Attention Is All You Need
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, "Attention Is All You Need," presented at the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 2017.
저자
아시시 바스와니가 1저자입니다. 노암 셰이저, 니키 파마르, 야코프 우스코레이트, 리온 존스, 에이단 고메즈, 루카시 카이저, 일리아 폴로수킨까지 총 8명이 이름을 올렸습니다. 발표 당시 대부분이 Google Brain과 Google Research 소속이었고, 에이단 고메즈는 University of Toronto 학부생 신분으로 구글 인턴십 중이었습니다.
이 사람들, 지금은 무엇을 하고 있을까요?
아시시 바스와니, 니키 파마르, 리온 존스는 Essential AI를 공동창업했습니다.
에이단 고메즈는 Cohere를 창업해 엔터프라이즈 LLM 시장을 공략하고 있습니다.
노암 셰이저는 Character.AI를 만들었다가 Google로 복귀했고, 2026년 6월 OpenAI로 이적했습니다.
야코프 우스코레이트는 RNA 약물 설계 스타트업 Inceptive를 세웠습니다.
일리아 폴로수킨은 블록체인 프로토콜 NEAR를 공동창업했습니다.
루카시 카이저는 OpenAI 연구원을 거쳤습니다. 논문 하나에서 시작해 LLM, 엔터프라이즈 AI, 생명공학, 블록체인으로 뻗어나간 팀입니다.
배경
2017년 이전까지 시퀀스-투-시퀀스 모델링의 주류는 RNN, LSTM, GRU였습니다. 이 구조들은 토큰을 순서대로 하나씩 처리합니다. 앞 단계 계산이 끝나야 다음 단계로 넘어가기 때문에 학습을 병렬화하기 어렵습니다. 긴 시퀀스에서는 소실 기울기(vanishing gradient) 문제로 먼 위치의 의존성을 포착하는 데도 한계가 있었습니다.
어텐션 메커니즘은 이미 있었습니다. 당시에는 RNN의 보조 구성요소로만 쓰였습니다. 디코더가 인코더 출력의 어느 부분에 집중할지 부드럽게 선택하는 용도였습니다. 이 논문의 핵심 질문은 "어텐션만으로 순환 구조를 완전히 대체할 수 있는가"였습니다.
결론은 그렇다는 것이었습니다. 재귀(recurrence)와 컨볼루션(convolution)을 모두 버리고 어텐션만 남긴 것이 트랜스포머입니다. 병렬 처리가 가능해졌고, 임의의 두 위치 사이 경로 길이가 \(O(1)\)로 줄어 장거리 의존성 학습이 쉬워졌습니다.
어텐션 메커니즘
트랜스포머의 기반은 스케일드 닷-프로덕트 어텐션입니다. 쿼리 \(Q\), 키 \(K\), 값 \(V\) 행렬을 입력받아 다음을 계산합니다.
\[\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^{T}}{\sqrt{d_k}} \right) V\]
\(\sqrt{d_k}\)로 나누는 이유는 내적이 커질수록 소프트맥스 기울기가 0에 가까워지기 때문입니다. 스케일링이 없으면 학습이 불안정해집니다.
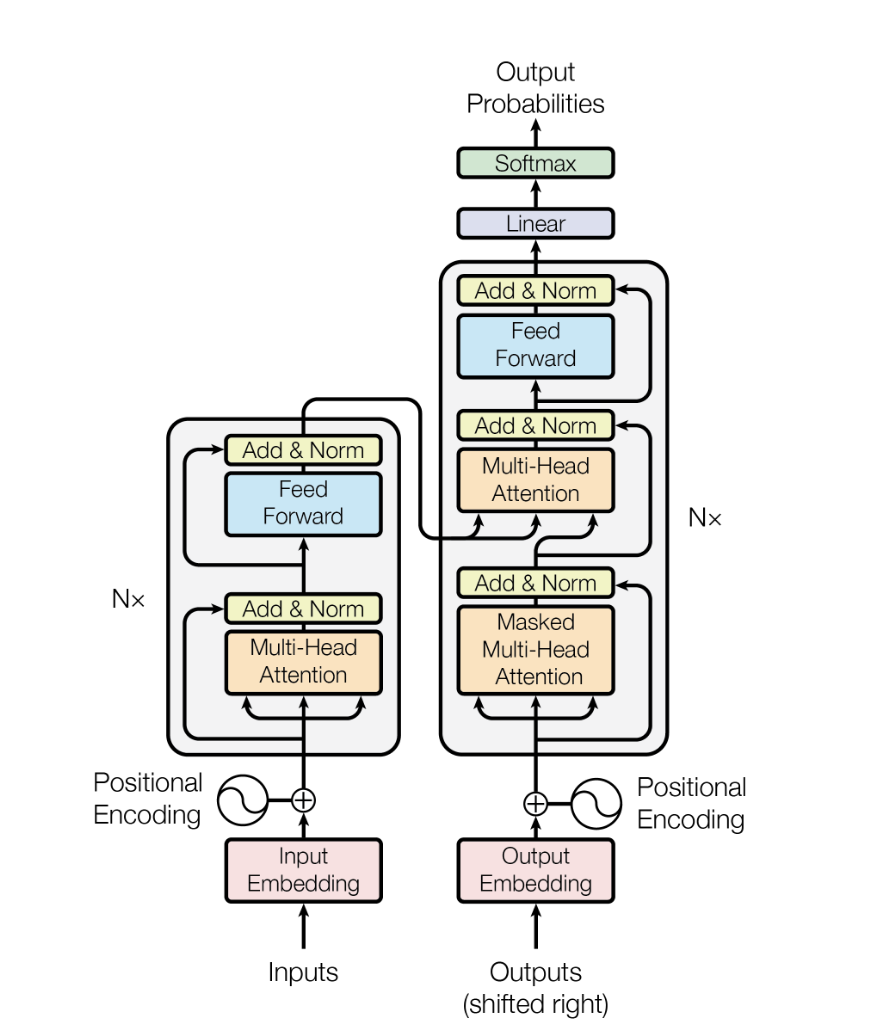
멀티 헤드 어텐션은 이 연산을 \(h\)개 부분공간에서 병렬로 수행합니다.
\[\begin{aligned} \text{MultiHead}(Q, K, V) &= \text{Concat}(\text{head}_1, \dots, \text{head}_h) W^O \\ \text{where } \quad \text{head}_i &= \text{Attention}(Q W_i^Q, \; K W_i^K, \; V W_i^V) \end{aligned}\]
헤드마다 서로 다른 관계를 포착합니다. 구문 의존성을 보는 헤드와 의미 연결을 보는 헤드가 분리됩니다. 논문에서는 \(h=8\)이 최적임을 절제 실험으로 확인했습니다.
트랜스포머는 어텐션을 세 가지 방식으로 씁니다.
- 인코더 셀프 어텐션: 입력 시퀀스의 모든 위치가 서로 참조합니다.
- 디코더 마스킹 셀프 어텐션: 현재 위치는 이전 위치만 참조합니다. 미래 토큰을 보지 않도록 마스킹합니다.
- 인코더-디코더 어텐션: 디코더 각 위치가 인코더 출력 전체를 참조합니다.
위치 인코딩
순환 구조를 버렸기 때문에 위치 정보를 별도로 주입해야 합니다. 저자들은 사인·코사인 함수를 씁니다.
\[\begin{aligned} PE_{(pos,\, 2i)} &= \sin\!\left( pos \,/\, 10000^{\,2i / d_{\text{model}}} \right) \\ PE_{(pos,\, 2i+1)} &= \cos\!\left( pos \,/\, 10000^{\,2i / d_{\text{model}}} \right) \end{aligned}\]
\(pos\)는 토큰 위치, \(i\)는 차원 인덱스입니다. 주파수가 차원마다 달라 각 위치에 고유한 벡터가 만들어집니다. 학습된 위치 임베딩 대비 성능 차이가 크지 않았으나, 훈련 중 보지 못한 더 긴 시퀀스로 외삽이 가능하다는 장점이 있습니다.
결과
WMT 2014 기계 번역 두 벤치마크에서 당시 SOTA를 경신했습니다.
시스템 |
EN-DE (BLEU) |
EN-FR (BLEU) |
훈련 비용 (FLOPs) |
|---|---|---|---|
Transformer (big) |
28.4 |
41.8 |
\(2.3 \times 10^{19}\) |
Transformer (base) |
27.3 |
38.1 |
\(3.3 \times 10^{18}\) |
ByteNet |
23.75 |
- |
- |
Deep-Att + PosUnk |
- |
39.2 |
\(1.0 \times 10^{20}\) |
GNMT + RL (앙상블) |
26.30 |
41.16 |
\(1.4 \times 10^{20}\) |
ConvS2S (앙상블) |
26.36 |
40.46 |
\(1.5 \times 10^{20}\) |
Transformer (big)이 EN-DE에서 28.4 BLEU로 당시 앙상블 SOTA를 단독 모델로 넘었습니다. EN-FR에서는 41.8 BLEU로 역시 당시 최고 앙상블 기록(41.16)을 경신했습니다. 훈련 비용은 앙상블 경쟁 모델 대비 \(\frac{1}{6}\) 수준입니다.
Transformer (base)는 12시간 훈련으로 이미 이전 SOTA를 넘어섰습니다. 속도 대비 품질 격차가 아키텍처 선택의 결정적인 근거가 되었습니다.
절제 실험(ablation)에서 주요 발견은 다음과 같습니다.
- 어텐션 헤드 수는 8개가 최적. 1개(단일 헤드)보다 확연히 낫고, 16개 이상이면 성능이 오히려 떨어집니다.
- 키 차원 \(d_k\)를 줄이면 품질이 저하됩니다. 내적 스케일링의 중요성을 확인합니다.
- 드롭아웃 없이는 과적합이 납니다.
- 학습된 위치 임베딩과 사인파 위치 인코딩의 성능 차이는 미미합니다.
일반화 능력 확인을 위해 영어 구성 구문 분석(constituency parsing)에도 적용했습니다. 태스크 특화 수정 없이 경쟁력 있는 결과를 냈습니다. 어텐션 기반 아키텍처가 번역 이외 시퀀스 태스크에도 범용적으로 작동한다는 근거입니다.
한계
논문 자체가 명시한 한계보다 이후 연구에서 드러난 문제가 더 큽니다. 셀프 어텐션의 계산 복잡도는 시퀀스 길이 \(n\)에 대해 \(O(n^2)\)입니다. 짧은 문장에서는 문제 없지만 문서 단위 처리에서는 메모리와 시간 비용이 급격히 올라갑니다. 이후 Sparse Transformer, Longformer, Flash Attention 등 어텐션 효율화 연구가 줄지어 나온 배경입니다.
위치 인코딩도 한계로 지적됩니다. 사인파 방식은 상대 위치보다 절대 위치를 인코딩하기 때문에 긴 시퀀스 일반화가 충분하지 않습니다. RoPE, ALiBi 같은 상대 위치 인코딩이 이를 해결하려는 시도입니다.
정리
- 어텐션만으로 순환·컨볼루션을 대체할 수 있음을 증명했습니다.
- 병렬 처리 가능으로 훈련 속도가 높아지고, 장거리 의존성 포착이 쉬워졌습니다.
- 기계 번역에서 당시 SOTA를 낮은 비용으로 경신했습니다.
- GPT, BERT, Claude, Gemini 등 현대 LLM 전부가 이 아키텍처를 기반으로 합니다.