LoopCoder-v2 - Only Loop Once for Efficient Test-Time Computation Scaling
J. Yang, S. Guo, W. Zhang, T. Zheng, et al., "LoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling," arXiv:2606.18023, 2026.
저자
1저자 Jian Yang은 북항공항천대학교(Beihang University) 소속으로, Wayne Xin Zhao 등 여러 기관의 연구자들과 공동 연구했습니다. 주력 실험 팀은 IQuest Research이며, Ming Zhou(Langboat)와 Wayne Xin Zhao(중국인민대학교 고링 인공지능학원 교수)가 시니어 저자로 참여했습니다. Wayne Xin Zhao는 LLM 대형 서베이 논문으로 잘 알려진 NLP 연구자입니다.
배경
루프드 트랜스포머(Looped Transformer)는 단일 파라미터 공유 블록을 여러 번 반복 적용해 파라미터 수를 늘리지 않고도 계산 깊이를 늘리는 방식입니다. 이는 테스트 타임 컴퓨팅 스케일링의 매력적인 형태입니다. 보조 추론 토큰 없이 내부 잠재 공간에서 추가 정제가 이루어집니다.
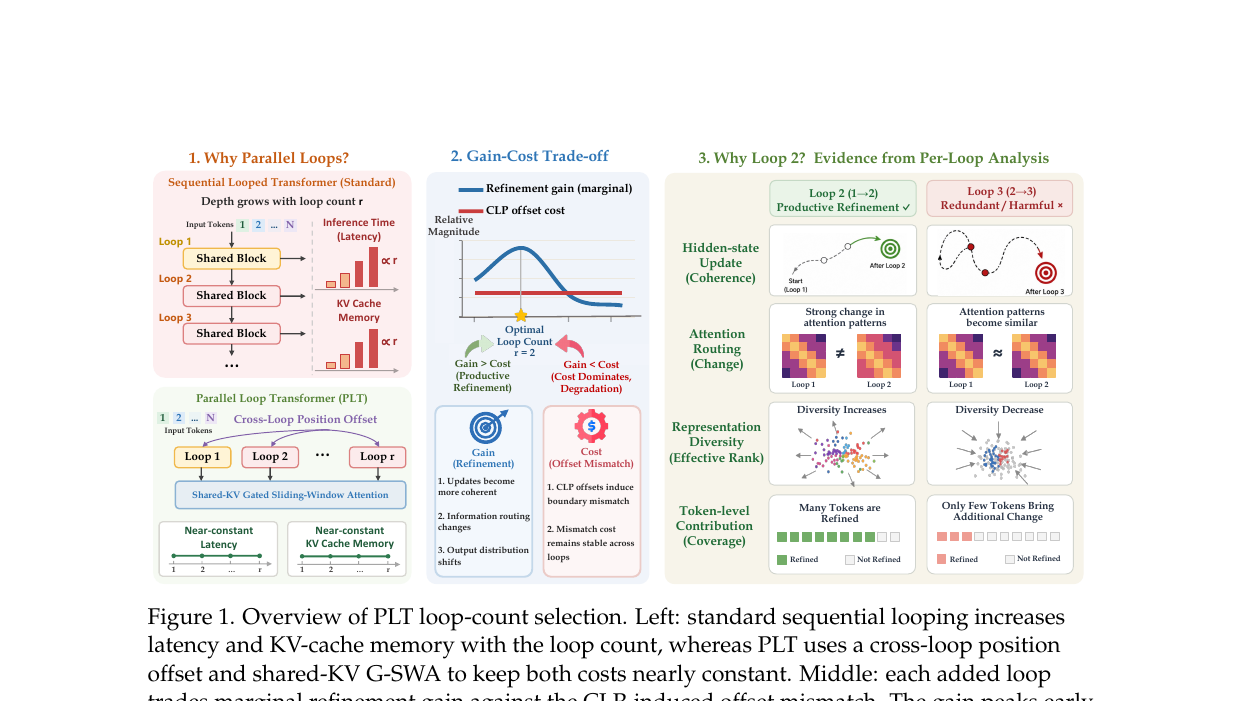
그러나 표준 순차 루프는 배포 효율이 낮습니다. 루프마다 공유 블록을 순차적으로 한 번 더 통과해야 하고, KV 캐시 메모리가 루프 수에 비례해 증가합니다. PLT(Parallel Loop Transformer)는 이 두 비용을 제거합니다.
그런데 PLT로 비용을 해결하더라도 "루프를 몇 번 돌리면 최선인가"라는 질문이 남습니다. 이 논문은 이 질문에 답하기 위해 7B 규모에서 루프 수를 \(R \in \{1, 2, 3, 4\}\)로 달리 학습한 뒤 성능을 비교하고, 내부 표현을 분석합니다. 결론은 단순합니다: 루프 2번이 최적이고, 3번째 루프부터는 오히려 퇴보합니다.
어떻게 만들었나
PLT 메커니즘
표준 순차 루프 트랜스포머는 다음과 같이 정의됩니다.
\[h^{(0)} = \text{Embed}(x), \quad h^{(r)} = f_\theta\!\left(h^{(r-1)}\right), \quad r=1,\ldots,R, \quad \text{logits} = \text{Head}\!\left(h^{(R)}\right)\]
파라미터 \(f_\theta\)를 공유하므로 유효 깊이는 \(R \cdot L\)로 늘어나지만, 파라미터 수는 단일 블록 \(L\)개 레이어 분량에 고정됩니다. 문제는 \(h^{(r)}\)이 \(h^{(r-1)}\)에 의존하므로 순차 실행이 강제된다는 점입니다. 레이턴시는 \(O(R)\), KV 캐시 메모리도 \(O(R \cdot L \cdot S \cdot d)\)로 증가합니다.
PLT는 두 가지 메커니즘으로 이를 해결합니다.
공유 KV 캐시 + G-SWA: 루프 1의 KV 캐시 \(K_\text{share}, V_\text{share}\)를 이후 루프에서 재사용해 메모리를 \(O(L \cdot S \cdot d)\)로 고정합니다. 비첫 루프의 어텐션은 두 컴포넌트를 게이트로 혼합합니다.
\[\tilde{y}^{(r)} = g \odot y^{(r)}_\text{global} + (1-g) \odot y^{(r)}_\text{local}, \quad g = \sigma\!\left(f_\text{gate}(\text{RMSNorm}(h))\right)\]
\(y^{(r)}_\text{global}\)은 동결된 루프 1 KV 캐시에 대한 전체 컨텍스트 어텐션, \(y^{(r)}_\text{local}\)은 현재 루프 KV에 대한 슬라이딩 윈도우(폭 \(w=64\)) 어텐션입니다.
교차 루프 위치 오프셋(CLP): 루프 \(r \geq 2\) 시작 전 이전 루프의 은닉 상태를 한 토큰 위치 오른쪽으로 시프트한 뒤 입력에 합산합니다.
\[B^{(r)} = \text{Embed}(x) + \text{shift}\!\left(h^{(r-1)}\right), \quad h^{(r)} = f_\theta\!\left(B^{(r)}\right)\]
이로써 토큰 \(x_i\)의 루프 \(r\)을 \(x_{i-1}\)의 루프 \(r+1\)과 동시에 계산할 수 있어, 레이턴시가 루프 수에 무관하게 거의 단일 패스 수준으로 유지됩니다.
이득-비용 관점
CLP 오프셋에는 비용이 따릅니다. 루프 \(r \geq 2\)에서 토큰 \(x_i\)는 자신의 루프 \(r-1\) 상태 대신 이웃 \(x_{i-1}\)의 루프 \(r-1\) 상태를 받습니다. 이 위치 불일치를 내재 오프셋 비용으로 정의합니다.
\[\Omega^{(r)} = \frac{1}{S} \sum_i \left\| h_i^{(r-1)} - h_{i-1}^{(r-1)} \right\|_2\]
실험에서 \(\Omega^{(r)}\)은 루프가 늘어도 거의 일정합니다. 반면 각 루프의 정제 이득은 빠르게 감소합니다. 따라서 이득 \(\gg\) 비용인 구간은 루프 2까지이고, 그 이후로는 비용이 이득을 잠식합니다.
학습 설정
LoopCoder-v2는 텍스트·코드 1:1 혼합 18T 토큰으로 처음부터 학습한 7B PLT 코더입니다. 슬라이딩 윈도우 폭 \(w = 64\), G-SWA, CLP가 전 레이어에 적용됩니다. 학습 루프 수와 추론 루프 수를 맞춥니다: \(R = r\)로 학습한 모델은 \(R = r\)로 평가합니다. 전체 학습에 총 1백만 GPU 시간이 소요됐습니다. 이후 600만 건 지시 튜닝 예시로 동일 레시피의 SFT를 거칩니다.
결과
코드 생성·에이전틱 소프트웨어 엔지니어링 벤치마크 비교
모델 |
HE+ |
MultiPL-E |
BCB |
LCB |
SWE |
SWE-M |
평균 |
|---|---|---|---|---|---|---|---|
Baseline (R=1) |
81.1 |
69.5 |
40.1 |
27.4 |
43.0 |
14.0 |
38.0 |
LoopCoder-v2 (R=2) |
84.1 |
73.9 |
46.1 |
35.4 |
64.4 |
31.0 |
46.5 |
LoopCoder-v2 (R=3) |
75.0 |
69.8 |
43.3 |
28.6 |
27.6 |
11.0 |
36.9 |
LoopCoder-v2 (R=4) |
76.8 |
67.3 |
40.8 |
24.5 |
22.4 |
9.3 |
34.3 |
HE+: HumanEval+, MultiPL-E: 다국어 평균, BCB: BigCodeBench-Full, LCB: LiveCodeBench, SWE: SWE-bench Verified, SWE-M: SWE-bench Multilingual
\(R = 2\) 모델이 \(R = 1\) 대비 모든 주요 지표에서 오릅니다. SWE-bench Verified에서는 43.0% → 64.4%로 +21.4%p 상승하며, 30B~72B 오픈 모델들과 경쟁합니다. Multi-SWE에서도 14.0% → 31.0%로 두 배 이상입니다.
반면 \(R = 3\)이 되면 SWE-bench Verified가 27.6%로 R=1보다도 낮아집니다. \(R = 4\)는 22.4%로 더 하락합니다. 강하게 비단조(non-monotonic)한 곡선입니다.
루프별 내부 분석
루프 2가 정제의 핵심 지점입니다. 세 가지 분석 렌즈가 일치된 결론을 냅니다.
- 은닉 상태 동역학: 루프 2에서 유효 랭크(표현 다양성)가 정점에 달하고, 루프 3부터 좁아집니다. 루프 2는 이전 루프와 방향이 일치하는 일관된 갱신을 보이는 반면, 루프 3부터는 방향이 반전되는 진동성 갱신이 나타납니다.
- 어텐션 패턴 진화: 루프 간 KL 발산 \(D_\text{KL}^{(r)}\)이 루프 2에서 가장 크고 루프 3 이후 급감합니다. 정보 라우팅이 루프 2 이후 동결에 가까워진다는 의미입니다.
- 출력 분포 이동: 루프 2가 전체 정제 기여의 가장 큰 몫을 차지합니다. 루프 3부터는 출력 분포 이동이 미미해집니다.
회고
논문이 명시한 한계입니다.
첫째, 분석 범위: 해석 실험은 7B PLT 단일 모델에서 이루어졌습니다. 다른 크기나 다른 루프 구현에서도 같은 패턴이 나타날지는 미확인입니다.
둘째, 이진 설계 결론: "두 루프가 최적"이라는 결론은 현재 PLT 설계에서의 결과입니다. CLP 오프셋 방식이나 G-SWA 설계를 바꾸면 최적 루프 수가 달라질 수 있습니다.
셋째, 비용 모델의 단순성: \(\Omega^{(r)}\)이 루프에 걸쳐 일정하다는 관찰은 현재 모델에서의 경험적 결과입니다. 다른 시퀀스 길이·태스크·데이터 혼합에서도 이 안정성이 유지될지는 추가 검증이 필요합니다.
정리
- PLT는 교차 루프 위치 오프셋(CLP)과 공유 KV 어텐션(G-SWA)으로 루프 수에 무관한 레이턴시·메모리를 달성합니다. 추가 루프가 저렴해집니다.
- 그러나 CLP가 유발하는 위치 불일치 비용 \(\Omega^{(r)}\)은 루프마다 거의 일정한데, 정제 이득은 루프 2 이후 급감합니다. 이득-비용 교점이 \(R = 2\)에 있습니다.
- LoopCoder-v2 \(R = 2\)는 7B 모델로 SWE-bench Verified 64.4%를 달성해 수십 배 큰 오픈 모델들과 경쟁합니다. 루프 수 선택은 아키텍처 설계의 중요한 하이퍼파라미터입니다.