AI 벤치마크 포화 문제
 Claude Mythos Preview 시스템 카드에 이런 문장이 있었습니다.
Claude Mythos Preview 시스템 카드에 이런 문장이 있었습니다.
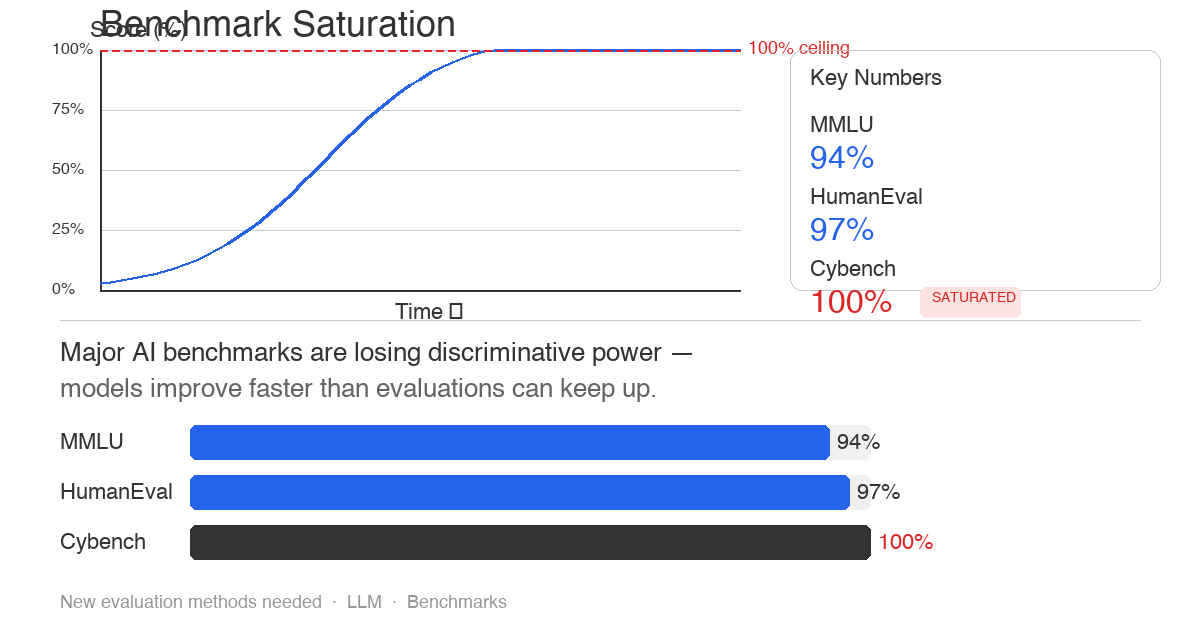
Cybench 벤치마크가 프론티어 모델에 더 이상 충분히 유의미하지 않다.
Cybench는 CTF 챌린지 40개로 구성된 사이버보안 벤치마크입니다. 상당히 어렵게 설계됐고, 전문 해커도 쉽게 풀지 못하는 문제들입니다. 그런데 Mythos Preview가 35개 서브셋에서 pass@1 100%를 기록했습니다.
Cybench만의 문제가 아닙니다. MMLU는 프론티어 모델들이 이미 88% 이상을 기록하면서 사실상 변별력을 잃었습니다. arXiv에 올라온 논문(2602.16763)은 60개 LLM 벤치마크를 분석한 결과, 절반 가까이가 포화 상태라고 결론 짓습니다.
포화가 왜 생기는가
두 가지 이유가 겹칩니다.
첫째, 모델이 너무 빨리 좋아집니다. "몇 년은 버틸 것"이라고 만든 벤치마크가 몇 달 만에 포화되는 일이 반복되고 있습니다. Cybench가 그랬고, HumanEval이 그랬습니다.
둘째, 훈련 데이터 오염입니다. 벤치마크 문제가 인터넷에 공개돼 있으면, 그 답이 훈련 데이터에 포함될 수 있습니다. 모델이 실제로 잘하는 게 아니라 정답을 기억하는 것일 수 있습니다. 흥미로운 발견이 있는데, 논문에 따르면 테스트 데이터를 비공개로 유지해도 포화 방지에는 별 효과가 없었습니다. 오염 경로가 더 다양하다는 의미입니다.
벤치마크를 세 묶음으로 보기
지금 벤치마크를 이야기하려면 적어도 세 묶음으로 나눠야 합니다. 이미 포화된 것, 아직 변별력이 남아 있는 것, 새로 등장한 것.
1) 이미 포화된 벤치마크
프론티어 모델 비교에는 사실상 쓸모를 잃은 벤치마크들입니다.
- *MMLU* (2020): 57개 과목 객관식. 프론티어 모델이 88~94% 구간에 몰려 있습니다. 2026년 4월 기준 Gemini 3.1 Pro 94.3%, Claude Opus 4.6 91.3%로 노이즈 ±1.7% 수준의 차이라 통계적 의미가 없습니다. Vellum은 아예 "outdated"로 분류하고 리더보드에서 제외했습니다.
- *HellaSwag* (2019): 상식 추론 객관식. 프론티어 모델들이 95% 이상으로 포화.
- *GSM8K* (2021): 초등 수학 문장제. 99%대에 도달. 모델이 초등 수학을 "다 풀 수 있다"는 의미가 아니라, 이 데이터셋의 분포에 대해 변별력이 사라졌다는 뜻입니다.
- *HumanEval* (2021): 164개 파이썬 과제. 93%+ 구간에 프론티어가 몰려 있고, 훈련 오염이 가장 많이 지적되는 벤치마크 중 하나입니다.
- *ARC (Easy/Challenge)*, CommonsenseQA, SQuAD: 상단이 압축됐거나 사람 상한에 근접.
이 묶음의 공통점은 앞서 본 포화 패턴과 정확히 겹칩니다. 객관식, 공개된 지 오래, 정답 고정.
2) 아직 변별력이 남아 있는 벤치마크
상단은 어느 정도 채워지고 있지만, 프론티어 모델 사이에 의미 있는 차이가 나오는 구간입니다.
- *MMLU-Pro*: MMLU의 후계. 선택지를 4개→10개로 늘리고 추론 단계를 강화했습니다. 프론티어 모델 점수가 MMLU 대비 14~16점 하락하면서 차이가 다시 보이기 시작합니다. 다만 출시 18개월이 지난 지금은 상단이 다시 압축되는 중입니다.
- *GPQA Diamond*: 대학원 수준 과학 문제. 최상단은 접근 중이지만 60~90% 구간에서 모델을 명확히 구분합니다. 제작 시 비전공자는 구글을 써도 풀지 못하게 설계했습니다.
- *SWE-bench Verified*: 실제 GitHub 이슈를 해결하는 과제. 환경 기반 평가라 정답을 암기하기 어렵습니다. 엔터프라이즈 업무 성능과 상관관계가 가장 높은 벤치마크로 꼽힙니다. 현재 Claude Opus 4.6 80.8%, Gemini 3.1 Pro 80.6%로 상단은 좁아졌지만 중위권 모델과의 격차는 여전히 뚜렷합니다.
- *LiveCodeBench*: 컨테스트 사이트에서 출시 후 등장한 문제만 수집해 훈련 오염을 구조적으로 차단합니다. 시간이 지나도 "신선한" 문제가 계속 유입되는 설계.
- *OSWorld-Verified*: 실제 컴퓨터 조작 과제. 환경이 작업 완료 여부를 직접 확인합니다. 인간 전문가 72.4%가 기준선.
- *Terminal-Bench 2.0*, BrowseComp: 각각 터미널·웹 내비게이션 과제. 환경 기반이라 오염에 강합니다.
이 묶음은 (ⅰ) 개방형·환경 기반이거나, (ⅱ) 문제를 계속 갱신하거나, (ⅲ) 전문가 큐레이션으로 난이도 상단을 밀어올렸다는 공통점이 있습니다.
3) 신생 프론티어 벤치마크
"지금 만들어도 몇 년은 버티게" 설계된 벤치마크들입니다.
- *Humanity's Last Exam (HLE)* (2025): 1,000명 가까운 전문가가 만든 2,500문제. 수학·인문학·자연과학 전반. 인간 도메인 전문가 평균 90%, 최강 AI 35% 내외로 격차가 크게 남아 있습니다. Nature 2026년 게재. Center for AI Safety가 공동 제작.
- *FrontierMath* (2024~): 미공개 원본 수학 문제 300개(Tier 1–3) + 50개(Tier 4). 파이썬·계산 도구 사용 허용. 현재 선두 GPT-5.4가 47.6%. Tier 4는 프로 수학자가 며칠씩 걸리는 난이도로 설계됐습니다.
- *ARC-AGI-2*: 추상 추론 퍼즐. Gemini 3.1 Pro 77.1%로 전 세대 대비 2배 이상 상승. 2026년 ARC-AGI-3 출시 예정이며, 정적 추론에서 상호작용적 추론으로 포맷을 바꿉니다 — 2019년 이후 첫 대규모 포맷 변경.
- *GDPval*: OpenAI가 주도한 직무 기반 평가. 미국 GDP 상위 9개 산업, 44개 직업군의 실제 업무 산출물로 채점. "경제적 가치가 있는 일을 실제로 할 수 있는가"를 측정합니다. GPT-5.4 83%.
- *MMMU-Pro*, OfficeQA Pro: 각각 멀티모달·오피스 업무 중심의 차세대 버전.
이 묶음의 공통점은 (ⅰ) 전문가 큐레이션, (ⅱ) 비공개 혹은 지속 갱신되는 문제 풀, (ⅲ) 단답이 아닌 개방형·검증형 채점입니다. 앞에서 본 "포화에 강한 설계 요소"를 정확히 따르고 있습니다.
포화된 벤치마크의 공통점
왜 어떤 건 포화되고 어떤 건 버티는가. 논문이 14가지 벤치마크 설계 요소를 분석한 결과, 몇 가지 패턴이 보입니다.
- 크라우드소싱 vs 전문가 큐레이션: 전문가가 직접 만든 벤치마크가 포화에 더 강합니다. 크라우드소싱은 더 빨리 포화됩니다.
- 정답의 고정성: 단답형·객관식은 훈련 데이터 오염에 취약합니다. 개방형 과제, 환경 기반 평가가 더 오래 버팁니다.
- 난이도 분포: 상단 난이도가 충분하지 않으면 모델이 좋아질수록 금방 천장에 닿습니다.
- 문제 풀의 정적/동적: 한 번 공개되고 고정된 풀은 결국 오염과 과적합에 노출됩니다. LiveCodeBench처럼 지속 갱신되거나 HLE처럼 비공개 유지 가능한 설계가 오래 버팁니다.
바로 앞 세 묶음의 경계가 이 요소들로 설명됩니다. MMLU·HumanEval이 1번 묶음(포화)으로 내려간 이유, HLE·FrontierMath가 3번 묶음(신생)에서 버티는 이유가 같은 원리입니다.
기업 프로덕션에서의 격차
Stanford HAI 2026 AI Index는 "벤치마크 점수와 실제 배포 성능 사이의 격차가 역대 가장 크다"고 지적합니다. 에이전틱 AI 시스템에서는 이 격차가 37%에 달한다는 분석도 있습니다.
즉, A 모델의 벤치마크 점수가 B 모델보다 높다고 해서 실제 업무에서 A가 낫다고 볼 수 없습니다. 이 격차가 커질수록 벤치마크 비교는 실용적 의미를 잃어갑니다.
실제로 일어난 일들
추상적인 이야기가 아닙니다. 최근 몇 년간 메이저 모델 출시에서 포화된 벤치마크를 근거로 우위를 주장한 사례가 계속 나왔습니다.
Llama 4 Maverick (Meta, 2025년 4월): Meta는 출시 당시 LMArena에서 2위에 올랐다며 성능을 홍보했지만, 공개 버전이 아니라 벤치마크용으로 별도 튜닝한 "실험 버전"을 제출한 것이 드러났습니다. 공개 버전이 업로드되자 순위는 2위에서 32위로 주저앉았습니다. LMArena는 "Meta의 해석이 우리가 기대한 기준과 달랐다"며 정책을 업데이트했고, 업계에서는 이를 "시험 문제를 미리 보고 들어간 것"이라고 비판했습니다.
Claude 3 Opus (Anthropic, 2024년 3월): 출시 공지문은 GPT-4·Gemini 1.0 Ultra와의 비교표를 중심에 두고 MMLU, GSM8K, HumanEval 등 당시 이미 상단이 압축되고 있던 벤치마크에서의 우위를 강조했습니다. 당시에도 MMLU는 88% 근처에 몰려 있어 차이가 실제 능력 차이인지 노이즈인지 구분이 어려웠습니다.
이런 마케팅 패턴이 반복되면서 Vellum 같은 리더보드는 아예 MMLU를 "구식(outdated)" 벤치마크로 분류하고 비교에서 제외하기 시작했습니다. InfoWorld는 Llama 4 사건을 두고 "엔터프라이즈 리더들이 벤치마크 점수를 액면 그대로 받아들이면 안 되는 이유"라고 정리했습니다.
그래서 어떻게 해야 하는가
공정하게 말하면, 벤치마크가 완전히 무용해진 건 아닙니다. 완전히 새로운 모델을 처음 평가할 때, 기본적인 능력 체크 용도로는 여전히 쓸 수 있습니다.
문제는 "이 모델이 저 모델보다 낫다"는 주장에 포화된 벤치마크를 근거로 쓰는 것입니다. 위의 사례들이 보여주듯, 마케팅 문서에서 자주 볼 수 있는 패턴입니다.
실제로 어떤 모델을 써야 하는지 판단하려면, 자신의 실제 작업에 모델을 직접 돌려보는 것 외에 현재로선 더 신뢰할 수 있는 방법이 없습니다. 불편하지만, 그게 현실입니다.
참고: - When AI Benchmarks Plateau: A Systematic Study | arXiv:2602.16763 - AI Benchmarks Are Broken | MIT Technology Review - Technical Performance | Stanford HAI 2026 AI Index - Humanity's Last Exam | Nature - Meta accused of Llama 4 bait-n-switch to juice LMArena rank | The Register - What misleading Meta Llama 4 benchmark scores show enterprise leaders | InfoWorld - Introducing the next generation of Claude | Anthropic - FrontierMath Leaderboard | llm-stats - ARC Prize 2025 Results and Analysis - LLM Benchmarks 2026: MMLU, GPQA Diamond, HLE, LiveCodeBench | CodeSOTA