ImageNet Classification with Deep Convolutional Neural Networks
도입부
이미지 분류는 컴퓨터 비전의 핵심 문제지만, 2012년까지만 해도 손으로 설계한 특징들에 크게 의존했습니다. 이 논문은 깊은 신경망이 대규모 이미지 데이터에서 자동으로 특징을 학습할 수 있음을 보여주었고, ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)에서 top-5 오류율 15.3%로 2위(26.2%)를 크게 앞지르며 우승했습니다. GPU 병렬 훈련, ReLU 활성화 함수, Dropout 정규화를 결합한 이 접근법은 딥러닝 시대를 열었습니다.
"We trained a large, deep convolutional neural network to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into 1000 different classes." [1]
배경
2012년은 딥러닝 역사에서 가장 결정적인 해입니다. ILSVRC에서 Krizhevsky, Sutskever, Hinton 팀이 GPU로 훈련한 CNN으로 2위를 10%p 이상 압도했습니다. 이 사건이 현대 AI 붐의 기점입니다.
저자 소개
Alex Krizhevsky는 우크라이나 출신 토론토대 박사과정 학생으로 GPU 프로그래밍에 뛰어났습니다. 일리야 수츠케버는 이후 OpenAI 공동 창립자가 되었습니다. Geoffrey Hinton은 이 논문의 성공으로 2013년 Google에 합류했습니다.
요약
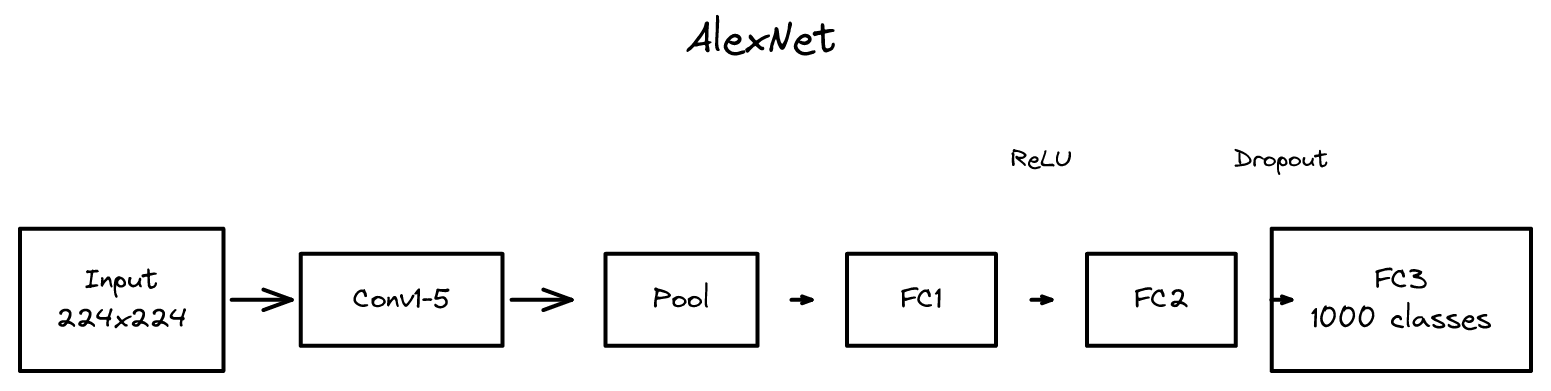
AlexNet은 5개의 합성곱 층과 3개의 완전 연결 층으로 구성된 신경망으로, 약 6천만 개의 파라미터와 65만 개의 뉴런을 포함합니다. 2개의 NVIDIA GTX 580 GPU를 활용한 병렬 훈련으로 6일 내에 학습을 완료했고, 약 120만 개의 이미지로 훈련되었습니다.
핵심 혁신점: - ReLU(정류 선형 단위) 활성화 함수로 훈련 속도 대폭 개선 - Dropout: 훈련 시 뉴런의 50%를 확률적으로 끄는 정규화 기법 - GPU 활용으로 깊은 네트워크 훈련 가능화 - Local Response Normalization (LRN)으로 일반화 성능 향상
논문 상세
배경과 동기
전통적 이미지 분류는 손으로 만든 특징(SIFT, Histograms 등)에 의존했고, 대규모 이미지 분류는 계산 복잡도가 높아 실용적이지 못했습니다. 하지만 ImageNet 데이터셋의 등장과 GPU 기술의 발전이 깊은 신경망 훈련을 현실적으로 만들었습니다.
방법론
아키텍처 설계: 논문에서는 224x224로 명시되어 있습니다 (구현에서는 227x227이 사용되었다고 알려져 있습니다). 입력은 RGB 이미지이며, 11x11 필터(stride 4)부터 시작하여 점진적으로 작은 필터(3x3, stride 1)를 사용합니다. Max-pooling 층은 3x3 윈도우에서 stride 2로 공간 차원을 축소합니다.
학습 기법: - SGD(확률 경사 하강)로 학습률 0.01에서 시작하여 검증 오류가 정체되면 10으로 나눕니다. - Momentum 0.9, 가중치 감소(L2 정규화) 0.0005 - 배치 크기 128, 약 90 에포크 훈련 - 두 개의 GPU에 모델을 나누어 계산을 병렬화합니다.
데이터 증강: - 무작위 crop(227x227) - 수평 반전 - RGB 값의 주성분 분석(PCA) 기반 색상 지터링
결과
ImageNet LSVRC-2010에서 top-1 오류율 37.5%, top-5 오류율 17.0%를 달성했습니다. ILSVRC-2012에서 top-5 오류율 15.3%로 2위(26.2%)를 크게 앞질렀습니다. 신경망의 깊이가 매우 중요함을 보여주었으며, 합성곱 층 하나를 제거하면 top-1 성능이 약 2% 하락합니다.
생각
잘한 점: 이 논문은 단순히 좋은 성능만 낸 게 아니라 왜 깊은 네트워크가 작동하는지 보여주려 노력했습니다. 특징 시각화(feature visualization)를 통해 첫 번째 층은 엣지 같은 저수준 특징을, 깊은 층은 얼굴이나 물체 같은 고수준 개념을 학습한다는 것을 증명했습니다. 또한 ReLU와 GPU 활용이라는 실용적 선택이 이후 표준이 되었습니다.
한계: 결과적으로 AlexNet은 이미지 크기가 작은 것에만 최적화되었고(227x227), 메모리와 계산량이 많아 배포가 어려웠습니다. 또한 하이퍼파라미터 튜닝에 의존하는 경향이 있어 다른 데이터셋으로 일반화하기까지는 상당한 작업이 필요했습니다.
의의: 이 논문은 "딥러닝이 실무에서 작동한다"는 가설을 검증했습니다. 이후 VGGNet, ResNet 등이 계속 성능을 개선했지만, AlexNet의 핵심 통찰—깊이, 비선형성, 정규화의 조합—은 여전히 유효합니다. 126,000회 이상의 인용으로 현대 딥러닝 아키텍처의 기반을 이루었습니다.
참고문헌
[1] A. Krizhevsky, I. Sutskever, and G. E. Hinton, "ImageNet Classification with Deep Convolutional Neural Networks," in Proc. Adv. Neural Information Processing Systems (NeurIPS), 2012.
후속 연구 링크
이 논문의 한계는 Hinton의 이후 연구에서 다루어졌습니다: - 과적합 문제 → Dropout - A Simple Way to Prevent Neural Networks from Overfitting: Dropout의 체계적 분석과 다양한 분야에서의 검증을 수행했습니다 - 모델 배포 어려움 → Distilling the Knowledge in a Neural Network: 지식 증류로 큰 모델을 작은 모델로 압축하는 방법을 제안했습니다