1장 - 트랜스포머
1장. 트랜스포머
트랜스포머는 자연어 처리의 판도를 완전히 바꾸어 놓았다. 순환 신경망이 단어를 하나씩 순차적으로 처리하던 시대에서, 모든 단어가 동시에 서로를 참조하는 시대로의 전환이다. 이 강의에서 우리는 그 여정을 처음부터 끝까지 따라갈 것이다. — 아프신 아미디
1.1 자연어 처리 개요
자연어 처리(Natural Language Processing, NLP)란 인간의 언어를 컴퓨터가 이해하고 생성할 수 있도록 하는 인공지능의 한 분야다. 텍스트 데이터를 입력으로 받아 유용한 출력을 생성하는 모든 과제가 NLP의 범주에 속한다.
NLP의 과제는 크게 세 가지로 분류할 수 있다.
분류 (Classification)
입력 텍스트를 미리 정해진 하나의 범주에 배정하는 과제다. 출력은 단일 레이블이다.
- 감정 분석: 영화 리뷰가 긍정적인지 부정적인지 판별한다. ("이 영화 정말 재미있었다" → 긍정)
- 스팸 탐지: 이메일이 스팸인지 아닌지 분류한다.
- 유해 콘텐츠 감지: 소셜 미디어 게시글이 혐오 발언, 괴롭힘, 위협 등에 해당하는지 판별한다.
분류 과제의 대표적 데이터셋으로는 IMDB 영화 리뷰 데이터셋, SST(Stanford Sentiment Treebank) 등이 있다.
다중 분류 (Multi-class Classification)
입력 텍스트의 각 토큰 또는 구간에 레이블을 부여하는 과제다. 출력은 입력과 동일한 길이의 레이블 시퀀스다.
- 개체명 인식(NER): 문장에서 인물, 조직, 장소 등의 고유명사를 식별하고 분류한다. ("스탠퍼드 대학교에서 공부한다" → [조직, 조직, O, O])
- 품사 태깅(POS Tagging): 각 단어의 품사를 결정한다. (명사, 동사, 형용사 등)
생성 (Generation)
입력 텍스트로부터 새로운 텍스트를 생성하는 과제다. 출력의 길이가 입력과 다를 수 있다.
- 기계 번역: 한 언어의 문장을 다른 언어로 변환한다. ("I love you" → "나는 너를 사랑한다")
- 텍스트 요약: 긴 문서의 핵심 내용을 짧게 요약한다.
- 질의 응답: 주어진 질문에 대해 적절한 답변을 생성한다.
대표적 데이터셋으로는 WMT(Workshop on Machine Translation) 번역 데이터셋, CNN/DailyMail 요약 데이터셋, SQuAD 질의응답 데이터셋 등이 있다.
평가 지표
NLP 과제의 성능을 측정하는 지표는 과제 유형에 따라 다르다.
분류 과제의 지표:
지표 |
정의 |
설명 |
|---|---|---|
정확도 (Accuracy) |
전체 예측 중 맞은 비율 |
가장 직관적이나 클래스 불균형 시 오도할 수 있다 |
정밀도 (Precision) |
양성 예측 중 실제 양성 비율 |
"양성이라고 했을 때 얼마나 믿을 수 있는가" |
재현율 (Recall) |
실제 양성 중 양성으로 예측한 비율 |
"실제 양성을 얼마나 잘 잡아내는가" |
F1 점수 |
정밀도와 재현율의 조화 평균 |
두 지표의 균형을 하나의 숫자로 표현 |
클래스 불균형 문제는 분류 과제에서 빈번하게 발생한다. 예를 들어 스팸 탐지에서 전체 이메일의 99%가 정상이고 1%만 스팸이라면, 모든 이메일을 "정상"으로 예측하는 모델도 정확도 99%를 달성한다. 그러나 이 모델은 스팸을 단 하나도 잡아내지 못하므로 쓸모가 없다. 이런 상황에서는 정확도 대신 정밀도, 재현율, F1 점수를 사용해야 한다.
생성 과제의 지표:
지표 |
용도 |
설명 |
|---|---|---|
BLEU |
번역 |
생성된 텍스트와 참조 텍스트의 n-gram 일치 비율. 정밀도 기반 |
ROUGE |
요약 |
참조 텍스트의 n-gram이 생성 텍스트에 얼마나 포함되었는지. 재현율 기반 |
퍼플렉시티 (Perplexity) |
언어 모델 |
모델이 다음 토큰을 얼마나 잘 예측하는지 측정. 낮을수록 좋다 |
퍼플렉시티는 직관적으로 "모델이 다음 단어를 예측할 때 평균적으로 몇 개의 선택지 사이에서 혼란을 느끼는가"로 해석할 수 있다. 퍼플렉시티가 10이라면, 모델이 매 단계마다 10개의 단어 사이에서 고민하는 것과 같다.
1.2 토큰화
컴퓨터, 특히 신경망 모델은 문자열을 직접 처리할 수 없다. 모델이 이해하는 것은 오직 숫자다. 따라서 텍스트를 숫자로 변환하는 과정이 필요하며, 이 과정의 첫 단계가 토큰화(Tokenization)다. 토큰화란 텍스트를 의미 있는 단위(토큰)로 분할하고, 각 토큰에 고유한 정수 인덱스를 부여하는 작업이다.
토큰화에는 네 가지 접근법이 있으며, 각각 장단점이 뚜렷하다.
임의 분할 (Arbitrary)
텍스트를 아무 규칙 없이 임의의 길이로 분할하는 방법이다. 의미적 단위를 고려하지 않으므로 실용적이지 않으며, 실제로 사용되지 않는다. 오직 비교를 위한 기준선으로만 언급된다.
단어 수준 (Word-level)
공백과 구두점을 기준으로 텍스트를 분할한다. 가장 직관적인 방법이다.
"I love natural language processing"
→ ["I", "love", "natural", "language", "processing"]
→ [42, 1057, 893, 512, 2341]
장점: 각 토큰이 의미를 가진다. 사람이 직관적으로 이해할 수 있다.
단점: 어휘 크기가 매우 커진다. 영어만 해도 수만 개의 단어가 필요하며, 다국어를 포함하면 수십만 개에 달한다. 또한 미등록 단어(OOV, Out-of-Vocabulary) 문제가 발생한다. 훈련 데이터에 없던 단어가 등장하면 모델이 처리할 수 없다. 이를 해결하기 위해 미등록 단어를 UNK(Unknown) 토큰으로 대체하지만, 이는 정보 손실을 의미한다.
서브워드 수준 (Subword-level)
단어를 더 작은 의미 단위로 분할한다. 현대 대부분의 언어 모델이 채택하는 방식이다. BPE(Byte Pair Encoding), WordPiece, SentencePiece 등의 알고리즘이 여기에 해당한다.
"unhappiness"
→ ["un", "happi", "ness"]
장점: 어휘 크기를 적절히 제한하면서도 OOV 문제를 대폭 줄인다. 처음 보는 단어도 알려진 서브워드의 조합으로 표현할 수 있다. 어휘 크기는 보통 영어의 경우 수만 개, 다국어 모델은 수십만 개 수준이다.
단점: 토큰이 항상 직관적인 의미 단위와 일치하지는 않는다.
문자 수준 (Character-level)
텍스트를 개별 문자로 분할한다.
"cat"
→ ["c", "a", "t"]
장점: 어휘 크기가 매우 작다 (영어의 경우 수십 개). OOV 문제가 원천적으로 없다.
단점: 시퀀스가 매우 길어져 계산 비용이 급증한다. 개별 문자만으로는 의미를 파악하기 어렵다. 모델이 문자 조합에서 단어의 의미를 재구성해야 하므로 학습 난이도가 높다.
토큰화 전략 비교
접근법 |
어휘 크기 |
OOV 문제 |
시퀀스 길이 |
의미 단위 |
|---|---|---|---|---|
단어 수준 |
매우 큼 (수만~수십만) |
심각 |
짧음 |
명확 |
서브워드 수준 |
중간 (수만) |
거의 없음 |
중간 |
대체로 명확 |
문자 수준 |
매우 작음 (수십) |
없음 |
매우 김 |
불명확 |
1.3 단어 표현
토큰화를 통해 텍스트를 정수 인덱스의 시퀀스로 변환했다. 그러나 정수 인덱스만으로는 단어 간의 의미적 관계를 표현할 수 없다. "고양이"가 42번이고 "개"가 1057번이라고 해서, 이 두 숫자의 관계가 "고양이"와 "개"의 의미적 유사성을 반영하지는 않는다. 단어의 의미를 수학적으로 표현하는 방법이 필요하다.
원-핫 인코딩 (One-Hot Encoding)
가장 단순한 방법은 각 단어를 어휘 크기 V와 동일한 길이의 벡터로 표현하되, 해당 단어의 인덱스 위치만 1이고 나머지는 모두 0인 벡터로 만드는 것이다.
어휘가 {"나는", "너를", "사랑", "한다", "좋아", "한다"} (V=6)라면:
"나는" → [1, 0, 0, 0, 0, 0]
"너를" → [0, 1, 0, 0, 0, 0]
"사랑" → [0, 0, 1, 0, 0, 0]
문제점: 모든 원-핫 벡터는 서로 **직교(orthogonal)**한다. 임의의 두 단어의 코사인 유사도가 항상 0이다.
코사인 유사도는 두 벡터 사이의 각도를 기반으로 유사성을 측정하는 방법이다.
cos(A, B) = (A · B) / (‖A‖ × ‖B‖)
원-핫 벡터끼리의 내적은 항상 0이므로, 코사인 유사도도 항상 0이다. 이는 "고양이"와 "개"의 유사도가 "고양이"와 "비행기"의 유사도와 동일하다는 뜻이다. 모든 단어가 의미적으로 무관하게 취급되므로, 언어의 의미 구조를 전혀 포착하지 못한다.
또한 어휘 크기가 커지면 벡터의 차원도 함께 커져 메모리와 계산 비용이 급증한다. 어휘 크기가 5만이면 각 단어를 5만 차원 벡터로 표현해야 한다.
Word2Vec (2013)
Word2Vec은 Mikolov 등이 2013년에 제안한 방법으로, 단어를 **저차원의 밀집 벡터(dense vector)**로 표현한다. 핵심 아이디어는 "비슷한 문맥에서 등장하는 단어는 비슷한 의미를 가진다"는 **분포 가설(distributional hypothesis)**이다.
Word2Vec에는 두 가지 훈련 방식이 있다.
CBOW (Continuous Bag of Words): 주변 단어들로부터 중심 단어를 예측한다. 예를 들어 "나는 ___ 먹는다"에서 빈칸에 올 단어를 주변 단어("나는", "먹는다")로부터 예측한다.
Skip-gram: 중심 단어로부터 주변 단어를 예측한다. "밥을"이 주어지면 이 단어의 주변에 나타날 법한 단어들("나는", "먹는다")을 예측한다.
이 두 방식 모두 **프록시 과제(proxy task)**의 개념을 사용한다. 최종 목적은 좋은 단어 벡터를 얻는 것이지, 실제로 주변 단어를 예측하는 것이 아니다. 예측 과제는 의미 있는 임베딩을 학습하기 위한 수단일 뿐이다.
신경망 구조
Word2Vec의 신경망은 매우 단순한 구조를 가진다.
입력층 (V차원) → 은닉층 (D차원) → 출력층 (V차원) → softmax
- 입력층: 원-핫 인코딩된 단어 벡터 (V차원)
- 은닉층: 저차원 임베딩 벡터 (D차원, 보통 100~300)
- 출력층: 어휘 전체에 대한 확률 분포 (V차원)
- softmax: 출력을 확률 분포로 변환
입력층에서 은닉층으로의 가중치 행렬 W₁의 크기는 V×D이고, 은닉층에서 출력층으로의 가중치 행렬 W₂의 크기는 D×V다. 훈련이 끝나면 W₁의 각 행이 해당 단어의 임베딩 벡터가 된다.
구체적 예시
어휘 크기 V=6, 임베딩 차원 D=2인 간단한 경우를 생각하자.
훈련 후 각 단어는 2차원 벡터로 표현된다. 예를 들어:
"고양이" → [2.0, 1.9]
"개" → [2.1, 1.8]
"자동차" → [8.0, 0.4]
"트럭" → [8.2, 0.3]
2차원 공간에 이 벡터들을 그려보면, "고양이"와 "개"는 서로 가까이 위치하고, "자동차"와 "트럭"도 서로 가까이 위치한다. 반면 동물 그룹과 차량 그룹은 멀리 떨어져 있다. 원-핫 인코딩에서는 불가능했던 의미적 관계가 벡터 공간에 자연스럽게 부호화된 것이다.
훈련 과정
훈련에는 **교차 엔트로피 손실(cross-entropy loss)**을 사용한다. 모델의 출력 확률 분포와 실제 정답 분포 사이의 차이를 측정하는 함수다.
L = -Σ yᵢ log(ŷᵢ)
여기서 yᵢ는 실제 정답의 원-핫 벡터이고, ŷᵢ는 모델의 예측 확률이다. 역전파(backpropagation) 알고리즘으로 손실을 최소화하는 방향으로 가중치를 갱신한다.
의미적 산술
Word2Vec의 가장 유명한 특성은 단어 벡터 간의 산술 연산이 의미적 관계를 반영한다는 점이다.
king - man + woman ≈ queen
"왕"에서 "남성"의 의미를 빼고 "여성"의 의미를 더하면 "여왕"에 가까운 벡터가 나온다. 이는 벡터 공간에서 "남성→여성" 방향이 일관되게 부호화되었음을 의미한다.
한계: 문맥 독립적 임베딩
Word2Vec의 근본적인 한계는 각 단어에 단 하나의 벡터만 할당된다는 점이다. "bank"라는 단어는 "은행"과 "강둑"이라는 완전히 다른 의미를 가지지만, Word2Vec에서는 두 의미가 하나의 벡터로 뭉뚱그려진다.
"I went to the bank to deposit money." → bank = [3.1, 2.4]
"I sat on the bank of the river." → bank = [3.1, 2.4] (동일!)
이를 **문맥 독립적 임베딩(context-independent embedding)**이라 하며, 동음이의어를 구별하지 못하는 심각한 제약이다. 이 문제를 해결하려면 문맥에 따라 임베딩이 달라지는 방법이 필요하다. 바로 이 필요가 이후 순환 신경망과 트랜스포머로 이어진다.
1.4 순환 신경망 (RNN)
동기
Word2Vec은 개별 단어의 의미를 벡터로 표현하는 데 성공했지만, 단어의 순서와 문맥을 고려하지 못한다. "고양이가 개를 쫓았다"와 "개가 고양이를 쫓았다"는 완전히 다른 의미이지만, Word2Vec 임베딩을 단순히 평균내면 동일한 벡터가 된다. 문장의 의미를 파악하려면 단어들이 어떤 순서로 등장하며, 이전 단어들이 이후 단어의 해석에 어떤 영향을 미치는지를 반영해야 한다.
*순환 신경망*(Recurrent Neural Network, RNN)은 이 문제를 해결하기 위해 고안된 아키텍처다.
은닉 상태 메커니즘
RNN의 핵심은 **은닉 상태(hidden state)**다. 입력 시퀀스의 각 시간 단계(time step)에서 RNN은 다음 두 가지를 입력으로 받는다:
- 현재 시간 단계의 입력 xₜ (현재 단어의 임베딩)
- 이전 시간 단계의 은닉 상태 hₜ₋₁ (지금까지 읽은 문맥의 요약)
이 둘을 결합하여 현재 시간 단계의 은닉 상태 hₜ를 생성한다.
hₜ = f(W_h · hₜ₋₁ + W_x · xₜ + b)
은닉 상태는 시퀀스를 처리하면서 누적되는 "기억"과 같다. 첫 번째 단어를 읽으면 h₁이 생기고, 두 번째 단어를 읽을 때 h₁과 x₂를 결합하여 h₂가 만들어진다. 이런 식으로 마지막 단어까지 처리하면, 최종 은닉 상태에 전체 문장의 정보가 압축된다.
과제별 활용
RNN은 세 가지 NLP 과제 모두에 활용할 수 있다.
분류: 전체 시퀀스를 처리한 후 최종 은닉 상태 hₙ을 분류기에 통과시킨다. 예를 들어 감정 분석에서는 리뷰 전체를 읽은 후의 은닉 상태를 긍정/부정으로 분류한다.
다중 분류: 매 시간 단계의 은닉 상태 hₜ를 개별적으로 분류기에 통과시킨다. 개체명 인식에서는 각 단어 위치의 은닉 상태를 사용하여 해당 단어의 개체명 태그를 예측한다.
생성: 인코더-디코더 구조를 사용한다. 인코더 RNN이 입력 시퀀스를 처리하여 문맥 벡터를 생성하고, 디코더 RNN이 이 문맥 벡터로부터 출력 시퀀스를 한 토큰씩 생성한다.
문제점
RNN에는 두 가지 심각한 문제가 있다.
소멸 그래디언트(Vanishing Gradient): 역전파 과정에서 그래디언트가 시간 단계를 거슬러 올라갈 때마다 가중치 행렬이 반복적으로 곱해진다. 이를 직관적으로 이해하려면, 0.9를 100번 곱하면 0.9¹⁰⁰ ≈ 0.0000265가 되는 것을 생각하면 된다. 1보다 작은 값을 반복적으로 곱하면 급격히 0에 수렴한다. 따라서 시퀀스가 길어지면 초기 단어에 대한 그래디언트가 거의 0이 되어, 먼 과거의 정보를 학습에 반영할 수 없게 된다.
느린 순차 처리: RNN은 본질적으로 순차적이다. hₜ를 계산하려면 hₜ₋₁이 필요하고, hₜ₋₁을 계산하려면 hₜ₋₂가 필요하다. 시퀀스의 모든 시간 단계를 하나씩 차례로 처리해야 하므로, GPU의 병렬 처리 능력을 활용할 수 없다. 시퀀스 길이가 n이면 최소 n번의 순차적 연산이 필요하다.
LSTM
*장단기 기억 네트워크*(Long Short-Term Memory, LSTM)는 소멸 그래디언트 문제를 완화하기 위해 고안되었다. 핵심 아이디어는 은닉 상태 외에 별도의 **셀 상태(cell state)**를 추가하는 것이다. 셀 상태는 컨베이어 벨트처럼 정보를 장거리로 전달할 수 있으며, 게이트(gate) 메커니즘을 통해 어떤 정보를 기억하고 어떤 정보를 잊을지 제어한다.
LSTM은 소멸 그래디언트 문제를 상당히 개선했지만, 근본적으로 해결하지는 못했다. 또한 순차 처리라는 한계는 여전히 남아 있다. 시퀀스의 각 시간 단계를 병렬로 처리할 수 없다는 구조적 제약은 LSTM에서도 동일하다.
1.5 어텐션 메커니즘 (2014)
핵심 아이디어
2014년 Bahdanau 등이 제안한 어텐션 메커니즘(attention mechanism)은 인코더-디코더 구조의 근본적인 병목을 해결했다. 기존 RNN 인코더-디코더에서는 입력 시퀀스 전체가 하나의 고정 길이 문맥 벡터로 압축되었다. 아무리 긴 문장이라도 하나의 벡터에 모든 정보를 담아야 했으므로, 정보 손실이 불가피했다.
어텐션의 핵심 아이디어는 **직접 연결(direct connection)**이다. 디코더가 출력을 생성할 때, 고정된 문맥 벡터에만 의존하지 않고, 인코더의 모든 은닉 상태에 직접 접근할 수 있게 하는 것이다.
번역 예시
프랑스어에서 영어로 번역하는 상황을 생각하자.
"Je suis étudiant" (나는 학생이다) → "I am a student"
디코더가 "I"를 생성할 때, 입력 문장의 어디를 주로 참고해야 할까? "Je"(나는)에 가장 높은 가중치를 두어야 한다. "am"을 생성할 때는 "suis"(이다)를, "student"를 생성할 때는 "étudiant"(학생)를 주로 참고해야 한다.
어텐션은 바로 이 선택적 참조를 가능하게 한다. 디코더의 각 시간 단계에서, 인코더의 모든 은닉 상태에 대한 가중치(어텐션 점수)를 계산하고, 이 가중치를 사용하여 인코더 은닉 상태의 가중 합을 구한다. 이것이 해당 시간 단계의 문맥 벡터가 된다.
어텐션 메커니즘은 RNN의 성능을 크게 향상시켰으며, 이 아이디어는 곧 트랜스포머의 핵심 구성 요소인 셀프 어텐션으로 발전한다.
1.6 셀프 어텐션
순차 처리의 완전한 제거
RNN의 근본적 문제는 순차 처리였다. 어텐션을 RNN에 추가하면 성능은 좋아지지만, 여전히 인코더와 디코더 내부는 순차적으로 동작한다. 2017년 "Attention Is All You Need" 논문의 핵심 통찰은 RNN을 완전히 제거하고 어텐션만으로 시퀀스를 처리할 수 있다는 것이었다.
*셀프 어텐션*(self-attention)에서는 시퀀스 내의 모든 토큰이 모든 토큰을 동시에 참조한다. 순차적 처리가 아니라, 한 번의 연산으로 모든 토큰 쌍 간의 관계를 계산한다.
문맥 의존적 임베딩
셀프 어텐션의 가장 중요한 결과는 **문맥 의존적 임베딩(context-dependent embedding)**이다. Word2Vec에서 "bank"는 문맥에 관계없이 항상 같은 벡터였지만, 셀프 어텐션을 거친 후에는 문맥에 따라 다른 벡터가 된다.
"I went to the bank to deposit money."
→ bank의 임베딩 = 주변 단어(deposit, money)의 영향으로 "은행" 방향
"I sat on the bank of the river."
→ bank의 임베딩 = 주변 단어(river, sat)의 영향으로 "강둑" 방향
셀프 어텐션은 각 단어의 임베딩을 문맥 전체를 반영하여 갱신한다. 이로써 Word2Vec의 동음이의어 문제가 근본적으로 해결된다.
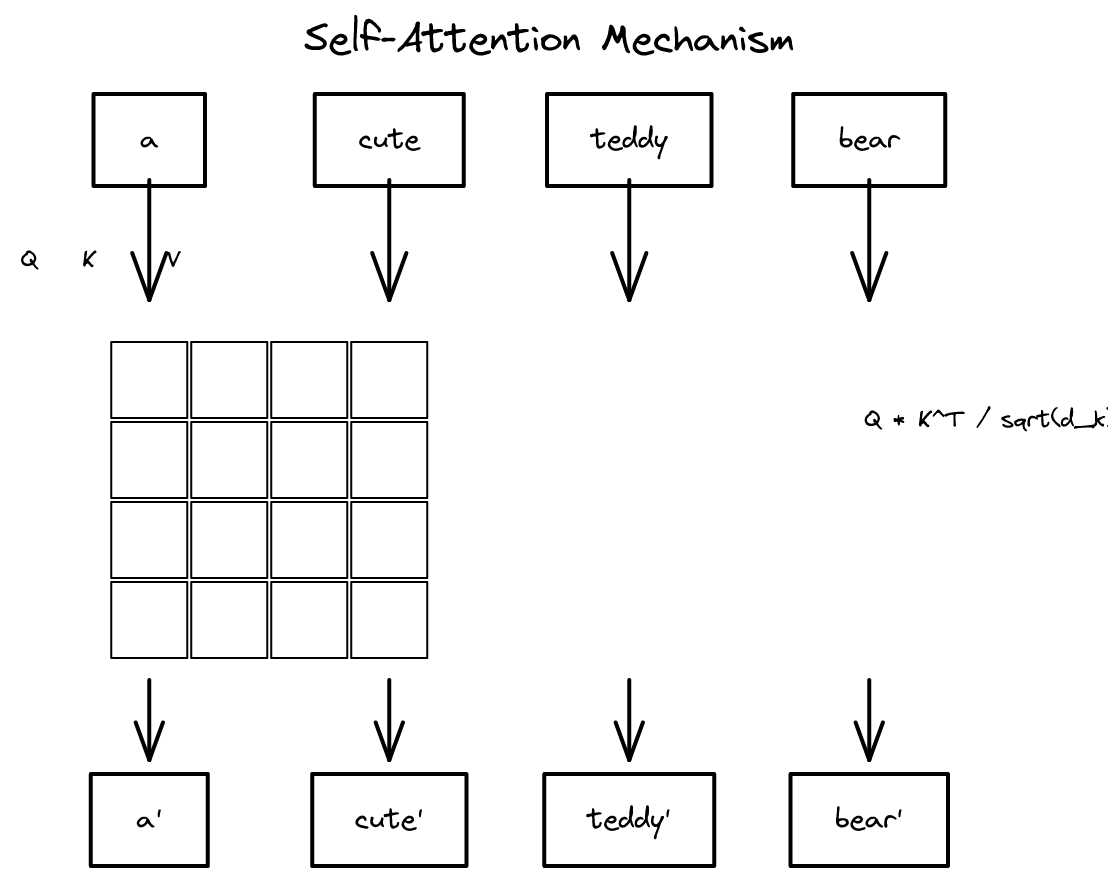
Q, K, V 프레임워크
셀프 어텐션은 질의(Query), 키(Key), **값(Value)**의 세 가지 벡터를 사용한다. 이를 데이터베이스에 비유하면 직관적으로 이해할 수 있다.
데이터베이스에서 검색할 때: - 질의(Query): "2024년에 출간된 AI 관련 도서를 찾아줘" - 키(Key): 데이터베이스의 각 레코드에 붙은 색인 (출간 연도, 주제 등) - 값(Value): 키와 일치하는 레코드의 실제 내용
셀프 어텐션에서도 마찬가지다: - Q (질의): "나는 어떤 정보가 필요한가?" — 현재 토큰이 다른 토큰에게 보내는 질문 - K (키): "나는 어떤 정보를 제공할 수 있는가?" — 각 토큰의 색인 - V (값): "나의 실제 내용은 무엇인가?" — 각 토큰이 전달하는 실제 정보
입력 임베딩 X에 세 개의 학습 가능한 가중치 행렬을 곱하여 Q, K, V를 생성한다.
Q = X · W_Q
K = X · W_K
V = X · W_V
핵심 수식
셀프 어텐션의 핵심 수식은 다음과 같다.
Attention(Q, K, V) = softmax(QK^T / √d_k) · V
이 수식을 단계별로 풀어보자.
1단계: Q와 K의 내적 계산 (QK^T)
Q의 각 행(질의 벡터)과 K의 각 행(키 벡터) 사이의 내적을 계산한다. 내적이 클수록 두 벡터가 유사하다는 뜻이므로, 이 값은 "질의와 키가 얼마나 관련 있는가"를 나타내는 **어텐션 점수(attention score)**다. 결과는 n×n 행렬이다 (n은 시퀀스 길이).
2단계: √d_k로 나누기 (스케일링)
내적 결과를 키 벡터의 차원 d_k의 제곱근으로 나눈다. 왜 이 스케일링이 필요한가? d_k가 클수록 내적 값의 분산이 커진다. 분산이 큰 값에 softmax를 적용하면, 가장 큰 값에 거의 모든 확률이 집중되어 다른 값들의 그래디언트가 극단적으로 작아진다. √d_k로 나누면 분산을 1에 가깝게 유지하여 softmax가 안정적으로 동작한다.
3단계: softmax 적용
스케일링된 점수에 행 단위로 softmax를 적용한다. 각 행이 하나의 확률 분포가 되어, 모든 값의 합이 1이 된다. 이제 각 토큰이 다른 토큰들에 어떤 비율로 주의를 기울이는지가 확률로 표현된다.
4단계: V와 가중 합 계산
softmax로 얻은 어텐션 가중치를 V에 곱한다. 이는 각 토큰의 값 벡터를 어텐션 가중치에 따라 가중 합하는 것이다. 결과적으로 각 토큰의 출력은 문맥 전체를 반영한 새로운 벡터가 된다.
5단계: 출력
최종 출력은 입력과 동일한 크기의 행렬이다. 각 행은 해당 토큰의 문맥 의존적 임베딩이다.
6단계: 역전파를 통한 학습
W_Q, W_K, W_V는 모두 학습 가능한 파라미터다. 훈련 과정에서 역전파를 통해 이 가중치 행렬들이 최적화된다.
GPU와 행렬 연산의 궁합
셀프 어텐션의 모든 연산은 행렬 곱셈으로 표현된다. 행렬 곱셈은 GPU가 극도로 효율적으로 처리할 수 있는 연산이다. RNN은 시간 단계마다 순차적으로 계산해야 하므로 GPU의 수천 개 코어 중 소수만 활용할 수 있었지만, 셀프 어텐션은 모든 토큰 쌍의 관계를 단일 행렬 곱셈으로 동시에 계산하므로 GPU의 병렬 처리 능력을 최대한 활용한다.
1.7 트랜스포머 아키텍처 (2017)
2017년 Vaswani 등이 발표한 "Attention Is All You Need" 논문은 트랜스포머(Transformer) 아키텍처를 제안했다. 이름이 시사하듯, RNN이나 CNN 없이 어텐션만으로 시퀀스-투-시퀀스 과제를 수행하는 모델이다.
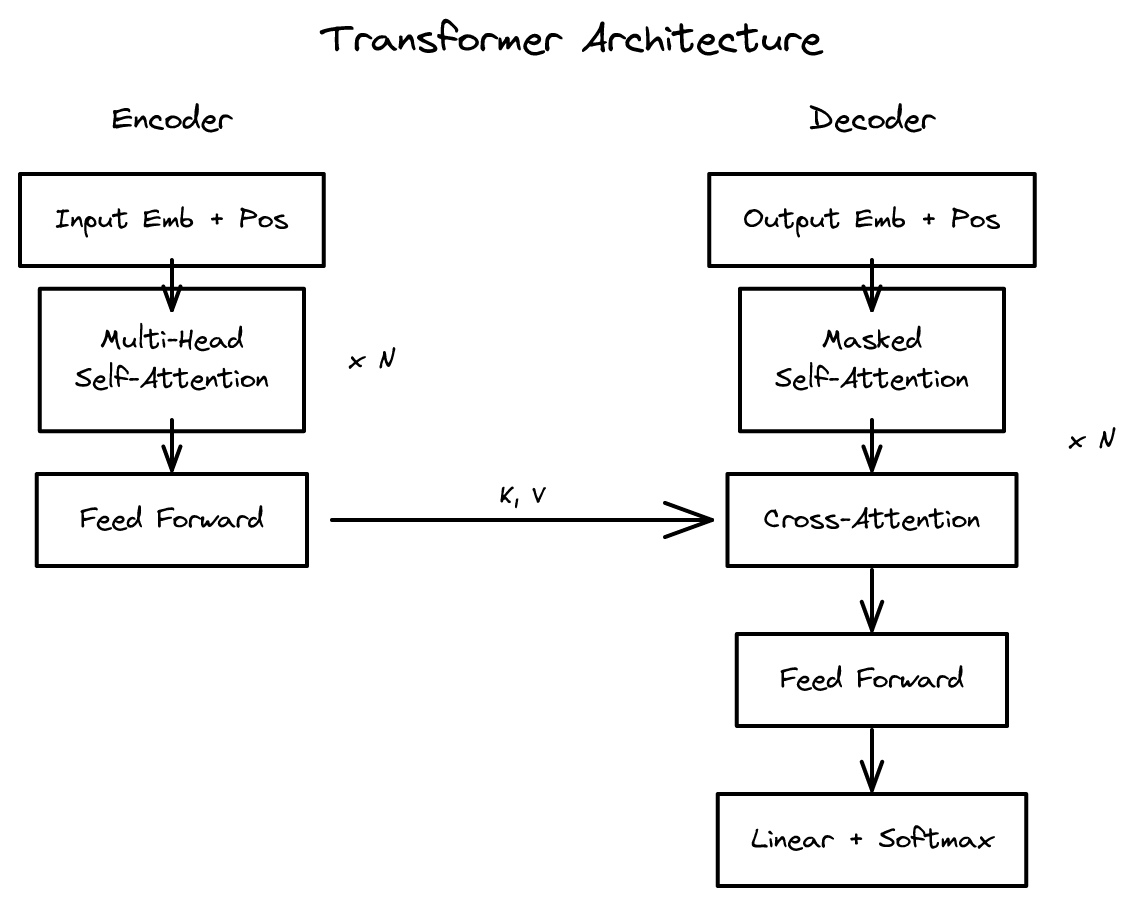
트랜스포머는 **인코더(encoder)**와 **디코더(decoder)**로 구성된다.
인코더
인코더는 입력 시퀀스를 처리하여 문맥을 반영한 표현을 생성한다. 하나의 인코더 층은 다음 두 가지 하위 층으로 구성된다.
- 셀프 어텐션 (Self-Attention): 입력 시퀀스의 모든 토큰이 서로를 참조하여 문맥 의존적 표현을 생성한다.
- 피드포워드 신경망 (FFN, Feed-Forward Network): 각 토큰의 표현을 독립적으로 비선형 변환한다.
각 하위 층 뒤에는 잔차 연결(residual connection)과 층 정규화(layer normalization)가 적용된다.
이 인코더 층을 N개 적층한다. 원래 논문에서는 N=6을 사용했다. 각 층은 동일한 구조를 가지되, 가중치는 독립적으로 학습된다.
디코더
디코더는 인코더의 출력과 이전까지 생성된 토큰을 사용하여 다음 토큰을 예측한다. 하나의 디코더 층은 세 가지 하위 층으로 구성된다.
마스크드 셀프 어텐션 (Masked Self-Attention): 디코더의 입력 시퀀스에 대한 셀프 어텐션이다. 단, 미래 토큰을 참조하지 못하도록 **마스크(mask)**가 적용된다. i번째 토큰은 1번째부터 i번째 토큰까지만 참조할 수 있다. 이는 추론 시 미래 토큰이 아직 생성되지 않은 상태와 일치하도록 훈련하기 위함이다.
크로스 어텐션 (Cross-Attention): 디코더의 질의(Q)와 인코더의 키(K), 값(V)을 사용하는 어텐션이다. 디코더의 각 토큰이 인코더의 입력 시퀀스 전체를 참조할 수 있게 한다. 번역 과제에서 디코더가 출력 단어를 생성할 때 입력 문장의 관련 부분을 참조하는 메커니즘이다.
피드포워드 신경망 (FFN): 인코더와 동일한 구조다.
디코더 역시 N개 층을 적층한다.
멀티헤드 어텐션
실제 트랜스포머에서는 단일 어텐션 대신 **멀티헤드 어텐션(multi-head attention)**을 사용한다. 핵심 아이디어는 어텐션을 h개의 병렬 헤드로 나누어 각각 독립적으로 수행하는 것이다.
각 헤드는 독립적인 W_Q, W_K, W_V 가중치 행렬을 가진다. 입력 차원이 d_model이고 헤드 수가 h라면, 각 헤드의 차원은 d_k = d_model / h가 된다.
head_i = Attention(Q · W_Qi, K · W_Ki, V · W_Vi)
h개 헤드의 출력을 **결합(concatenation)**한 후, 추가적인 가중치 행렬 W_O를 곱하여 원래 차원으로 투영한다.
MultiHead(Q, K, V) = Concat(head_1, ..., head_h) · W_O
왜 여러 헤드가 필요한가? 이를 CNN의 필터에 비유할 수 있다. CNN에서 각 필터가 이미지의 서로 다른 특성(가장자리, 질감, 색상 등)을 포착하듯이, 멀티헤드 어텐션의 각 헤드는 서로 다른 종류의 관계를 학습한다. 한 헤드는 구문적 관계(주어-동사)를, 다른 헤드는 의미적 관계(동의어)를, 또 다른 헤드는 위치적 관계(인접 단어)를 포착할 수 있다.
위치 인코딩
셀프 어텐션은 모든 토큰을 동시에 처리하므로, 토큰의 순서 정보가 자연스럽게 반영되지 않는다. "고양이가 개를 쫓았다"와 "개가 고양이를 쫓았다"의 셀프 어텐션 결과가 (순서 정보 없이는) 동일해진다.
이를 해결하기 위해 위치 인코딩(positional encoding)을 추가한다. 각 토큰의 위치에 고유한 벡터를 부여하고, 이를 토큰 임베딩에 더한다. 원래 트랜스포머 논문에서는 사인(sin)과 코사인(cos) 함수를 사용한다.
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
여기서 pos는 토큰의 위치, i는 차원 인덱스, d_model은 임베딩 차원이다. 짝수 차원에는 사인 함수를, 홀수 차원에는 코사인 함수를 사용한다. 서로 다른 주파수의 사인/코사인 함수를 조합하여 각 위치에 고유한 패턴을 부여한다.
피드포워드 신경망 (FFN)
각 인코더/디코더 층의 피드포워드 신경망은 두 개의 선형 변환과 활성화 함수로 구성된다.
FFN(x) = W₂ · ReLU(W₁ · x + b₁) + b₂
주목할 점은 FFN의 은닉 차원이 입력 차원보다 크다는 것이다. 원래 논문에서 d_model=512인데, FFN의 은닉 차원 d_ff=2048로 4배 크다. 이는 더 넓은 표현 공간에서 비선형 변환을 수행한 후 다시 원래 차원으로 압축하는 병목(bottleneck) 구조다. 넓은 은닉 차원은 모델이 더 복잡한 특성 조합을 학습할 수 있게 해준다.
주요 차원 정리
기호 |
의미 |
원래 논문 값 |
|---|---|---|
d_model |
모델 차원 (임베딩 크기) |
512 |
d_k |
각 헤드의 키/질의 차원 |
64 |
d_v |
각 헤드의 값 차원 |
64 |
h |
어텐션 헤드 수 |
8 |
N |
인코더/디코더 층 수 |
6 |
d_ff |
FFN 은닉 차원 |
2048 |
d_k = d_v = d_model / h = 512 / 8 = 64라는 관계가 성립한다.
1.8 번역 예제: 전체 과정
트랜스포머가 "I love you" → "나는 너를 사랑한다"로 번역하는 전체 과정을 단계별로 추적해 보자.
1단계: 토큰화
입력과 출력 문장을 토큰으로 분할한다.
입력: "I love you" → ["I", "love", "you"]
출력: "나는 너를 사랑한다" → ["나는", "너를", "사랑", "한다"]
2단계: 특수 토큰 추가
시퀀스의 시작과 끝을 나타내는 특수 토큰을 추가한다.
인코더 입력: ["BOS", "I", "love", "you", "EOS"]
디코더 입력: ["BOS"] (처음에는 시작 토큰만)
BOS(Beginning of Sequence)는 시퀀스의 시작, EOS(End of Sequence)는 시퀀스의 끝을 나타낸다.
3단계: 임베딩 + 위치 인코딩
각 토큰을 d_model 차원의 임베딩 벡터로 변환하고, 위치 인코딩을 더한다.
최종 입력 = 토큰 임베딩 + 위치 인코딩
4단계: 인코더 처리
임베딩된 입력이 N개의 인코더 층을 순차적으로 통과한다. 각 층에서 셀프 어텐션과 FFN을 거치며, 모든 토큰의 표현이 문맥을 반영하여 갱신된다. 인코더의 최종 출력은 입력 시퀀스의 깊은 문맥 표현이다.
5단계: 디코더 (자기회귀 생성)
디코더는 **자기회귀적(autoregressive)**으로 토큰을 하나씩 생성한다.
반복 1: 디코더 입력 = ["BOS"] - 마스크드 셀프 어텐션: "BOS"만 참조 - 크로스 어텐션: 인코더 출력 전체 참조 - FFN 통과 - 출력층 (d_model → V 차원으로 투영) - softmax → 어휘 전체에 대한 확률 분포 - 가장 높은 확률의 토큰 선택: "나는"
반복 2: 디코더 입력 = ["BOS", "나는"] - 마스크드 셀프 어텐션: "BOS"와 "나는"만 참조 - 크로스 어텐션 → FFN → softmax - 다음 토큰: "너를"
반복 3: 디코더 입력 = ["BOS", "나는", "너를"] - 다음 토큰: "사랑"
반복 4: 디코더 입력 = ["BOS", "나는", "너를", "사랑"] - 다음 토큰: "한다"
반복 5: 디코더 입력 = ["BOS", "나는", "너를", "사랑", "한다"] - 다음 토큰: "EOS"
6단계: 종료
EOS 토큰이 생성되면 디코더가 생성을 멈추고, 최종 출력 "나는 너를 사랑한다"를 반환한다.
이 과정에서 핵심은 디코더가 매 단계마다 이전에 생성한 모든 토큰과 인코더의 전체 출력을 참조한다는 점이다. 크로스 어텐션 덕분에 디코더는 입력 문장의 어떤 부분이 현재 생성할 토큰과 관련 있는지를 동적으로 파악한다.
1.9 라벨 스무딩
동기
번역이나 텍스트 생성에서는 하나의 입력에 대해 여러 정답이 존재할 수 있다. "I love you"의 번역은 "나는 너를 사랑한다", "난 널 사랑해", "너를 사랑한다" 등 다양하다. 그런데 훈련 데이터에는 보통 하나의 정답만 제공되며, 정답 토큰의 확률이 1이고 나머지가 0인 원-핫 벡터가 사용된다.
이 경우 모델은 정답 토큰에 극도로 높은 확률을 할당하도록 학습되어 **과적합(overfitting)**되기 쉽다. 정답이 아닌 다른 합리적인 대안의 확률을 지나치게 낮추게 된다.
기법
**라벨 스무딩(label smoothing)**은 정답의 확률을 1에서 약간 낮추고, 그 차이를 나머지 토큰에 균등하게 분배하는 기법이다.
스무딩 파라미터 ε (보통 0.1)를 사용하면:
원래 레이블: [1, 0, 0, ..., 0]
스무딩 후: [1-ε, ε/(V-1), ε/(V-1), ..., ε/(V-1)]
예를 들어 어휘 크기 V=10000, ε=0.1이면:
원래: [1.0, 0, 0, ..., 0]
스무딩 후: [0.9, 0.00001, 0.00001, ..., 0.00001]
정답 토큰의 확률은 0.9로 낮아지고, 나머지 9999개 토큰이 각각 약 0.00001의 확률을 가진다.
효과
라벨 스무딩은 모델이 정답에 대해 지나치게 확신하는 것을 방지한다. 이는 여러 실험에서 BLEU 점수 등의 평가 지표를 개선하는 것으로 확인되었다. 모델이 다양한 합리적 답변에 적절한 확률을 부여하게 되어, 일반화 성능이 향상된다.
원래 트랜스포머 논문에서도 라벨 스무딩을 적용하여 퍼플렉시티는 소폭 악화되었으나, 실질적 번역 품질을 나타내는 BLEU 점수는 개선되었다고 보고했다. 퍼플렉시티가 나빠지는 이유는 모델이 정답에 100%의 확신을 주지 못하도록 훈련되기 때문이다. 그러나 실제 생성 품질은 오히려 좋아지므로, 이는 유의미한 트레이드오프다.
핵심 정리
개념 |
핵심 |
|---|---|
NLP 과제 분류 |
분류 (단일 레이블), 다중 분류 (시퀀스 레이블), 생성 (새 시퀀스) |
토큰화 |
텍스트를 숫자로 변환. 서브워드 수준이 현대 표준 |
원-핫 인코딩 |
단순하나 단어 간 유사도 표현 불가 (코사인 유사도 = 0) |
Word2Vec |
밀집 벡터 임베딩. 프록시 과제로 의미 학습. 문맥 독립적 한계 |
RNN |
순서와 문맥 반영. 소멸 그래디언트와 순차 처리 문제 |
LSTM |
셀 상태 추가로 장거리 의존성 개선. 순차 처리는 여전 |
어텐션 |
직접 연결로 인코더 전체 참조. RNN 성능 향상 |
셀프 어텐션 |
모든 토큰이 모든 토큰 참조. 문맥 의존적 임베딩. 완전 병렬화 |
트랜스포머 |
인코더-디코더. 멀티헤드 어텐션 + FFN + 위치 인코딩 |
라벨 스무딩 |
과적합 방지. BLEU 등 실질 지표 개선 |
다음 장: 2장 - 트랜스포머 모델과 기법