6장 - LLM 추론
6장. LLM 추론
추론 모델의 핵심은 단순하다. 답을 바로 내놓지 말고, 먼저 생각하라. 그리고 그 "생각"을 RL로 학습시켜라. 검증 가능한 보상만 있으면 가치 함수 없이도 작동한다. — 아프신 아미디
6.1 바닐라 LLM의 한계
5장까지 다룬 LLM 파이프라인을 복습하자. 1단계 사전 훈련에서 모델은 텍스트와 코드의 구조를 학습한다. 2단계 지도 미세 조정(SFT)에서 특정 과제에 맞게 행동하도록 가르친다. 3단계 선호도 튜닝에서 인간의 선호에 정렬한다. 이 과정을 거친 모델을 **바닐라 LLM(vanilla LLM)**이라 부른다.
바닐라 LLM에는 분명한 강점이 있다. 코드 디버깅에 뛰어나고, 에세이나 시를 생성하는 데 능숙하며, 텍스트의 구조를 잘 파악한다. 하지만 다음과 같은 약점이 존재한다.
첫째, 제한된 추론 능력이다. 복잡한 수학 문제를 제시하면 모델이 올바른 해법에 도달하지 못하는 경우가 많다. 바닐라 LLM은 다음 토큰 예측으로 훈련되었을 뿐, 다단계 추론을 체계적으로 수행하도록 설계되지 않았다.
둘째, 지식의 정적 특성이다. 사전 훈련 데이터의 컷오프 날짜 이후 발생한 사건에 대해서는 답할 수 없다.
셋째, 행동 불능이다. 바닐라 LLM은 주문을 넣거나 파일을 수정하는 등의 실제 행동을 취할 수 없다.
넷째, 평가의 어려움이다. 전통적인 NLP 모델은 BLEU(번역)나 ROUGE(요약) 같은 규칙 기반 메트릭으로 평가했다. 하지만 LLM은 자유 형식 텍스트를 생성하므로 이러한 고정된 메트릭이 적합하지 않다.
이 중 둘째부터 넷째까지의 약점은 7장과 8장에서 다룬다. 이번 장의 초점은 첫째, 즉 추론(reasoning) 능력의 향상이다.
6.2 추론이란 무엇인가
추론에 대해 보편적으로 합의된 정의는 아직 없다. 이 강의에서는 추론을 다단계 과정을 통해 문제를 해결하는 능력으로 정의한다. 여기서 "문제"란 주로 수학 문제나 코딩 문제처럼 정답이 명확한 과제를 가리키지만, 이러한 능력은 다른 영역으로도 확장될 수 있다.
추론 과제와 비추론 과제의 구분을 예시로 보자.
- 비추론 질문: "스탠퍼드의 트랜스포머와 LLM 강의의 과목 코드는?" → 이것은 지식(knowledge)의 문제다. 답은 CME 295다.
- 추론 질문: "2020년에 태어난 곰이 2025년 현재 몇 살인가?" → 이것은 추론의 문제다. 2025 - 2020 = 5라는 단계를 거쳐야 한다.
물론 이 예시는 극히 단순하다. 실제 추론 벤치마크에서 다루는 문제는 이보다 훨씬 복잡하다.
6.3 추론 모델의 핵심 아이디어
추론 모델의 핵심은 2장이나 3장에서 다룬 연쇄 사고(chain-of-thought, CoT) 기법을 대규모로 적용하는 것이다. CoT의 아이디어는 모델이 최종 답을 내놓기 전에 단계별로 사고 과정을 명시하도록 유도하는 것이었다. 추론 모델은 이 원리를 모델의 근본적인 행동으로 내재화한다.
바닐라 LLM에서는 입력(프롬프트)이 주어지면 바로 출력(답변)을 생성한다. 반면 추론 모델에서는 입력이 주어지면 먼저 추론 체인(reasoning chain)을 생성하고, 그 후에 답변을 생성한다. 즉, 출력은 추론 체인 + 답변의 결합이다.
이것이 효과적인 이유에 대한 직관은 두 가지다.
첫째, 문제 분해다. LLM은 다음 토큰 예측을 최적화하도록 훈련되었다. 매우 어려운 문제가 입력되면, 그 문제가 훈련 데이터에 그대로 등장했을 확률은 낮다. 하지만 문제를 더 작고 다루기 쉬운 하위 문제로 분해하면, 각 하위 문제는 훈련 시 접한 패턴과 유사할 가능성이 높다. 시험을 치를 때 어려운 문제를 만나면 공부한 내용과 연결지어 풀듯이, 모델도 같은 전략을 취하는 것이다.
둘째, 추가 연산의 확보다. 모델이 더 많은 토큰을 생성하도록 허용하면, 그만큼 더 많은 포워드 패스가 수행된다. 이는 모델에게 더 많은 연산(compute)을 부여하는 것과 같다. 이와 관련하여 **연산 예산(compute budget)**이라는 용어가 사용되는데, 모델이 응답을 생성하기 위해 사용할 수 있는 연산량의 한도를 뜻한다.
추론 모델의 타임라인
추론 모델은 매우 최근의 발전이다. 핵심적인 이정표는 다음과 같다.
시기 |
사건 |
|---|---|
2024년 9월 |
OpenAI가 o1-preview를 출시. 추론 모델 시대의 개막 |
2024년 12월 |
Google이 Gemini 2.0 Flash Thinking을 출시 |
2025년 1월 |
DeepSeek가 R1 논문을 공개. OpenAI 수준의 추론 성능을 재현하며, 방법론을 상세히 기술하여 큰 반향을 일으킴 |
2025년 이후 |
xAI(Grok), Anthropic(Claude), Mistral 등 다수의 연구소가 자사 모델에 추론 능력을 추가 |
추론 모델의 사용자 인터페이스
ChatGPT, Gemini 등의 인터페이스에서 "사고 중(thinking)"이라는 표시를 본 적이 있을 것이다. 이 시간은 모델이 추론 체인을 생성하는 데 소요되는 시간이다. 사용자에게 보이는 "사고 요약(thought summary)"은 원시 추론 체인 자체가 아니라 그것의 요약본이다. 원시 체인을 그대로 보여주지 않는 이유는 세 가지로 추정된다.
- 원시 추론 체인이 인간에게 완전히 이해 가능한 형태가 아닐 수 있다.
- 사용자가 수 페이지 분량의 추론 과정을 읽고 싶어 하지 않는다.
- 추론 체인이 공개되면, 경쟁자가 이를 훈련 데이터로 사용하여 유사한 능력을 복제할 수 있다.
API 과금 측면에서, 추론 토큰은 출력 토큰에 포함되어 과금된다. 사용자에게 추론 체인 전체가 반환되지 않더라도, API 문서에는 출력 토큰에 추론 토큰이 포함된다고 명시되어 있다. 따라서 사용자 입장에서는 최소한의 추론 토큰으로 최대의 추론 성능을 달성하는 것이 경제적이며, 제공자 입장에서도 효율성을 높이는 것이 유리하다.
6.4 추론 벤치마크
추론 능력을 정량적으로 평가하기 위한 벤치마크는 크게 코딩과 수학 두 영역으로 나뉜다.
코딩 벤치마크
코딩 벤치마크의 목표는 코딩 문제를 풀거나 버그를 수정하는 것이다. 평가 구조는 다음과 같다. 문제가 주어지면 모델이 솔루션을 생성하고, 이 솔루션이 테스트 케이스를 모두 통과하는지 검증한다. 통과하면 정답, 실패하면 오답이다.
대표적인 코딩 벤치마크는 다음과 같다.
벤치마크 |
설명 |
|---|---|
HumanEval |
인간이 직접 작성한 약 164개의 코딩 문제 세트. 이름의 유래가 "인간이 작성한(human-written)" 문제라는 뜻이다 |
Codeforces |
경쟁 프로그래밍 웹사이트에서 가져온 문제들. 난이도가 높다 |
SWE-bench |
GitHub 이슈에서 파생된 실제적인(practical) 소프트웨어 엔지니어링 문제 세트 |
수학 벤치마크
수학 벤치마크의 목표는 수학 문제의 정답을 맞히는 것이다. 모델이 추론 체인과 함께 답을 생성하면, 답을 파싱하여 정답(ground truth)과 비교한다. 파싱을 위해 프롬프트에서 특정 형식(예: 박스 괄호 안에 답을 넣기)으로 출력하도록 지시한다.
벤치마크 |
설명 |
|---|---|
AIME |
미국 수학 올림피아드 예선 시험(American Invitational Mathematics Examination) 문제. 난이도가 상당히 높다 |
GSM8K |
초등학교 수준의 수학 문제(Grade School Math 8K) 약 8,000개로 구성. AIME보다 쉽지만 기본적인 추론 능력을 측정한다 |
6.5 pass@k 메트릭
추론 벤치마크에서 가장 널리 사용되는 메트릭은 pass@k다. 정의는 다음과 같다.
pass@k는 \(k\)번의 시도 중 적어도 하나가 성공할 확률을 추정하는 메트릭이다.
코딩 문제를 예로 들면, 모델에게 \(k\)개의 답을 생성하게 한 뒤 그중 하나라도 테스트 케이스를 통과하면 성공으로 간주한다.
pass@k가 유용한 이유는 실용적이다. 코딩처럼 정답 여부를 자동으로 검증할 수 있는 과제에서는, 하나의 답만 생성하는 대신 여러 답을 생성하여 그중 올바른 것을 선택할 수 있다. 더 많은 시도에 더 많은 연산을 투입할 여유가 있다면, 정답을 얻을 확률이 높아진다. 이는 5장에서 다룬 Best-of-N과 유사하지만, 보상 모델 대신 결정론적이고 검증 가능한 방법(테스트 케이스 통과, 정답 일치)으로 정답 여부를 판단한다는 차이가 있다.
pass@k의 추정 공식
pass@k를 단순히 \(k\)번 시도하여 성공 비율을 세면 추정치의 분산이 클 수 있다. 따라서 실제로는 \(k\)보다 많은 \(n\)개의 답을 생성하고, 그중 \(c\)개가 성공, \(n - c\)개가 실패했다고 하자. 이 \(n\)개 중 \(k\)개를 무작위로 뽑았을 때 적어도 하나가 성공할 확률을 구한다.
유도 과정은 다음과 같다. "적어도 하나가 성공"할 확률은 1에서 "모두 실패"할 확률을 빼면 된다.
\[\text{pass@k} = 1 - P(\text{k개 시도가 모두 실패})\]
\(n\)개 중 실패한 것은 \(n - c\)개다. \(k\)개를 비복원 추출(sampling without replacement)할 때 모두 실패인 경우의 확률은 다음과 같다.
\[P(\text{모두 실패}) = \frac{n-c}{n} \cdot \frac{n-c-1}{n-1} \cdots \frac{n-c-k+1}{n-k+1}\]
이를 조합(combination) 표기로 정리하면 다음과 같다.
\[\boxed{\text{pass@k} = 1 - \frac{\binom{n-c}{k}}{\binom{n}{k}}}\]
여기서 \(\binom{n}{k} = \frac{n!}{k!(n-k)!}\)이다.
특수 경우: pass@1. \(k = 1\)을 대입하면 공식이 크게 단순화된다.
\[\text{pass@1} = 1 - \frac{n - c}{n} = \frac{c}{n}\]
이는 단순히 성공 비율, 즉 직관적으로 기대하는 값과 일치한다.
온도와 pass@k의 관계
pass@k를 측정할 때 모델의 생성 온도(temperature)가 결과에 큰 영향을 미친다.
- 온도가 너무 낮으면 (\(T \approx 0\)): 생성된 답이 거의 동일하다. 다양성이 없으므로 \(k\)를 늘려도 pass@k가 거의 개선되지 않는다.
- 온도가 너무 높으면 (\(T \gg 1\), 예: \(T = 1.2\)): 다양성은 확보되지만, 확률이 낮은 토큰이 과도하게 선택되어 개별 답의 품질이 저하된다.
- 적절한 온도 (예: \(T = 0.4 \sim 0.8\)): 다양성과 품질의 균형이 맞아 pass@k가 가장 높다.
따라서 논문에서 pass@k 벤치마크 결과를 보고할 때는 반드시 사용한 온도를 명시한다.
consensus@k
pass@k 외에 consensus@k라는 메트릭도 있다. \(k\)개의 생성물 중 가장 빈번하게 등장하는 답을 최종 답으로 선택하는 방식이다. 이는 자기 일관성(self-consistency) 기법과 밀접하게 관련된다. 그 외에도 정확도(accuracy), 정확 일치(exact match) 등 전통적인 메트릭도 함께 사용된다.
6.6 RL을 통한 추론 능력 확장
이제 추론 모델을 실제로 어떻게 구축하는지 살펴보자. 모델이 추론 체인을 생성하도록 가르치려면 어떻게 해야 할까?
SFT가 아닌 RL을 선택하는 이유
추론 체인을 학습시키는 데 SFT를 사용하지 않는 이유는 세 가지다.
첫째, 고품질 데이터 부재다. SFT에는 고품질의 (프롬프트, 추론 체인 + 답변) 쌍이 필요하다. 하지만 긴 추론 체인을 인간이 처음부터 작성하는 것은 극히 어렵고 비용이 높다.
둘째, 모델의 추론 방식은 인간과 다를 수 있다. 인간이 작성한 추론 체인이 모델에게 최적의 추론 방식이라는 보장이 없다. 모델은 자기 고유의 추론 패턴을 발전시킬 수 있다.
셋째, 검증 가능한 보상 신호가 존재한다. 코딩에서는 테스트 케이스 통과 여부로, 수학에서는 정답 일치 여부로 솔루션의 정확성을 자동 검증할 수 있다. 보상 신호가 자연스럽게 존재하므로, RL을 적용할 수 있는 이상적인 조건이다.
RL 보상 설계
추론 모델의 RL 훈련에서 보상은 두 가지 요소의 결합이다.
- 형식 보상(format reward): 모델이
<think>...</think>토큰 안에 추론 체인을 생성했는지 확인한다. - 정확도 보상(accuracy reward): 모델이 생성한 최종 답이 정답과 일치하는지 확인한다.
두 보상 모두 결정론적이고 검증 가능하다. 별도의 보상 모델 훈련이 필요 없다. 이것이 5장에서 다룬 선호도 튜닝의 보상 모델 기반 접근법과의 핵심적인 차이다.
이러한 보상으로 RL을 수행하면, AIME 같은 수학 벤치마크에서 모델의 성능이 RL 스텝에 따라 유의미하게 증가하는 것을 관찰할 수 있다. DeepSeek R1-Zero의 훈련 그래프가 이를 명확하게 보여준다.
연산 예산 제어
모든 프롬프트가 동일한 수준의 사고를 요구하지는 않는다. 간단한 질문에 과도한 추론 체인을 생성하는 것은 비효율적이다. 이와 관련된 연구 방향은 다음과 같다.
- 동적 예산(dynamic budget): 프롬프트의 난이도를 분류하여, 어려운 문제에는 더 긴 추론을, 쉬운 문제에는 짧은 추론을 할당한다.
- 컨텍스트 인식: LLM의 컨텍스트 윈도가 유한하므로, 추론 체인이 남은 컨텍스트 길이를 초과하지 않도록 관리해야 한다.
- 예산 강제(budget forcing): S1 논문에서 도입된 개념이다. 모델의 사고를 더 이어가게 하려면 "Wait"과 같은 토큰을 삽입하여 추가 추론 경로를 탐색하도록 유도한다. 반대로 사고를 멈추게 하려면 "Okay, your time is up. My answer is..."와 같은 토큰을 삽입한다.
- 연속적 사고(continuous thoughts): 추론 체인을 언어 토큰이 아닌 은닉 표현(hidden representation)으로 수행하는 연구 방향이다. 토큰보다 더 의미 있고 압축된 표현이 가능하며, 현재 활발한 연구가 진행 중이다.
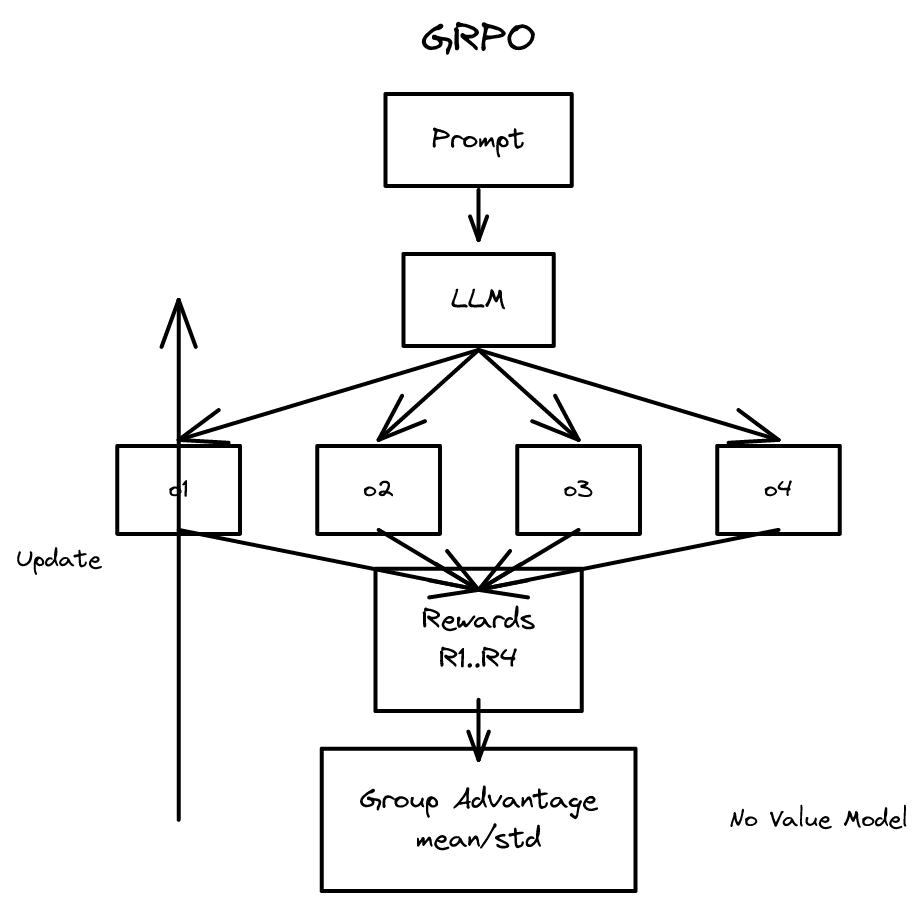
6.7 GRPO (Group Relative Policy Optimization)
RL 단계에서 사용되는 핵심 알고리즘이 **GRPO(Group Relative Policy Optimization)**다. GRPO는 2024년 DeepSeek 팀이 "DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models" 논문에서 제안했으며, 추론 기반 RL 훈련의 사실상의 표준이 되었다.
GRPO의 목적
GRPO는 PPO와 마찬가지로 두 가지를 동시에 달성하려 한다.
- 어드밴티지 최대화: 현재 생성한 출력이 기대 수준보다 얼마나 더 좋은지를 나타내는 어드밴티지를 최대화한다.
- 모델 이탈 제한: 현재 정책이 이전 반복의 정책(old model)이나 기준 모델(reference model, SFT 모델)에서 너무 벗어나지 않도록 한다.
핵심적인 차이는 어드밴티지의 계산 방식에 있다.
PPO의 어드밴티지 vs GRPO의 어드밴티지
PPO에서는 어드밴티지를 보상(completion 수준)과 **가치 함수(value function, 토큰 수준)**를 결합하여 추정한다. 가치 함수는 현재 정책을 따라 생성을 계속했을 때 최종적으로 받게 될 보상을 예측하는 별도의 모델이다. 이 두 값을 **일반화 어드밴티지 추정(GAE, Generalized Advantage Estimation)**이라는 복잡한 공식에 입력하여 어드밴티지를 구한다.
GRPO는 가치 함수를 완전히 제거한다. 대신, 하나의 프롬프트에 대해 \(G\)개의 완성(completion)을 생성하고, 각 완성의 보상을 그룹 내 다른 완성들의 보상과 비교하여 어드밴티지를 계산한다.
\[\hat{A}_i = \frac{r_i - \text{mean}(r_1, \ldots, r_G)}{\text{std}(r_1, \ldots, r_G)}\]
여기서 \(r_i\)는 \(i\)번째 완성의 보상이다. 이것이 "Group Relative"라는 이름의 유래다. 그룹 내 상대적 위치가 곧 어드밴티지다.
직관은 명확하다. 쉬운 문제에서 정답을 맞히면 그룹 내 대부분이 정답이므로 어드밴티지가 크지 않다. 반면 어려운 문제에서 정답을 맞히면 그룹 내 소수만 정답이므로 어드밴티지가 크다. 문제의 난이도가 자연스럽게 반영된다.
GRPO 손실 함수
GRPO의 목적 함수를 전체적으로 쓰면 다음과 같다.
\[J_\text{GRPO} = \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \left[ \min\left( \frac{\pi_\theta(o_{i,t} | q, o_{i,<t})}{\pi_{\theta_\text{old}}(o_{i,t} | q, o_{i,<t})} \hat{A}_i,\; \text{clip}\left(\frac{\pi_\theta(o_{i,t} | q, o_{i,<t})}{\pi_{\theta_\text{old}}(o_{i,t} | q, o_{i,<t})}, 1-\epsilon, 1+\epsilon\right) \hat{A}_i \right) - \beta \, D_\text{KL}(\pi_\theta \| \pi_\text{ref}) \right]\]
여기서: - \(G\): 그룹 내 완성의 수 - \(|o_i|\): \(i\)번째 완성의 토큰 수 - \(\pi_\theta\): 현재 정책 (훈련 중인 LLM) - \(\pi_{\theta_\text{old}}\): 이전 RL 반복의 정책 - \(\pi_\text{ref}\): 기준 모델 (SFT 모델) - \(\hat{A}_i\): \(i\)번째 완성의 그룹 상대 어드밴티지 - \(\epsilon\): 클리핑 범위 - \(\beta\): KL 발산 페널티의 강도
이중 합산의 의미는 다음과 같다. 바깥쪽 합산(\(\sum_{i=1}^{G}\))은 그룹 내 모든 완성을 순회한다. 안쪽 합산(\(\sum_{t=1}^{|o_i|}\))은 각 완성 내 모든 토큰을 순회한다.
6.8 GRPO와 PPO의 비교
구조적 유사점
- 확률 비율 기반: 두 알고리즘 모두 현재 정책과 이전 정책 간의 확률 비율 \(r(\theta) = \pi_\theta / \pi_{\theta_\text{old}}\)을 기반으로 작동한다.
- 클리핑 메커니즘: 갱신 폭이 \([1 - \epsilon, 1 + \epsilon]\) 범위를 벗어나지 않도록 클리핑한다.
구조적 차이점
측면 |
GRPO |
PPO |
|---|---|---|
어드밴티지 계산 |
그룹 내 보상의 평균/표준편차로 정규화 |
보상 + 가치 함수 → GAE |
가치 함수 |
불필요 |
필요 (정책과 공동 훈련) |
KL 발산 위치 |
목적 함수에 명시적 항으로 포함 |
구현상 보상에 포함 (토큰별 KL 페널티) |
완성 수 |
프롬프트당 \(G\)개 |
프롬프트당 1개 |
훈련 모델 수 |
1개 (정책 모델) |
2개 (정책 모델 + 가치 모델) |
필요 모델 수 비교
모델 |
GRPO |
PPO |
|---|---|---|
정책 모델 \(\pi_\theta\) |
훈련됨 |
훈련됨 |
가치 함수 \(V\) |
없음 |
훈련됨 |
보상 모델/검증기 |
고정 (추론의 경우 검증 가능한 보상이므로 모델 불필요) |
고정 (추론의 경우 역시 모델 불필요) |
기준 모델 \(\pi_\text{ref}\) |
고정 |
고정 |
핵심 요약: GRPO는 가치 함수를 제거함으로써 훈련해야 할 모델 수를 줄이고 메모리 요구량을 낮춘다. 추론 과제에서는 검증 가능한 보상을 사용하므로 별도의 보상 모델도 필요 없어, GRPO와 PPO 모두 보상 모델이 불필요하다.
PPO는 주로 5장에서 다룬 선호도 튜닝(인간 선호 정렬)에 사용되고, GRPO는 추론 기반 RL 훈련에 주로 사용된다.
6.9 길이 편향 문제
추론 모델의 RL 훈련에서 관찰되는 중요한 현상이 있다. 훈련이 진행됨에 따라 모델의 출력 길이가 계속 증가하는 것이다.
현상
RL 스텝에 따른 평균 응답 길이를 그래프로 그리면, 길이가 단조 증가하는 경향이 나타난다. 초기에는 이 길이 증가가 성능 향상과 상관되어 있다. 추론 체인이 더 정교해지면서 벤치마크 점수도 올라간다. 하지만 어느 시점부터 성능은 정체되는데 출력 길이는 계속 증가한다. 이는 비효율적이며, API 과금 측면에서도 바람직하지 않다.
원인: GRPO 손실의 \(1/|o_i|\) 항
GRPO 목적 함수를 다시 보자. 안쪽 합산 앞에 \(1/|o_i|\) 정규화 항이 있다. 이 항을 바깥으로 옮겨보면, 각 토큰의 기여도가 해당 완성의 길이에 반비례한다는 것을 알 수 있다.
- 짧은 출력의 토큰: \(1/|o_i|\)가 크므로, 토큰당 가중치가 높다.
- 긴 출력의 토큰: \(1/|o_i|\)가 작으므로, 토큰당 가중치가 낮다.
이제 어드밴티지의 부호에 따라 분석해보자.
어드밴티지가 음수일 때 (나쁜 출력): 해당 출력의 토큰 생성 확률을 낮추려 한다. 그런데 짧은 나쁜 출력은 토큰당 가중치가 높으므로 확률이 더 강하게 감소하고, 긴 나쁜 출력은 토큰당 가중치가 낮으므로 확률이 덜 감소한다. 결과적으로, 모델은 짧은 나쁜 출력보다 긴 나쁜 출력을 선호하게 된다. 이것이 출력 길이가 계속 증가하는 원인이다.
6.10 DAPO와 Dr. GRPO
길이 편향 문제를 해결하기 위한 두 가지 대표적인 후속 연구가 있다.
DAPO (Decoupled Clip and Dynamic Sampling Policy Optimization)
DAPO는 2025년 3월에 발표된 논문이다. 핵심 수정은 토큰 수준 기여도를 균등화하는 것이다. \(1/|o_i|\)를 각 완성에 개별적으로 적용하는 대신, 모든 토큰에 공통적인 정규화 인자를 적용한다. 이렇게 하면 토큰의 기여도가 해당 완성의 길이에 의존하지 않게 된다.
Dr. GRPO (GRPO Done Right)
Dr. GRPO는 더 급진적인 접근을 취한다. \(1/|o_i|\) 정규화 인자를 아예 제거한다.
효과
이러한 수정을 적용하면, 보상 대비 출력 길이 그래프에서 모델이 길이를 무한히 늘리지 않는 것을 확인할 수 있다. 특히 오답인 경우의 평균 길이가 원래 GRPO에 비해 크게 줄어든다. 정답인 경우의 길이는 GRPO와 유사하게 유지되지만, 오답인 경우 불필요하게 긴 추론 체인을 생성하는 현상이 억제된다.
표준편차 편향 문제
GRPO의 어드밴티지 공식에서 표준편차로 나누는 것도 문제를 일으킬 수 있다. 매우 어려운 문제의 경우, 대부분의 완성이 실패하므로 보상 분포의 표준편차가 작아진다. 표준편차가 작으면 어드밴티지의 절대값이 과도하게 커져 훈련이 불안정해질 수 있다.
비대칭 클리핑
또 다른 수정은 클리핑 범위의 비대칭화다. 표준 GRPO에서는 확률 비율을 \([1 - \epsilon, 1 + \epsilon]\)으로 대칭적으로 클리핑한다. 하지만 확률이 매우 낮은 토큰의 경우를 생각해보자.
\[\pi_\theta(o_{i,t}) \in [( 1 - \epsilon) \cdot \pi_{\theta_\text{old}}(o_{i,t}),\; (1 + \epsilon) \cdot \pi_{\theta_\text{old}}(o_{i,t})]\]
\(\pi_{\theta_\text{old}}\)가 매우 작으면, \(\epsilon\)을 곱해도 허용 범위가 극히 좁아 확률을 충분히 키울 수 없다. 반면 높은 확률의 토큰에 같은 \(\epsilon\)을 적용하면 확률이 0 이하로 내려가는 것을 원하지 않는다. 따라서 하한과 상한에 서로 다른 \(\epsilon\) 값을 사용하여 비대칭 클리핑을 적용하는 방법이 제안되었다.
6.11 DeepSeek R1 레시피
지금까지 다룬 모든 기법이 실제로 어떻게 조합되는지를 DeepSeek R1 논문(2025년 1월)을 통해 살펴보자. DeepSeek 팀은 두 가지 모델을 단계적으로 개발했다. 먼저 RL만으로 추론 능력을 입증하는 개념 증명(proof of concept)인 R1-Zero, 그리고 이를 기반으로 완전한 추론 모델인 R1이다.
R1-Zero: 순수 RL로 추론 능력 입증
R1-Zero의 출발점은 DeepSeek V3의 사전 훈련된 기본 모델이다. 이 모델은 Mixture of Experts(MoE) 아키텍처, Multi-Latent Attention(MLA), RMSNorm 등 최신 기법을 사용한다.
핵심적인 점은, SFT를 전혀 거치지 않고 곧바로 RL을 적용한다는 것이다. 다음 토큰 예측만 학습한 기본 모델에, 검증 가능한 보상(정확도 보상 + 형식 보상)만으로 GRPO를 적용한다.
훈련 시 사용하는 프롬프트 템플릿은 다음과 같은 구조다.
[시스템 프롬프트: 당신은 사용자와 대화하는 어시스턴트입니다]
[형식 지시: 사고 과정은 <think>...</think> 안에, 최종 답은 <answer>...</answer> 안에 넣으세요]
[사용자 프롬프트: {문제}]
[모델 응답 영역]
결과: SFT 없이 검증 가능한 보상만으로도 AIME 등 수학 벤치마크에서 성능이 RL 스텝에 따라 유의미하게 증가한다.
하지만 문제가 발견되었다. R1-Zero의 추론 체인에서 두 가지 이슈가 나타났다.
- 언어 혼재: 추론 체인 내에서 여러 언어가 섞여 나타났다.
- 구문 오류: 문법적으로 부자연스러운 표현이 빈번했다.
이는 SFT라는 강한 지도 신호 없이 RL만 적용했기 때문에, 모델이 보상을 최적화하는 과정에서 언어적 일관성을 유지하지 못한 것으로 분석된다.
R1: 완전한 추론 모델 파이프라인
R1-Zero의 관찰을 바탕으로, DeepSeek 팀은 다단계 파이프라인으로 완전한 추론 모델 R1을 구축했다. 전체 과정은 네 단계다.
1단계: 콜드 스타트 SFT (Cold Start SFT)
R1-Zero 훈련 과정에서 생성된 추론 체인(CoT)을 수집한다. 이 중 품질이 낮은 것(언어 혼재, 구문 오류 등)은 인간이 직접 재작성(rewriting)하여 형식과 언어 일관성을 갖추도록 교정한다. 이렇게 정제된 (프롬프트, 재작성된 추론 체인 + 답변) 쌍으로 소규모 SFT를 수행한다. 데이터 규모는 수천 쌍 수준(다른 단계보다 수 자릿수 적음)으로 추정된다.
2단계: 추론 RL (Reasoning RL)
콜드 스타트 SFT를 거친 모델에 GRPO를 적용한다. 보상 함수는 세 가지 요소의 결합이다.
보상 유형 |
설명 |
|---|---|
정확도 보상 |
최종 답이 정답과 일치하는지 검증 |
형식 보상 |
|
언어 일관성 보상 |
출력 체인 내 목표 언어 토큰의 비율로 측정하는 단순 휴리스틱. R1-Zero에서 발견된 언어 혼재 문제를 해결하기 위해 도입 |
3단계: 거부 샘플링 SFT (Rejection Sampling SFT)
2단계까지 훈련된 모델을 사용하여 대규모 SFT 데이터를 생성한다. 추론 데이터와 비추론 데이터를 3:1 비율로 혼합한다.
- 추론 데이터: 추론 관련 프롬프트에 대해 모델이 응답을 생성하고, LLM 심판 등의 자동 평가를 통해 품질이 낮은 답을 거부(reject)하여 고품질 답만 남기는 거부 샘플링(rejection sampling) 기법을 사용한다.
- 비추론 데이터: DeepSeek V3의 SFT에서 사용한 데이터를 재활용하여 약 20만 쌍을 확보한다. 일반적인 어시스턴트 능력(다양한 주제에 대한 응답)을 유지하기 위함이다.
4단계: 최종 RL (Final RL)
마지막 RL 단계에서는 추론 데이터와 비추론 데이터를 모두 사용한다.
- 추론 데이터에 대한 보상: 2단계와 동일 (정확도 + 형식 + 언어 일관성)
-
비추론 데이터에 대한 보상: 두 가지 축으로 평가
- 유용성(helpfulness): 사용자에게 보이는 최종 답변의 품질
- 무해성(harmlessness): 추론 체인을 포함한 전체 출력에 적용.
<think>안의 사고 과정도 해로운 내용을 포함해서는 안 된다
R1의 결과
R1의 벤치마크 결과는 두 가지 관찰을 보여준다.
첫째, 추론 기반 벤치마크에서 추론 모델과 비추론 모델 사이에 뚜렷한 성능 격차가 존재한다. 추론 모델들은 비추론 모델들보다 확연히 높은 성능 클러스터를 형성한다.
둘째, 오픈소스인 R1이 OpenAI o1 등 비공개 추론 모델과 대등한 성능을 보인다. 이는 방법론을 상세히 공개한 논문으로서 큰 의미가 있다.
소형 모델로의 증류
600B 파라미터 규모의 모델을 운용할 수 없는 환경에서는 **증류(distillation)**를 사용한다. R1에서의 증류는 3장에서 다룬 전통적 증류와는 다른 방식이다.
- 전통적 증류: 교사 모델의 다음 토큰 확률 분포를 학생 모델이 모방한다.
- R1 증류: 교사 모델(R1)이 생성한 전체 시퀀스(추론 체인 + 답변)를 학생 모델이 SFT로 학습한다. 확률 분포가 아닌 시퀀스 자체를 모방하는 것이다.
DeepSeek 팀은 소규모 모델에서 직접 RL을 수행하는 것보다 증류가 더 효율적임을 확인했다. 증류된 소형 모델은 OpenAI o1-mini 등의 소형 추론 모델과 대등한 성능을 달성했다.
핵심 정리
개념 |
핵심 |
|---|---|
추론 모델 |
답을 내기 전 추론 체인을 생성. 출력 = 추론 + 답변 |
추론의 정의 |
다단계 과정을 통한 문제 해결 능력. 주로 수학/코딩 과제 |
타임라인 |
2024년 9월 o1-preview → 12월 Gemini Flash Thinking → 2025년 1월 DeepSeek R1 |
코딩 벤치마크 |
HumanEval (164문제), Codeforces (경쟁 프로그래밍), SWE-bench (GitHub 이슈) |
수학 벤치마크 |
AIME (올림피아드 예선), GSM8K (초등 수학) |
pass@k |
\(k\)번 중 적어도 하나 성공할 확률. \(\text{pass@k} = 1 - \binom{n-c}{k} / \binom{n}{k}\) |
온도와 pass@k |
너무 낮으면 다양성 부족, 너무 높으면 품질 저하. \(T = 0.4 \sim 0.8\)이 적절 |
consensus@k |
\(k\)개 생성 중 최빈 답을 선택. 자기 일관성과 관련 |
SFT 대신 RL |
추론 체인 작성이 어렵고, 검증 가능한 보상이 존재하며, 모델 고유의 추론 방식이 더 효과적 |
GRPO |
가치 함수 없이 그룹 내 보상의 상대적 위치로 어드밴티지 계산. \(\hat{A}_i = (r_i - \mu) / \sigma\) |
GRPO vs PPO |
GRPO: 가치 함수 불필요, 1개 모델 훈련. PPO: 가치 함수 필요, 2개 모델 훈련 |
길이 편향 |
GRPO의 \(1/\|o_i\|\) 항이 긴 오답을 짧은 오답보다 덜 벌하여 출력 길이 증가 유발 |
DAPO |
토큰 기여도를 균등화하여 길이 편향 완화 |
Dr. GRPO |
\(1/\|o_i\|\) 정규화를 제거하여 길이 편향 근본적 해결 |
DeepSeek R1-Zero |
SFT 없이 순수 RL만으로 추론 능력 입증. 언어 혼재/구문 오류 문제 발견 |
DeepSeek R1 |
콜드 스타트 SFT → 추론 RL → 거부 샘플링 SFT → 최종 RL의 4단계 파이프라인 |
증류 |
교사 모델의 전체 시퀀스를 학생 모델이 SFT로 학습. 소형 모델에서 직접 RL보다 효율적 |
다음 장: 7장 - 에이전트 LLM