Gated Attention for Large Language Models - Non-linearity, Sparsity, and Attention-Sink-Free
Z. Qiu, Z. Wang, B. Zheng, Z. Huang, et al., "Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free," arXiv:2505.06708, 2025.
소프트맥스 어텐션은 2017년 "Attention Is All You Need" 이후 한 번도 근본적으로 건드려진 적 없는 트랜스포머의 심장부입니다. Qwen 팀은 그 심장부에 게이트 하나를 달았을 때 무슨 일이 일어나는지 30개 이상의 변형 실험으로 체계적으로 조사했고, 그 결과물로 NeurIPS 2025 Best Paper Award를 받았습니다.
저자
치우쯔한, Zekun Wang, Bo Zheng은 Alibaba Qwen Team 소속 공동 1저자들이고, 에든버러 대학교의 Zeyu Huang도 공동 1저자로 합류했습니다. 교신저자는 류다이헝와 린준양입니다.
외부에서 합류한 가장 주목할 인물은 MIT CSAIL의 양송린입니다. Gated DeltaNet(Mamba2에 게이팅과 Delta Rule을 결합한 ICLR 2025 연구)으로 선형 어텐션 계열에서 게이팅의 효과를 직접 다룬 연구자가, 이번에는 소프트맥스 어텐션에 같은 질문을 던지는 팀에 합류한 구도입니다. 양송린의 게이팅 경험이 이 논문의 분석 깊이와 직결됩니다.
배경
게이팅 메커니즘은 신경망 곳곳에서 쓰여왔습니다. LSTM, GRU, Highway Networks, 그리고 현재 대부분의 LLM FFN에서 쓰이는 SwiGLU까지 전부 게이트를 씁니다. 그런데 정작 트랜스포머의 핵심인 소프트맥스 어텐션 층에 게이팅을 체계적으로 적용한 연구는 거의 없었습니다.
일부 연구(Switch Heads, Native Sparse Attention)는 게이팅을 선택 메커니즘에 사용하면서 부수적으로 성능 향상을 보였지만, 게이팅 자체의 기여를 다른 요소(Expert 라우팅, 희소성 패턴)와 분리해 측정하지 못했습니다. "게이팅이 왜 효과적인가"라는 질문에 엄밀한 답이 없었다는 뜻입니다.
이 논문은 그 답을 찾기 위해 어텐션 층 내부의 5개 위치에 다양한 형태의 게이트를 체계적으로 실험했습니다.
게이팅 층
표준 트랜스포머 어텐션을 짚고 넘어갑니다. QKV 선형 투영 이후 SDPA(Scaled Dot-Product Attention)를 거쳐 Multi-Head Concatenation과 출력 레이어 \(W_O\)로 이어지는 구조입니다.
\[\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^T}{\sqrt{d_k}}\right) V\]
\[O = \text{MultiHead}(Q, K, V)W_O\]
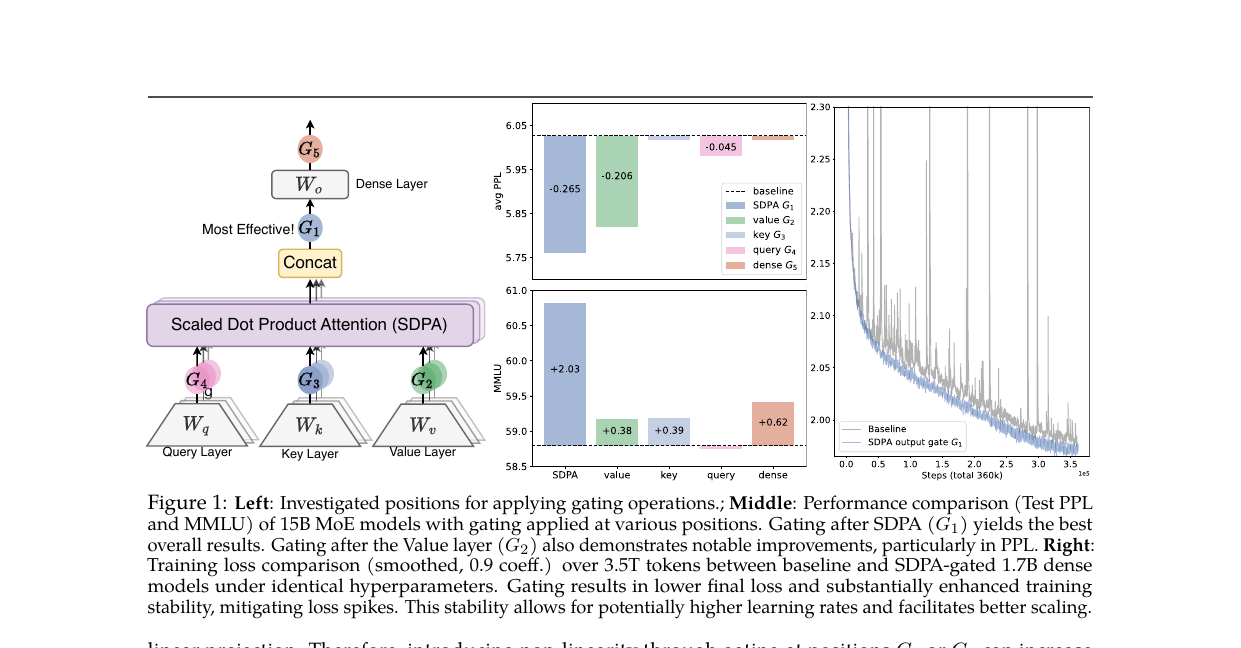
게이팅은 이 흐름 중 어디에든 삽입할 수 있습니다. 논문은 5개 위치를 정의했습니다. Q/K/V 선형 투영 이후인 \(G_2, G_3, G_4\), SDPA 출력 이후인 \(G_1\), 최종 출력 레이어 이후인 \(G_5\)입니다.
게이팅 연산의 수식은 다음과 같습니다.
\[Y' = g(Y, X, W_\theta, \sigma) = Y \odot \sigma(XW_\theta)\]
\(Y\)는 게이팅 대상 입력, \(X\)는 게이팅 점수를 계산하는 데 쓰는 입력(어텐션의 경우 현재 쿼리의 히든 스테이트), \(W_\theta\)는 학습 가능한 게이트 파라미터, \(\sigma\)는 시그모이드 함수입니다. 게이트는 \([0, 1]\) 범위의 스코어로 출력을 채널별로 선택적으로 통과시킵니다.
30개 이상의 변형 실험 결과, SDPA 출력에 헤드별(head-specific) 원소별(elementwise) 시그모이드 게이트(\(G_1\))를 곱하는 방식이 가장 효과적이었습니다. 추가 파라미터는 전체 모델 대비 1% 남짓이고, 추론 레이턴시 증가는 2% 미만입니다.
왜 작동하는가
논문은 두 가지 핵심 요인을 분리해 분석합니다.
비선형성(Non-linearity). 멀티헤드 어텐션에서 \(i\)번째 토큰의 \(k\)번째 헤드 출력은 다음과 같이 표현됩니다.
\[o_i^k = \left(\sum_{j=0}^{i} S_{ij}^k \cdot X_j W_V^k\right) W_O^k\]
\(W_V^k\)와 \(W_O^k\)는 연속된 두 선형 투영이므로 하나의 저랭크(low-rank) 선형 변환으로 합쳐집니다. \(d_k < d_\text{model}\)인 GQA 환경에서 이 병목은 더 두드러집니다. \(G_1\)에 게이트를 추가하면 \(W_V\)와 \(W_O\) 사이에 비선형성이 들어가 이 저랭크 제약이 깨집니다. 같은 이유로 \(G_2\) 위치의 게이팅도 \(V\) 투영 내부에 비선형성을 도입해 성능을 끌어올립니다.
희소성(Sparsity). \(G_1\) 위치의 시그모이드 게이트 점수 분포를 측정하면 평균값이 0.116으로 0에 가깝게 집중돼 있습니다. 이 희소한 게이트는 현재 쿼리와 무관한 컨텍스트를 SDPA 출력에서 걸러냅니다. 게이트가 쿼리 히든 스테이트 \(X_i\)로부터 계산되기 때문에 "이 쿼리에 대해 이 어텐션 헤드의 출력이 얼마나 중요한가"를 동적으로 판단하는 구조입니다.
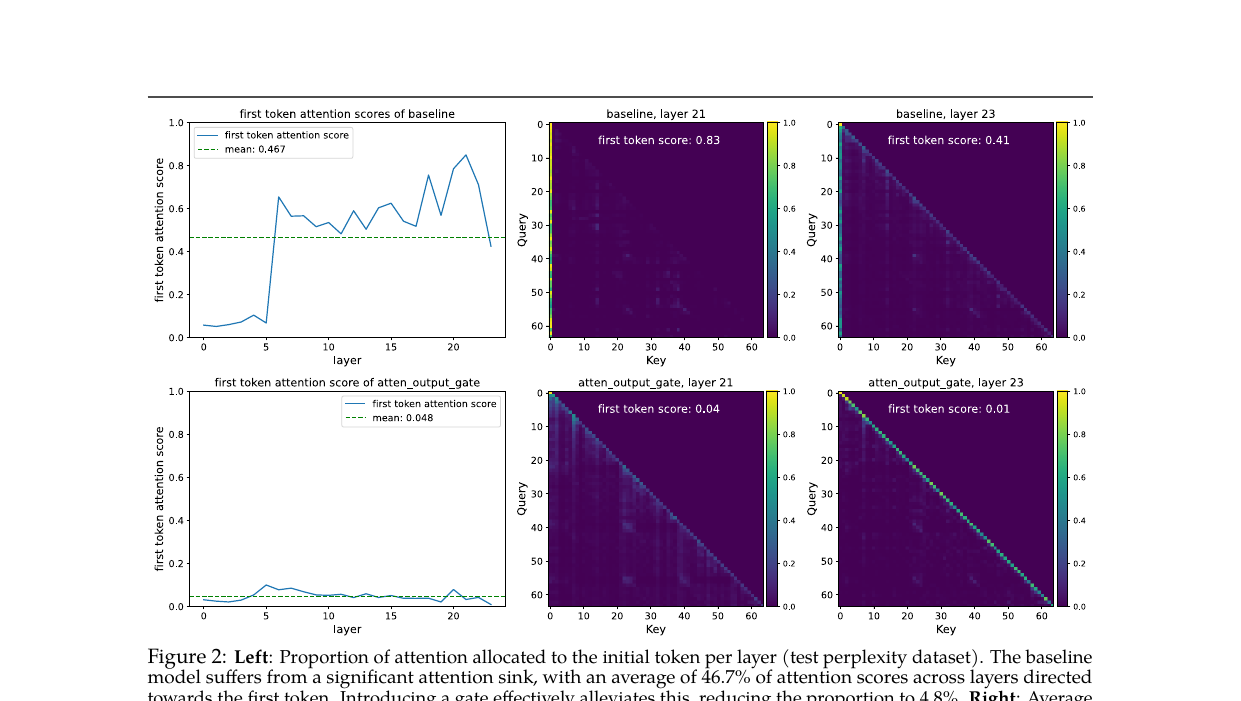
이 희소성이 어텐션 싱크(attention sink) 현상을 제거합니다. 표준 소프트맥스 어텐션에서는 첫 번째 토큰이 전 층에 걸쳐 평균 46.7%의 어텐션 가중치를 독식하는 현상이 관찰됩니다. SDPA 출력에 쿼리 의존적 희소 게이팅을 적용하면 이 비율이 4.8%로 떨어집니다. Figure 2의 히트맵에서 이 변화는 시각적으로 선명합니다. 베이스라인의 layer 21에서 첫 번째 토큰 점수가 0.83인 반면, 게이팅 모델은 같은 층에서 0.04를 기록했습니다.
결과
MoE 15B 모델(15A2B, 400B 토큰 학습)에서 게이팅 위치별 비교:
방법 |
Avg PPL |
Hellaswag |
MMLU |
GSM8k |
C-eval |
|---|---|---|---|---|---|
Baseline |
6.026 |
73.07 |
58.79 |
52.92 |
60.26 |
SDPA Elem \(G_1\) |
5.761 |
74.64 |
60.82 |
55.27 |
62.20 |
v Elem \(G_2\) |
5.820 |
74.38 |
59.17 |
53.97 |
61.00 |
k Elem \(G_3\) |
6.016 |
72.88 |
59.18 |
50.49 |
61.74 |
q Elem \(G_4\) |
5.981 |
73.01 |
58.74 |
53.97 |
62.14 |
Dense \(G_5\) |
6.017 |
73.32 |
59.41 |
50.87 |
59.43 |
SDPA 출력 게이팅(\(G_1\))이 PPL을 0.265 줄이고 MMLU를 2.03점 올렸습니다. 같은 파라미터 예산으로 Query 헤드 수를 48개로 늘리거나 전문가 4개를 추가한 베이스라인 변형보다도 더 높은 성능입니다.
Dense 1.7B 모델에서 설정별 비교:
설정 |
방법 |
Avg PPL |
HumanEval |
MMLU |
GSM8k |
Hellaswag |
|---|---|---|---|---|---|---|
400B 토큰, bsz=1024 |
Baseline |
7.499 |
28.66 |
50.21 |
27.82 |
64.94 |
SDPA Elem |
7.404 |
29.27 |
51.15 |
28.28 |
65.48 |
|
3.5T 토큰, bsz=2048 |
Baseline |
6.180 |
34.15 |
59.10 |
69.07 |
68.02 |
SDPA Elem |
6.130 |
37.80 |
59.61 |
70.20 |
68.84 |
|
1T 토큰, LR=8×10⁻³ |
Baseline |
7.363 |
29.88 |
54.44 |
32.22 |
65.43 |
SDPA Elem |
7.078 |
31.71 |
56.47 |
39.73 |
67.38 |
특히 마지막 행은 게이팅의 학습 안정성 효과를 보여줍니다. 학습률을 \(8 \times 10^{-3}\)으로 키우면 베이스라인은 손실 폭증으로 발산하지만, SDPA 게이팅 모델은 수렴합니다. 같은 LR에서 게이팅 모델의 GSM8k 점수가 39.73으로 베이스라인(32.22)보다 7.5점 높습니다.
컨텍스트 길이 확장 실험에서도 효과가 드러납니다. RULER 벤치마크 기준, 64k 컨텍스트에서 베이스라인이 실패(발산)하는 반면 SDPA 게이팅 모델은 YaRN 없이도 79.77을 기록했습니다. YaRN으로 128k까지 확장한 경우에도 66.60 대 31.65로 베이스라인을 크게 앞섰습니다.
회고
논문은 Limitations 절에서 솔직하게 두 가지를 인정합니다.
게이팅이 어텐션 동역학과 전체 학습 과정에 미치는 더 넓은 함의는 충분히 탐구되지 않았습니다. 어텐션 싱크를 제거하면 장문 컨텍스트 일반화가 향상된다는 관찰은 있지만, 어텐션 싱크가 정확히 왜 컨텍스트 길이 일반화를 방해하는지 이론적 설명은 없습니다.
Appendix A.5의 추가 실험에서도 한계가 드러납니다. 게이팅과 Sandwich Normalization이 모두 Massive Activation을 줄여 학습 안정성을 높이는 것에 착안해, attention/FFN 출력에 클리핑(-clip, clip)을 적용하는 더 단순한 방법을 시도했습니다. 그런데 클립 값을 300 또는 100으로 설정해도 학습률 \(8 \times 10^{-3}\)에서 여전히 발산이 일어났습니다. 학습 불안정성의 근본 원인이 Residual 내 큰 활성화값에만 있지 않다는 뜻으로, 게이팅이 왜 안정성을 가져오는지의 완전한 설명은 여전히 열린 문제로 남습니다.
정리
- 소프트맥스 어텐션 출력(\(G_1\)) 직후에 헤드별 시그모이드 게이트를 곱하는 것이 30개 이상의 변형 중 가장 효과적입니다. 파라미터 증가 1%, 레이턴시 증가 2% 미만으로 PPL -0.2, MMLU +2점을 가져옵니다.
- 효과의 두 원인은 비선형성(W_V와 W_O 사이 저랭크 병목 해소)과 희소성(쿼리 의존적 게이트가 무관한 컨텍스트를 차단)으로 분리해 설명됩니다.
- 어텐션 싱크가 첫 토큰 집중 비율을 46.7%에서 4.8%로 낮추는 부수 효과로 사라지며, 이것이 컨텍스트 길이 확장 성능 향상으로 이어집니다. Qwen3-Next는 이 구조를 기본 아키텍처로 채택했습니다.