RAG-Anything - All-in-One RAG Framework
Z. Guo, X. Ren, L. Xu, J. Zhang, and C. Huang, "RAG-Anything: All-in-One RAG Framework," arXiv:2510.12323, 2025.
실제 업무에서 쓰는 문서에는 텍스트만 있지 않습니다. 논문에는 그래프와 수식, 재무 보고서에는 표와 차트, 기술 슬라이드에는 다이어그램이 뒤섞입니다. 지금까지의 RAG 시스템은 이것들을 텍스트로 변환하거나, 아예 무시하거나, 둘 중 하나였습니다. RAG-Anything은 그 gap을 정면으로 건드립니다.
저자
궈즈루이는 홍콩대학교 HKUDS Lab의 박사과정 연구자이자 1저자입니다. 2024년 같은 랩에서 LightRAG를 발표해 RAG 생태계에 그래프 기반 듀얼 레벨 검색을 도입한 인물입니다. RAG-Anything은 LightRAG의 멀티모달 확장판이며, 같은 아키텍처 철학을 비텍스트 모달리티까지 밀어붙인 결과물입니다.
교신저자 황차오은 HKUDS Lab의 수장으로, LightRAG(36,000+ GitHub 스타)를 비롯한 일련의 RAG 프레임워크를 오픈소스로 공개해온 것으로 알려져 있습니다. 연구 발표 속도와 구현 완성도로 2025년 기준 GitHub Trending에 59회 이상 오른 랩을 이끌고 있습니다.
배경
RAG가 빠르게 실용 AI의 기본 패러다임으로 자리잡으면서 한 가지 근본적인 미스매치가 드러났습니다. 현실의 지식 저장소는 텍스트만으로 이루어지지 않는다는 것입니다. 학술 논문의 핵심 발견은 시각화 그래프 안에 있고, 재무 보고서의 핵심 수치는 표 셀 교차점에 있으며, 의학 문헌의 진단 근거는 영상 이미지 안에 있습니다. 기존 RAG 시스템은 이런 콘텐츠를 텍스트로 변환하는 과정에서 필연적으로 정보를 잃거나, 변환 자체를 포기하고 무시합니다.
세 가지 기술적 과제가 멀티모달 RAG를 어렵게 만듭니다. 첫째는 이질적인 데이터 타입을 하나의 표현으로 통합하는 문제, 둘째는 복잡한 문서 레이아웃의 공간적·계층적 관계를 파악하는 문제, 셋째는 서로 다른 모달리티를 가로질러 관련 정보를 검색하는 크로스 모달 검색 문제입니다. 이 셋을 동시에 해결하는 단일 프레임워크가 없었습니다.
기존 접근들은 각자 한쪽만 풀었습니다. VisRAG는 문서 레이아웃을 이미지로 보존하지만 세밀한 관계는 놓칩니다. MMGraphRAG는 이미지를 그래프로 처리하지만 표와 수식은 여전히 평문 텍스트로 취급합니다. 그 결과 표 헤더-셀-단위 관계나 수식 내 변수 연결이 사라집니다.
어떻게 만들었나
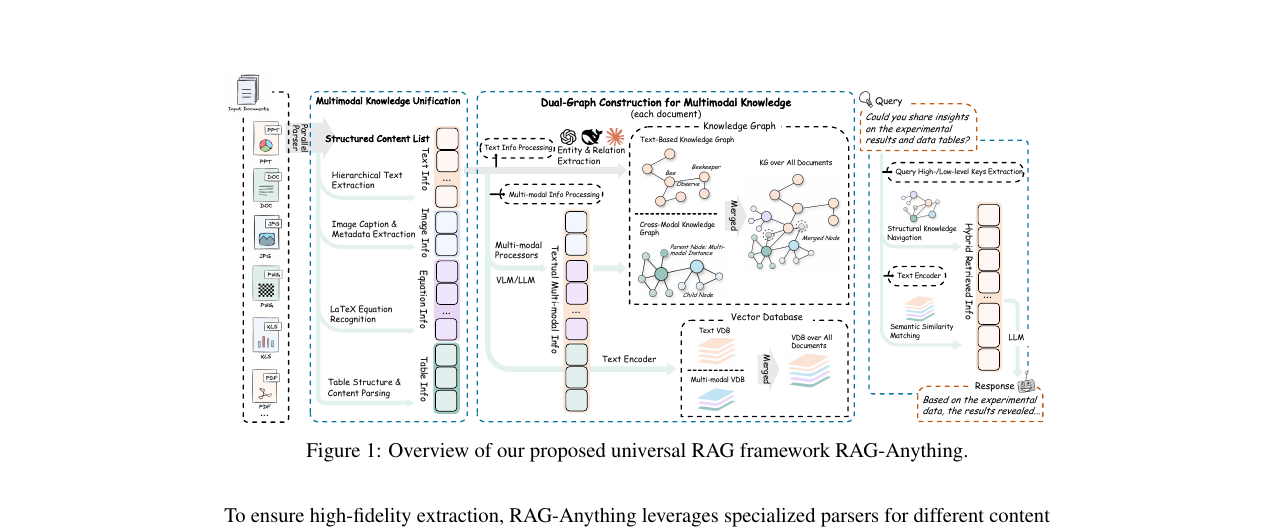
1단계: Multimodal Knowledge Unification
파이프라인의 첫 단계는 문서에서 원자적 콘텐츠 단위를 추출하는 것입니다. RAG-Anything은 MinerU를 사용해 문서에서 텍스트, 이미지, 표, 수식을 각각 파싱합니다. 각 단위 \(c_j\)는 모달리티 타입 \(t_j \in \{\text{text}, \text{image}, \text{table}, \text{equation}, \ldots\}\)와 원본 콘텐츠 \(x_j\)로 구성됩니다.
중요한 것은 추출 과정이 문맥을 유지한다는 점입니다. 논문 안의 그림은 해당 캡션과 연결된 채로, 수식은 주변의 정의 문장과 연결된 채로 남습니다. 이 구조를 잃으면 이후 그래프 구축의 의미가 없어집니다.
2단계: Dual-Graph Construction
핵심 기여는 두 개의 보완적 지식 그래프를 구축하는 것입니다.
Cross-Modal Knowledge Graph는 비텍스트 콘텐츠를 위한 그래프입니다. 이미지, 표, 수식 등 각 비텍스트 단위 \(c_j\)에 대해 VLM/LLM을 사용해 두 가지 텍스트 표현을 생성합니다. 검색에 최적화된 상세 설명 \(d_j^{\text{chunk}}\)와, 엔티티 이름·타입·설명을 담은 엔티티 요약 \(e_j^{\text{entity}}\)입니다. 그 다음 설명으로부터 엔티티와 관계를 추출해 그래프를 구성합니다. 각 비텍스트 단위는 멀티모달 앵커 노드 \(v_j^{\text{mm}}\)이 되고, 그 안에서 추출된 엔티티들은 belongs_to 엣지로 앵커에 연결됩니다.
Text-based Knowledge Graph는 텍스트 청크를 LightRAG 방식으로 처리한 그래프입니다. Named Entity Recognition과 관계 추출로 엔티티와 의미 관계를 뽑습니다. 비텍스트 콘텐츠에 대한 멀티모달 컨텍스트 통합은 필요 없습니다.
두 그래프는 **엔티티 정렬(entity alignment)**로 병합됩니다. 엔티티 이름을 기본 매칭 키로 사용해 두 그래프에서 의미상 동일한 엔티티를 찾아 통합하면, 멀티모달 관계와 텍스트 의미 관계를 모두 아우르는 단일 지식 그래프 \(G = (V, E)\)가 완성됩니다.
Dense 표현도 함께 생성합니다. 그래프 엔티티, 관계, 콘텐츠 청크 전부를 text-embedding-3-large 모델로 임베딩해 벡터 데이터베이스 \(T\)를 구축합니다. 검색 인덱스는 \(I = (G, T)\), 즉 그래프와 벡터 공간의 조합입니다.
3단계: Cross-Modal Hybrid Retrieval
검색도 두 경로를 병렬로 사용합니다.
Structural Knowledge Navigation은 그래프를 활용합니다. 쿼리에서 키워드와 엔티티를 인식해 그래프 매칭을 수행하고, 인접 엔티티와 관계를 지정 hop 거리까지 확장합니다. 명시적 관계와 멀티 홉 추론 패턴을 포착하는 데 효과적입니다. 쿼리에 "figure", "table", "equation" 같은 단어가 있으면 해당 모달리티에 가중치를 줍니다.
Semantic Similarity Matching은 벡터를 활용합니다. 쿼리 임베딩과 \(T\) 안의 모든 컴포넌트 사이의 코사인 유사도를 계산해 top-k를 반환합니다. 그래프 경로로는 연결되지 않지만 의미상 관련된 콘텐츠를 잡습니다.
두 경로의 결과는 멀티 시그널 퓨전 스코어링으로 통합됩니다. 그래프 구조적 중요도, 시맨틱 유사도, 쿼리 모달리티 선호가 동시에 반영됩니다.
4단계: 생성
검색된 멀티모달 정보를 VLM에 넣어 답변을 생성합니다. 텍스트 컨텍스트(엔티티 요약, 관계 설명, 청크 내용)와 원본 시각 콘텐츠를 함께 조건으로 사용합니다. 텍스트 프록시로 검색 효율을 확보하면서, 최종 생성 시에는 원본 이미지의 시각 의미를 활용합니다.
결과
실험은 두 멀티모달 문서 QA 벤치마크에서 진행됐습니다. DocBench는 229개 문서, 평균 66페이지, 1,102개 질문으로 구성된 장문서 중심 벤치마크입니다. MMLongBench는 135개 문서, 7개 문서 유형, 1,082개 질문으로 구성됩니다.
방법 |
전체 (DocBench) |
전체 (MMLongBench) |
|---|---|---|
GPT-4o-mini |
51.2 |
33.5 |
LightRAG |
58.4 |
38.9 |
MMGraphRAG |
61.0 |
37.7 |
RAG-Anything |
63.4 |
42.8 |
DocBench 세부 도메인 결과입니다.
방법 |
학술(Aca.) |
금융(Fin.) |
정부(Gov.) |
법률(Law.) |
뉴스(News) |
텍스트전용 |
멀티모달 |
전체 |
|---|---|---|---|---|---|---|---|---|
GPT-4o-mini |
40.3 |
46.9 |
60.3 |
59.2 |
61.0 |
61.0 |
43.8 |
51.2 |
LightRAG |
53.8 |
56.2 |
59.5 |
61.8 |
65.7 |
85.0 |
59.7 |
58.4 |
MMGraphRAG |
64.3 |
52.8 |
64.9 |
40.0 |
61.5 |
67.6 |
66.0 |
61.0 |
RAG-Anything |
61.4 |
67.0 |
61.5 |
60.2 |
66.3 |
85.0 |
76.3 |
63.4 |
멀티모달 문서 타입에서 RAG-Anything은 76.3%로 가장 낮은 방법(GPT-4o-mini 43.8%)과 32.5포인트 차이입니다. 텍스트 전용 문서에서는 LightRAG와 동률이지만, 실제 복합 문서에서의 차이가 두드러집니다.
문서 길이에 따른 효과도 뚜렷합니다. DocBench에서 101~200페이지 구간의 정확도는 RAG-Anything 68.2%, MMGraphRAG 54.6%로 13포인트 이상 차이납니다. 200페이지 초과에서는 68.8% vs 55.0%입니다. MMLongBench에서도 51~100페이지 구간에서 9.3포인트 앞섰습니다.
Ablation study에서 그래프 구성 자체의 기여가 가장 큽니다. 그래프를 제거하고 전통적 청크 검색만 쓰면 전체 정확도가 63.4%에서 60.0%로 떨어집니다. Reranker 제거 시에는 62.4%로, 리랭커보다 그래프가 더 중요합니다.
회고
저자들이 Appendix A.5에서 솔직하게 공개한 실패 패턴 두 가지가 있습니다.
첫째는 **텍스트 편향 검색(text-centric retrieval bias)**입니다. 쿼리가 "Figure에 따르면"이라고 명시해도 시스템이 텍스트 소스를 우선 검색하는 경향이 있습니다. 이미지 콘텐츠에 정확한 키워드 매치가 없을 때 특히 심합니다. 이 실패 케이스에서는 모든 방법(RAG-Anything 포함)이 함께 틀렸습니다.
둘째는 비표준 레이아웃 처리 실패입니다. 표에 병합된 셀이 있거나, 그림이 아래에서 위로 읽어야 하는 방향으로 구성돼 있는 경우 적응하지 못합니다. 대부분의 시각 처리 모델이 위→아래, 왼→오른의 기본 스캔 패턴을 기본값으로 쓰기 때문입니다. 이 실패 케이스에서도 역시 모든 방법이 함께 틀렸습니다.
정리
- 기존 RAG는 비텍스트 콘텐츠를 평문으로 변환하거나 무시했습니다. RAG-Anything은 이미지·표·수식을 별도 그래프 노드로 두고, 텍스트 그래프와 병합해 크로스 모달 검색을 가능하게 합니다.
- 장문서에서 효과가 두드러집니다. 100페이지 이상 문서에서 기존 최강 방법 대비 13포인트 이상 앞섭니다.
- 아직 남은 과제는 명확합니다. 이미지를 명시적으로 찾으라고 해도 텍스트를 우선 검색하는 편향, 비정형 레이아웃에 대한 적응력 부족. 이 둘은 RAG-Anything도 해결하지 못한 근본 문제입니다.