HyGRAG - A Unified Framework for Context-Aware and Relation-Aware Graph Retrieval-Augmented Generation
H. Zhong, Y. Sun, A. Zhang, C. Wang, L. Chen, and Y. Yang, "A Unified Framework for Context-Aware and Relation-Aware Graph Retrieval-Augmented Generation," arXiv:2606.18075, 2026.
Graph RAG는 크게 두 방향으로 발전해왔습니다. 엔티티를 추출해 지식 그래프를 만드는 관계 중심 방법(Microsoft GraphRAG, HippoRAG)과, 텍스트 청크를 계층적으로 요약하는 맥락 중심 방법(RAPTOR, EraRAG)입니다. 두 방법은 각각 장단점이 있고, 이를 합치려는 시도도 있었습니다.
HyGRAG의 출발점은 다른 곳에 있습니다. "합치는 것만으로는 부족하다"는 주장입니다. 청크와 엔티티를 같은 그래프에 넣더라도, 둘이 여전히 원본 텍스트에 각자 묶여 있으면 진정한 지식 융합이 일어나지 않습니다. 질문이 들어올 때 맥락과 관계는 여전히 따로따로 검색됩니다.
이 논문은 ACM Web Conference 2026(WWW '26)에 채택되었습니다. 코드는 github.com/zjunet/HyGRAG에 공개되어 있습니다.
저자
총 6명입니다. 절강대학교(ZJU) 그룹이 중심이고, FinVolution 산업 그룹이 합류했습니다.
Haoyang Zhong(제1저자)은 난양공과대학교(NTU) 방문 연구원으로 실험을 수행했습니다. 쑨이페이(교신저자)은 ZJU 조교수로 NeurIPS 2024 G-Retriever 저자입니다. Graph RAG와 GNN 파인튜닝이 주요 연구 분야입니다. Antong Zhang은 ZJU 소속 3저자입니다.
*왕청핑은 FinVolution Group의 Chief AI Scientist로 NeurIPS 2023 Universal Prompt Tuning for GNN 저자입니다. *천레이*은 HKUST(GZ) Information Hub 학장이자 ACM·IEEE 펠로우로, 이번 논문에서는 FinVolution 소속으로 참여했습니다. 2026-27 VLDB Endowment 의장입니다. *양양(교신저자)은 ZJU 인공지능 학과장이자 그룹 PI입니다.
ZJU 학술 그룹과 FinVolution 산업 그룹이 결합한 구도입니다. 쑨이페이의 G-Retriever 이후 Graph RAG 방향을 실용화하는 연장선에 있는 논문입니다.
배경
RAG의 핵심 약점은 멀티홉 추론입니다. "Jan Klapáč가 태어난 도시의 성 이름은?"처럼 여러 단계를 거쳐야 답이 나오는 질문에서, 단순 벡터 검색은 각 단계의 청크를 따로 가져오지만 그 사이의 연결을 만들지 못합니다.
Microsoft GraphRAG류의 관계 중심 방법은 엔티티 추출 오류가 누적됩니다. Named Entity Recognition이 틀리면 그 오류가 전체 지식 그래프에 퍼집니다. 반대로 RAPTOR 같은 맥락 중심 방법은 텍스트를 잘 보존하지만 멀티홉 논리 연결이 안 됩니다.
두 방법의 약점을 동시에 해결하는 것이 HyGRAG의 목표입니다. 단순히 합치는 것이 아니라, 두 표현을 함께 클러스터링하고 그 위에서 LLM 요약을 생성해 원본 텍스트를 넘어서는 "창발적 이해"를 만드는 것입니다.
방법론
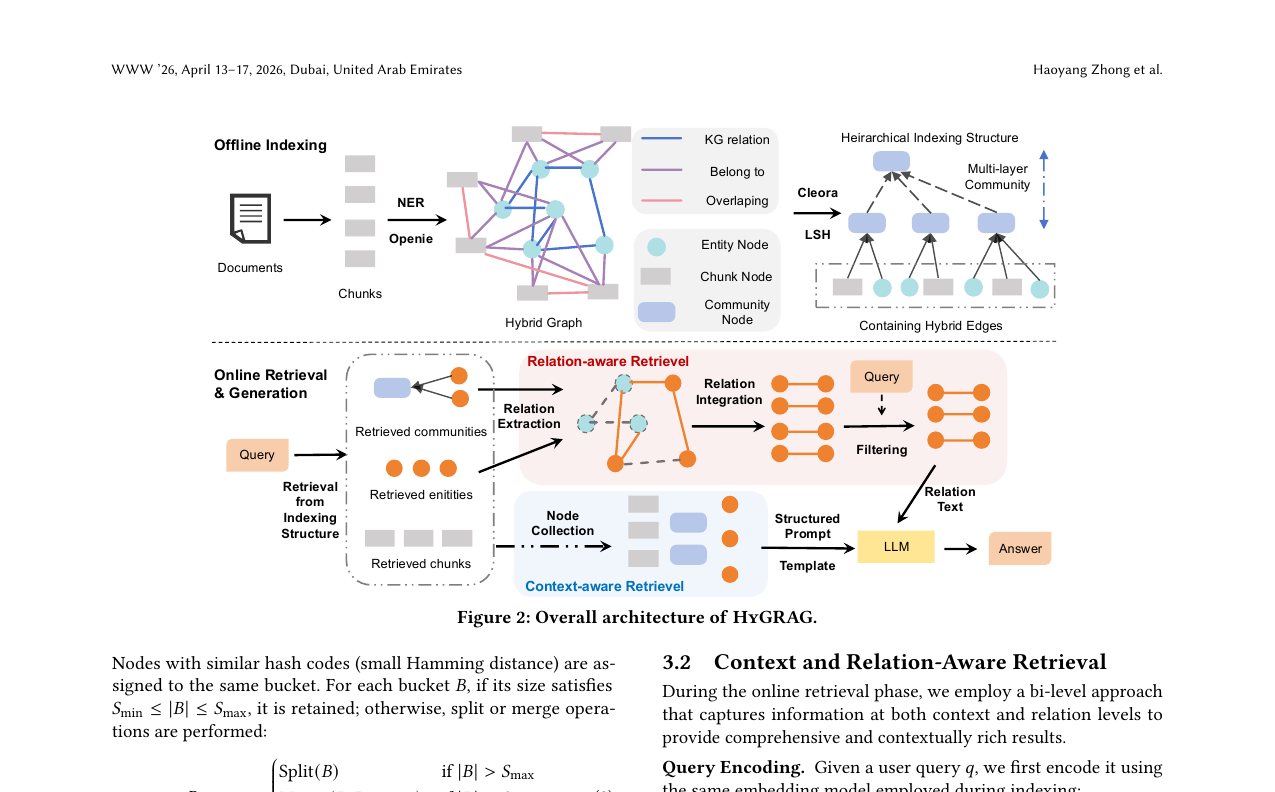
HyGRAG는 네 단계로 구성됩니다.
하이브리드 그래프 구성
청크 그래프 \(G_c\)와 엔티티 그래프 \(G_e\)를 별도로 만든 뒤, 크로스 레이어 엣지 \(E_{ce}\)로 연결합니다.
\[G_{\text{hybrid}} = (V^c \cup V^e,\; E^c \cup E^e \cup E_{ce})\]
청크 간 엣지는 임베딩 유사도가 아니라 공유 엔티티 수로 결정합니다. 두 청크 \(c_i\), \(c_j\)가 3개 이상의 엔티티를 공유하면 엣지가 생성됩니다.
\[( c_i, c_j ) \in E^c \iff |E_i \cap E_j| > 3\]
피상적인 텍스트 유사도보다 의미론적으로 강한 연결을 만듭니다.
계층적 인덱스 구성
하이브리드 그래프 위에 계층적 트리 구조 \(T_{\text{index}}\)를 만듭니다. Cleora로 구조 인식 임베딩을 생성하고, LSH(Locality-Sensitive Hashing)로 노드를 클러스터링합니다. 각 클러스터(커뮤니티)에 대해 Llama3.1-8B-Instruct로 요약 \(t_C\)를 생성합니다.
\[t_C = \text{LLM}_{\text{summarize}}(\{v \mid v \in C\})\]
이 요약이 다음 레이어의 노드가 되고, 같은 과정을 \(L\)번 반복합니다. 결과는 \(L\)층 계층 트리입니다. 요약이 원본 청크와 엔티티 양쪽 정보를 함께 담기 때문에, 원본 텍스트에서는 따로 존재했던 맥락과 관계 정보가 하나의 표현으로 합쳐집니다.
이중 검색
쿼리가 들어오면 두 방향으로 동시에 검색합니다.
맥락 인식 검색(Context-Aware): 커뮤니티·청크·엔티티 노드 전체에서 유사도 기반 검색을 수행합니다. 추상화 수준별로 세 가지 결과 집합을 반환합니다.
관계 인식 검색(Relation-Aware): 검색된 커뮤니티에 속한 엔티티를 수집한 뒤, 그 엔티티들과 연결된 관계 트리플렛을 추출합니다. 삼중 임베딩 \(z_{(h,r,t)}\)으로 관련성을 다시 필터링합니다.
\[R_{\text{retrieved}} = \text{TopK}(\{(h,r,t) \in R_{\text{all}} \mid z_{(h,r,t)} = \text{LMEmbedding}(h \oplus r \oplus t)\}, k)\]
최종 컨텍스트는 커뮤니티 요약, 청크, 엔티티, 관계 트리플렛 네 가지를 구조화된 프롬프트로 묶어 LLM에 전달합니다.
동적 업데이트
새 문서가 들어오면 계층 트리를 처음부터 재구성하지 않습니다. 새 콘텐츠의 임베딩과 가장 유사한 커뮤니티를 찾아 붙이고, 그 경로의 조상 요약만 다시 만듭니다. 온라인 검색 효율에는 영향을 주지 않습니다.
결과
Llama-3.1-8B-Instruct 기반, 5개 데이터셋 실험입니다.
방법 |
PopQA (Acc) |
MultiHop-RAG (Acc) |
MuSiQue (Acc) |
HotpotQA (Acc) |
QuALITY (Acc) |
|---|---|---|---|---|---|
VanillaRAG |
66.98 |
58.49 |
32.30 |
60.97 |
56.38 |
RAPTOR |
66.33 |
58.72 |
31.17 |
OOT |
58.08 |
EraRAG |
61.40 |
58.67 |
26.70 |
61.03 |
60.79 |
L-LightRAG |
67.05 |
53.05 |
30.63 |
OOT |
48.05 |
HippoRAG2 |
68.12 |
61.66 |
30.23 |
OOT |
45.98 |
HiRAG |
53.18 |
54.00 |
26.20 |
OOT |
55.83 |
HyGRAG |
72.34 |
65.41 |
35.87 |
68.72 |
59.49 |
OOT(Out Of Time)는 2일 초과로 실험 완료 불가를 의미합니다. HyGRAG는 5개 데이터셋에서 최고 또는 2위를 기록했습니다.
주목할 점이 두 가지입니다. 첫째, 다수의 관계 중심 방법(HiRAG, G-LightRAG, ArchRAG)이 HotpotQA, MuSiQue에서 OOT를 기록했습니다. 규모가 커지면 기존 커뮤니티 클러스터링 방법의 인덱싱 비용이 감당이 안 됩니다. HyGRAG는 LSH 기반 클러스터링으로 이 문제를 피했습니다.
둘째, QuALITY 데이터셋(독해 이해)에서는 EraRAG(60.79%)가 HyGRAG(59.49%)보다 높습니다. 독해 중심 태스크에서는 관계 정보가 오히려 소형 LLM을 혼란시킬 수 있습니다. 어블레이션에서도 엔티티·관계를 제거했을 때 QuALITY 점수가 오르는 현상이 확인되었습니다.
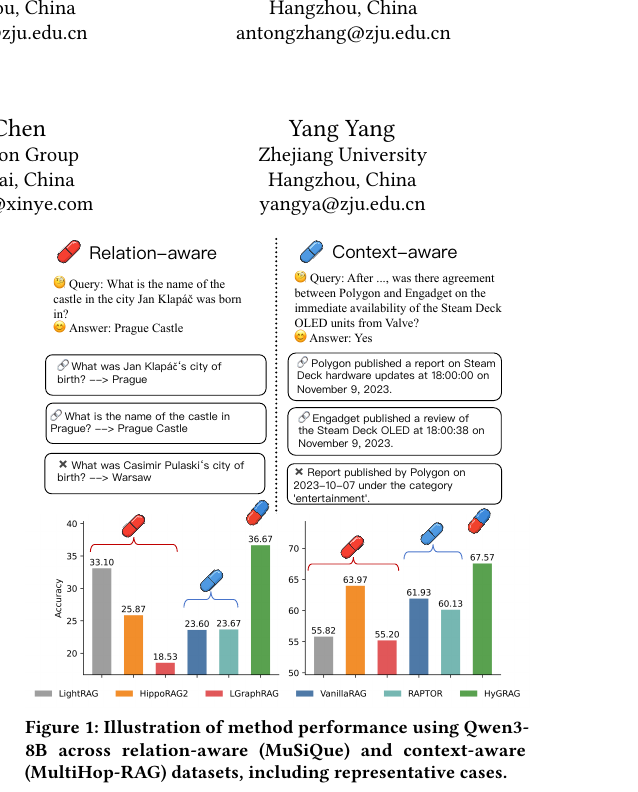
Qwen3-8B 기준 테스터 비교입니다. MuSiQue(관계 인식)에서 HyGRAG 36.67% vs LightRAG 33.10%, HippoRAG2 25.87%. MultiHop-RAG(맥락 인식)에서 HyGRAG 67.57% vs VanillaRAG 55.82%, RAPTOR 61.93%.
효율성 측면에서 HyGRAG는 HiRAG+RAPTOR 조합 대비 동등하거나 높은 정확도를 유지하면서 토큰을 30% 적게 씁니다(MultiHop-RAG: HyGRAG 5,030 토큰 vs HiRAG+RAPTOR 7,171 토큰).
회고
저자들이 직접 인정한 한계가 있습니다.
소형 LLM의 관계 정보 과부하. 독해 태스크에서 관계 트리플렛이 소형 LLM을 혼란시킵니다. 저자들은 이를 명시적으로 인정하며 "+Inference" 모드(모델이 도메인 지식을 적극 활용하도록 프롬프트 강화)로 부분 보완합니다. 근본적 해결은 아닙니다.
코퍼스 확장 시 커뮤니티 품질 저하. 동적 업데이트 실험에서 초기 코퍼스 비율이 낮을수록 성능이 떨어집니다. 처음부터 20% 데이터로 인덱스를 만들고 80%를 점진적으로 추가하면 정적 구성 대비 1~2% 성능 저하가 생깁니다. 미미하지만 존재합니다.
LLM 요약 비용. 계층 인덱스 구성 단계에서 LLM 요약을 반복 생성합니다. 오프라인 단계이므로 온라인 검색 효율에는 영향이 없지만, 인덱스 구성 비용 자체는 높습니다. 논문에는 구체적인 인덱싱 시간 비교가 부분적으로만 제시되어 있습니다.
임베딩 모델 의존성. BGE-M3를 기준으로 실험했습니다. 다른 임베딩 모델로 실험한 결과를 Appendix D에 추가했고, 성능이 안정적임을 보고합니다. 다만 도메인 특화 임베딩이 필요한 환경에서의 성능은 추가 검증이 필요합니다.
정리
- 청크와 엔티티를 함께 클러스터링해 "지식 융합" 요약을 생성하는 것이 핵심. 단순 병합이 아닙니다.
- 멀티홉 추론 태스크에서 평균 9.7%, HotpotQA 기준 최대 12.2% 향상. 다수의 기존 방법이 OOT를 기록한 규모에서도 완주합니다.
- 읽기 이해 중심 태스크에서는 관계 정보가 오히려 방해가 될 수 있습니다. 모든 상황에서 최선은 아닙니다.
KMS 시리즈의 개념 해설 글: HyGRAG - 단순 벡터 검색이 놓치는 것