 계산했습니다. 결과는 두 방향에서 모두 약점을 드러냅니다.
첫째, 유사한 품질의 응답들 사이에서 모델-인간 상관이 크게 떨어집니다. 두 응답이 품질 면에서 비슷할수록 모델들은 어느 쪽이 더 나은지 판별을 못합니다. 현재 보상 모델은 명확하게 더 나은 답을 골라내도록 훈련됐기 때문입니다.
둘째, 인간 평가자들이 서로 의견이 갈리는 응답에서도 상관이 떨어집니다. 저자들은 각 쌍별 비교의 불일치 정도를 다음 식으로 정의합니다.
\[P_{disagree} = 1 - \frac{\max(C_{prefer1}, C_{prefer2}) + 0.5 \cdot C_{tie}}{C_{total}}\]
\(C_{prefer1}\), \(C_{prefer2}\)는 각 응답을 선호한 주석자 수, \(C_{tie}\)는 동점 판정 수, \(C_{total}\)은 전체 주석 수입니다. 이 지표가 높은 응답들, 즉 25명의 평가자들이 선호를 나누는 경우에는 모델들이 인간 판단을 따라가지 못합니다. 개방형 질문에는 "옳은 답"이 없고 개인 취향에 따라 갈리는 경우가 많은데, 이런 다원적 판단을 보상 모델은 반영하지 못하고 있습니다.
회고
저자들이 솔직하게 인정한 한계가 몇 가지 있습니다.
Infinity-Chat은 영어 WildChat에서 만들어졌습니다. 비영어권 사용자의 개방형 쿼리는 다루지 못했고, 따라서 문화적 다양성에 대한 함의는 제한적입니다. 저자들은 동질화 문제가 다른 언어에서도 유사하게 나타날 것으로 예상하지만, 이는 추후 연구로 미뤘습니다.
인과 규명도 미완성입니다. 모델들이 왜 수렴하는지, 원인이 사전학습 데이터인지 RLHF 과정인지 합성 데이터 오염인지 직접 밝히지 못했습니다. 동질화 현상을 기술하는 데는 성공했지만 메커니즘 분석은 다음 연구 과제로 남습니다. taxonomy를 만드는 데 GPT-4o를 사용했고, 인간 주석자와의 일치도가 74.7%였다는 점도 개선 여지로 적어뒀습니다.
다양성에 초점을 두다 보니 응답 품질은 고정 조건에서만 다뤘습니다. 다양성과 품질 사이의 트레이드오프를 탐색하는 것은 별도 연구가 필요합니다.
"and Beyond"가 제목에 붙은 이유도 회고에서 명확해집니다. 저자들이 우려하는 핵심은 모델 출력 다양성에 그치지 않습니다. 여러 모델을 조합해 합성 데이터를 만드는 관행은 각 모델이 독립적인 관점을 갖는다는 전제를 깔고 있습니다. 그런데 이 논문의 데이터는 그 전제가 개방형 과제에서 성립하지 않음을 보여줍니다. RLHF/RLAIF, Constitutional AI 등 앙상블 기반 정렬 방식은 Artificial Hivemind 같은 진단 도구 없이는 동질화를 세대에 걸쳐 강화할 수 있습니다.
정리
- 개방형 질문에서 LLM의 intra-model 반복은 적극적 샘플링(top-p=0.9, t=1.0)으로도 막히지 않습니다. 79% 경우 평균 유사도 > 0.8.
- Inter-model 동질화도 실재합니다. 서로 다른 회사의 모델들이 71~82% 유사한 답을 내놓으며, "앙상블하면 다양해진다"는 가정이 흔들립니다.
- 보상 모델과 LM judge 역시 유사한 품질의 대안 응답들, 또는 인간 의견이 갈리는 응답들을 제대로 평가하지 못합니다. 훈련 파이프라인이 단일한 정답 개념을 전제하기 때문입니다.