SkillOrchestra - Learning to Route Agents via Skill Transfer
도입
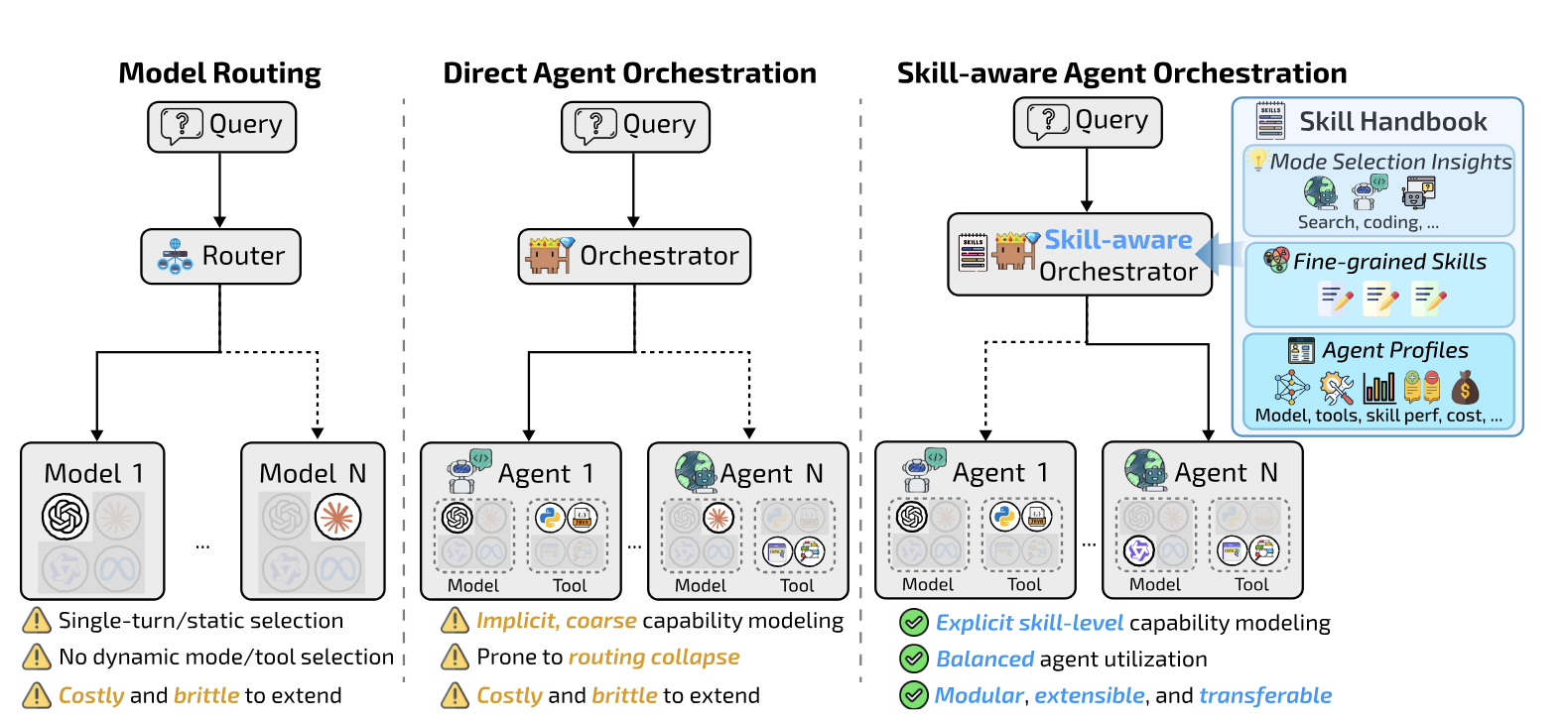
복합 AI 시스템(Compound AI System)이 점점 복잡해지면서, 자연스럽게 이런 질문이 떠오릅니다. "여러 모델과 도구를 어떻게 효율적으로 조합할 것인가?" 기존의 모델 라우팅 방식은 쿼리 단위로 한 번 결정하거나, RL로 엔드투엔드 학습하는 방식이 주를 이뤘습니다. 하지만 전자는 멀티턴 상호작용에서 무력하고, 후자는 비용이 비싸면서도 **라우팅 붕괴(routing collapse)**라는 고질적 문제를 안고 있습니다.
결론부터 말하면, SkillOrchestra는 "스킬"이라는 중간 추상 계층을 도입하여, RL 기반 오케스트레이터 대비 최대 22.5%p 정확도 향상과 700배 학습 비용 절감을 달성했습니다 [1]. 위스콘신-매디슨 대학교와 Salesforce AI Research의 공동 연구입니다.
핵심 요약
- 문제: 기존 모델 라우팅은 쿼리 수준의 단발성 결정이거나, RL 기반 학습은 비용이 높고 라우팅 붕괴 발생
- 해법: 실행 경험에서 재사용 가능한 "스킬 핸드북"을 학습하여, 스킬 단위로 에이전트를 선택
- 성과: 10개 벤치마크에서 SOTA RL 기반 방법(Router-R1, ToolOrchestra) 대비 우수한 정확도-비용 트레이드오프
- 이전성: 한 오케스트레이터에서 학습한 핸드북을 다른 모델에 재훈련 없이 전이 가능
기존 방법의 한계
모델 라우팅의 문제
모델 라우팅(Model Routing)은 쿼리가 들어오면 모델 풀에서 적합한 모델을 선택하는 방식입니다 [2][3]. KNN Router, BERT Router, GraphRouter 같은 판별적(discriminative) 방법들이 대표적이죠.
문제는 이런 방법들이 단발성 결정이라는 점입니다. 쿼리를 한 번 보고 모델을 고르면 끝입니다. 멀티턴 에이전트 워크플로에서는 각 단계마다 다른 능력이 필요한데, 이걸 반영하지 못합니다. 예를 들어 첫 턴에서는 웹 검색이, 두 번째 턴에서는 코드 실행이, 세 번째 턴에서는 수학 추론이 필요할 수 있습니다.
RL 기반 오케스트레이션의 문제
Router-R1 [4]이나 ToolOrchestra [5] 같은 RL 기반 방법은 이 문제를 해결하려 했습니다. LLM을 PPO나 GRPO로 학습시켜 순차적 라우팅 정책을 최적화하는 방식이죠.
하지만 두 가지 문제가 있습니다.
- 학습 비용이 비쌉니다. Router-R1은 14k 샘플로 PPO 학습이 필요합니다.
- 라우팅 붕괴가 발생합니다. 실험 결과 Router-R1은 전체 호출의 98%를 LLaMA-3.1-70B 한 모델에 집중시켰습니다. 다른 모델들은 각각 1% 미만으로, 사실상 멀티모델 라우터가 아니라 단일 모델 호출기에 불과한 셈입니다.
이것이 SkillOrchestra가 해결하려는 핵심 문제입니다.
SkillOrchestra: 스킬 핸드북 기반 오케스트레이션
핵심 아이디어
SkillOrchestra의 발상은 단순합니다. 라우팅 정책을 엔드투엔드로 학습하는 대신, **재사용 가능한 스킬 핸드북(Skill Handbook)**을 구축하자는 것입니다.
스킬(Skill)은 "특정 운영 모드에서 필요한 재사용 가능한 능력 추상화"로 정의됩니다. 예를 들어 코딩 모드 아래에 data_processing.symbolic_logic(규칙 기반 추론)이나 data_processing.numerical_approximation(수치 근사) 같은 세분화된 스킬이 존재합니다.
형식적으로, 스킬 \(\sigma\)는 다음과 같이 표현됩니다:
\[\sigma \triangleq \langle D, I \rangle\]
여기서 \(D\)는 해당 능력의 자연어 설명, \(I\)는 스킬이 적용되는 상황을 알려주는 맥락 지표(키워드, 구조적 패턴 등)입니다.
스킬 핸드북의 구조
스킬 핸드북 \(H\)는 세 가지 계층으로 구성됩니다:
- 모드 수준 메타데이터 (\(V_\Psi\)): 각 운영 모드(검색, 코딩, 답변 등)에 대한 전환 인사이트를 저장합니다. 예를 들어 "산술 연산이 2개 이상이거나 집계가 필요하면 검색 대신 코딩 모드로 전환하라"는 규칙이 여기에 해당합니다.
- 스킬 레지스트리 (\(V_\Sigma\)): 세분화된 스킬 정의와 적용 조건을 관리합니다.
- 에이전트 프로필 (\(V_P\)): 각 에이전트의 스킬별 성공 확률, 비용 특성, 강점과 약점을 요약합니다.
에이전트 프로필은 구체적으로 다음과 같이 정의됩니다:
\[P_{A,\psi} = ({\phi_{A,\sigma}}_{\sigma \in \Sigma_\psi}, \hat{C}_A(\psi), R_{A,\psi}, \Gamma_A)\]
여기서 \(\phi_{A,\sigma}\)는 에이전트 \(A\)의 스킬 \(\sigma\)에 대한 추정 성공 확률, \(\hat{C}_A(\psi)\)는 모드별 예상 비용, \(R_{A,\psi}\)는 라우팅 시그널, \(\Gamma_A\)는 강약점 요약입니다.
배포 시 동작 방식
배포 시 오케스트레이터는 각 타임스텝에서 두 가지를 결정합니다:
1단계 - 모드 선택: 현재 상태 \(s_t\)에서 어떤 운영 모드(검색, 코딩, 답변)를 수행할지 결정합니다.
2단계 - 스킬 기반 에이전트 선택: 선택된 모드에서 활성화된 스킬 집합 \(\Sigma_t\)를 식별하고, 각 에이전트의 역량과 비용을 종합하여 최적 에이전트를 선택합니다:
\[A^*_t = \arg\max_{A \in \mathcal{A}_{\psi_t}} \left[ \sum_{\sigma \in \Sigma_t} w_{t,\sigma} \frac{\alpha_{A,\sigma}}{\alpha_{A,\sigma} + \beta_{A,\sigma}} - \lambda_c \cdot \hat{C}_A(\psi_t) \right]\]
여기서 \(\frac{\alpha_{A,\sigma}}{\alpha_{A,\sigma} + \beta_{A,\sigma}}\)는 Beta 분포의 사후 평균으로 추정된 스킬별 성공 확률입니다. 이 방식이 깔끔한 이유는, 역량 추정과 비용을 명시적으로 분리하여 트레이드오프를 제어할 수 있다는 점입니다.
스킬 핸드북 학습
Phase 1: 스킬 발견과 프로필 구축
탐색 데이터셋 \(D_{\text{train}} = {(q_i, B_i)}_{i=1}^N\)에서, 같은 쿼리에 대해 에이전트를 바꿔가며 얻은 성공/실패 궤적을 대조합니다.
성공 궤적 \(\tau^+\)와 실패 궤적 \(\tau^-\)의 차이 \(D_{\text{diff}}(\tau^+ | \tau^-)\)를 분석하면, 실패한 에이전트에게 부족했던 능력이 드러납니다. LLM 기반 발견기가 이 능력 격차를 재사용 가능한 스킬 정의로 추상화합니다.
에이전트 프로필은 집계된 결과로부터 추정됩니다. 각 에이전트 \(A\), 모드 \(\psi\), 스킬 \(\sigma\)에 대해 성공 확률을 Beta 분포로 모델링합니다:
\[\alpha_{A,\sigma}^{(t+1)} \leftarrow \alpha_{A,\sigma}^{(t)} + \sum_{\tau} \mathbb{I}[A \text{ succeeds on } \sigma]$$ $$\beta_{A,\sigma}^{(t+1)} \leftarrow \beta_{A,\sigma}^{(t)} + \sum_{\tau} \mathbb{I}[A \text{ fails on } \sigma]\]
Beta 분포를 사용하는 건 꽤 합리적인 선택입니다. 데이터가 적을 때는 사전 분포에 의존하고, 데이터가 쌓이면 자연스럽게 정확해지니까요.
Phase 2: 핸드북 정제
스킬이 너무 세분화되거나 중복되는 것을 방지하기 위한 정제 과정입니다:
- 분할(Splitting): 한 스킬에 대한 에이전트 성능 분산이 높으면, 실제로는 여러 하위 능력이 섞여 있을 가능성이 있습니다.
- 병합(Merging): 두 스킬의 에이전트 성능 프로필이 통계적으로 구분 불가능하면 중복이므로 합칩니다.
파레토 최적 핸드북 선택
흥미로운 점은, 스킬을 세분화할수록 항상 좋아지는 게 아니라는 발견입니다. 오케스트레이터의 추론 능력에 따라 적절한 세분화 수준이 다릅니다.
약한 오케스트레이터에게 symbolic_logic과 numerical_approximation을 구분하게 시키면 오히려 잘못된 스킬을 활성화할 수 있습니다. 이런 경우 상위 스킬인 data_processing 수준에서 결정하는 게 더 안정적이죠.
이를 위해 검증 데이터에서 파레토 최적 핸드북을 선택합니다:
\[H_{\text{base}}^{(O)} = \arg\max_{H \subseteq H^*} \mathbb{E}_{q \sim D_{\text{val}}} \left[ R(\tau_H(q)) - \lambda \sum_{t=0}^{|\tau_H(q)|} C(\psi_t, A_t) \right]\]
실험 결과
모델 라우팅 (QA 벤치마크)
Qwen2.5-3B을 오케스트레이터로, 6개 모델 풀(Qwen2.5-7B, LLaMA-3.1-8B/70B, Mistral-7B, Mixtral-8x22B, Gemma-2-27B)을 사용한 실험입니다. 7개 QA 벤치마크에서의 결과를 보겠습니다.
방법 |
평균 EM |
|---|---|
RAG |
26.7 |
Search-R1 |
29.1 |
RouterDC |
31.4 |
FrugalGPT |
31.8 |
Router-R1 (RL) |
41.6 |
SkillOrchestra |
47.4 |
SkillOrchestra+ |
51.6 |
SkillOrchestra가 Router-R1 대비 +5.8, SkillOrchestra+는 +10.0의 개선을 보였습니다. 특히 멀티홉 QA에서 두드러집니다. Musique에서 13.8 → 18.2 → 20.6, Bamboogle에서 51.2 → 58.4 → 63.2로 상승했습니다.
수학 추론(MATH, AMC23)에서는 더 극적입니다. MATH에서 55.8% → 73.6%로 17.8%p 향상, AMC23에서 25.0% → 52.5%로 27.5%p 향상을 달성하면서, 비용은 오히려 약 2배 절감되었습니다.
라우팅 붕괴 해소
Router-R1의 모델 선택 분포를 보면:
- LLaMA-3.1-70B: 98.02%
- 나머지 5개 모델: 각 0~0.92%
사실상 단일 모델 호출기입니다. 반면 SkillOrchestra는:
- Mixtral-8x22B: 44.53%
- Qwen2.5-7B: 25.99%
- LLaMA-3.1-70B: 15.38%
- Qwen2.5-3B: 11.50%
각 모델이 자신의 강점에 맞는 작업을 처리하는, 실질적인 멀티모델 오케스트레이션이 일어나고 있습니다. 오케스트레이터 자체가 직접 답변하는 경우(11.50%)도 있어서, 불필요한 외부 호출을 줄이는 효과도 있네요.
에이전트 오케스트레이션 (FRAMES)
도구 사용까지 포함한 전체 에이전트 오케스트레이션에서도 결과가 좋습니다. Qwen3-8B을 오케스트레이터로, 검색·코딩·답변 3개 모드에 각각 다른 모델 풀을 사용한 FRAMES 벤치마크 결과입니다:
방법 |
정확도 (%) |
비용 ($) |
|---|---|---|
ToolOrchestra (RL) |
76.3 |
92.7 |
GPT-5 (오케스트레이터) |
74.6 |
120.4 |
Claude Opus 4.5 (오케스트레이터) |
77.9 |
758.1 |
Gemini 3 Pro (오케스트레이터) |
78.9 |
1,729.3 |
SkillOrchestra |
84.3 |
72.7 |
SkillOrchestra가 RL 학습된 ToolOrchestra 대비 +8.0%p 정확도를 달성하면서 비용은 21.6% 절감했습니다. GPT-5나 Claude Opus 4.5 같은 강력한 프로프라이어터리 모델을 오케스트레이터로 쓰는 것보다도 정확하면서 훨씬 저렴합니다.
Claude Opus 4.5의 비용(\(758.1)이나 Gemini 3 Pro(\)1,729.3)를 보면,, 강한 모델 하나에 의존하는 전략이 비용 측면에서 얼마나 비효율적인지 잘 드러납니다.
핸드북 전이성
Qwen2.5-3B에서 학습한 스킬 핸드북을 다른 모델에 그대로 적용한 결과:
모델 |
핸드북 없이 |
핸드북 적용 |
향상 |
|---|---|---|---|
Qwen2.5-3B |
40.7% |
56.1% |
+15.4 |
Qwen2.5-7B |
35.7% |
60.0% |
+24.3 |
LLaMA-3.1-8B |
35.5% |
58.0% |
+22.5 |
Mistral-7B |
36.5% |
59.8% |
+23.3 |
Mixtral-8x22B |
46.5% |
61.3% |
+14.8 |
재훈련 없이 일관된 성능 향상을 보입니다. 강한 모델일수록 핸드북과의 시너지가 크다는 점도 흥미롭습니다. 이건 스킬 핸드북이 모델 파라미터에 종속되지 않는 전이 가능한 오케스트레이션 지식을 담고 있다는 의미입니다.
컴포넌트 기여 분석 (Ablation)
FRAMES에서 100개 샘플로 수행한 ablation 결과입니다:
설정 |
정확도 (%) |
비용 ($) |
|---|---|---|
핸드북 없음 |
71.0 |
122.9 |
발견만 (정제·선택 없음) |
79.0 |
5.5 |
정제까지 (선택 없음) |
79.3 |
3.4 |
세분화 스킬 없음 |
80.4 |
15.1 |
전체 시스템 |
85.0 |
9.3 |
핸드북 없이는 71.0%에 비용 \(122.9입니다. 스킬 발견만으로도 비용이\)5.5로 급감하고, 전체 시스템에서 85.0%/$9.3으로 최적 트레이드오프를 달성합니다. 정제가 비용을 줄이고, 세분화 스킬이 정확도를 높이는 데 각각 기여하는 구조입니다.
비판적 분석
잘한 점
스킬이라는 중간 추상화: 쿼리 수준과 에이전트 수준 사이에 "스킬"을 놓은 것은 직관적이면서도 효과적입니다. 인간이 팀을 구성할 때도 "이 일에는 어떤 역량이 필요하고, 누가 그 역량이 있나?"를 따지는 것과 같은 원리죠.
라우팅 붕괴 해결: RL 기반 방법의 98% 편중 문제를 명시적 역량 모델링으로 자연스럽게 해결한 것은 가치가 있습니다.
비용 효율성: 700배(Router-R1 대비), 300배(ToolOrchestra 대비) 학습 비용 절감은 실용적으로 큰 의미가 있습니다. 50개 미만의 샘플로 핸드북을 학습할 수 있다는 점은 빠른 적용이 가능하다는 뜻입니다.
해석 가능성: 어떤 스킬이 활성화되었고, 왜 특정 에이전트가 선택되었는지 추적할 수 있습니다. RL 기반 방법의 블랙박스 특성과 대비됩니다.
아쉬운 점
스킬 발견의 LLM 의존성: 스킬을 발견하고 정제하는 과정에서 LLM(GPT-5로 추정)을 사용합니다. 이 LLM의 품질에 핸드북의 품질이 좌우될 수 있는데, 이에 대한 민감도 분석이 없습니다.
동적 환경 적응: 모델 풀이 변경되거나 새 도구가 추가되면 핸드북을 어떻게 업데이트하는지에 대한 논의가 부족합니다. "전이 가능"하다고 했지만, 이건 기존 모델 풀 내에서 오케스트레이터만 바꾼 경우입니다.
실험 환경의 제한: FRAMES 벤치마크의 최대 50턴 설정이 실제 복합 에이전트 시나리오를 충분히 반영하는지는 의문입니다. 더 긴 호라이즌에서의 성능 변화가 궁금합니다.
스킬 세분화의 자동 결정: 파레토 최적 핸드북 선택이 검증 데이터에 의존하는데, 검증 데이터가 실제 배포 환경의 분포와 다를 경우 최적 세분화 수준이 달라질 수 있습니다.
결론
SkillOrchestra는 복합 AI 시스템의 오케스트레이션 문제에 "스킬"이라는 중간 추상화를 도입하여, RL 없이도 효과적인 멀티에이전트 라우팅을 달성했습니다. 라우팅 붕괴를 해결하고, 학습 비용을 수백 배 절감하면서, 핸드북의 전이 가능성까지 확보한 것은 실용적으로 의미가 큽니다.
제 생각에는, 이 접근이 특히 가치 있는 이유가 모델 풀이 빠르게 변하는 현실에 있습니다. 매달 새 모델이 나오는 상황에서, RL로 정책을 처음부터 다시 학습하는 건 현실적이지 않습니다. 스킬 핸드북이라는 독립적 지식 구조를 유지하고, 새 모델의 프로필만 추가하는 방식이 훨씬 확장 가능하죠.
에이전트 오케스트레이션이 점점 중요해지는 시점에서, 스킬 기반 접근이 어디까지 확장될 수 있을지 지켜볼 필요가 있습니다.
References
[1] J. Wang, Y. Ming, Z. Ke, S. Joty, A. Albarghouthi, and F. Sala, "SkillOrchestra: Learning to Route Agents via Skill Transfer," arXiv preprint arXiv:2602.19672, 2026.
[2] L. Chen, M. Zaharia, and J. Zou, "FrugalGPT: How to use large language models while reducing cost and improving performance," Transactions on Machine Learning Research, 2024.
[3] Q. J. Hu et al., "Routerbench: A benchmark for multi-LLM routing system," arXiv preprint arXiv:2403.12031, 2024.
[4] H. Zhang, T. Feng, and J. You, "Router-R1: Teaching LLMs multi-round routing and aggregation via reinforcement learning," in NeurIPS, 2025.
[5] H. Su et al., "ToolOrchestra: Elevating intelligence via efficient model and tool orchestration," arXiv preprint arXiv:2511.21689, 2025.