3장 - 대규모 언어 모델
3장. 대규모 언어 모델
오늘은 매우 흥미로운 날이다. 드디어 대규모 언어 모델을 소개할 것이다. 이 모델들은 수천억 개의 파라미터와 수조 개의 토큰으로 훈련되었으며, 현대 AI의 핵심이 되었다. — 아프신 아미디
3.1 LLM의 정의
LLM은 Large Language Model, 즉 대규모 언어 모델의 약자다. 이 용어는 두 가지 핵심 요소로 분해된다.
첫째, 언어 모델(Language Model)이다. 언어 모델이란 토큰 시퀀스에 확률을 부여하는 모델을 말한다. 구체적으로, 주어진 이전 토큰들을 조건으로 다음 토큰의 확률을 예측한다. 이것이 언어 모델의 본질이다.
둘째, "대규모(Large)"다. LLM이 대규모인 이유는 세 가지 측면에서 확인된다.
측면 |
규모 |
설명 |
|---|---|---|
모델 크기 |
수십억~수천억 파라미터 |
최소 10억(1B) 파라미터 이상. 수백억~수천억이 일반적 |
훈련 데이터 |
수천억~수조 토큰 |
최대 수십조(tens of trillions) 토큰 규모 |
연산량 |
대규모 GPU 클러스터 |
다수의 GPU를 필요로 하는 막대한 연산 |
이 용어는 비교적 최근에 정립되었다. 2018~2019년에는 LLM이라는 명확한 정의가 없었고, 초기에는 BERT 같은 인코더 전용 모델도 LLM으로 분류하는 경우가 있었다. 그러나 현재의 정의에 따르면, BERT는 텍스트를 생성하지 않으므로 LLM이 아니다. LLM은 텍스트를 입력으로 받아 텍스트를 출력하는, 대규모 언어 모델만을 지칭한다.
디코더 전용 아키텍처
현대 LLM의 90% 이상은 디코더 전용(decoder-only) 아키텍처를 사용한다. 트랜스포머의 인코더를 제거하고 디코더만 남긴 구조다. 인코더가 없으므로 크로스 어텐션도 제거된다. 남는 것은 다음 세 가지다.
- 마스크드 셀프 어텐션(Masked Self-Attention): 현재 토큰이 이전 토큰만 참조하도록 미래 토큰을 마스킹한다.
- 피드포워드 신경망(Feed-Forward Neural Network, FFN): 각 토큰의 표현을 비선형 변환한다.
- 덧셈 및 정규화(Add & Norm): 잔차 연결과 레이어 정규화를 적용한다.
이것이 LLM의 백본이다. GPT가 대표적인 예시이며, 이 외에도 다양한 디코더 전용 모델이 존재한다.
모델 |
개발사 |
|---|---|
Llama |
Meta |
Gemma |
|
DeepSeek |
DeepSeek |
Mistral |
Mistral AI |
Qwen |
Alibaba |
3.2 혼합 전문가 모델 (Mixture of Experts)
LLM은 수백억에서 수천억 개의 파라미터를 가진다. 하나의 순방향 전파에 이 모든 파라미터를 활성화해야 할까? 강의에서는 이를 비유로 설명한다.
방에 수학자, 물리학자, 화학자, 역사학자가 있다. 수학 문제가 있다면 누구에게 물을 것인가? 모두에게 물을 필요는 없다. 수학자에게만 물으면 된다.
이것이 혼합 전문가 모델(Mixture of Experts, MoE)의 핵심 아이디어다. 주어진 입력에 대해 모든 파라미터를 활성화하는 대신, 적절한 전문가(expert)의 부분집합만 활성화하여 연산량을 줄인다.
MoE의 수식
n개의 전문가 \(E_1, E_2, \ldots, E_n\)과 게이트(gate) 또는 라우터(router)라 불리는 네트워크 \(G\)가 있다고 하자. 입력 \(x\)가 주어지면 출력은 다음과 같다.
y_hat = sum_{i=1}^{n} g_i(x) * E_i(x)
여기서 \(g_i(x)\)는 게이트의 출력으로, 전문가 \(E_i\)의 출력에 부여되는 가중치다. 게이트와 전문가는 공동으로(jointly) 훈련된다. 순방향 전파 후 손실을 계산하고 역전파하는 일반적인 훈련 방식을 따른다.
밀집 MoE와 희소 MoE
MoE는 활성화 방식에 따라 두 종류로 나뉜다.
밀집 MoE (Dense MoE): 활성화되는 전문가 수에 제약이 없다. 가중치 \(g_i(x)\)는 0과 1 사이의 값을 가지며, 확률 분포처럼 작동한다. 모든 전문가가 관여하되, 입력에 따라 특정 전문가에 더 큰 가중치를 부여한다. 수학 문제라면 수학자에게 높은 가중치를, 역사학자에게 낮은 가중치를 부여하는 셈이다.
희소 MoE (Sparse MoE): 상위 K개의 전문가만 선택하여 활성화한다. K는 하이퍼파라미터로, 보통 1 또는 2다. 출력 수식은 다음과 같다.
y_hat = sum_{i in top-K} g_i(x) * E_i(x)
희소 MoE는 밀집 MoE에 비해 순방향 전파당 **부동소수점 연산(FLOPs, Floating Point Operations)**이 적다. FLOPs는 한 번의 순방향 전파에 필요한 덧셈, 곱셈 등의 연산 횟수를 정량화하는 단위로, 모델의 연산 부하를 측정하는 표준 지표다.
LLM에서의 MoE 배치
디코더 전용 LLM에 MoE를 적용할 때, 전문가를 어디에 배치해야 하는가? 선택지는 마스크드 셀프 어텐션, FFN, 정규화 레이어다.
정답은 **피드포워드 신경망(FFN)**이다. 그 이유는 FFN이 가장 많은 파라미터를 포함하기 때문이다.
FFN의 구조를 보자. 입력은 \(d_{model}\) 차원이고, 이를 \(d_{ff}\) 차원으로 확장한 뒤 다시 \(d_{model}\) 차원으로 축소한다. \(d_{ff}\)는 통상 \(d_{model}\)보다 훨씬 크다 (수천~수만 차원). FFN의 파라미터 수는 다음과 같다.
FFN 파라미터 수 ≈ 2 * d_model * d_ff + bias
반면 어텐션 레이어의 투영 행렬은 \(d_{model} \times d_k\) (또는 \(d_q\), \(d_v\)) 크기이며, \(d_k\)는 통상 수백 차원에 불과하다. 따라서 FFN의 파라미터 수가 어텐션 레이어보다 압도적으로 많다.
구성 요소 |
차원 규모 |
파라미터 수 |
|---|---|---|
FFN |
\(d_{model}\): O(1000), \(d_{ff}\): O(1000~10000) |
O(\(d_{model} \times d_{ff}\)) |
어텐션 투영 |
\(d_{model}\): O(1000), \(d_k\): O(100) |
O(\(d_{model} \times d_k\)) |
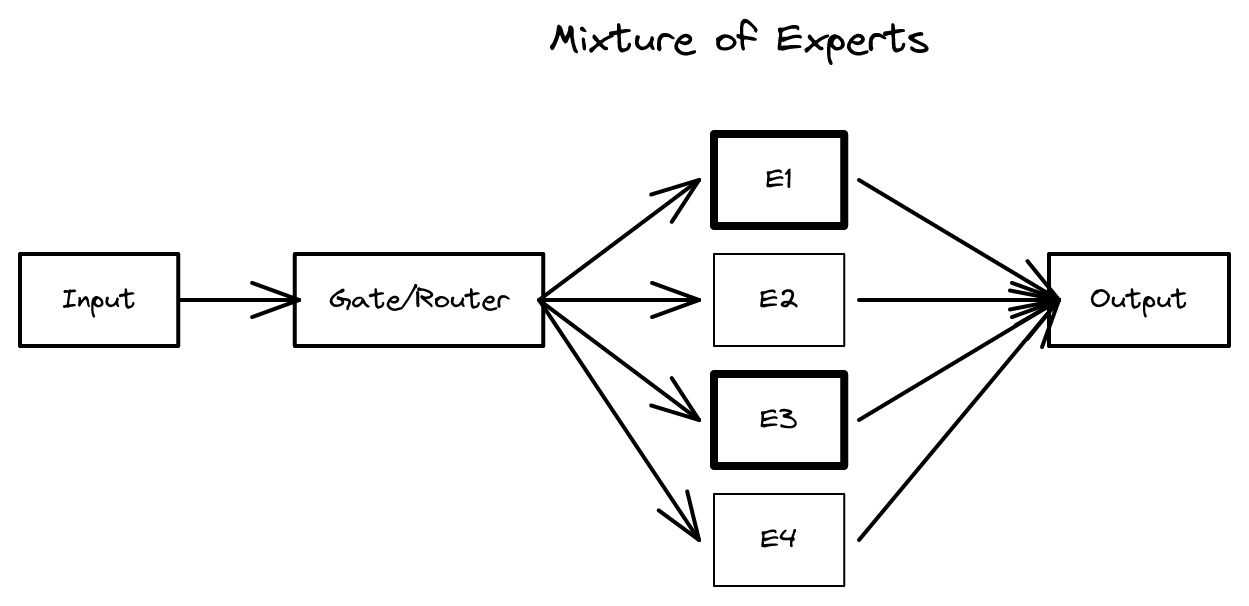
현대 LLM에서 MoE는 FFN 위치에 배치되며, 보통 희소 MoE를 사용한다. 각 전문가는 개별 FFN이고, 통상 K=1 또는 K=2로 설정하여 소수의 전문가만 활성화한다. 라우팅은 토큰 수준에서 수행된다. 즉, 각 토큰이 어텐션 레이어를 거쳐 문맥 정보를 반영한 뒤, 그 표현이 게이트에 입력되어 어떤 전문가로 보낼지 결정된다. 같은 시퀀스 내에서도 토큰마다 다른 전문가가 선택될 수 있다.
게이트는 레이어별로 독립적이며 가중치가 공유되지 않는다. 1번 레이어에서 전문가 3이 선택되었더라도, 2번 레이어에서는 전문가 1이 선택될 수 있다. 모든 것이 학습 가능하다. 또한 전문가의 수는 어텐션 헤드 수와 독립적이다. 멀티헤드 어텐션은 최종적으로 모든 헤드의 출력을 연결하고 \(d_{model}\) 공간으로 재투영한 뒤, 그 결과가 하나의 라우터에 입력된다.
라우팅 붕괴와 보조 손실
MoE 모델을 훈련할 때의 핵심 과제는 모든 전문가가 고르게 활용되도록 보장하는 것이다. 훈련 과정에서 라우터가 특정 전문가만 반복적으로 선택하고 나머지 전문가는 영구적으로 비활성 상태에 빠지는 현상이 발생할 수 있다. 이를 **라우팅 붕괴(routing collapse)**라 한다.
이 문제를 완화하기 위해 손실 함수에 보조 손실(auxiliary loss) 항을 추가한다.
L_aux = alpha * n * sum_{i=1}^{n} f_i * P_i
여기서: - \(\alpha\): 보조 손실의 가중치를 조절하는 하이퍼파라미터 - \(n\): 전문가의 수 - \(f_i\): 전문가 \(i\)로 라우팅된 토큰의 비율 - \(P_i\): 전문가 \(i\)에 대한 평균 라우팅 확률
이 보조 손실은 \(f_i\)와 \(P_i\)가 모든 전문가에 대해 균일 분포에 가까워지도록 유도한다. 즉, 모든 전문가가 비슷한 빈도로 활용되게 만든다.
\(P_i\)의 계산 방식을 구체적으로 보면, 게이트의 출력은 입력 벡터를 \(n\) 차원 공간으로 투영한 뒤 소프트맥스를 적용한 결과다. 각 차원이 해당 전문가의 선택 확률을 나타내며, 이 확률의 미니배치 평균이 \(P_i\)다.
추가적으로 노이지 게이팅(noisy gating) 기법도 사용된다. 게이트의 출력에 무작위 노이즈를 추가하여, 확률적으로 다른 전문가가 선택될 기회를 제공한다. 드롭아웃과 유사한 발상이다.
MoE의 확장성
MoE의 핵심 이점은 **활성 파라미터(active parameters)**를 통제하면서 모델의 전체 용량(capacity)을 확장할 수 있다는 점이다. 전문가 수를 늘리면 전체 파라미터 수는 증가하지만, 순방향 전파에 관여하는 활성 파라미터 수는 일정하게 유지된다. 이 덕분에 MoE 기반 모델은 수조 개의 파라미터를 가질 수 있다. 예를 들어 Switch Transformer는 약 1조(1T) 이상의 파라미터로 확장되었다.
또한 MoE 모델은 **샘플 효율성(sample efficiency)**이 높은 것으로 알려져 있다. 동일한 훈련 시간 대비, 적은 파라미터를 가진 밀집 모델과 비슷한 성능에 더 빨리 도달한다. 훈련 곡선을 시간축으로 그리면 MoE 모델이 더 가파르게 성능이 향상되는 것을 확인할 수 있다.
Mistral 팀은 주어진 텍스트에서 각 토큰이 어떤 전문가로 라우팅되었는지 시각화한 결과를 발표했다. 특정 레이어(예: 레이어 0)에서 토큰들이 대체로 균일하게 다양한 전문가에 분배되는 것을 확인할 수 있었다. 모든 토큰이 같은 전문가로 가는 것이 아니라 골고루 분산되는 것이 정상이다.
3.3 응답 생성
LLM은 **다음 토큰 예측(next token prediction)**을 통해 텍스트를 생성한다. 시작 토큰(BOS)을 입력하면 다음 토큰을 예측하고, 그 토큰을 다시 입력에 추가하여 그다음 토큰을 예측하는 과정을 반복한다.
BOS → "a" → "cute" → "teddy" → "bear" → "is" → ...
이 과정에서 핵심 질문은, 모델이 출력하는 확률 분포로부터 어떻게 다음 토큰을 선택하는가다. 디코더의 출력은 어휘 전체에 대한 확률 분포다. 예를 들어:
"a": 0.25, "airplane": 0.01, "fluffy": 0.20, "gentle": 0.18,
"kind": 0.15, "smart": 0.12, "wear": 0.02, ...
이 확률 분포에서 다음 토큰을 선택하는 방법이 **디코딩 전략(decoding strategy)**이다.
탐욕적 디코딩 (Greedy Decoding)
가장 단순한 접근법은 매 단계에서 확률이 가장 높은 토큰을 선택하는 것이다. 이를 **탐욕적 디코딩(greedy decoding)**이라 한다.
문제점 1 — 다양성 부재: 트랜스포머 아키텍처 내부의 모든 연산은 결정론적이다. 유일하게 비결정론적인 부분은 다음 토큰을 샘플링하는 단계뿐이다. 따라서 항상 최고 확률 토큰을 선택하면, 동일한 입력에 대해 항상 동일한 출력을 생성한다.
문제점 2 — 지역 최적(locally optimal)이나 전역 최적(globally optimal)이 아니다: 매 단계에서 최고 확률 토큰을 선택하는 것이 가장 높은 확률의 시퀀스를 보장하지 않는다. 예를 들어 첫 단계에서 확률 0.8인 토큰을 선택하면 이후 모든 토큰의 확률이 매우 낮을 수 있고, 확률 0.2인 토큰을 선택했다면 이후 토큰들의 확률이 훨씬 높아 전체 시퀀스 확률이 더 클 수 있다.
빔 서치 (Beam Search)
빔 서치는 K개의 가장 유망한 경로를 동시에 추적하는 방법이다. K를 빔 크기(beam size) 또는 빔 폭(beam width)이라 한다.
과정: 1. BOS에서 출발하여 상위 K개의 토큰을 선택한다. (예: K=2이면 "a"와 "z") 2. 각 경로에서 다음 토큰의 확률을 계산하고, 전체 K개 경로 중 상위 K개를 유지한다. 3. 이 과정을 반복한 뒤, 최종적으로 가장 높은 확률의 시퀀스를 선택한다.
시퀀스 확률은 각 토큰의 로그 확률의 합으로 계산한다.
log P(sequence) = log P(x_1 | BOS) + log P(x_2 | BOS, x_1) + ...
길이 패널티: 토큰이 추가될수록 시퀀스의 전체 확률은 감소한다. 각 토큰의 확률이 1 미만이므로, 곱할수록 값이 작아지기 때문이다. 이로 인해 빔 서치는 짧은 시퀀스를 선호하는 편향이 생긴다. 이를 보정하기 위해 \(\frac{1}{T^\alpha}\) 형태의 길이 정규화 항을 적용한다 (T는 토큰 수).
한계: 빔 서치는 기계 번역처럼 가장 가능성 높은 출력이 필요한 과제에서 사용된다. 그러나 K개 경로를 유지해야 하므로 연산 비용이 크고, 여전히 가장 유망한 경로만 추구하므로 출력의 다양성과 창의성이 부족하다.
샘플링 기반 방법
실제로 대부분의 LLM은 확률 분포에서 다음 토큰을 **샘플링(sampling)**하는 방식을 사용한다. 확률이 높은 토큰이 더 자주 선택되지만, 확률이 낮은 토큰도 가끔 선택될 수 있어 다양한 출력을 생성한다.
그러나 극히 낮은 확률의 토큰까지 샘플링 대상에 포함하면 품질이 저하될 수 있다. 이를 방지하기 위해 샘플링 범위를 제한하는 기법이 사용된다.
Top-K 샘플링: 확률이 가장 높은 상위 K개의 토큰만 선택하여 그 중에서 샘플링한다. 예를 들어 K=4이면 상위 4개 토큰에서만 샘플링한다.
Top-P 샘플링 (Nucleus Sampling): 누적 확률이 임계값 P를 초과할 때까지 확률 순서대로 토큰을 포함한다. 예를 들어 P=0.9이면, 누적 확률이 0.9에 도달할 때까지의 토큰들만 샘플링 대상에 포함한다.
3.4 온도 (Temperature)
샘플링의 확률 분포는 어디서 오는가? 디코더의 최상위에서 토큰의 인코딩된 임베딩이 선형 레이어를 통해 \(d_{model}\) 차원에서 어휘 크기 \(|V|\) 차원으로 투영된다. 이 투영 결과(로짓)에 소프트맥스를 적용하여 확률 분포를 얻는다. 이때 핵심 하이퍼파라미터가 온도(temperature) \(T\)다.
P(next token = w_i) = exp(x_i / T) / sum_j exp(x_j / T)
여기서 \(x_i\)는 토큰 \(w_i\)에 대한 로짓(활성화 값)이다.
온도의 수학적 분석
온도의 효과를 엄밀히 분석할 수 있다. 가장 큰 로짓값을 가진 인덱스를 \(k\)라 하자 (즉, \(x_k = \max_i x_i\)). 확률 식의 분자와 분모를 \(\exp(x_k / T)\)로 나누면:
P(w_i) = exp((x_i - x_k) / T) / sum_j exp((x_j - x_k) / T)
\(i = k\)일 때 분자는 \(\exp(0) = 1\)이다. \(i \neq k\)일 때 \(x_i - x_k < 0\)이다.
낮은 온도 (\(T \to 0\)): \(i \neq k\)인 항에서 \((x_i - x_k)/T \to -\infty\)이므로 \(\exp(\cdot) \to 0\)이다. 결과적으로 최대 로짓 토큰만 확률 1에 가까워지고, 나머지는 0에 수렴한다. 분포가 **뾰족(spiky)**해진다. \(T = 0\)이면 이론적으로 탐욕적 디코딩과 동일하며 출력이 결정론적이 된다.
높은 온도 (\(T \to \infty\)): 모든 항에서 \((x_j - x_k)/T \to 0\)이므로 \(\exp(\cdot) \to 1\)이다. 모든 토큰의 확률이 \(1/|V|\)에 가까워져 균일 분포가 된다.
온도 |
분포 형태 |
출력 특성 |
용도 |
|---|---|---|---|
\(T \to 0\) |
극도로 뾰족 |
결정론적, 가장 높은 확률 토큰만 선택 |
정확성이 중요한 과제 |
\(T\) 낮음 |
뾰족 |
예측 가능하고 보수적 |
코드 생성, 사실 기반 응답 |
\(T\) 높음 |
평탄 |
다양하고 창의적 |
창작, 브레인스토밍 |
\(T \to \infty\) |
균일 |
완전 무작위 |
실용적으로 사용하지 않음 |
비결정성의 근원: 트랜스포머 아키텍처 내부의 모든 연산은 결정론적이다. 비결정론적인 유일한 부분은 토큰 샘플링이다. 따라서 양의 온도(\(T > 0\))를 사용하면 동일한 입력에 대해 매번 다른 출력이 생성된다.
실무적 참고: 이론적으로 \(T = 0\)이면 완전히 결정론적이어야 하지만, 실제로는 GPU 하드웨어에서 부동소수점 연산의 축약(reduction) 순서 차이로 인해 미세한 비결정성이 발생할 수 있다. 서로 다른 스케일의 수를 축약할 때 연산 순서가 결과에 영향을 미치기 때문이다. 이에 대한 자세한 내용은 "Defeating Non-Determinism in LLM Inference" 논문을 참고하라.
3.5 가이드 디코딩 (Guided Decoding)
LLM의 출력을 JSON 같은 특정 형식으로 강제해야 하는 경우가 있다. 순진한 접근법은 "JSON 형식으로 출력하라"는 프롬프트를 주고, 유효한 JSON이 나올 때까지 반복 생성하는 것이다.
가이드 디코딩(guided decoding) 또는 **제약 디코딩(constrained decoding)**은 생성 과정에서 문법적으로 유효하지 않은 다음 토큰을 필터링하는 방법이다.
예를 들어 JSON을 생성할 때:
- 첫 토큰은 반드시 {여야 한다.
- 다음에는 속성 이름(문자열)이 와야 한다.
- 속성 이름 뒤에는 :이 와야 한다.
각 단계에서 허용되는 토큰이 하나뿐이면 그것을 선택하고, 여러 개가 허용되면 기존의 디코딩 전략(샘플링, top-K 등)을 적용한다.
이 기법은 유한 상태 기계(Finite State Machine, FSM)와 문맥 자유 문법(Context-Free Grammar) 기반의 논문들에서 구체적인 구현 방법을 다루고 있다.
3.6 프롬프팅 전략
LLM이 원하는 작업을 수행하도록 유도하는 입력을 **프롬프트(prompt)**라 한다. 프롬프트의 길이는 토큰 수로 측정하며, 이를 컨텍스트 길이(context length), 컨텍스트 크기, 윈도우 크기 등으로 부른다.
현대 LLM의 컨텍스트 길이는 수만에서 수백만 토큰에 달한다. Gemini 등 일부 모델은 100만 토큰 이상을 지원한다.
컨텍스트 로트 (Context Rot)
컨텍스트가 길다고 해서 모든 문제가 해결되는 것은 아니다. 최근 연구에서 **컨텍스트 로트(context rot)**라 불리는 현상이 보고되었다. "바늘 찾기(needle in a haystack)" 테스트에서, 컨텍스트가 길어질수록 모델이 특정 정보를 검색하는 능력이 저하된다. 특히 관련 없는 텍스트(방해자, distractors)가 컨텍스트에 포함되면 검색 성능이 더욱 떨어진다. 따라서 검색 기반 과제에서는 LLM에 제공하는 컨텍스트를 가능한 한 정확하게 타겟팅하는 것이 중요하다.
프롬프트의 구조
프롬프트에 대한 공식적 이론은 없지만, 일반적으로 네 가지 구성 요소로 분해할 수 있다.
구성 요소 |
설명 |
예시 |
|---|---|---|
컨텍스트 |
배경 설정 |
"당신은 ChatGPT입니다. 현재 2025년 10월 10일입니다." |
지시사항 |
수행할 작업 |
"아래 텍스트를 요약하시오." |
입력 |
처리할 데이터 |
요약할 원본 텍스트 |
제약 조건 |
출력 형식이나 안전 지침 |
"해로운 콘텐츠를 생성하지 마시오." |
인컨텍스트 학습 (In-Context Learning)
LLM의 가중치를 전혀 조정하지 않으면서도, 프롬프트에 정보를 포함하는 것만으로 원하는 작업을 수행하게 만드는 방법이다. "학습"이라는 용어가 포함되어 있지만, 가중치에 대한 실질적 학습은 일어나지 않는다.
제로샷 (Zero-shot): 예시를 제공하지 않고 지시사항만으로 작업을 수행하게 한다.
입력: "이 테디베어는 몇 살인가?"
출력: "3살이다."
퓨샷 (Few-shot): 입력-출력 예시 쌍을 하나 이상 제공한 뒤, 원하는 입력에 대한 출력을 요청한다.
예시 1: 테디 → "테디는 숲에서 꿀을 찾아 모험을 떠났다..."
예시 2: 밥 → "밥은 비 오는 날 창가에 앉아..."
질문: 루나 → ?
일반적으로 퓨샷이 제로샷보다 성능이 높다. 예시가 모델에게 과제의 형식과 기대 출력을 명확히 전달하기 때문이다. 그러나 최근의 추론 능력이 강화된 모델에서는 반드시 그렇지 않다. 지시사항을 추론 기반(reasoning-based)으로 잘 작성하면, 제로샷으로도 퓨샷과 동등하거나 더 나은 성능을 달성할 수 있다. 유한한 예시에 모델이 과적합되는 것보다, 자연어로 과제 수행 방법을 설명하면 모델의 추론 능력을 더 잘 활용할 수 있기 때문이다. "Plan and Solve" 등의 논문에서 이러한 접근법의 효과를 보고하고 있다.
3.7 사고의 연쇄와 자기 일관성
사고의 연쇄 (Chain-of-Thought, CoT)
모델이 최종 답변을 내놓기 전에 **추론 과정(rationale)**을 먼저 생성하도록 유도하는 기법이다. 연구자들은 모델이 단계적으로 사고하게 하면 성능이 향상된다는 것을 발견했다.
직접 응답 (CoT 없이):
Q: 테디베어는 몇 살인가?
A: 3살
사고의 연쇄 (CoT 적용):
Q: 테디베어는 몇 살인가?
A: 테디베어는 2022년에 만들어졌다. 현재 2025년이다.
따라서 2025 - 2022 = 3. 테디베어는 3살이다.
CoT의 장점은 두 가지다.
- 성능 향상: 중간 추론 단계를 거치면서 모델이 더 정확한 답에 도달한다. 특히 산술 및 수학 과제에서 효과가 크다.
- 디버깅 용이: 추론 과정이 텍스트로 출력되므로, 잘못된 답변의 원인을 추적할 수 있다. 예를 들어 "현재 2019년"이라는 추론이 보이면, 컨텍스트에 잘못된 날짜 정보가 있음을 알 수 있다. 기존의 가중치 분석과 달리 해석 가능한 디버깅이 가능하다.
퓨샷 설정에서 CoT를 적용하면, 예시에 추론 과정을 포함하여 모델이 동일한 형식으로 응답하도록 유도할 수 있다. 트레이드오프는 생성해야 할 토큰 수가 늘어나므로 추론 시간이 증가한다는 점이다.
자기 일관성 (Self-Consistency)
CoT를 더 강화하는 기법이다. 동일한 질문에 대해 모델을 여러 번 샘플링하여 다수의 응답을 생성한 뒤, 각 응답에서 최종 답변을 추출하고 **다수결 투표(majority voting)**로 최종 답을 결정한다.
샘플 1: "... 따라서 답은 3이다." → 3
샘플 2: "... 그러므로 3살이다." → 3
샘플 3: "... 결론적으로 4살이다." → 4
다수결: 3 (2/3)
각 샘플링은 병렬로 수행되므로, 전체 지연 시간은 가장 오래 걸리는 단일 생성의 시간과 대략 같다. 각 샘플은 서로의 컨텍스트에 포함되지 않으며 독립적이다.
답변을 추출하는 방법으로는 "최종 답변을 마지막에 배치하라"는 지시사항을 추가한 뒤 정규식(regex)으로 파싱하거나, 별도의 LLM을 사용하여 추출하는 방식이 있다. 이 기법의 효과를 검증하려면 벤치마크와 정답 레이블이 필요하다. 원 논문은 산술 및 수학 벤치마크에서 성능 향상을 보고했다.
3.8 추론 최적화: KV 캐시
LLM 추론의 효율성을 높이는 기법은 두 범주로 나뉜다.
범주 |
설명 |
기법 |
|---|---|---|
정확 기법 (Exact) |
동일한 연산을 더 효율적으로 수행 |
KV 캐시, PagedAttention, MLA |
근사 기법 (Approximate) |
약간의 품질 트레이드오프로 속도 향상 |
투기적 디코딩, 멀티토큰 예측 |
KV 캐시의 원리
마스크드 셀프 어텐션에서 현재 토큰은 이전의 모든 토큰에 어텐드해야 한다. 시퀀스 "a cute teddy bear is"를 생성 중이고 현재 토큰이 "is"라면:
- "is"의 쿼리(Q), 키(K), 값(V)을 계산해야 한다.
- 이전 토큰들("a", "cute", "teddy", "bear")의 K와 V도 필요하다.
- 그러나 이전 토큰들의 Q는 현재 토큰의 어텐션 계산에 필요하지 않다.
**KV 캐시(KV Cache)**는 이전 토큰들의 키와 값 행렬을 저장(cache)하고, 새 토큰을 생성할 때 캐시에서 직접 가져와 재사용하는 기법이다. 이를 통해 이전 토큰의 K, V를 매번 다시 계산하는 중복 연산을 완전히 제거한다.
KV 캐시는 추론 시에만 사용된다. 훈련 시에는 교사 강제(teacher forcing)로 모든 입력을 한꺼번에 처리하므로 KV 캐시가 필요하지 않다.
그룹 쿼리 어텐션 (GQA)과의 결합
멀티헤드 어텐션에서 H개의 헤드는 각각 독립적인 Q, K, V 투영을 가진다. 이는 H세트의 K, V를 캐시해야 함을 의미한다. 2장에서 다룬 **그룹 쿼리 어텐션(Grouped Query Attention, GQA)**을 적용하면 K, V의 수를 줄여 캐시 크기를 줄일 수 있다.
- 멀티헤드 어텐션: H개의 Q, K, V (H=KV 헤드 수)
- GQA: H개의 Q, G개의 K와 V (G < H)
- 멀티쿼리 어텐션: H개의 Q, 1개의 K와 V
현대 LLM의 대부분이 GQA를 적절한 그룹 수로 사용한다.
3.9 PagedAttention
KV 캐시를 나이브하게 관리하면 메모리 낭비가 심각하다. 추론 서버가 여러 사용자의 요청을 처리할 때, 각 요청에 대해 최대 컨텍스트 길이 전체만큼의 메모리를 미리 할당해야 한다. EOS 토큰이 언제 나올지 모르기 때문이다.
예를 들어 최대 컨텍스트 길이가 2K 토큰이면, 각 요청에 2K 토큰 분량의 메모리가 예약된다. 실제로 생성된 토큰이 100개라도 2K 전체가 점유된다. 이는 세 가지 낭비를 초래한다.
낭비 유형 |
설명 |
|---|---|
예약 공간 |
실제 사용된 토큰에 해당하는 메모리 |
내부 단편화(Internal Fragmentation) |
예약되었으나 아직 사용되지 않은 공간 |
외부 단편화(External Fragmentation) |
메모리 할당 시스템의 블록 배치로 인한 빈 공간 |
PagedAttention은 이 문제를 해결하기 위해 고안된 기법으로, vLLM 추론 패키지의 핵심 기술이다. 핵심 아이디어는 전체 컨텍스트에 대한 연속적인 메모리 블록 대신, 고정 크기의 작은 블록(논문에서는 16 토큰)으로 나누어 관리하는 것이다.
- 생성이 진행되면서 하나의 블록이 차면 새 블록을 할당한다.
- 토큰 위치 인덱스를 캐시 값에 매핑하는 딕셔너리를 유지한다.
- 운영체제의 가상 메모리 페이징과 유사한 개념이다.
이 방식으로 내부 및 외부 단편화를 대폭 줄여, 동일 메모리에서 더 많은 동시 요청을 처리할 수 있다.
3.10 멀티래턴트 어텐션 (Multi-Latent Attention, MLA)
KV 캐시의 크기를 더 근본적으로 줄이는 방법이다. 멀티헤드 어텐션에서 각 토큰은 H개의 헤드에 대한 K, V 벡터를 가지며, 이를 모든 트랜스포머 블록에 걸쳐 저장해야 한다. 저장해야 할 벡터의 수가 막대하다.
DeepSeek가 제안한 **멀티래턴트 어텐션(Multi-Latent Attention, MLA)**은 투영 행렬을 저차원 중간 공간으로 분해한다.
기존 멀티헤드 어텐션:
토큰 표현 → W_k^(h) → K^(h) (h = 1, ..., H)
토큰 표현 → W_v^(h) → V^(h) (h = 1, ..., H)
캐시: H개의 K + H개의 V = 2H개 벡터/토큰
MLA:
토큰 표현 → W_compress (공유) → 저차원 잠재 표현 (캐시 대상)
저차원 잠재 표현 → W_dk^(h) → K^(h)
저차원 잠재 표현 → W_dv^(h) → V^(h)
캐시: 1개 잠재 벡터/토큰
핵심 설계 결정: 1. 압축 행렬이 K와 V 간에 공유된다: 하나의 저차원 잠재 표현에서 K와 V 모두를 복원할 수 있다. 2. 압축 행렬이 모든 헤드 간에 공유된다: H개의 헤드에 대해 하나의 잠재 표현만 저장하면 된다. 3. 복원 행렬은 헤드별로 다르다: K와 V의 서로 다른 표현은 복원 단계에서 학습된다.
결과적으로 트랜스포머 블록당 토큰 하나에 대해 단일 저차원 벡터만 캐시하면 된다. 저차원의 크기는 설계 선택이며 고정된 하이퍼파라미터다.
DeepSeek-V2 논문은 캐시 크기 감소뿐만 아니라 성능 향상도 보고했다. 이는 공유 압축이 일종의 정규화 효과를 가져, K와 V에 대해 더 유용하고 공유 가능한 표현을 학습하게 되기 때문으로 해석된다.
3.11 투기적 디코딩과 멀티토큰 예측
투기적 디코딩 (Speculative Decoding)
LLM 추론은 **메모리 바운드(memory-bound)**다. 연산 자체가 아니라 메모리 접근이 병목이므로, 여러 토큰을 동시에 처리해도 단일 토큰 처리와 비용이 비슷하다. 이 성질을 활용한 것이 투기적 디코딩이다.
과정: 1. 작은 모델(초안 모델, draft model)이 여러 토큰을 빠르게 생성한다.
"my teddy bear" → "is" → "cute" → "and" → "smart"
- 생성된 토큰들을 한꺼번에 큰 모델(타겟 모델, target model)에 입력하여, 각 위치에서의 확률 분포를 단일 순방향 전파로 계산한다.
-
각 토큰에 대해 수용/거부 판정을 수행한다.
- 타겟 모델의 확률이 초안 모델의 확률 이상이면: 수용
- 그렇지 않으면: 수용 확률 \(P_{target}/P_{draft}\)로 확률적 수용/거부 (거부 샘플링)
- 수용된 토큰까지 채택하고, 거부된 토큰부터 타겟 모델의 분포로 재생성한다.
이 방식이 타겟 모델의 분포를 정확히 재현하는 이유는 전체 확률의 법칙(law of total probability)에 기반한다. 논문에서 수 줄의 간결한 증명으로 이를 보인다.
또한 초안 토큰의 마지막 위치까지 타겟 모델에 입력하면, 그다음 위치의 확률 분포를 "무료로" 얻을 수 있어 추가 토큰 생성에 활용한다.
멀티토큰 예측 (Multi-Token Prediction)
투기적 디코딩과 유사하지만, 초안 모델과 타겟 모델이 동일한 모델에 내장되어 있다. 마지막 디코더 블록의 표현 위에 여러 개의 예측 헤드를 부착한다.
- 훈련 시: 다음 단어 예측이 아닌 여러 단어 동시 예측을 목적 함수로 사용한다.
- 추론 시: 첫 번째 헤드가 타겟 모델, 나머지 헤드들이 초안 모델의 역할을 한다. 나머지 헤드들이 생성한 토큰을 첫 번째 헤드에 피드백하여 수용/거부를 판정한다.
이 논문에서는 목적 함수가 변경되었으므로 기존의 거부 샘플링 공식이 정확히 적용되지 않아, 탐욕적(greedy) 방식으로 수용/거부를 수행한다. 핵심 장점은 별도의 초안 모델을 유지할 필요 없이 단일 모델 내에서 투기적 디코딩의 이점을 누릴 수 있다는 점이다.
핵심 정리
개념 |
핵심 |
|---|---|
LLM 정의 |
언어 모델 + 대규모: 수십억 파라미터, 수조 토큰, 대규모 연산 |
디코더 전용 |
현대 LLM의 90% 이상. 마스크드 셀프 어텐션 + FFN + Add&Norm |
MoE |
FFN을 여러 전문가로 분할. 게이트가 입력별로 전문가 선택. 희소 MoE는 top-K만 활성화 |
라우팅 붕괴 |
특정 전문가만 사용되는 문제. 보조 손실로 균일 분포 유도 |
디코딩 전략 |
탐욕적(결정론적), 빔 서치(K경로), 샘플링(top-K/top-P) |
온도 |
낮으면 뾰족(결정론적), 높으면 균일(창의적). 소프트맥스의 스케일링 파라미터 |
가이드 디코딩 |
FSM/문법 기반으로 유효하지 않은 토큰 필터링. JSON 등 구조화된 출력 보장 |
프롬프팅 |
제로샷 vs 퓨샷. 인컨텍스트 학습으로 가중치 변경 없이 과제 수행 |
CoT / 자기 일관성 |
추론 과정을 출력하여 성능 향상. 다수결 투표로 강건성 확보 |
KV 캐시 |
이전 토큰의 K, V를 저장하여 중복 연산 제거. 추론 전용 |
PagedAttention |
메모리를 고정 크기 블록으로 관리하여 단편화 감소 |
MLA |
K, V 투영을 저차원 잠재 공간으로 압축. 캐시 크기 극적 감소 |
투기적 디코딩 |
작은 모델이 초안 생성, 큰 모델이 검증. 거부 샘플링으로 분포 보존 |
다음 장: 4장 - LLM 훈련