MiniMax Sparse Attention
X. Lai, W. Xu, Y. Yang, Q. Chen, Y. Xu, L. Zeng, X. Li, H. Sun, H. Zhu, V. Zhang, J. Hu, J. Li, R. Gao, Z. Li, S. Zhu, J. Zhou, and P. Zhao, "MiniMax Sparse Attention," arXiv:2606.13392, 2026.
저자
17명의 저자 전원이 MiniMax 소속입니다. 이 논문은 학술 기관 연구가 아니라 MiniMax가 M3 모델에 탑재한 기술을 공개 문서화한 산업 기술 보고서입니다.
1저자 라이쉰하오는 베이징대 지능과학기술학원 석사과정에서 MiniMax와 협력 연구를 이어온 연구자입니다. 유연한 희소 어텐션을 다룬 FlexPrefill(ICLR 2025 Oral)을 공저했고, 그 문제의식이 이 논문으로 이어집니다. 시니어 저자 자오펑위는 MiniMax LLM 팀장으로 MiniMax-Text-01부터 M3까지 모든 LLM 시리즈를 총괄해왔습니다. 사전학습 리드 쑨하오하이이 109B MoE 전훈련 실험을 담당했습니다.
이 논문이 나온 직접적인 이유는 배포입니다. MiniMax M3는 이미 2026년 6월 1일 공개됐고, 논문은 그 시점과 맞물려 M3 핵심 기술의 이론적 근거를 학술적으로 제시합니다.
배경
프론티어 LLM이 1M 토큰급 컨텍스트를 요구하는 상황에서 소프트맥스 어텐션의 이차 비용은 배포 병목이 됩니다. 기존 대응책은 크게 두 가지입니다. 하나는 선형 어텐션이나 SSM으로 어텐션 자체를 대체하는 방식이고, 다른 하나는 슬라이딩 윈도우나 글로벌 토큰처럼 고정 패턴으로 어텐션 범위를 제한하는 방식입니다. 두 방법 모두 내용에 따라 어텐션 대상을 동적으로 골라내지는 못합니다.
MiniMax가 내놓은 MSA(MiniMax Sparse Attention)는 세 번째 방향입니다. 소프트맥스 어텐션을 유지하되, 경량 인덱서가 쿼리마다 "지금 정말 봐야 할 KV 블록"만 선별하고 나머지를 건너뜁니다. 이 아이디어 자체는 새롭지 않지만, MSA가 주목받는 이유는 단순성(Occam's razor를 명시적 설계 원칙으로 내세움)과 실제 배포 스케일 검증입니다. 109B 파라미터 MoE 모델을 3T 토큰 예산으로 전훈련하며 기존 GQA 풀 어텐션과 정면 비교했습니다.
어떻게 만들었나

MSA는 각 어텐션 레이어에 두 개의 브랜치를 답니다.
**인덱스 브랜치(Index Branch)**는 GQA 그룹마다 KV 블록 중 상위 \(k\)개를 고릅니다. 구조는 극히 단순합니다. GQA 그룹당 인덱스 쿼리 헤드 하나, 전 그룹이 공유하는 인덱스 키 헤드 하나입니다. 두 헤드로 블록별 점수를 내고 max-pooling으로 블록 단위 점수를 집계한 뒤 Top-\(k\)를 취합니다. 현재 쿼리가 속한 로컬 블록은 점수에 상관없이 항상 포함됩니다.
**메인 브랜치(Main Branch)**는 선택된 블록들에만 표준 소프트맥스 어텐션을 적용합니다. 전체 컨텍스트 길이 \(N\)에 대해 이차로 계산하는 대신, 선택 예산 \(kB_k\)에 대해서만 계산하므로 시퀀스 길이가 늘어나도 메인 브랜치 비용은 고정됩니다.
FLOPs를 수식으로 쓰면:
\[F_\text{MSA}(N) = H_{kv} d_\text{idx} N^2 + 4 H_q d_h N k B_k\]
앞 항이 인덱스 브랜치(여전히 이차이지만 헤드 수와 차원이 매우 작음), 뒤 항이 메인 브랜치(선형 스케일)입니다. 배포 설정(\(B_k=128\), \(k=16\))에서 선택 예산은 쿼리당 2,048 토큰으로 고정됩니다.
훈련은 두 가지 과제를 해결해야 합니다. 첫째, Top-\(k\) 선택은 미분 불가능합니다. MSA는 인덱스 브랜치를 KL 정렬 손실로 훈련합니다. 선택된 위치에서 인덱스 브랜치의 어텐션 분포가 메인 브랜치의 분포를 따르도록 유도하는 방식입니다:
\[\mathcal{L}_\text{KL} = \frac{1}{N H_{kv}} \sum_{i,r} D_\text{KL}\!\left(\text{stopgrad}(P^{(r)}_{i,\cdot}) \,\|\, P^{\text{idx},(r)}_{i,\cdot}\right)\]
둘째, 훈련 안정성을 위해 인덱스 브랜치 입력에 stopgrad를 걸어 KL 손실이 백본까지 역전파되지 않도록 막습니다. 초반에는 풀 어텐션으로 인덱서를 워밍업한 뒤 희소 어텐션으로 전환하는 2단계 스케줄도 씁니다.
GPU 커널 공동 설계
MSA가 "이론적 FLOPs 절감을 실제 속도로 변환"한다고 강조하는 이유는, 이 부분에 상당한 공학적 노력을 쏟았기 때문입니다.
Exp-free Top-k: 소프트맥스는 순서 보존 변환이므로, 블록 순위를 구하는 데 exp 계산이 필요 없습니다. 원시 점수를 바로 선택에 넘깁니다. 와프의 32개 레인이 각자 로컬 min-heap을 관리하고 마지막에 셔플 머지로 합치는 방식으로, torch.topk 대비 \(k=16\) 배포 설정에서 3.7~5.1배 빠릅니다.
KV-outer 반복 순서: 쿼리를 외부 루프로 돌리는 Q-outer 방식 대비 KV 블록을 외부 루프로 돌리는 KV-outer 방식이 산술 강도(FLOPs/IO)가 \(\frac{2}{3}B_k\) 대 \(G\)로 유리합니다. 실제로 \(B_k=128\), GQA 비율 \(G=16\)이면 \(\frac{2}{3}\times128=85 \gg 16\)입니다. 인기 있는 KV 블록에 쿼리가 몰리는 "싱크 로우" 문제는 타일당 쿼리 차원을 최대 \(\sim2kB_k\)개로 청킹하고 미리 예약된 슬롯에 원자 연산 없이 쓰는 방식으로 해결했습니다.
결과
109B MoE 모델(활성 파라미터 6B/토큰, 41레이어, 200K 어휘)로 두 훈련 경로를 비교했습니다: GQA 풀 어텐션(Full), 처음부터 희소 훈련(MSA-PT), 풀 어텐션 체크포인트에서 이어받아 희소 계속훈련(MSA-CPT).
그룹 |
벤치마크 |
Full |
MSA-PT |
MSA-CPT |
|---|---|---|---|---|
일반 |
MMLU |
67.0 |
67.2 |
66.8 |
일반 |
BBH |
67.7 |
66.6 |
66.1 |
수학 |
GSM8K |
76.2 |
77.7 |
73.7 |
수학 |
MathVista |
43.8 |
46.8 |
44.5 |
코드 |
HumanEval |
61.0 |
64.0 |
57.9 |
검색 |
RULER-32K |
75.0 |
77.5 |
75.7 |
이미지 |
VisualWebBench |
55.6 |
68.4 |
59.4 |
영상 |
VideoMME |
41.1 |
45.5 |
39.7 |
MSA-PT가 수학, 이미지, 영상, 장문 검색 벤치마크에서 풀 어텐션을 오히려 앞서는 경우가 많습니다. 희소 어텐션 패턴이 학습 내내 유지되면서 모델 표현이 거기에 맞춰 적응했기 때문으로 분석합니다. MSA-CPT는 풀 어텐션 체크포인트를 보존하는 보수적 경로로, 기존 체크포인트가 있을 때 실용적 전환 수단이 됩니다.
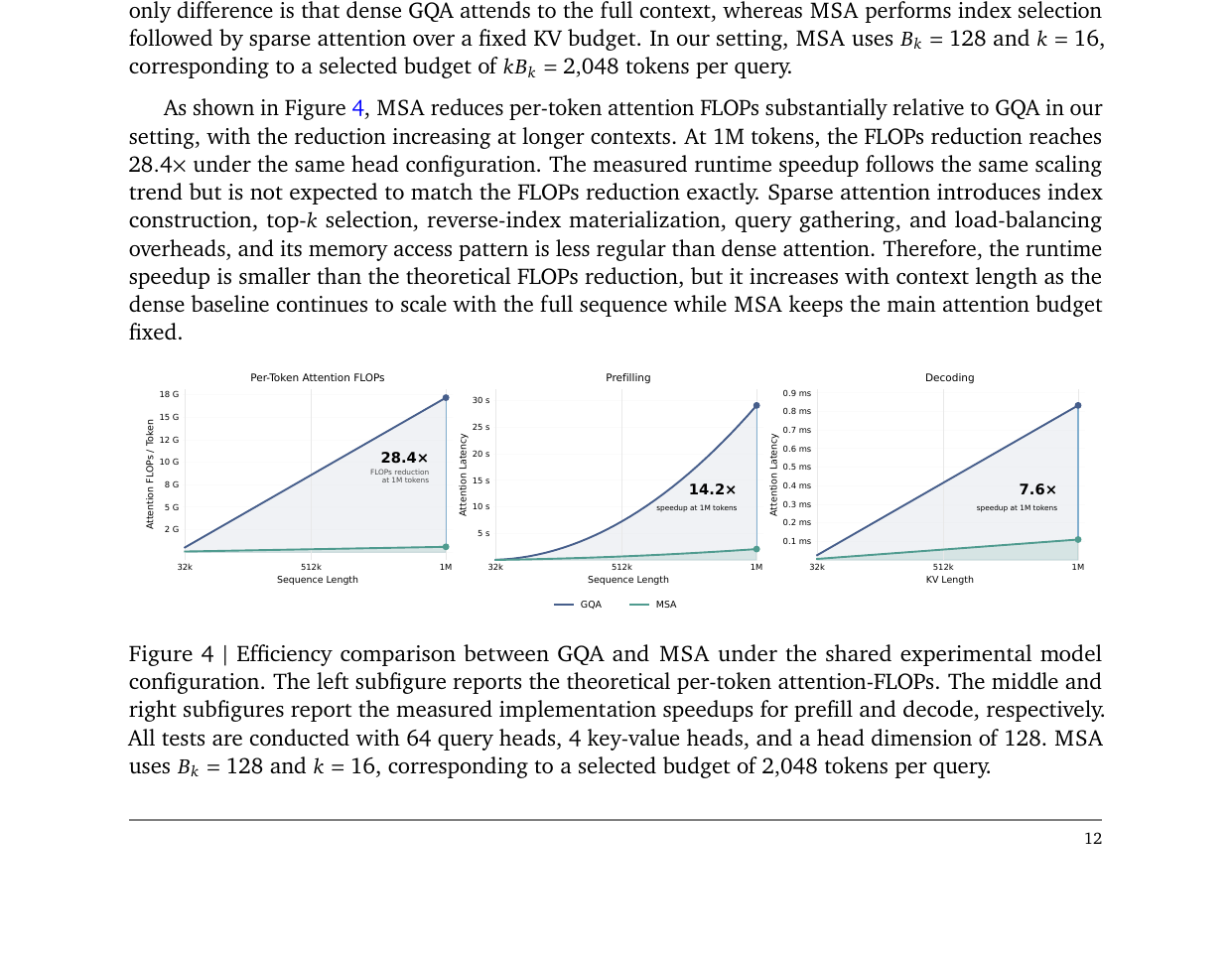
효율성 측면에서 1M 토큰 기준: - 어텐션 FLOPs: 28.4배 감소 - 프리필 레이턴시(H800): 14.2배 개선 - 디코딩 레이턴시(H800): 7.6배 개선
장문 컨텍스트 확장 실험에서도 HELMET-128K, RULER-128K 전체 점수가 풀 어텐션과 0.6점 이내 차이를 유지합니다. 각 쿼리가 여전히 2,048 토큰 예산만 사용하면서 이 수준을 지킨다는 점이 주목할 만합니다.
회고
저자들이 직접 밝힌 다음 과제는 두 가지입니다. 첫째, 장문 검색 일부 서브태스크(예: HELMET의 Rerank/RAG)에서 풀 어텐션보다 소폭 낮은 수치가 남아 있습니다. 선택 예산 확대, 더 긴 희소 훈련, 더 정교한 인덱서 점수 함수가 후보 해결책입니다. 둘째, 이 설계를 RL 후훈련과 에이전트 배포까지 확장하는 문제입니다. 장문 컨텍스트 비용이 가장 큰 운영 제약이 되는 영역입니다.
인덱서 훈련에 KL 손실을 쓰는 방식의 약점도 있습니다. 메인 브랜치가 "어떤 블록이 중요한지" 이미 알고 있다는 가정 아래 이를 흉내 내도록 훈련하는 구조이므로, 메인 브랜치가 선택하지 않은 블록이 실제로는 중요할 경우 인덱서가 이를 배울 수 없습니다. 저자들은 이 문제를 로컬 블록 강제 포함으로 부분 완화했지만, 이론적으로는 열린 문제입니다.
논문을 재구현 관점에서 읽으면 두 개의 암묵적 가정이 눈에 띕니다. 하나는 "쿼리당 2,048 토큰 선택 예산이 모든 태스크에 충분하다"는 전제입니다. 장문 검색 서브태스크에서 성능 저하가 남는 이유가 이 예산 상한에 있을 가능성이 있습니다. 예산을 늘리면 선형 스케일 이점이 줄어드는 트레이드오프가 생겨 배포 설정 그대로 풀기 어렵습니다. 다른 하나는 "109B MoE에서 확인된 동작이 더 큰 모델에서도 유지된다"는 가정입니다. 논문은 이 스케일 단 하나만 검증했으므로, 모델이 커질수록 인덱서 헤드 수나 블록 크기 \(B_k\)를 어떻게 조정해야 하는지는 후속 연구 과제로 남습니다.
정리
- MSA는 각 GQA 그룹이 독립적으로 KV 블록을 선별하는 경량 인덱서를 붙여, 1M 컨텍스트에서 어텐션 FLOPs를 28.4배 줄이고 실제 추론 속도는 프리필 14.2배, 디코딩 7.6배를 달성했습니다.
- 109B MoE 스케일 전훈련 비교에서 수학, 이미지, 영상, 장문 검색 다수 벤치마크에서 풀 어텐션을 앞서거나 동등합니다.
- 아키텍처, 훈련(KL+워밍업+stopgrad), 커널(exp-free TopK, KV-outer)이 공동 설계된 시스템입니다. MiniMax M3 모델이 이 설계로 이미 공개 배포 중입니다.