Program-as-Weights - A Programming Paradigm for Fuzzy Functions
W. Zhang, L. Hotsko, W. Kim, P. Nie, S. Shieber, and Y. Deng, "Program-as-Weights: A Programming Paradigm for Fuzzy Functions," arXiv:2607.02512, 2026.
저자
Yuntian Deng이 이끄는 University of Waterloo Reading to Learn Lab에서 나온 논문입니다. Wentao Zhang, Liliana Hotsko, Pengyu Nie가 워털루 소속이고, Woojeong Kim이 Cornell University에서, Stuart Shieber가 Harvard University에서 참여했습니다. Wentao Zhang, Liliana Hotsko, Woojeong Kim 세 명은 공동 1저자입니다.
Yuntian Deng은 Im2LaTeX(이미지에서 LaTeX 수식을 생성하는 연구)와 WildChat(대규모 대화 데이터셋) 등을 개발한 NLP 연구자입니다. Im2LaTeX에서 이미지를 구조화된 코드로 변환하던 관심이, 이번에는 자연어 명세를 실행 가능한 신경망 어댑터로 변환하는 방향으로 이어졌다고 볼 수 있습니다. Stuart Shieber는 계산언어학 분야의 원로 교수로, 하버드 SEAS에 재직하며 NLP·AI 철학·계산생물학에 걸쳐 연구해왔습니다.
논문 사사 섹션에는 Sasha Rush(Alexander Rush)의 지도에 감사를 표합니다. 현재 저자 명단에는 없지만, 논문 구조를 잡는 초기 프로젝트에서 결정적 역할을 한 것으로 보입니다.
배경
코드베이스를 보면 이런 코드를 자주 볼 수 있습니다.
result = gpt("extract answer from this log line", log_line)
로그에서 중요한 줄만 골라 알림을 보내거나, 망가진 JSON을 수리하거나, 검색 결과를 사용자 의도에 맞게 재정렬하는 작업입니다. 정규식으로는 엣지 케이스가 너무 많고, 규칙 기반으로는 노이즈에 취약하니 LLM API를 호출해버리는 선택입니다. 논문은 이런 종류의 함수를 퍼지 함수(fuzzy function)라 부릅니다. 사람은 직관적으로 처리하지만 정확한 기호 규칙으로 포착하기 어려운 함수입니다.
문제는 이 방식이 비용과 재현성 면에서 취약하다는 점입니다. API 제공사가 모델을 조용히 교체하면 동일한 코드가 다른 결과를 냅니다. 인터넷 연결 없이는 작동하지 않으며, 호출당 비용이 계속 발생합니다.
PAW는 다른 방향을 제안합니다. LLM을 매 입력마다 호출하는 것이 아니라, 함수 명세를 한 번 컴파일해서 로컬에서 실행 가능한 작은 신경망 바이너리로 만듭니다. 고전 컴파일러가 소스 코드를 실행 파일로 변환하듯이, 신경 컴파일러가 자연어 명세를 매개변수 덩어리(PEFT 어댑터)로 변환합니다.
어떻게 만들었나
컴파일러-인터프리터 구조
PAW 프로그램은 두 부분으로 구성됩니다.
\[p = (p_{\text{discrete}},\ p_{\text{continuous}})\]
\(p_{\text{discrete}}\)는 함수 명세를 정리한 의사-프로그램(pseudo-program) 텍스트입니다. \(p_{\text{continuous}}\)는 컴파일러가 생성한 LoRA 어댑터입니다. 실행 시에는 인터프리터가 이 두 가지를 받아 입력 \(x\)에 대해 출력 \(\hat{y}\)를 생성합니다.
\[p = \text{Compiler}(s), \quad \hat{y} = \text{Interpreter}(p,\ x) \approx f(x)\]
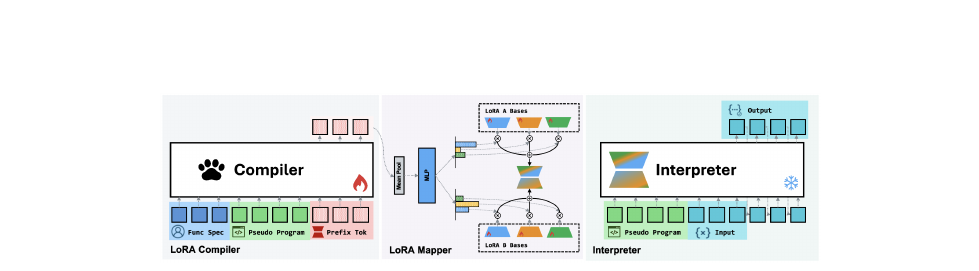
컴파일 단계는 두 단계로 나뉩니다. 첫 번째는 의사 컴파일러(\(C_p\))로, Qwen3-4B-Instruct를 그대로 씁니다. 별도 학습 없이 프롬프트만으로 사용자 명세를 정리된 의사-프로그램으로 변환합니다. 두 번째는 LoRA 컴파일러(\(C_L\))로, 학습된 4B Qwen3 모델입니다. 명세와 의사-프로그램을 읽고 LoRA 어댑터를 생성합니다.
인터프리터는 0.6B Qwen3 모델로, 한 번 설치하면 수많은 PAW 프로그램을 호환 없이 쓸 수 있습니다. LoRA가 핫스왑 가능하기 때문입니다. 인터프리터 자체는 재학습하지 않습니다.
LoRA 매퍼
LoRA 컴파일러의 핵심은 히든 스테이트 \(H \in \mathbb{R}^{L \times T \times d_{\text{teacher}}}\)를 LoRA 행렬로 변환하는 매퍼입니다. 평균 풀링 후 얕은 MLP 트렁크를 통과해 공유 베이스 집합에 대한 혼합 계수 \(\alpha\)를 계산하고, 각 레이어 \(l\)과 모듈 \(m\)의 LoRA를 조합합니다.
\[A^{\text{ex}}_{l,m} = \sum_{n=1}^{N} \alpha^A_{l,m,n} A^{(m)}_n, \quad B^{\text{ex}}_{l,m} = \sum_{n=1}^{N} \alpha^B_{l,m,n} B^{(m)}_n\]
랭크 \(r = 64\), \(N = 64\) 공유 베이스를 씁니다. 함수당 약 38.5M LoRA 파라미터가 인터프리터에 주입됩니다.
흥미로운 점은 더 표현력 높은 매퍼(레이어별 베이스, 위치별 집계 등)가 오히려 성능을 떨어뜨린다는 것입니다. 가장 단순한 설계가 가장 강력했습니다.
FuzzyBench
학습 데이터셋인 FuzzyBench-10M은 29개 테마 버전에 걸쳐 점진적으로 구축된 1,000만 예제 데이터셋입니다. 분류, 형식 변환, 파싱, 퍼지 매칭, 자연어 명령, 에이전트 도구 사용 등 800개 이상의 카테고리를 포함합니다. 테스트 분할은 두 강력한 LLM이 동의한 출력만 포함해 모호한 레이블을 걸러냅니다.
PAW는 논문과 함께 FuzzyBench와 코드를 오픈소스로 공개했습니다.
결과
메인 결과
FuzzyBench 테스트 세트에서 PAW(Qwen3 0.6B)는 73.78%의 정확 매칭 정확도를 달성합니다. 직접 프롬프팅한 Qwen3-32B의 68.70%를 뛰어넘으면서 추론 메모리는 약 50배 적습니다(~1.2 GB vs. ~60 GB at bf16).
방법 |
인터프리터 |
FuzzyBench (%) |
자급자족 |
|---|---|---|---|
gpt-5.2 (API) |
- |
96.09 |
x |
gpt-5-mini (API) |
- |
91.87 |
x |
Qwen3-32B (직접) |
32B |
68.70 |
o |
Qwen3-14B (직접) |
14B |
63.96 |
o |
Qwen3-8B (직접) |
8B |
52.15 |
o |
LM→Code |
29 MB |
35.81 |
o |
Qwen3-0.6B (직접) |
0.6B |
9.84 |
o |
PAW (Qwen3 0.6B) |
0.6B |
73.78 |
o |
PAW (GPT-2 124M) |
124M |
54.39 |
o |
PAW 0.6B(73.78%)는 Qwen3-32B(68.70%)를 앞서고, 메모리 50배 절약에 MacBook M3에서 초당 30토큰으로 실행됩니다. API 비의존 방법 중에서 사실상 최상위입니다.
GPT-2 124M도 54.39%를 달성하는 점도 눈에 띕니다. 인스트럭션 튜닝조차 없는 구형 모델인데도, 컴파일러가 생성한 LoRA만으로 이 수준이 나온다는 것은 컴파일러 자체의 기여가 크다는 방증입니다.
컴파일러 없이는?
동일한 0.6B 베이스 모델, 동일한 데이터, 동일한 학습 예산으로 컴파일러만 제거하면 어떻게 될까요?
방법 (0.6B 베이스) |
정확도 |
|---|---|
Fixed LoRA r=128 |
0.5159 |
Fixed LoRA r=64 |
0.5210 |
Full fine-tuning |
0.5840 |
PAW (Qwen3 0.6B) |
0.7378 |
컴파일러 생성 LoRA가 고정 LoRA 최강 버전보다 21.7포인트, 전체 파인튜닝보다 15.4포인트 앞섭니다. 성능 차이가 컴파일러에서 나온다는 것을 직접 확인한 ablation입니다.
양자화 및 로컬 실행
Q6_K 베이스 + Q4_0 LoRA 조합은 bf16 대비 통계적으로 구별 불가능한 정확도를 유지하면서 총 용량을 ~623 MB로 줄입니다. 더 낮춘 Q4_K_M + Q4_0은 ~507 MB로 줄지만 정확도는 1.3포인트만 떨어집니다.
설정 |
베이스 크기 |
어댑터 크기 |
정확도 |
|---|---|---|---|
bf16 (무양자화) |
1515 MB |
- |
0.6580 |
Q8_0 + Q4_0 LoRA |
805 MB |
23 MB |
0.6567 |
Q6_K + Q4_0 LoRA |
623 MB |
23 MB |
0.6575 |
Q4_K_M + Q4_0 LoRA |
484 MB |
23 MB |
0.6453 |
IQ4_XS + Q4_0 LoRA |
430 MB |
23 MB |
0.6462 |
공유 베이스(~430 MB GGUF)는 모든 PAW 프로그램이 공유하고, 함수당 23 MB LoRA 어댑터만 추가됩니다. 개발자 API는 paw.compile(spec) 한 줄로 컴파일하고, paw.function(id_or_path)로 로드해 파이썬 callable로 쓸 수 있습니다. 컴파일 후에는 인터넷 연결 없이 동작합니다.
회고
저자들이 직접 인정한 한계가 있습니다. Im2LaTeX처럼 긴 구조화 출력이 필요한 작업에서 PAW(LoRA)가 prefix-tuning 전임자보다 약합니다. 의사-프로그램의 길고 상세한 입출력 예시들이 작은 인터프리터의 컨텍스트 예산을 잠식하기 때문입니다. 단문 분류, 형식 변환, 도구 호출에 강한 반면 장문 생성에서는 약점이 있습니다.
또 하나의 한계는 컴파일 단계가 클라우드 GPU를 필요로 한다는 점입니다. 실행은 완전히 로컬이지만 컴파일 자체는 서버에서 이루어집니다. 진정한 오프라인 소프트웨어 스택과는 아직 거리가 있습니다.
SMS 작업에서 PAW 0.6B의 F1이 80.77%로 gpt-5.2의 97.06%에 비해 낮다는 점도 눈에 띕니다. FuzzyBench에서의 우세가 모든 퍼지 작업에서 일관되게 유지되지는 않습니다.
정리
- 자연어 명세를 LoRA 어댑터로 컴파일하는 퍼지 함수 프로그래밍 패러다임입니다. 한 번 컴파일하면 인터넷 없이 로컬 실행됩니다.
- 0.6B 인터프리터 + PAW 어댑터가 Qwen3-32B 직접 프롬프팅을 메모리 50배 절약하면서 앞섭니다. MacBook M3에서 초당 30토큰.
- 컴파일러가 핵심입니다. 동일 베이스로 컴파일러 없이 파인튜닝하면 15포인트 이상 떨어집니다. FuzzyBench 10M과 코드는 오픈소스로 공개됩니다.