JetSpec - Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
L. Hu, Z. Feng, Y. Wu, H. Yuan, Y. Zhao, Y.-Y. Qian, B. Wang, P. Zhao, D. Jiang, Y. Zhu, T. Rosing, and H. Zhang, "JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting," arXiv:2606.18394, 2026.
LLM이 수학 문제를 풀거나 코드를 작성할 때, 토큰을 하나씩 순서대로 생성하는 방식은 근본적인 병목입니다. 투기적 디코딩(Speculative Decoding)은 작은 모델이 여러 토큰을 한꺼번에 초안(draft)으로 제안하면 큰 모델이 병렬로 검증하는 방법으로 이 병목을 공략합니다. 그런데 초안 예산(draft budget)을 더 많이 줄수록 속도가 오르기는 하지만, 생각처럼 무한정 오르지는 않습니다. 여기에는 구조적인 천장이 있습니다. JetSpec은 그 천장을 깨는 방법을 제안합니다.
저자
이 연구는 UC San Diego의 Hao Zhang 교수 팀(hao-ai-lab)과 중국 AI 스타트업 StepFun의 협력으로 탄생했습니다. 1저자 Lanxiang Hu는 같은 팀에서 Online Speculative Decoding(ICML 2024)과 CLLMs(ICML 2024)를 발표한 데 이어, 이번에는 투기적 디코딩의 스케일링 문제를 정면으로 다루는 작업을 이끌었습니다. Hao Zhang 교수는 vLLM과 LMSYS Org를 통해 LLM 서빙 인프라를 오픈소스로 공개해온 인물로, 실제 서빙 엔진(vLLM)에 JetSpec을 통합해 현장 검증까지 수행한 배경에는 이 팀의 시스템 경험이 있습니다. Tajana Rosing 교수(IEEE Fellow, SEElab 디렉터)는 하드웨어 효율 측면의 시니어 검토 역할을 맡았습니다.
배경
투기적 디코딩의 속도 향상은 수식으로 깔끔하게 표현됩니다. 초안 모델 \(M_q\)가 \(N\)개 토큰을 제안하면, 수락률 \(\alpha\)와 토큰당 드래프팅 비용 \(c\)에 따라 기대 가속은 다음과 같습니다.
\[\text{Speedup} = \frac{1-\alpha^{N+1}}{(1-\alpha)(Nc+1)}\]
분자는 한 번의 투기적 반복에서 수락되는 토큰 수(\(\mathbb{E}[\#\text{tokens}] = (1-\alpha^{N+1})/(1-\alpha)\))이고, 분모의 \(Nc+1\)은 드래프팅 비용과 검증 비용의 합입니다.
이 식은 한 가지 사실을 폭로합니다. \(N\)(예산)을 늘리는 것이 유효하려면 \(\alpha\)가 높게 유지되고 \(Nc\)가 작아야 합니다. \(N\)이 커질수록 \(\alpha\)가 조금만 떨어져도 분자 이득이 사라지고, \(c\)가 조금만 커져도 분모 비용이 가속을 잠식합니다.
기존 헤드 기반 방법들은 이 두 요소를 따로따로 공략해왔습니다. EAGLE 계열은 자기회귀(AR) 드래프터로 경로 조건부 후보를 생성하기 때문에 \(\alpha\)가 높지만, 트리 깊이가 커질수록 순차 드래프팅 패스가 쌓여 \(c\)가 증가합니다. DFlash는 블록-확산 방식으로 모든 위치를 한 번의 포워드 패스에 생성해 \(c\)를 극단적으로 낮추지만, 각 위치를 독립적으로 예측하기 때문에 분기 간 인과 관계가 없어 개별적으로는 그럴듯해도 함께 두면 모순되는 토큰 조합이 만들어집니다. 결과적으로 \(\alpha\)가 낮아집니다.
인과성과 효율, 두 마리 토끼를 잡는 방법이 없었습니다.
아이디어
JetSpec의 핵심 통찰은 간결합니다. 드래프트 헤드에 **트리-인과 어텐션 마스크(tree-causal attention mask)**를 적용하면, DFlash처럼 모든 노드를 한 번의 포워드 패스에 생성하면서도 EAGLE처럼 각 분기가 자신의 조상 토큰들에 조건부 분포를 유지할 수 있습니다.
기존 블록-확산 방식의 실패 원인은 "분기-불가지론적(branch-agnostic)" 주변 분포를 독립적으로 합성하는 데 있었습니다. 예를 들어 깊이 1에서 "given"이 높은 확률이고 깊이 2에서 "told"가 높은 확률이어도, 실제로 "given told"라는 연속은 영어 문법상 거의 나타나지 않는 조합입니다. 목표 모델은 이를 거부합니다. 반면 JetSpec의 인과 헤드는 "given"을 선택했다는 사실을 아는 상태에서 다음 위치를 예측하므로, 실제로 목표 모델의 자기회귀 팩터라이제이션과 일치하는 분포를 냅니다.
어떻게 작동하나
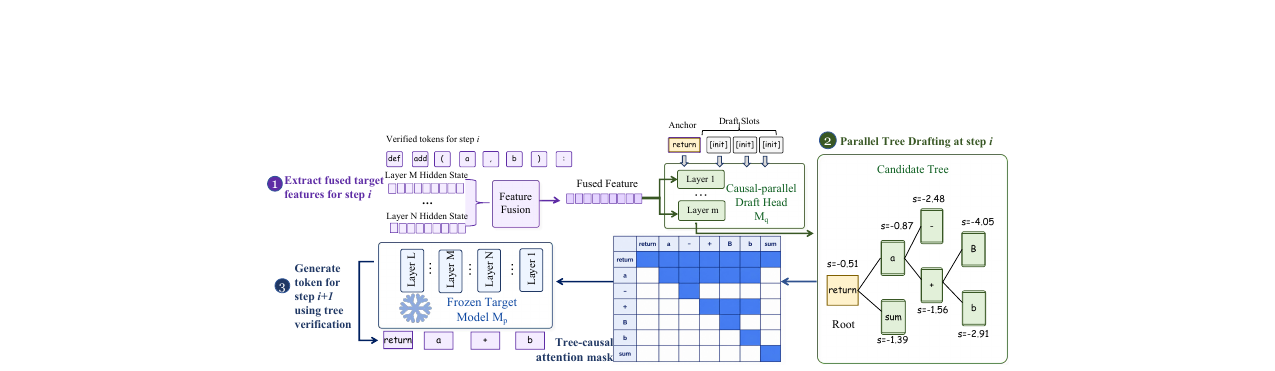
아키텍처. JetSpec은 헤드 기반(head-based) 아키텍처입니다. 드래프트 헤드는 동결된 타겟 모델 \(M_p\)의 중간 히든 스테이트를 퓨전(feature fusion)해서 재사용합니다. Qwen3-8B 기준으로 36개 레이어 중 레이어 1, 9, 17, 25, 33의 히든 스테이트를 추출해 채널 차원으로 결합한 뒤, 바이어스 없는 선형 레이어와 RMSNorm을 통해 \(d=4096\)으로 투영합니다. 드래프트 헤드 자체는 5레이어, 32개 어텐션 헤드, 8 KV 헤드, 헤드 차원 128인 경량 Qwen3 스타일 디코더입니다.
핵심은 이 헤드에 적용되는 트리-인과 어텐션 마스크입니다. 후보 트리의 각 노드 \(v\)에 대해, 마스크는 다음 규칙을 따릅니다.
\[M_{v,u} = \begin{cases} 0, & \text{if } u \in \text{Anc}(v) \cup \{v\}, \\ -\infty, & \text{otherwise} \end{cases}\]
즉, 노드 \(v\)는 자신의 조상 노드들과 자신만 볼 수 있고, 형제 분기나 자식 노드는 볼 수 없습니다. 이 마스크가 유도하는 분기별 팩터라이제이션은 다음과 같습니다.
\[q(\pi(v) \mid x) = \prod_{u \in \pi(v)} q(y_u \mid x, h_x^o, \pi_{<u})\]
이는 타겟 모델의 자기회귀 팩터라이제이션과 정확히 같은 구조입니다.
\[p(y_{1:k} \mid x) = \prod_{i=1}^{k} p(y_i \mid x, y_{<i})\]
이 일치 덕분에 드래프트 분포가 타겟 분포에 더 가깝게 유지되고, 기존 투기적 디코딩의 수락 규칙(rejection sampling)이 더 많은 토큰을 통과시킵니다.
훈련. 드래프트 헤드는 Forward KL 증류 목적함수로 학습됩니다. 초안 위치 \(m\)마다:
\[\mathcal{L}_{\text{FKL}}^{(m)} = D_{\text{KL}}\!\left(\tilde{p}^{(m)} \,\|\, \tilde{q}^{(m)}\right)\]
여기서 \(\tilde{p}^{(m)} = \text{softmax}(z_p^{(m)} / T_{\text{KD}})\), \(\tilde{q}^{(m)} = \text{softmax}(z_q^{(m)} / T_{\text{KD}})\)입니다. Forward KL은 타겟 모델의 확률 질량 전반을 커버하게 유도해, 여러 유효한 계속(continuation)을 보존합니다. Reverse KL은 반대로 모드 탐색적으로 동작해 고확률 토큰에만 확률을 집중시키는데, 실험에서는 Forward KL 대비 36-46% 성능 하락을 보였습니다. 전체 훈련 목적함수는 위치별 가중치 \(w_m\)을 적용해 정규화합니다.
\[\mathcal{L}_{\text{train}} = T_{\text{KD}}^2 \frac{\sum_m w_m \mathcal{L}_{\text{FKL}}^{(m)}}{\sum_m w_m}\]
학습 데이터는 타겟 모델이 재생성한 시퀀스를 사용하는 것이 가장 좋습니다. Nemotron Post-Training Dataset V2에서 780K 예제를 샘플링해 타겟 모델로 계속 생성한 뒤 학습 레이블로 활용했으며, 학습률 \(3 \times 10^{-4}\), 8개 H100 GPU에서 훈련했습니다.
추론. 테스트 시에는 두 단계로 동작합니다.
먼저 **병렬 트리 드래프팅(Parallel Tree Drafting)**에서, 드래프트 헤드가 한 번의 포워드 패스로 모든 트리 노드의 로짓을 계산합니다. 트리 구성은 Best-First 힙을 사용한 누적 로그 확률 점수로 진행됩니다.
\[s(\pi(v)) = \sum_{u \in \pi(v)} \log q(y_u \mid x, h_x^o, \pi_{<u})\]
가장 높은 점수의 노드를 팝하고, 최대 너비 \(W\)개의 자식을 추가하는 과정을 노드 예산 \(B\)가 소진될 때까지 반복해 후보 트리 \(\mathcal{T}(x)\)를 완성합니다.
그다음 **트리 검증(Tree Verification)**에서, 타겟 모델 \(M_p\)가 트리 어텐션으로 모든 노드를 한 번에 병렬 검증합니다. 각 토큰의 수락은 다음 확률로 결정됩니다.
\[\alpha_t = \min\!\left(1, \frac{p(y_t \mid x, y_{<t})}{q(y_t \mid x, y_{<t})}\right)\]
결과
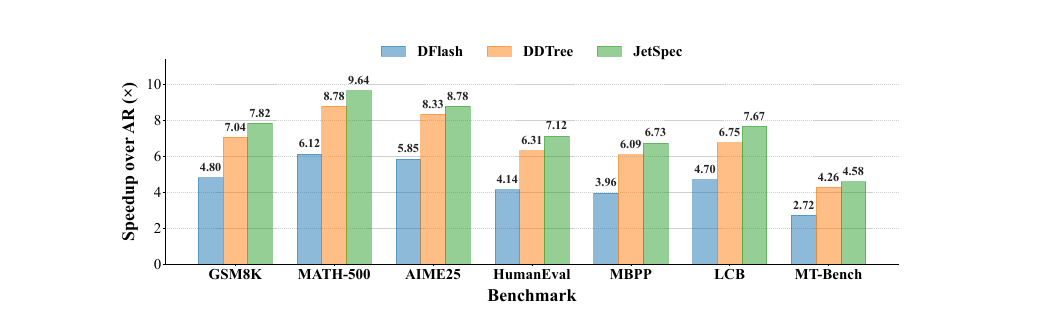
Qwen3-8B를 타겟 모델로, 드래프트 예산 256토큰에서 DFlash(블록 확산), DDTree(DFlash의 트리 변형), JetSpec을 비교했습니다. 온도 \(T=0\), H100 GPU 기준입니다.
벤치마크별 속도 향상 (예산 256, 온도 0)
벤치마크 |
DFlash |
DDTree |
JetSpec |
|---|---|---|---|
GSM8K |
4.80 |
7.04 |
7.82 |
MATH-500 |
6.12 |
8.78 |
9.64 |
AIME25 |
5.85 |
8.33 |
8.78 |
HumanEval |
4.14 |
6.31 |
7.12 |
MBPP |
3.96 |
6.09 |
6.73 |
LCB |
4.70 |
6.75 |
7.67 |
MT-Bench |
2.72 |
4.26 |
4.58 |
단위: 표준 AR 디코딩 대비 배수 (\(\times\)).
JetSpec은 수학(MATH-500 9.64배)과 코딩(HumanEval 7.12배) 전 영역에서 DDTree를 앞섭니다. DFlash 대비 격차가 두드러지는 이유는 인과 조건화로 수락률이 높아진 덕분이고, DDTree보다도 앞서는 이유는 DDTree가 DFlash의 확산 헤드를 그대로 쓰면서 트리만 Best-First로 구성하기 때문입니다. 인과 드래프팅이 트리 구성 방식보다 더 근본적인 개선이라는 점을 보여줍니다.
예산 규모별 양상. 저예산(16, 32토큰) 영역에서는 DFlash와 JetSpec이 거의 동등합니다. 짧은 선형 드래프트에서는 블록 확산도 충분히 일관된 후보를 냅니다. 예산이 커질수록(64→256) JetSpec이 점점 벌어집니다. 예산 확장 시 누적되는 분기-불일치 문제가 DFlash에서는 누적되고 JetSpec에서는 구조적으로 차단되기 때문입니다.
MoE 모델 일반화. Qwen3-30B-A3B(MoE 아키텍처) 타겟 모델에서도 JetSpec은 DDTree를 전 벤치마크에서 앞섭니다. 예산 256, MATH-500 기준 JetSpec 9.45배 대 DDTree 8.61배입니다. 인과 트리 드래프팅이 특정 아키텍처에 의존하지 않음을 확인합니다.
vLLM 서빙 성능. JetSpec을 vLLM에 통합해 H100 단일 GPU에서 측정한 서빙 처리량(TPS, 초당 토큰 수)입니다.
배치 크기 |
AR |
JetSpec(16) |
JetSpec(32) |
JetSpec(64) |
JetSpec(128) |
|---|---|---|---|---|---|
1 |
127.8 |
224.0 (1.75\(\times\)) |
312.0 (2.44\(\times\)) |
447.3 (3.50\(\times\)) |
553.3 (4.33\(\times\)) |
4 |
203.8 |
433.6 (2.13\(\times\)) |
534.2 (2.62\(\times\)) |
664.2 (3.26\(\times\)) |
742.9 (3.64\(\times\)) |
8 |
246.2 |
679.3 (2.76\(\times\)) |
839.3 (3.41\(\times\)) |
859.3 (3.49\(\times\)) |
803.5 (3.26\(\times\)) |
16 |
287.3 |
891.8 (3.10\(\times\)) |
1094.6 (3.81\(\times\)) |
995.8 (3.47\(\times\)) |
803.1 (2.80\(\times\)) |
HumanEval 기준, Math-500 프로토콜로 평가. 저배치(1~4)에서 큰 예산이 유리하고, 고배치(16)에서는 중간 예산(32)이 최적입니다. 배치가 클수록 GPU가 이미 포화 상태여서 큰 드래프트 트리의 추가 이득이 줄어들기 때문입니다.
Ablation: 인과 헤드 vs 확산 헤드. 인과 헤드와 확산 헤드를 동일 조건(\(3 \times 10^{-4}\), Forward-KL, MATH-500)에서 비교한 핵심 결과입니다.
헤드 |
\(\gamma=0\) 속도 |
\(\gamma=0\) \(\tau\) |
\(\gamma=7\) 속도 |
\(\gamma=7\) \(\tau\) |
|---|---|---|---|---|
Causal |
8.29 |
9.81 |
8.40 |
9.99 |
Diffusion |
5.46 |
6.45 |
8.36 |
9.72 |
\(\gamma\)는 DFlash 스타일 지수 깊이 가중치 파라미터입니다. \(\gamma=0\)(균일 가중치)에서 인과 헤드는 8.29배이지만 확산 헤드는 5.46배에 그칩니다. \(\gamma=7\)로 확산 헤드를 조정하면 8.36배로 따라오지만, 이는 손실 가중치 튜닝이 선행돼야 하는 조건입니다.
Appendix A 분석에 따르면, MATH-500 50개 프롬프트에서 확산 헤드의 rank-1 분기가 목표 조건부 확률과 벌어진 양(gap)이 인과 헤드보다 중앙값 기준 5배 큽니다(+62.81 vs +12.36 nats). 인과 헤드는 \(\gamma\) 조정 없이도 rank-1 분기가 지속적으로 faithful한 반면, 확산 헤드는 \(\gamma=0\)일 때 26%의 프롬프트에서 rank-1 gap이 +80 nats 이상인 극단적 실패를 보입니다.
회고
저자들이 명시한 한계와 논문에서 확인할 수 있는 숨겨진 전제가 있습니다.
서빙 예산 스케줄링. 이 논문은 정적 예산 정책(static budget policy)만 평가했습니다. 실제 서빙 환경에서는 배치 크기에 따라 최적 예산이 달라지므로(저배치 256, 고배치 32), 동적으로 예산을 조정하는 메커니즘이 추가로 필요합니다. 저자들은 이를 명시적으로 미래 과제로 남겼습니다.
데이터 비용. 최고 성능을 내려면 타겟 모델이 재생성한 시퀀스로 학습해야 합니다. 원본 코퍼스로 직접 학습한 JetSpec-Corpus는 예산 256에서 MATH-500 3.66배로, 완전 재생성 JetSpec(8.78배)에 크게 못 미칩니다. 재생성 비용이 크거나 불가능한 상황(예: 지속적 사전훈련 단계)에서는 타협이 필요합니다.
대화형 태스크의 작은 이득. MT-Bench(개방형 대화) 에서 JetSpec은 4.58배로 수학(9.64배)의 절반 수준입니다. 대화형 응답은 수락률이 수학 추론보다 낮고, 예산 확장 효과도 제한적입니다.
드래프팅 비용의 실측값. Appendix G는 H200 NVL GPU에서 맥락 길이 \(L=1024\), 드래프트 깊이 \(N=256\) 조건의 토큰당 드래프팅 비용 \(c\)를 0.054%로 측정했습니다. 이는 Figure 2의 "Ultra low-cost SD(\(c=0.0005\))" 패널에 해당하는 영역으로, 이 조건에서 스케일링 곡선이 가장 가파르게 올라갑니다. 하지만 \(L=4096\)에서는 \(c=0.073\%\)로 오르는 등 맥락 길이가 길어질수록 비용이 서서히 증가합니다.
정리
- 투기적 디코딩에서 드래프트 예산을 늘려도 속도가 잘 오르지 않는 원인은 기존 방법이 인과성(수락률)과 효율(드래프팅 비용) 중 하나를 포기했기 때문입니다.
- JetSpec은 트리-인과 어텐션 마스크로 한 번의 포워드 패스에 모든 트리 노드를 생성하면서도 각 분기가 자신의 조상 토큰에 조건부인 분포를 유지합니다.
- Qwen3-8B 기준 MATH-500 9.64배, Qwen3-30B-A3B 기준 9.45배 가속을 달성했으며, vLLM에 통합해 저배치 서빙 시나리오에서 AR 대비 3-4배 처리량을 확인했습니다.