8장 - LLM 평가
8장. LLM 평가
LLM의 성능을 측정할 수 없다면, 무엇을 개선해야 하는지도 알 수 없다. 평가는 모델 개발의 나침반이다. — 아프신 아미디
8.1 평가의 범위와 어려움
지금까지 트랜스포머의 구조, 사전 훈련, 미세 조정, 추론 최적화, 에이전트 워크플로까지 살펴보았다. 이번 장에서는 이 모든 과정의 결과물인 LLM의 출력을 어떻게 정량적으로 평가하는가를 다룬다. LLM이 생성하는 응답이 실제로 얼마나 좋은지 측정하지 못하면, 모델 개선의 방향을 잡을 수 없다.
평가의 의미
"LLM을 평가한다"는 말은 여러 차원을 포괄한다.
차원 |
예시 |
|---|---|
출력 품질 |
일관성(coherence), 사실 정확도(factuality), 유용성(helpfulness) |
시스템 성능 |
지연 시간(latency), 가격(pricing), 가용성(uptime) |
정렬(alignment) |
톤, 스타일, 안전성(safety) |
이번 장은 출력 품질에 집중한다. 즉, LLM이 돌려주는 텍스트 응답 자체가 얼마나 좋은지를 정량화하는 방법을 살펴본다.
자유 형식 출력의 도전
LLM은 자연어, 코드, 수학적 추론 등 사실상 어떤 형태의 텍스트든 생성할 수 있는 텍스트-투-텍스트 모델이다. 따라서 출력의 품질을 측정하는 보편적 지표를 설계하기가 매우 어렵다. 분류 모델이라면 정확도(accuracy)로 간단히 평가할 수 있지만, 자유 형식 텍스트에는 그런 단일 지표가 존재하지 않는다.
가장 이상적인 시나리오는 매번 사람에게 응답을 평가시키는 것이다. 프롬프트를 LLM에 보내고, 응답을 받으면, 사람이 등급을 매기는 과정을 반복하여 전체 성능을 집계한다. 그러나 이 방식은 비용이 막대하고 속도가 느리다. 이 한계를 극복하기 위한 세 가지 접근법 -- 평가자 간 일치 지표, 규칙 기반 지표, LLM-as-a-Judge -- 을 차례로 살펴본다.
8.2 평가자 간 일치도 지표
사람에게 LLM 출력을 평가시킬 때 가장 먼저 부딪히는 문제는 평가 과제 자체가 주관적일 수 있다는 점이다.
주관성의 예시
LLM에게 "어떤 생일 선물을 사면 좋을까?"라고 물었고, 모델이 "인형 곰은 거의 언제나 좋은 선물이에요. 마음에 드는 걸 골라 보세요."라고 답했다고 하자. "유용성(usefulness)" 기준으로 이 답변을 평가한다면, 한 평가자는 "인형 곰이라는 구체적 제안이 있으니 유용하다"고 할 수 있고, 다른 평가자는 "어떤 인형 곰인지, 어디서 사는지 구체적이지 않으니 유용하지 않다"고 할 수 있다. 같은 응답에 대해 평가자마다 판단이 갈리는 것이다.
이러한 불일치를 체계적으로 관리하기 위해, 평가자들이 얼마나 일관되게 판단하는지를 측정하는 평가자 간 일치도(inter-rater agreement) 지표가 필요하다.
단순 일치율의 한계
가장 직관적인 지표는 **일치율(agreement rate)**이다. 두 평가자가 동일한 등급을 부여한 비율을 측정한다.
\[\text{Agreement Rate} = \frac{\text{두 평가자가 동일 등급을 부여한 횟수}}{\text{전체 평가 횟수}}\]
그러나 이 지표에는 근본적 문제가 있다. 순전히 무작위로 답하더라도 일정 수준의 일치율이 나온다.
두 평가자 Alice와 Bob이 이진 평가(좋음/나쁨)를 독립적이고 무작위로 수행한다고 가정하자. Alice가 "좋음"이라 답할 확률을 \(p_A\), Bob이 "좋음"이라 답할 확률을 \(p_B\)라 하면, 우연에 의한 일치 확률은 다음과 같다.
\[p_e = p_A \cdot p_B + (1 - p_A)(1 - p_B)\]
예를 들어 \(p_A = p_B = 0.5\)이면, \(p_e = 0.5^2 + 0.5^2 = 0.5\)이다. 무작위로 답해도 50%의 일치율을 보이는 것이다. \(p_A\)와 \(p_B\)가 높아질수록(예: 둘 다 0.9) 우연 일치율은 더욱 높아진다(\(0.9^2 + 0.1^2 = 0.82\)). 따라서 단순 일치율만으로는 평가자들이 실제로 합의하고 있는지, 아니면 우연의 일치인지 구별할 수 없다.
코헨의 카파 (Cohen's Kappa)
이 문제를 해결하기 위해 코헨의 카파(\(\kappa\)) 계수가 도입되었다. 관찰된 일치율에서 우연 일치율을 제거하여, 순수하게 의미 있는 일치의 비율을 측정한다.
\[\kappa = \frac{p_o - p_e}{1 - p_e}\]
여기서 \(p_o\)는 관찰된 일치율, \(p_e\)는 우연에 의한 기대 일치율이다.
\(\kappa\) 값 |
해석 |
|---|---|
1 |
완전 일치 (\(p_o = 1\)) |
0 |
우연 수준의 일치 (\(p_o = p_e\)) |
음수 |
우연보다 못한 일치 (체계적 불일치) |
\(\kappa\)가 양수이면 평가자들이 우연 이상으로 합의하고 있다는 뜻이고, 음수이면 체계적으로 불일치하고 있다는 뜻이다.
플라이스의 카파와 크리펜도르프의 알파
코헨의 카파는 평가자가 2명일 때 사용한다. 현실에서는 3명 이상의 평가자가 참여하는 경우가 많으므로, 이를 확장한 지표가 존재한다.
**플라이스의 카파(Fleiss' Kappa)**는 코헨의 카파를 여러 평가자로 일반화한 것이다. 각 항목에 대해 모든 평가자 쌍의 일치를 고려하며, 동일한 기본 아이디어 -- 관찰된 일치에서 우연 일치를 빼는 것 -- 를 따른다.
**크리펜도르프의 알파(Krippendorff's Alpha)**는 더 유연한 지표로, 평가자 수가 항목마다 다르거나 결측값이 있는 상황에서도 적용할 수 있다. 명목형, 순서형, 구간형 등 다양한 척도를 지원한다.
세 지표 모두 핵심 원리는 동일하다. 우연에 의한 기대 일치를 기준선(baseline)으로 삼고, 실제 관찰된 일치가 그 기준선을 얼마나 초과하는지를 정량화한다.
일치도 지표의 실무 활용
실무에서 평가자 간 일치도 지표는 **건강 지표(health metric)**로 활용된다. 일치도가 만족스럽지 않으면, 평가자들을 모아 **일치 세션(alignment session)**을 열고 평가 기준을 재정립한다. 가이드라인을 더 명확히 하고, 경계 사례(edge case)에 대한 합의를 도출하여 평가의 일관성을 높인다.
정리하면, 인간 평가의 첫 번째 한계인 주관성은 일치도 지표로 관리할 수 있다. 그러나 두 번째 한계인 속도와 비용은 여전히 해결되지 않는다. 수천 건의 LLM 출력을 사람이 일일이 평가하는 것은 현실적으로 불가능하다. 이 한계를 극복하기 위한 첫 번째 시도가 규칙 기반 지표다.
8.3 규칙 기반 지표: METEOR, BLEU, ROUGE
규칙 기반 지표의 핵심 아이디어는 다음과 같다. 사람에게 매번 LLM 출력을 평가시키는 대신, **참조 텍스트(reference text)**를 미리 작성해 두고, LLM 출력과 참조를 자동으로 비교하는 것이다.
고정된 프롬프트 집합에 대해 인간이 이상적인 참조 응답을 한 번 작성하면, 이후 모델을 반복 개선할 때마다 LLM 출력을 그 참조와 비교할 수 있다. 매번 사람을 부를 필요가 없으므로 비용이 크게 절감된다.
이상적으로 이 지표들은 자연어의 유연성을 반영해야 한다. 같은 의미를 다양하게 표현할 수 있기 때문이다. 실제 지표들이 이 이상에 얼마나 부합하는지 살펴보자.
METEOR
**METEOR(Metric for Evaluation of Translation with Explicit Ordering)**는 기계 번역 평가를 위해 설계된 지표로, 참조와 예측을 비교하되 단어 순서도 고려한다.
공식은 다음과 같다.
\[\text{METEOR} = F_\text{score} \times (1 - \text{Penalty})\]
F-score 부분. 정밀도와 재현율의 가중 조화 평균이다.
\[F_\text{score} = \frac{P \cdot R}{\alpha \cdot P + (1 - \alpha) \cdot R}\]
여기서: - \(P\)(정밀도) = 예측 시퀀스의 유니그램 중 참조와 일치하는 비율 - \(R\)(재현율) = 참조 시퀀스의 유니그램 중 예측과 일치하는 비율 - \(\alpha\)는 가중 하이퍼파라미터
METEOR는 유니그램 일치를 정확한 단어 매칭뿐 아니라 **동의어(synonym)**와 **어간(stem)**까지 확장하여 매칭 범위를 넓힌다.
순서 벌점(Ordering Penalty) 부분. 단어가 올바른 순서로 나타나는지를 평가한다.
\[\text{Penalty} = \gamma \left(\frac{C}{M}\right)^\beta\]
여기서: - \(C\) = 연속적으로 일치하는 청크(contiguous chunk)의 수 - \(M\) = 일치하는 유니그램의 총 수 - \(\gamma\), \(\beta\)는 하이퍼파라미터
\(C\)가 낮을수록 좋다. \(C\)가 낮다는 것은 연속 일치 구간이 길다는 뜻이고, 이는 예측과 참조의 순서가 유사하다는 의미다. 반대로 \(M\)은 높을수록 좋다. 따라서 \(C/M\) 비율이 낮으면 벌점이 작아지고, METEOR 점수가 높아진다.
METEOR 점수가 높을수록 좋은 번역(또는 응답)이다.
BLEU
**BLEU(Bilingual Evaluation Understudy)**는 기계 번역에서 가장 널리 알려진 지표 중 하나로, 정밀도 중심(precision-focused) 지표다.
\[\text{BLEU} = \text{BP} \cdot \exp\left(\sum_{n=1}^{N} w_n \log p_n\right)\]
여기서: - \(p_n\) = 예측의 \(n\)-그램 중 참조와 일치하는 비율 (수정된 \(n\)-그램 정밀도) - \(w_n\) = 각 \(n\)-그램 수준의 가중치 (보통 \(w_n = 1/N\)) - \(\text{BP}\) = 간결성 벌점(brevity penalty)
간결성 벌점. BLEU가 정밀도 기반이므로, 매우 짧은 번역을 생성하면 정밀도를 쉽게 높일 수 있다. 이를 방지하기 위해 예측이 참조보다 짧으면 벌점을 부과한다.
\[\text{BP} = \begin{cases} 1 & \text{if } c > r \\ e^{(1 - r/c)} & \text{if } c \leq r \end{cases}\]
여기서 \(c\)는 예측의 길이, \(r\)은 참조의 길이다. 예측이 참조보다 짧을수록 \(\text{BP}\)가 급격히 감소하여 전체 BLEU 점수를 낮춘다.
ROUGE
**ROUGE(Recall-Oriented Understudy for Gisting Evaluation)**는 주로 요약(summarization) 과제에 사용되며, 재현율 중심(recall-focused) 지표다. 참조의 \(n\)-그램 중 예측에 등장하는 비율을 측정한다.
ROUGE에는 여러 변형이 있다.
변형 |
설명 |
|---|---|
ROUGE-N |
\(n\)-그램 재현율. ROUGE-1(유니그램), ROUGE-2(바이그램) 등 |
ROUGE-L |
최장 공통 부분 수열(LCS) 기반. 순서를 유연하게 고려 |
ROUGE-S |
스킵-바이그램 기반. 사이에 다른 단어를 허용 |
세 지표 모두 LLM 출력과 참조 텍스트를 비교한다는 공통점을 가진다.
규칙 기반 지표의 한계
규칙 기반 지표에는 세 가지 근본적 한계가 있다.
첫째, 문체적 변형을 허용하지 않는다. "봉제 인형 곰은 아이의 취침 시간에 위안이 된다"와 "부드러운 봉제 곰은 아이들이 잠들 때 안전함을 느끼게 해 준다"와 "많은 아이들이 포근한 장난감 친구를 안고 있으면 밤에 더 편히 쉰다" -- 이 세 문장은 같은 의미이지만, \(n\)-그램 겹침이 매우 적다. 규칙 기반 지표는 이 세 응답을 모두 낮게 평가할 것이다.
둘째, 인간 평가와의 상관관계가 낮다. \(\alpha\), \(\beta\), \(\gamma\) 같은 하이퍼파라미터를 조정하여 인간 판단과의 상관을 높이려 하지만, 여전히 상관이 충분하지 않다. 지표가 높은 점수를 줬다고 해서 인간이 좋다고 판단하리라는 보장이 없다.
셋째, 여전히 인간 참조가 필요하다. 프로젝트에 따라서는 인간 참조 응답을 작성할 여력이 없을 수 있다. 이 경우 규칙 기반 지표 자체를 사용할 수 없다.
이 세 가지 한계가 바로 이번 장의 핵심 방법론인 LLM-as-a-Judge를 동기부여한다.
8.4 LLM-as-a-Judge
지난 일곱 개 장에 걸쳐, 방대한 데이터로 사전 훈련되고 인간 선호에 맞춰 튜닝된 대규모 언어 모델을 살펴보았다. 이 모델들은 인간의 지식과 선호에 대한 상당한 이해를 이미 내재하고 있다. LLM-as-a-Judge는 이 능력을 활용하여, 또 다른 LLM이 모델 응답을 평가하게 하는 방법이다.
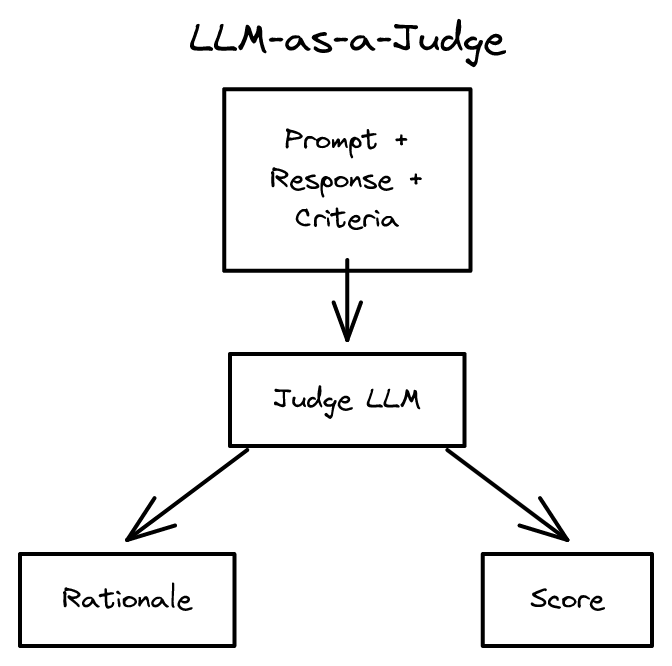
기본 구조
LLM-as-a-Judge의 입력과 출력은 다음과 같다.
입력: - 원래 프롬프트 (응답을 생성하는 데 사용된 질문) - 모델 응답 (평가 대상) - 평가 기준 (어떤 차원에서 평가할 것인지)
출력: - 점수(score): 이진 척도(합격/불합격) 또는 등급 - 근거(rationale): 왜 그 점수를 부여했는지에 대한 설명
근거를 함께 출력한다는 점이 규칙 기반 지표와의 핵심 차이다. METEOR이나 BLEU가 숫자 하나만 돌려줄 때, 그 숫자가 왜 그런지 설명할 수 없다. LLM-as-a-Judge는 점수와 함께 "이 응답은 사실 오류가 있고, 구체적 예시가 부족하다"처럼 해석 가능한 근거를 제공한다.
프롬프트 설계
전형적인 LLM-as-a-Judge 프롬프트는 다음 구조를 따른다.
주어진 기준에 따라 아래 응답을 평가하시오.
[평가 기준]
유용성: 응답이 사용자의 질문에 실질적으로 도움이 되는가?
[프롬프트]
어떤 생일 선물을 사면 좋을까?
[모델 응답]
인형 곰은 거의 언제나 좋은 선물이에요...
다음 형식으로 출력하시오:
1. 근거(rationale): ...
2. 점수(score): 합격 또는 불합격
여기서 중요한 트릭이 있다. 근거를 점수보다 먼저 출력하도록 요청한다. 이는 경험적으로 평가 품질을 향상시킨다. 직관은 6장에서 다룬 추론 모델과 동일하다. 사고 과정(chain-of-thought)을 먼저 외부화하면 최종 답변의 질이 높아지듯, 평가 근거를 먼저 작성하면 모델이 응답의 장단점을 충분히 분석한 뒤 점수를 부여하게 된다.
구조화된 출력 (Structured Outputs)
위 프롬프트를 LLM에 보낸다고 해서, 항상 파싱 가능한 형식으로 근거와 점수가 나온다는 보장은 없다. LLM의 샘플링 과정에는 확률적 요소가 있으므로, 출력 형식이 달라질 수 있다.
이 문제를 해결하는 기법이 3장에서 다룬 **제한된 안내 디코딩(constrained guided decoding)**이다. 디코딩 과정에서 유효한 토큰만 샘플링하도록 제한하여, 출력이 반드시 원하는 형식(예: JSON)을 따르게 한다.
주요 API 제공사(OpenAI, Google, Anthropic 등)는 이 기법을 **구조화된 출력(structured outputs)**이라는 이름으로 제공한다. 예를 들어 다음과 같이 응답 형식을 지정할 수 있다.
class EvaluationResult:
rationale: str
score: str # "pass" or "fail"
response = client.chat.completions.create(
...,
text_format=EvaluationResult
)
이렇게 하면 LLM의 출력이 반드시 rationale과 score 필드를 포함하는 구조화된 형태로 나온다.
LLM-as-a-Judge의 두 가지 핵심 장점
참조 텍스트가 불필요하다. 규칙 기반 지표와 달리, 인간이 미리 참조 응답을 작성할 필요가 없다. LLM이 사전 훈련과 인간 선호 튜닝 과정에서 획득한 지식과 판단력을 활용하기 때문이다.
점수를 해석할 수 있다. 근거가 함께 출력되므로, 왜 그 점수가 나왔는지 이해할 수 있다. "이 응답은 사실적으로 정확하지만 구체적 예시가 부족하여 유용성이 떨어진다" 같은 설명은 모델 개선에 직접적인 방향을 제시한다.
8.5 LLM-as-a-Judge의 변형: 포인트와이즈와 페어와이즈
LLM-as-a-Judge에는 크게 두 가지 변형이 있다.
포인트와이즈 평가 (Pointwise Evaluation)
하나의 응답을 독립적으로 평가한다. "이 응답이 좋은가, 나쁜가?"라고 판사 모델에게 묻는 방식이다.
이 응답을 [기준]에 따라 평가하시오.
→ 점수: 합격 / 불합격
단일 모델의 절대적 성능을 측정할 때 적합하다.
페어와이즈 평가 (Pairwise Evaluation)
두 응답을 비교하여 어느 것이 더 나은지 판단한다.
응답 A와 응답 B 중 어느 것이 더 나은가?
→ 선택: A 또는 B
이 방식은 5장에서 다룬 **선호 튜닝(preference tuning)**과 직접 연결된다. 두 응답에 대해 LLM-as-a-Judge가 선호를 표시하면, 이 결과를 합성적으로 생성된 선호 데이터로 활용하여 보상 모델(reward model)을 훈련할 수 있다.
참조 기반 평가 (Reference-based Evaluation)
참조 텍스트를 함께 제공하여 평가하는 변형도 있다. 판사 모델에게 "이상적 답변은 이것인데, 모델의 응답은 어떠한가?"라고 묻는 방식이다. 규칙 기반 지표의 참조 비교 개념과 LLM-as-a-Judge의 유연한 판단을 결합한 접근이다.
8.6 LLM-as-a-Judge의 편향
LLM-as-a-Judge는 강력하지만 완벽하지 않다. 체계적 편향(bias)이 존재하며, 이를 인식하고 완화하는 것이 중요하다.
위치 편향 (Position Bias)
페어와이즈 평가에서, 응답이 제시되는 순서가 판단에 영향을 미치는 편향이다. "응답 A와 응답 B 중 어느 것이 더 나은가?"라고 물었을 때, 모델이 단순히 A가 먼저 언급되었다는 이유로 A를 선택할 수 있다.
완화 방법: 위치 교체(position swapping). 동일한 두 응답에 대해 순서를 바꿔 두 번 질문한다.
- "A와 B 중 어느 것이 더 나은가?" → 답: A
- "B와 A 중 어느 것이 더 나은가?" → 답: B (= 원래의 A)
두 결과가 동일하면 신뢰할 수 있다. 결과가 달라지면 해당 비교는 신뢰할 수 없으므로 추가 조치가 필요하다. 위치 임베딩을 조정하는 고급 기법도 연구되고 있지만, 위치 교체 후 다수결이 가장 보편적인 실무 방법이다.
장황함 편향 (Verbosity Bias)
더 길고 상세한 응답을 선호하는 편향이다. 짧고 핵심적인 응답이 실제로 더 정확하더라도, 판사 모델이 장황한 응답에 더 높은 점수를 줄 수 있다. 길이가 곧 품질을 의미하지 않는데도, 풍부한 텍스트가 더 좋아 보이는 것이다.
완화 방법: - 가이드라인에 명시. 프롬프트에 "응답의 길이에 좌우되지 말고, 내용의 정확성과 관련성을 기준으로 판단하라"고 명시한다. - 인컨텍스트 학습 예시. 짧지만 정확한 응답이 길지만 부정확한 응답보다 높은 점수를 받는 예시를 포함한다. - 길이 벌점. 포인트와이즈 평가에서 출력 길이에 비례하는 벌점을 적용한다.
자기 강화 편향 (Self-Enhancement Bias)
모델이 자기 자신이 생성한 응답을 더 높게 평가하는 편향이다. 모델이 어떤 응답을 생성했다는 것은, 그 모델의 확률 분포에서 해당 시퀀스가 높은 확률을 가졌다는 뜻이다. 따라서 동일 모델이 판사 역할을 하면, 자기가 생성할 법한 응답에 자연스럽게 높은 점수를 부여하게 된다.
완화 방법: 생성 모델과 판사 모델을 다른 모델로 사용한다. 현실적으로 모든 모델이 유사한 훈련 데이터를 사용하므로 완전한 분리는 어렵지만, 최소한 동일 모델을 쓰지 않는 것이 기본 원칙이다. 또한 판사 모델은 일반적으로 생성 모델보다 더 큰, 강력한 추론 능력을 가진 모델을 사용하는 것이 좋다. 더 큰 모델일수록 이러한 편향에 덜 취약하다.
이 세 가지 편향은 대표적인 것일 뿐 전부가 아니다. LLM-as-a-Judge 자체가 인간 선호와 완전히 정렬되지 않은 경우(alignment bias)도 다른 유형의 편향이 될 수 있다.
8.7 LLM-as-a-Judge 모범 사례
편향을 인식한 위에서, LLM-as-a-Judge를 효과적으로 운영하기 위한 모범 사례를 정리한다.
1. 명확한 가이드라인 작성
평가 기준이 모호하면 판사 모델도 일관되지 않은 판단을 내린다. "이 응답은 좋은가?"보다 "이 응답은 사용자의 질문에 직접적으로 답하는가? 사실적 오류가 있는가? 불필요한 정보를 포함하는가?"처럼 구체적으로 기준을 명시한다.
2. 이진 척도 사용
1~5점 같은 세분화된 척도보다 합격/불합격(pass/fail) 이진 척도가 더 효과적이다. 이유는 두 가지다.
- 판사 모델의 과제가 단순해져 판단의 일관성이 높아진다.
- 인간 평가자 역시 이진 선택이 더 쉬우므로, 인간-모델 간 일치도가 높아진다.
세분화된 척도는 추가적 신호를 제공하는 것 같지만, 실제로는 노이즈만 증가시키는 경우가 많다.
3. 근거를 점수보다 먼저 출력
앞서 언급한 대로, 근거 → 점수 순서로 출력하게 하면 평가 품질이 향상된다. 이는 추론 모델의 사고 과정과 동일한 원리다.
4. 위치 교체로 편향 완화
페어와이즈 평가에서는 반드시 응답 순서를 교체하여 두 번 평가하고, 결과의 일관성을 확인한다.
5. 인간 평가와 교정
LLM-as-a-Judge를 도입한 후에도, 정기적으로 인간 평가 결과와 비교하여 **교정(calibration)**해야 한다. 구체적으로:
- 동일한 평가 세트에 대해 인간 평가와 LLM-as-a-Judge 평가를 모두 수행한다.
- 두 결과 간의 상관 분석을 실행한다.
- 불일치가 크면 프롬프트를 조정한다.
LLM-as-a-Judge 점수는 결국 인간 평가의 **근사(proxy)**다. 근사치에 대해 과도하게 최적화하면, 실제 인간 판단과 괴리가 생길 수 있다. 따라서 근사치가 원래 기준(ground truth)인 인간 평가와 최대한 정렬되어 있는지를 지속적으로 확인해야 한다.
6. 낮은 온도 사용
평가 과제에서는 **온도(temperature)**를 낮게 설정한다. 일반적으로 0.1 ~ 0.2 수준이다. 이유는 재현성(reproducibility) 때문이다. 오늘 수행한 평가와 이틀 후 수행한 평가의 점수가 크게 달라지면, 모델 개선의 효과를 정확히 측정할 수 없다. 낮은 온도는 생성의 확률적 변동을 줄여 평가 결과를 안정적으로 만든다.
8.8 사실 정확도 평가
LLM 출력의 여러 평가 차원 중, **사실 정확도(factuality)**는 특별히 세밀한 접근이 필요한 차원이다.
이진 평가의 한계
대부분의 평가 차원에서는 이진 척도(합격/불합격)가 효과적이지만, 사실 정확도에서는 뉘앙스가 훨씬 풍부하다. 텍스트가 완전히 틀릴 수도 있고, 조금만 틀릴 수도 있고, 전혀 틀리지 않을 수도 있다. 여러 문장으로 이루어진 긴 텍스트에서 하나의 사소한 오류가 있다고 해서 전체를 "불합격"으로 처리하면 유용한 정보를 잃는다.
사실 분해 기반 평가
현대적인 사실 정확도 평가는 다음 단계를 따른다.
1단계: 사실 분해(Fact Decomposition). LLM 호출을 통해 원문을 개별 사실(fact) 목록으로 변환한다.
예를 들어 "인형 곰은 1920년대에 처음 만들어졌으며, 시어도어 루스벨트 대통령이 사냥 여행에서 포획된 곰을 자랑스럽게 쏘려 한 것에서 이름을 따왔다"라는 텍스트를 분해하면:
번호 |
사실 |
|---|---|
1 |
인형 곰은 1920년대에 처음 만들어졌다 |
2 |
시어도어 루스벨트 대통령의 이름을 따서 명명되었다 |
3 |
루스벨트는 사냥 여행에서 곰을 자랑스럽게 쏘려 했다 |
4 |
그 곰은 포획된 상태였다 |
2단계: 사실 검증(Fact Verification). 각 사실을 독립적으로 검증한다. 사실은 맞거나 틀리므로 이진 판단이 적절하다. 검증에는 RAG(7장 참조), 웹 검색, 또는 별도의 LLM 호출이 활용된다. 지식 베이스에서 관련 정보를 검색하여 각 사실과 대조한다.
위 예시에서: - 사실 1: 오류. 인형 곰은 1920년대가 아니라 1900년대에 처음 만들어졌다. - 사실 2: 정확. 시어도어 루스벨트의 이름을 따왔다. - 사실 3: 오류. 루스벨트는 곰을 쏘려 한 것이 아니라 쏘기를 거부했다. - 사실 4: 정확. 곰은 포획된 상태였다.
3단계: 가중 집계. 모든 사실이 동등하게 중요하지 않을 수 있다. 예를 들어, 인형 곰이 누구의 이름을 따왔는지는 핵심 사실이고, 정확한 연대는 상대적으로 덜 중요할 수 있다. 이를 반영하여 가중 합산한다.
\[\text{Factuality Score} = \frac{\sum_{i=1}^{n} \alpha_i \cdot v_i}{\sum_{i=1}^{n} \alpha_i}\]
여기서: - \(n\) = 사실의 총 개수 - \(v_i \in \{0, 1\}\) = 사실 \(i\)의 검증 결과 (1 = 정확, 0 = 오류) - \(\alpha_i\) = 사실 \(i\)의 중요도 가중치
가중치 \(\alpha_i\)를 모두 동일하게 설정하면 단순 정확 비율이 된다. 가중치를 다르게 설정하면 핵심 사실의 오류에 더 큰 벌점을 부과할 수 있다.
이 방법의 핵심은 텍스트 전체를 한 번에 판단하는 대신, 원자적 사실 단위로 분해하여 각각을 검증하고 집계하는 것이다. 이렇게 하면 "부분적으로 정확한" 텍스트의 정확도를 정밀하게 정량화할 수 있다.
8.9 에이전트 평가
7장에서 다룬 에이전트 워크플로는 관찰-계획-행동(ReAct) 루프로 구성된다. 이러한 다단계 시스템을 평가하려면, 단일 응답 평가와는 다른 접근이 필요하다.
도구 호출의 3단계와 실패 모드
에이전트의 핵심인 도구 호출은 세 단계로 분해된다.
단계 |
설명 |
|---|---|
1. 도구 예측 |
올바른 도구를 올바른 인자와 함께 선택 |
2. 도구 실행 |
선택된 도구를 실행하고 결과를 받음 |
3. 결과 종합 |
도구 결과를 사용자에게 의미 있는 응답으로 변환 |
에이전트 평가의 핵심은 각 단계에서 발생할 수 있는 실패 모드를 체계적으로 분류하고 진단하는 것이다.
도구 예측 단계의 실패 모드
실패 모드 1: 도구를 사용하지 않음. 사용자가 "근처에서 곰 인형을 찾아 줘"라고 요청했는데, 모델이 도구를 호출하지 않고 "죄송합니다, 도와드리기 어렵습니다"라고 응답하는 경우다. 이를 **펀트(punt)**라 한다.
원인과 대응: - 도구 라우터 오류. 도구 선택기(tool router)가 관련 도구를 후보에서 누락했을 수 있다. 이는 재현율(recall) 문제이므로 도구 라우터를 조정한다. - LLM의 도구 인식 부족. 도구가 프리앰블에 포함되어 있지만 모델이 사용해야 한다고 판단하지 못한 경우다. SFT로 도구 사용 패턴을 훈련하거나, 프롬프트를 개선한다.
실패 모드 2: 존재하지 않는 도구를 호출(도구 환각). 정의되지 않은 함수를 호출하는 경우다. 예를 들어 find_teddy_bear가 정의된 API인데 모델이 find_bear를 호출하려 하는 것이다.
원인과 대응: - 모델의 그라운딩 능력이 부족할 수 있다. 더 강력한 모델로 교체를 고려한다. - API 정의(함수명, 인자명, 설명)가 불명확할 수 있다. API 명세를 더 직관적으로 재작성한다. - 최상위 지시사항(horizontal instructions)에 "제공된 도구만 사용하라"는 명확한 지침이 없을 수 있다.
실패 모드 3: 잘못된 도구 선택. 도구는 존재하지만 맥락에 맞지 않는 도구를 선택하는 경우다. 예를 들어 곰 인형을 찾으라는 요청에 "메시지 보내기" 도구를 호출하는 것이다.
원인과 대응: - 도구 라우터가 적절한 도구를 후보에 포함하지 않았을 수 있다. - 두 도구의 API 설명이 범위가 겹쳐 혼란을 일으킬 수 있다. 각 도구의 용도를 명확하고 배타적으로 기술한다.
실패 모드 4: 올바른 도구, 잘못된 인자. 올바른 도구를 선택했지만 인자가 틀린 경우다. 위치 정보가 필요한데 좌표 (0, 0)(남대서양 한가운데)을 입력하는 것이 예다.
원인과 대응: - 필요한 컨텍스트 정보(위치 등)가 제공되지 않았을 수 있다. 위치 조회 도구를 사전에 실행하거나, 사용자에게 권한 요청을 안내한다. - 인자의 의미가 모델에게 명확하지 않을 수 있다. API 명세의 인자 설명을 개선한다.
도구 실행 단계의 실패 모드
실패 모드 5: 잘못된 응답 반환. 도구의 코드 로직에 버그가 있어 오류가 발생하는 경우다. 오류를 그대로 모델에 돌려주면, 모델이 "내부 오류가 발생했습니다"라고만 응답하여 사용자에게 도움이 되지 않는다.
대응: 도구 구현을 수정하는 소프트웨어 엔지니어링 문제다. 오류 대신 구조화된 출력으로 상태를 전달한다.
실패 모드 6: 응답 없음. 특히 액션을 수행하는 도구(예: 온도 조절기 올리기)에서 위험하다. 도구가 아무 응답도 반환하지 않으면, 모델은 성공 여부를 알 수 없다. 이 경우 모델이 거짓 확인("온도를 올렸습니다!")을 생성할 수 있다.
대응: 모든 도구 호출에 반드시 의미 있는 출력을 반환한다. 결과가 없는 경우에도 빈 JSON({})이 None보다 낫다. 빈 JSON은 "결과 없음"이라는 의미를 전달하지만, None은 아무 정보도 주지 않는다.
결과 종합 단계의 실패 모드
실패 모드 7: 올바른 도구 출력을 잘못 해석. 도구가 올바른 결과를 반환했는데, 모델이 이를 잘못 읽고 엉뚱한 응답을 생성하는 경우다. 예를 들어 곰 인형을 찾았는데 "찾지 못했습니다"라고 응답하는 것이다.
원인과 대응: - 모델의 그라운딩 능력 부족. 더 강력한 모델로 교체를 고려한다. - 도구 출력이 과도하게 많아 핵심 정보가 묻힐 수 있다. 도구 출력을 간결하고 의미 있는 형태로 정리한다. - 도구 출력의 형식이 모델이 이해하기 어려울 수 있다. Python 클래스처럼 속성명이 명확한 구조화된 객체로 반환한다.
에이전트 평가의 핵심 원칙
에이전트의 실패 원인은 크게 두 범주로 나뉜다.
범주 |
세부 |
|---|---|
모델링 측면 |
모델의 추론·그라운딩 능력, 컨텍스트 윈도우의 관련성, 도구 라우터/API 설계 |
도구 자체 |
도구 구현의 버그, 출력 형식의 부적절성 |
에이전트 시스템에서는 오류의 종류가 다양하므로, 체계적으로 오류를 분류하고 유형별로 묶어서 대응하는 것이 핵심이다. 개별 오류를 산발적으로 해결하기보다, 같은 원인을 가진 오류들을 일괄적으로 처리하는 것이 효율적이다.
8.10 벤치마크
지금까지 개별 평가 방법론을 살펴보았다. 이제 여러 모델을 상호 비교하기 위한 표준화된 평가 체계인 벤치마크를 다룬다.
벤치마크는 다음 범주로 나뉜다.
범주 |
측정 대상 |
대표 벤치마크 |
|---|---|---|
지식 |
사전 훈련에서 획득한 사실적 지식의 보유량 |
MMLU |
추론 |
논리적·수학적 사고 능력 |
AIME, PIQA |
코딩 |
코드 이해·생성 능력 |
SWE-bench |
안전성 |
유해 콘텐츠 생성 방지 능력 |
HarmBench |
에이전트 |
도구 사용·다단계 과제 수행 능력 |
Tau-Bench |
MMLU: 대규모 다중 과제 언어 이해
**MMLU(Massive Multitask Language Understanding)**는 약 60개의 다양한 분야(법, 의학, 일상생활, 수학, 역사 등)에 걸쳐 모델의 지식을 평가한다.
형식. 각 문제는 4지선다 객관식이다. 모델이 정답 알파벳(A, B, C, D)을 출력하면, 이를 하드코딩된 정답과 비교한다. 이렇게 제한된 형식을 사용하는 이유는, 자유 형식 응답을 LLM-as-a-Judge로 평가하면 추가적인 오류층이 생기기 때문이다. 객관식 형식은 평가 과정 자체의 노이즈를 제거한다.
특성. MMLU의 문제들은 대부분 해당 분야의 사전 지식을 요구한다. 순수 논리만으로는 풀 수 없고, 법률 조문, 의학적 사실, 역사적 사건 등을 알고 있어야 한다. 따라서 MMLU는 주로 사전 훈련이 얼마나 잘 되었는지를 측정한다.
의학 분야 예시: 환자의 특정 수치(혈압, 간 수치 등)가 주어지고, "병변은 어디에 있을 가능성이 높은가?"를 4개 선택지 중 고르는 문제다. 의학 교과서의 지식 없이는 답할 수 없다.
AIME: 수학 추론
**AIME(American Invitational Mathematics Examination)**는 미국의 수학 올림피아드 예선 시험이다. 고교 수준의 고난도 수학 문제가 출제된다.
형식. 각 문제의 정답은 세 자리 정수다. 이 제한된 형식 덕분에 LLM 평가에 적합하다. 모델의 출력에서 세 자리 숫자를 추출하여 정답과 비교하면 된다.
특성. AIME 문제는 한 문장으로 제시되지만 풀이에는 상당한 추론이 필요하다. 단순히 지식을 회상하는 것이 아니라, 여러 단계의 수학적 추론을 거쳐야 한다. 따라서 6장에서 다룬 **추론 모델(reasoning models)**의 성능을 직접적으로 평가한다.
PIQA: 상식 추론
**PIQA(Physical Interaction Question Answering)**는 물리적 상호작용에 대한 상식 추론을 평가한다. 일상 세계에서 사물이 어떻게 작동하는지에 대한 이해를 테스트한다.
형식. 2지선다 객관식으로, 약 20,000개의 예제가 포함되어 있다.
특성. PIQA는 수학이 아닌 일상적 물리 상식을 평가한다. 예를 들어:
질문: 카펫에서 잃어버린 작은 물건을 찾으려면? - (A) 밀봉된 막으로 진공청소기를 막고 청소한다. - (B) 헤어넷으로 진공청소기 입구를 막고 청소한다.
정답은 (B)다. 밀봉된 막으로 막으면 공기가 통하지 않아 흡입이 안 되지만, 헤어넷으로 막으면 공기는 통과하되 물건은 헤어넷에 걸린다. 이는 상식이지만 명시적으로 학습하지 않으면 자명하지 않을 수 있으며, 모델의 물리적 추론 능력을 시험한다.
SWE-bench: 코딩
**SWE-bench(Software Engineering Benchmark)**는 실제 소프트웨어 엔지니어링 과제에서 모델의 코딩 능력을 평가한다.
구축 방법. 인기 있는 Python 저장소에서, (1) 이슈를 해결하고 (2) 테스트를 도입한 풀 리퀘스트를 수집했다. 이 풀 리퀘스트가 도입한 테스트는 수정 전에는 실패하고 수정 후에는 통과한다는 가정이 핵심이다.
평가 방법. 모델에게 코드베이스와 GitHub 이슈를 제공하고, 패치를 생성하도록 요청한다. 모델이 제안한 패치를 적용한 뒤, 테스트가 통과하는지 확인한다. 이는 **테스트 주도 개발(test-driven development)**의 원리를 차용한 것이다.
코딩 벤치마크의 의의. 코딩 능력은 두 가지 이유로 중요하다. 1. AI 보조 코딩 도구의 품질을 직접 평가한다. 2. 에이전트 워크플로에서 도구 호출 코드를 읽고 쓰는 능력과 직결된다.
HarmBench: 안전성
**HarmBench(Harmful Behavior Benchmark)**는 모델이 유해한 콘텐츠를 생성하지 않는지 평가한다.
주의점. 안전성 벤치마크는 다른 벤치마크와 성격이 다르다. 각 LLM 제공사마다 안전성 정책이 다르므로, 모든 모델을 동일 벤치마크로 단순 비교하기 어렵다. 따라서 모델 카드에서 안전성은 별도 섹션으로 다루지, 다른 벤치마크처럼 모델 간 순위를 매기는 용도로 쓰이지 않는 경우가 많다.
4가지 범주:
범주 |
설명 |
|---|---|
표준(Standard) |
일반적인 유해 행동 유도 시도 |
저작권(Copyright) |
저작권 보호 콘텐츠 생성 유도 |
맥락적(Contextual) |
텍스트 기반의 맥락적 유해 행동 |
멀티모달(Multimodal) |
텍스트 외 다른 모달리티를 활용한 유해 행동 |
평가 방법. HarmBench의 유해 시도는 자유 형식이므로, 정규 표현식 매칭만으로는 평가할 수 없다. 대신 **분류기(classifier)**를 훈련하여 모델의 응답이 유해한 행동을 시도했는지 판단한다. 중요한 구분은, 유해 행동이 실제로 성공했는지가 아니라 시도 자체를 했는지가 기준이라는 점이다. 모델 능력이 부족해서 실패했더라도, 시도했다면 공격 성공으로 간주한다.
이 벤치마크는 분류기 자체가 오류를 가질 수 있다는 점에서, 하드코딩된 정답을 비교하는 다른 벤치마크보다 불확실성이 높다.
Tau-Bench: 에이전트
**Tau-Bench(Tool Agent User Benchmark)**는 에이전트의 도구 사용 능력을 종합적으로 평가한다. Tau는 Tool-Agent-User의 약자다.
구성. 항공(airline)과 소매(retail) 두 분야에서 도구 세트, 정책(에이전트가 할 수 있는 것과 할 수 없는 것), 과제(task)를 제공한다.
특징: LLM 시뮬레이션 사용자. 에이전트와 사용자의 대화를 하드코딩할 수 없다. 이전 턴의 응답에 따라 이후 턴이 달라지기 때문이다. 따라서 Tau-Bench에서는 별도의 대규모 모델이 사용자 역할을 시뮬레이션한다. 에이전트와 시뮬레이션 사용자가 대화를 주고받으며, 과제 달성 여부를 평가한다.
평가 방법. 대화가 끝나면 데이터베이스의 상태 변화(예: 항공권이 실제로 변경되었는지)와 수행된 액션을 확인하여 보상(reward)을 계산한다.
pass^K 지표. 7장에서 다룬 pass@K(K번 시도 중 최소 1회 성공 확률)와 달리, Tau-Bench는 **pass^K(pass-hat-K)**를 사용한다. 이는 K번 시도 전부 성공할 확률이다.
\[\text{pass}^K = \left(\frac{c}{n}\right)^K\]
여기서 \(c\)는 성공 횟수, \(n\)은 총 시도 횟수다. 항공 예약이나 소매 주문 같은 실제 서비스에서는, 10번 중 8번 성공하는 에이전트로는 충분하지 않다. 매번 일관되게 성공하는 신뢰성이 필요하다. pass^K는 이 요구를 반영한다.
벤치마크의 한계와 주의점
벤치마크는 LLM의 프로파일을 파악하는 도구다. 어떤 모델이 모든 벤치마크에서 최고인 경우는 드물며, 각 모델마다 강점과 약점이 있다.
데이터 오염(Data Contamination). 벤치마크가 유효하려면, 모델이 훈련 중에 벤치마크의 정답을 보지 않았어야 한다. 이를 방지하기 위해: - 해시값을 도입하여 데이터 유출을 탐지한다. - 도구 사용 벤치마크에서는 정답이 포함된 웹사이트에 대한 차단 목록(block list)을 운영한다. - 수학 벤치마크(AIME 등)는 매년 새로운 문제가 출제되므로, 모델이 확실히 보지 못한 문제로 평가할 수 있다.
굿하트의 법칙(Goodhart's Law). "측정 지표가 목표가 되면, 좋은 측정 지표이기를 멈춘다." 벤치마크 점수만 최적화하면, 실제 사용자 경험과 괴리가 생길 수 있다. 따라서 벤치마크 결과는 Chatbot Arena 같은 실사용 기반 평가와 함께 해석해야 하며, 궁극적으로는 자신의 용도에 맞는 모델을 직접 시험해 보는 것이 가장 신뢰할 수 있다.
파레토 프론티어. 비용 대비 성능, 안전성 대비 성능 등 여러 축으로 모델을 배치하면, 특정 제약 조건에서 최적인 모델의 경계선을 **파레토 프론티어(Pareto frontier)**라 한다. 실무에서는 단일 벤치마크 점수가 아니라, 비용, 지연 시간, 안전성 등 자신이 중요시하는 차원에서의 트레이드오프를 고려하여 모델을 선택한다.
핵심 정리
개념 |
핵심 |
|---|---|
평가 범위 |
출력 품질(사실성, 유용성, 일관성)에 초점. 시스템 지표(지연, 비용)는 별도 |
일치율의 한계 |
무작위 응답도 높은 일치율 가능. 우연 기준선 보정 필요 |
코헨의 카파 |
\(\kappa = (p_o - p_e)/(1 - p_e)\). 우연 제거 후 순수 일치도 측정 |
플라이스/크리펜도르프 |
3명 이상의 평가자, 결측값, 다양한 척도에 대한 확장 |
METEOR |
\(F_\text{score} \times (1 - \text{Penalty})\). 유니그램 매칭 + 순서 벌점 |
BLEU |
\(n\)-그램 정밀도 + 간결성 벌점. 번역 평가용 |
ROUGE |
재현율 중심. 요약 평가용. ROUGE-N, ROUGE-L 등 변형 |
규칙 기반 한계 |
문체 변형 불허, 낮은 인간 상관, 참조 텍스트 필요 |
LLM-as-a-Judge |
점수 + 근거 출력. 참조 불필요. 구조화된 출력으로 형식 보장 |
포인트와이즈/페어와이즈 |
단일 응답 절대 평가 vs. 두 응답 상대 비교 |
위치/장황함/자기 강화 편향 |
순서 교체, 가이드라인 명시, 다른 모델 사용으로 완화 |
모범 사례 |
이진 척도, 근거→점수 순서, 낮은 온도, 인간 평가 교정 |
사실 정확도 평가 |
사실 분해 → 개별 검증 → 가중 집계. RAG/웹 검색 활용 |
에이전트 실패 모드 |
도구 예측(4종), 도구 실행(2종), 결과 종합(1종). 체계적 분류가 핵심 |
MMLU |
60개 분야 4지선다. 사전 훈련 지식 측정 |
AIME |
수학 올림피아드. 세 자리 정수 정답. 추론 능력 측정 |
PIQA |
물리 상식 2지선다. 20K 예제. 일상 추론 측정 |
SWE-bench |
실제 GitHub 이슈 해결. 테스트 통과 여부로 평가 |
HarmBench |
4범주(표준/저작권/맥락/멀티모달). 분류기 기반 평가 |
Tau-Bench |
항공·소매 에이전트. LLM 시뮬레이션 사용자. pass^K로 신뢰성 측정 |
데이터 오염/굿하트 법칙 |
벤치마크 점수만 추구하면 실사용 성능과 괴리 발생 |
다음 장: 9장 - 종합 정리와 최신 동향