9장 - 종합 정리와 최신 동향
9장. 종합 정리와 최신 동향
트랜스포머는 기계 번역을 위해 태어났지만, 텍스트를 넘어 이미지, 비전-언어, 확산 모델에까지 퍼져 나갔다. 한 분야에서 탄생한 아이디어가 다른 분야로 넘어가 새로운 돌파구를 만드는 것 -- 이 교차 수분(cross-pollination)이야말로 오늘날 AI 연구의 가장 강력한 엔진이다. — 아프신 아미디
9.1 강의 전체 복습
이 장은 CME295 강의의 마지막 회차로, 크게 세 부분으로 구성된다. 첫째, 1장부터 8장까지 다룬 내용을 관통하는 줄기를 짚는다. 둘째, 2025년 현재 가장 활발히 연구되는 최신 동향을 살핀다. 셋째, 앞으로의 방향과 학습 자원을 안내한다.
1장 -- 트랜스포머
텍스트를 원자 단위인 토큰으로 분할하는 것에서 출발했다. 서브워드 토크나이저가 어근 재활용의 이점으로 표준이 되었고, Word2Vec 같은 정적 임베딩의 한계(문맥 무관)를 확인했다. RNN은 문맥을 반영하지만 장거리 의존성 문제가 있었고, 이를 해결한 것이 셀프 어텐션이다. 토큰이 시퀀스 내 위치와 무관하게 서로 직접 연결되어, 쿼리-키-밸류 구조로 가중 평균을 계산한다.
\[\text{Attention}(Q,K,V) = \text{softmax}\!\Bigl(\frac{QK^{\top}}{\sqrt{d_k}}\Bigr)V\]
이 수식은 행렬 연산으로 효율적으로 처리되며, 현대 GPU에 최적화되어 있다. 인코더와 디코더로 구성된 트랜스포머 아키텍처가 번역 과제에서 뛰어난 성능을 보이며 이후 모든 발전의 기반이 되었다. (1장 - 트랜스포머)
2장 -- 트랜스포머 모델과 기법
원래 트랜스포머의 절대 위치 인코딩을 대체하여, 토큰 간 상대 거리를 셀프 어텐션 내부에서 직접 반영하는 **RoPE(Rotary Position Embedding)**가 표준으로 자리 잡았다. **GQA(Grouped Query Attention)**로 키-밸류 투영 행렬을 그룹화하여 연산을 줄이고, 정규화 위치를 서브레이어 뒤(post-norm)에서 앞(pre-norm)으로 옮기는 변화도 있었다. 트랜스포머에서 파생된 세 모델 유형 -- 인코더 전용(BERT, 분류), 디코더 전용(GPT, 텍스트 생성), 인코더-디코더(T5, 텍스트-투-텍스트) -- 을 정리했다. (2장 - 트랜스포머 모델과 기법)
3장 -- 대규모 언어 모델
디코더 전용 트랜스포머를 확장한 것이 LLM이다. 모든 매개변수를 매 순전파마다 활성화할 필요가 없다는 관찰에서 **MoE(Mixture of Experts)**가 등장했다. 피드포워드 층을 여러 전문가로 나누고, 게이팅 메커니즘이 토큰 단위로 일부 전문가만 활성화하여 연산을 희소화한다. 다음 토큰 예측 시 탐욕 디코딩 대신 확률 분포에서 샘플링하며, 온도 하이퍼파라미터로 출력의 다양성을 조절한다. (3장 - 대규모 언어 모델)
4장 -- LLM 훈련
모델이 클수록 성능이 좋아지지만 컴퓨트는 유한하다. Chinchilla 스케일링 법칙에 따르면, \(N\)개의 매개변수를 가진 모델은 최소 \(20N\)개의 토큰으로 훈련해야 한다 -- 예컨대 1,000억 매개변수 모델에는 2조 토큰이 필요하다. Flash Attention은 GPU의 HBM(크고 느림)과 SRAM(작고 빠름) 간 읽기/쓰기를 최소화하되, 중간 결과를 버리고 필요할 때 재계산하는 전략으로 정확한 연산을 유지하면서도 상당한 속도 향상을 달성했다. 데이터 병렬화와 모델 병렬화를 결합하여 다수의 GPU에서 효율적으로 훈련한다. (4장 - LLM 훈련)
5장 -- LLM 튜닝
훈련은 세 단계로 나뉜다. (1) 사전 훈련: 수조 토큰으로 언어 구조를 학습하여 자동 완성 능력을 얻는다. (2) 지도 미세 조정(SFT): 원하는 입출력 쌍으로 행동을 가르친다. (3) 선호도 튜닝: 무엇을 하지 말아야 하는지를 가르친다. Bradley-Terry 공식으로 보상 모델을 쌍별(pairwise) 방식으로 훈련하고, 이를 RL 프레임워크에 연결하여 LLM의 가중치를 인간 선호 방향으로 조정한다. 보상이 불완전하므로 보상 해킹을 방지하기 위해 기본 모델(SFT 모델)에서 너무 벗어나지 않도록 정규화한다. (5장 - LLM 튜닝)
6장 -- LLM 추론
바닐라 LLM이 최종 답 앞에 추론 체인을 출력하도록 가르치면 성능이 향상된다. 이는 연쇄 사고(Chain-of-Thought) 프롬프팅의 아이디어를 RL 훈련으로 내재화한 것이다. GRPO는 PPO와 달리 가치 함수 없이, 여러 완성을 생성한 뒤 보상을 상호 비교하여 이점(advantage)을 계산한다. 수학처럼 검증 가능한 보상이 있는 과제에서는 보상 모델조차 불필요하여, 정책 모델과 참조 모델 두 개만으로 훈련이 가능하다. 원래 GRPO의 정규화 항이 짧은 오답보다 긴 오답을 덜 벌하여 출력 길이가 비대해지는 문제가 있었고, GRPO-Done-Right나 DAPO 같은 확장이 이를 해결한다. (6장 - LLM 추론)
7장 -- 에이전트 LLM
LLM의 지식 컷오프를 넘어서기 위해 **RAG(검색 증강 생성)**를 도입했다. 바이 인코더로 의미 유사도 기반 후보 검색을 수행하고, 크로스 인코더로 재순위화하여 상위 \(K\)개 문서를 프롬프트에 삽입한다. 도구 호출은 LLM이 어떤 API를 어떤 인자로 호출할지 결정한 뒤, 실행 결과를 다시 LLM에 입력하여 최종 답변을 생성하는 2단계 과정이다. RAG와 도구 호출을 결합한 에이전트 워크플로(관찰-계획-행동 루프)가 복잡한 목표를 자율적으로 수행한다. (7장 - 에이전트 LLM)
8장 -- LLM 평가
BLEU, ROUGE 같은 규칙 기반 지표는 표현의 다양성을 반영하지 못한다. 이를 보완하는 LLM-as-a-Judge는 프롬프트, 모델 응답, 평가 기준을 함께 입력받아 근거(rationale)를 먼저 출력한 뒤 점수를 매긴다. 위치 편향, 장황함 편향, 자기 선호 편향 등의 한계가 있으며, 지식, 추론, 코딩, 안전성 등 다차원 벤치마크로 모델 성능을 종합 평가한다. (8장 - LLM 평가)
9.2 비전 트랜스포머(ViT)
트랜스포머는 기계 번역에서 시작하여 다양한 텍스트 과제에서 성공을 거뒀다. 자연스러운 다음 질문은 텍스트가 아닌 입력에도 적용할 수 있는가이다. 셀프 어텐션의 본질을 되돌아보면, 쿼리에 대해 시퀀스 내 다른 요소들(키/밸류)의 관련성을 계산하는 메커니즘이다. 텍스트 토큰은 결국 벡터이므로, 이미지의 일부분을 벡터로 표현할 수만 있다면 동일한 메커니즘을 적용할 수 있다.
아키텍처
2020년에 발표된 **비전 트랜스포머(ViT, Vision Transformer)**는 이 아이디어를 실현했다. 이미지 분류라는 전통적 컴퓨터 비전 과제에 트랜스포머를 적용하되, BERT가 CLS 토큰의 인코딩된 임베딩으로 분류를 수행했듯이 인코더 전용 구조를 채택한다.

ViT의 처리 과정은 다음과 같다.
1단계: 패치 분할. 입력 이미지를 고정 크기의 패치(예: \(16 \times 16\) 픽셀)로 분할한다. \(3 \times 3\) 그리드라면 9개의 패치가 생성된다.
2단계: 평탄화와 선형 투영. 각 패치의 픽셀을 1차원으로 평탄화한다. 각 픽셀은 RGB 3채널 값을 가지므로, \(16 \times 16\) 패치의 경우 \(16 \times 16 \times 3 = 768\)차원의 벡터가 된다. 이를 학습 가능한 선형 투영(linear projection) 층을 통해 모델의 임베딩 차원으로 사영한다. 이 과정은 텍스트에서 토큰 임베딩 테이블이 하는 역할과 동일하다.
3단계: CLS 토큰 추가. BERT와 마찬가지로, 시퀀스 맨 앞에 학습 가능한 CLS 토큰을 추가한다. 이 토큰의 인코딩된 임베딩이 전체 이미지의 표현으로 사용된다.
4단계: 위치 임베딩 합산. 각 패치 임베딩에 위치 임베딩을 더한다. 이미지에서 패치의 공간적 위치 정보를 모델에 제공한다.
5단계: 트랜스포머 인코더 통과. 위치 정보가 포함된 패치 임베딩 시퀀스를 트랜스포머 인코더에 입력한다. 셀프 어텐션을 통해 모든 패치가 서로 상호작용하며 의미 있는 표현을 학습한다.
6단계: CLS 토큰 기반 분류. 인코더를 통과한 CLS 토큰의 임베딩은 모든 패치와 어텐션을 주고받았으므로, 이미지 전체의 정보를 집약하고 있다. 이를 피드포워드 신경망(분류 헤드)에 통과시켜 최종 클래스를 예측한다.
낮은 유도 편향과 데이터 규모
이 결과가 주목할 만한 이유는 **유도 편향(inductive bias)**과의 관계에 있다. CNN은 슬라이딩 윈도우 방식의 합성곱 연산으로 설계되어, 이미지의 국소적 패턴을 우선 포착하도록 강한 유도 편향을 내장하고 있다. 이는 인간이 이미지를 인식하는 방식과 유사하여 비전 과제에 자연스럽다고 여겨져 왔다.
반면 ViT는 이미지의 모든 부분이 서로 어텐션할 수 있도록 허용하여, CNN에 비해 매우 낮은 유도 편향을 갖는다. 국소 패턴에 대한 사전 가정 없이, 데이터로부터 어떤 부분이 중요한지 스스로 학습한다.
ViT 논문이 보여준 핵심 발견은 다음과 같다: 충분한 양의 이미지 데이터로 훈련하면, 낮은 유도 편향의 ViT가 강한 유도 편향의 CNN을 능가한다. 데이터가 적을 때는 CNN의 유도 편향이 유리하지만, 대규모 데이터에서는 ViT의 유연성이 더 강력한 표현을 학습할 수 있게 한다.
9.3 비전-언어 모델(VLM)
ViT로 이미지를 처리할 수 있게 되었다면, 다음 단계는 이미지에 대한 질문에 LLM이 답변하는 것이다. 오늘날 ChatGPT에 이미지를 업로드하고 질문하면 자연어로 답하는 기능이 바로 이 **비전-언어 모델(Vision-Language Model, VLM)**이다. VLM은 이미지 토큰과 텍스트 토큰이라는 두 종류의 입력을 처리해야 한다.
방법 1: 연결(Concatenation) -- LLaVA 방식
가장 보편적인 방법이다. 이미지를 비전 인코더(ViT 등)에 통과시켜 이미지 토큰을 생성한 뒤, 텍스트 토큰과 **연결(concatenate)**하여 디코더 전용 LLM에 입력한다. 모델은 어떤 토큰이 이미지에서 왔고 어떤 토큰이 텍스트에서 왔는지 구분할 수 있는 표현을 학습한다. 이후 자기 회귀 방식으로 답변을 생성한다.
대표적 모델인 LLaVA가 이 구조를 따른다. 비전 인코더의 출력을 선형 투영 층으로 LLM의 임베딩 공간에 사영한 뒤 텍스트 토큰과 이어 붙인다.
방법 2: 교차 어텐션(Cross-Attention) -- Llama 3 방식
덜 일반적이지만 대안이 되는 방법이다. 텍스트 토큰은 일반적으로 디코더에 입력하되, 이미지 토큰은 입력 시퀀스가 아닌 교차 어텐션 층에서 텍스트 토큰과 상호작용한다. 이는 원래 트랜스포머의 인코더-디코더 구조에서 디코더가 인코더 출력을 교차 어텐션으로 참조하는 것과 같은 원리이다. Llama 3의 비전 모델이 이 방식을 채택했다.
방법 |
이미지 토큰 입력 위치 |
대표 모델 |
특징 |
|---|---|---|---|
연결 |
LLM 입력 시퀀스 |
LLaVA |
구현이 단순, 더 보편적 |
교차 어텐션 |
교차 어텐션 층 |
Llama 3 |
텍스트-이미지 분리 유지, 덜 보편적 |
9.4 확산 기반 LLM
지금까지의 LLM은 모두 자기 회귀(auto-regressive) 모델이었다. 입력이 주어지면 다음 토큰을 예측하고, 그 토큰을 다시 입력에 추가하여 그 다음 토큰을 예측하는 과정을 EOS 토큰이 나올 때까지 반복한다.
자기 회귀 모델의 한계
이 패러다임의 근본적 제약은 추론 시 병렬화가 불가능하다는 것이다. 항상 이전 토큰이 있어야 다음 토큰을 예측할 수 있으므로, 출력 길이에 비례하는 순전파 횟수가 필요하다. (훈련 시에는 인과 마스크를 사용하여 모든 위치의 예측을 동시에 계산하므로 병렬화가 가능하다.)
이미지 확산의 핵심 아이디어
이미지 생성 분야에서 **확산 모델(diffusion model)**은 이미 표준이 되어 있다. 그 원리는 다음과 같다.
- 왜 노이즈에서 시작하는가? 이미지는 연속 공간에 존재하며, 픽셀 단위 자기 회귀 생성은 비현실적이다. 가우시안 분포에서 추출한 노이즈는 수학적으로 잘 정의되어 있고, 샘플링이 쉬우며, 무작위성을 자연스럽게 도입하여 다양한 이미지를 생성할 수 있다.
- 순방향 과정(forward process): 깨끗한 이미지에 점진적으로 노이즈를 추가하여 완전한 노이즈로 만든다.
- 역방향 과정(reverse process): 노이즈로부터 제거해야 할 노이즈를 예측하여 원래 이미지를 복원하는 모델을 학습한다.
미켈란젤로의 말을 빌리자면: "조각은 대리석 블록 안에 이미 완성되어 있다. 나는 불필요한 재료를 제거할 뿐이다." 노이즈에서 이미지를 복원하는 과정은 대리석에서 불필요한 부분을 깎아내는 것과 같다.
텍스트로의 적응: 마스크 = 노이즈
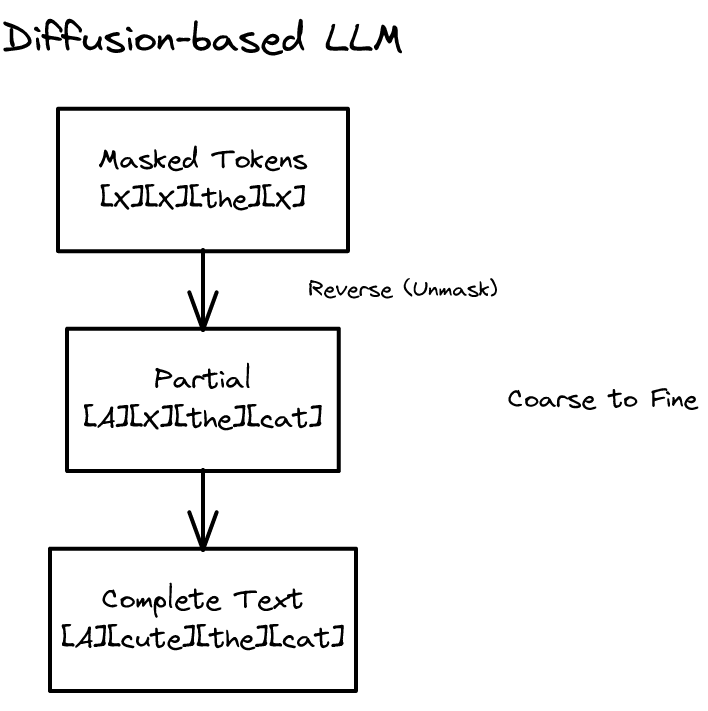
핵심 문제는 **텍스트가 이산적(discrete)**이라는 것이다. 연속 값에 가우시안 노이즈를 더하는 것은 이산 토큰에 적용할 수 없다. 현재 연구가 수렴하고 있는 해법은 다음과 같다.
이미지에서 노이즈가 하는 역할을, 텍스트에서는 마스크 토큰이 한다.
이를 바탕으로 확산 과정을 텍스트에 적응시킨다.
과정 |
이미지 확산 |
텍스트 확산 |
|---|---|---|
순방향 |
깨끗한 이미지 → 점진적 노이즈 추가 → 완전한 노이즈 |
원문 → 점진적 마스킹 → 전부 마스크 토큰 |
역방향 |
노이즈 → 노이즈 제거 → 깨끗한 이미지 |
전부 마스크 → 점진적 언마스킹 → 원문 복원 |
- 순방향(forward): 원문의 토큰을 점진적으로 마스크 토큰으로 대체한다. 마지막에는 시퀀스 전체가 마스크 토큰이 된다.
- 역방향(reverse): 완전히 마스킹된 시퀀스에서 출발하여, 마스크 토큰 뒤에 숨겨진 원래 토큰을 예측하며 점진적으로 언마스킹한다.
실제 추론 시에는 프롬프트가 조건으로 주어진다. 모델은 프롬프트를 참조하면서 마스킹된 응답 부분을 점진적으로 채워 나간다.
MDM과 DLLM
이 패러다임의 모델을 MDM(Masked Diffusion Model) 또는 **DLLM(Diffusion-based LLM)**이라 부른다. 자기 회귀 모델이 한 번에 하나의 토큰을 예측하는 것과 달리, 확산 기반 모델은 매 확산 스텝마다 여러 마스크 토큰을 동시에 예측한다.
관련 논문으로 LaDa(Large Language Diffusion Model with Masking) 등이 이 방향의 수학적 기반을 제시하고 있다.
직관: 거친 것에서 세밀한 것으로
자기 회귀 생성이 왼쪽에서 오른쪽으로 한 단어씩 쓰는 것이라면, 확산 기반 생성은 연설문 작성에 비유할 수 있다. 먼저 전체 구조의 대략적 초안(거친 버전)을 잡고, 점차 각 부분을 정제해 나간다. 확산 모델은 이처럼 거친 것에서 세밀한 것으로(coarse-to-fine) 텍스트를 생성한다. 아직 예측되지 않은 뒤쪽 토큰도 대략적으로 존재하는 상태에서 전체적인 일관성을 고려할 수 있다.
속도 이점과 현재 상태
핵심 이점은 추론 속도이다. 자기 회귀 모델은 출력 토큰 수만큼 순전파가 필요하지만, 확산 모델은 확산 스텝 수만큼만 필요하다. 스텝 수는 사용자가 설정하는 하이퍼파라미터로, 출력 길이보다 훨씬 작다. 스텝이 많을수록 품질이 높아지지만, 일반적으로 출력 토큰 수 대비 극히 적은 스텝으로도 충분한 품질을 달성한다.
일부 벤치마크에서 최대 10배의 추론 속도 향상이 보고되었다. 특히 코딩 과제처럼 여러 번의 모델 호출이 필요하고, 사용자가 낮은 지연 시간을 기대하는 시나리오에서 강력한 이점이 된다.
또한 확산 모델은 텍스트를 전체적으로 고려하므로, 코드 빈칸 채우기(fill-in-the-middle) 같은 과제에 자연스럽게 적합하다. 앞뒤 맥락을 모두 참조하여 중간 부분을 생성하는 것이 자기 회귀 모델보다 구조적으로 유리하다.
현재 확산 기반 LLM의 성능은 최전선 자기 회귀 모델에 근접하고 있으나, 아직 완전히 동등하지는 않다. 추론 체인(reasoning chain) 같은 자기 회귀 모델에 맞게 개발된 기법을 확산 패러다임에 적응시키는 연구가 활발히 진행 중이다. 2025년 Google의 실험적 텍스트 확산 모델(Google I/O 발표)이나 Inception 같은 스타트업의 성과가 이 방향의 잠재력을 보여주고 있다.
9.5 교차 수분: 모달리티 간 기술 이전
트랜스포머의 역사에서 가장 주목할 만한 현상 중 하나는 **교차 수분(cross-pollination)**이다. 한 분야에서 개발된 아이디어가 다른 분야로 넘어가 새로운 돌파구를 여는 것이다.
텍스트 → 이미지: 아키텍처
이미지 생성 분야에서 전통적으로 사용하던 CNN 기반 아키텍처(U-Net 등)를 트랜스포머로 대체한 것이 **DiT(Diffusion Transformer)**이다. 최신 확산 기반 이미지 생성 논문들은 대부분 트랜스포머를 백본으로 사용하며, CNN 대비 더 나은 결과를 보여주고 있다.
이미지 → 텍스트: 입력 표현
DeepSeek OCR 논문은 비전 토큰에서 텍스트 토큰을 복원하는 함수를 학습할 수 있음을 보여주었다. 논문 이름과 달리 OCR 과제 자체의 성능 향상을 주장하는 것이 아니라, 극히 적은 수의 비전 토큰만으로도 텍스트의 의미를 충분히 표현할 수 있음을 입증했다. 이미지 패치가 토큰으로서 갖는 표현력이 매우 강하다는 것이다. 일부 연구자들은 텍스트 토크나이저가 최적의 도구가 아닐 수 있으며, 이모지처럼 패치 하나로 전달할 수 있는 의미를 텍스트 토큰으로는 훨씬 많은 수가 필요하다고 주장한다.
텍스트 → 이미지: 내부 기법
아키텍처뿐 아니라 내부 기법도 이전된다. 텍스트에서 토큰 간 상대 위치를 표현하기 위해 개발된 RoPE가 이미지 분야에서 2D RoPE로 확장되었다. 2차원 격자 위의 패치 위치를 RoPE로 인코딩하고, 텍스트 토큰과 이미지 패치가 동일한 시퀀스에 공존하는 멀티모달 설정에서도 상대 위치 계산이 일관되도록 설계한다.
이러한 교차 수분은 양방향으로 작동한다. 텍스트에서 비전으로, 비전에서 텍스트로, 그리고 추천, 음성 등 더 많은 분야로 확장되고 있다.
9.6 진행 중인 연구: 설계 결정의 최전선
트랜스포머의 연구는 여전히 활발하며, 기본적인 설계 결정조차 확정되지 않았다. 현재 반복적으로 개선되고 있는 주요 영역을 정리한다.
옵티마이저
오랫동안 Adam 옵티마이저가 표준이었으나, Kim K2 논문(2025)이 도입한 Muon 옵티마이저(및 그 변형 Muon-Clip)가 새로운 후보로 떠오르고 있다. 대규모 LLM 훈련에서 Adam을 대체할 잠재력을 보여주며, 이 분야는 여전히 발전 중이다.
정규화
원래 트랜스포머 논문은 서브레이어 뒤에 Layer Norm을 적용했다(post-norm). 현대 LLM은 서브레이어 앞에 적용한다(pre-norm). 그러나 정규화의 위치뿐 아니라 유형도 변화하고 있다. Layer Norm 대신 매개변수가 더 적은 RMSNorm이 널리 채택되었으며, 다른 변형도 연구 중이다. 최적의 정규화 방식은 아직 확립되지 않았다.
활성화 함수
전통적 딥러닝에서 ReLU가 지배적이었으나, LLM 세계에서는 ReLU 계열이지만 정확히 ReLU가 아닌 활성화 함수로 이동했다. GELU(Gaussian Error Linear Unit), SiLU(Swish) 등이 사용되며, 새로운 활성화 함수가 지속적으로 제안되고 있다.
어텐션 변형
GQA가 도입된 이후에도, 어떤 어텐션 구성이 최적인지는 모델마다 다르다. 일부 논문은 특정 층에서는 하나의 어텐션 유형을, 다른 층에서는 다른 유형을 사용한다. 헤드 수, 그룹 크기, 심지어 MoE를 적용하는 층의 수까지 모델마다 상이하며, 하나의 정답이 존재하지 않는다.
FFN 설계와 기타 하이퍼파라미터
FFN의 유닛 수, 층 수, 헤드 수, MoE 적용 여부와 전문가 수 등 모든 하이퍼파라미터가 여전히 논쟁의 대상이다. 각 모델 논문은 자체적인 설계 결정을 내리고 있으며, 통일된 최적 구성은 존재하지 않는다.
9.7 데이터 도전: 합성 오염과 모델 붕괴
초기 LLM은 상대적으로 깨끗한 환경에서 훈련되었다. 인터넷을 스크레이핑하면 대부분 인간이 작성한 텍스트를 얻을 수 있었다. 그러나 2025년 현재 상황은 크게 달라졌다. 검색 엔진의 상위 결과 중 상당 부분이 LLM이 생성한 텍스트로 추정된다.
모델 붕괴(Model Collapse)
LLM이 생성한 텍스트로 다음 세대의 LLM을 훈련하면 어떤 일이 발생하는가? 연구에 따르면, LLM이 생성한 텍스트는 인간 텍스트보다 다양성이 낮다. 이로 인해 훈련 데이터의 분포가 변형되고, 학습의 질이 저하된다. 이 현상을 **모델 붕괴(model collapse)**라 부른다. 세대를 거듭할수록 출력의 다양성이 줄어들고, 원래 인간 언어의 풍부한 분포에서 점점 멀어진다.
대응 전략
이 문제에 대한 대응은 **데이터 큐레이션(data curation)**의 중요성을 부각시켰다. 과거에는 인터넷 전체를 무차별적으로 스크레이핑하여 훈련했지만, 이제는 고품질 데이터를 선별하고 정제하는 작업이 필수가 되었다.
새로운 훈련 패러다임도 등장하고 있다. 기존의 사전 훈련 → 미세 조정 2단계에서, 사전 훈련 → 중간 훈련(mid-training) → 미세 조정 3단계로 확장되었다. 중간 훈련은 여전히 대규모 코퍼스를 사용하지만, 사전 훈련보다 더 높은 품질의 데이터로 수행된다.
9.8 미래 방향
효율성의 파레토 프런티어
지금까지의 연구는 벤치마크 성능의 극대화에 집중했다. 그러나 모든 주요 용례가 해결되는 시점이 오면, 관심은 비용 효율성으로 이동할 것이다. 동일한 성능을 더 적은 연산으로 달성하는 **소형 언어 모델(SLM, Small Language Model)**의 부상이 이 추세를 반영한다.
하드웨어 혁신
현재 LLM 훈련에 사용되는 GPU는 행렬 곱셈에 최적화되어 있지만, 트랜스포머는 \(QK^{\top}\) 연산, 소프트맥스 등 행렬 곱셈 이외의 연산도 많이 필요로 한다. Flash Attention이 메모리 이동을 최적화한 것은 현재 하드웨어의 한계를 우회한 것이다. 2025년 9월 발표된 한 논문은 아날로그 신호의 물리적 특성(키르히호프 법칙 등)을 활용하여 어텐션 연산을 하드웨어 자체에 내장하는 개념 증명을 제시했다. 입력 값을 펄스로 시뮬레이션하고, 물리적 특성이 연산을 수행하여 결과를 읽어내는 방식으로, 지연 시간과 에너지 소비 모두에서 상당한 개선을 보였다.
에이전트 민주화와 웹 브라우징
에이전트 워크플로가 현재는 기술 전문가들에게 국한되어 있지만, 자연어만으로 에이전트를 구성하는 민주화가 진행 중이다. LLM이 웹을 자연스럽게 탐색하는 AI 브라우징 시나리오가 현실화되고 있으며(ChatGPT의 Atlas 등), 보안 과제(프롬프트 주입, 데이터 유출)를 해결하기 위한 새로운 인증 체계가 필요하다.
근본적 한계
아키텍처 자체가 최선인지 여전히 열린 질문이다. 지속적 학습(가중치 고정 후 변하지 않는 문제), 환각(다음 토큰 예측이라는 설계상 사실 대응이 아닌 점), 개인화, 해석 가능성, 안전성 등의 도전이 남아 있다.
핵심 정리
개념 |
핵심 |
|---|---|
전체 복습 |
토큰화 → 셀프 어텐션 → 트랜스포머 → LLM → 훈련 → 튜닝 → 추론 → 에이전트 → 평가의 흐름 |
ViT |
이미지 → 패치 → 평탄화 → 선형 투영 → 위치 임베딩 → 인코더 → CLS → 분류 |
유도 편향 |
ViT는 CNN보다 낮은 유도 편향이지만, 충분한 데이터로 CNN을 능가 |
VLM (연결) |
이미지 토큰 + 텍스트 토큰을 이어붙여 LLM에 입력 (LLaVA) |
VLM (교차 어텐션) |
이미지 토큰을 교차 어텐션 층에서 텍스트와 상호작용 (Llama 3) |
확산 기반 LLM |
마스크 토큰 = 노이즈. 순방향: 점진적 마스킹, 역방향: 점진적 언마스킹 |
MDM / DLLM |
여러 토큰을 동시 예측. 확산 스텝 수 ≪ 출력 길이 → 최대 10배 속도 향상 |
교차 수분 |
DiT(텍스트→이미지), 2D RoPE, DeepSeek OCR(이미지→텍스트) |
옵티마이저 |
Adam → Muon(Muon-Clip)이 새 후보. 아직 확정되지 않은 영역 |
정규화 |
post-norm → pre-norm, Layer Norm → RMSNorm. 여전히 진화 중 |
활성화 함수 |
ReLU → GELU, SiLU 등. LLM 전용 최적 함수 탐색 중 |
모델 붕괴 |
LLM 생성 텍스트로 훈련 시 다양성 저하. 데이터 큐레이션과 중간 훈련으로 대응 |
미래 방향 |
SLM, 아날로그 하드웨어, 에이전트 민주화, 지속적 학습 |
이로써 CME295 시리즈 전체를 마무리한다. 1장에서 텍스트를 토큰으로 분할하는 것에서 출발하여, 셀프 어텐션과 트랜스포머 아키텍처를 이해하고, 대규모 언어 모델의 훈련, 튜닝, 추론, 에이전트 활용, 평가를 거쳐, 마지막으로 비전 트랜스포머와 확산 기반 LLM까지 살펴보았다. 트랜스포머는 2017년 기계 번역을 위해 탄생했지만, 텍스트를 넘어 이미지, 음성, 추천 등 거의 모든 영역으로 확산되었다. 옵티마이저, 정규화, 활성화 함수 같은 기본적인 설계 결정조차 여전히 진화하고 있으며, 데이터 품질, 하드웨어, 에이전트 민주화 등 새로운 도전이 끊임없이 등장하고 있다. 이 시리즈가 트랜스포머와 LLM의 전체 그림을 이해하는 토대가 되어, 앞으로 쏟아질 새로운 논문과 기술을 주체적으로 소화하는 데 도움이 되기를 바란다.