Representation Alignment for Just Image Transformers is not Easier than You Think
REPA(Representation Alignment)는 디퓨전 트랜스포머 훈련을 가속하는 단순하고 효과적인 방법으로 자리 잡았습니다. DINOv2 같은 사전학습된 시맨틱 인코더의 특징과 디퓨전 모델의 중간 활성화를 정렬하면 수렴이 빨라지고 최종 품질도 올라갑니다. DiT, SiT 같은 잠재 공간(latent space) 디퓨전에서요.
근데 픽셀 공간(pixel space) 디퓨전에서는? 이 논문은 REPA를 JiT(Just image Transformers)에 그대로 적용하면 오히려 성능이 나빠진다는 걸 보여줍니다. 훈련이 진행될수록 FID가 올라가고, 시맨틱 인코더의 특징 공간에서 밀집된 이미지 하위 집합에서 다양성이 붕괴합니다. 원인을 추적하고, 이를 해결하는 PixelREPA를 제안합니다.
KAIST AI의 연구이고, 코드도 공개되었습니다.
Shin, Jaeyo; Kim, Jiwook; Shim, Hyunjung, "Representation Alignment for Just Image Transformers is not Easier than You Think", arXiv preprint, arXiv:2603.14366, Mar. 2026.
링크 : https://arxiv.org/abs/2603.14366
요약
기술 스펙
모델 - 아키텍처: JiT(Just image Transformers) 기반, B/16, L/16, H/16 - 정렬 모듈: Masked Transformer Adapter (MTA) — 2블록 트랜스포머 어댑터 + 부분 토큰 마스킹 - 외부 인코더: DINOv2 (frozen) - 추론 시 추가 비용: 없음 (MTA는 훈련 시에만 사용)
성능 (ImageNet 256×256, 50K 샘플) - PixelREPA-B/16: FID 3.17 (JiT-B/16: 3.66, JiT+REPA: 5.14) - PixelREPA-L/16: FID 2.11 (JiT-L/16: 2.36) - PixelREPA-H/16: FID 1.81, IS 317.2 (JiT-H/16: 1.86, JiT-G/16: 1.82) - 수렴 속도: JiT 대비 2배 이상 빠름
핵심 발견
- REPA는 픽셀 공간에서 실패한다: 훈련이 진행될수록 JiT+REPA의 FID가 vanilla JiT보다 나빠짐
- 원인은 정보 비대칭: 픽셀 공간은 \(O(H \times W)\) 자유도를 가지지만 시맨틱 인코더는 강하게 압축된 표현 → 직접 정렬이 shortcut objective가 됨
- Feature hacking: 시맨틱 특징 공간에서 밀집된 이미지들의 생성 다양성이 붕괴
- PixelREPA: 정렬 대상을 변환하고, MTA로 정렬 경로를 제약하여 문제 해결
논문 상세
배경: 왜 픽셀 공간 디퓨전인가
잠재 디퓨전 모델(LDM)은 사전학습된 이미지 토크나이저를 통해 압축된 잠재 공간에서 디노이징합니다. 효율적이지만 근본적 한계가 있죠. 토크나이저의 재구성 품질이 생성 품질의 상한선이 됩니다. 강한 압축은 미세한 텍스처와 작은 구조를 제거합니다.
JiT는 이 의존성을 제거합니다. 순수 ViT(Vision Transformer)로 원본 이미지에서 직접 디노이징합니다. 외부 토크나이저도, 적대적 손실도, 지각적 손실도 없이. 재구성 병목이 없으니 원칙적으로 임의의 고주파 디테일을 표현할 수 있습니다.
문제는 훈련 비용입니다. 잠재 공간보다 차원이 훨씬 높으니까요. REPA가 잠재 디퓨전 훈련을 극적으로 가속했으니, JiT에도 적용하는 건 자연스러운 다음 단계였습니다.
REPA가 실패하는 이유
REPA의 원리는 간단합니다. 디퓨전 모델의 중간 특징을 MLP로 투영하고, DINOv2 같은 외부 시맨틱 인코더의 특징과 코사인 유사도로 정렬합니다. 잠재 디퓨전에서는 잘 작동합니다.
근데 JiT에 적용하면 Fig. 1에서 보듯, 훈련 초기에는 약간 도움이 되지만 훈련이 진행될수록 vanilla JiT보다 FID가 높아집니다. 200 에포크에서 JiT+REPA의 FID는 5.14로, vanilla JiT의 4.37보다 17.6% 나쁩니다.
저자들은 원인을 **정보 비대칭(information asymmetry)**으로 추적합니다.
잠재 디퓨전에서는 토크나이저가 이미지를 이미 압축합니다. 시맨틱 인코더도 압축된 표현을 만들죠. 두 공간 모두 정보 병목을 통과한 상태라 자유도가 대략 일치합니다. 그래서 직접 정렬이 효과적입니다.
픽셀 공간에서는 디노이징이 원본 이미지 공간에서 일어납니다. \(O(H \times W)\)의 자유도를 가지죠. 반면 시맨틱 인코더는 여전히 압축된 표현을 만듭니다. 픽셀 공간에서 서로 다른 많은 이미지가 특징 공간의 비슷한 영역에 매핑되고, 이 모호성은 해상도가 올라갈수록 커집니다.
디퓨전 모델이 이 압축된 타겟에 회귀하도록 강제하면? Feature hacking이 발생합니다. 모델이 외부 특징 공간의 좁은 영역에 과적합하고, 시맨틱 특징이 유사한 이미지들의 생성 다양성을 잃습니다.
Feature Hacking의 증거
저자들은 이걸 두 가지 실험으로 증명합니다.
해상도별 비교: 32×32에서는 REPA가 JiT를 개선합니다. 256×256에서는 오히려 악화시킵니다. 픽셀-특징 간 갭이 작을 때는 괜찮지만, 커지면 문제가 된다는 뜻입니다.
밀집도별 비교: 각 ImageNet 클래스에서 시맨틱 특징 공간의 중심(centroid)에 가장 가까운 100개 샘플("Most Similar 100")과 가장 먼 100개 샘플("Least Similar 100")을 나눕니다. Most Similar 100은 픽셀 공간에서는 다양하지만 특징 공간에서 밀집된 이미지들이고, Least Similar 100은 특징 공간에서도 분산된 이미지들입니다.
결과: vanilla JiT는 Most Similar 100에서 JiT+REPA보다 FID가 낮고, Least Similar 100에서는 반대입니다. 정확히 feature hacking의 시그니처죠. 특징 공간이 모호한 곳에서만 악화되고, 잘 분리된 곳에서는 REPA가 도움이 됩니다.
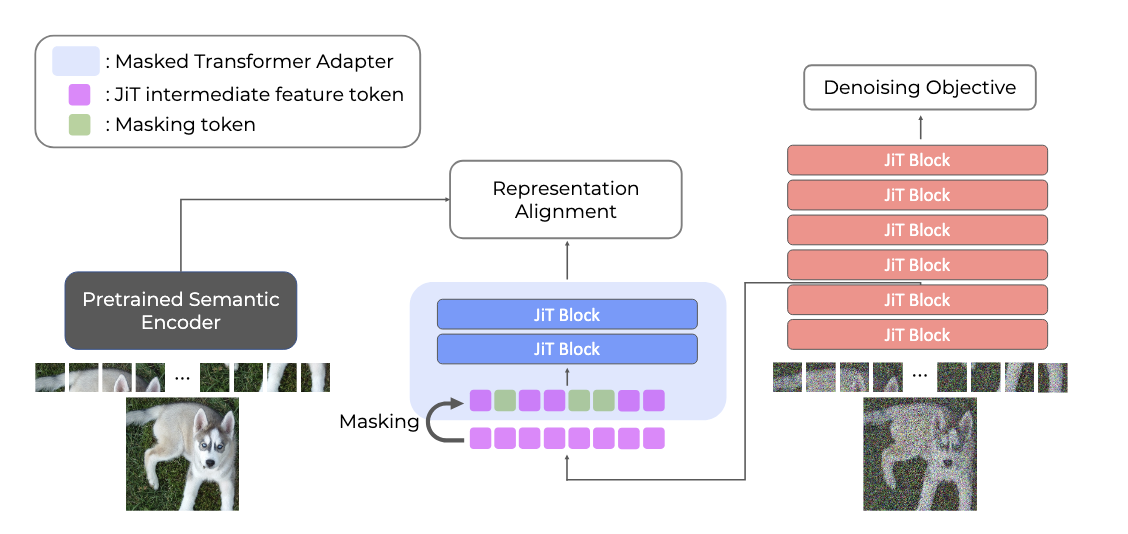
PixelREPA: Masked Transformer Adapter
문제의 핵심은 정렬 대상(alignment target)입니다. 기존 REPA는 MLP로 JiT 특징을 시맨틱 인코더 공간에 투영합니다. 이건 본질적으로 풍부한 픽셀 표현을 압축된 시맨틱 타겟에 맞추라는 요구입니다.
PixelREPA는 방향을 바꿉니다. JiT 표현이 시맨틱 타겟을 직접 학습하는 대신, 전용 모듈을 통해 시맨틱 타겟을 변환하고, 이 변환된 공간에서 정렬합니다. 이 모듈이 Masked Transformer Adapter(MTA)입니다.
구성요소 1: Shallow Transformer Adapter
2블록짜리 트랜스포머 어댑터입니다. MLP 대신 셀프 어텐션이 있으므로 각 토큰이 이웃 토큰의 정보를 활용할 수 있습니다. 핵심은 정렬 목적함수가 JiT 중간 표현 자체를 압축된 타겟에 맞추도록 압박하지 않는다는 것. 어댑터가 JiT 표현에서 시맨틱 정보를 선택적으로 추출해서 인코더 공간에 투영합니다. JiT 표현은 픽셀 수준의 풍부한 정보를 자유롭게 유지할 수 있죠.
구성요소 2: Partial Masking
근데 어댑터만으로는 부족합니다. 마스킹 없는 어댑터(mask ratio 0.0)의 200 에포크 FID는 4.68로, JiT+REPA(5.14)보다는 낫지만 vanilla JiT(4.37)에는 못 미칩니다. 어댑터가 여전히 토큰별 trivial mapping을 학습할 수 있기 때문입니다.
부분 마스킹이 이걸 해결합니다. 어댑터 입력 토큰의 일부(비율 \(r\))를 랜덤으로 마스킹합니다. 두 가지 역할을 합니다:
- Shortcut 방지: 토큰 일부가 없으니 토큰별 직접 대응이 깨지고, 문맥적 추론이 필요해집니다
- 정보 병목: 어댑터 입력의 유효 자유도를 \(O((1-r) \cdot N \cdot d)\)로 줄여서 픽셀 표현과 시맨틱 타겟 사이의 정보 격차를 좁힘. 잠재 디퓨전에서 토크나이저가 하는 역할과 유사하지만, 디노이징 경로가 아닌 정렬 경로에만 적용
중요한 건, MTA는 정렬 브랜치에만 적용됩니다. 메인 디노이징 경로는 마스킹 없이 전체 토큰을 유지합니다. 그리고 추론 시에는 MTA를 사용하지 않으므로 추가 비용이 없습니다.
실험 결과
ImageNet 256×256에서 PixelREPA는 모든 모델 스케일에서 JiT를 일관되게 앞섭니다.
- B/16: FID 3.66 → 3.17 (13.4% 개선)
- L/16: FID 2.36 → 2.11 (10.6% 개선)
- H/16: FID 1.86 → 1.81 (2.7% 개선), IS 303.4 → 317.2
PixelREPA-H/16(953M)이 JiT-G/16(2B)을 앞선다는 점이 주목할 만합니다. 거의 2배 큰 모델을 이겼으니, 파라미터 효율이 좋다는 뜻입니다.
수렴 속도도 개선됩니다. vanilla JiT 대비 2배 이상 빠른 수렴을 보입니다.
마스킹 비율 ablation에서는 \(r = 0.2\)가 최적이었고, \(r = 0.5\) 이상에서는 과도한 정보 병목으로 성능이 하락합니다.
Most Similar / Least Similar 분석에서 PixelREPA는 두 조건 모두에서 최고 FID를 달성합니다. Feature hacking이 발생하던 밀집 영역에서도 잘 작동한다는 뜻이죠.
생각
문제 분석이 체계적입니다. "REPA가 픽셀 공간에서 안 되네" → "왜?" → 해상도별 비교, 밀집도별 비교로 원인 특정 → 정보 비대칭 가설 → 해결책 설계. 이 흐름이 깔끔합니다.
Feature hacking이라는 실패 모드를 명확히 정의하고 증거를 보인 게 이 논문의 가장 큰 기여입니다. REPA를 픽셀 디퓨전에 적용하면 "전체적으로" 나빠지는 게 아니라, 특징 공간에서 밀집된 이미지에서만 선택적으로 나빠진다는 발견은 후속 연구에 중요한 참고가 될 것 같습니다.
MTA 설계도 합리적입니다. 어댑터만으로는 shortcut을 완전히 방지하지 못한다는 걸 실험으로 보이고(FID 4.68 vs 4.37), 마스킹을 추가해서 해결하는 과정이 논리적입니다. 추론 비용이 추가되지 않는 것도 실용적이고요.
이 연구의 가치는 "REPA가 보편적으로 좋다"는 가정에 의문을 제기한 데 있습니다. 잠재 공간에서 잘 작동하는 기법이 픽셀 공간에서는 실패할 수 있고, 그 원인이 두 공간의 정보 구조 차이에 있다는 분석은 디퓨전 모델 훈련 방법론 전반에 시사점을 줍니다.
픽셀 공간 디퓨전이 최근 다시 주목받고 있는 흐름(JiT, SiD2, PixelFlow 등)에서, 기존 잠재 디퓨전의 기법을 그대로 가져올 수 없다는 건 중요한 경고입니다. PixelREPA가 보여준 "정렬 대상의 변환 + 정렬 경로의 제약"이라는 패턴은 다른 정규화 기법을 픽셀 공간에 적용할 때도 참고할 만한 설계 원칙이 될 것 같네요.